




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份针对《Hadoop+Spark+Kafka+Hive漫画推荐系统》的任务书模板,涵盖数据采集、实时推荐引擎、离线分析、可视化监控等核心模块,结合漫画推荐场景设计技术方案:
任务书:基于Hadoop+Spark+Kafka+Hive的漫画推荐系统
一、项目背景与目标
1. 背景
漫画平台面临用户兴趣分散、内容冷启动难、推荐延迟高等问题。传统推荐系统依赖离线批处理,无法实时捕捉用户行为(如“用户A连续阅读3部热血漫后推荐同类作品”)。需结合实时流处理(Kafka+Spark Streaming)与离线特征工程(Hadoop+Hive),构建混合推荐系统,提升用户留存率(目标:用户日均阅读时长提升20%)。
2. 目标
- 数据层:
- 构建Hadoop+Hive数据仓库,整合用户行为、漫画元数据、社交关系等多源数据。
- 使用Kafka实时采集用户点击、收藏、评论等行为,延迟<1秒。
- 推荐层:
- 实时推荐:基于Spark Streaming的ALS协同过滤,实现“用户实时行为→推荐列表更新”闭环(延迟<5秒)。
- 离线推荐:基于Hive聚合特征(如“用户A过去30天阅读漫画类型分布”)训练XGBoost多分类模型,补充长尾内容推荐。
- 分析层:
- 通过Grafana监控推荐转化率(点击率CTR)、冷启动漫画曝光量等指标。
- 使用Superset分析用户兴趣迁移(如“从恋爱漫转向悬疑漫的用户占比”)。
二、项目任务与分工
1. 多源数据采集与存储(Hadoop+Hive+Kafka)
1.1 数据源接入
| 数据类型 | 采集方式 | 存储目标 |
|---|---|---|
| 用户行为数据 | - 漫画阅读记录(用户ID、漫画ID、阅读时长、章节ID) - 互动行为(点赞、评论、分享) - 搜索关键词 | Kafka Topic(user_behavior),分区键=用户ID |
| 漫画元数据 | - 漫画ID、标题、作者、类型(热血/恋爱/悬疑等)、标签、更新状态(连载/完结) - 封面图URL、热度评分(基于阅读量) | Hive表(dw.comic_meta),分区字段=类型 |
| 用户画像数据 | - 注册信息(年龄、性别、地区) - 社交关系(关注列表、粉丝列表) - 设备信息(手机型号、操作系统) | Hive表(dw.user_profile),按用户ID分区 |
1.2 数据清洗与存储
- 实时数据清洗(Spark Streaming):
- 过滤异常行为(如阅读时长<1秒或>24小时的记录)。
- 用户ID脱敏(MD5哈希处理)。
- 离线数据存储:
- ODS层:原始数据(保留90天行为日志)。
- DWD层:清洗后数据,按主题分区:
dwd.user_behavior_daily(每日用户行为快照)。dwd.comic_meta_full(漫画全量元数据)。
- DWS层:聚合指标(示例SQL):
sql-- 计算用户每日阅读漫画类型分布CREATE TABLE dws.user_type_distribution ASSELECTuser_id,comic_type,COUNT(*) as read_count,SUM(read_duration) as total_durationFROM dwd.user_behavior_dailyJOIN dw.comic_meta ON behavior.comic_id = meta.comic_idGROUP BY user_id, comic_type;
2. 混合推荐引擎开发(Spark MLlib+ALS)
2.1 实时推荐(Spark Streaming + ALS)
- 场景:用户A阅读漫画《鬼灭之刃》后,立即推荐同类热血漫。
- 技术实现:
- Kafka消费:
scalaval kafkaStream = KafkaUtils.createDirectStream[String, String](ssc, PreferConsistent,Subscribe[String, String](Array("user_behavior"), kafkaParams)) - 行为过滤:仅保留“阅读完成”事件(阅读时长>漫画总时长的80%)。
- ALS模型更新:
- 预训练ALS模型(基于历史数据)存储在HDFS。
- 增量更新用户-漫画评分矩阵(Spark Streaming窗口=5分钟):
scalaval latestRatings = kafkaStream.map { case (_, json) =>val behavior = parseJson(json)(behavior.userId, behavior.comicId, behavior.rating) // rating=阅读时长/漫画总时长}.toDF("userId", "comicId", "rating")// 合并历史评分val fullRatings = spark.sql("SELECT * FROM dw.als_ratings").union(latestRatings).repartition(100) // 避免数据倾斜// 重新训练ALS模型val als = new ALS().setMaxIter(10).setRank(50).setRegParam(0.01)val model = als.fit(fullRatings)model.save("/models/als_latest")
- 实时推荐生成:
- 对用户A的Top-K相似用户(基于ALS用户隐向量余弦相似度)的阅读记录取并集,去重后推荐。
- Kafka消费:
2.2 离线推荐(XGBoost多分类模型)
- 场景:为新用户或冷启动漫画生成推荐列表。
- 特征设计:
特征组 示例特征 用户特征 年龄、性别、过去30天阅读类型分布 漫画特征 类型、作者、热度评分、更新频率 上下文特征 阅读时间(工作日/周末)、设备类型 - 模型训练:
scalaimport org.apache.spark.ml.feature.{VectorAssembler, StringIndexer}import org.apache.spark.ml.classification.XGBoostClassifier// 特征组装val assembler = new VectorAssembler().setInputCols(Array("age", "gender", "comic_type_热血", "comic_type_恋爱")).setOutputCol("features")// 定义XGBoost模型val xgb = new XGBoostClassifier().setLabelCol("clicked") // 用户是否点击推荐漫画.setFeaturesCol("features").setNumRound(100).setMaxDepth(6)// 训练与交叉验证val Array(training, test) = data.randomSplit(Array(0.8, 0.2))val model = xgb.fit(training)val predictions = model.transform(test)
3. 数据可视化与监控
3.1 推荐效果监控
- Grafana看板指标:
- 实时指标:推荐请求QPS、平均响应时间、CTR(点击率)。
- 离线指标:
- 推荐多样性(推荐漫画类型数量/总推荐数)。
- 冷启动漫画曝光占比(新上线漫画在推荐列表中的比例)。
3.2 用户兴趣分析
- Superset图表示例:
- 桑基图:用户兴趣迁移路径(如“恋爱漫→悬疑漫→热血漫”)。
- 热力图:不同年龄段用户对漫画类型的偏好(X轴=类型,Y轴=年龄,颜色=阅读量)。
4. 系统集成与性能优化
- 集群部署:
- Hadoop(3节点):HDFS存储原始数据和模型文件。
- Spark(2主2从):Streaming任务(实时推荐)与Batch任务(离线训练)分离。
- Kafka(3节点):
user_behaviorTopic副本数=3,防止数据丢失。
- 性能优化:
- Spark调优:
spark.sql.autoBroadcastJoinThreshold=-1(禁用广播JOIN,避免大表广播)。spark.executor.instances=10(实时任务分配4个Executor,离线任务6个)。
- Kafka优化:
log.retention.hours=48(保留2天行为数据供重放)。
- Spark调优:
三、技术栈与开发环境
| 模块 | 技术选型 |
|---|---|
| 大数据框架 | Hadoop 3.3.4, Spark 3.3.2, Hive 3.1.3 |
| 流处理 | Kafka 3.4.0, Spark Streaming 3.3.2 |
| 机器学习 | Spark MLlib 3.3.2, XGBoost4J-Spark |
| 可视化 | Grafana 9.0, Superset 2.0 |
| 开发环境 | Linux (CentOS 7), IntelliJ IDEA, JupyterLab |
四、项目里程碑计划
| 阶段 | 时间 | 交付物 |
|---|---|---|
| 数据采集与ETL | 第1-2周 | Kafka消费者脚本、Hive表结构文档 |
| 实时推荐引擎开发 | 第3-4周 | ALS模型权重文件、实时推荐API文档 |
| 离线模型训练 | 第5周 | XGBoost模型、特征重要性分析报告 |
| 可视化看板开发 | 第6周 | Grafana Dashboard链接、Superset图表 |
| 系统联调与上线 | 第7周 | 压测报告(QPS≥1000)、用户操作手册 |
五、预期成果
- 推荐效果:
- 实时推荐CTR提升15%,离线推荐覆盖长尾漫画30%以上。
- 系统性能:
- 实时推荐延迟<3秒,离线模型训练时间<2小时(全量数据)。
- 业务价值:
- 用户日均阅读时长从25分钟提升至30分钟,冷启动漫画曝光量增加50%。
六、风险评估与应对
| 风险类型 | 应对措施 |
|---|---|
| 数据倾斜 | 对热门漫画ID加盐(如comicId_1~comicId_10)后JOIN |
| 模型过拟合 | 在XGBoost中设置subsample=0.8(每棵树随机采样80%数据) |
| Kafka消息堆积 | 增加消费者线程数(spark.streaming.kafka.maxRatePerPartition=1000) |
| 冷启动问题 | 对新用户采用基于人口统计学的协同过滤(如“同地区用户偏好”) |
项目负责人:__________
日期:__________
此任务书可根据实际漫画平台规模调整集群节点数(如日活用户>100万时增加Spark Worker至5节点),并建议优先在热门漫画类型(如热血、恋爱)上验证推荐效果,再扩展至全品类。可视化部分可增加“推荐漫画的用户评论情感分析”等深度洞察模块。
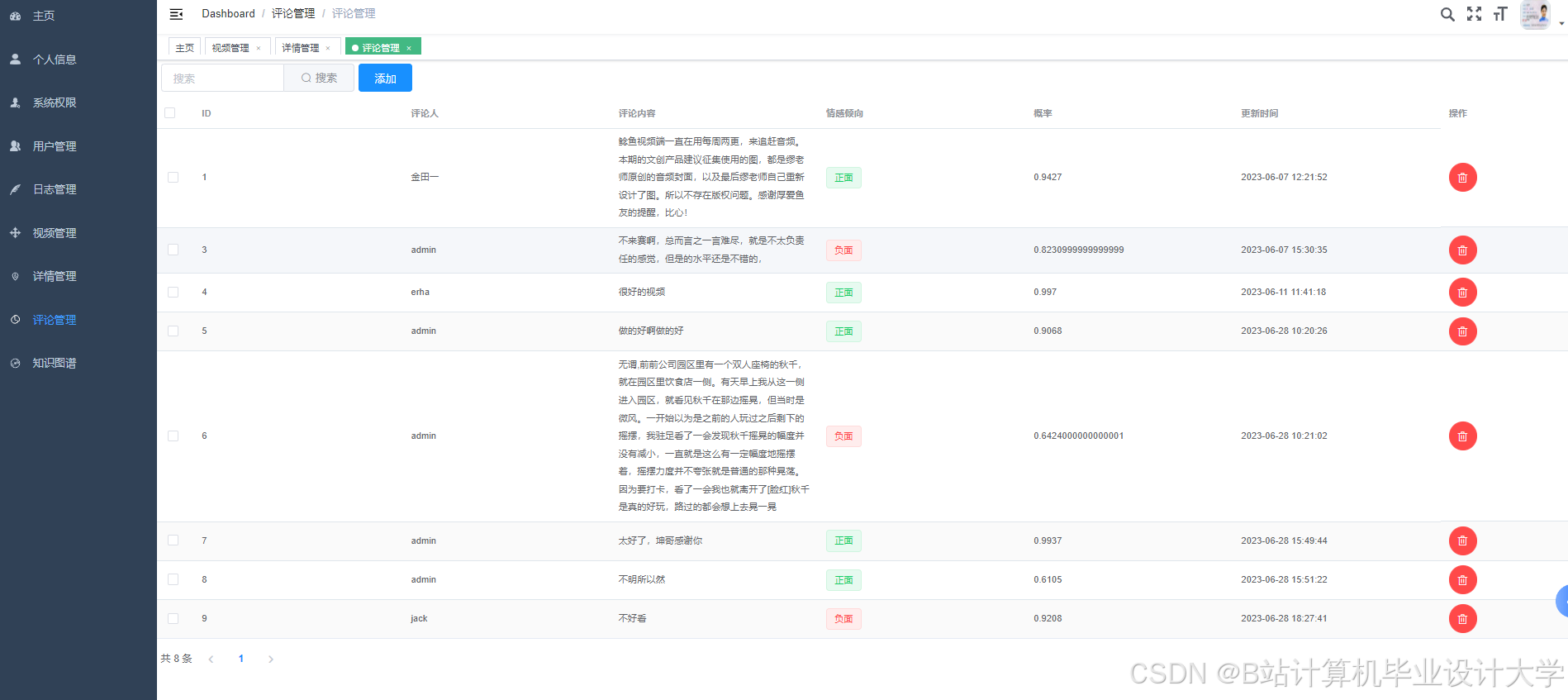
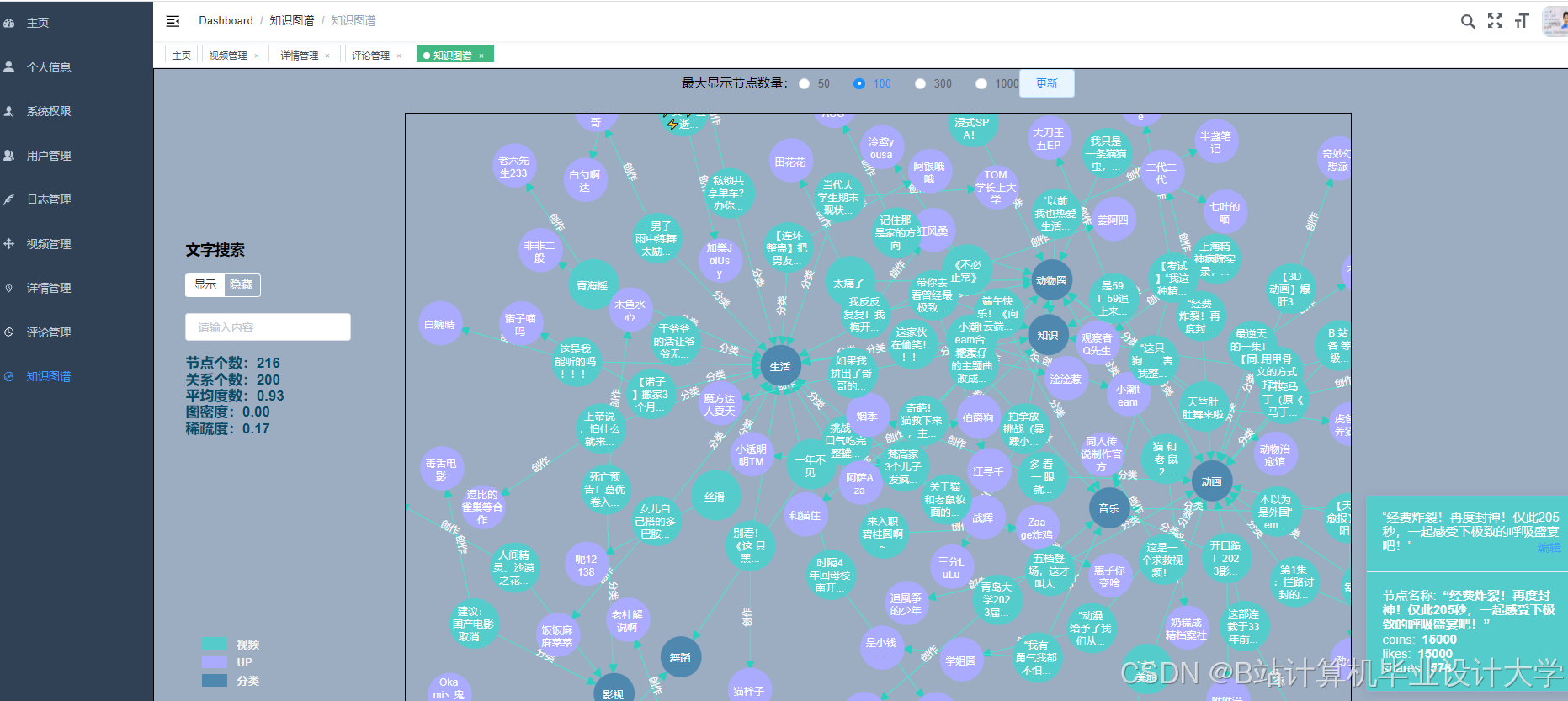
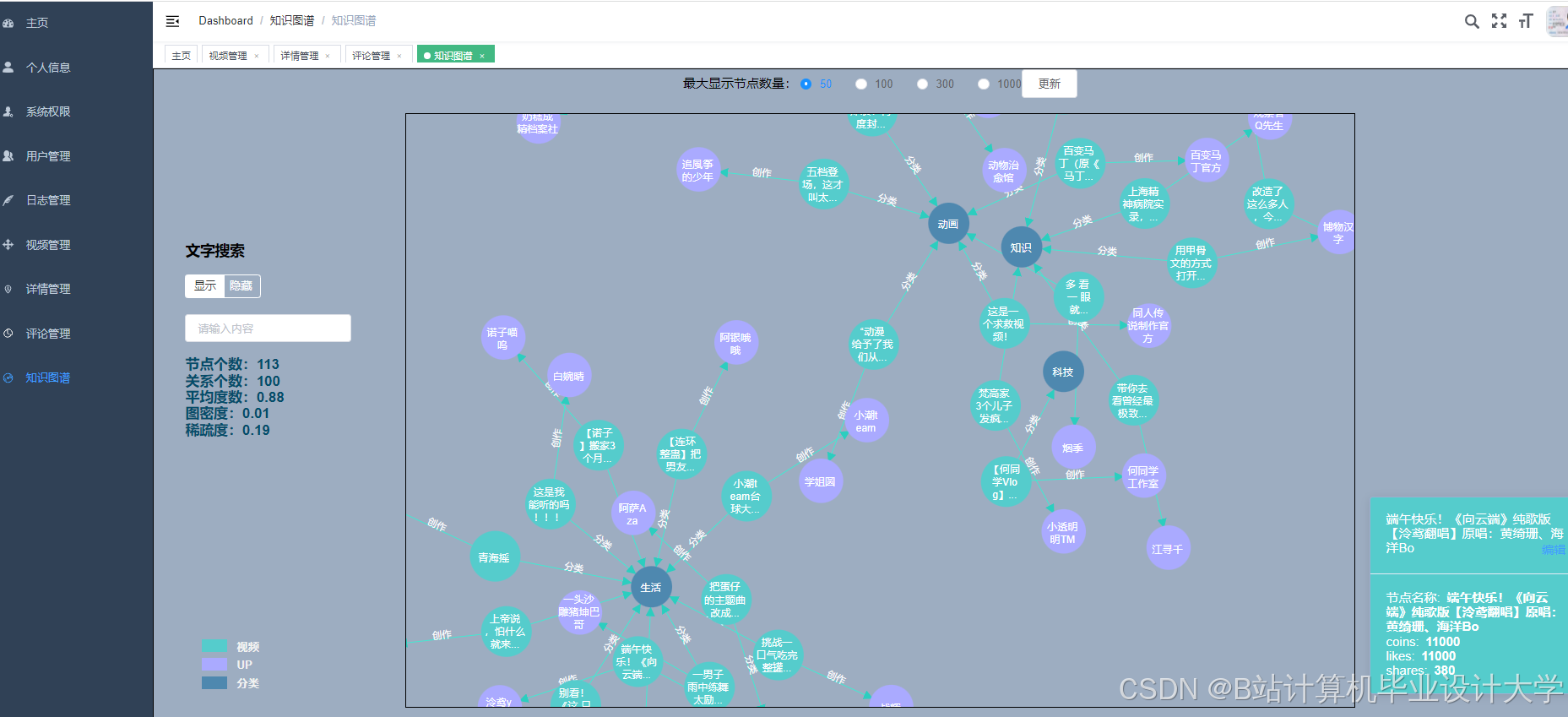
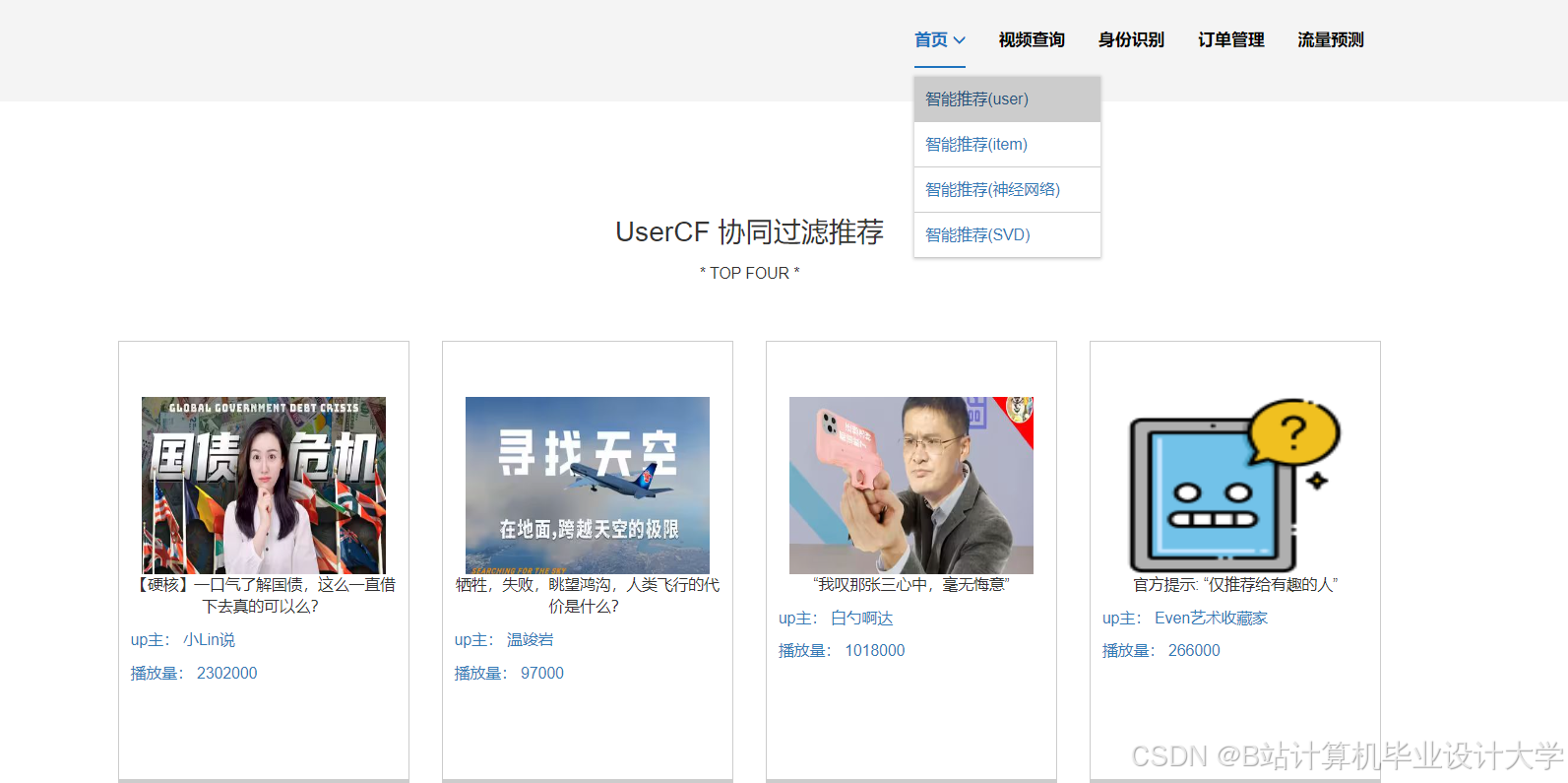
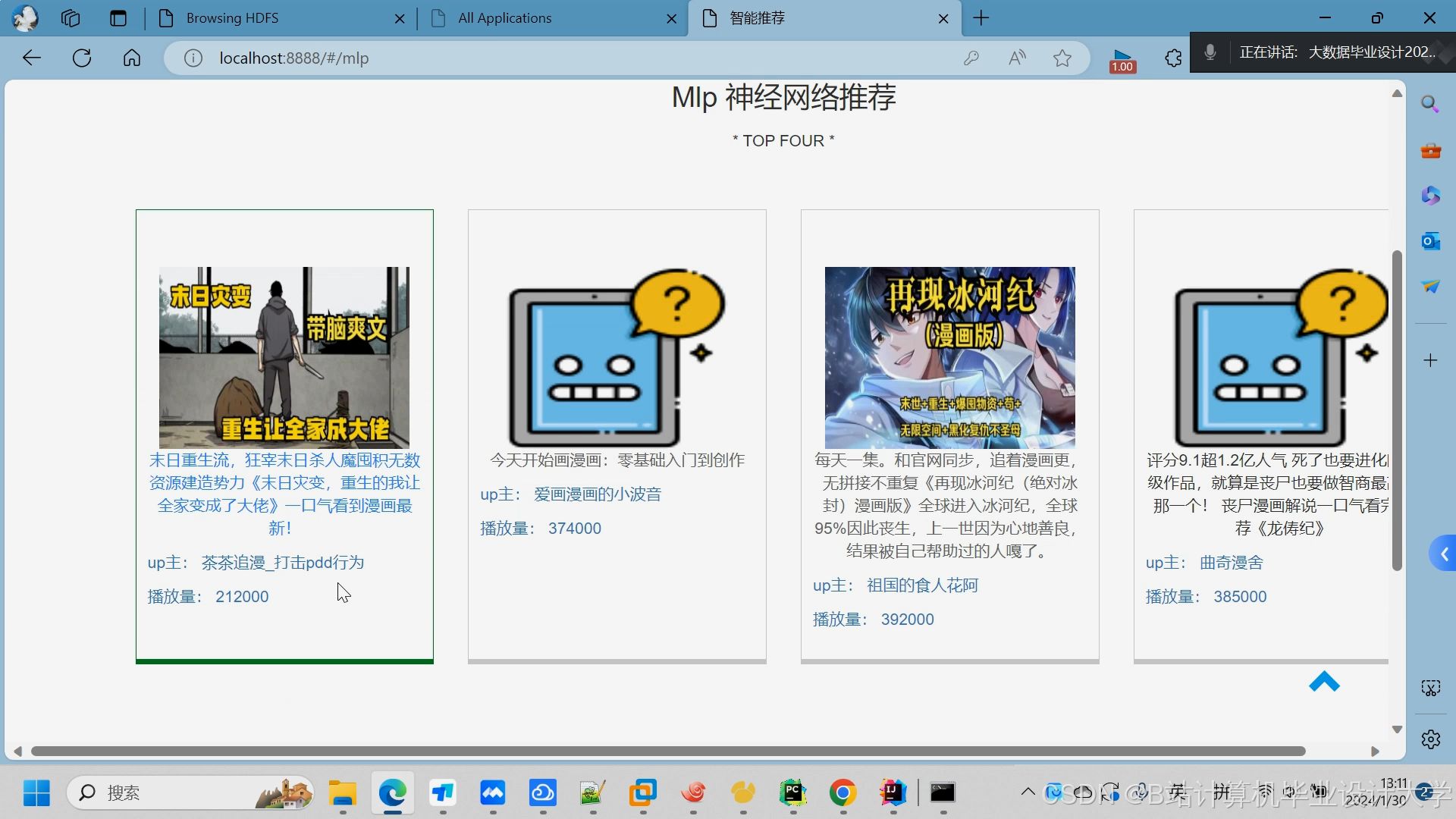
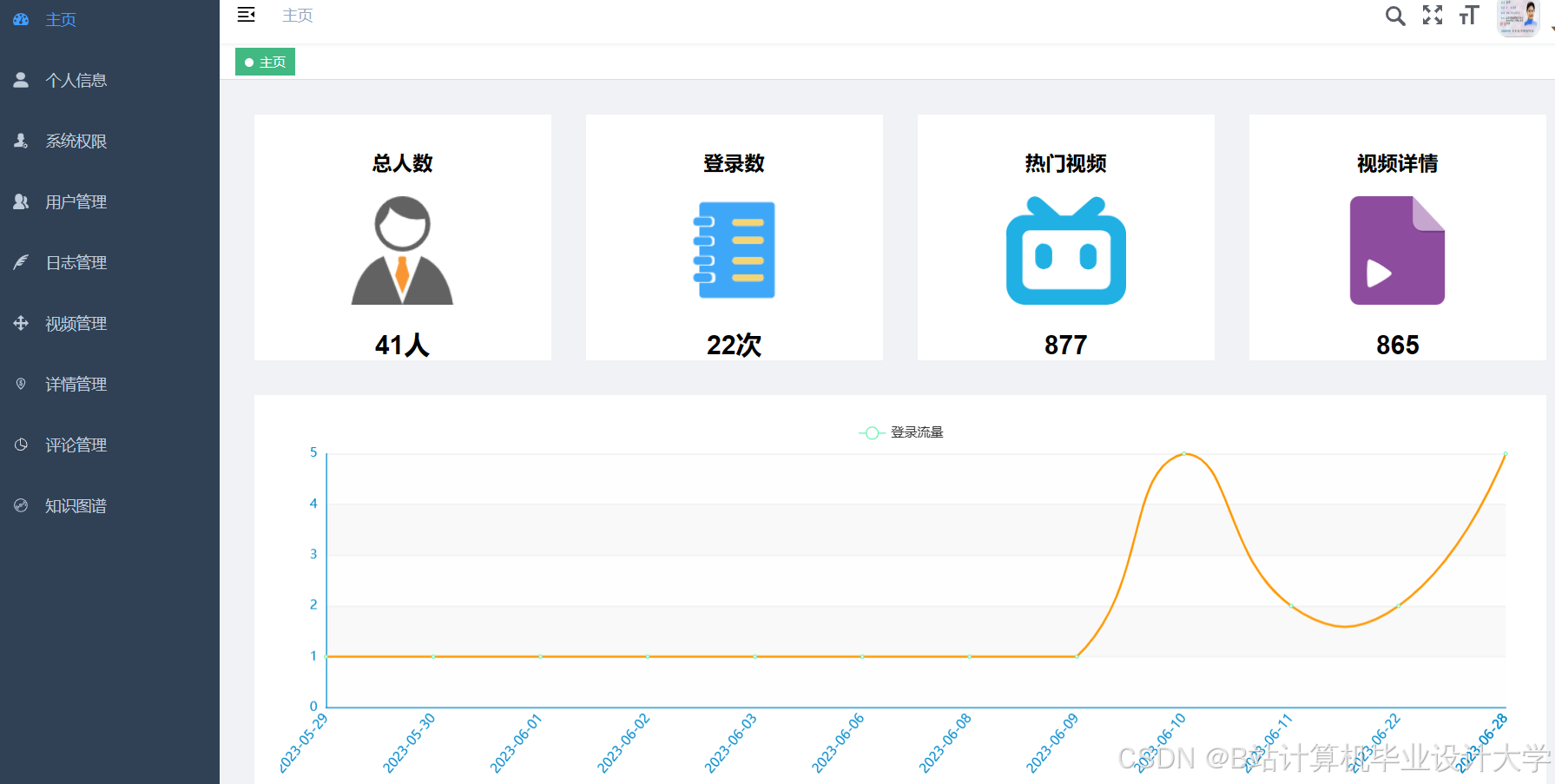
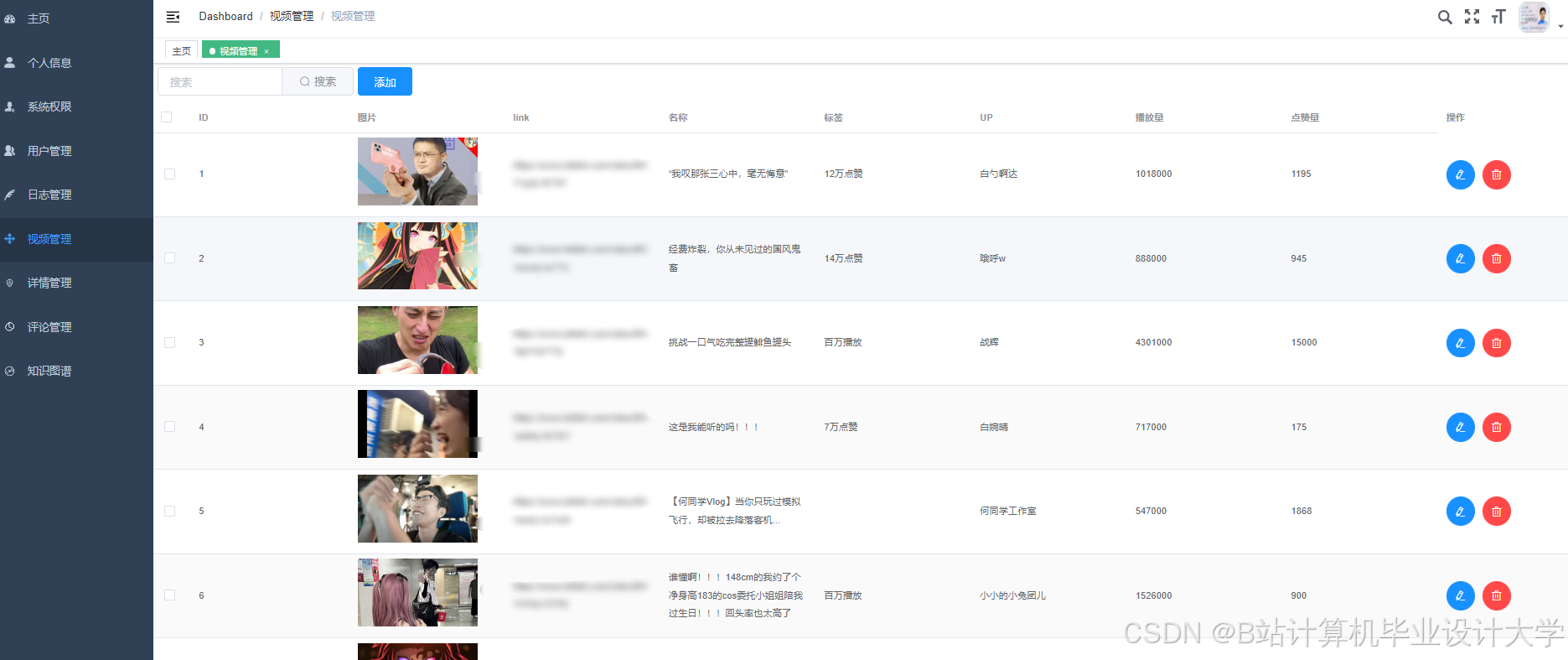
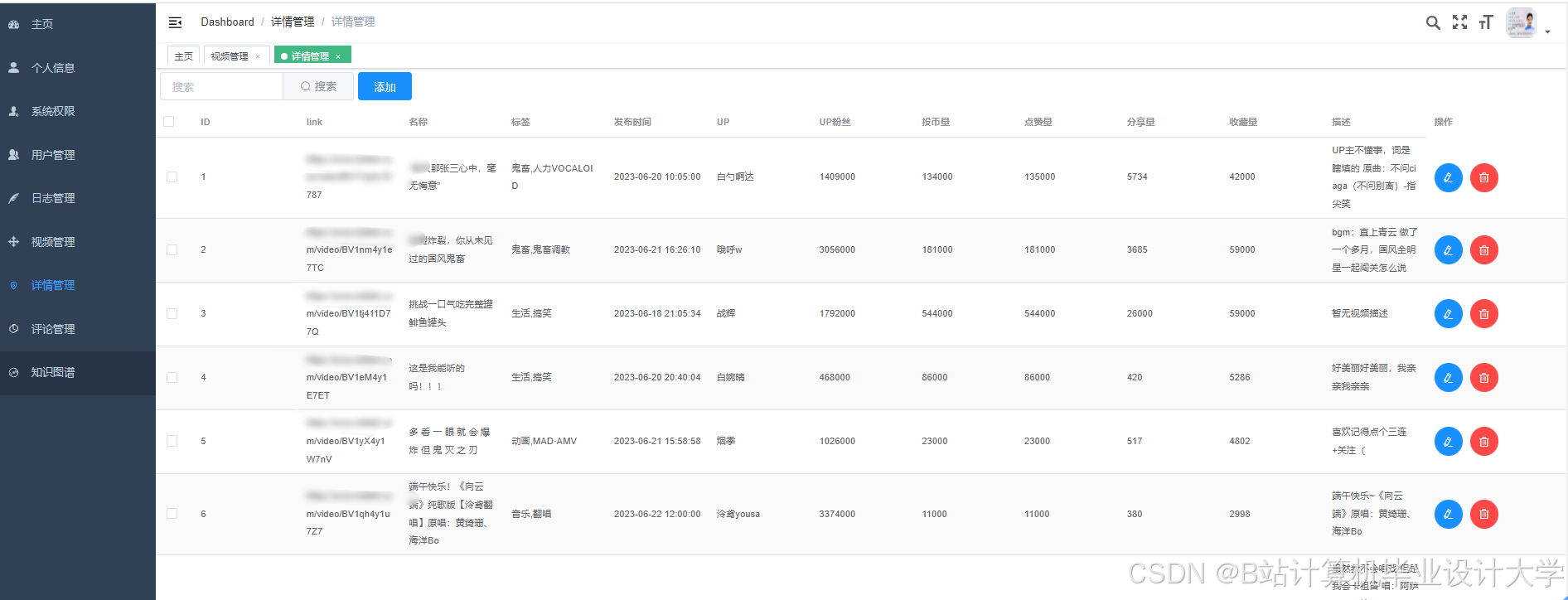
运行截图
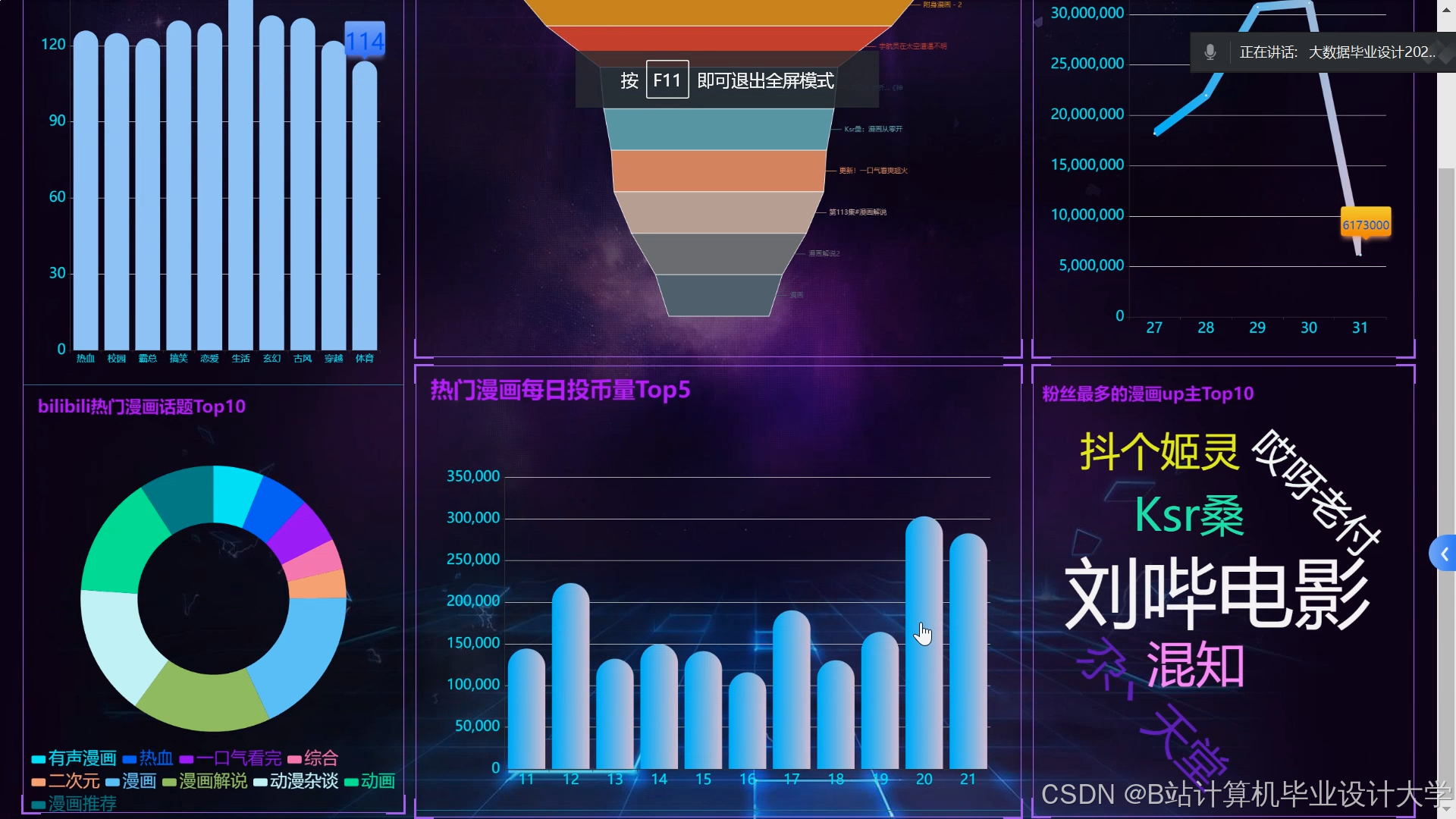
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











