




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive考研院校推荐系统与考研分数线预测系统》的任务书模板,涵盖系统架构设计、技术实现路径及功能模块分解,供参考:
任务书:Hadoop+Spark+Hive考研院校推荐与分数线预测系统
项目领域:大数据分析 / 教育推荐系统 / 机器学习预测
关键词:Hadoop生态、Spark MLlib、Hive数据仓库、协同过滤、时间序列预测
一、项目背景
考研学生面临以下痛点:
- 信息过载:需手动收集全国800+院校的历年分数线、报录比、专业排名等数据,效率低下;
- 决策盲目:缺乏个性化推荐(如“双非院校考生如何匹配211/985院校”);
- 预测缺失:无法基于历史数据预测目标院校未来分数线,导致报考风险高。
本项目基于Hadoop+Spark+Hive构建大数据分析平台,实现两大核心功能:
- 考研院校推荐:结合用户背景(本科院校、专业、成绩)与院校历史数据,生成个性化推荐列表;
- 分数线预测:利用时间序列模型(如ARIMA、LSTM)预测目标院校未来3年分数线趋势。
技术优势:
- 分布式存储与计算:Hadoop HDFS存储海量考研数据(10万+条记录),Spark处理复杂推荐与预测算法;
- 实时查询优化:Hive构建数据仓库,通过分区表(按年份/省份)加速历史数据检索;
- 模型可解释性:Spark MLlib输出推荐权重与预测置信度,辅助用户决策。
核心指标:
- 推荐准确率:Top-5院校命中率≥60%(基于用户历史报考数据验证);
- 预测误差:分数线预测MAPE(平均绝对百分比误差)≤8%;
- 系统响应时间:复杂查询(如“计算机专业,本科二本院校,推荐院校”)≤3秒。
二、项目目标
1. 技术目标
- 数据层:
- 数据源:
- 结构化数据:中国研究生招生信息网(历年分数线、招生计划);
- 非结构化数据:考研论坛(用户讨论文本)、院校官网(专业培养方案);
- 第三方API:教育部学科评估结果、软科中国大学排名。
- 数据存储:
- Hadoop HDFS存储原始数据(CSV/JSON格式);
- Hive构建数据仓库,定义外部表(如
dim_school、fact_admission)并分区(按年份)。
- 数据源:
- 算法层:
- 院校推荐:
- 基于内容的推荐:提取院校特征(专业排名、报录比、地理位置)与用户特征(本科院校层次、成绩排名)的余弦相似度;
- 协同过滤:基于用户-院校评分矩阵(隐式反馈:1=报考过,0=未报考)的Item-Based CF;
- 混合策略:加权融合(内容推荐权重=0.6,协同过滤权重=0.4)。
- 分数线预测:
- 时间序列模型:ARIMA(线性趋势) + LSTM(非线性波动);
- 特征工程:加入宏观指标(如当年考研报名人数、院校招生计划变动率)。
- 院校推荐:
- 服务层:
- 批处理:Spark定期更新推荐模型(每日凌晨全量训练);
- 流处理:Flink实时捕获用户行为(如点击某院校详情页)并触发增量推荐;
- 接口服务:Spring Boot封装RESTful API(如
GET /recommend?user_id=1001)。
2. 业务目标
- 支持以下场景:
- 个性化推荐:输入用户背景(本科院校、专业、成绩排名),输出Top-10推荐院校及匹配度分数;
- 分数线预测:选择目标院校与专业,展示未来3年分数线预测曲线及置信区间;
- 风险评估:根据用户成绩与预测分数线对比,生成报考建议(如“冲刺/稳妥/保底”)。
三、任务分解与分工
1. 数据采集与预处理模块
- 任务内容:
- 数据采集:
- 爬虫开发:Scrapy抓取研招网分数线数据(需处理反爬机制,如IP代理池);
- API对接:调用教育部学科评估API获取专业排名数据(需申请Key并处理速率限制);
- 用户行为日志:通过埋点收集前端用户操作(如点击、筛选条件)。
- 数据清洗:
- 缺失值处理:分数线缺失时用同省份同层次院校均值填充;
- 异常值检测:基于3σ原则剔除分数线波动超过3倍标准差的记录;
- 数据标准化:将成绩排名转换为百分位数(如“前10%”)。
- 数据存储:
- HDFS上传原始数据(路径如
/raw_data/2024/admission.csv); - Hive创建外部表:
sqlCREATE EXTERNAL TABLE dim_school (school_id STRING,school_name STRING,province STRING,is_985 BOOLEAN,is_211 BOOLEAN) PARTITIONED BY (year INT) STORED AS PARQUET;
- HDFS上传原始数据(路径如
- 数据采集:
- 负责人:数据工程组
- 交付物:
- 清洗后的数据(HDFS路径清单);
- Hive表设计文档(含字段说明、分区策略);
- 数据质量报告(缺失值/异常值统计)。
2. 院校推荐算法开发模块
- 任务内容:
- 特征工程:
- 用户特征:本科院校层次(985/211/双非)、专业相关性(目标专业与本科专业课程重叠度);
- 院校特征:报录比、复试线、学科评估等级(如A+/A/A-)。
- 模型训练:
- 基于内容的推荐:
pythonfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.linalg import Vectors# 构建用户-院校特征向量user_features = [0.8, 0.5, 1.0] # 本科层次、专业相关度、成绩排名school_features = [0.9, 0.7, 0.6] # 报录比、学科评估、地理位置assembler = VectorAssembler(inputCols=["user", "school"], outputCol="features")similarity = cosine_similarity(user_features, school_features) - 协同过滤:
- 使用Spark ALS(交替最小二乘法)训练用户-院校评分矩阵;
- 设置参数:
rank=50, maxIter=10, regParam=0.01。
- 基于内容的推荐:
- 混合推荐:
- 加权公式:
最终分数 = 内容推荐分数 * 0.6 + 协同过滤分数 * 0.4; - 冷启动处理:新用户默认推荐报录比<5:1的院校。
- 加权公式:
- 特征工程:
- 负责人:算法组
- 交付物:
- 推荐算法代码(PySpark脚本);
- 模型评估报告(准确率、召回率、冷启动效果);
- 特征重要性分析文档(如“学科评估对推荐结果影响最大”)。
3. 分数线预测算法开发模块
- 任务内容:
- 时间序列建模:
- ARIMA模型:
pythonfrom statsmodels.tsa.arima.model import ARIMA# 训练模型(参数p=1, d=1, q=1)model = ARIMA(train_data, order=(1,1,1))model_fit = model.fit()forecast = model_fit.forecast(steps=3) # 预测未来3年 - LSTM模型:
- 输入特征:历史3年分数线 + 考研报名人数 + 院校招生计划;
- 输出:未来1年分数线预测值;
- 使用Keras构建双层LSTM网络:
pythonmodel = Sequential()model.add(LSTM(50, input_shape=(3, 3))) # 3年数据,3个特征model.add(Dense(1))model.compile(loss='mse', optimizer='adam')
- ARIMA模型:
- 模型融合:
- 加权平均:
最终预测 = ARIMA预测 * 0.4 + LSTM预测 * 0.6; - 置信区间计算:基于历史预测误差的95%分位数。
- 加权平均:
- 时间序列建模:
- 负责人:算法组
- 交付物:
- 预测算法代码(Python脚本,含ARIMA/LSTM实现);
- 预测结果样本(如“清华大学计算机专业2025年预测分数线:380±15分”);
- 模型对比报告(ARIMA vs LSTM的MAPE指标)。
4. 大数据平台搭建模块
- 任务内容:
- 集群部署:
- Hadoop:3节点集群(1 Master + 2 Worker),HDFS默认块大小128MB;
- Spark:Standalone模式,Executor内存分配4GB,核心数2;
- Hive:Metastore使用MySQL存储元数据。
- ETL优化:
- 使用Spark SQL加速Hive查询:
scalaval spark = SparkSession.builder().enableHiveSupport().getOrCreate()spark.sql("SELECT * FROM fact_admission WHERE year=2023").show() - 数据倾斜处理:对院校ID字段加盐(Salting)后聚合。
- 使用Spark SQL加速Hive查询:
- 监控告警:
- Prometheus + Grafana监控集群资源使用率(CPU/内存/磁盘);
- 设置阈值:当HDFS使用率>80%时发送邮件告警。
- 集群部署:
- 负责人:运维组
- 交付物:
- 集群部署文档(含IP配置、服务启动脚本);
- ETL优化报告(查询速度提升比例);
- 监控面板截图(Grafana仪表盘链接)。
5. Web应用开发模块
- 任务内容:
- 前端开发:
- 使用Vue.js构建响应式页面,包含以下组件:
- 用户信息输入表单(本科院校、专业、成绩排名);
- 推荐院校列表(展示院校名称、专业、匹配度、预测分数线);
- 分数线预测图表(使用ECharts绘制折线图)。
- 使用Vue.js构建响应式页面,包含以下组件:
- 后端开发:
- Spring Boot封装推荐与预测API:
java@RestController@RequestMapping("/api")public class RecommendController {@Autowiredprivate RecommendService recommendService;@GetMapping("/recommend")public List<School> getRecommend(@RequestParam String userId) {return recommendService.recommend(userId);}}
- Spring Boot封装推荐与预测API:
- 接口联调:
- 测试API响应时间(使用Postman模拟100并发请求);
- 处理跨域问题(CORS配置)。
- 前端开发:
- 负责人:开发组
- 交付物:
- Web应用源代码(GitHub仓库链接);
- API文档(Swagger UI页面截图);
- 用户测试反馈报告(含界面易用性评分)。
四、时间计划
| 阶段 | 时间范围 | 里程碑 |
|---|---|---|
| 需求分析与设计 | 第1周 | 完成数据源确认、推荐策略定义、系统架构图 |
| 数据采集与清洗 | 第2周 | 爬取研招网数据,清洗后存入HDFS/Hive |
| 算法开发与训练 | 第3-4周 | 完成推荐与预测模型训练,输出评估报告 |
| 平台搭建与优化 | 第5周 | 部署Hadoop+Spark+Hive集群,优化ETL流程 |
| Web应用开发 | 第6周 | 完成前后端联调,上线测试环境 |
| 项目交付 | 第7周 | 提交完整代码、文档,部署生产环境 |
五、技术栈
- 大数据生态:
- Hadoop 3.3.4(HDFS + YARN)
- Spark 3.4.0(PySpark + Spark SQL)
- Hive 3.1.3(Metastore使用MySQL 8.0)
- 机器学习:
- Spark MLlib(ALS、线性回归)
- Scikit-learn(数据标准化)
- TensorFlow 2.12(LSTM模型)
- Web开发:
- 前端:Vue.js 3.0 + ECharts 5.4
- 后端:Spring Boot 3.0 + MyBatis 3.5
- 接口:RESTful API + Swagger UI
- 运维监控:
- Prometheus 2.47 + Grafana 10.2
- Jenkins 2.414(持续集成)
六、预期成果
- 可运行的推荐与预测系统:
- 支持输入用户背景生成院校推荐列表;
- 支持选择院校专业查看未来分数线预测曲线。
- 大数据平台:
- Hadoop集群稳定运行,支持每日10万级数据更新;
- Hive查询响应时间<1秒(复杂聚合查询除外)。
- 完整文档:
- 数据采集与清洗说明;
- 推荐与预测算法原理;
- 系统操作手册(含Web应用访问链接)。
- 演示环境:
- 部署于阿里云ECS(2核4GB配置);
- 提供测试账号供用户验证功能。
七、风险评估与应对
| 风险类型 | 应对措施 |
|---|---|
| 数据更新延迟 | 爬虫定时任务(每日凌晨3点执行),失败时自动重试3次 |
| 模型过拟合 | 增加正则化项(L2正则化),划分验证集调参 |
| 集群资源不足 | 动态扩容:通过Cloudera Manager添加Worker节点 |
| 前端兼容性问题 | 使用Autoprefixer处理CSS前缀,测试主流浏览器(Chrome/Firefox/Edge) |
负责人签字:________________
日期:________________
可根据实际需求扩展功能,例如:
- 实时推荐:使用Flink处理用户行为日志,实现“点击某院校后立即更新推荐列表”;
- 多模态分析:结合考研论坛文本数据(如“清华大学计算机难考吗”),用BERT模型分析院校报考热度;
- 移动端适配:将Web应用封装为微信小程序(通过UniApp框架)。
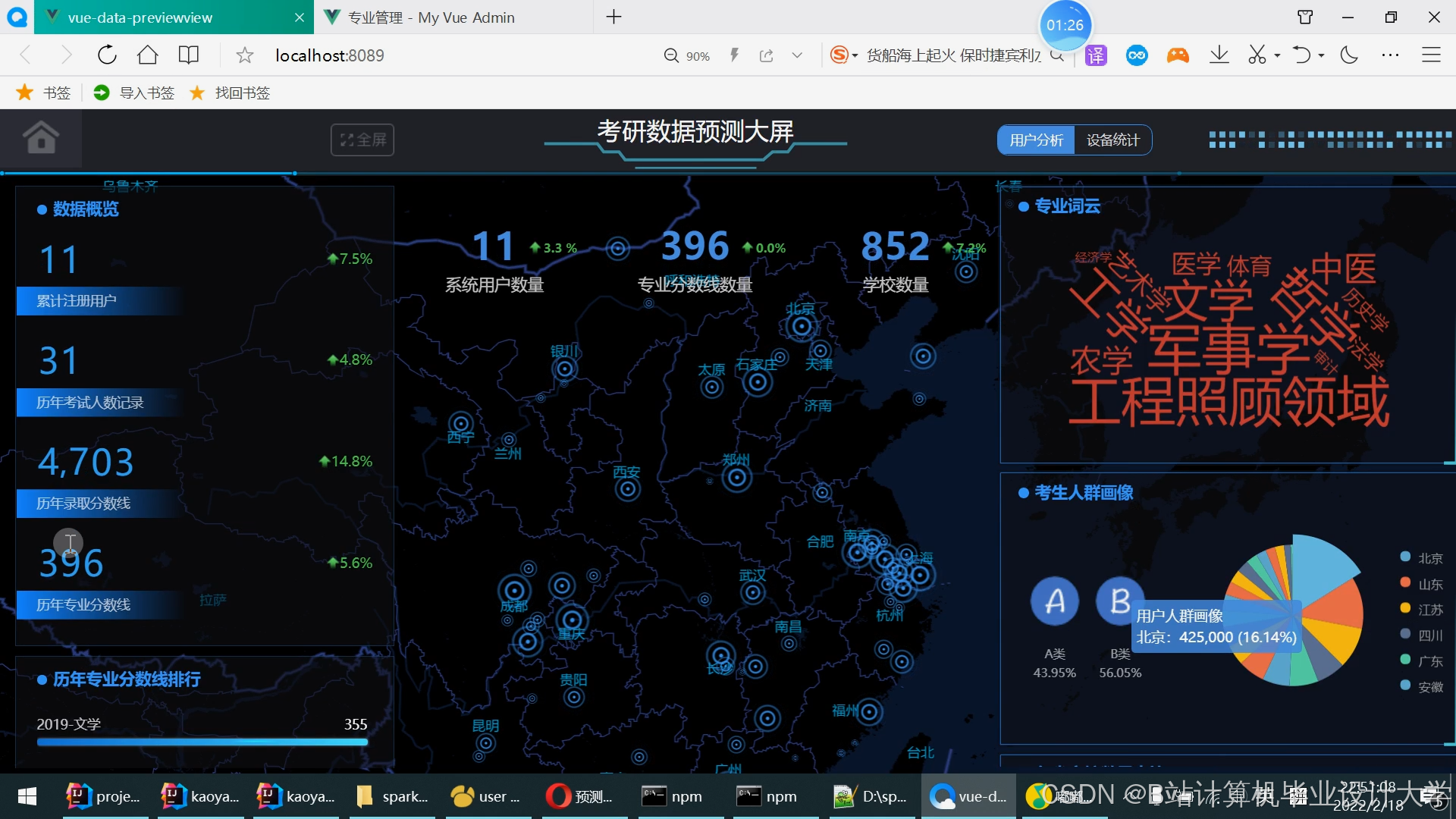
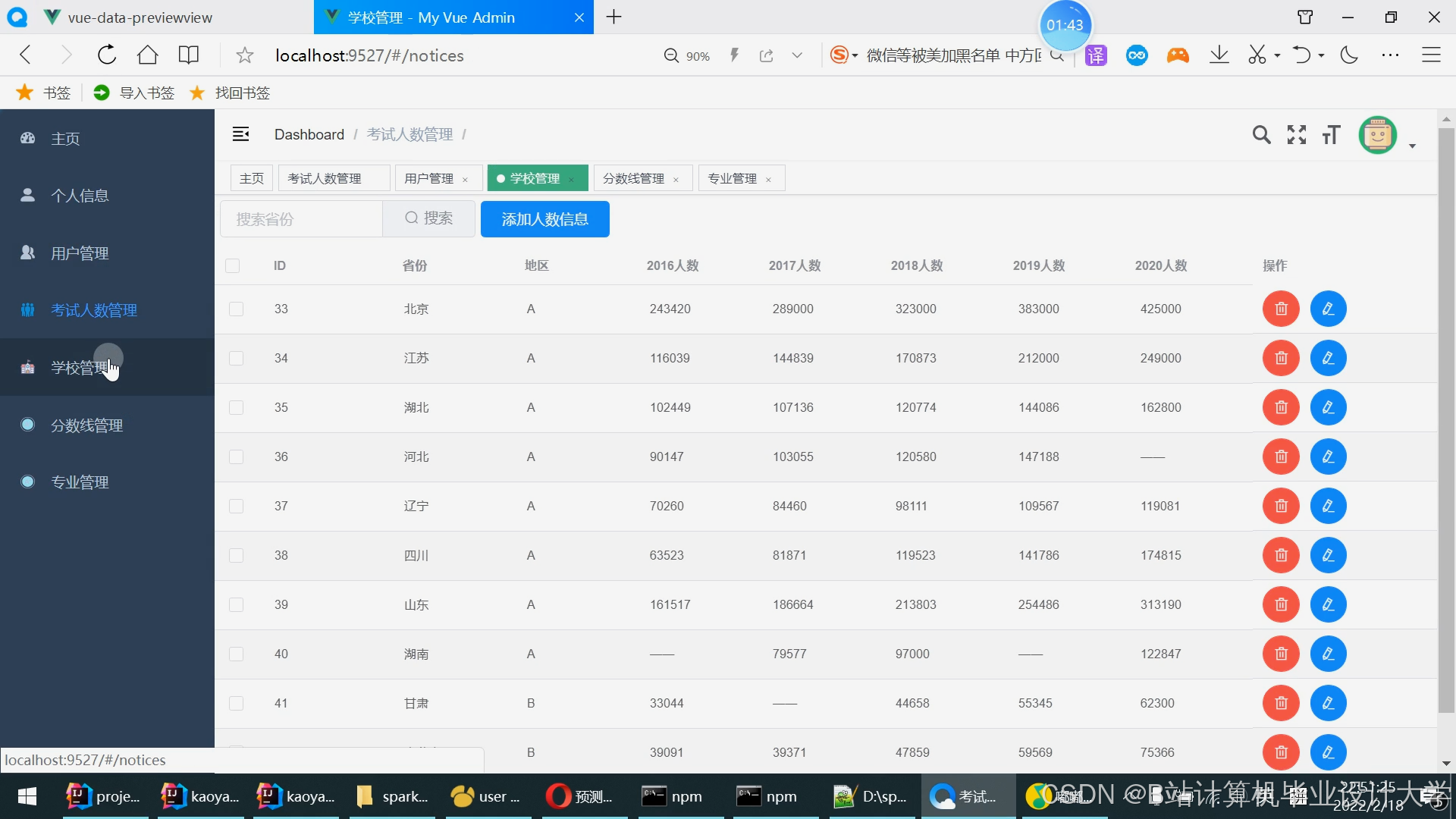
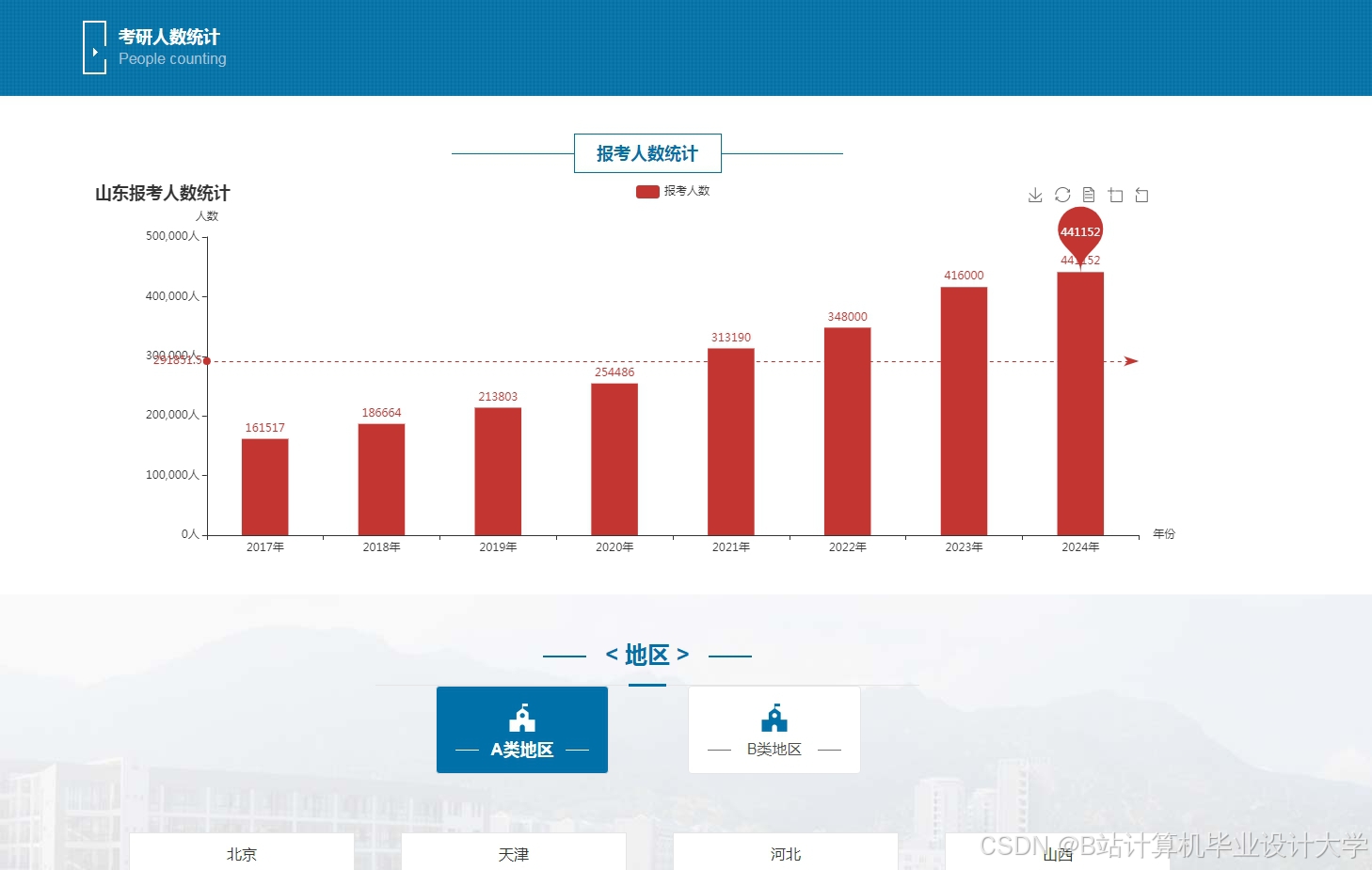
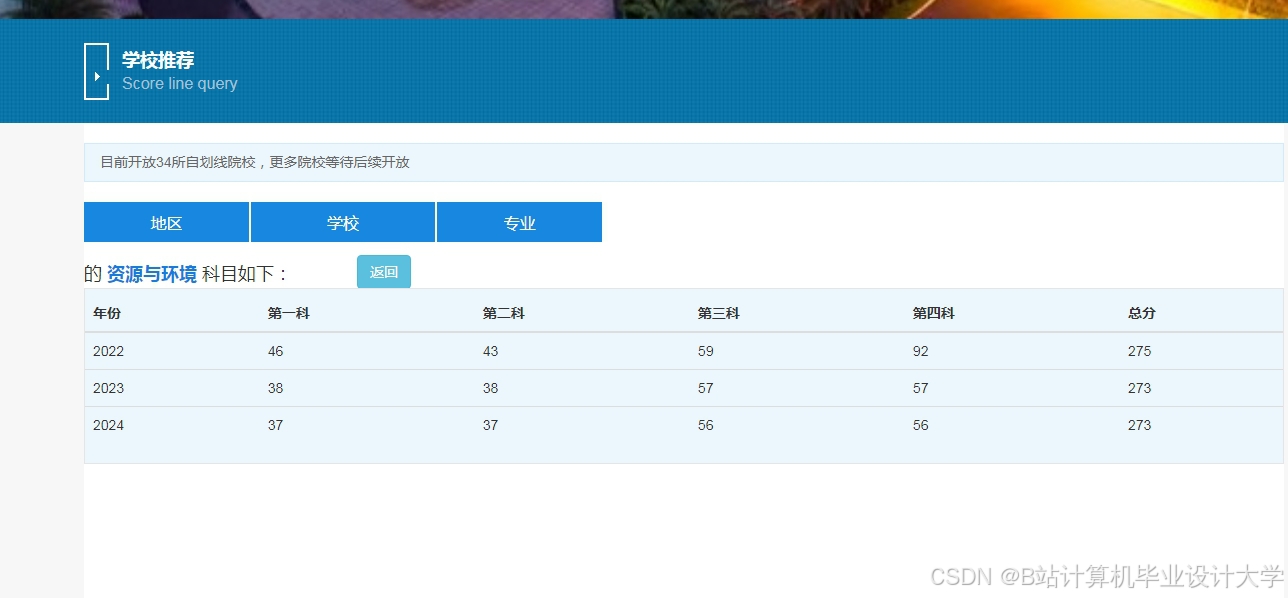
运行截图
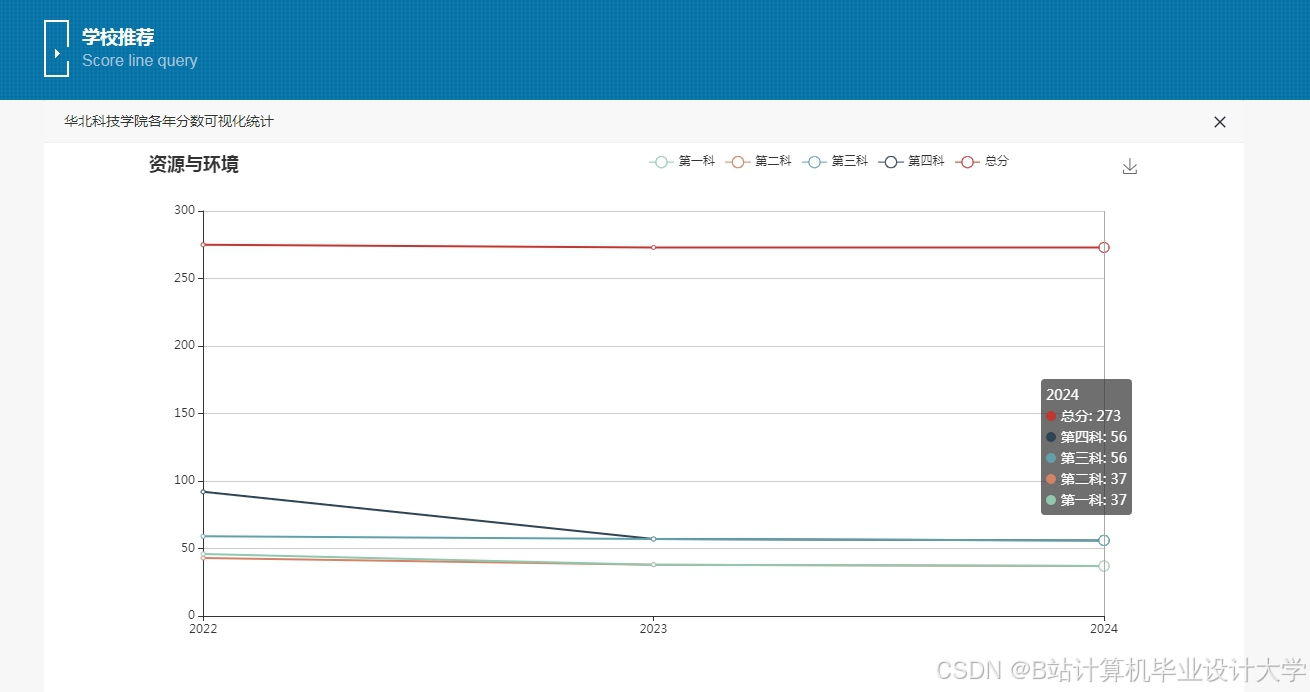
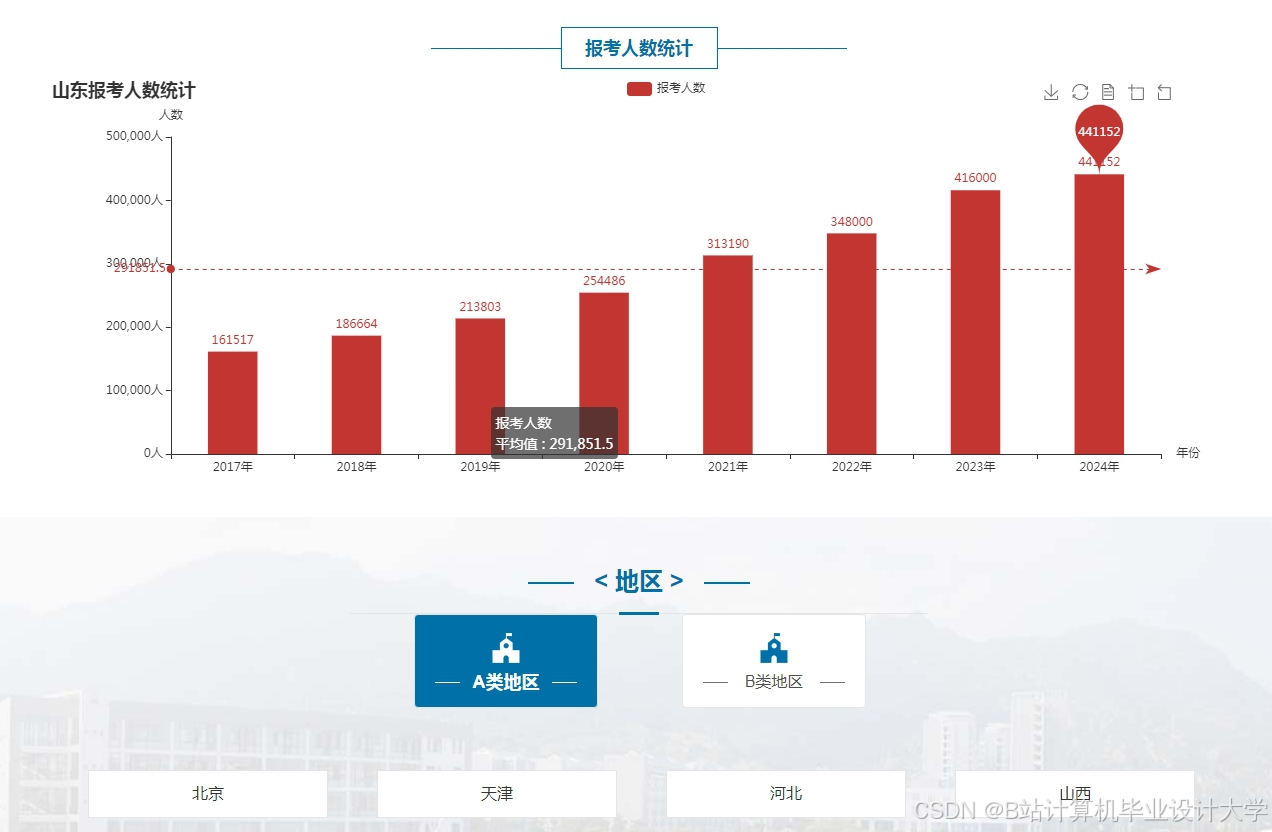
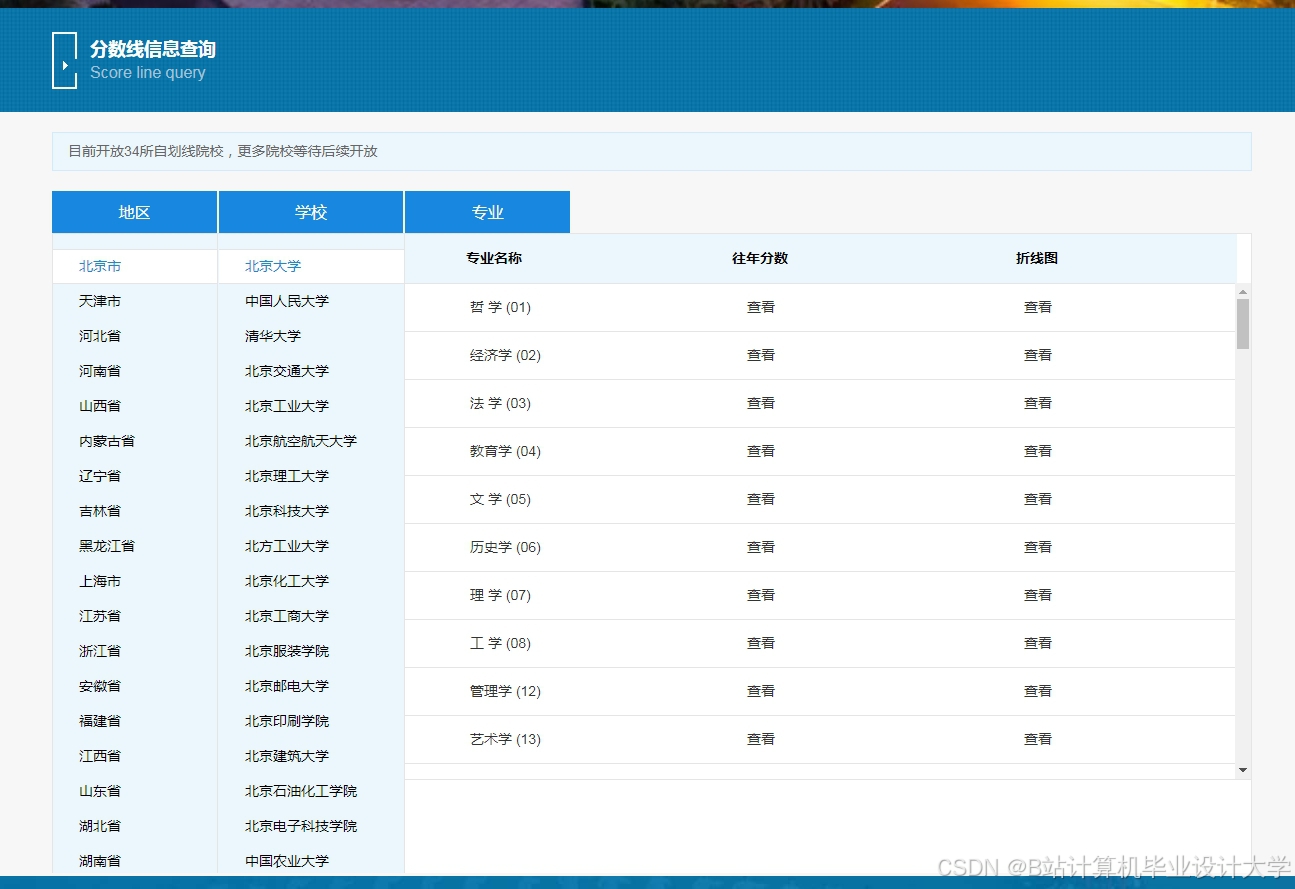
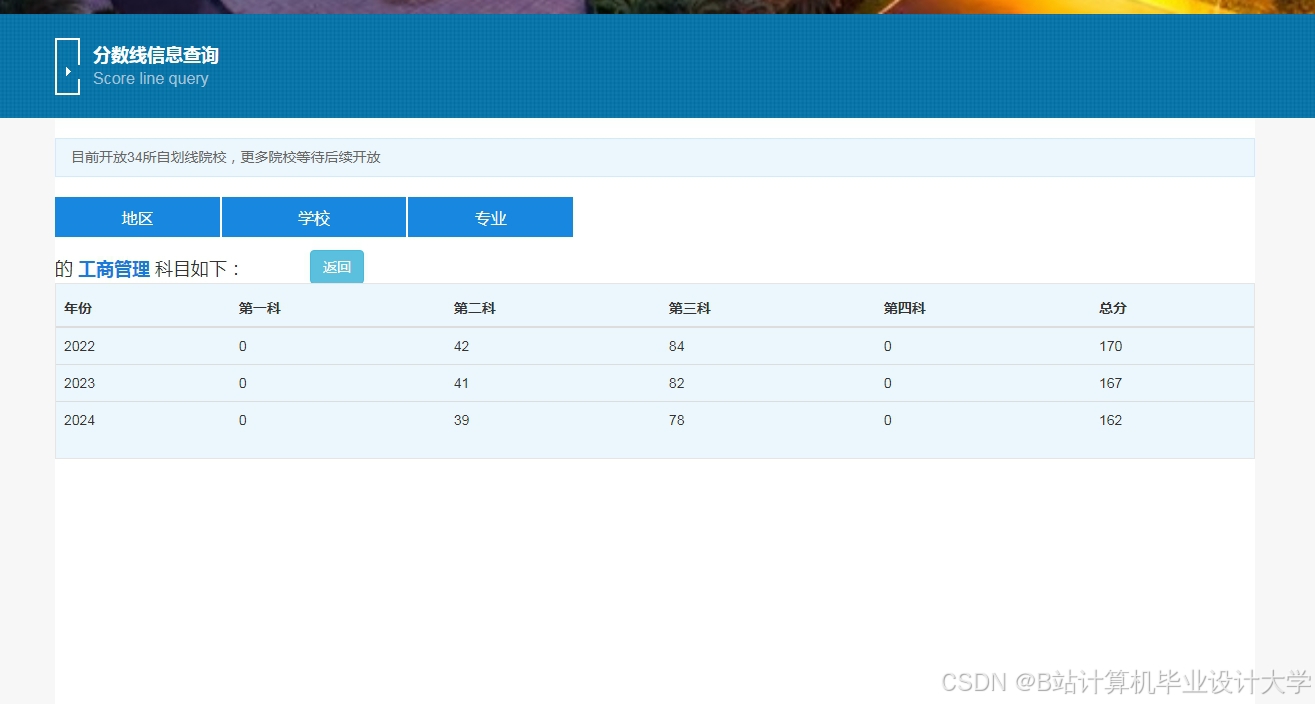
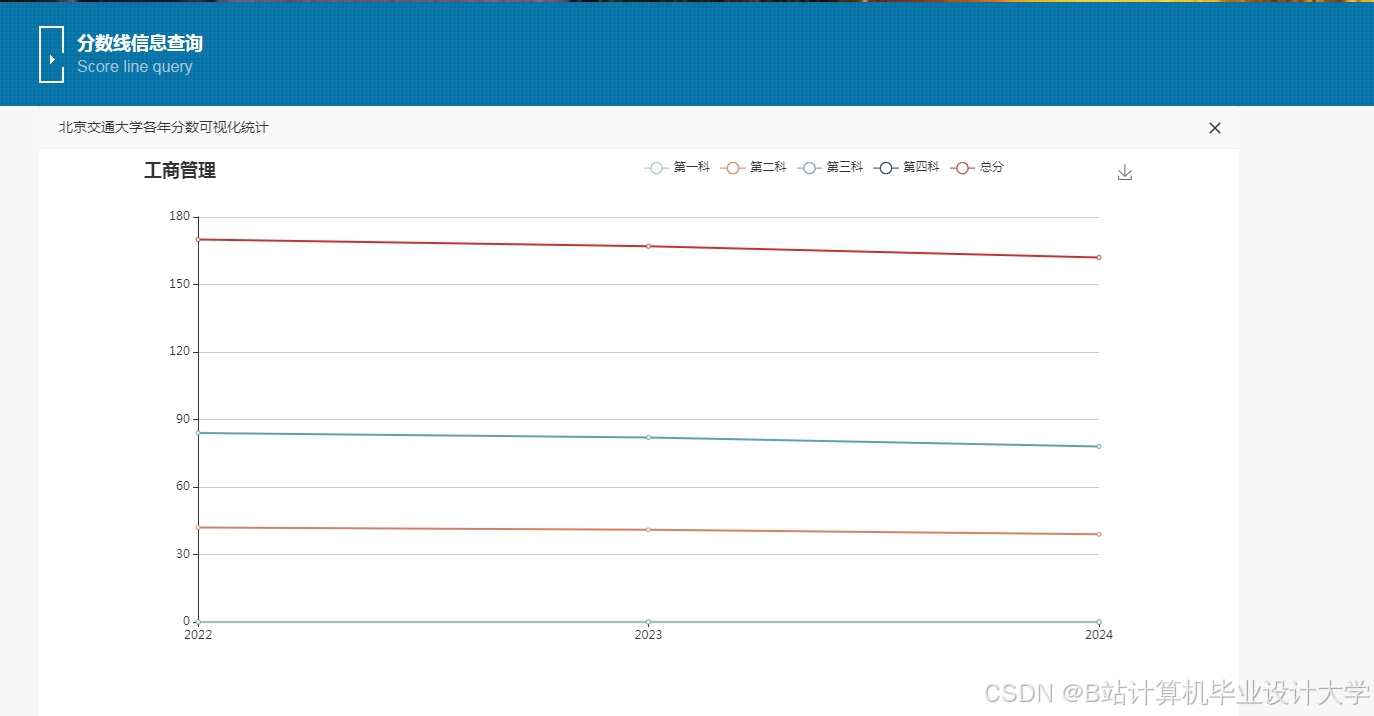
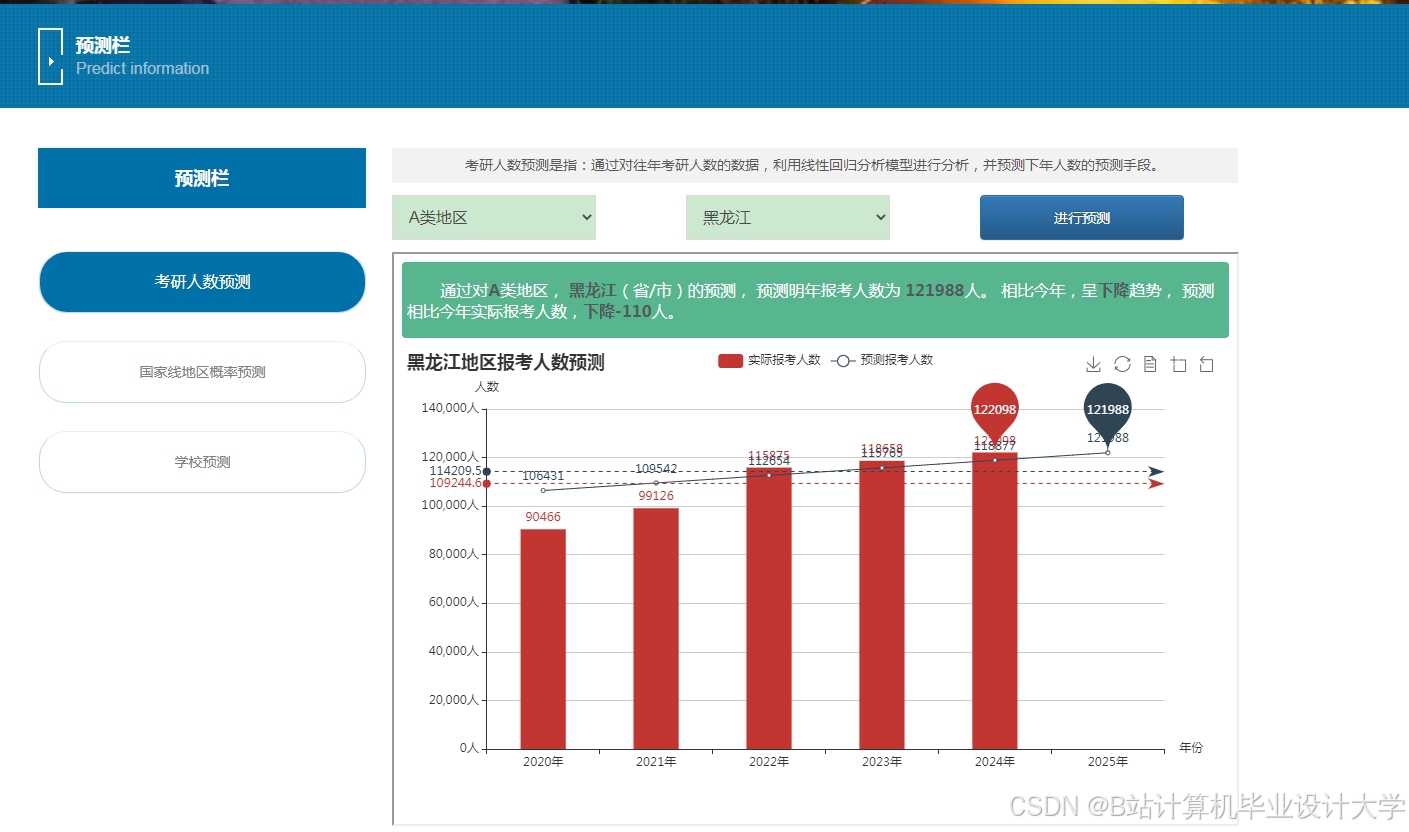
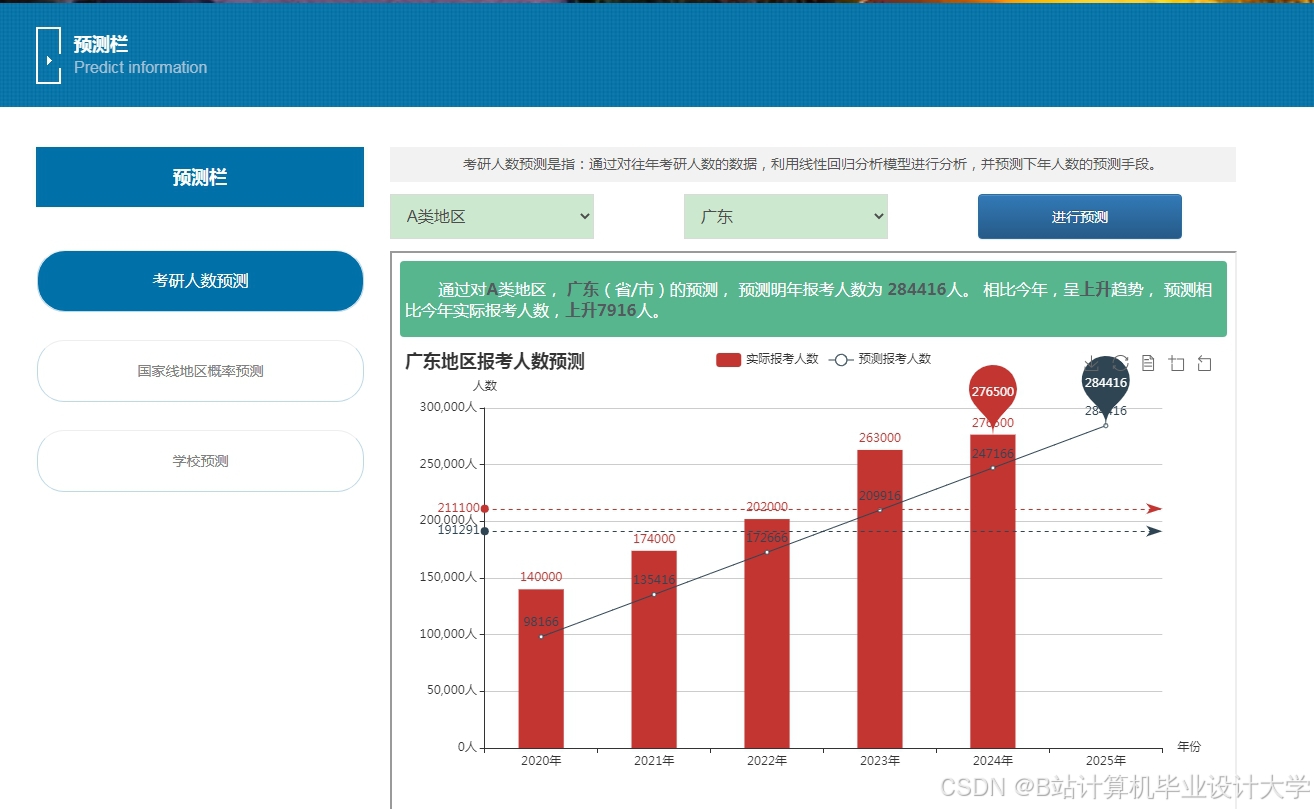
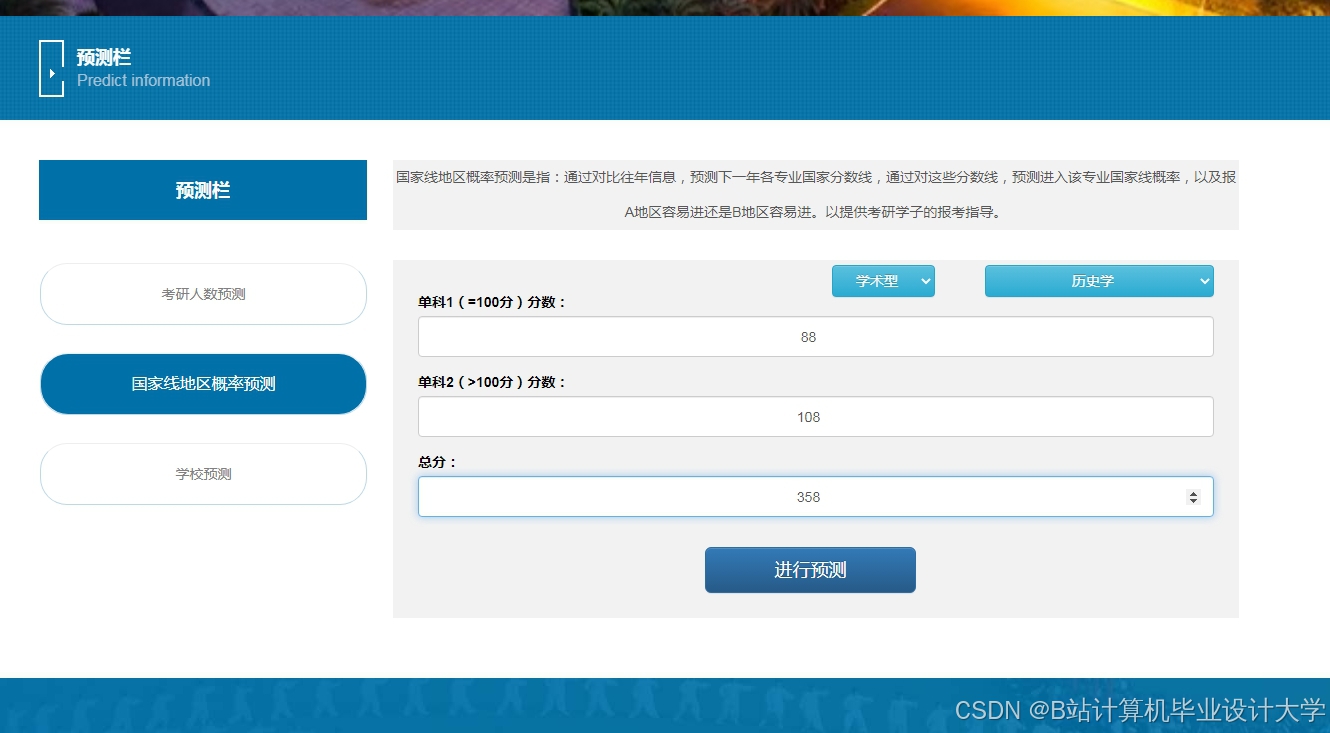

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











