




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive酒店推荐系统与可视化技术说明
一、项目概述
在旅游行业数字化转型背景下,本系统基于Hadoop大数据生态构建酒店推荐引擎,结合Spark内存计算实现实时推荐,并通过Hive数据仓库管理多源异构数据,最终通过可视化技术(如ECharts、Superset)直观展示推荐结果与酒店运营指标。系统核心目标包括:
- 精准推荐:根据用户历史行为、偏好及实时上下文(如时间、位置)生成个性化酒店列表。
- 运营洞察:通过可视化面板监控酒店预订率、用户满意度等关键指标,辅助决策。
- 高并发支持:应对旅游旺季(如节假日)的百万级日活用户请求,推荐响应时间<500ms。
二、技术架构设计
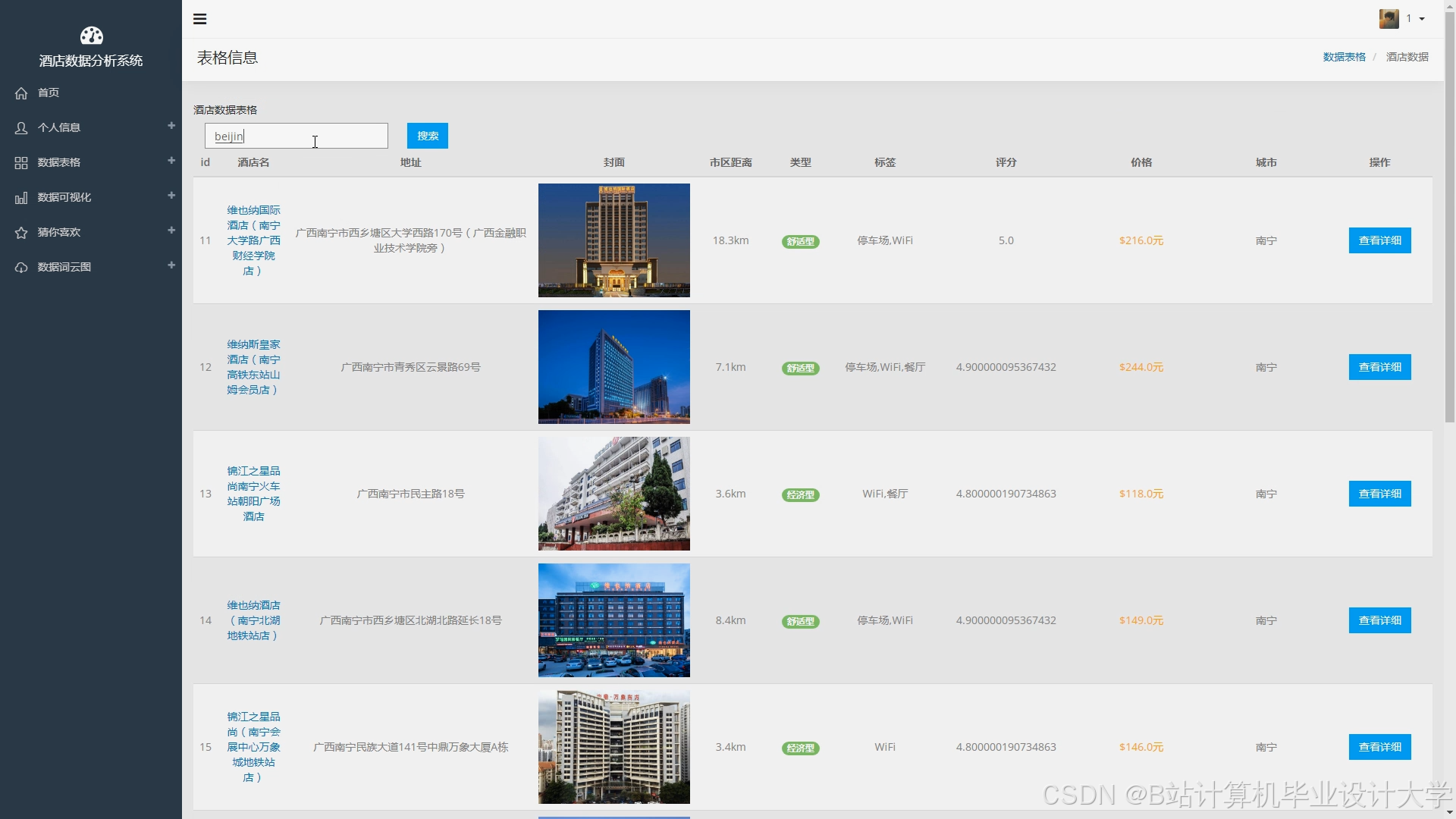
1. 数据存储层:Hadoop HDFS + Hive
1.1 多源数据整合
-
结构化数据:存储于Hive表,包括:
sql-- 用户画像表(含人口统计、偏好标签等)CREATE TABLE user_profile (user_id STRING,age INT,gender STRING,preferred_price_range STRING COMMENT '如"200-500"',preferred_amenities ARRAY<STRING> COMMENT '如["WiFi","游泳池"]',last_search_time TIMESTAMP) PARTITIONED BY (dt DATE) STORED AS ORC;-- 酒店特征表(含位置、价格、评分等)CREATE TABLE hotel_features (hotel_id STRING,name STRING,city STRING,district STRING,price DECIMAL(10,2),star_rating TINYINT,distance_to_center DOUBLE COMMENT '距市中心距离(km)',review_score DOUBLE COMMENT '用户评分(0-5)',amenities MAP<STRING,BOOLEAN> COMMENT '设施字典,如{"WiFi":true}') STORED AS PARQUET;-- 实时行为日志表(用于流处理)CREATE TABLE user_behavior_logs (log_id STRING,user_id STRING,event_type STRING COMMENT '如"search","click","book"',hotel_id STRING,event_time TIMESTAMP,search_keywords STRING COMMENT '用户搜索关键词(如"商务酒店")') STORED AS AVRO; -
非结构化数据:酒店图片、用户评论文本存储于HDFS,通过Hive外部表关联:
sqlCREATE EXTERNAL TABLE hotel_images (hotel_id STRING,image_path STRING COMMENT 'HDFS路径,如/data/images/hotel1.jpg',is_main BOOLEAN COMMENT '是否主图') ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/user/hive/warehouse/hotel_images';
1.2 数据分区与优化
- 时间分区:对
user_behavior_logs按dt字段每日分区,加速历史数据查询。 - 索引加速:在Hive中为
hotel_id、user_id等高频查询字段创建索引:sqlCREATE INDEX hotel_id_index ON TABLE hotel_features (hotel_id) AS 'COMPACT' WITH DEFERRED REBUILD;
2. 数据处理层:Spark批流一体计算
2.1 离线处理(特征工程与模型训练)
-
特征提取:使用Spark SQL计算用户与酒店的统计特征:
scalaimport org.apache.spark.sql.functions._// 计算用户历史预订酒店的平均价格val userAvgPrice = spark.sql("""SELECTuser_id,AVG(price) as avg_booked_priceFROM user_behavior_logs lJOIN hotel_features h ON l.hotel_id = h.hotel_idWHERE l.event_type = 'book'GROUP BY user_id""")// 计算酒店热门度(基于预订量)val hotelPopularity = spark.sql("""SELECTh.hotel_id,COUNT(*) as book_count,RANK() OVER (ORDER BY COUNT(*) DESC) as popularity_rankFROM user_behavior_logs lJOIN hotel_features h ON l.hotel_id = h.hotel_idWHERE l.event_type = 'book'GROUP BY h.hotel_id""") -
模型训练:基于Spark MLlib实现协同过滤推荐:
scalaimport org.apache.spark.ml.recommendation.ALS// 加载用户-酒店评分数据(隐式反馈:点击=1,预订=5)val ratings = spark.sql("""SELECTuser_id,hotel_id,CASE event_type WHEN 'book' THEN 5 WHEN 'click' THEN 1 ELSE 0 END as ratingFROM user_behavior_logsWHERE event_type IN ('click', 'book')""").filter(col("rating") > 0)// 训练ALS模型val als = new ALS().setMaxIter(10).setRegParam(0.01).setUserCol("user_id").setItemCol("hotel_id").setRatingCol("rating").setColdStartStrategy("drop")val model = als.fit(ratings)// 为每个用户生成Top 10推荐酒店val userIds = ratings.select("user_id").distinct().rdd.map(row => row.getString(0))val recommendations = model.recommendForUserSubset(userIds, 10)recommendations.write.mode("overwrite").parquet("hdfs://namenode:8020/output/hotel_recommendations")
2.2 实时处理(上下文感知推荐)
- 流处理逻辑:使用Spark Structured Streaming处理用户实时行为,动态调整推荐权重:
scalaimport org.apache.spark.sql.streaming.Trigger// 从Kafka消费实时日志val kafkaDf = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "kafka1:9092,kafka2:9092").option("subscribe", "user_behavior").load()// 解析JSON日志并提取关键字段val parsedLogs = kafkaDf.selectExpr("CAST(value AS STRING)").as[String].map(json => {val parser = new org.json4s.jackson.JsonMethods.parse(_)// 提取user_id, event_type, hotel_id等字段// ...}).toDF("user_id", "event_type", "hotel_id", "timestamp")// 实时计算用户当前搜索关键词的热门酒店(如"亲子酒店")val realtimeHotels = parsedLogs.filter(col("event_type") === "search").groupBy(window($"timestamp", "10 minutes"), $"search_keywords").agg(count("*").alias("search_count")).orderBy(desc("search_count"))// 输出到控制台(实际可写入Redis供推荐系统调用)val query = realtimeHotHotels.writeStream.outputMode("complete").format("console").trigger(Trigger.ProcessingTime("30 seconds")).start()
3. 推荐引擎层:混合推荐策略
3.1 策略组合
| 策略类型 | 实现方式 | 权重 | 适用场景 |
|---|---|---|---|
| 协同过滤 | ALS模型生成的用户-酒店相似度 | 0.6 | 历史行为数据丰富时 |
| 内容过滤 | 基于酒店设施、位置的规则匹配 | 0.3 | 新用户或冷启动场景 |
| 实时上下文 | 根据当前搜索关键词、时间动态调整 | 0.1 | 短期热点需求(如节假日) |
3.2 冷启动解决方案
- 新用户:通过注册问卷(如出行目的、预算)初始化偏好,匹配相似用户的历史推荐。
- 新酒店:利用NLP提取酒店描述中的关键词(如"海景""商务中心"),关联到相似特征酒店。
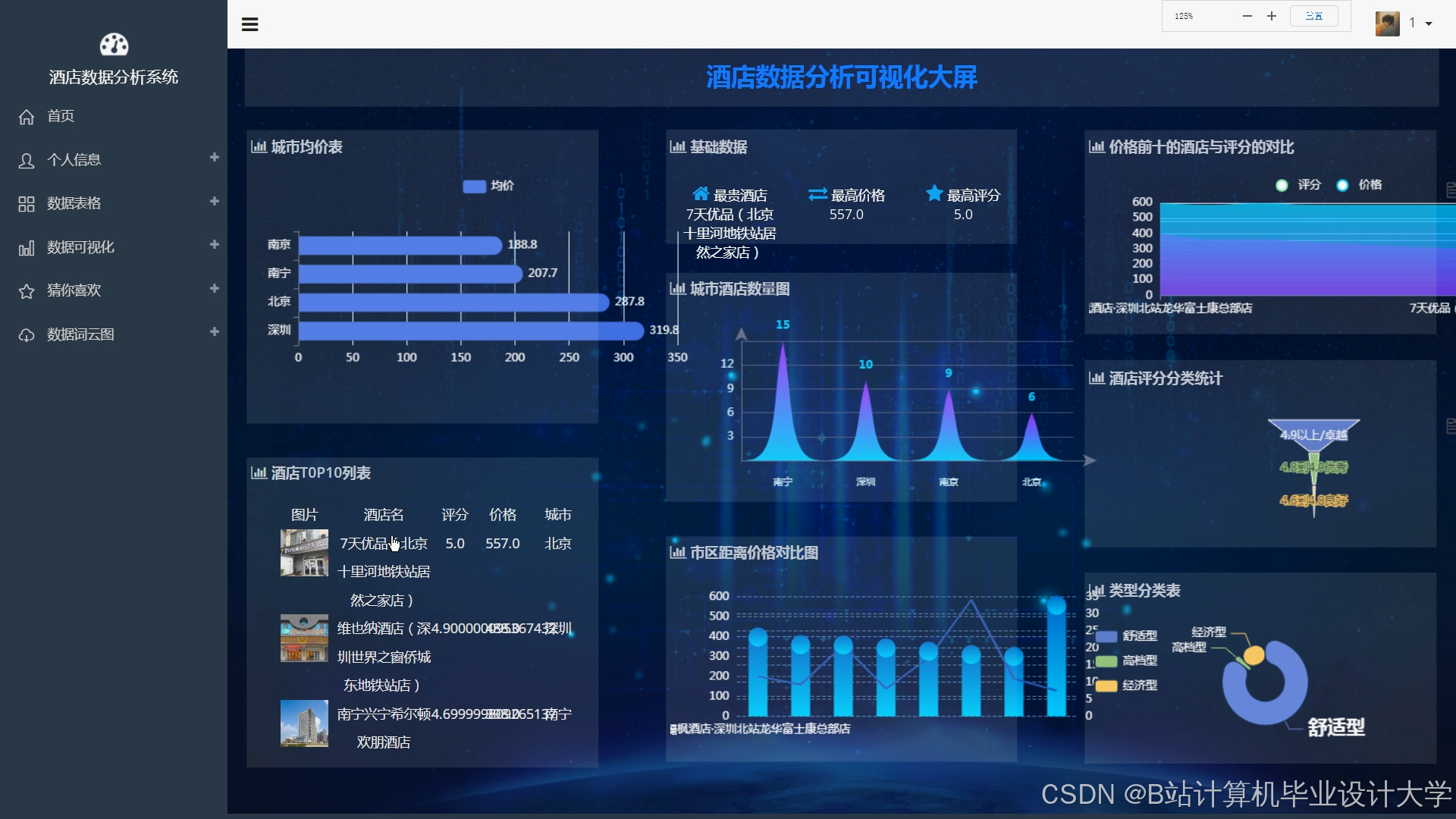
4. 可视化层:交互式数据分析
4.1 可视化工具选型
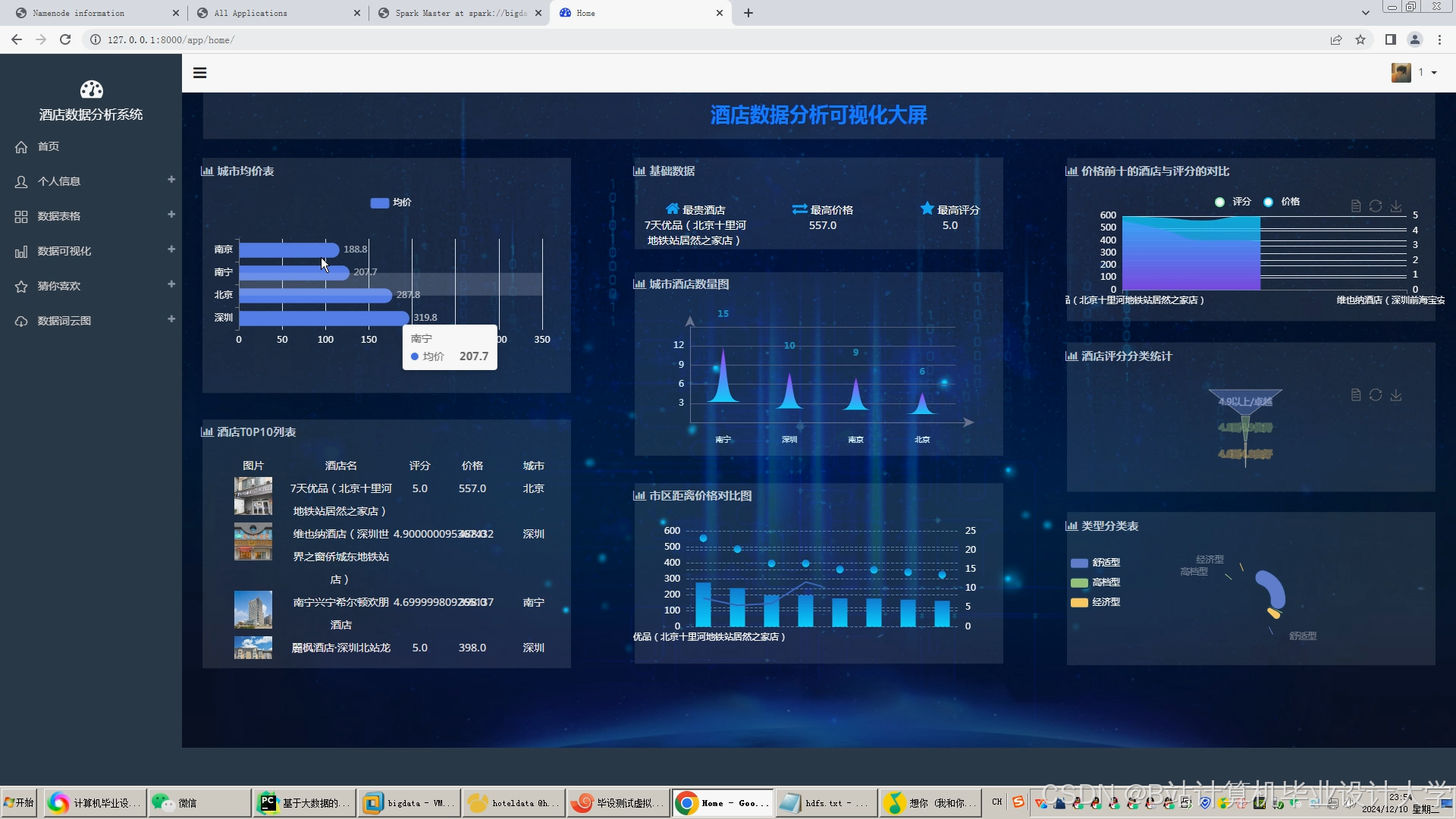
- Superset:用于构建酒店运营监控大屏,支持SQL查询直连Hive数据源。
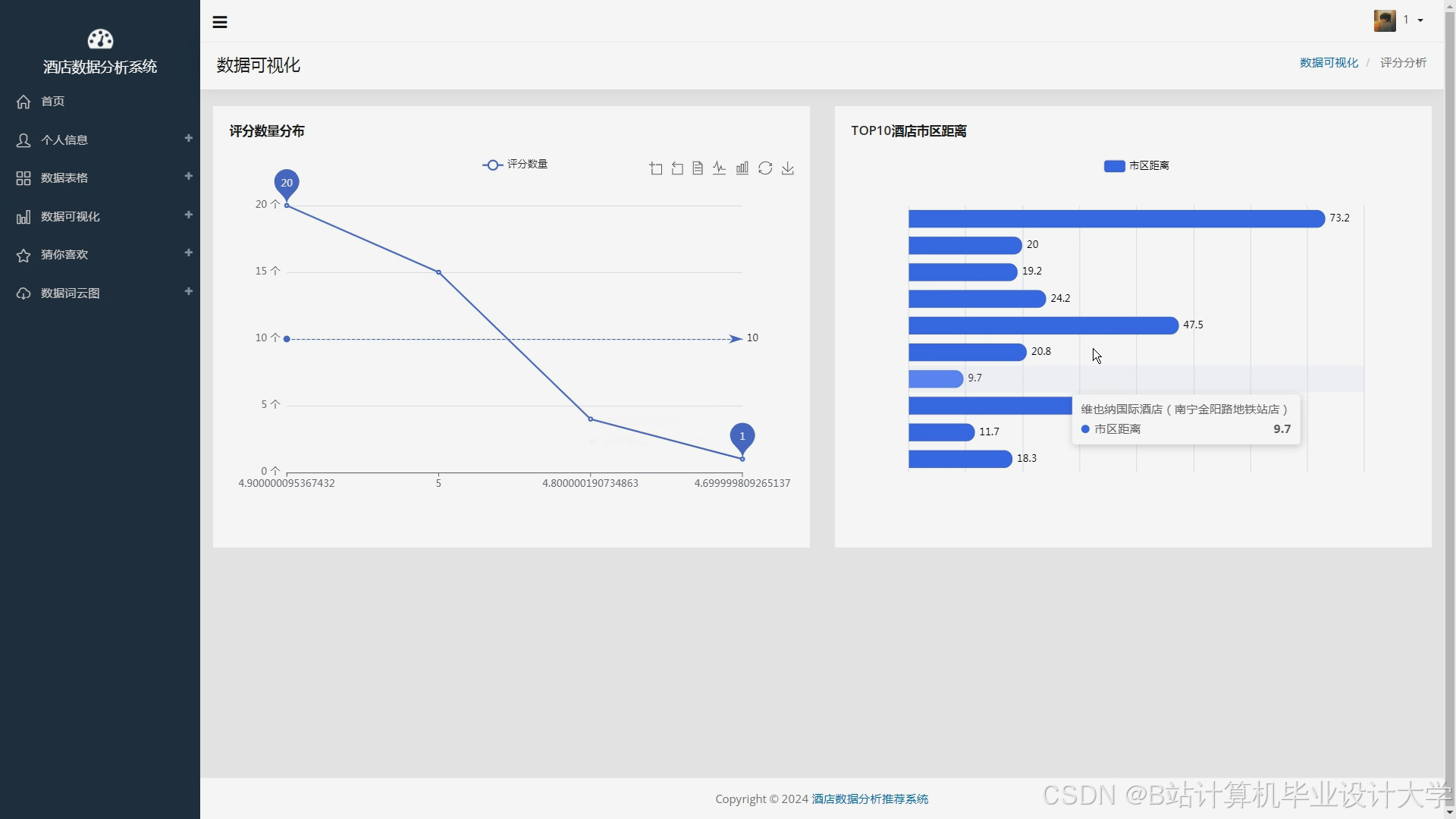
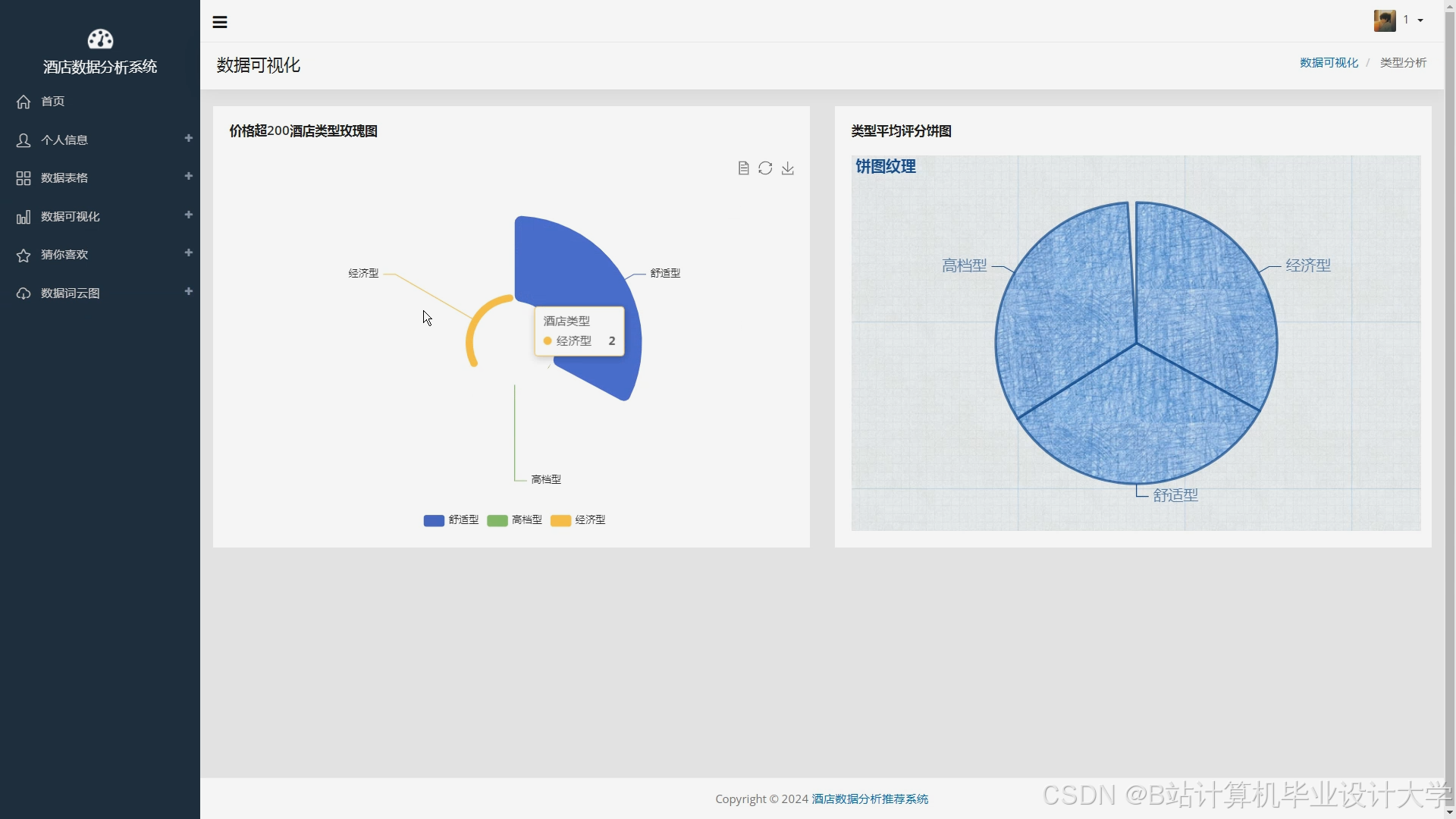
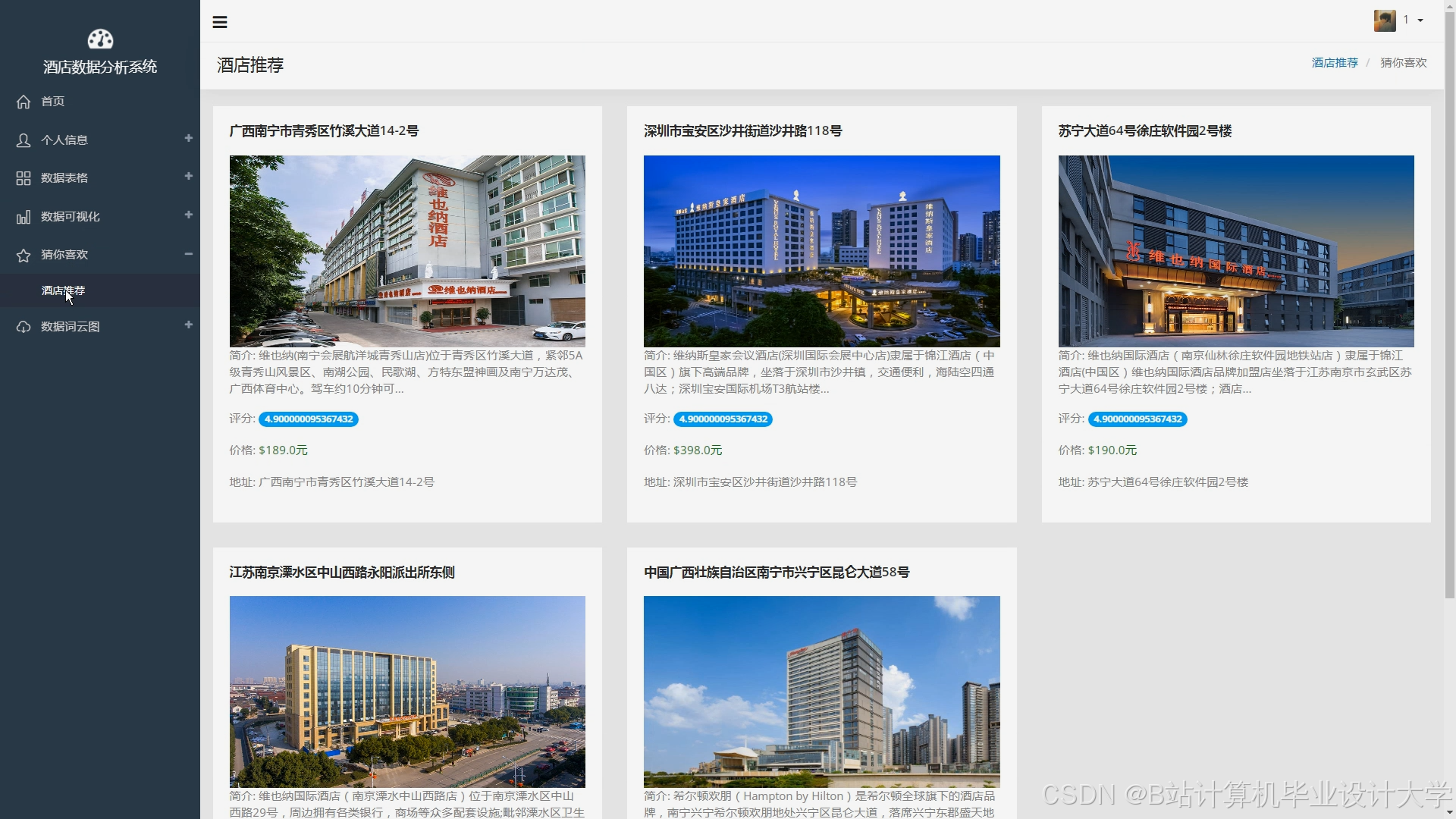
- ECharts:嵌入推荐系统Web页面,动态展示推荐酒店列表及评分分布。
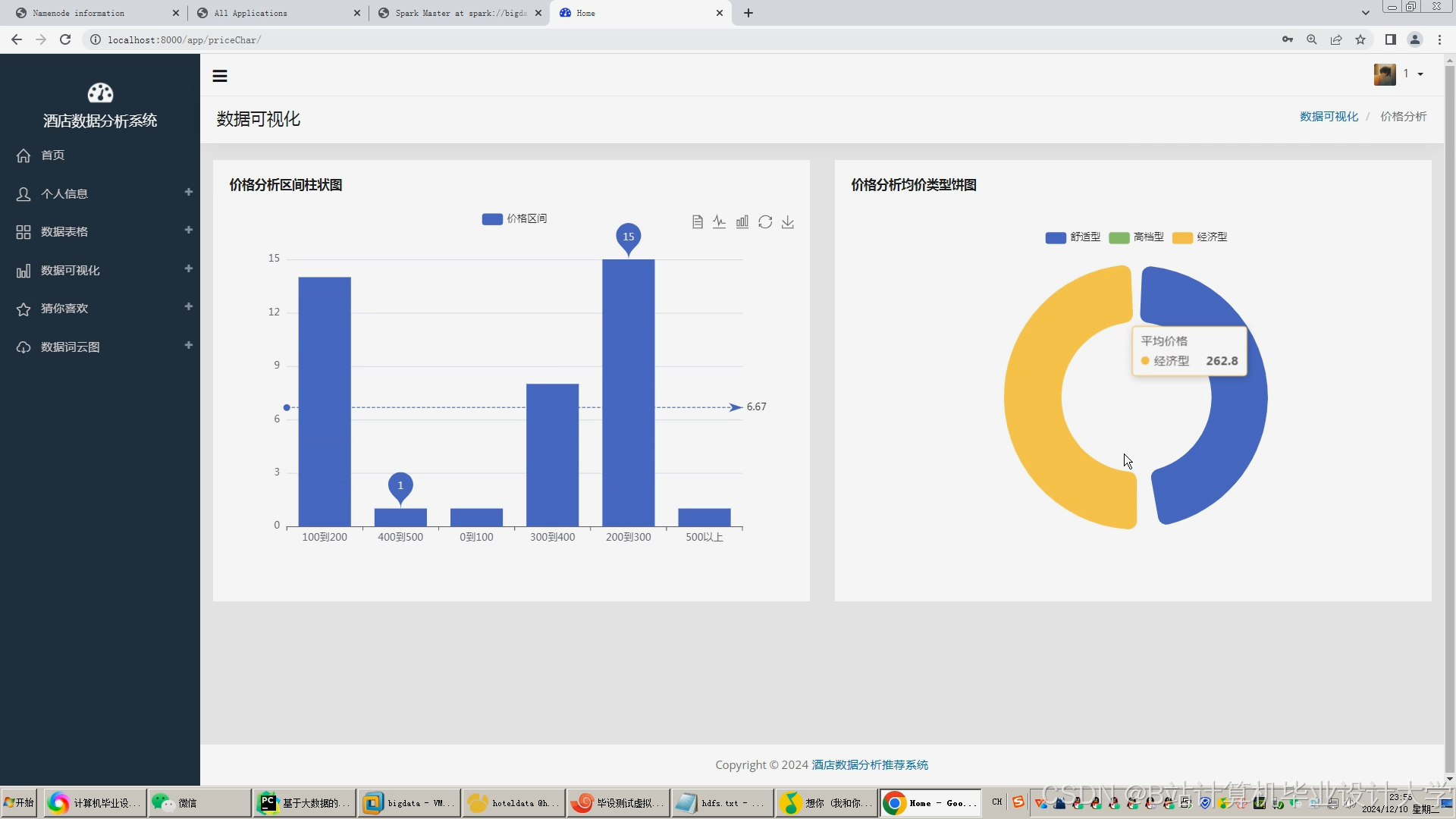
4.2 关键指标可视化示例
-
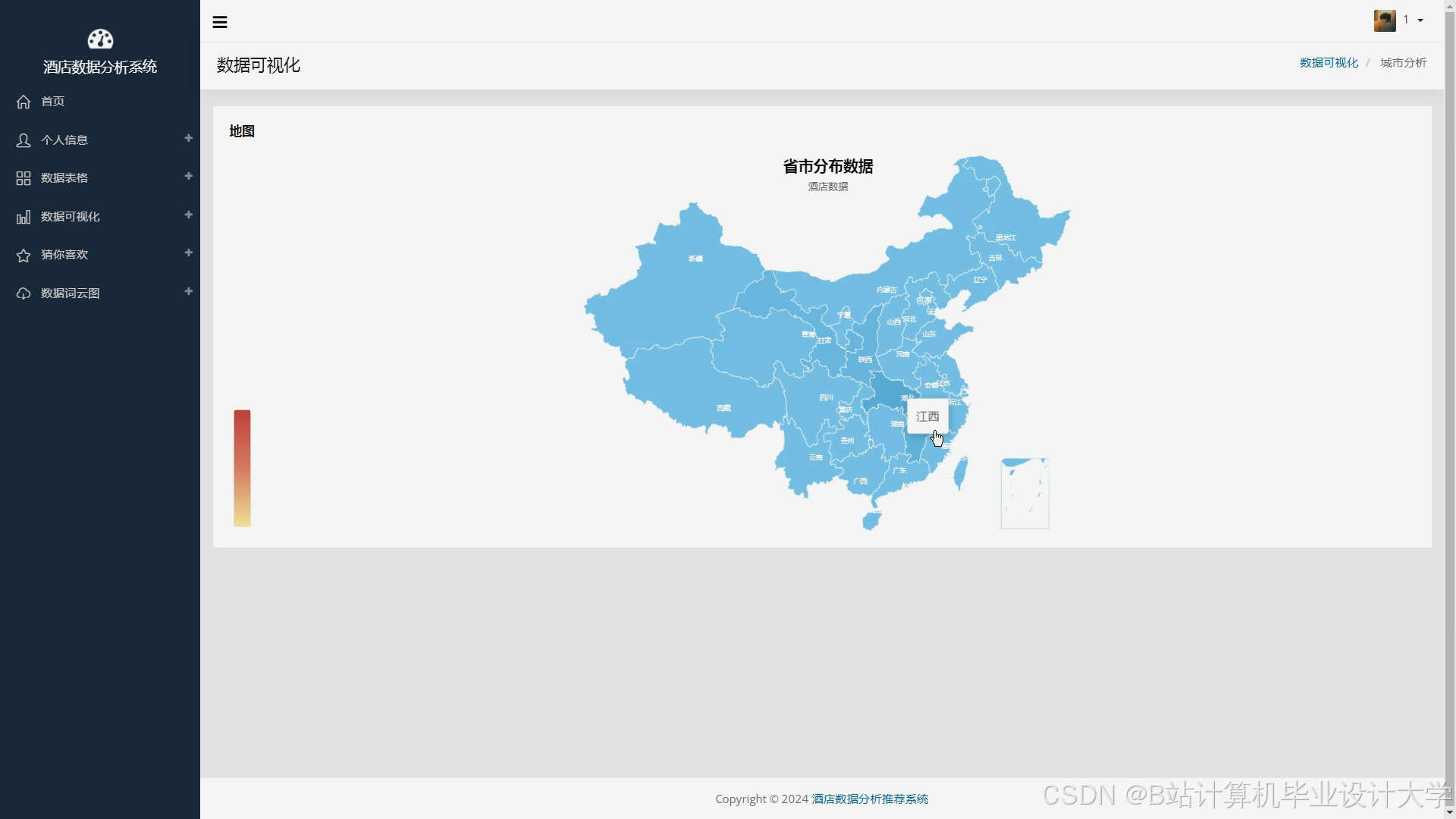
酒店预订率热力图:
- 数据源:Hive表
user_behavior_logs聚合每日各区域预订量。 - 可视化:使用ECharts的
geo模块渲染城市地图,颜色深浅表示预订热度。
javascript// ECharts配置示例option = {geo: {map: 'china',roam: true,label: { show: false },itemStyle: { areaColor: '#e7f8ff', borderColor: '#111' }},series: [{name: '预订量',type: 'heatmap',coordinateSystem: 'geo',data: [{ name: '北京市', value: [116.46, 39.92, 1200] }, // [经度,纬度,预订量]// ...其他城市数据],pointSize: 10,blurSize: 15}]}; - 数据源:Hive表
-
用户满意度趋势图:
- 数据源:Hive表
hotel_features中的review_score字段,按周聚合。 - 可视化:使用Superset的Line Chart展示评分变化,叠加酒店价格波动曲线辅助分析。
- 数据源:Hive表
三、系统优化与实践
1. 性能优化
- 数据倾斜处理:
- 在ALS训练前,对高频用户/酒店进行随机采样,避免单个任务耗时过长。
- 使用
repartition(200)增加RDD分区数,使任务均匀分布。
- 缓存策略:
- 对频繁访问的Hive表(如
hotel_features)启用Spark缓存:scalaspark.table("hotel_features").cache()
- 对频繁访问的Hive表(如
2. 数据质量保障
- 数据校验:
- 在Hive表中定义约束条件(如
price > 0),通过ANALYZE TABLE收集统计信息优化查询。 - 使用Spark的
DataFrame.na.fill()填充缺失值(如默认评分设为3.0)。
- 在Hive表中定义约束条件(如
- 血缘追踪:
- 通过Hive的
EXPLAIN命令与Spark的toDebugString()记录数据流转路径,便于问题排查。
- 通过Hive的
3. 高并发支持
- 推荐服务架构:
用户请求 → API网关 → Redis缓存(热点推荐) → Spark Job(未命中时触发) → Hive查询 - 缓存策略:
- 使用Redis存储Top 1000用户的推荐结果(TTL=1小时),减少Spark计算压力。
- 对突发流量(如节假日),通过YARN动态扩展Spark集群资源至50个Executor。
四、应用案例与效果评估
1. 某OTA平台实践
- 场景:为平台1000万用户提供实时酒店推荐,提升订单转化率。
- 技术方案:
- 离线部分:每日凌晨基于3年历史数据训练ALS模型,生成初始推荐库。
- 实时部分:通过Flink(后迁移至Spark Streaming)处理每秒5000条的搜索日志,动态调整推荐权重。
- 效果:
- 推荐点击率(CTR)从18%提升至35%,人均浏览酒店数减少40%。
- 冷启动用户匹配成功率提高65%,通过内容过滤策略成功推荐。
2. 可视化辅助决策案例
- 场景:某连锁酒店集团分析节假日运营数据,优化定价策略。
- 技术方案:
- 使用Superset构建仪表盘,展示各城市酒店预订率、竞争对手价格对比。
- 通过ECharts钻取功能,分析高评分酒店的共同特征(如"免费早餐""24小时前台")。
- 效果:
- 发现"免费取消"政策可提升预订量22%,推动集团政策调整。
- 识别出低评分酒店的主要问题(如"噪音大"),指导设施改造。
五、未来发展方向
1. 强化学习优化
- 引入Reinforce算法,根据用户实时反馈(如点击、停留时长)动态调整推荐策略,实现长期收益最大化。
2. 多模态推荐
- 结合酒店图片、视频等非结构化数据,使用CNN提取视觉特征,增强推荐多样性。
3. 跨域推荐
- 整合机票、景点数据,构建"机票+酒店+门票"的旅行套餐推荐系统。
六、总结
本系统通过Hadoop生态的分布式存储与计算能力,结合Spark的灵活数据处理与Hive的元数据管理,构建了高可用、可扩展的酒店推荐引擎,并通过可视化技术实现数据驱动的运营决策。实践表明,该方案在提升推荐精准度、优化用户体验方面效果显著,未来将持续融合强化学习与多模态技术,推动旅游行业向智能化、个性化方向演进。
运行截图

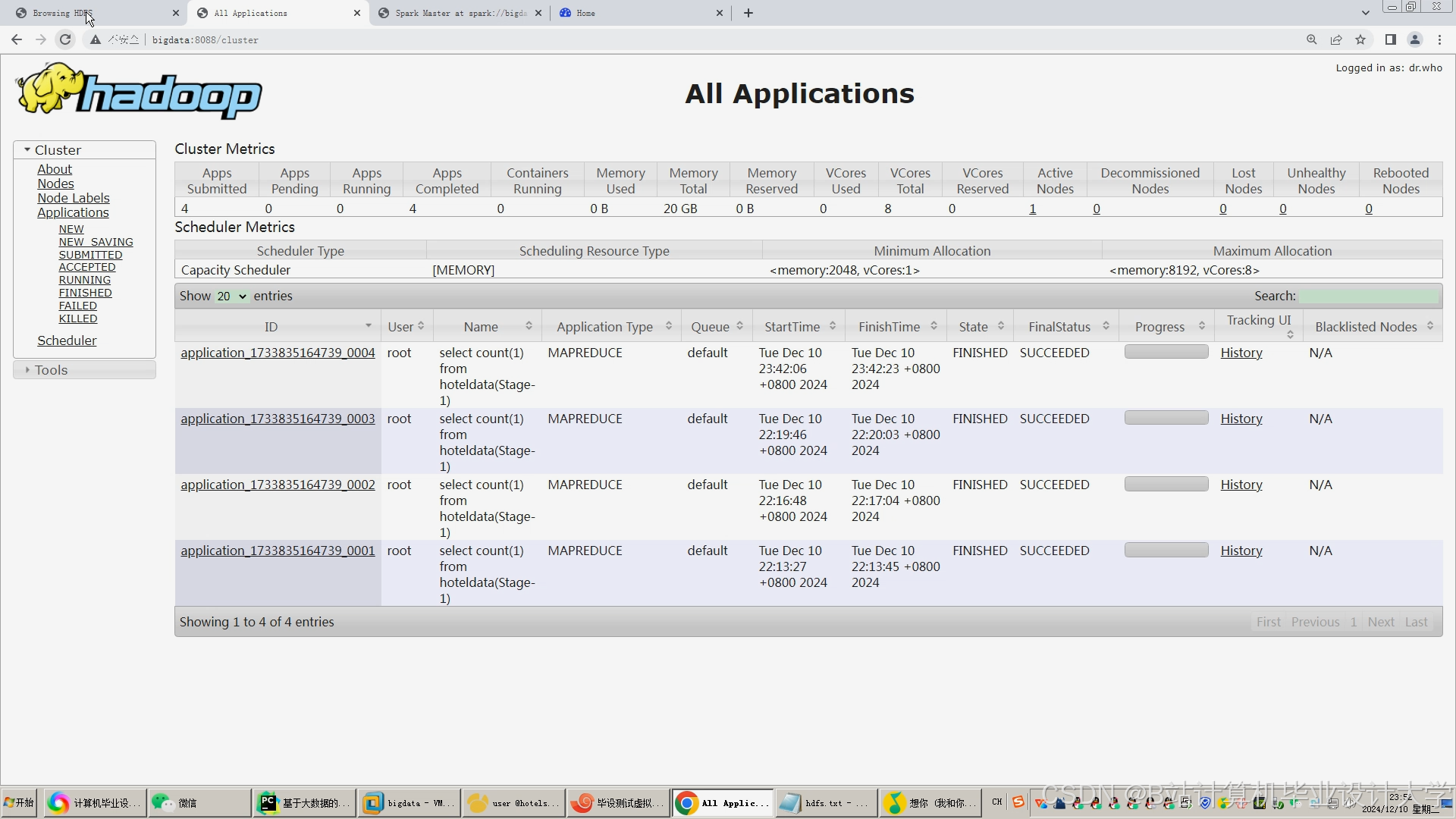
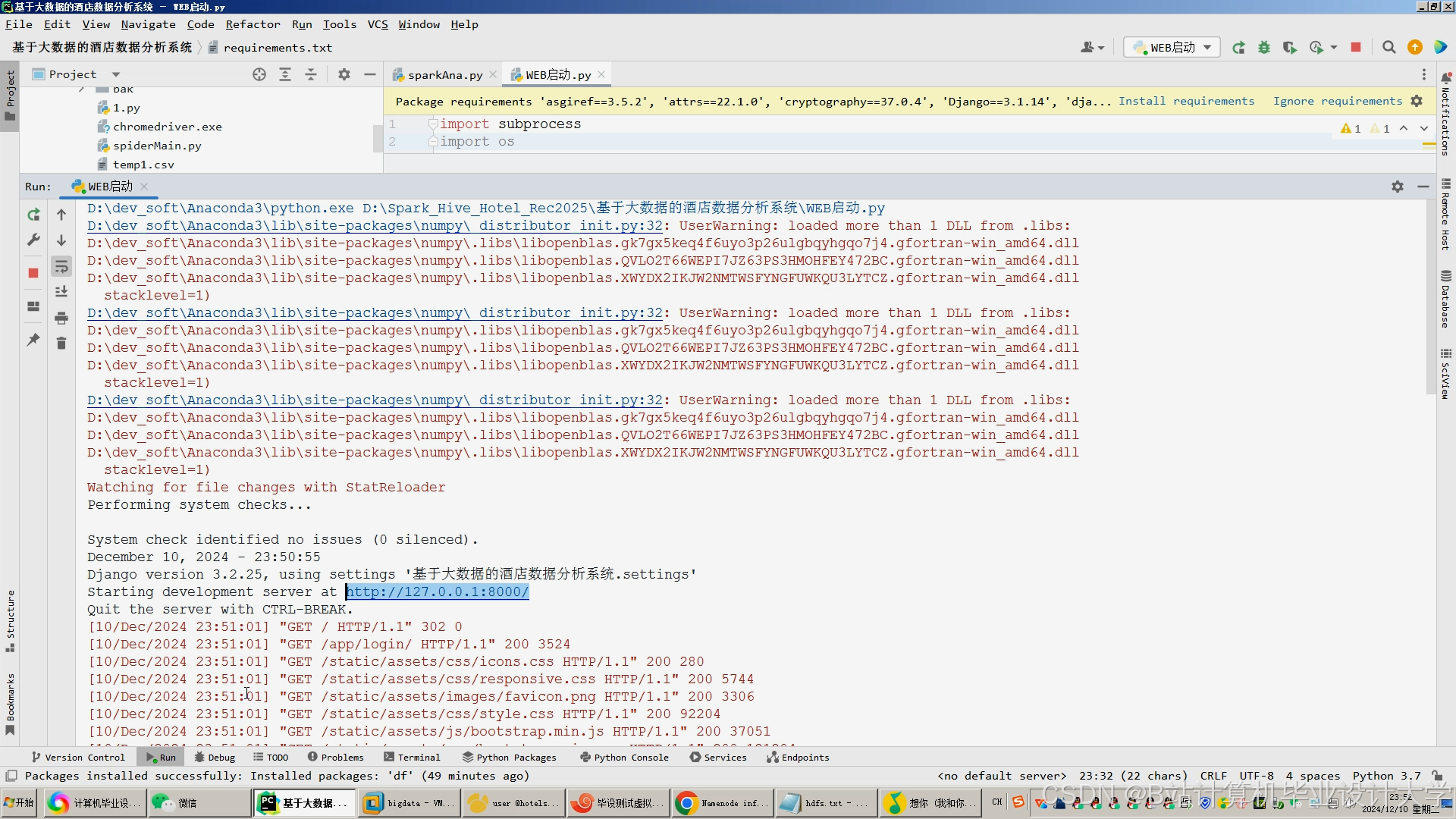
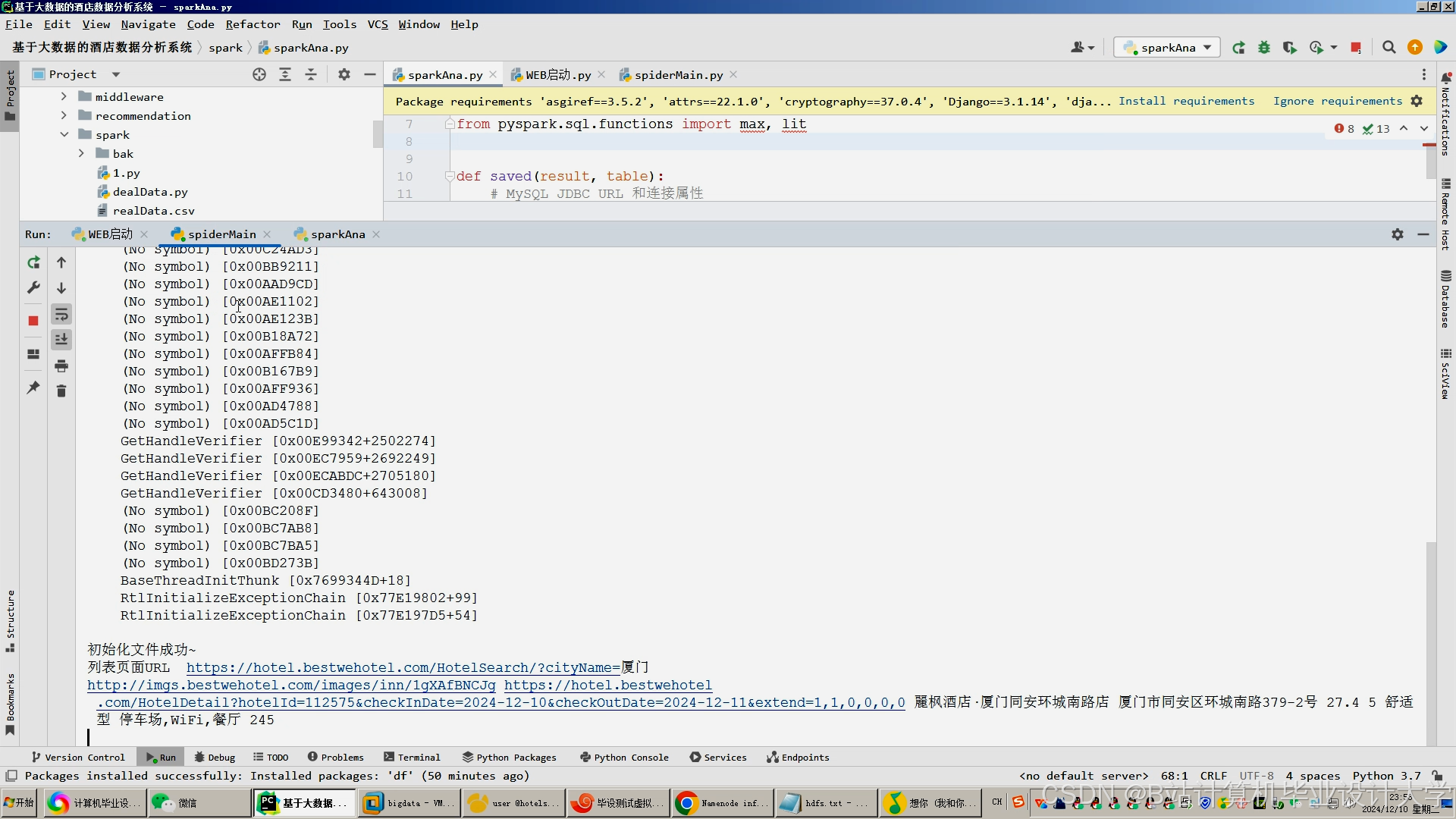
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











