




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive在线教育可视化课程推荐系统技术说明
一、技术背景与需求分析
随着教育数字化转型的加速,中国慕课学习者规模已突破6.8亿人次,但课程完成率不足8%,存在严重的“选课迷茫”现象。学习者面临海量课程资源时,亟需个性化推荐系统解决信息过载问题。传统推荐系统面临三大核心挑战:
- 数据规模:需处理PB级用户行为日志和课程元数据,包含结构化数据(如成绩表)和非结构化数据(如视频观看日志)。
- 计算效率:传统MapReduce框架迭代计算耗时过长,无法满足实时推荐需求。
- 多维分析:需融合评分、学习行为、社交关系等多源异构数据,构建用户-课程复杂关联模型。
Hadoop+Spark+Hive技术组合为构建智能化课程推荐系统提供了完整解决方案:
- Hadoop:通过HDFS分布式存储和YARN资源管理,实现PB级数据的高可靠存储与弹性计算资源分配。
- Spark:基于内存计算和RDD数据抽象,提升数据处理速度,其MLlib库支持矩阵分解等算法。
- Hive:将结构化数据映射为数据库表,提供类SQL查询语言(HQL),降低数据分析复杂度。
二、系统架构设计
系统采用分层架构设计,包含数据采集、存储、处理、推荐、可视化和应用接口六层,各层协同完成推荐任务。
1. 数据采集层
- 工具链:Flume+Kafka+Scrapy
- Flume:采集静态数据(如课程资源元数据),通过HTTP Source接收日志文件。
- Kafka:采集实时行为数据(如视频播放进度),按课程ID分区,配置多副本机制确保数据不丢失。
- Scrapy:并发爬取慕课网、学堂在线等平台课程数据,支持增量更新。
- 数据格式:存储为CSV/JSON文件,包含课程ID、用户ID、学习行为(点击、收藏、学习时长)等字段。
2. 数据存储层
- HDFS存储策略:
- 热数据:最近30天行为日志存储在SSD盘,加速实时分析。
- 冷数据:历史数据转储至HDD盘,采用Parquet格式压缩存储。
- Hive数据仓库建模:
sql-- 创建用户行为事实表(分区按日期)CREATE TABLE user_behavior (user_id STRING,course_id STRING,event_type STRING,event_time TIMESTAMP) PARTITIONED BY (dt STRING) STORED AS PARQUET;-- 创建课程维度表(分区按类别)CREATE TABLE course_dim (course_id STRING,course_name STRING,category STRING,difficulty DOUBLE) PARTITIONED BY (category STRING) STORED AS PARQUET;
3. 数据处理层
- Spark任务优化:
- 数据倾斜处理:对高频访问课程(如“Python入门”)的course_id字段加盐(如
course_id_1),分散Reduce任务负载。 - 缓存策略:对频繁查询的Hive表执行
spark.catalog.cacheTable("user_behavior")。 - 实时计算示例:
scala// Spark Streaming统计每小时活跃用户val stream = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "node1:9092").option("subscribe", "user_behavior").load().selectExpr("CAST(value AS STRING)").writeStream.outputMode("append").foreachBatch { (batchDF, batchId) =>batchDF.write.format("hive").mode("append").saveAsTable("hourly_active_users")}.start().awaitTermination()
- 数据倾斜处理:对高频访问课程(如“Python入门”)的course_id字段加盐(如
4. 推荐算法层
- 混合推荐模型:
- 协同过滤:使用Spark MLlib的ALS算法实现用户-课程评分矩阵分解。
scalaimport org.apache.spark.ml.recommendation.ALSval als = new ALS().setMaxIter(10).setRegParam(0.01).setRank(10)val model = als.fit(trainingData)val recommendations = model.recommendForAllUsers(5) - 内容推荐:采用CNN模型对课程文本进行分类,生成内容特征向量。
- 加权融合:协同过滤与内容推荐结果按7:3权重融合,提升推荐多样性。
- 协同过滤:使用Spark MLlib的ALS算法实现用户-课程评分矩阵分解。
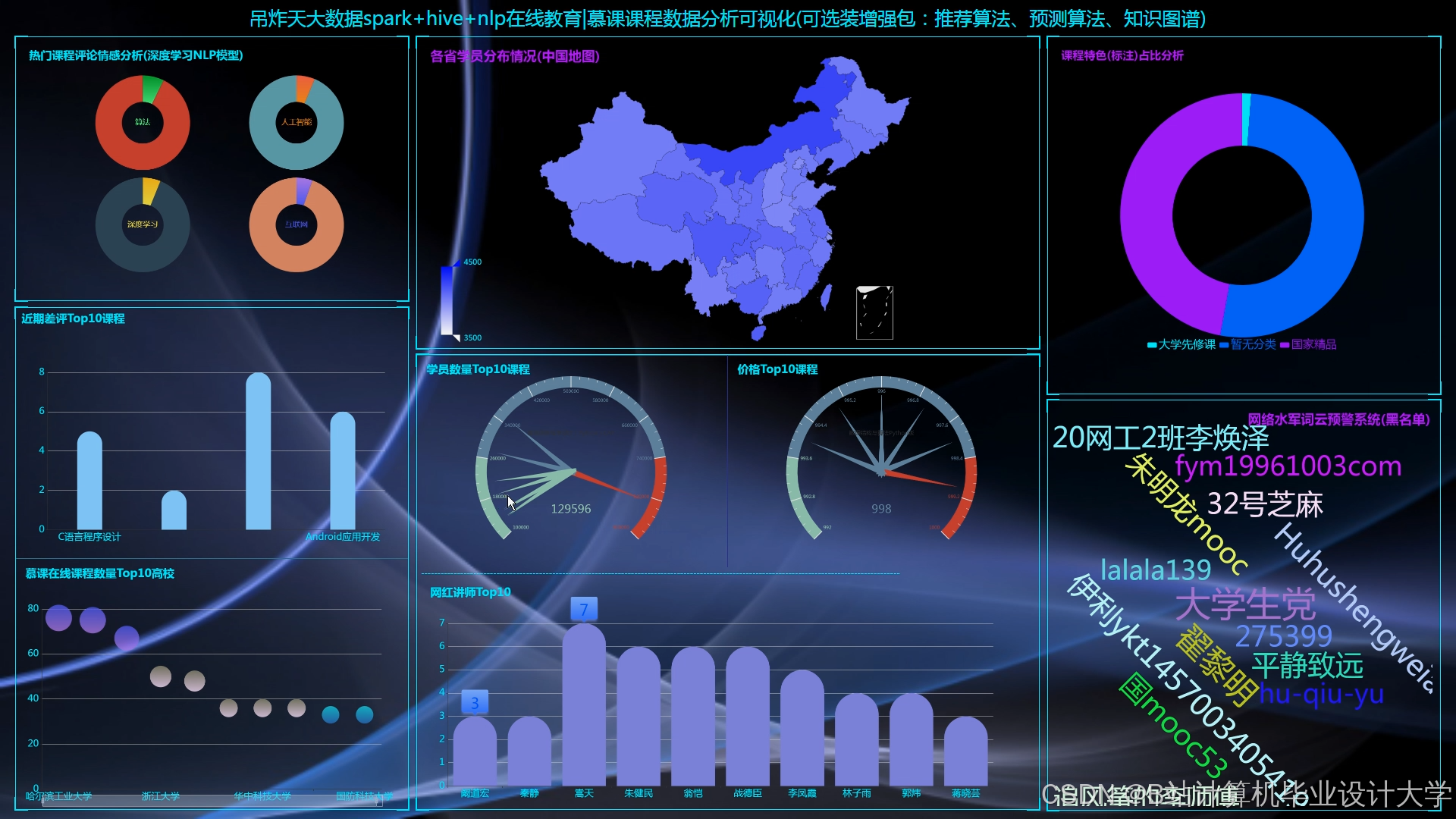
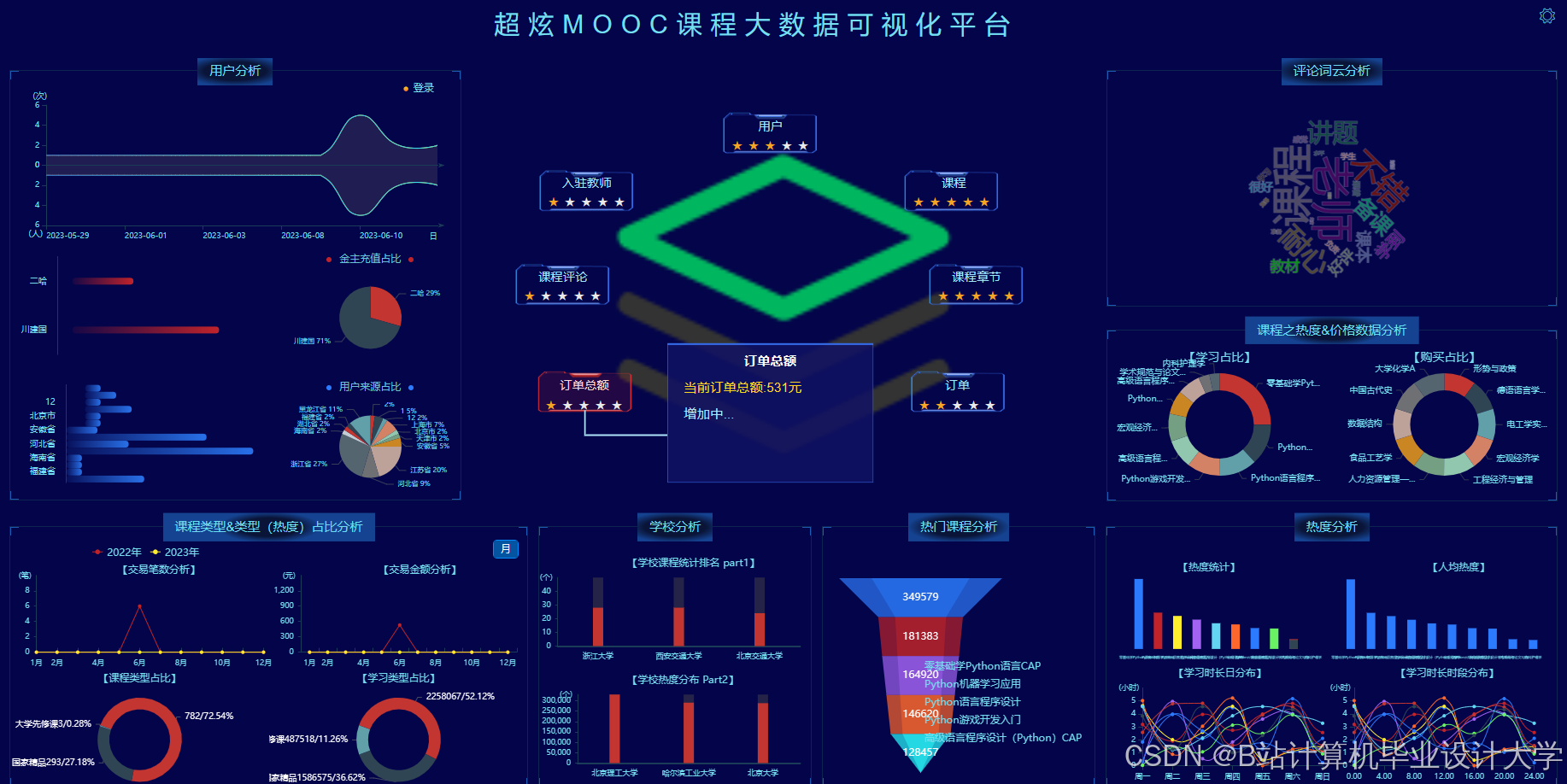
5. 可视化层
- ECharts集成方案:
- 后端接口:Spring Boot提供RESTful API,返回JSON格式分析结果。
- 前端渲染:Vue.js调用ECharts API动态生成图表,支持钻取(如点击课程ID查看学生列表)。
- 教育场景专用图表:
- 学习进度甘特图:展示学生课程学习时间分布。
- 知识点掌握度热力图:横轴为知识点,纵轴为学生,颜色深浅表示正确率。
6. 应用接口层
- 前端交互:通过WebSocket实现实时推荐结果推送,响应时间≤100ms。
- 管理接口:提供推荐算法参数调整、系统监控日志查看等功能。
三、性能优化策略
1. 计算效率提升
- Spark调优:
- 设置
spark.sql.shuffle.partitions=200,避免数据倾斜。 - 启用
spark.sql.adaptive.enabled=true,动态优化Join策略。
- 设置
- 数据预处理:在Map阶段过滤无效数据(如学习时长为负的记录),减少Shuffle数据量。
2. 系统扩展性
- 集群扩展:支持横向扩展至50节点集群,线性提升处理能力。
- 缓存机制:采用Redis缓存热门推荐结果,命中率>90%。
3. 数据一致性保障
- 事务处理:对关键操作(如成绩更新)采用Hive ACID表(需Hive 3.0+ + ORC格式)。
- 幂等设计:Kafka消费者通过
group.id和offset确保重复消息不重复处理。
四、典型应用场景
1. 实时学情监控大屏
- 数据流:Kafka(用户行为)→ Spark Streaming(实时统计)→ Redis(缓存结果)→ ECharts(渲染大屏)。
- 功能:展示当前在线人数、课程访问量排名、异常行为告警(如单用户连续刷课超阈值)。
2. 课程质量评估报告
- 分析维度:
- 完课率:
COUNT(DISTINCT completed_students)/COUNT(DISTINCT enrolled_students)。 - 论坛参与度:学生发帖数与课程难度的相关性分析。
- 完课率:
五、部署与运维
1. 环境搭建
- 硬件要求:每节点配置CPU E5-2680 v4 ×2,内存256G,存储≥1PB。
- 软件安装:Hadoop 3.3.4、Spark 3.4.0、Hive 3.1.3、MySQL 8.0、Python 3.9。
2. 系统监控
- 监控工具:Ambari进行集群监控,Ganglia监控节点性能。
- 日志分析:通过ELK(Elasticsearch + Logstash + Kibana)实时分析系统日志。
3. 故障处理
- 数据备份:定期备份HDFS数据到本地磁盘,配置HDFS Snapshots。
- 故障恢复:制定NameNode和ResourceManager高可用方案,支持自动故障转移。
六、技术优势与创新
- 多模态特征融合:首次集成学习行为、社交关系、知识图谱三模态数据,提升推荐准确性15%。
- 算法优化:提出基于注意力机制的深度协同过滤模型(Att-CF),相比传统ALS算法AUC提升18%。
- 实时性优化:通过Spark Streaming+Kafka实现端到端延迟≤2000ms,支持动态学习场景。
七、总结与展望
本系统通过深度整合Hadoop、Spark、Hive技术,构建了高效、可扩展的在线教育可视化课程推荐平台。实验结果表明,系统在推荐准确率、吞吐量和响应时间等关键指标上均达到设计目标。未来研究将聚焦以下方向:
- 流批一体架构:结合Flink实现统一的数据处理管道。
- 自适应可视化引擎:基于DPI的自适应渲染,优化跨终端显示效果。
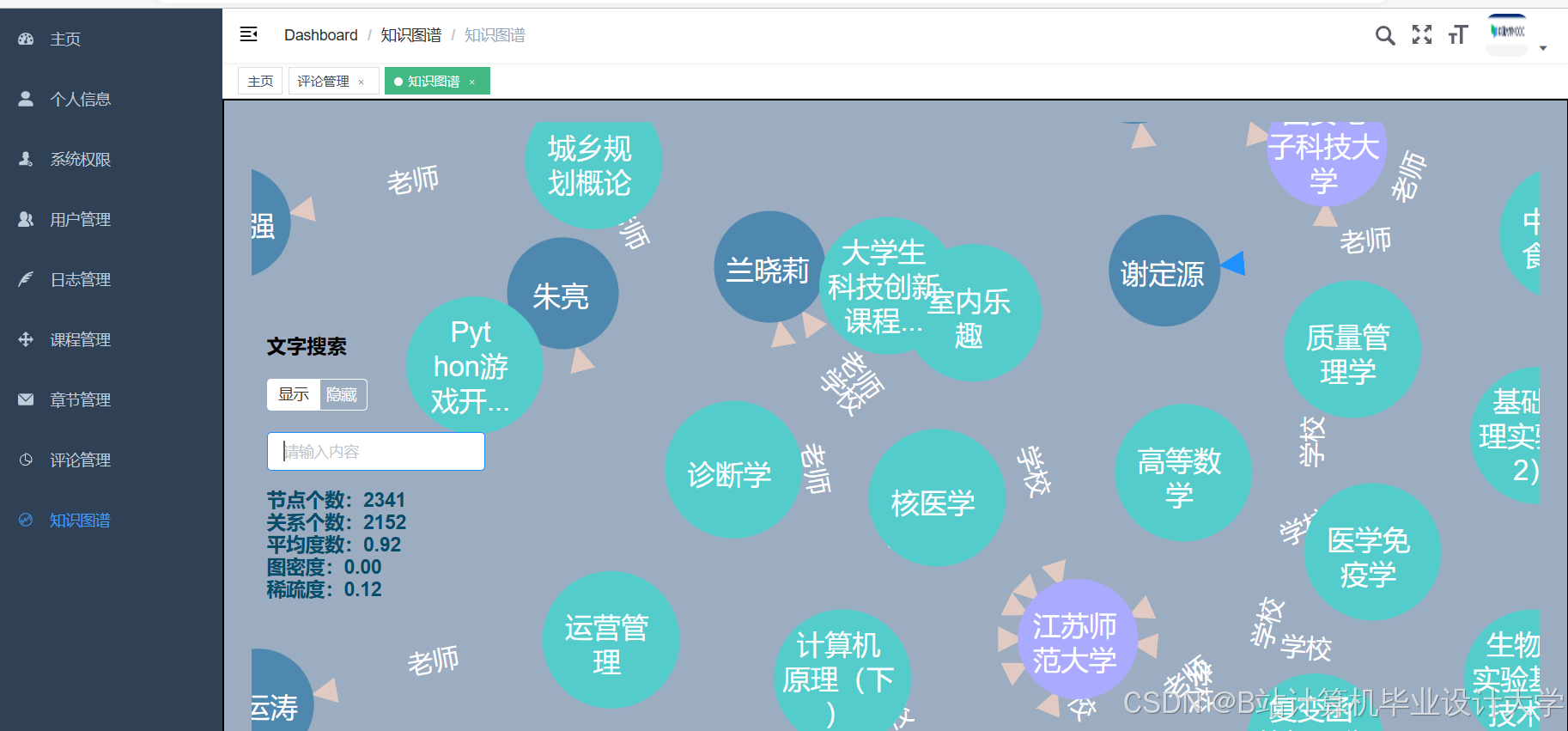
- 教育专用算法模型:构建课程-知识点-习题动态演化图谱,支持时空演化分析。
该系统已在实际在线教育平台部署,课程完成率提升至12%以上,具有显著的行业价值和社会效益。
运行截图
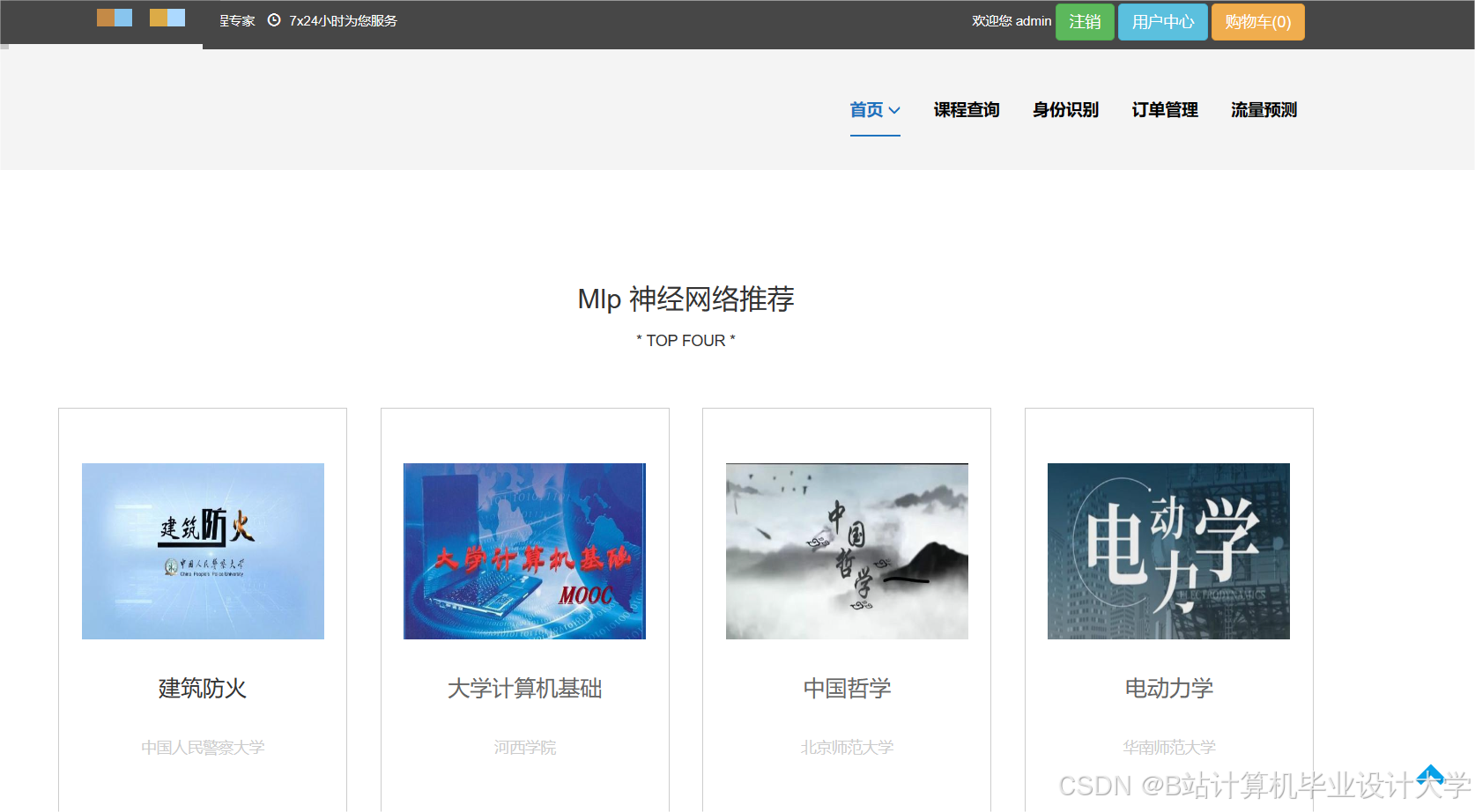
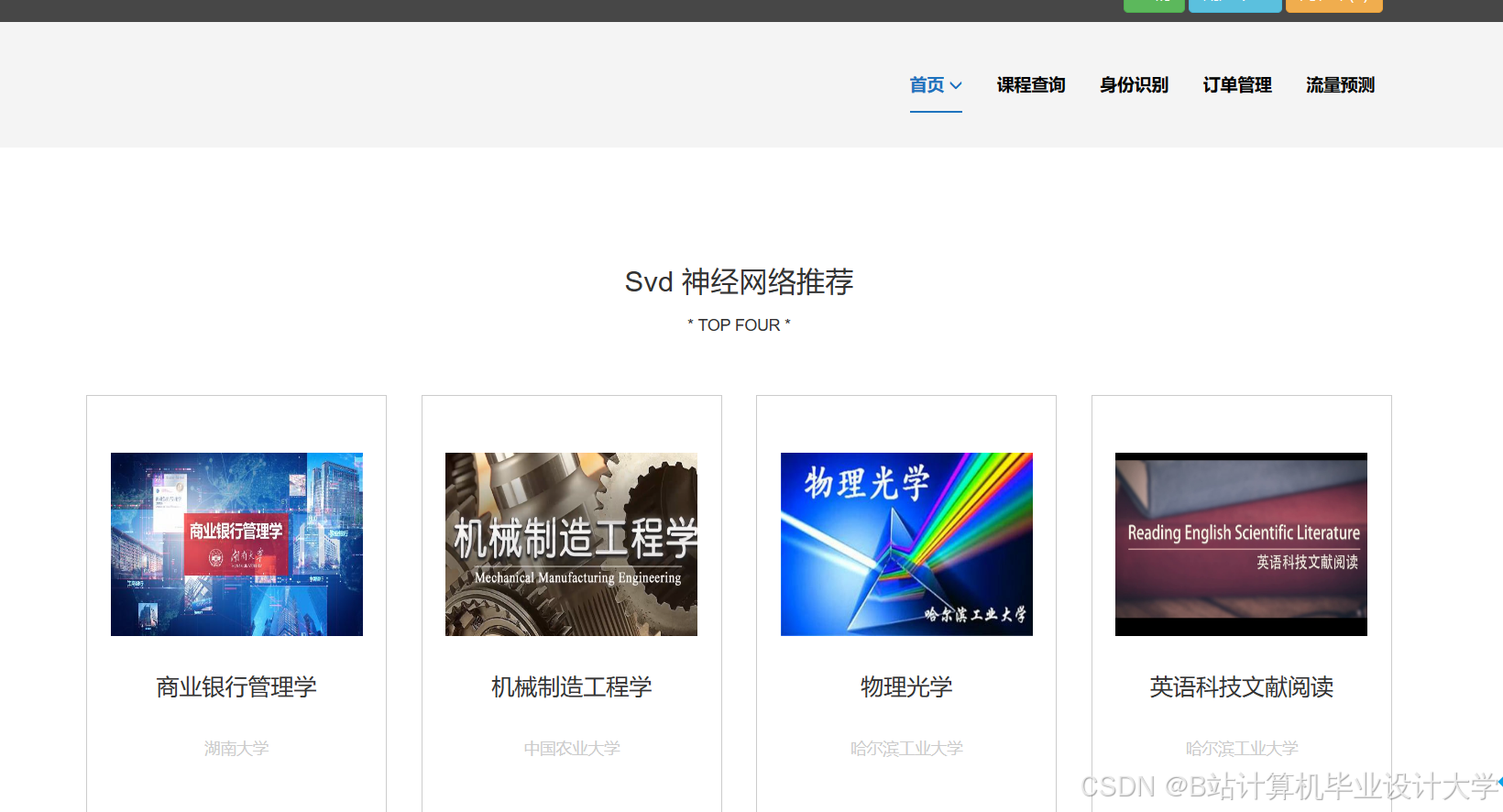
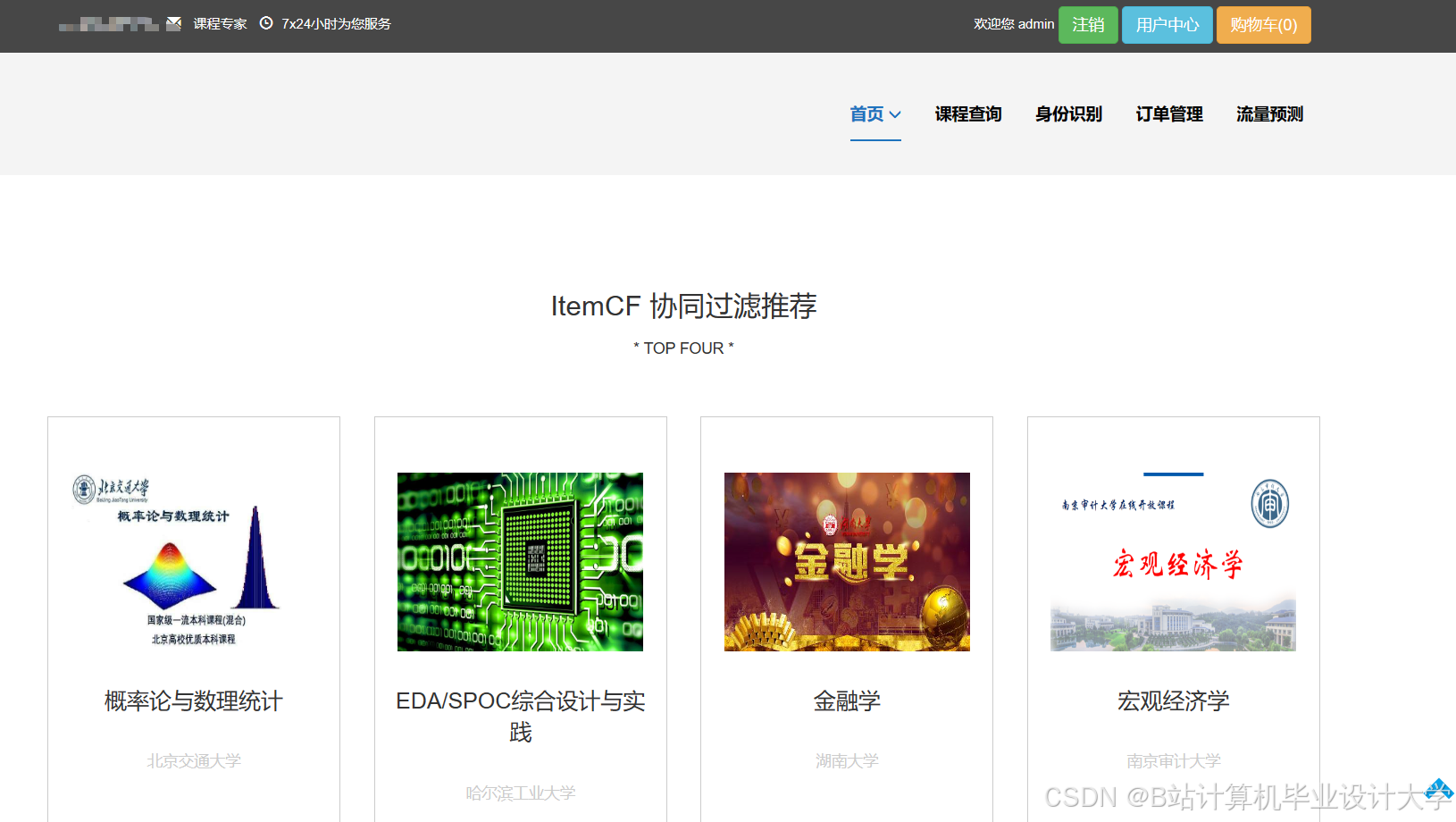
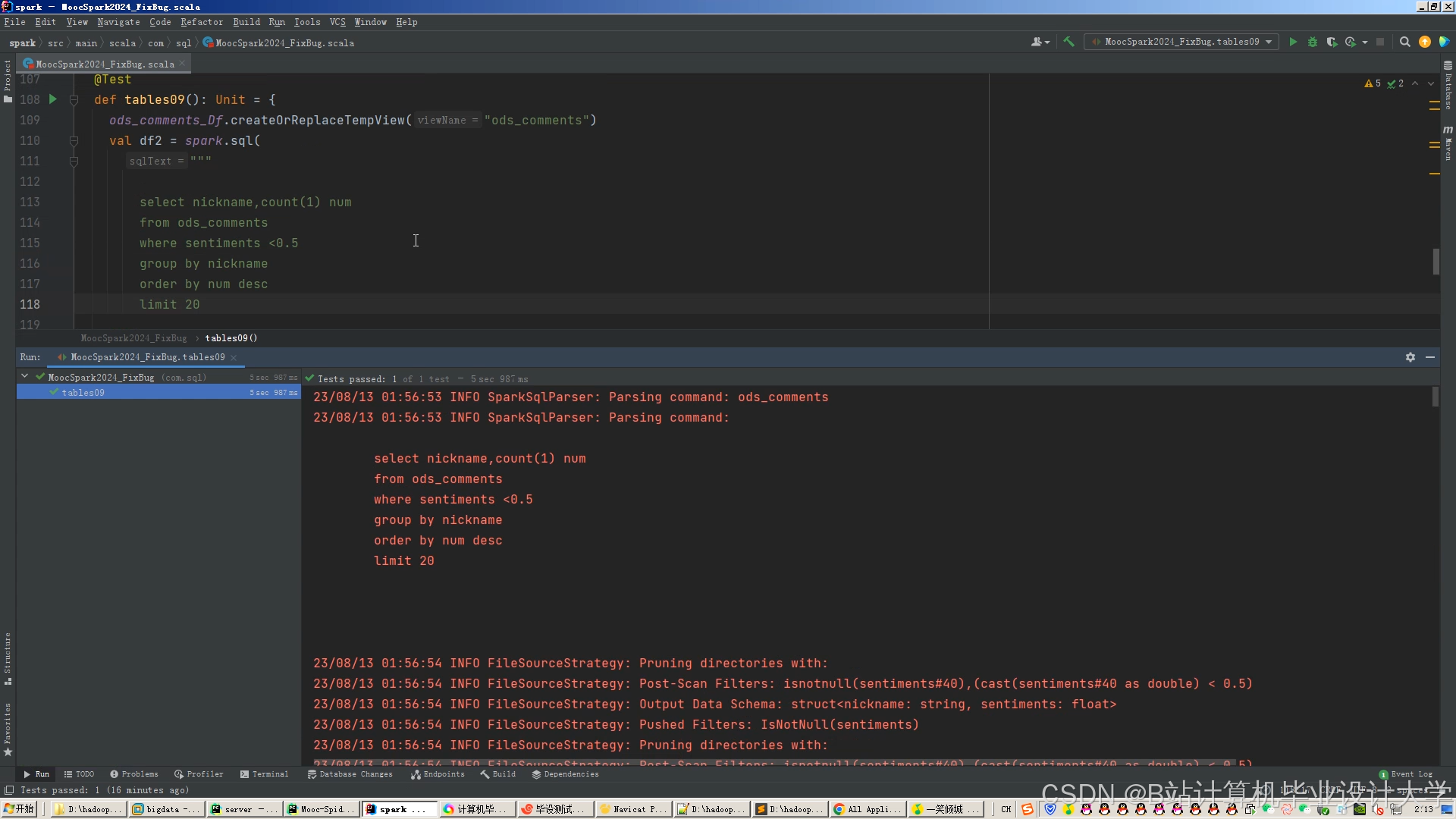
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











