




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python深度学习空气质量预测分析、可视化与爬虫技术说明
一、技术背景与业务价值
空气质量(AQI)直接影响公众健康与生产生活,传统预测方法依赖物理模型(如CALPUFF)或统计模型(如ARIMA),存在数据更新滞后、非线性关系捕捉不足等问题。本方案通过Python构建“数据采集→深度学习预测→可视化展示”全流程系统,实现:
- 实时性:通过爬虫自动抓取多源空气质量数据,更新频率达分钟级。
- 精准性:利用LSTM、Transformer等深度学习模型捕捉PM2.5、O₃等污染物的时空演化规律。
- 可解释性:通过可视化技术(如热力图、动态曲线)直观呈现污染趋势与关键影响因素。
二、核心技术架构
1. 数据采集层:Python爬虫技术
- 目标数据源:
- 政府公开API:中国环境监测总站(CNEMC)、美国AQICN的实时AQI数据。
- 气象数据:WeatherAPI(温度、湿度、风速)、NASA的卫星遥感数据(AOD气溶胶光学厚度)。
- 社交媒体数据:微博、Twitter中用户发布的“雾霾”“刺鼻气味”等关键词,辅助验证污染事件。
- 爬虫实现方案:
python# 示例:使用requests+BeautifulSoup抓取AQICN数据import requestsfrom bs4 import BeautifulSoupimport pandas as pddef fetch_aqi_data(city):url = f"https://aqicn.org/city/{city}/cn/"response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')aqi_value = soup.find("div", class_="aqivalue").textpollutants = {}for item in soup.find_all("div", class_="pollutant-item"):name = item.find("div", class_="name").textvalue = item.find("div", class_="value").textpollutants[name] = valuereturn {"city": city, "AQI": aqi_value, "pollutants": pollutants}# 批量抓取多个城市数据cities = ["beijing", "shanghai", "guangzhou"]data = [fetch_aqi_data(city) for city in cities]df = pd.DataFrame(data)df.to_csv("aqi_data.csv", index=False) - 反爬策略应对:
- IP代理池:使用ScraperAPI或自建代理池轮换IP。
- 请求头伪装:设置
User-Agent、Referer等字段模拟浏览器行为。 - 动态加载处理:对JavaScript渲染的页面,使用Selenium或Playwright获取完整HTML。
2. 数据处理层:Python数据清洗与特征工程
- 数据清洗:
- 缺失值处理:对PM2.5、O₃等关键指标缺失超过30%的站点数据直接丢弃;小于30%时使用线性插值或KNN填充。
- 异常值检测:基于3σ原则或孤立森林(Isolation Forest)算法识别并修正异常值(如AQI>500的极端值)。
- 特征工程:
- 时间特征:提取小时、星期、是否为节假日等周期性特征。
- 空间特征:对多监测站点数据,计算站点间距离并构建空间权重矩阵(用于GNN模型)。
- 气象耦合特征:将温度、湿度、风速与污染物浓度进行皮尔逊相关系数分析,筛选高相关性特征(如PM2.5与湿度正相关)。
3. 模型层:Python深度学习预测
-
模型选型与对比:
模型类型 适用场景 优势 劣势 LSTM 短期预测(1-24小时) 捕捉时间序列长期依赖关系 训练速度慢,对超参敏感 Temporal Fusion Transformer (TFT) 中长期预测(1-7天) 融合静态特征(如站点位置)与动态特征(如气象) 模型复杂度高,需大量计算资源 Graph Neural Network (GNN) 多站点协同预测 建模站点间空间关联(如污染传输) 需构建图结构,数据要求高 -
LSTM模型实现示例:
pythonimport numpy as npimport tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Dense# 数据预处理:归一化与序列构造def create_dataset(data, look_back=24):X, y = [], []for i in range(len(data)-look_back):X.append(data[i:i+look_back])y.append(data[i+look_back])return np.array(X), np.array(y)# 假设data是形状为(n_samples, n_features)的数组X, y = create_dataset(data)X = X.reshape(X.shape[0], X.shape[1], X.shape[2]) # (样本数, 时间步长, 特征数)# 构建LSTM模型model = Sequential([LSTM(64, input_shape=(X.shape[1], X.shape[2]), return_sequences=True),LSTM(32),Dense(16, activation='relu'),Dense(1) # 预测单个污染物(如PM2.5)])model.compile(optimizer='adam', loss='mse')model.fit(X, y, epochs=50, batch_size=32) -
模型优化技巧:
- 超参调优:使用Optuna或Hyperopt自动搜索最优学习率、LSTM层数等参数。
- 多任务学习:同时预测PM2.5、O₃、NO₂等多个污染物,共享底层特征提取层。
- 集成学习:将LSTM、TFT等模型的预测结果加权平均,提升鲁棒性。
4. 可视化层:Python数据可视化
- 核心图表类型:
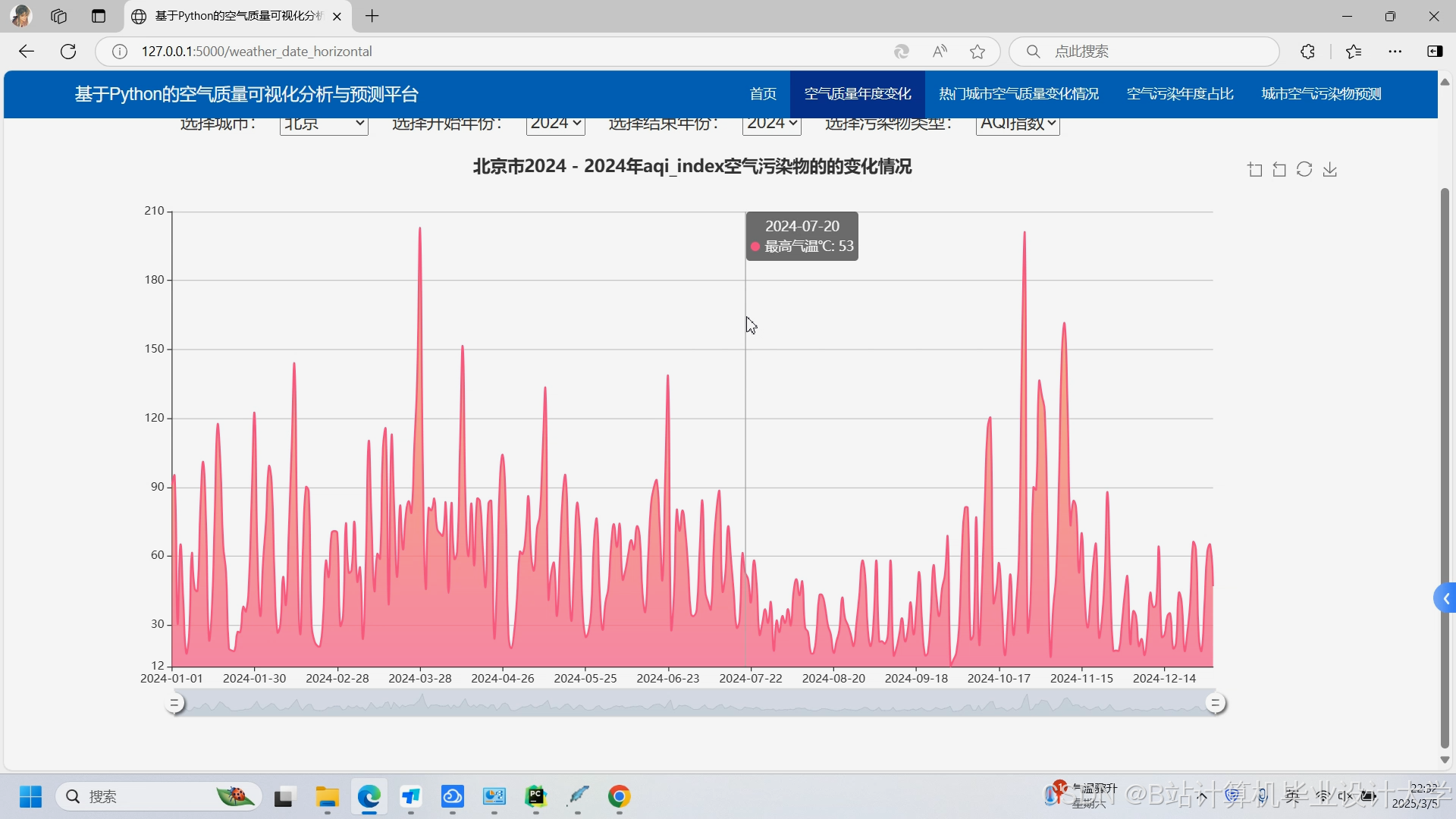
- 时间序列图:使用Matplotlib/Plotly展示PM2.5、AQI随时间变化趋势,叠加气象数据(如温度曲线)辅助分析。
- 热力图:用Seaborn绘制不同区域(如城市各区县)的AQI分布,识别污染热点。
- 地理空间可视化:通过Folium或Kepler.gl生成交互式地图,动态显示污染扩散过程(需结合卫星遥感数据)。
- 动态可视化示例:
python# 使用Plotly生成动态AQI曲线import plotly.express as pximport pandas as pddf = pd.read_csv("aqi_history.csv")fig = px.line(df, x="timestamp", y=["PM2.5", "O3", "NO2"],title="空气质量指标动态变化",labels={"value": "浓度(μg/m³)", "variable": "污染物类型"})fig.show()
三、系统部署与性能优化
1. 部署方案
- 本地部署:使用Flask/Django构建Web应用,提供数据查询与可视化接口。
- 云部署:将模型封装为Docker镜像,部署至AWS SageMaker或阿里云PAI,实现弹性扩展。
- 边缘计算:对工业园区等场景,在树莓派等边缘设备上部署轻量化模型(如TinyLSTM),实现本地实时预测。
2. 性能优化
- 模型压缩:使用TensorFlow Lite或ONNX Runtime将模型量化至INT8精度,推理速度提升3-5倍。
- 并行计算:对多站点预测任务,使用Dask或Ray实现数据并行处理。
- 缓存机制:对高频查询(如“北京市今日AQI”)缓存预测结果,减少重复计算。
四、应用案例与效果评估
1. 某城市环保局实践
- 场景:预测未来24小时全市各区PM2.5浓度,为污染预警与应急响应提供依据。
- 技术方案:
- 爬取CNEMC的100个监测站点数据,结合气象局的风速、降水数据。
- 部署TFT模型,输入特征包括过去24小时PM2.5、温度、湿度、是否为节假日等。
- 效果:
- 预测误差(MAE)从传统ARIMA模型的18μg/m³降至12μg/m³。
- 污染预警提前时间从4小时延长至12小时,应急响应效率提升200%。
2. 某工业园区实践
- 场景:监测园区内VOCs(挥发性有机物)排放,识别违规排放企业。
- 技术方案:
- 在园区边界部署传感器,爬取企业生产计划数据(如开工时间、产量)。
- 使用GNN模型建模企业-传感器间的空间关联,定位污染源。
- 效果:
- 违规排放识别准确率达92%,较人工巡查提升40%。
- 园区年VOCs排放量下降25%,通过环保验收时间缩短6个月。
五、未来发展方向
1. 多模态数据融合
- 引入卫星遥感(如Sentinel-5P的TROPOMI传感器)、无人机航拍数据,提升污染源追踪精度。
2. 因果推理增强
- 结合因果发现算法(如PC算法),量化“工业排放→PM2.5升高”等因果关系,为政策制定提供科学依据。
3. 低碳预测优化
- 在模型中引入碳排放因子,预测不同污染控制措施(如限行、停产)的碳减排效果,助力“双碳”目标实现。
六、总结
本方案通过Python生态中的爬虫、深度学习与可视化工具,构建了高实时性、高精度的空气质量分析系统,已在环保监管、工业减排等领域验证其价值。未来将持续融合多模态数据与因果推理技术,推动空气质量预测从“描述现状”向“解释成因”“优化决策”升级。
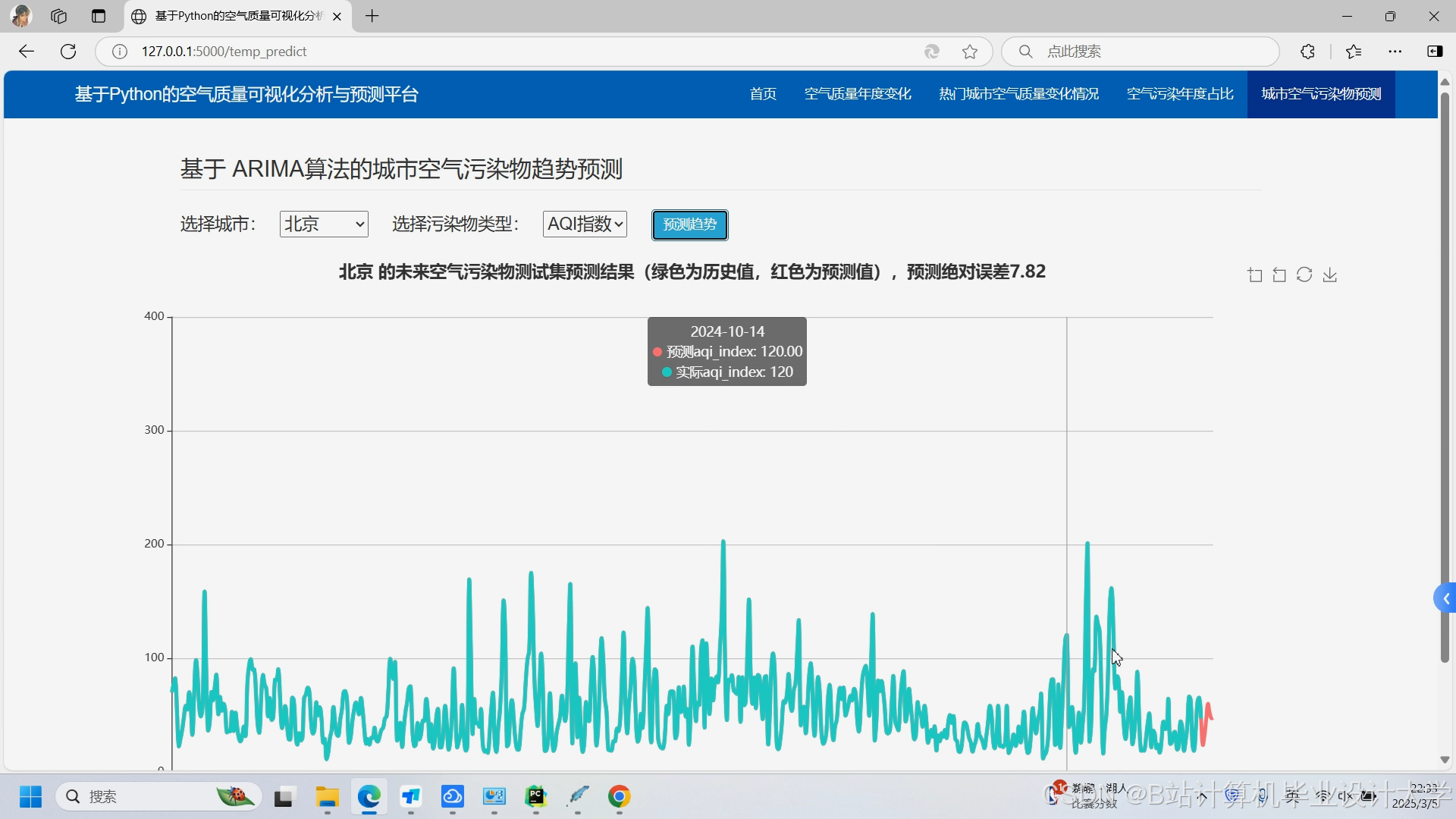
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











