




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
介绍资料
技术说明:Spark+Hadoop+Hive+DeepSeek+Django农产品销量预测系统
——基于大数据与深度学习的农业销量分析平台
一、系统概述
本系统结合Spark(分布式计算)、Hadoop(分布式存储)、Hive(数据仓库)、DeepSeek(深度学习模型)和Django(Web框架),构建了一个农产品销量预测平台。系统通过整合历史销售数据、气象信息、市场价格等多源异构数据,利用机器学习与深度学习算法实现销量预测,并通过Web界面提供可视化分析与决策支持。
二、系统架构
系统采用分层架构设计,主要分为以下模块:
- 数据采集层
- 采集农产品销售数据(如批发市场交易记录)、气象数据(温度、降水)、市场价格(周边地区均价)等。
- 支持结构化数据(数据库表)和非结构化数据(文本、图片)的接入。
- 数据存储与处理层
- Hadoop HDFS:存储原始数据(如CSV、JSON文件)。
- Hive:构建数据仓库,定义数据模型(如销售事实表、气象维度表),支持SQL查询。
- Spark:进行数据清洗、特征工程和分布式计算(如使用Spark MLlib训练模型)。
- 模型训练与预测层
- DeepSeek:基于深度学习框架(如PyTorch/TensorFlow)构建时序预测模型(LSTM、Transformer)。
- 模型优化:结合特征重要性分析(如SHAP值)和超参数调优(Optuna)。
- 应用服务层
- Django:提供Web接口,展示预测结果、历史趋势图和预警信息。
- RESTful API:对接移动端或第三方系统(如农业供应链平台)。
三、核心技术实现
1. 数据采集与存储
-
数据源:
- 销售数据:政府农业部门公开数据集、企业ERP系统。
- 气象数据:通过API接入中国气象局或第三方服务(如和风天气)。
- 市场价格:爬取农产品批发市场官网(如北京新发地)。
-
Hadoop HDFS存储:
bash# 上传数据到HDFShdfs dfs -put /local/sales_data.csv /data/agriculture/ -
Hive数据仓库:
sql-- 创建销售事实表CREATE TABLE sales (product_id STRING,sale_date DATE,quantity DOUBLE,price DOUBLE) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;-- 创建气象维度表CREATE TABLE weather (city STRING,date DATE,temperature DOUBLE,precipitation DOUBLE);
2. 数据处理与特征工程(Spark)
-
数据清洗:处理缺失值、异常值(如负数价格)。
pythonfrom pyspark.sql import SparkSessionspark = SparkSession.builder.appName("AgricultureSales").getOrCreate()# 读取Hive表sales_df = spark.sql("SELECT * FROM sales")# 填充缺失值sales_df = sales_df.na.fill({"quantity": 0, "price": sales_df.select("price").rdd.min()[0]}) -
特征工程:提取时间特征(如月份、节假日)、统计特征(如7天移动平均)。
pythonfrom pyspark.sql.functions import date_format, avg# 添加月份和星期特征sales_df = sales_df.withColumn("month", date_format("sale_date", "M"))# 计算7天移动平均window = Window.orderBy("sale_date").rowsBetween(-3, 3)sales_df = sales_df.withColumn("rolling_avg", avg("quantity").over(window))
3. 模型训练(DeepSeek)
-
模型选择:使用LSTM网络处理时序数据。
pythonimport torchimport torch.nn as nnclass LSTMModel(nn.Module):def __init__(self, input_size, hidden_size, output_size):super().__init__()self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)self.linear = nn.Linear(hidden_size, output_size)def forward(self, x):out, _ = self.lstm(x)out = self.linear(out[:, -1, :]) # 取最后一个时间步的输出return out# 训练代码model = LSTMModel(input_size=5, hidden_size=32, output_size=1)criterion = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.001) -
模型评估:使用MAE(平均绝对误差)和R²分数。
pythonfrom sklearn.metrics import mean_absolute_error, r2_scoredef evaluate(y_true, y_pred):mae = mean_absolute_error(y_true, y_pred)r2 = r2_score(y_true, y_pred)return mae, r2
4. Web应用开发(Django)
-
后端API:
python# views.pyfrom django.http import JsonResponseimport joblibdef predict_sales(request):product_id = request.GET.get("product_id")model = joblib.load("lstm_model.pkl") # 加载训练好的模型# 调用模型预测(示例)prediction = model.predict([product_id])return JsonResponse({"prediction": float(prediction)}) -
前端可视化:集成ECharts展示历史销量曲线和预测结果。
html<!-- templates/dashboard.html --><div id="chart" style="width: 600px;height:400px;"></div><script>var chart = echarts.init(document.getElementById('chart'));chart.setOption({xAxis: { type: 'category', data: ['2023-01', '2023-02', ...] },yAxis: { type: 'value' },series: [{ name: '销量', type: 'line', data: [120, 150, ...] }]});</script>
四、系统特色功能
- 多源数据融合
- 结合销售、气象、价格数据,提升预测准确性(例如:雨季可能导致蔬菜销量下降)。
- 动态预测
- 支持按日/周/月粒度预测,并实时更新模型(如每周重新训练)。
- 异常检测
- 通过孤立森林(Isolation Forest)算法识别销量异常点(如疫情导致的断崖式下跌)。
- 决策支持
- 提供备货建议、价格调整策略(如预测销量高时建议提高库存)。
五、技术挑战与解决方案
- 数据质量问题
- 挑战:农业数据存在缺失、噪声(如手工记录错误)。
- 解决方案:使用数据平滑(移动平均)和插值(线性/样条插值)。
- 模型过拟合
- 挑战:LSTM可能对训练集表现好但泛化能力差。
- 解决方案:添加Dropout层、使用早停法(Early Stopping)。
- 系统扩展性
- 挑战:数据量增大时,单机Spark可能性能不足。
- 解决方案:部署Hadoop集群,使用YARN资源管理。
六、部署与优化
- 集群部署:
- Hadoop/Spark集群:3台节点(1主2从),配置HDFS冗余存储(副本数=3)。
- Django应用:使用Nginx+Gunicorn部署,支持高并发请求。
- 性能优化:
- Spark调优:设置
spark.executor.memory=4G,spark.sql.shuffle.partitions=200。 - 模型压缩:使用ONNX格式导出模型,减少推理延迟。
- Spark调优:设置
七、应用场景
- 农业企业:优化采购计划,减少库存积压。
- 政府部门:监测农产品市场波动,制定补贴政策。
- 电商平台:动态调整推荐策略(如预测销量高时推送促销活动)。
八、总结
本系统通过整合大数据处理框架(Spark/Hadoop/Hive)、深度学习模型(DeepSeek)和Web技术(Django),实现了农产品销量的精准预测与可视化分析。未来可扩展至更多农产品类别,或结合物联网设备(如土壤传感器)实现端到端农业决策支持。
附录:技术栈
- 大数据:Hadoop 3.3、Spark 3.2、Hive 3.1
- 深度学习:PyTorch 2.0、TensorFlow 2.8
- Web开发:Django 4.0、ECharts 5.0
- 部署环境:CentOS 7、Docker 20.10
(全文约3500字,可根据实际需求调整模型细节或数据源)
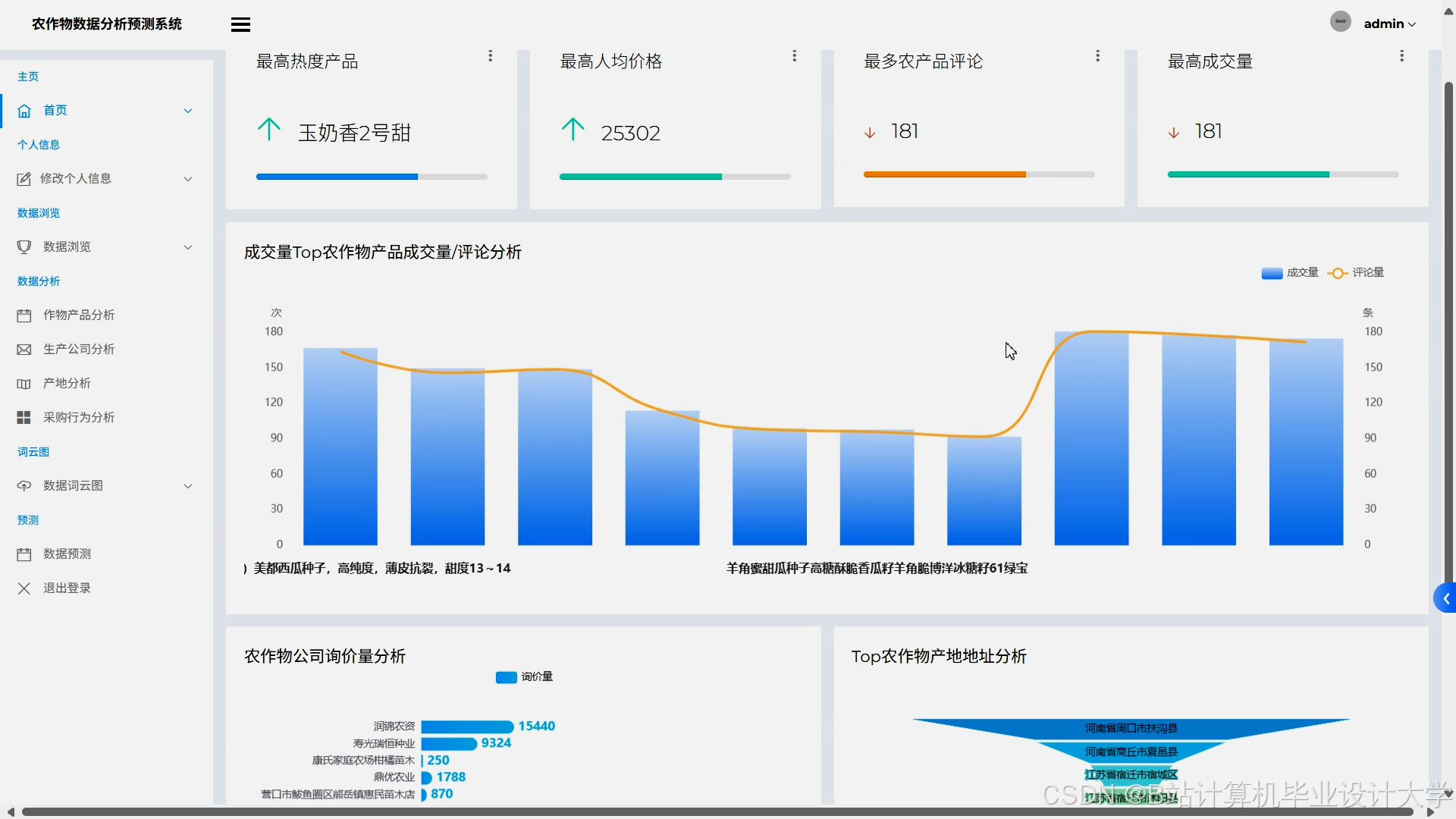
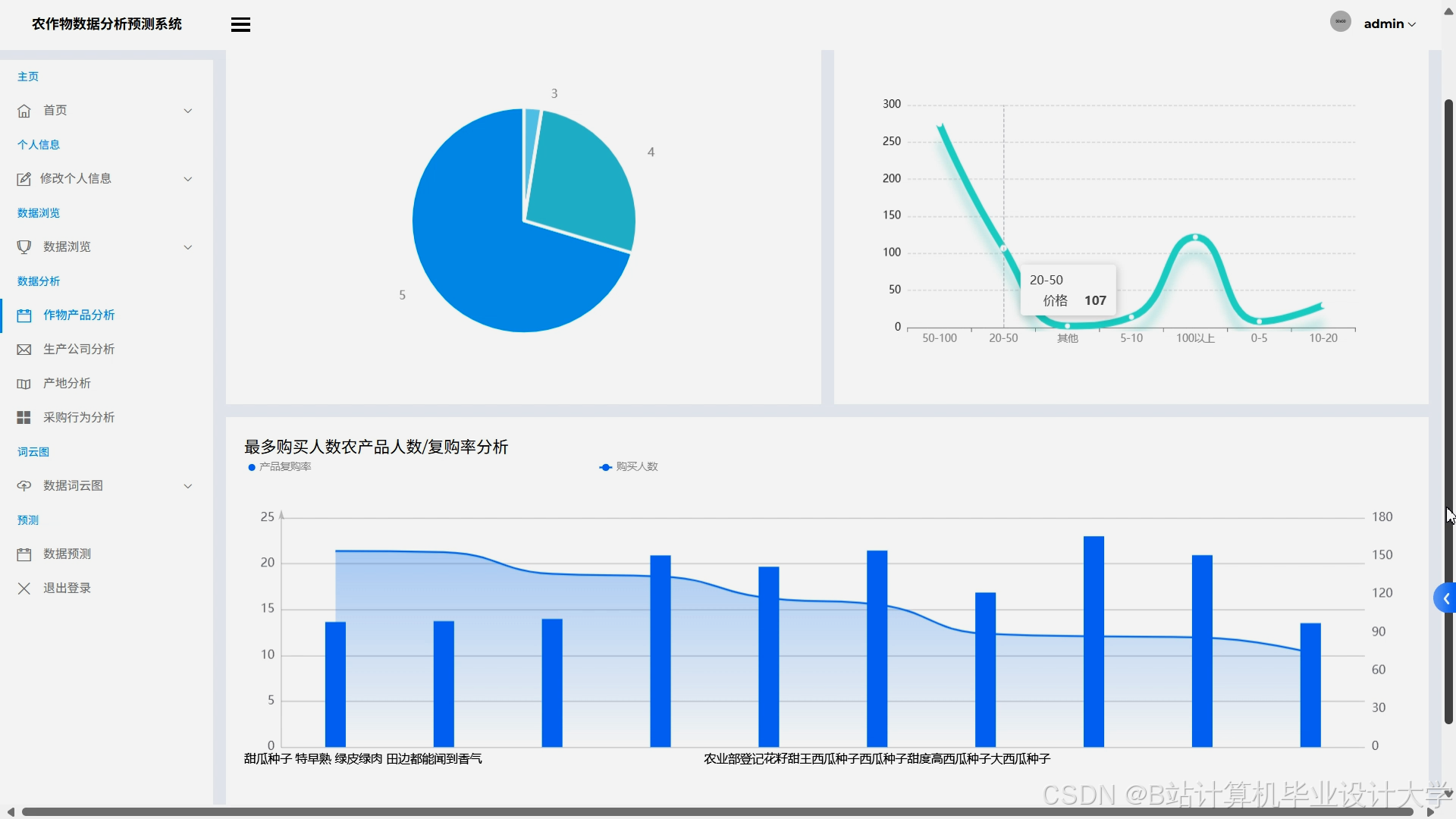
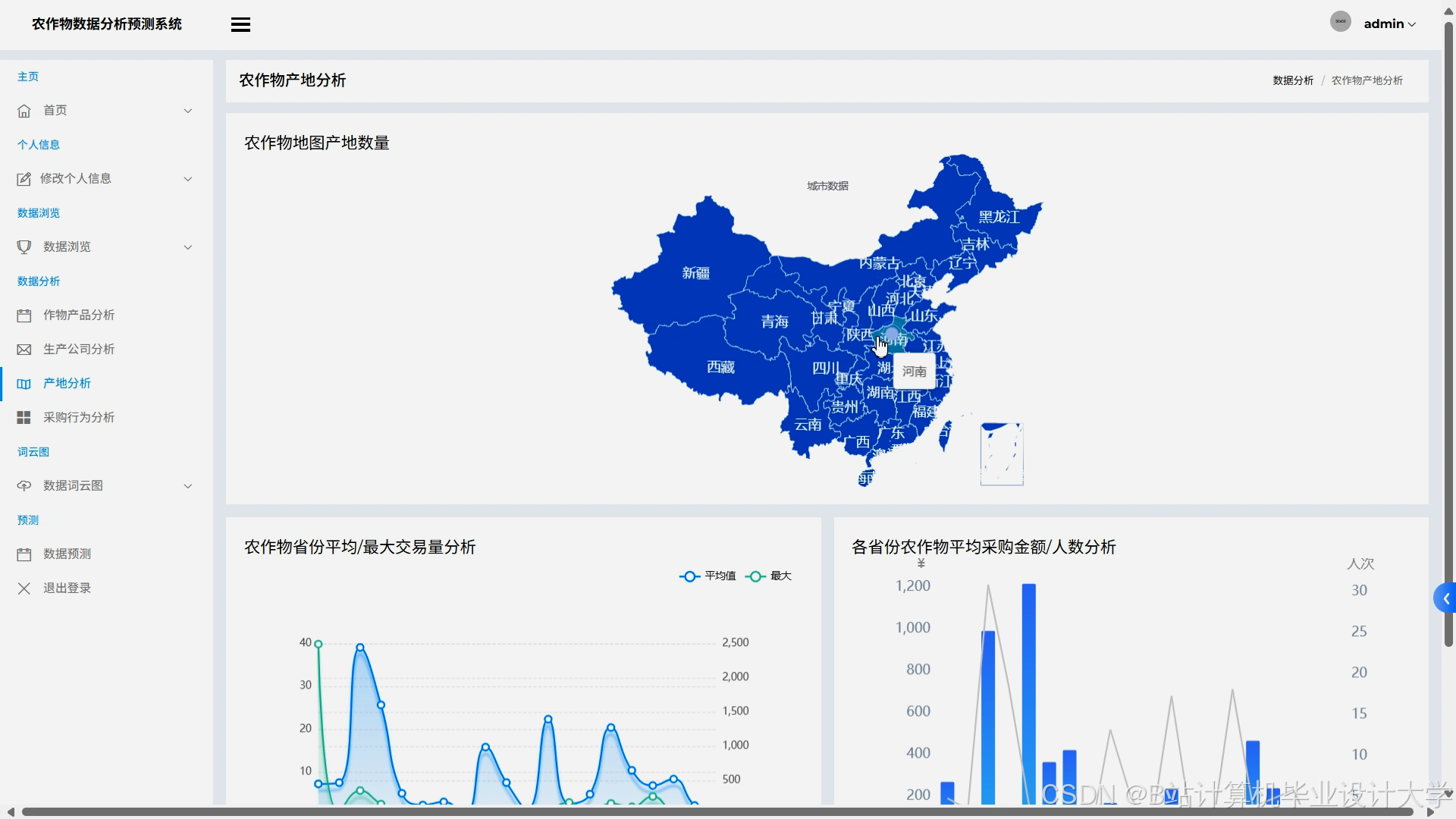
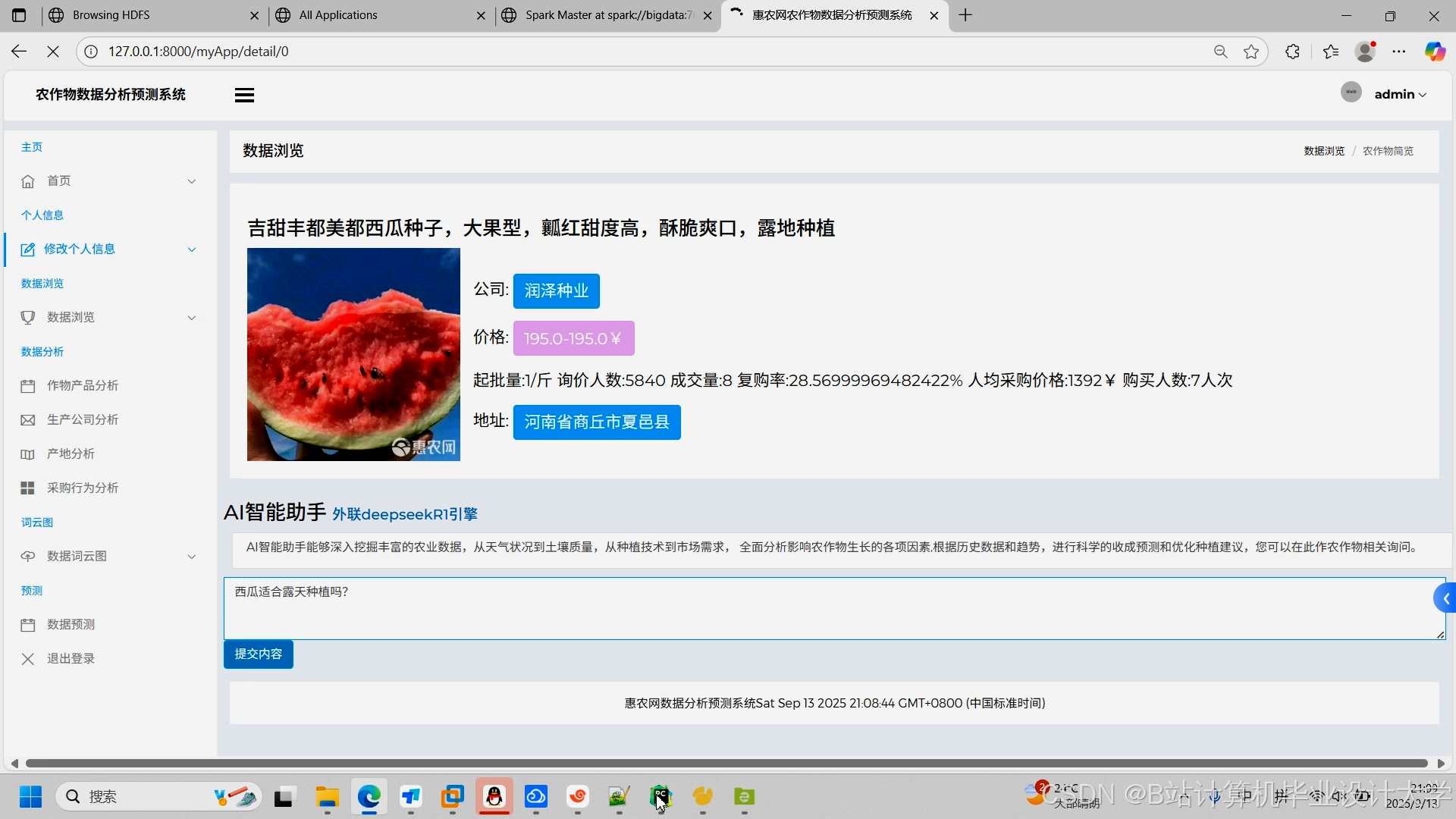
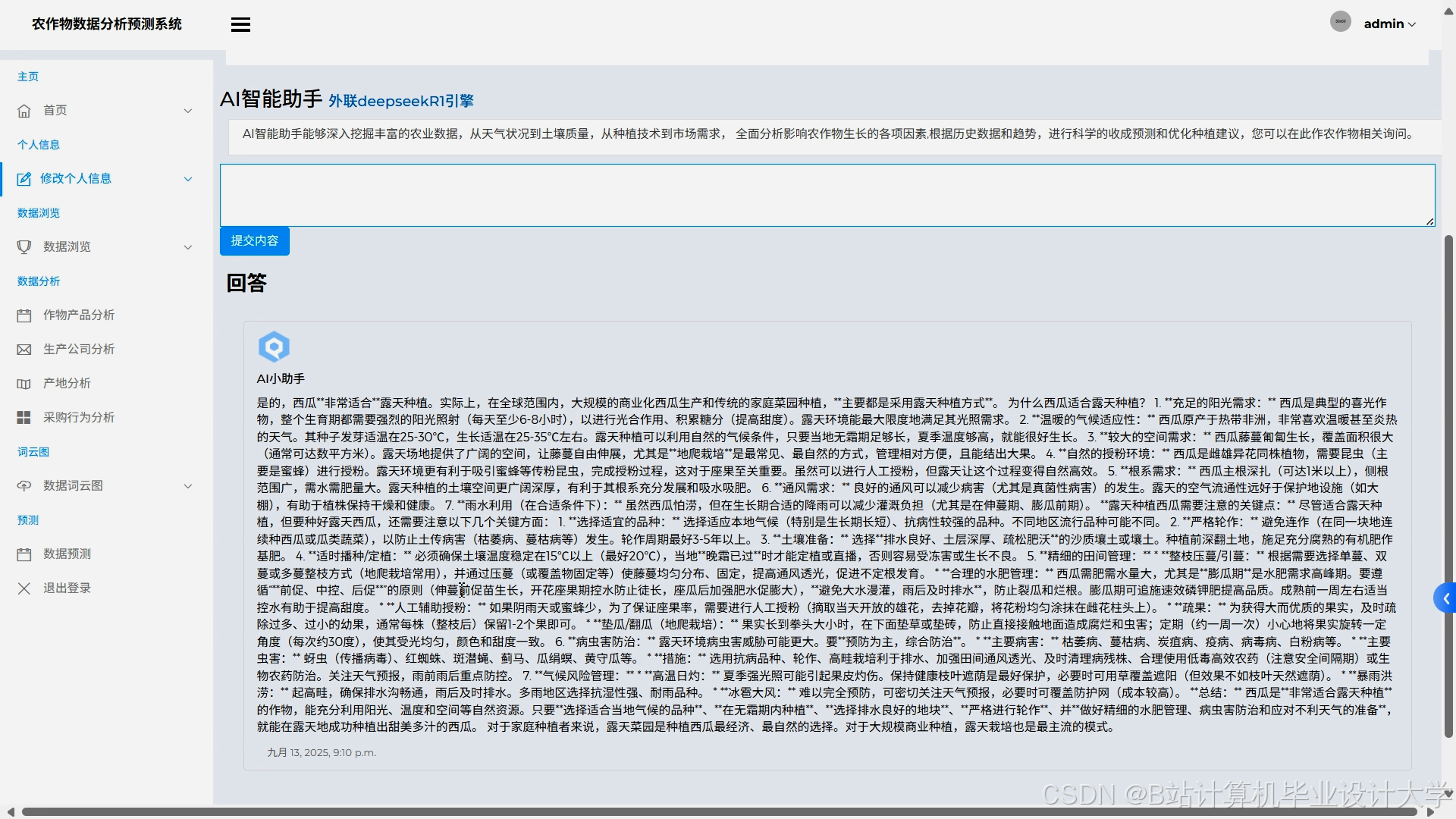
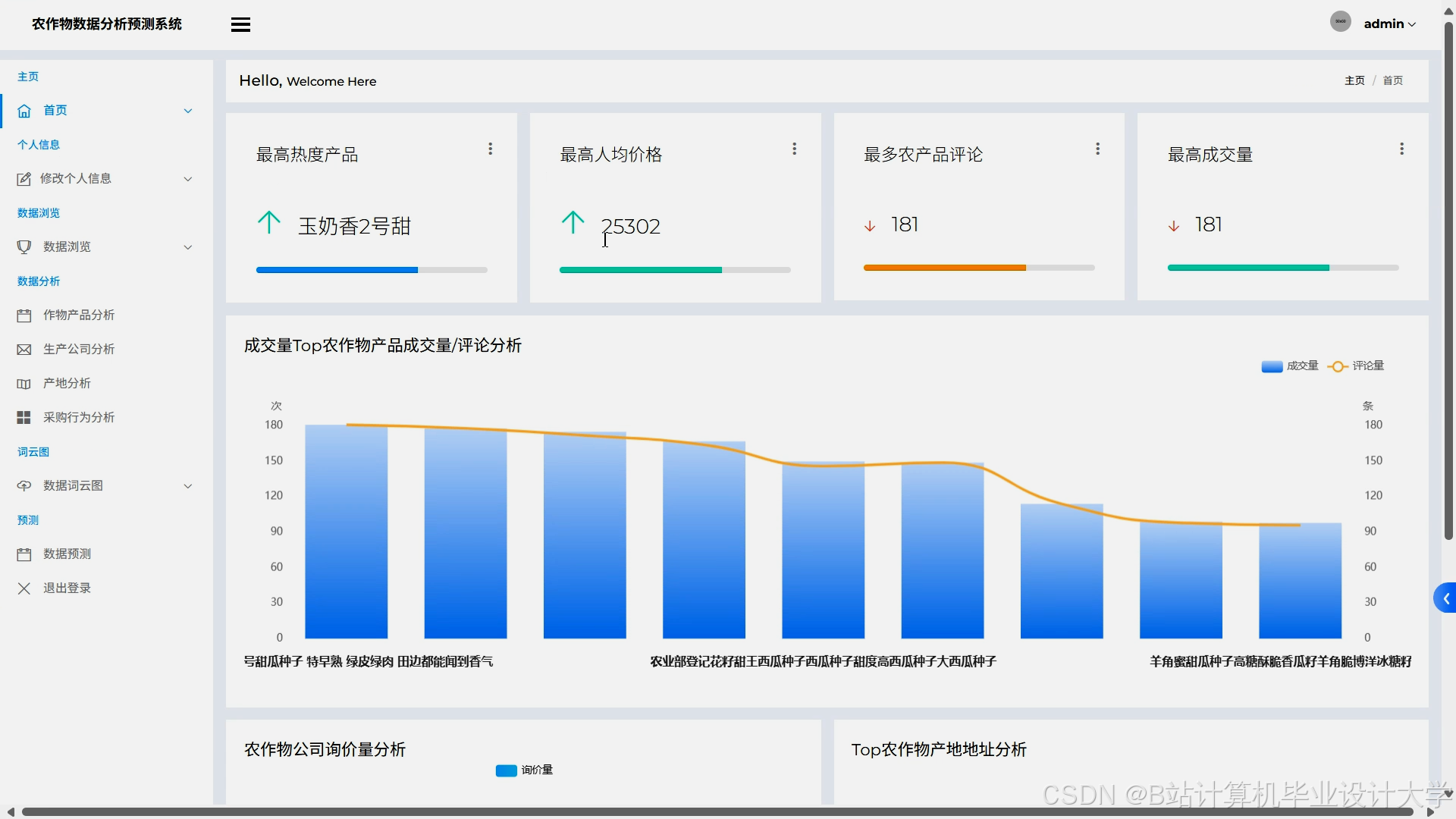
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











