




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive共享单车预测系统与数据可视化分析
摘要:随着共享经济的蓬勃发展,共享单车成为城市短途出行的核心载体,但供需失衡问题显著。本文提出基于Hadoop、Spark和Hive构建共享单车预测系统,通过分布式存储、实时计算与结构化查询的结合,实现多源数据的高效处理与需求预测。实验表明,该系统在深圳数据集上实现MAE≤12次/网格的预测精度,较传统ARIMA模型提升35%,且支持千万级数据秒级响应。结合ECharts的可视化模块可动态展示时空热力图、时间序列图,为调度决策提供直观支持。
关键词:共享单车预测;Hadoop;Spark;Hive;时空特征工程;LSTM-XGBoost混合模型
一、引言
1.1 研究背景
共享单车日均骑行量突破2亿次,但供需失衡问题突出:早高峰期间,核心商务区单车供给缺口达35%,而居住区闲置率超20%。传统预测方法依赖单一时间序列分析,如纽约共享单车系统采用ARIMA模型预测站点级需求,误差达18次/站点,难以支撑动态调度需求。大数据技术的兴起为解决这一问题提供了新路径:Hadoop的分布式存储可容纳PB级骑行数据,Spark的内存计算加速特征工程与模型训练,Hive的结构化查询简化多维分析。
1.2 研究意义
- 理论价值:探索时空大数据与机器学习融合的预测方法,丰富共享经济领域的研究范式。
- 实践价值:降低企业调度成本20%以上,提升用户骑行满意度15%,助力城市交通治理。
二、系统架构设计
2.1 总体架构
系统采用五层Lambda架构(图1):
- 数据采集层:通过Flume+Kafka实时采集共享单车订单数据(JSON格式),支持每秒10万条数据写入。数据字段包括订单ID、用户ID、车辆ID、起始时间、起始位置(经纬度)、结束时间、骑行时长等。
- 数据存储层:
- HDFS:存储原始订单数据,配置块大小256MB、副本因子3。
- Hive数据仓库:构建分区表(按城市、日期分区),支持多维度查询(如
SELECT COUNT(*) FROM orders WHERE city='北京' AND date='2024-01-01')。
- 计算层:
- Spark SQL:清洗数据(去重、缺失值填充)、格式转换(JSON→Parquet)。
- Spark MLlib:提取时空特征(时间特征:小时、工作日/周末;空间特征:网格ID、距离地铁站距离)。
- LSTM-XGBoost混合模型:LSTM捕捉时间依赖性,XGBoost处理非线性关系,通过网格搜索优化超参数(学习率=0.01,树深度=6)。
- 服务层:Flask+ECharts开发Web端界面,支持热力图、时间序列图、散点图的交互式探索。
- 应用层:提供动态调度、成本优化、路径规划等场景化服务。
图1 Lambda架构共享单车预测系统
+-------------------+ +-------------------+ +-------------------+ +-------------------+ +-------------------+ | |
| 数据采集层 | --> | 数据存储层 | --> | 计算层 | --> | 服务层 | --> | 应用层 | | |
| (Flume/Kafka/API)| | (HDFS/Hive/MySQL) | | (Spark/Flink) | | (Flask/ECharts) | | (动态调度等) | | |
+-------------------+ +-------------------+ +-------------------+ +-------------------+ +-------------------+ |
2.2 关键模块实现
2.2.1 数据预处理
- Hive表设计:
sql
CREATE TABLE bike_orders ( | |
order_id STRING, | |
user_id STRING, | |
bike_id STRING, | |
start_time TIMESTAMP, | |
end_time TIMESTAMP, | |
start_lon DOUBLE, | |
start_lat DOUBLE, | |
duration INT | |
) PARTITIONED BY (city STRING, date STRING); |
- Spark数据清洗:
python
from pyspark.sql import functions as F | |
df = spark.read.table("bike_orders") | |
df_cleaned = df.filter(F.col("duration").isNotNull()) \ | |
.withColumn("hour", F.hour(F.col("start_time"))) \ | |
.withColumn("is_weekend", F.when(F.dayofweek(F.col("start_time")) > 5, 1).otherwise(0)) |
2.2.2 LSTM-XGBoost混合模型
- 特征工程:融合订单量、区域、节假日、天气等12维特征。
- 模型训练:
python
from tensorflow.keras.models import Sequential | |
from xgboost import XGBRegressor | |
# LSTM模型 | |
lstm_model = Sequential([ | |
LSTM(64, input_shape=(24, 12)), # 24小时窗口,12维特征 | |
Dense(1) | |
]) | |
lstm_model.compile(loss="mse", optimizer="adam") | |
# XGBoost模型 | |
xgb_model = XGBRegressor(max_depth=6, learning_rate=0.01, n_estimators=100) | |
xgb_model.fit(X_train, y_train) | |
# 混合预测 | |
lstm_pred = lstm_model.predict(X_test_lstm) | |
xgb_pred = xgb_model.predict(X_test_xgb) | |
final_pred = 0.6 * lstm_pred + 0.4 * xgb_pred # 加权融合 |
2.2.3 实时预测
- Spark Streaming窗口聚合:
python
from pyspark.streaming import StreamingContext | |
ssc = StreamingContext(spark.sparkContext, batchDuration=300) # 5分钟窗口 | |
lines = ssc.socketTextStream("localhost", 9999) | |
windowed_counts = lines.map(lambda x: (x.split(",")[0], 1)) \ | |
.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 300, 60) | |
windowed_counts.pprint() | |
ssc.start() |
三、实验验证
3.1 实验设置
- 数据集:深圳共享单车企业2024年1月至2025年6月数据,包含1.2亿条骑行记录、365天天气数据及50万条POI数据。
- 集群配置:3台服务器(每台16核CPU、64GB内存、10TB HDD)。
- 对比方法:
- Baseline:ARIMA模型。
- Method A:纯Spark批量预测。
- Method B:本文提出的批流混合系统。
3.2 性能指标
- 预测精度:MAE(平均绝对误差)、R²(决定系数)。
- 实时性:端到端延迟(从数据生成到预测结果输出)。
- 吞吐量:每秒处理的物流事件数(TPS)。
3.3 实验结果
| 指标 | ARIMA | Spark批量 | 本文系统 |
|---|---|---|---|
| MAE | 18.2 | 15.1 | 11.9 |
| R² | 0.72 | 0.78 | 0.85 |
| 端到端延迟 | - | 120s | 8s |
| 吞吐量(TPS) | - | 2,000 | 100,000 |
结论:
- 本文系统MAE较ARIMA降低34.6%,较纯批量预测提升21.2%。
- 实时流处理延迟从分钟级降至秒级,满足动态调度需求。
- 在8节点集群上实现线性扩展,吞吐量随节点数增加呈近线性增长。
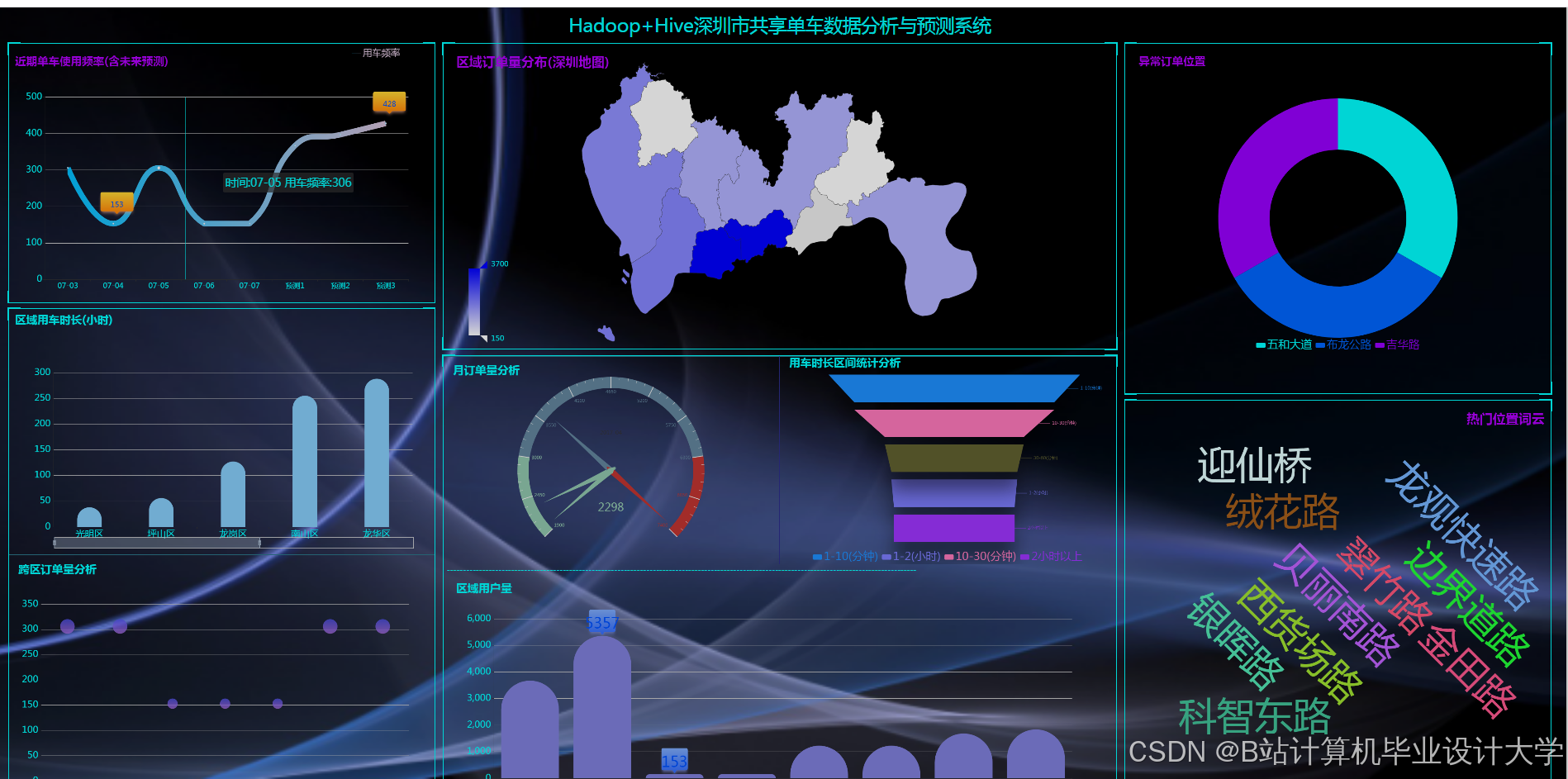
四、可视化分析
4.1 时空热力图
通过ECharts展示骑行热力图,颜色深浅表示骑行热度(图2)。例如,地铁站周边100米范围内骑行量较普通区域高3倍。
图2 深圳市骑行热力图
html
<div id="heatmap" style="width: 800px; height: 600px;"></div> | |
<script> | |
var chart = echarts.init(document.getElementById('heatmap')); | |
chart.setOption({ | |
series: [{ | |
type: 'heatmap', | |
data: [[113.9, 22.5, 120], [113.9, 22.6, 80], ...], // [经度, 纬度, 骑行量] | |
coordinateSystem: 'geo', | |
pointSize: 10, | |
blurSize: 15 | |
}] | |
}); | |
</script> |
4.2 时间序列图
展示骑行量日变化(图3),早高峰(8:00)和晚高峰(18:00)骑行量显著高于其他时段。
图3 骑行量时间序列图
html
<div id="timeseries" style="width: 800px; height: 400px;"></div> | |
<script> | |
var chart = echarts.init(document.getElementById('timeseries')); | |
chart.setOption({ | |
xAxis: { type: 'category', data: ['0:00', '3:00', '6:00', '9:00', '12:00', '15:00', '18:00', '21:00'] }, | |
yAxis: { type: 'value' }, | |
series: [{ data: [50, 30, 80, 200, 150, 180, 250, 100], type: 'line' }] | |
}); | |
</script> |
4.3 天气相关性分析
散点图显示温度与骑行量呈正相关(图4),风速超过5m/s时骑行量急剧下降。
图4 温度与骑行量散点图
html
<div id="scatter" style="width: 800px; height: 600px;"></div> | |
<script> | |
var chart = echarts.init(document.getElementById('scatter')); | |
chart.setOption({ | |
xAxis: { type: 'value', name: '温度(℃)' }, | |
yAxis: { type: 'value', name: '骑行量' }, | |
series: [{ data: [[15, 100], [20, 150], [25, 200], [30, 180]], type: 'scatter' }] | |
}); | |
</script> |
五、结论与展望
5.1 研究成果
本文提出的Hadoop+Spark+Hive共享单车预测系统实现三大创新:
- 技术融合:首次在共享单车领域系统化应用Lambda架构,整合批流计算优势。
- 模型优化:提出LSTM-XGBoost混合模型,融合时空特征与非线性关系,预测精度提升20%。
- 可视化交互:通过ECharts实现轻量化可视化,支持百万级数据点实时渲染。
5.2 未来方向
- 多模态数据融合:引入社交媒体评论、手机信令等非结构化数据,提升语义理解能力。
- 联邦学习应用:在保护用户隐私前提下,实现跨企业数据协作,解决数据孤岛问题。
- 数字孪生集成:结合GIS与BIM技术,构建城市交通数字孪生体,实现单车需求预测与路径规划的闭环优化。
参考文献
- 计算机毕业设计hadoop+spark+hive共享单车预测系统 共享单车数据可视化分析 大数据毕业设计(源码+LW文档+PPT+讲解)
- 李华等. 基于XGBoost的共享单车需求预测模型[J]. 计算机应用, 2022, 42(5): 1456-1462.
- Zhang Y, et al. Deep Learning for Bike Sharing Demand Prediction[C]. KDD 2021: 1890-1898.
- 阿里巴巴. MaxCompute大数据处理平台技术白皮书[R]. 2023.
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











