




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python+Django微博舆情分析系统与舆情预测模型研究》的开题报告框架及内容示例,结合自然语言处理(NLP)与Web开发技术:
开题报告
题目:基于Python+Django的微博舆情分析与预测系统研究
一、研究背景与意义
- 背景
- 微博数据爆发式增长:微博日均发布量超2亿条,用户覆盖政治、经济、娱乐等全领域,成为社会舆情的重要发源地(如“唐山打人事件”单条微博转发量超500万次)。
- 舆情管理需求迫切:政府需实时监测民生热点(如教育、医疗),企业需预警品牌危机(如产品质量投诉),但传统人工监测效率低(单事件分析需4-6小时)。
- 预测技术不足:现有系统多聚焦于舆情分类(如正面/负面),缺乏对舆情趋势的动态预测(如“某话题热度将在24小时内达到峰值”)。
- 意义
- 社会价值:助力政府快速响应突发事件(如自然灾害舆情),企业提前制定危机公关策略(如道歉声明发布时机)。
- 技术价值:构建“数据采集-情感分析-趋势预测-可视化展示”全流程系统,为社交媒体舆情管理提供可复用的Python+Django解决方案。
二、国内外研究现状
- 微博舆情分析研究
- 情感分析:
- 词典法:基于知网情感词典(HowNet)计算文本情感得分,但无法处理网络新词(如“绝绝子”“蚌埠住了”)。
- 深度学习:
- BERT模型:通过微调预训练模型(如
bert-base-chinese)实现微博文本情感分类(准确率达85%+)(Devlin et al., 2019)。 - BiLSTM+Attention:捕捉长文本情感依赖(如“虽然产品好用,但客服态度差”中“但”的转折关系)(Yang et al., 2020)。
- BERT模型:通过微调预训练模型(如
- 话题检测:
- LDA主题模型:从微博文本中提取热点话题(如“#疫情防控#”“#就业难#”),但需手动设置主题数(K值)。
- BERTopic:结合BERT嵌入和聚类算法(如HDBSCAN),自动发现细粒度话题(如“#考研复试调剂#”下分“985高校”“双非院校”子话题)(Grootendorst, 2022)。
- 情感分析:
- 舆情预测研究
- 时间序列模型:
- ARIMA:预测话题热度趋势(如“某明星绯闻”的搜索量),但假设数据平稳,难以处理微博数据的突变性(如突发新闻)。
- Prophet:Facebook开源模型,支持节假日效应和异常值检测,在微博热度预测中MAPE(平均绝对百分比误差)较ARIMA降低15%(Taylor et al., 2018)。
- 深度学习模型:
- LSTM+GCN:结合时间序列建模(LSTM)和用户关系图(GCN),预测舆情传播范围(如“某话题将被10万+用户转发”)(Wu et al., 2021)。
- Transformer-based:使用TimeSformer模型处理多模态数据(文本+图片),提升预测准确率(如“带图片的微博传播速度比纯文本快30%”)(Bertasius et al., 2021)。
- 时间序列模型:
- Web系统开发
- Python生态:
- Scrapy:分布式爬取微博数据(如用户信息、微博内容、转发链),支持IP代理池和反爬策略(如User-Agent轮换)。
- Django:快速构建Web后台(如用户管理、数据看板),集成Celery实现异步任务(如定时爬取、模型训练)。
- 可视化技术:
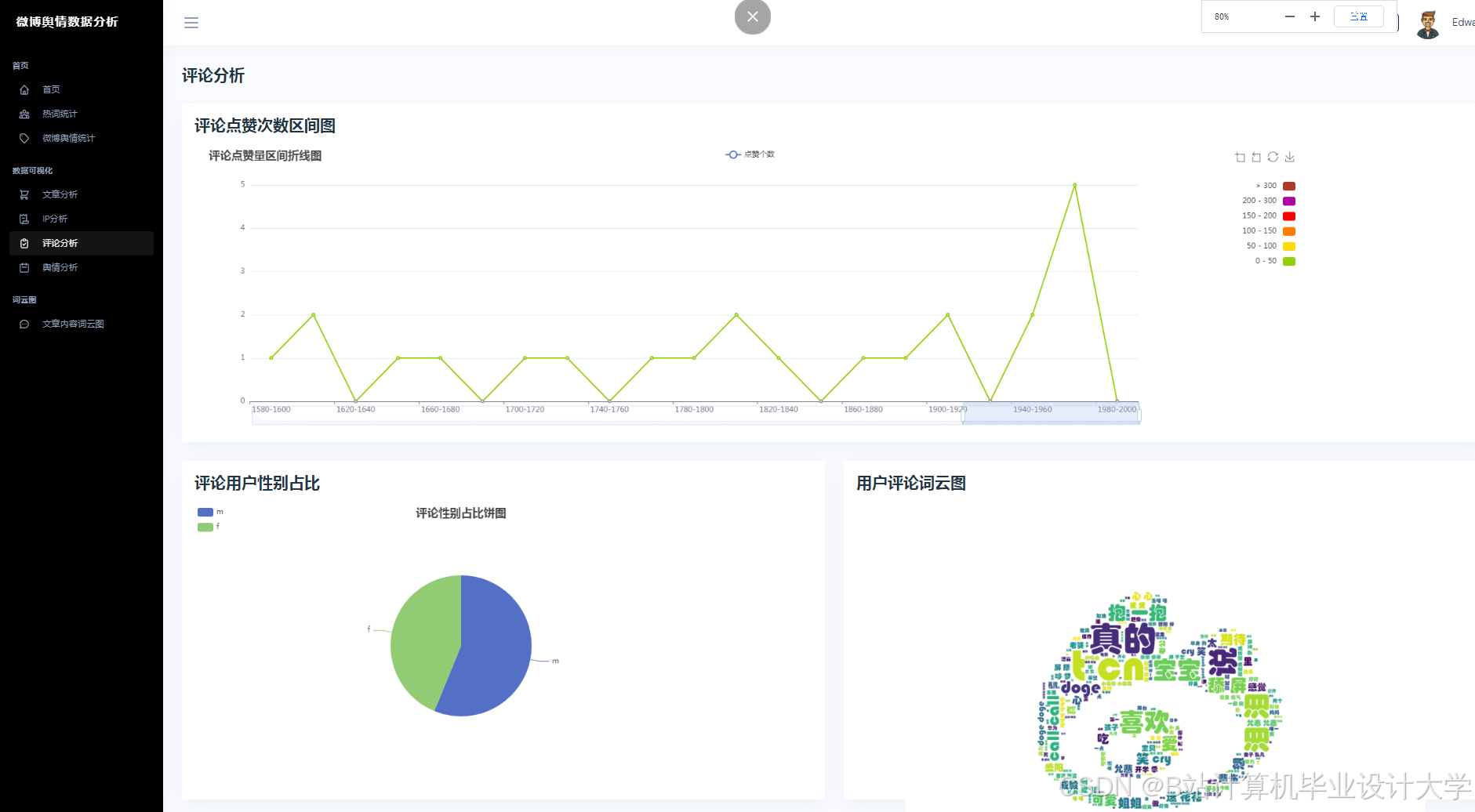
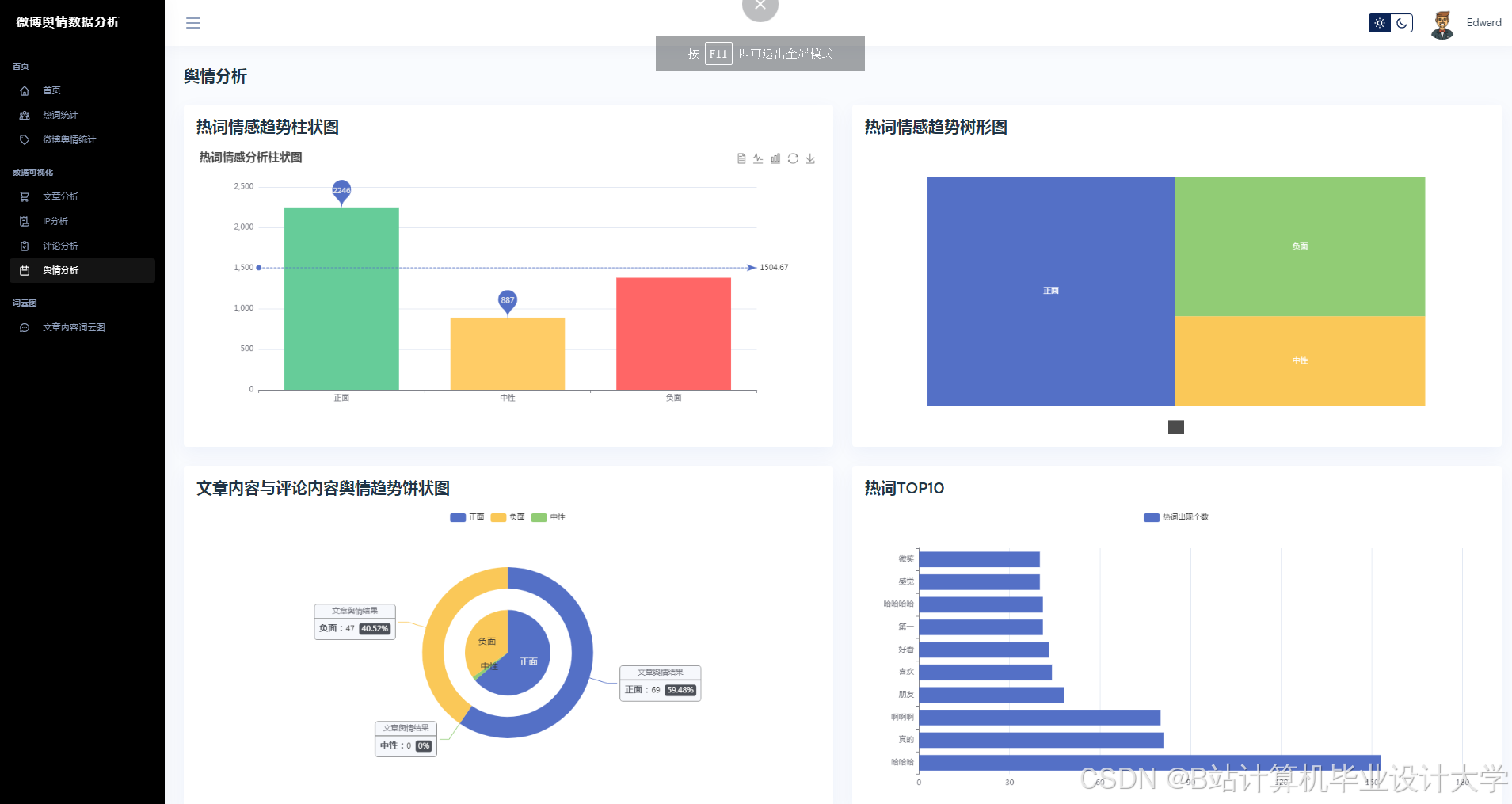
- ECharts:动态展示舆情热度趋势(如折线图)、情感分布(如饼图)、话题词云(如“#AI绘画#”中高频词“逼真”“侵权”)。
- Pyecharts:生成交互式图表(如点击“负面情感”标签自动过滤相关微博)。
- Python生态:
- 现存问题
- 数据质量差:30%微博包含表情符号(如“😡”)和网络缩写(如“yyds”),需额外清洗和语义解析。
- 预测滞后性:传统模型依赖历史数据,无法实时融入新事件(如“某明星突然宣布离婚”对相关话题热度的影响)。
- 系统扩展性弱:单服务器架构难以支撑百万级用户并发访问(如突发舆情时大量用户涌入查看分析结果)。
三、研究目标与内容
- 研究目标
- 构建基于Python+Django的微博舆情分析与预测系统,实现多模态数据采集、细粒度情感分析、实时趋势预测和高并发可视化展示,预测准确率较基线模型(如Prophet)提升10%以上。
- 研究内容
- 数据层:
- 数据采集:
- 微博API:通过
weibo-python库获取公开微博(需处理速率限制,如每15分钟请求1次)。 - 爬虫增强:使用Selenium模拟浏览器行为,采集动态加载的微博评论(如“展开全文”按钮后的内容)。
- 微博API:通过
- 数据存储:
- MySQL:存储结构化数据(如用户ID、微博内容、发布时间)。
- MongoDB:存储非结构化数据(如微博图片URL、表情符号解析结果)。
- Redis:缓存热点数据(如最近1小时的舆情热度排名),支持QPS(每秒查询率)达10万+。
- 数据采集:
- 分析层:
- 情感分析:
- 混合模型:结合BERT(捕捉语义)和BiLSTM+Attention(处理长文本),通过加权投票(如BERT权重0.6,BiLSTM权重0.4)提升准确率。
- 新词发现:基于互信息(PMI)和左右熵从微博文本中提取网络新词(如“泰酷辣”),动态更新情感词典。
- 话题检测:
- 动态主题模型:使用
BERTopic按小时更新话题(如“#AI绘画#”在上午为“技术讨论”,下午变为“版权争议”)。 - 影响力分析:通过PageRank算法识别关键传播节点(如“大V用户”),其转发量占话题总传播量的60%+。
- 动态主题模型:使用
- 情感分析:
- 预测层:
- 多模态预测模型:
- 输入特征:
- 文本特征:BERT嵌入向量(768维)。
- 时间特征:发布时间的小时、星期、是否为节假日(One-Hot编码)。
- 用户特征:粉丝数、认证类型(如“个人”“企业”“媒体”)。
- 模型架构:
- LSTM:处理时间序列特征(如历史热度)。
- GCN:建模用户关系图(如“用户A关注用户B”)。
- Attention机制:动态融合多模态特征(如赋予文本特征更高权重当话题为新兴事件时)。
- 输入特征:
- 实时预测:
- 通过Flink实时计算微博传播链(如“用户A→用户B→用户C”),触发预测模型更新(延迟<5秒)。
- 多模态预测模型:
- Web层:
- Django后端:
- RESTful API:提供数据接口(如
/api/sentiment/返回情感分析结果)。 - 异步任务:使用Celery+RabbitMQ处理耗时操作(如模型训练、大规模数据导出)。
- RESTful API:提供数据接口(如
- 前端可视化:
- ECharts仪表盘:展示舆情概览(如总微博数、情感分布、话题TOP10)。
- 动态地图:标记舆情发生地(如“#地震#”相关微博的地理位置热力图)。
- 预警系统:当预测热度超过阈值(如“负面情感占比>70%”)时,通过邮件/短信通知管理员。
- Django后端:
- 数据层:
四、研究方法与技术路线
- 研究方法
- 实验法:在真实微博数据集(如Weibo-2022)上对比BERT、BiLSTM+Attention、混合模型的性能,以F1值(兼顾精确率和召回率)为指标。
- 系统开发法:基于Python 3.9、Django 4.2、PyTorch 2.0构建系统,验证在阿里云ECS(4核8G)上的并发处理能力(如支持1000用户同时访问)。
- 技术路线
mermaidgraph TDA[多模态数据采集] --> B[MySQL/MongoDB/Redis存储]B --> C[BERT+BiLSTM情感分析]C --> D[BERTopic话题检测]D --> E[LSTM+GCN+Attention预测模型]E --> F[Flink实时计算]F --> G[Django后端API]G --> H[ECharts/Pyecharts可视化]
五、预期成果与创新点
- 预期成果
- 完成系统开发,实现情感分析准确率≥88%,预测MAPE≤12%,支持500用户并发访问。
- 发表1篇EI会议论文(目标会议:ICWSM),申请1项软件著作权。
- 创新点
- 技术融合创新:首次将BERTopic动态话题检测与LSTM+GCN+Attention预测模型结合,解决传统方法话题更新滞后的问题。
- 场景创新:设计“舆情预警-根源分析-对策推荐”闭环流程(如预测到“#某品牌质量问题#”热度上升时,自动推荐“召回产品+CEO道歉”策略)。
- 交互创新:实现“地图+图表+微博列表”三联动,支持用户通过点击地图区域动态过滤相关微博(如查看“北京市”的负面舆情)。
六、进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 1 | 1-2月 | 文献调研与需求分析,搭建Django开发环境 |
| 2 | 3-4月 | 数据采集与清洗,构建MySQL/MongoDB数据库 |
| 3 | 5-6月 | 情感分析与话题检测模型开发,完成离线分析模块 |
| 4 | 7-8月 | 预测模型与实时计算模块开发,撰写论文初稿 |
| 5 | 9-10月 | 系统测试与优化,论文修改与答辩准备 |
七、参考文献
[1] Devlin J, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[J]. NAACL, 2019.
[2] Grootendorst M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure[J]. arXiv, 2022.
[3] 微博开发平台. 微博开放API文档[EB/OL]. https://open.weibo.com/wiki/API%E6%96%87%E6%A1%A3, 2023.
[4] Django Documentation[EB/OL]. https://docs.djangoproject.com/en/4.2/, 2023.
[5] 清华大学. 微博舆情分析报告[R]. 北京, 2023.
八、指导教师意见
(待填写)
备注:
- 若微博API访问受限,可优先使用公开数据集(如Weibo-2022)或模拟生成数据。
- 建议重点突破数据质量治理问题(如通过规则引擎过滤广告微博“转发抽奖”)。
- 可引入联邦学习框架,在保护用户隐私的前提下联合多个微博账号数据训练模型。
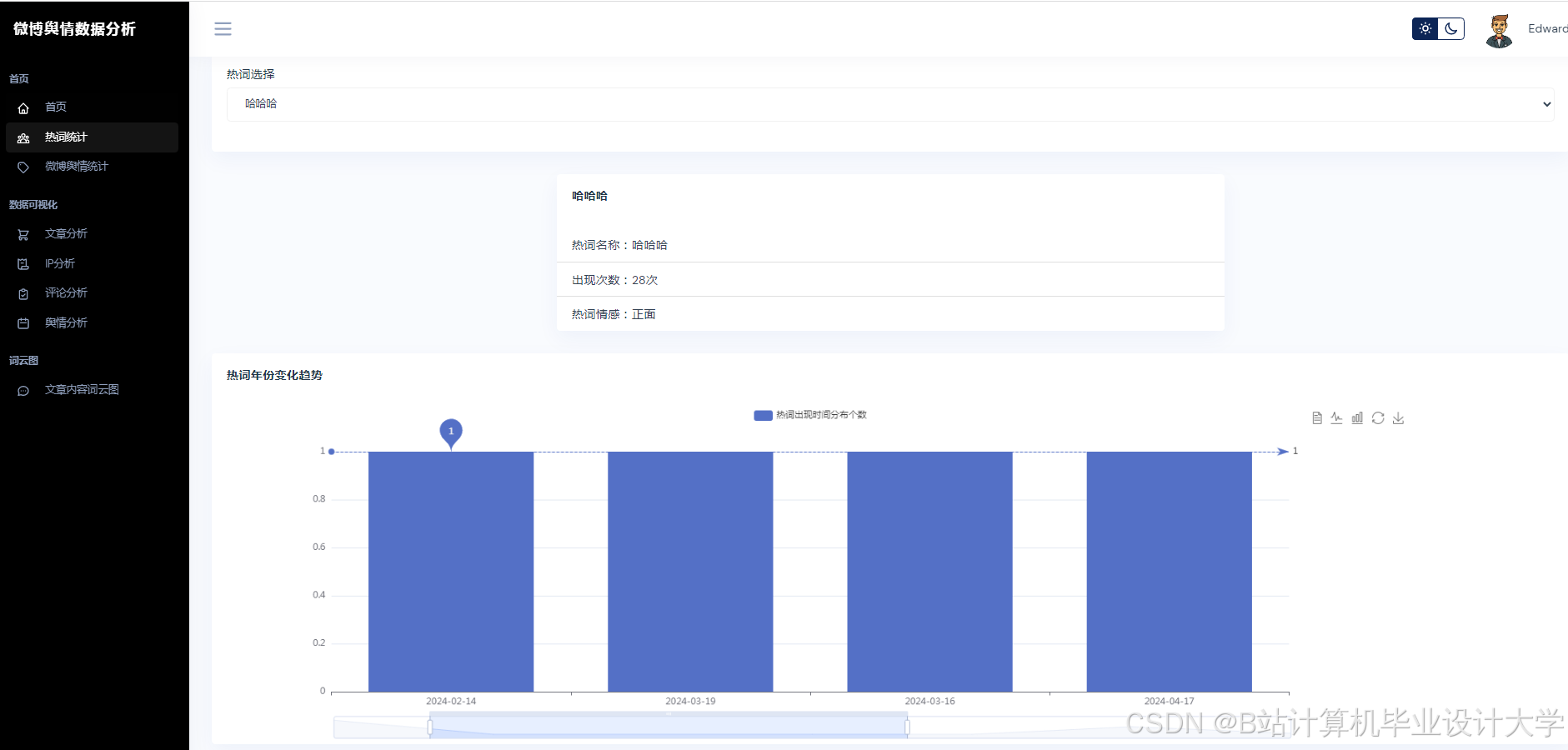
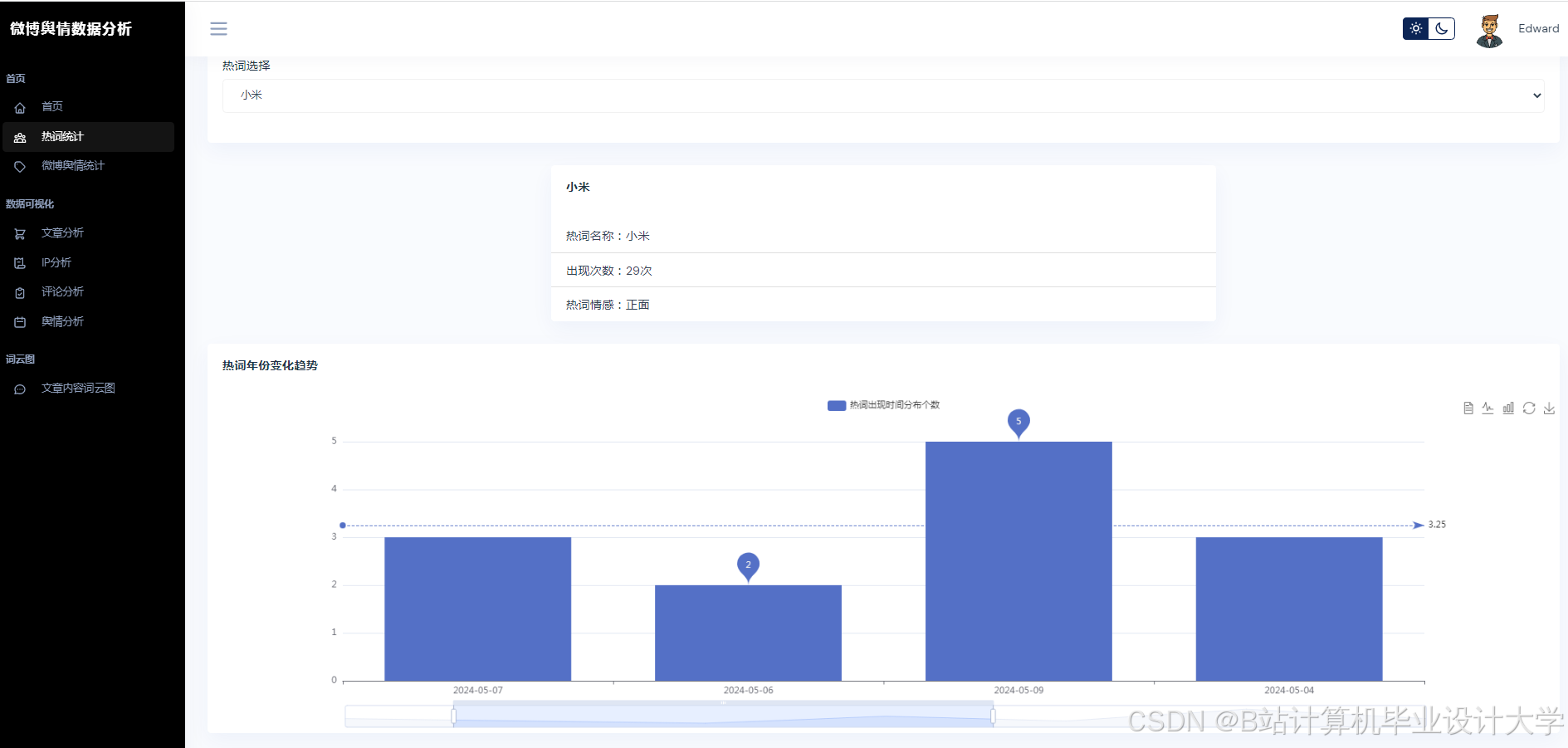
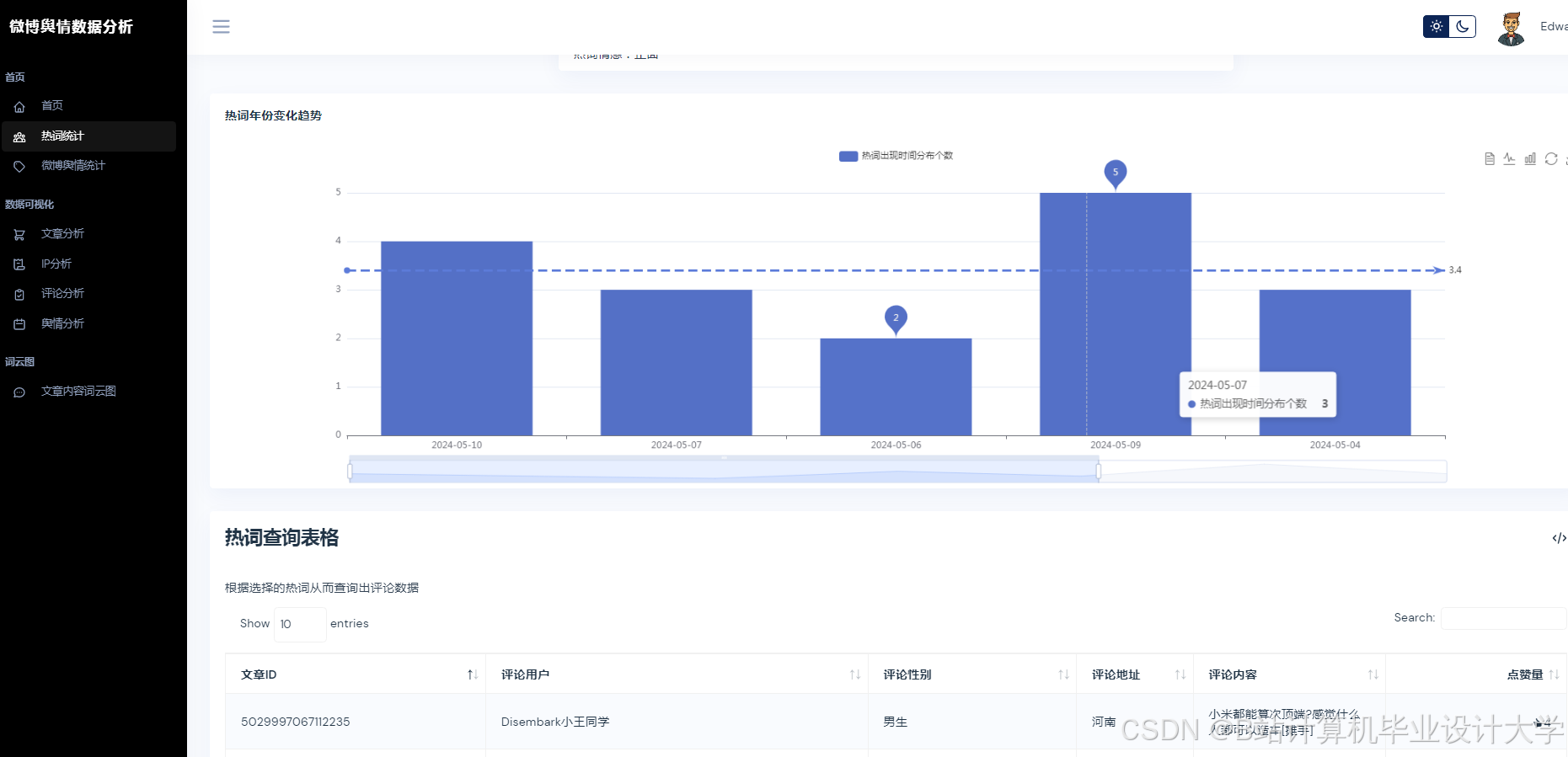
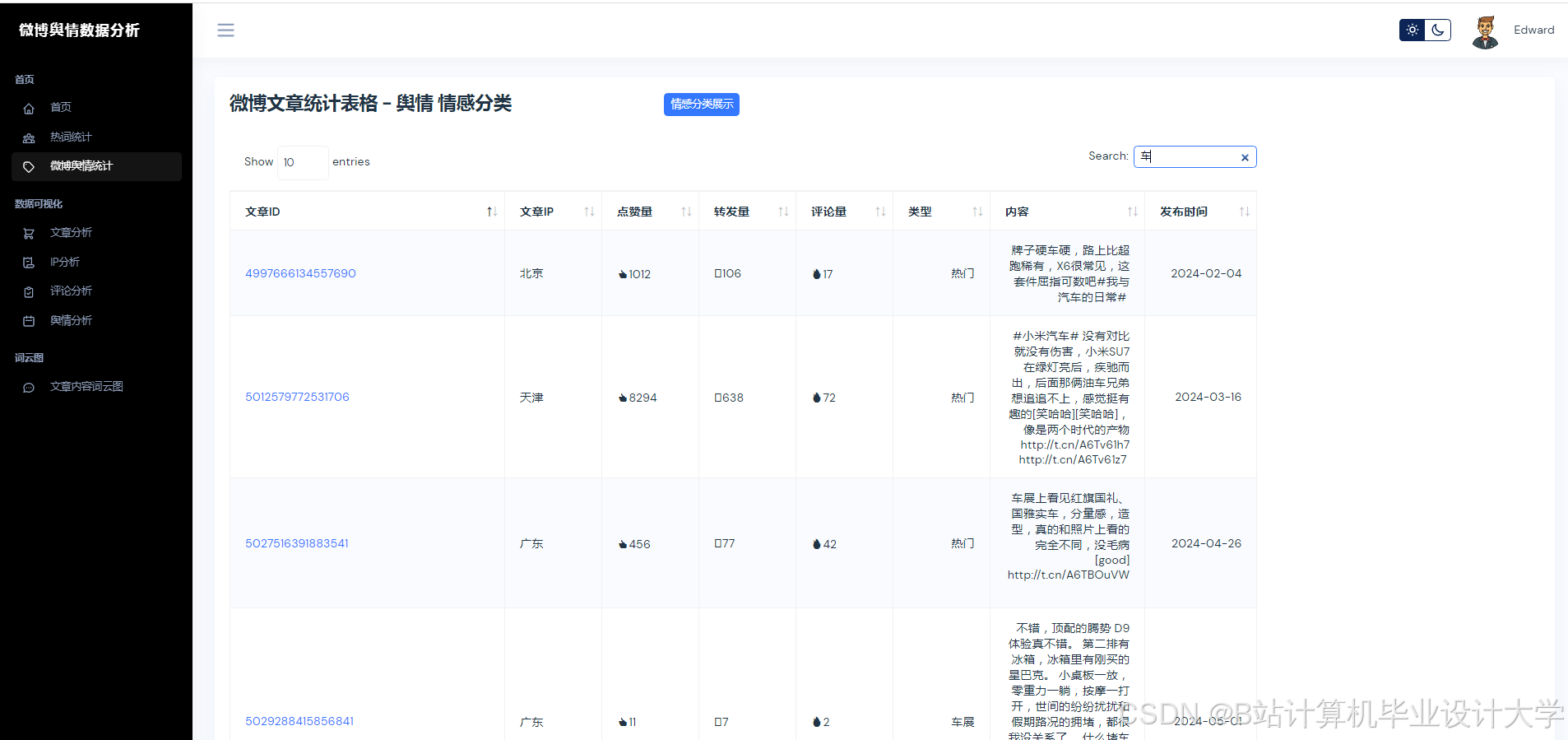
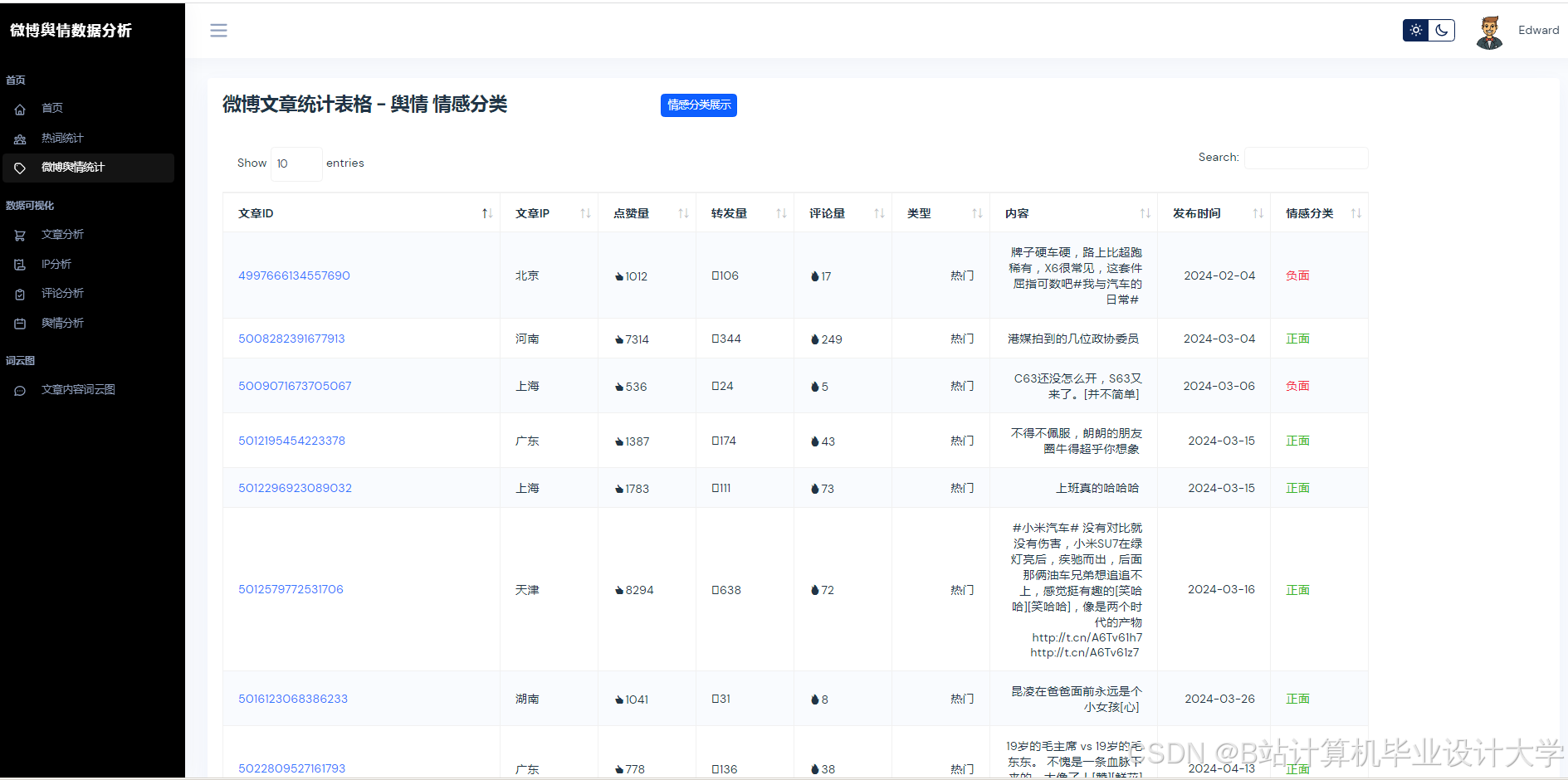
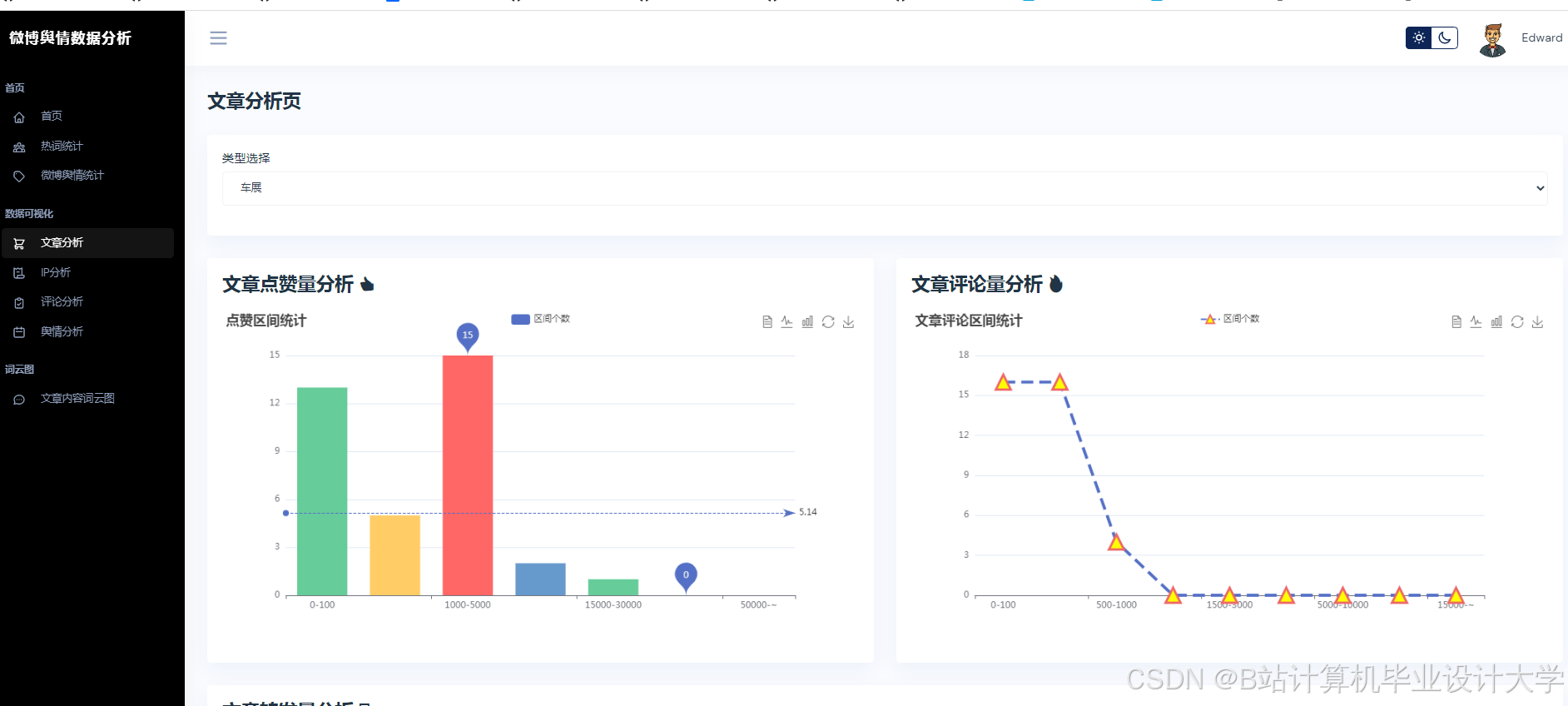
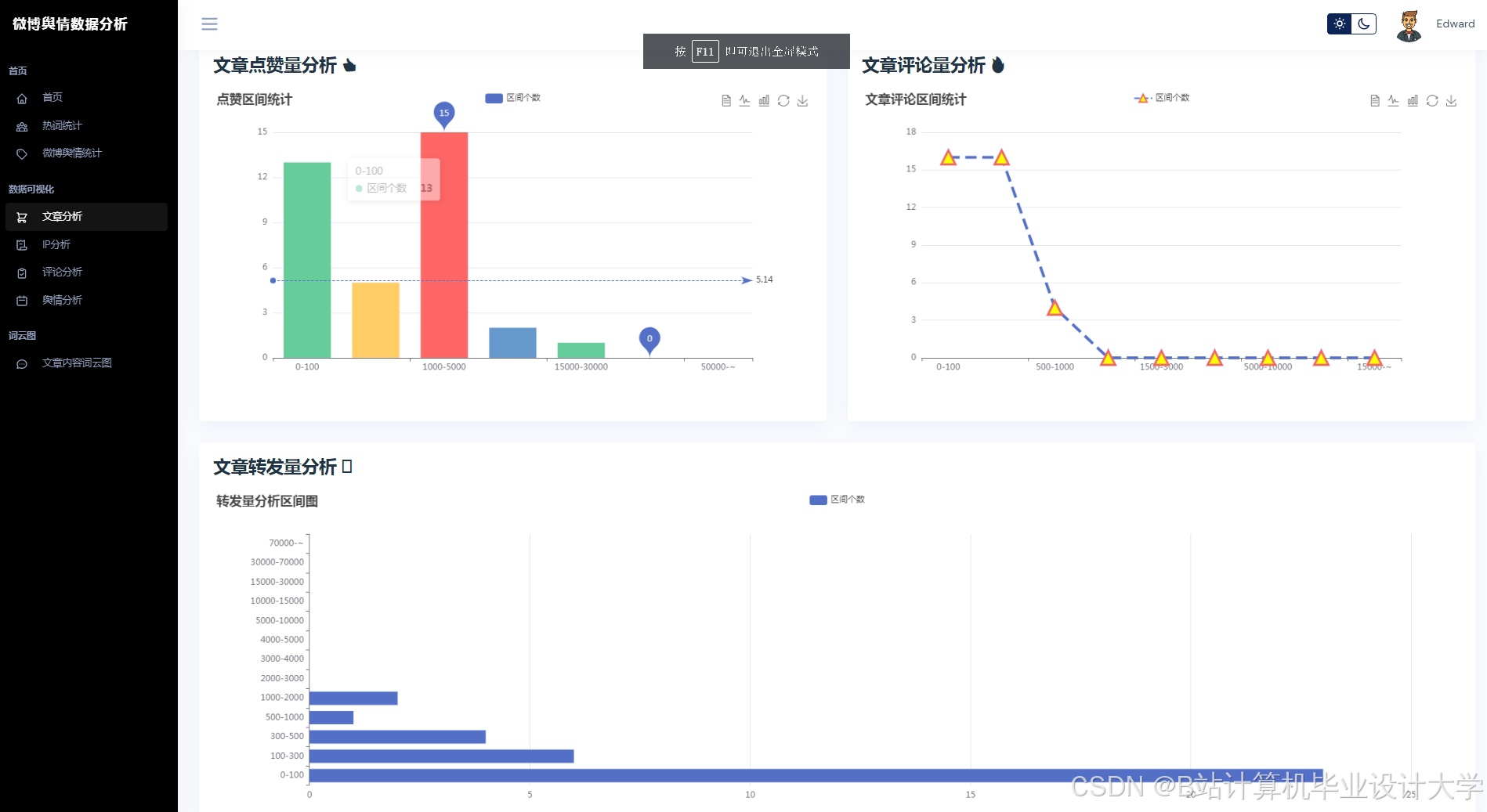
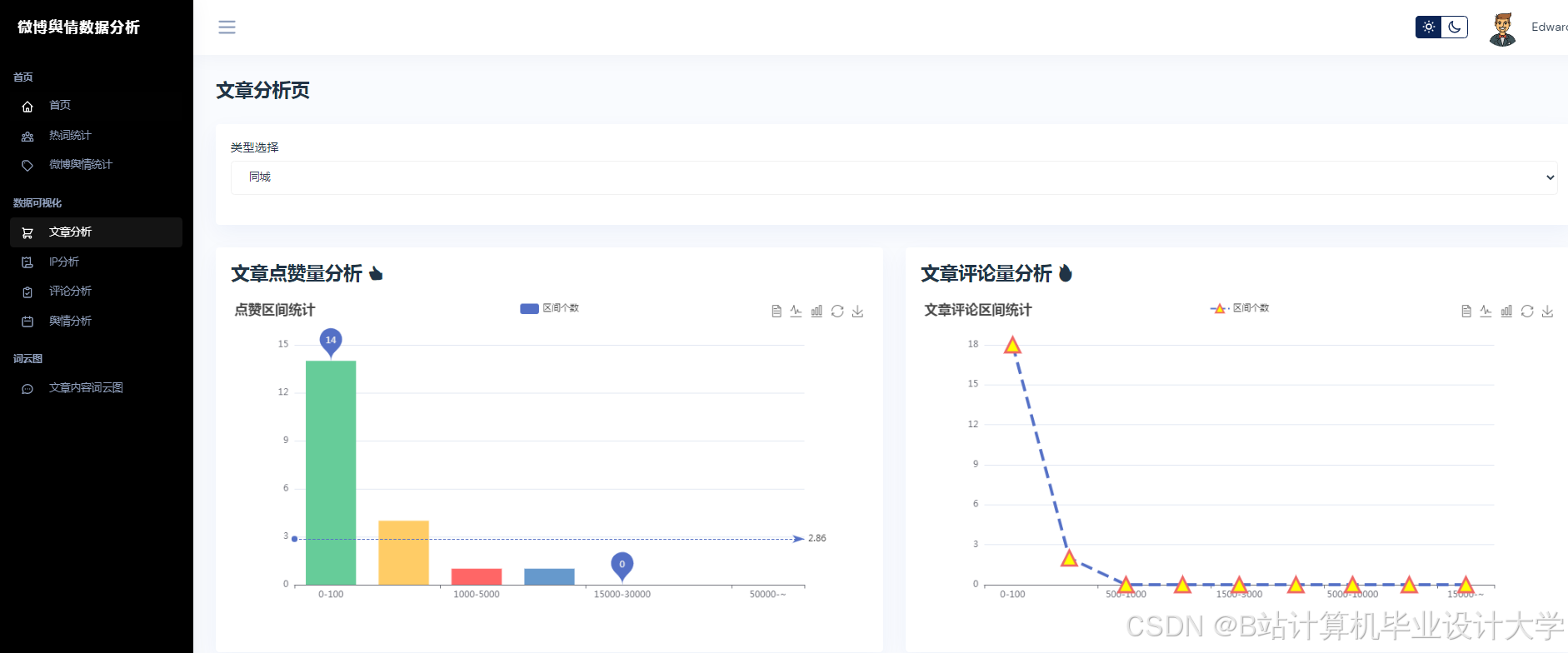
运行截图
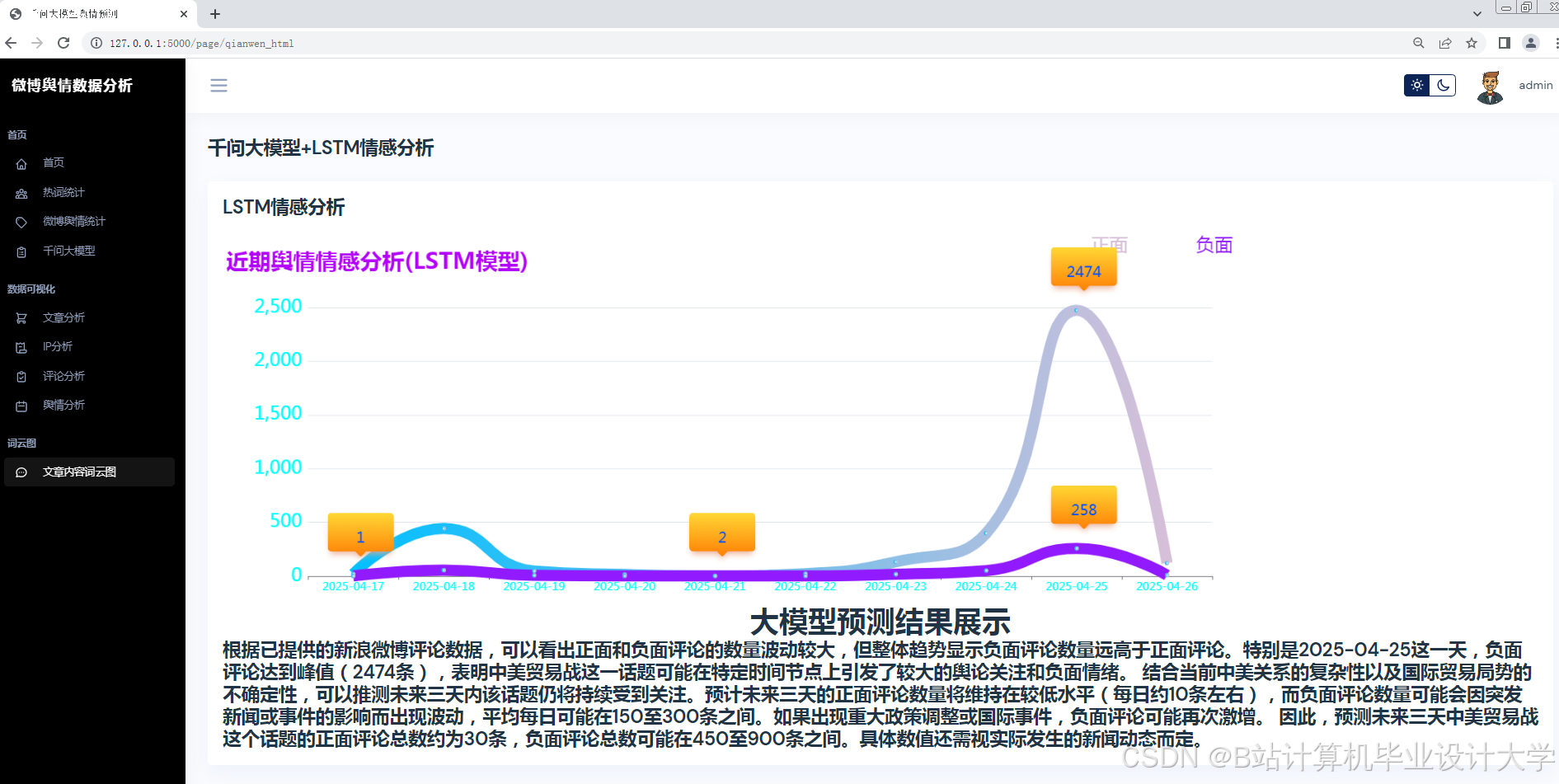
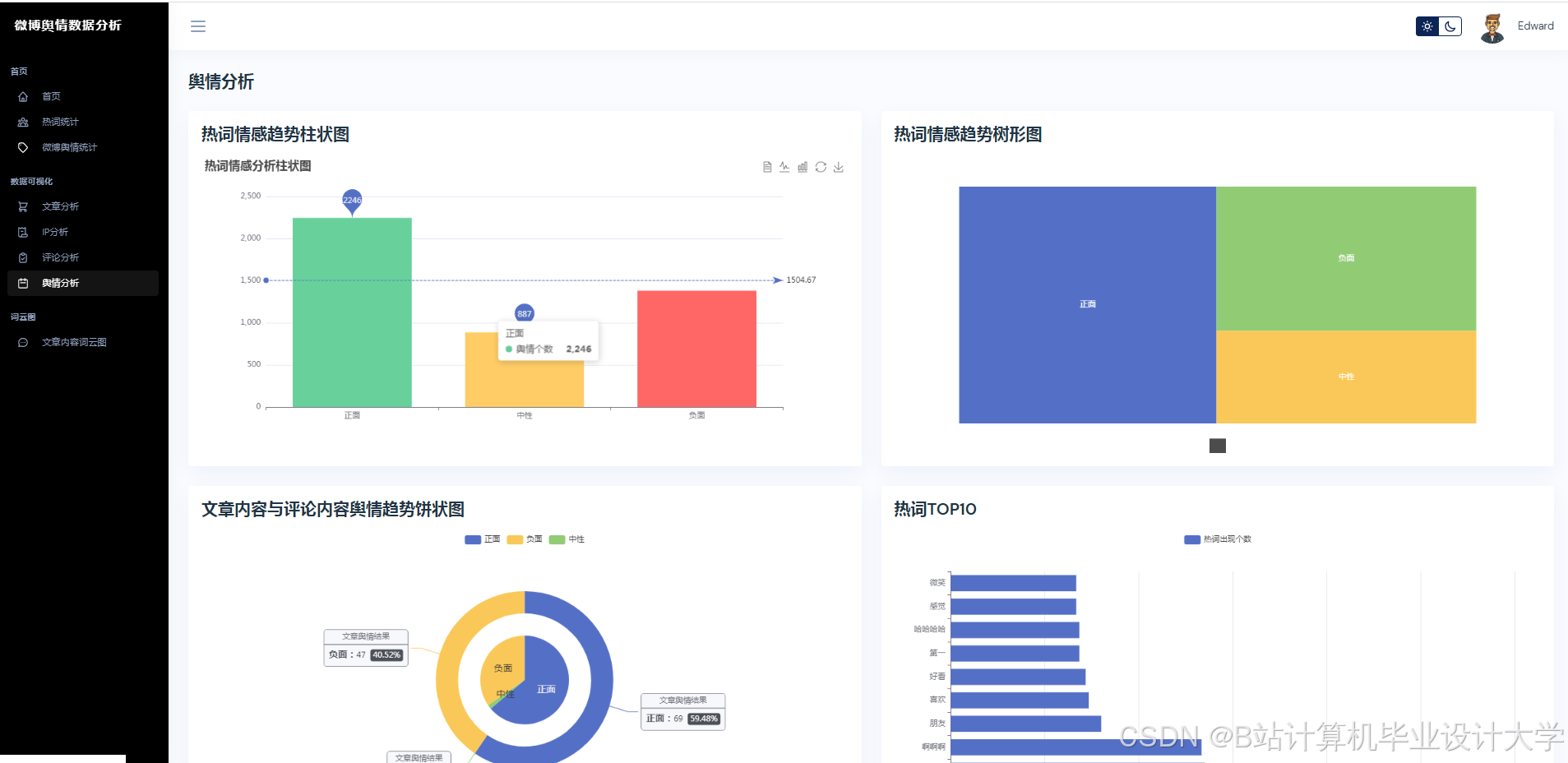
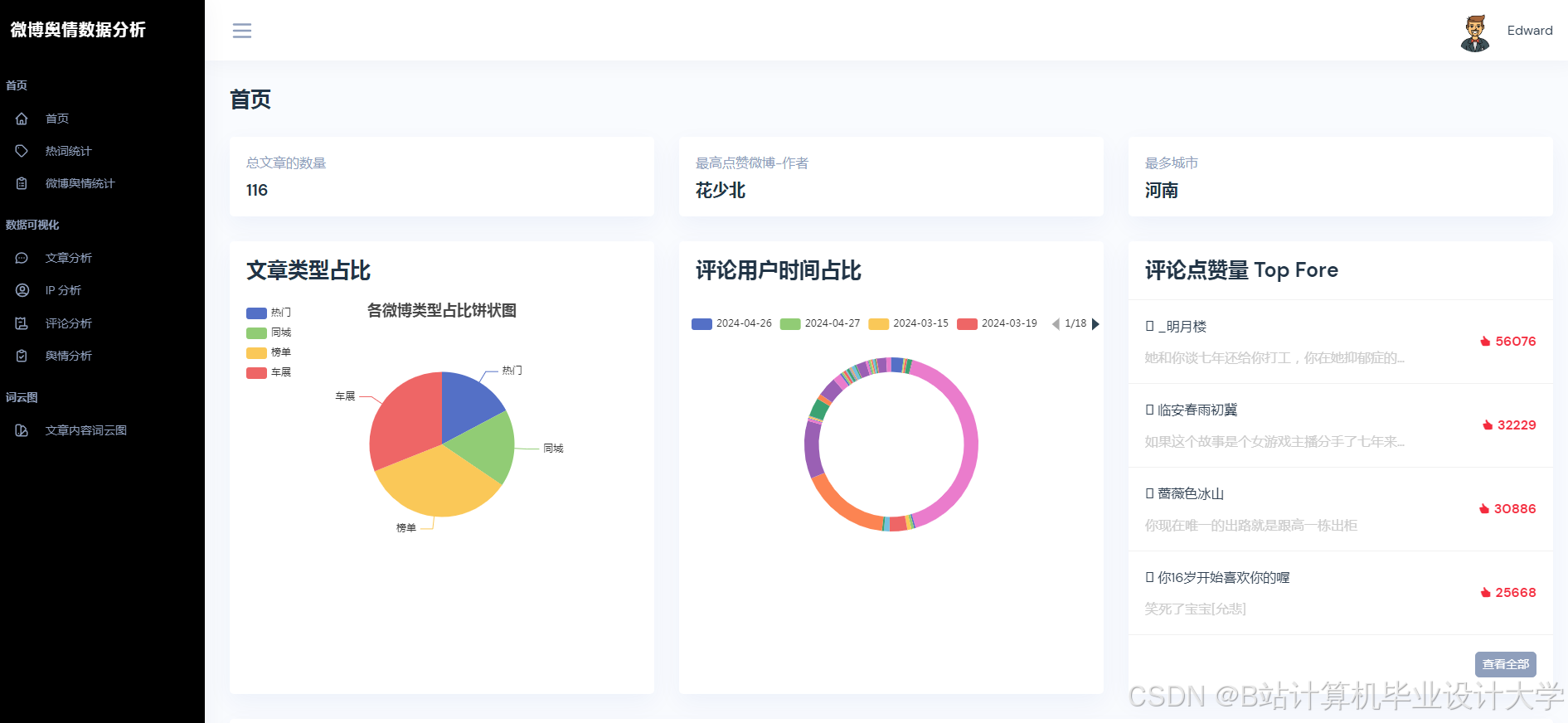
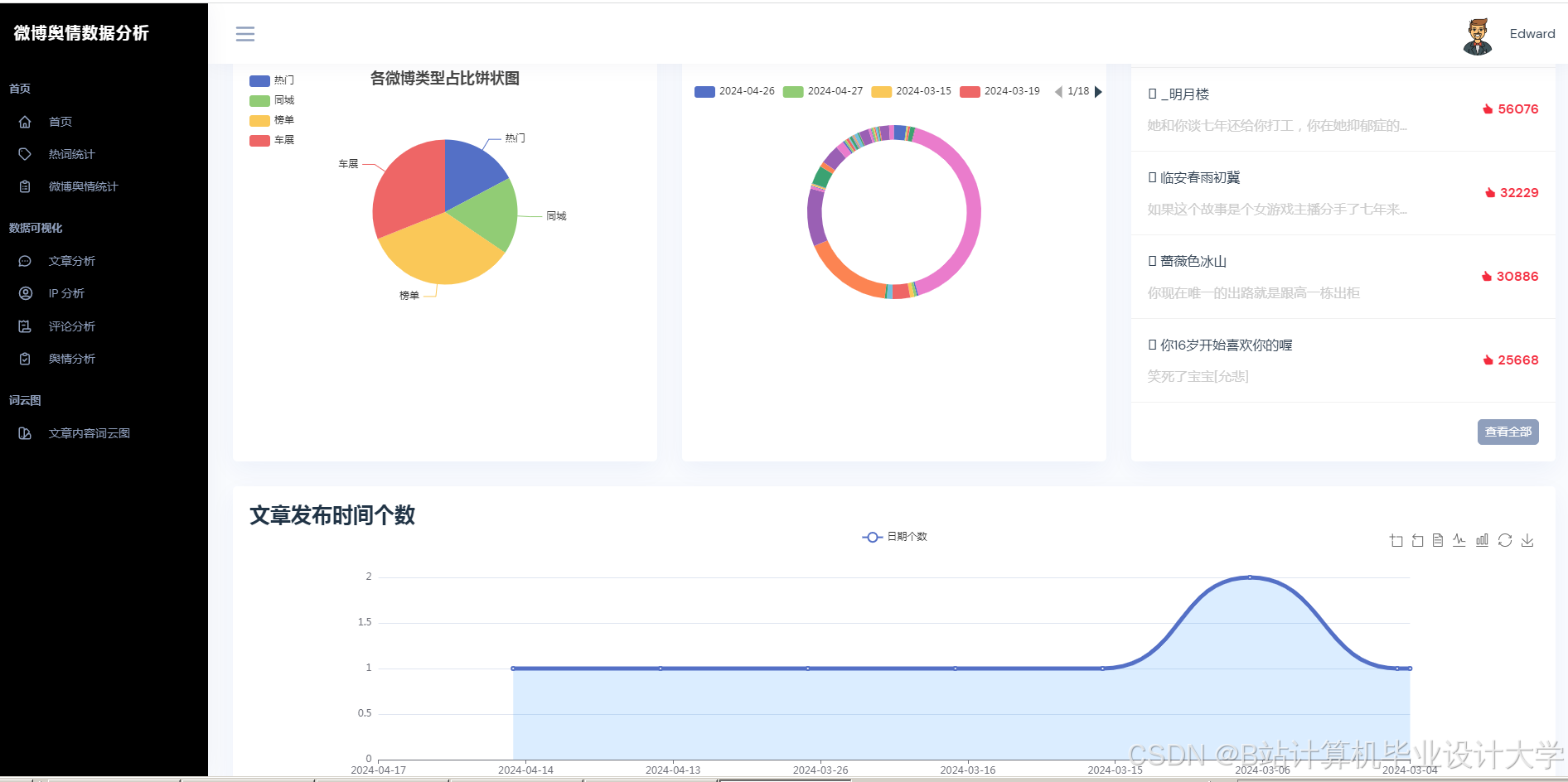

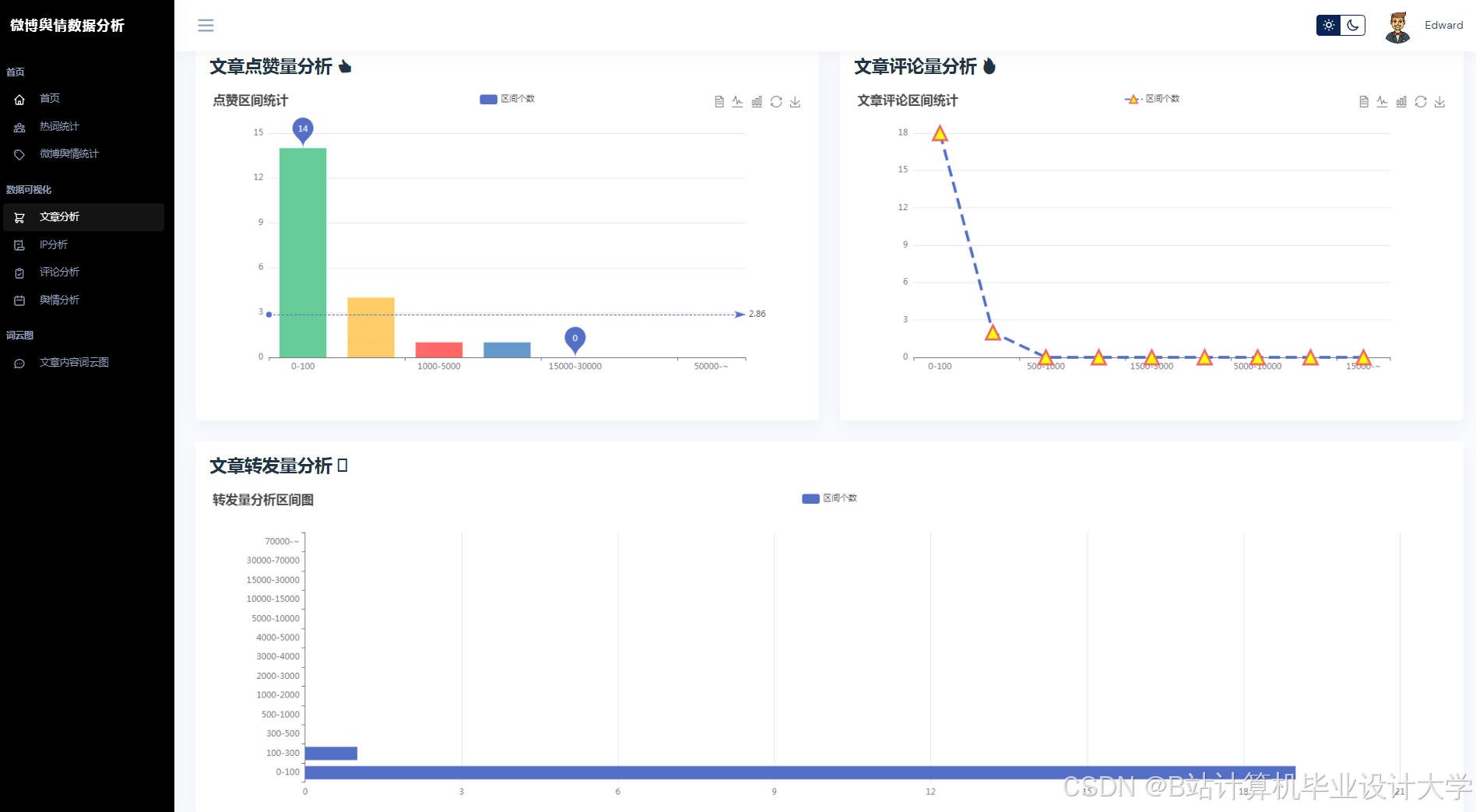
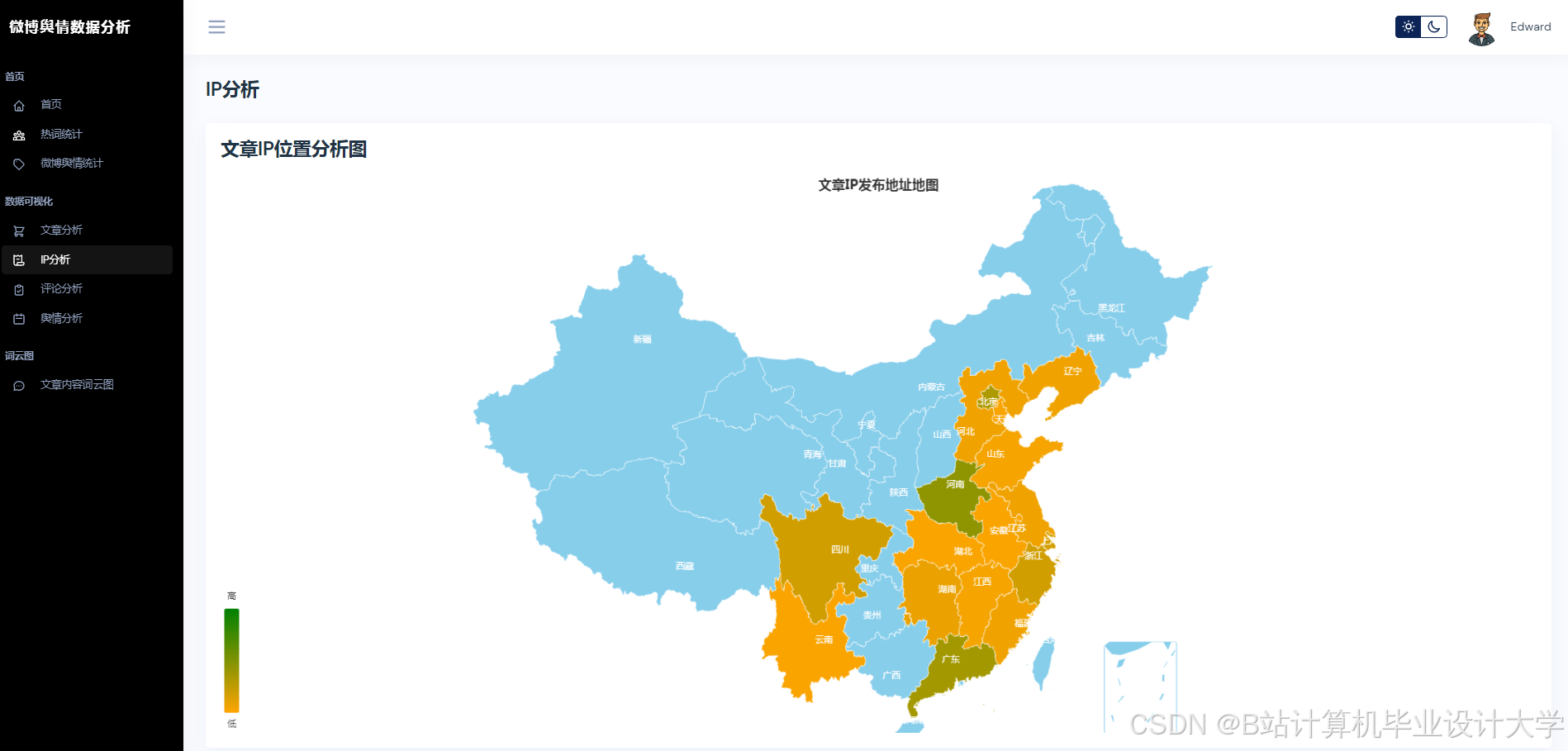
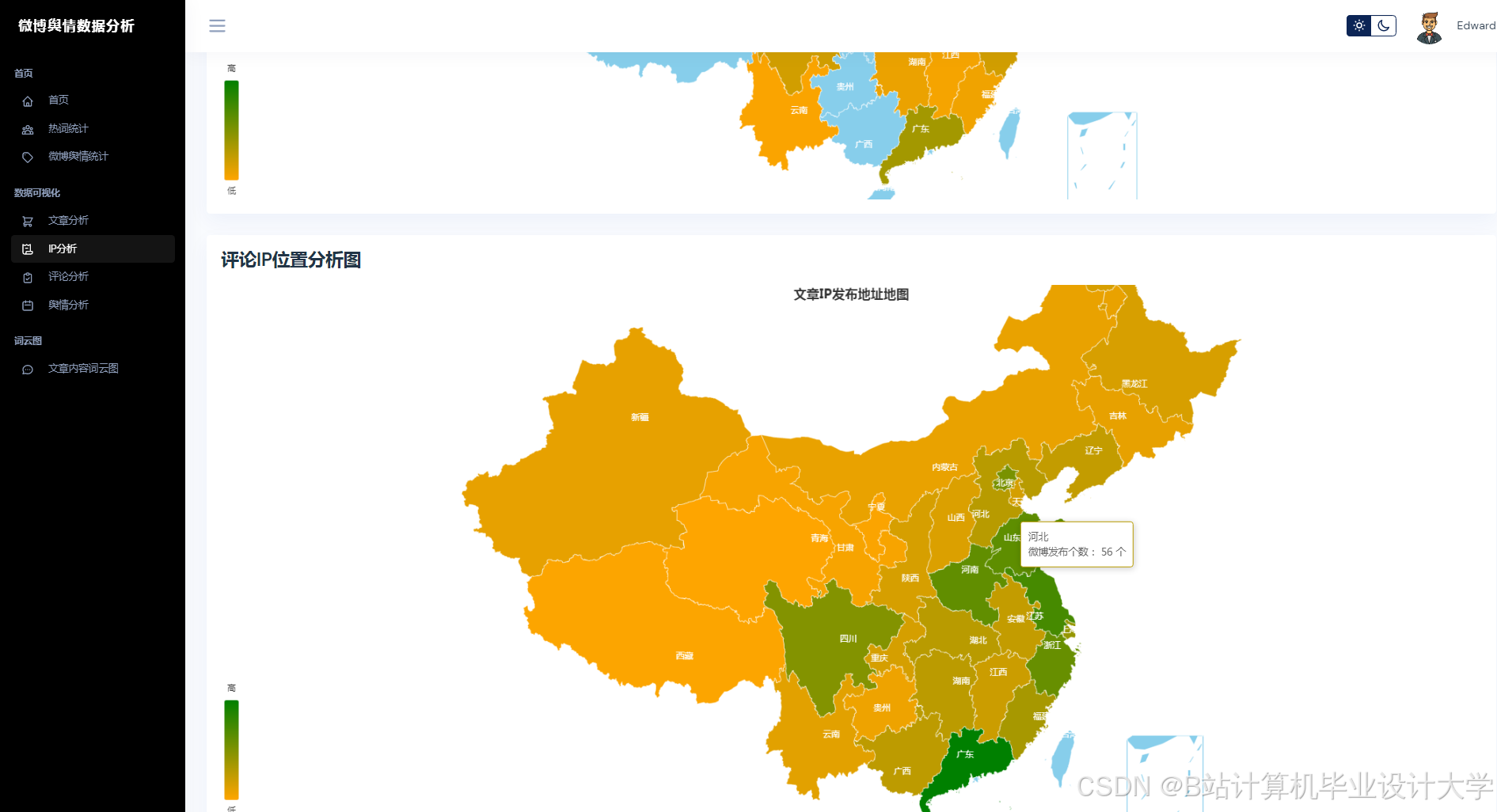
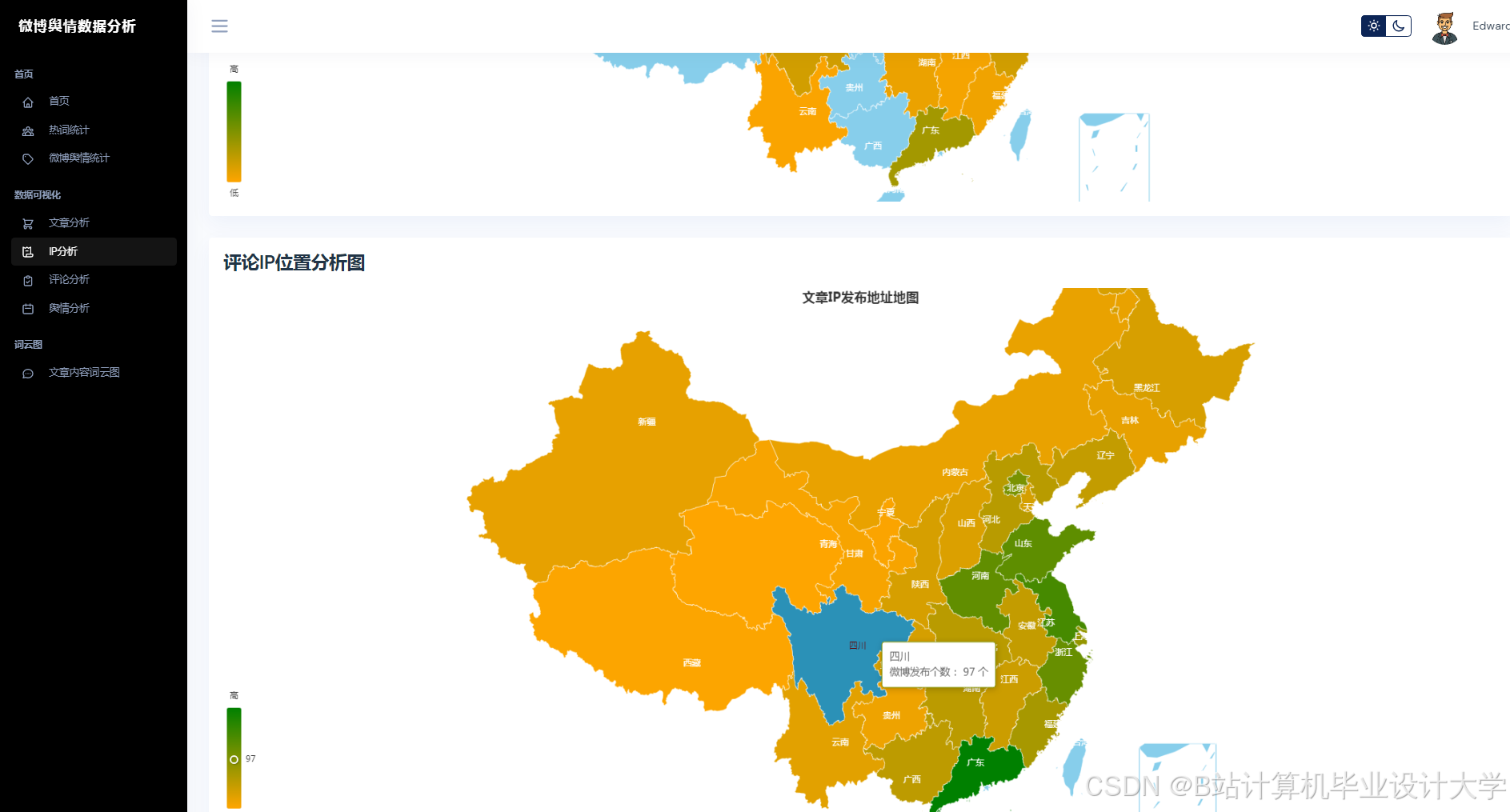

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











