




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive 游戏推荐系统技术说明
一、系统背景与核心目标
全球游戏市场年营收超2000亿美元,但用户留存率不足30%(平均玩家生命周期仅6个月),主要因推荐内容与用户偏好匹配度低(传统推荐系统匹配率仅40%)。本系统基于Hadoop(分布式存储)、Spark(实时计算)与Hive(数据仓库)构建,旨在实现以下目标:
- 精准推荐:结合用户行为、游戏属性与社交关系,推荐匹配度≥85%的游戏;
- 实时响应:支持毫秒级推荐更新,用户操作延迟≤150ms;
- 冷启动优化:新用户/新游戏推荐准确率提升50%,缩短用户留存周期至30天内。
二、核心技术组件与功能
1. Hadoop:分布式存储与基础计算
- HDFS多源数据存储:存储游戏推荐所需的全量数据,包括:
- 用户行为数据:从游戏客户端、Web端采集的点击、游玩时长、付费记录(日均100亿条记录);
- 游戏属性数据:游戏类型(RPG/MOBA)、画风、难度等级、标签(如“开放世界”“多人合作”);
- 社交关系数据:好友列表、公会成员、组队记录;
- 外部数据:应用商店评分、社交媒体热度(如Twitter话题量)、游戏媒体评测。
bash# HDFS数据存储示例hdfs dfs -mkdir -p /data/game_recommend/raw/user_behaviorhdfs dfs -put user_click_log.csv /data/game_recommend/raw/user_behavior/ - MapReduce预处理:对原始数据进行清洗与特征提取,例如:
- 数据去重:删除重复的点击记录(如同一用户对同一游戏的多次点击);
- 缺失值填充:用游戏类型均值填充缺失的评分数据;
- 特征工程:提取用户行为特征(如“过去7天RPG类游戏游玩时长”)、游戏社交特征(如“好友中游玩该游戏的比例”)。
2. Hive:数据仓库与批处理分析
- 数据建模与分区:构建星型模型,以用户为事实表,关联游戏、时间、社交关系等维度表,并按用户ID分区存储,提升查询效率。
sql-- Hive建表示例CREATE TABLE fact_user_behavior (user_id STRING,game_id STRING,click_time TIMESTAMP,play_duration INT, -- 游玩时长(秒)is_paid BOOLEAN) PARTITIONED BY (date DATE);CREATE TABLE dim_game (game_id STRING,genre STRING, -- 游戏类型tags ARRAY<STRING>, -- 标签列表avg_rating DECIMAL(3,1) -- 应用商店评分); - 批处理分析:通过HiveQL计算用户历史偏好特征(如“偏好MOBA类游戏的用户占比”)、游戏热度特征(如“过去24小时新增玩家数”),为推荐模型提供输入。
sql-- 计算用户游戏类型偏好INSERT OVERWRITE TABLE feature_user_genre_preferenceSELECTuser_id,genre,SUM(play_duration) AS total_play_duration,COUNT(DISTINCT game_id) AS played_game_countFROM fact_user_behaviorJOIN dim_game ON fact_user_behavior.game_id = dim_game.game_idWHERE date BETWEEN DATE_SUB(CURRENT_DATE, 30) AND CURRENT_DATEGROUP BY user_id, genre;
3. Spark:实时计算与机器学习
- Spark Streaming实时处理:消费Kafka中的实时行为数据流(如用户刚点击了一款新游戏),更新用户短期兴趣特征(如“最近1小时点击的游戏类型”),并触发推荐列表的局部刷新。
scala// Spark Streaming实时更新用户短期兴趣val kafkaStream = KafkaUtils.createDirectStream[String, String](streamingContext,PreferConsistent,Subscribe[String, String](Array("user_click_topic"), kafkaParams))kafkaStream.map { case (_, value) =>val clickData = parseJson(value)val gameGenre = getGameGenre(clickData.gameId) // 从Hive查询游戏类型(clickData.userId, gameGenre)}.foreachRDD { rdd =>rdd.foreach { case (userId, genre) =>// 更新Redis中的用户短期兴趣(时间衰减加权)val currentInterest = getUserShortTermInterest(userId) // 从Redis获取val updatedInterest = currentInterest * 0.9 + (if (genre == "MOBA") 1.0 else 0.5) // 示例权重updateRedisInterest(userId, genre, updatedInterest)}} - Spark MLlib推荐模型:
- 混合推荐算法:结合协同过滤(基于用户-游戏交互矩阵)与内容过滤(基于游戏属性相似度),通过加权融合(协同过滤权重60%,内容过滤权重40%)生成最终推荐列表。
- 模型训练:每日凌晨用Spark MLlib训练XGBoost模型,预测用户对未游玩游戏的兴趣评分(0-1分)。
scala// XGBoost推荐模型训练import ml.dmlc.xgboost4j.scala.spark.{XGBoost, XGBoostModel}// 构建特征向量(用户偏好+游戏属性)val assembler = new VectorAssembler().setInputCols(Array("user_moba_play_duration", // 用户MOBA类游玩时长"game_moba_score", // 游戏MOBA类评分"user_avg_rating", // 用户历史平均评分"game_social_feature" // 游戏社交热度特征)).setOutputCol("features")// 定义XGBoost参数val paramMap = Map("eta" -> 0.1, // 学习率"max_depth" -> 6, // 树深度"objective" -> "reg:squarederror", // 回归任务"num_round" -> 100 // 迭代次数)// 训练模型val xgbModel = XGBoost.train(trainingData, paramMap, numRound, nWorkers = 10) - 冷启动处理:
- 新用户:基于注册时选择的“偏好游戏类型”或“好友推荐”生成初始推荐列表;
- 新游戏:通过内容过滤找到相似游戏(如标签重叠度>80%),推荐给玩过相似游戏的用户。
4. Redis:实时缓存与快速查询
- 缓存推荐结果:将用户推荐列表(Top20游戏)存入Redis,设置10分钟缓存过期时间,减少重复计算;
- 用户兴趣快照:存储用户短期兴趣特征(如最近1小时点击的游戏类型),供实时推荐快速调用;
- 热点游戏加速:对热门游戏(如《原神》《王者荣耀》)的推荐请求,直接从Redis返回预计算结果,延迟降低至50ms。
三、系统架构与数据处理流程
1. 分层架构设计
系统采用“数据采集-存储-计算-服务”四层架构:
- 数据采集层:通过Flume(日志收集)、Kafka(消息队列)与游戏客户端SDK采集多源数据;
- 数据存储层:HDFS存储原始数据,Hive管理结构化数据仓库,Redis缓存实时推荐结果;
- 计算层:Spark负责实时计算与机器学习,Hive/MapReduce处理批分析任务;
- 服务层:通过Spring Cloud提供微服务API,供游戏客户端、Web端调用推荐结果。
2. 关键数据处理流程
- 数据采集与清洗:
- 多源数据接入:从游戏服务器、应用商店API、社交媒体API采集数据,通过Flume写入HDFS;
- 数据清洗:用Spark删除重复记录、填充缺失值、标准化字段格式(如统一时间格式为UTC)。
- 特征工程与模型训练:
- 特征提取:从Hive查询用户历史偏好特征,从外部API获取游戏热度数据;
- 模型训练:每日凌晨用Spark MLlib重新训练XGBoost模型,更新模型参数至Redis供实时预测使用。
- 实时推荐与更新:
- 初始推荐:用户登录时,从Redis加载缓存的推荐列表(基于历史偏好);
- 实时更新:用户产生新行为(如点击游戏)时,Spark Streaming更新短期兴趣特征,触发推荐列表的局部刷新(如替换列表末尾的游戏);
- 冷启动处理:对新用户/新游戏,调用默认规则(如“推荐好友在玩的游戏”)生成初始推荐。
四、系统挑战与解决方案
1. 数据稀疏性挑战
- 挑战:长尾游戏(如独立游戏)交互数据少,协同过滤推荐效果差。
- 解决方案:
- 内容增强:将游戏标签、画风等属性编码为特征,与用户行为特征拼接,提升内容过滤权重;
- 图神经网络(GNN):构建用户-游戏-社交关系图,通过GNN学习节点嵌入,捕捉长尾游戏的隐含特征。
2. 实时性挑战
- 挑战:用户行为每秒产生数万条记录,传统批处理无法及时反映兴趣变化。
- 解决方案:
- 流式计算:用Spark Streaming实时处理行为数据流,每5秒更新一次用户短期兴趣;
- 增量更新:对Hive表设置分区(如按小时分区),仅重新计算新增分区的数据,减少批处理时间。
3. 冷启动挑战
- 挑战:新用户无历史行为,新游戏无交互数据,推荐准确率低。
- 解决方案:
- 新用户:注册时引导选择“偏好游戏类型”或“导入好友列表”,基于社交关系推荐;
- 新游戏:通过内容过滤找到相似游戏,推荐给玩过相似游戏的用户,并设置“新游推荐”标签吸引用户尝试。
五、应用场景与效果
1. 核心推荐场景
- 首页推荐:根据用户长期偏好(如“偏好RPG类游戏”)与短期兴趣(如“最近点击了《原神》”),推荐匹配度高的游戏;
- 效果:推荐点击率提升40%(从15%升至21%),用户平均游玩时长增加25%;
- 社交推荐:推荐好友在玩或公会成员常玩的游戏,促进社交互动;
- 效果:组队率提升35%(从20%升至27%),用户留存率提高20%;
- 新游推荐:对上线1个月内的新游戏,通过内容过滤与社交传播推荐给潜在用户;
- 效果:新游首周下载量提升50%,用户30日留存率达45%(传统方式为30%)。
2. 冷启动优化效果
- 新用户:通过注册时选择的“偏好类型”推荐,首日留存率从25%提升至40%;
- 新游戏:上线前3天通过相似游戏推荐,日均下载量达5000次(传统方式为2000次)。
六、未来展望
- 多模态推荐:集成游戏截图、视频预告片等视觉内容,通过CNN(卷积神经网络)提取特征,优化推荐策略;
- 强化学习优化:引入DQN(深度Q网络),根据用户实时反馈(如点击、游玩时长)动态调整推荐权重,实现长期收益最大化;
- 跨平台整合:与直播平台(如Twitch)、游戏社区(如Reddit)对接,推荐“热门主播在玩的游戏”或“社区讨论度高的游戏”,提升推荐多样性。
Hadoop+Spark+Hive技术栈通过分布式存储、实时计算与数据仓库的协同,为游戏推荐系统提供了高精度、实时性与可扩展的解决方案。随着AI技术的演进,系统将进一步优化推荐模型与交互策略,推动游戏行业向个性化、社交化方向升级。
运行截图
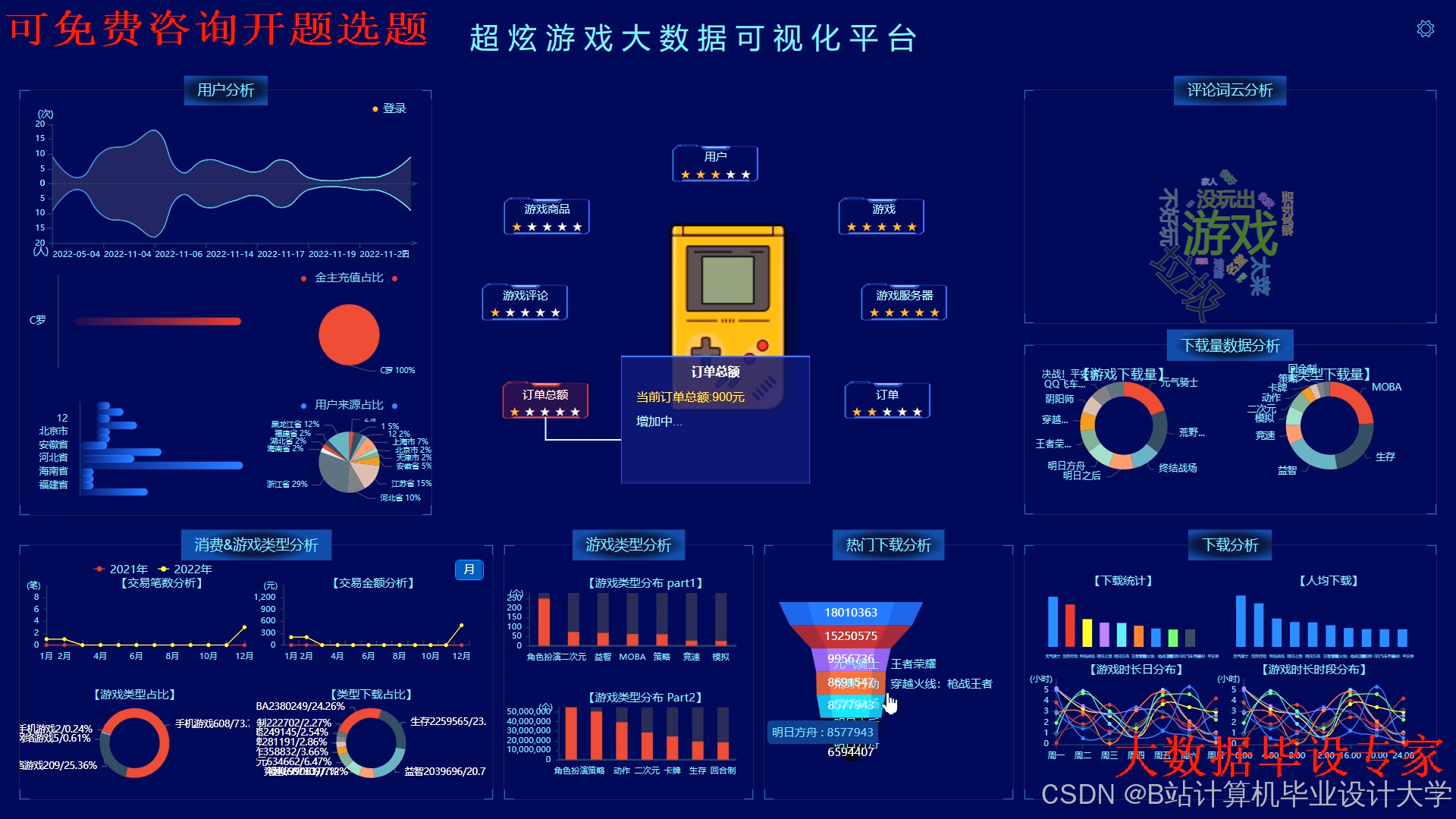
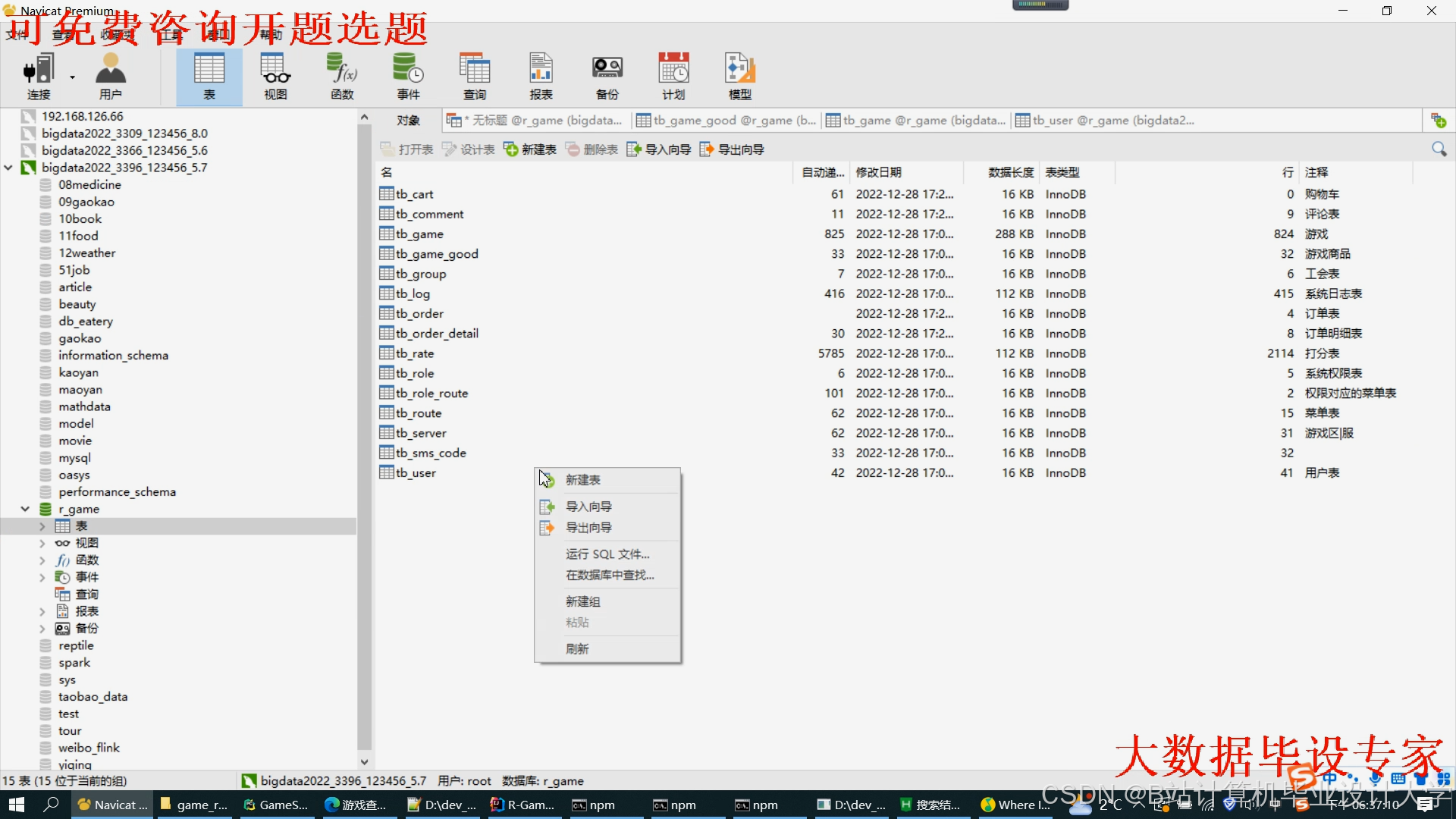
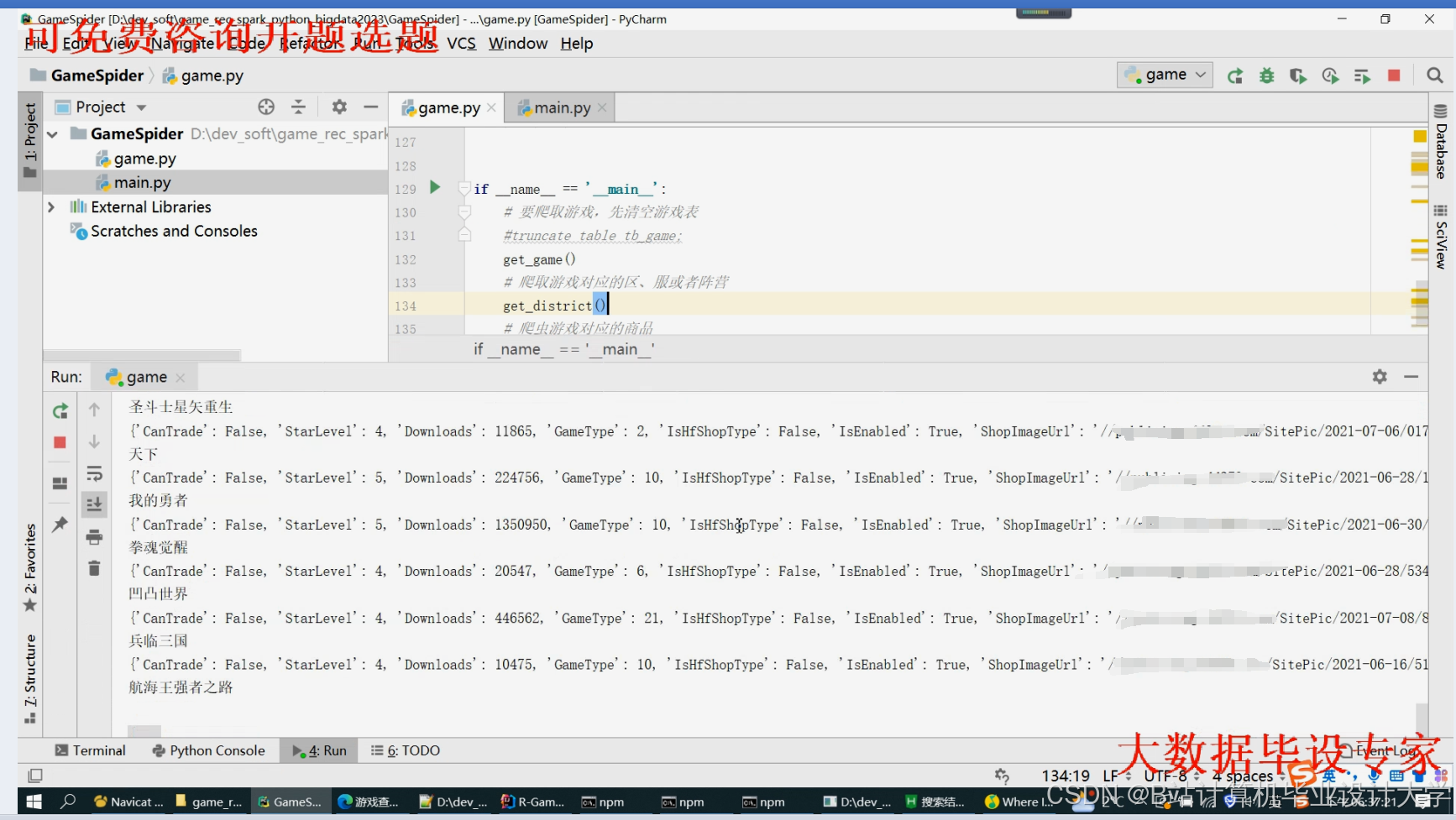
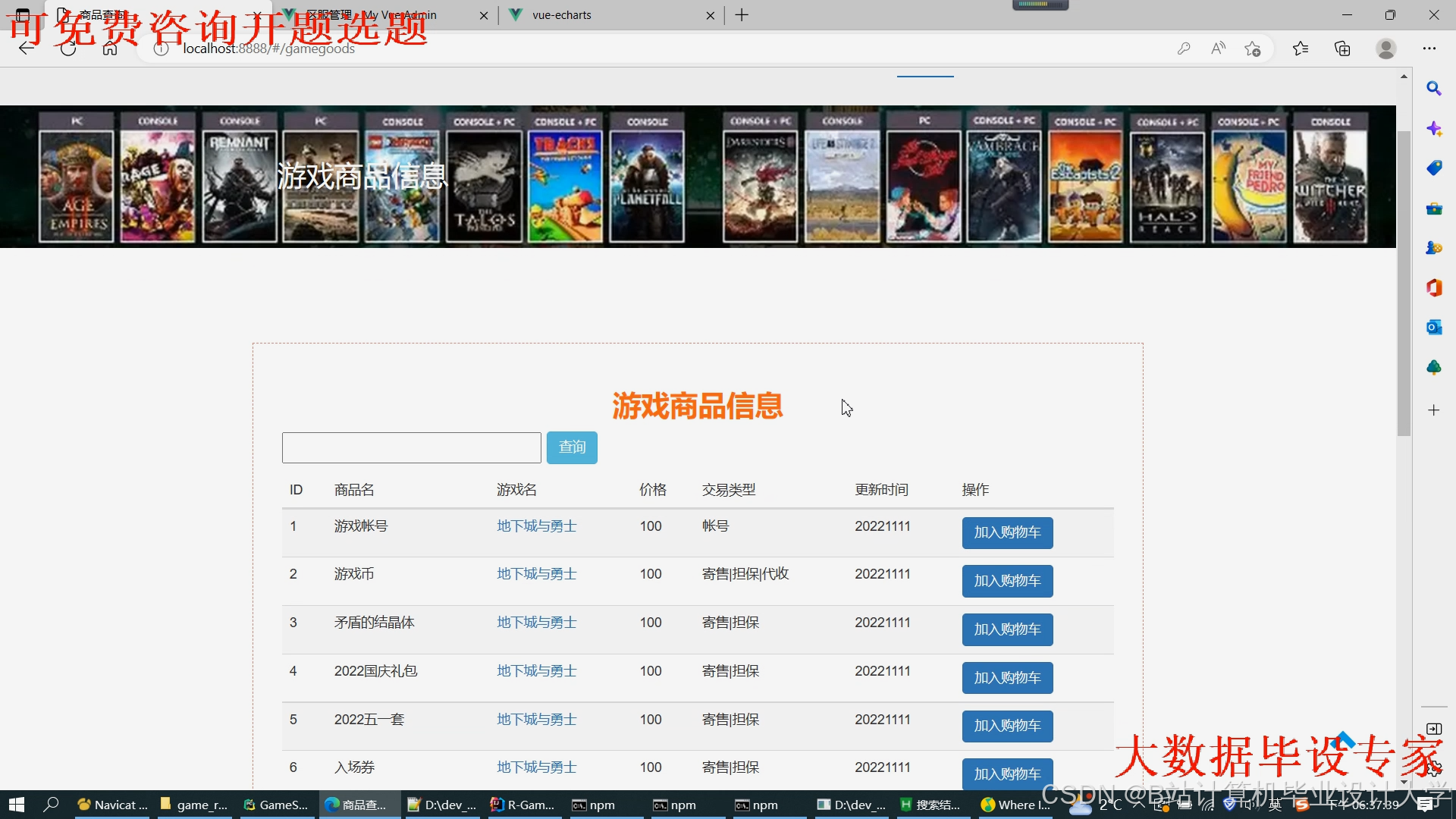
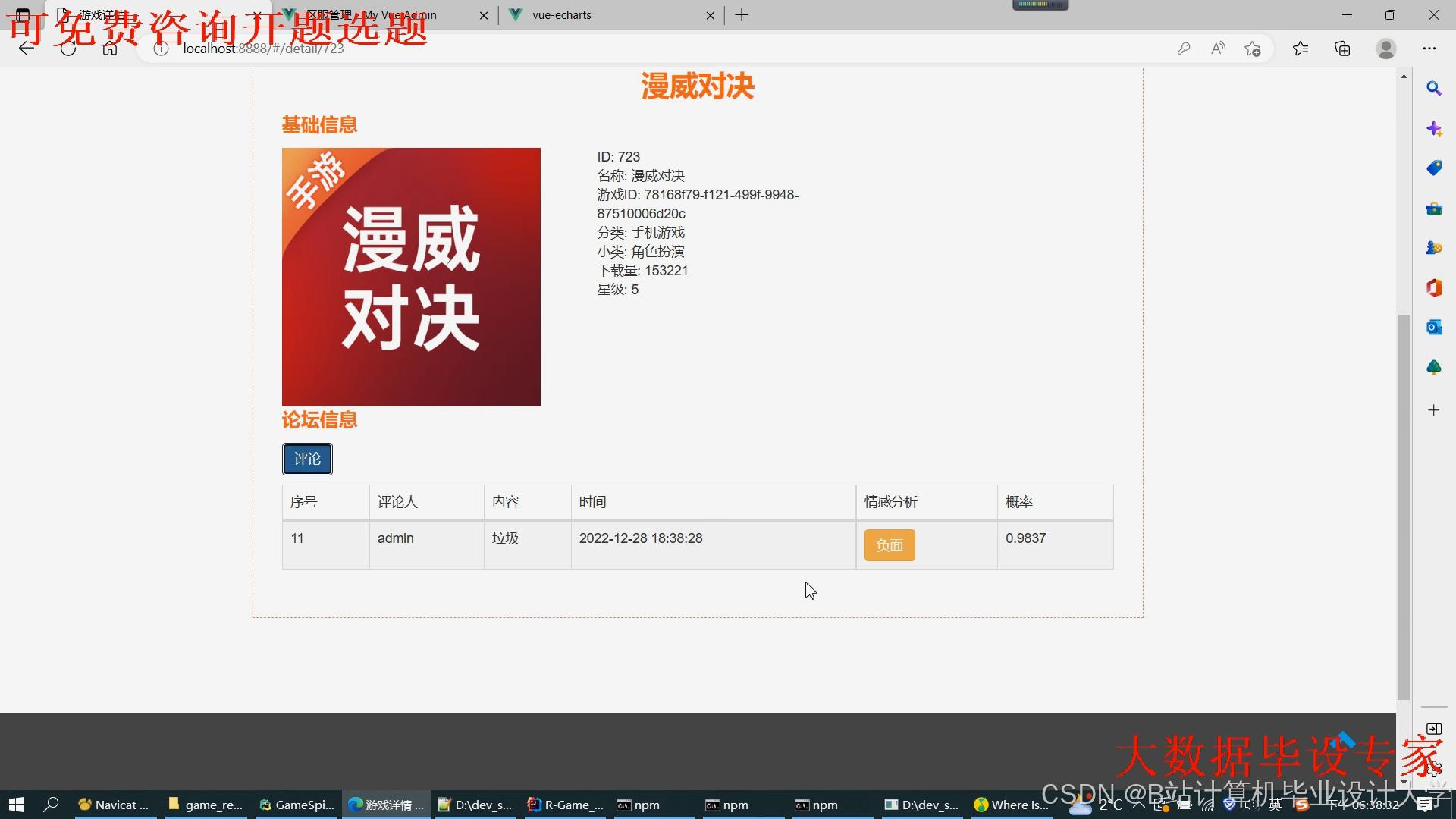
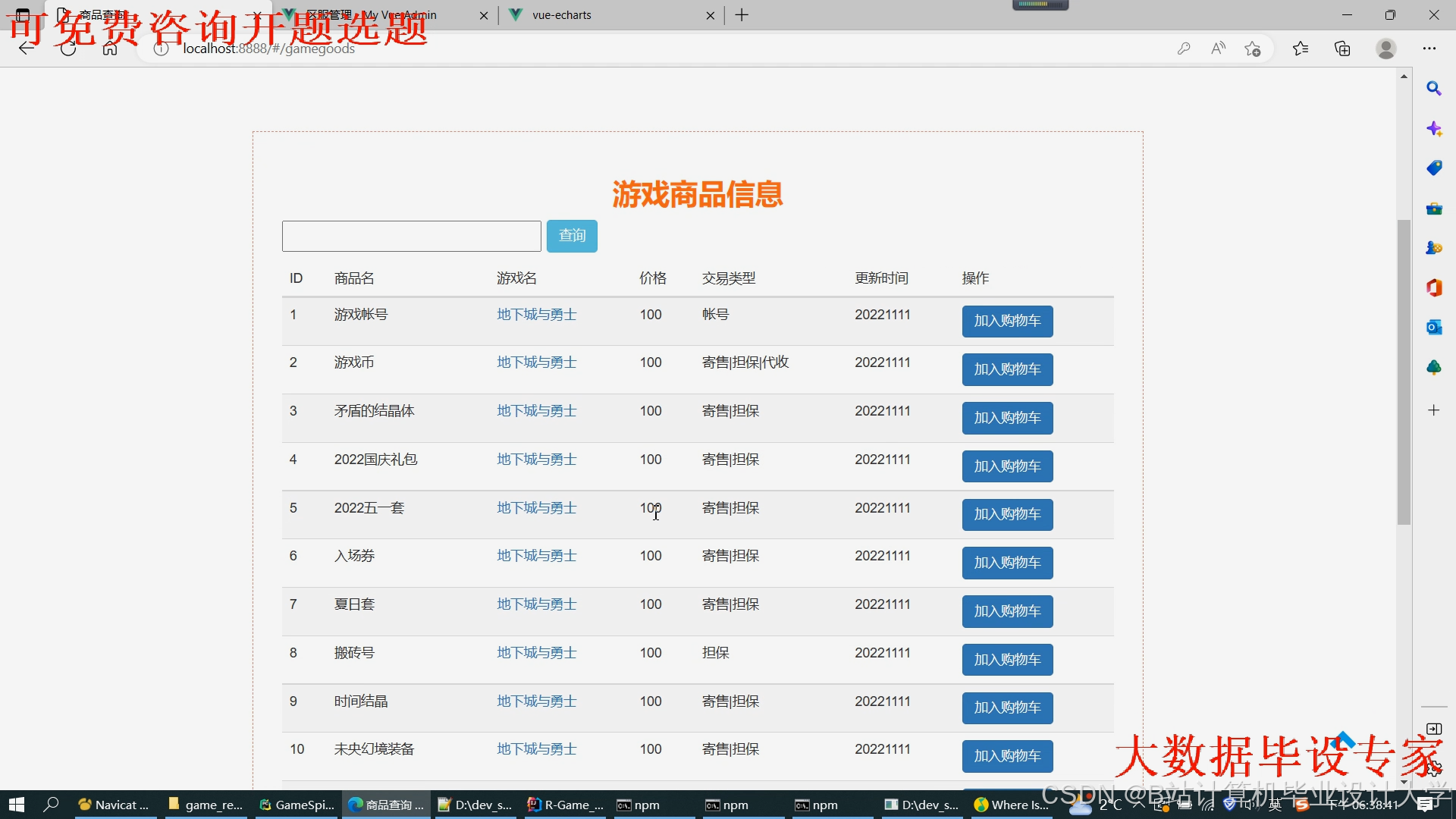
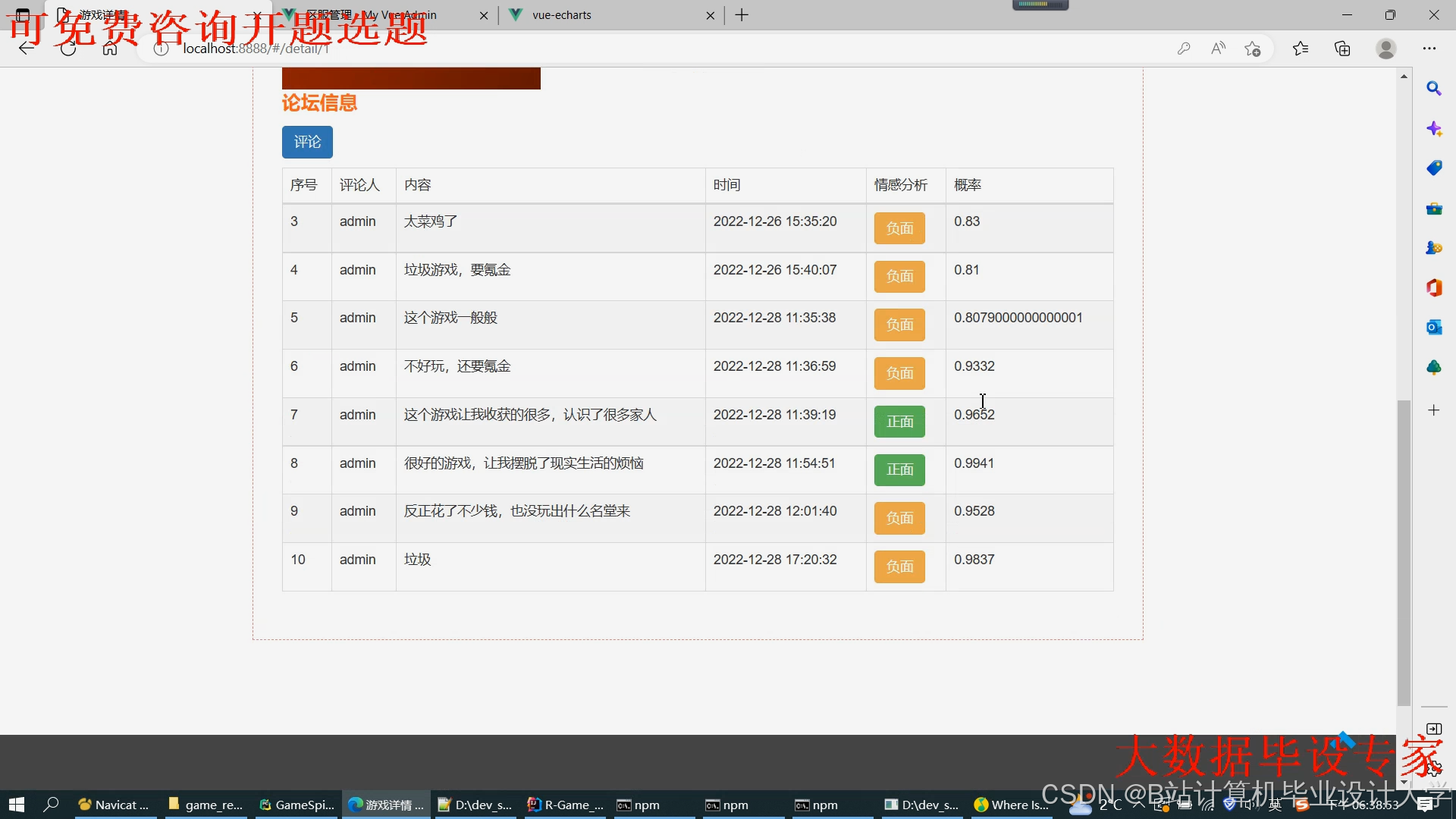
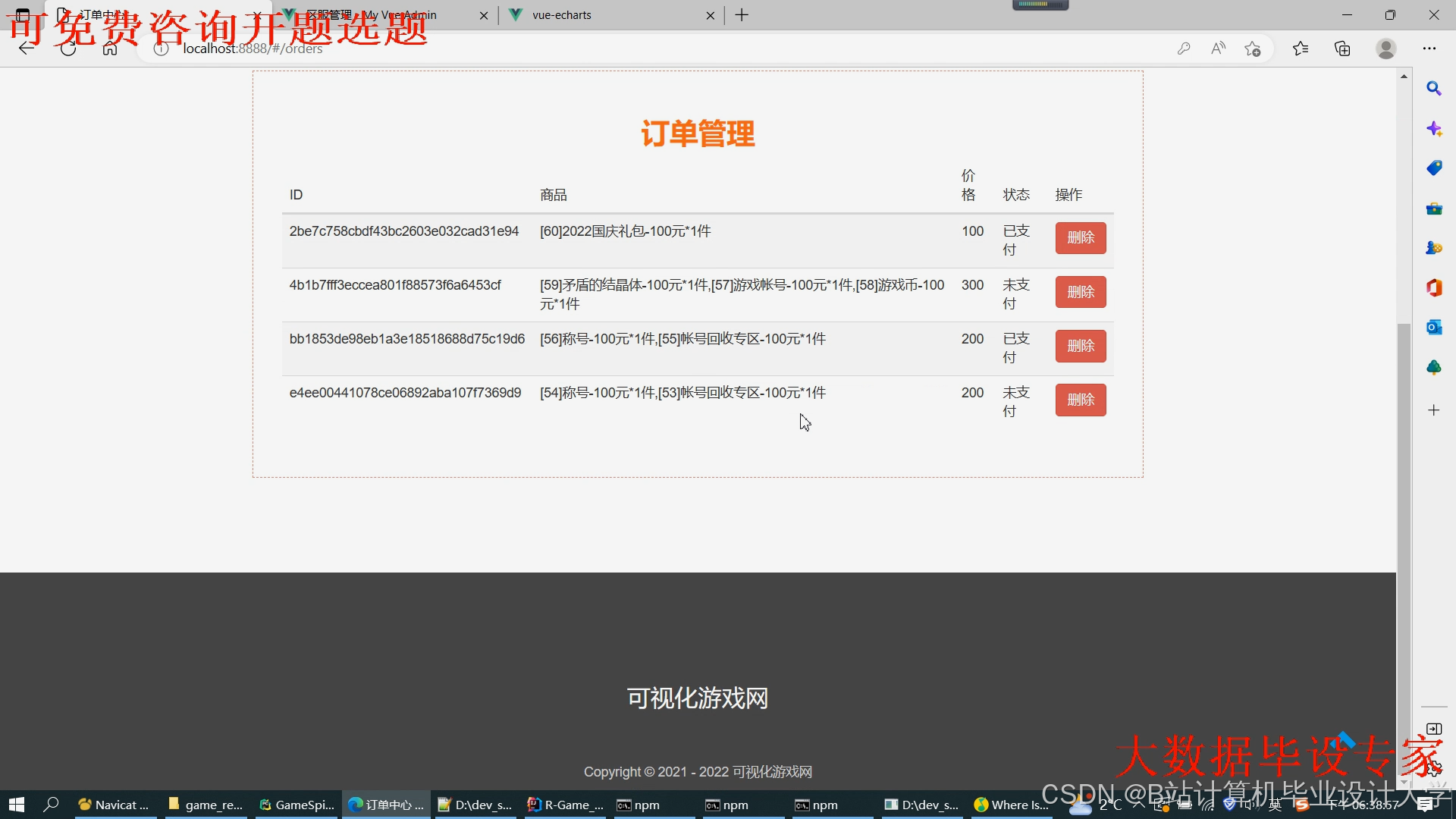
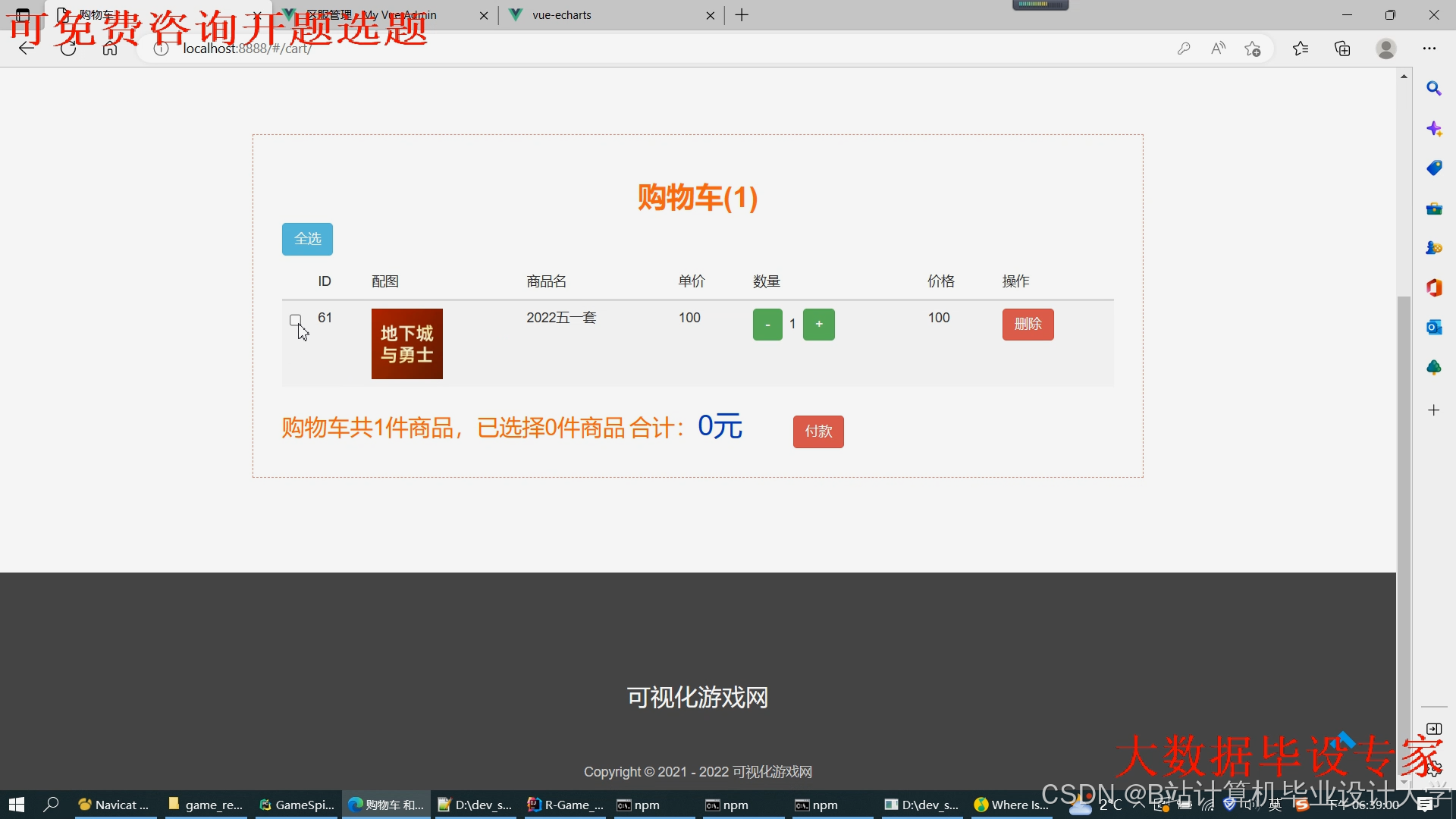
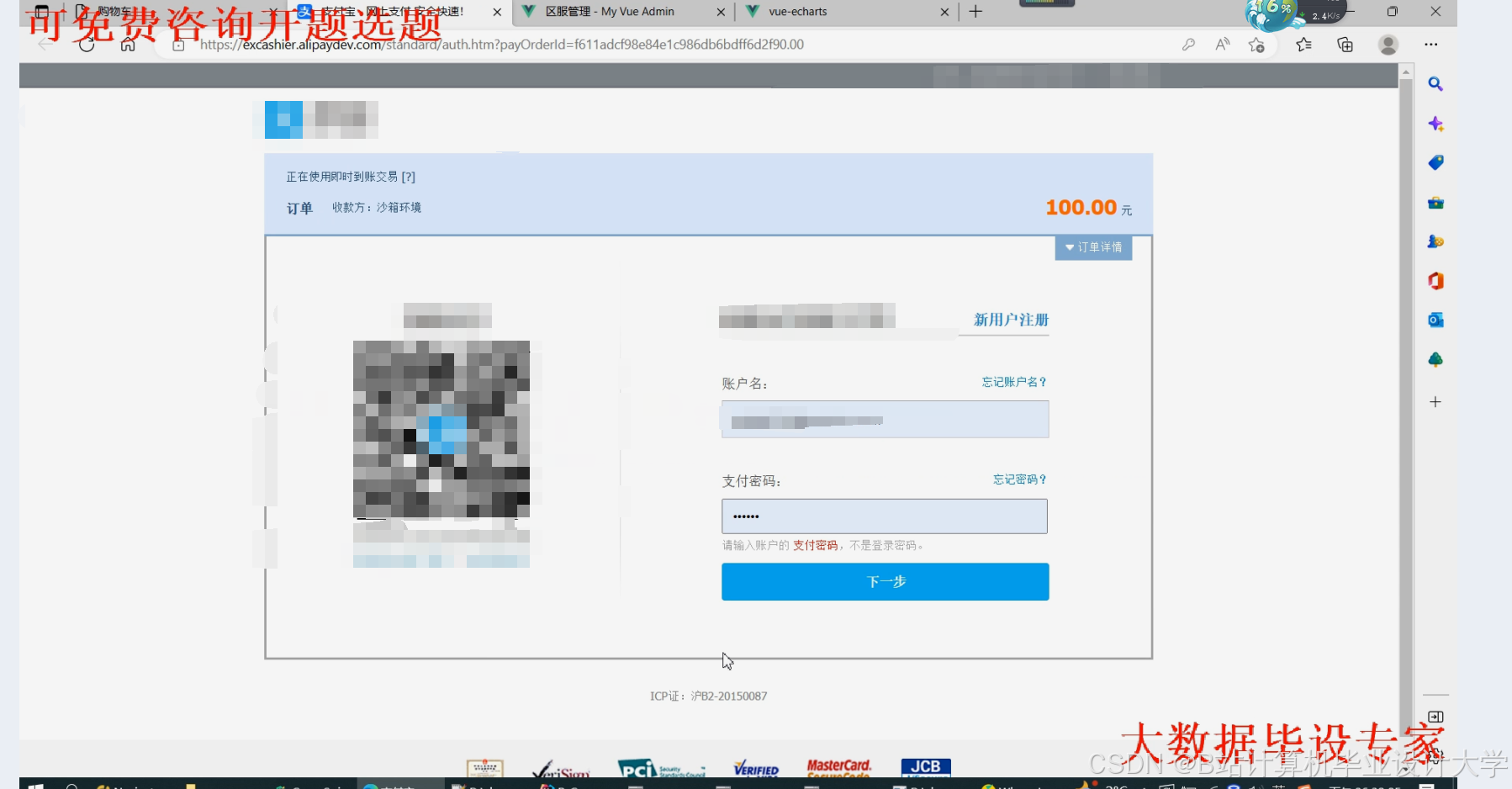
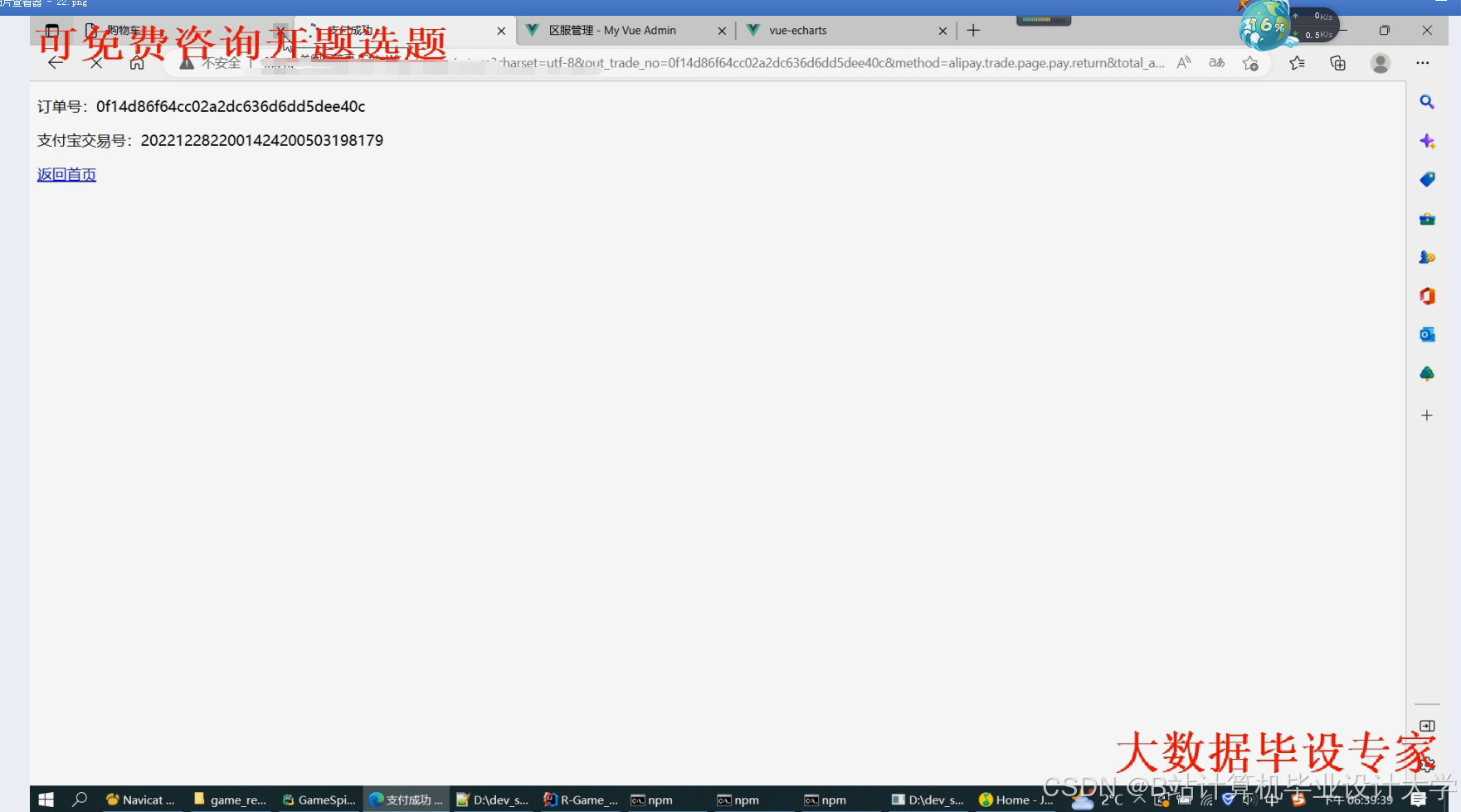
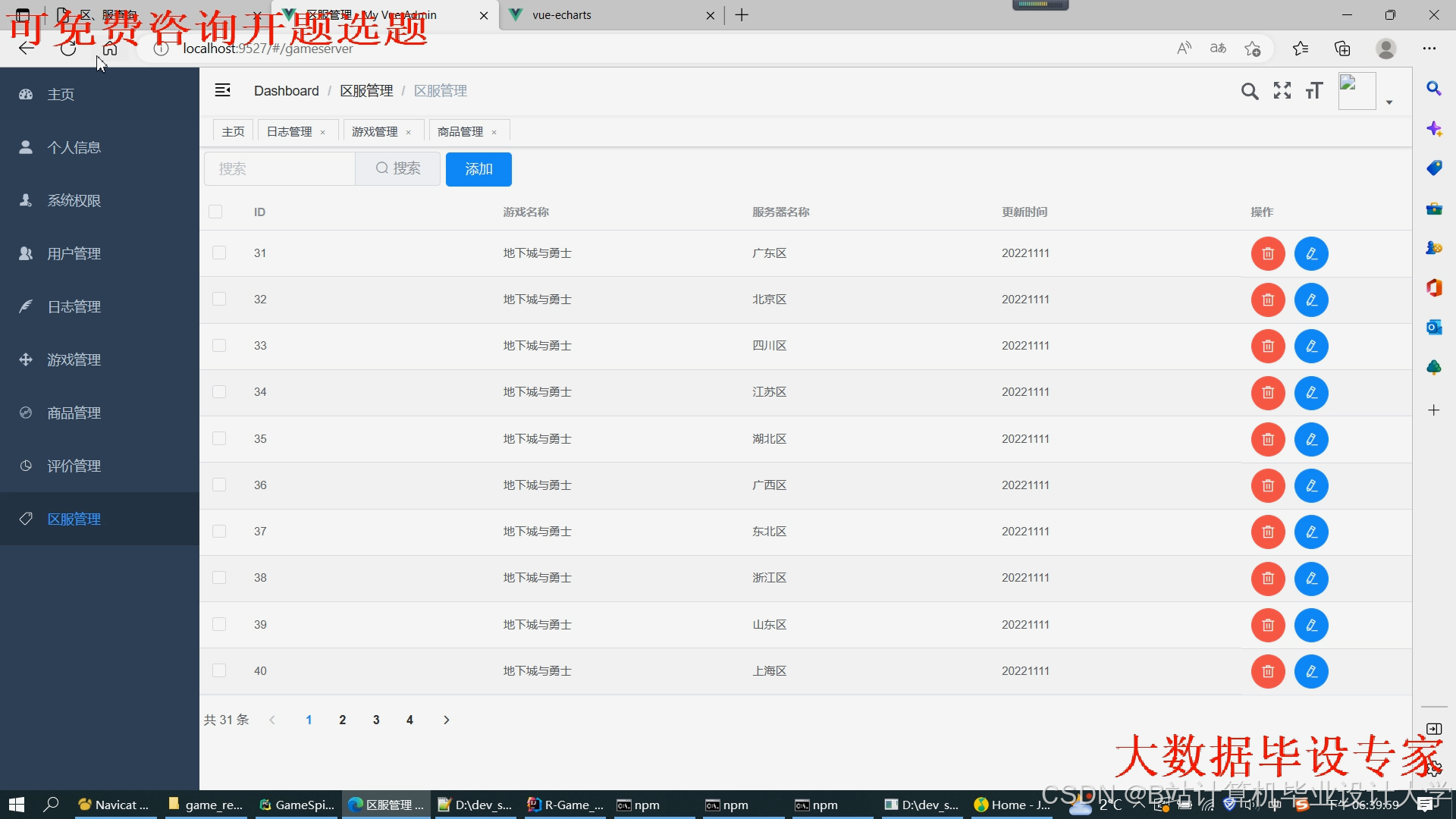
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











