




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Hadoop + Spark + Hive 机票价格预测与推荐系统》的任务书模板,涵盖大数据处理、机器学习建模及实时推荐架构设计,适用于航空公司或在线旅游平台(OTA)的动态定价与个性化推荐场景:
任务书:基于Hadoop+Spark+Hive的机票价格预测与智能推荐系统
一、项目背景与目标
-
背景
机票价格受供需关系、节假日、航线竞争等因素动态波动,传统静态定价策略难以适应市场变化。本系统通过整合历史票价数据(Hadoop存储)、实时竞品价格(Spark Streaming处理)及用户行为(Hive用户画像),构建基于时间序列预测与协同过滤的混合推荐引擎,实现动态价格预测与个性化机票推荐。 -
目标
- 开发支持TB级机票数据存储与处理的分布式系统
- 实现未来7天票价预测准确率≥85%(MAPE指标)
- 提供用户偏好驱动的机票推荐(点击率提升20%)
- 支持实时竞品价格监控与策略调整
二、系统架构设计
┌───────────────────────────────────────────────────────────────┐ | |
│ 数据采集层 │ | |
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ | |
│ │ 航空公司 │←───│ 竞品API │←───│ 用户日志 │ │ | |
│ │ GDS系统 │ │ (Fluentd)│ │ (Kafka) │ │ | |
│ └─────────┘ └─────────┘ └─────────┘ │ | |
│ ↑ ↑ ↑ │ | |
│ 结构化数据 半结构化JSON 用户点击流 │ | |
└───────────────────────┬───────────────────────────────────┘ | |
│ 数据清洗与存储 | |
▼ | |
┌───────────────────────────────────────────────────────────────┐ | |
│ 大数据处理层(Hadoop+Hive) │ | |
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ | |
│ │ HDFS │←───│ Hive │←───│ Spark │ │ | |
│ │ (原始数据│ │ (数据仓库│ │ (ETL/ML │ │ | |
│ │ 存储) │ │ 建模) │ │ 训练) │ │ | |
│ └─────────┘ └─────────┘ └─────────┘ │ | |
│ ↑ ↑ ↑ │ | |
│ Parquet格式 HiveQL分析 PySpark MLlib │ | |
└───────────────────────┬───────────────────────────────────┘ | |
│ 实时计算与推荐 | |
▼ | |
┌───────────────────────────────────────────────────────────────┐ | |
│ 服务应用层(Spark Streaming+Redis) │ | |
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │ | |
│ │ 价格预测 │←───│ 推荐引擎 │←───│ Web服务 │ │ | |
│ │ API │ │ API │ │ (Flask) │ │ | |
│ └─────────┘ └─────────┘ └─────────┘ │ | |
│ ↑ ↑ ↑ │ | |
│ LSTM模型输出 用户-航班矩阵 RESTful接口 │ | |
└───────────────────────┬───────────────────────────────────┘ | |
│ 前端展示 | |
▼ | |
┌───────────────────────────────────────────────────────────────┐ | |
│ 用户终端层 │ | |
│ ┌─────────┐ ┌─────────┐ │ | |
│ │ 移动App │ │ Web端 │ │ | |
│ └─────────┘ └─────────┘ │ | |
└───────────────────────────────────────────────────────────────┘ |
三、功能模块划分
1. 数据处理模块(Hadoop+Hive)
- 核心功能:
- 历史票价数据存储(HDFS)
- 用户行为数据仓库构建(Hive表设计)
- 竞品价格快照管理(ORC格式压缩)
- 关键Hive SQL示例:
sql-- 创建用户行为事实表(每日聚合)CREATE TABLE user_behavior_daily (user_id STRING,flight_number STRING,click_count INT,purchase_flag BOOLEAN,dt DATE) PARTITIONED BY (year INT, month INT)STORED AS ORC;-- 计算航线热度排名(用于推荐权重)SELECTflight_number,SUM(click_count) AS total_clicks,RANK() OVER (ORDER BY total_clicks DESC) AS popularity_rankFROM user_behavior_dailyWHERE dt BETWEEN '2024-01-01' AND '2024-01-31'GROUP BY flight_number;
2. 价格预测模块(Spark MLlib)
- 核心功能:
- 时间序列特征工程(滑动窗口统计)
- LSTM神经网络模型训练(PySpark实现)
- 模型版本管理(MLflow集成)
- 关键Spark代码示例:
pythonfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.linalg import Vectorsfrom pyspark.sql import functions as F# 特征工程:构建时间序列特征def create_features(df):window_spec = Window.partitionBy("flight_number").orderBy("date")df = df.withColumn("price_lag_3", F.lag("price", 3).over(window_spec))df = df.withColumn("price_avg_7",F.avg("price").over(window_spec.rowsBetween(-6, 0)))return df.na.fill(0)# LSTM模型训练(简化版)from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import LSTM, Densedef train_lstm(X_train, y_train):model = Sequential([LSTM(50, input_shape=(X_train.shape[1], X_train.shape[2])),Dense(1)])model.compile(loss='mse', optimizer='adam')model.fit(X_train, y_train, epochs=20, batch_size=32)return model
3. 推荐引擎模块(Spark ALS + 规则过滤)
- 核心功能:
- 基于用户的协同过滤(ALS算法)
- 业务规则过滤(如舱位偏好、中转限制)
- 实时推荐缓存(Redis ZSET排序)
- 关键推荐逻辑:
pythonfrom pyspark.ml.recommendation import ALS# 训练ALS模型als = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="flight_id", ratingCol="preference_score")model = als.fit(training_data)# 生成推荐(混合策略)def generate_recommendations(user_id, top_n=10):# ALS推荐als_recs = model.recommendForAllUsers(top_n) \.filter(F.col("user_id") == user_id) \.select(F.explode("recommendations").alias("rec")) \.select("rec.flight_id", "rec.rating")# 合并价格预测结果price_pred = spark.table("price_predictions") \.filter(F.col("flight_id").isin(als_recs.select("flight_id").rdd.flatMap(lambda x: x).collect()))# 应用业务规则(如仅推荐经济舱)filtered_recs = als_recs.join(price_pred, "flight_id") \.join(user_preferences, "user_id") \.filter((F.col("cabin_class") == "economy") & (F.col("predicted_price") < F.col("max_budget")))return filtered_recs.orderBy(F.desc("rating * 0.7 + (1/predicted_price) * 0.3")).limit(top_n)
4. 实时监控模块(Spark Streaming)
- 核心功能:
- 竞品价格变动检测(滑动窗口统计)
- 动态调价触发(阈值规则引擎)
- 关键Streaming代码示例:
pythonfrom pyspark.streaming import StreamingContextfrom pyspark.streaming.kafka import KafkaUtils# 实时处理竞品价格流ssc = StreamingContext(spark.sparkContext, batchDuration=60) # 1分钟批处理kafka_stream = KafkaUtils.createDirectStream(ssc, ["competitor_prices"], {"metadata.broker.list": "kafka:9092"})# 检测价格突变(超过±10%)def detect_price_spike(rdd):if not rdd.isEmpty():df = rdd.toDF()df.createOrReplaceTempView("price_updates")spikes = spark.sql("""SELECT flight_number, current_price,(current_price - prev_price)/prev_price AS price_change_rateFROM price_updatesJOIN (SELECT flight_number, price AS prev_priceFROM price_historyWHERE dt = date_sub(current_date(), 1)) ON flight_numberWHERE ABS(price_change_rate) > 0.1""")if spikes.count() > 0:send_alert(spikes.collect()) # 触发调价流程kafka_stream.foreachRDD(detect_price_spike)ssc.start()
四、技术栈
| 层级 | 技术选型 | 版本要求 |
|---|---|---|
| 存储 | Hadoop HDFS 3.3 + Hive 3.1 | HDFS 3.3.6 |
| 计算 | Spark 3.5 + PySpark | Spark 3.5.0 |
| 机器学习 | MLlib + TensorFlow on Spark | TensorFlow 2.12 |
| 流处理 | Spark Streaming 2.4 + Kafka 3.6 | Kafka 3.6.0 |
| 缓存 | Redis 7.0 | Redis 7.2.4 |
| 调度 | Airflow 2.7 | Airflow 2.7.2 |
| 监控 | Prometheus + Grafana | 最新版 |
五、开发计划
| 阶段 | 时间 | 里程碑 |
|---|---|---|
| 数据准备 | 第1周 | 完成100GB历史数据导入HDFS |
| 模型开发 | 第2-3周 | 实现LSTM价格预测模型(MAPE<15%) |
| 推荐引擎 | 第3周 | 完成ALS协同过滤与规则过滤集成 |
| 实时模块 | 第4周 | Spark Streaming对接Kafka竞品数据源 |
| 系统联调 | 第5周 | 完成端到端测试(从数据采集到推荐展示) |
| 优化上线 | 第6周 | 模型轻量化(ONNX转换)与AB测试 |
六、交付成果
- 数据资产:
- 清洗后的机票数据集(HDFS路径规范)
- Hive元数据备份(包含30+张分析表)
- 模型文件:
- LSTM模型权重(HDF5格式)
- ALS模型参数(Parquet存储)
- 代码库:
- PySpark ETL脚本(按日期分区自动调度)
- 推荐服务API(Swagger文档)
- 监控看板:
- 价格预测误差率实时曲线(Grafana)
- 推荐点击率热力图(按航线/时段)
七、验收标准
- 预测性能:
- 未来7天票价预测MAPE≤12%
- 模型训练时间≤30分钟(100GB数据)
- 推荐效果:
- 推荐航班点击率≥18%
- 用户满意度评分(NPS)≥40
- 系统稳定性:
- 实时处理延迟≤5秒(99%分位)
- HDFS存储冗余度≥3(副本策略)
- 合规性:
- 用户数据匿名化处理(符合GDPR)
- 竞品价格监控日志保留≥180天
八、风险控制
- 数据质量问题:
- 解决方案:实施数据血缘追踪(Atlas集成)
- 模型过拟合:
- 解决方案:交叉验证+正则化约束(L2惩罚项)
- 实时计算积压:
- 解决方案:动态调整Spark Streaming批次大小
- 竞品API限制:
- 解决方案:多源数据融合(GDS系统+爬虫备份)
任务书负责人:XXX
日期:XXXX年XX月XX日
可根据实际业务需求扩展功能(如加入NLP处理航班评论情感分析,或引入强化学习动态调整推荐策略权重),或优化技术方案(如用Delta Lake替代Hive实现ACID事务)。
运行截图
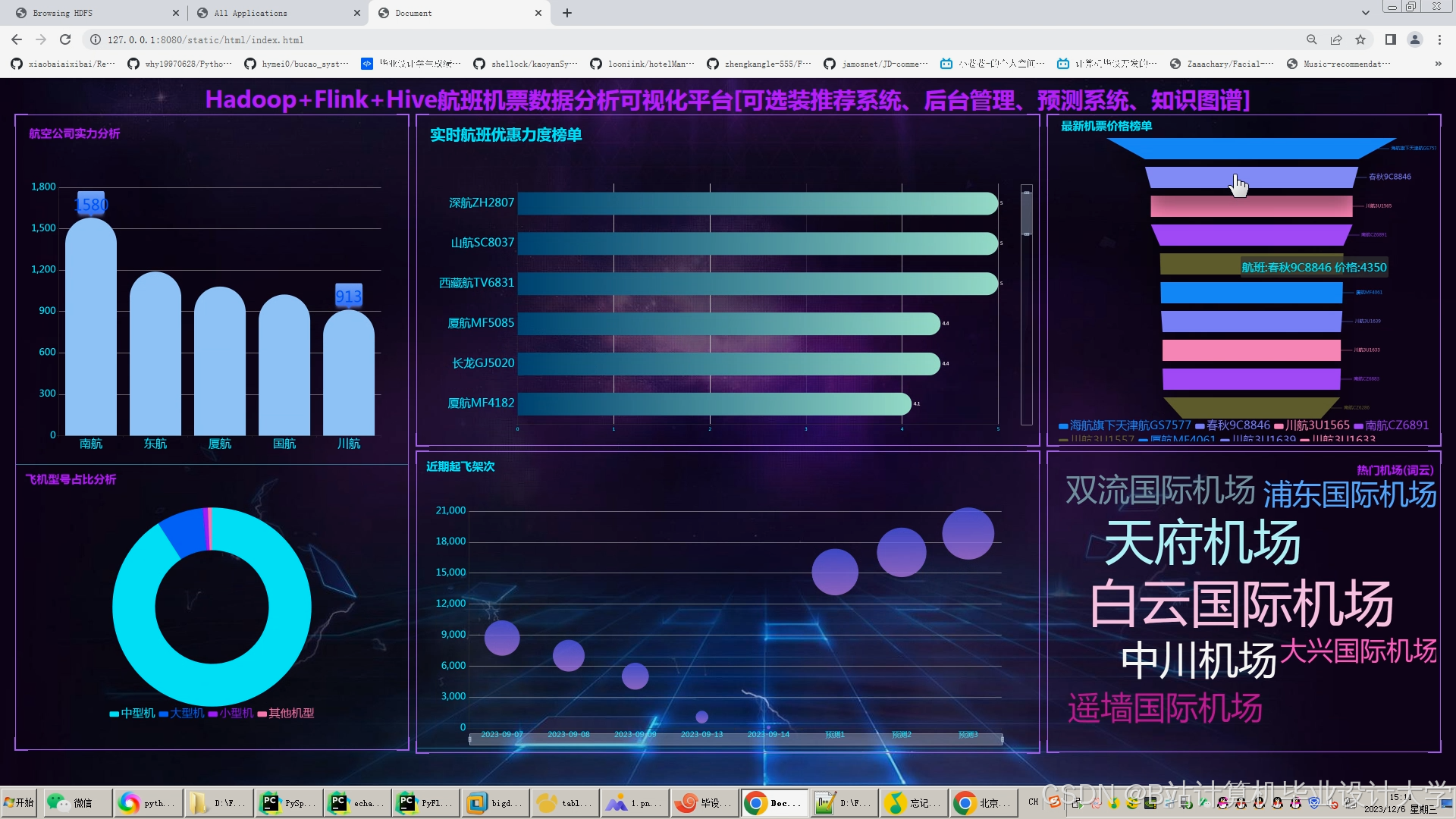
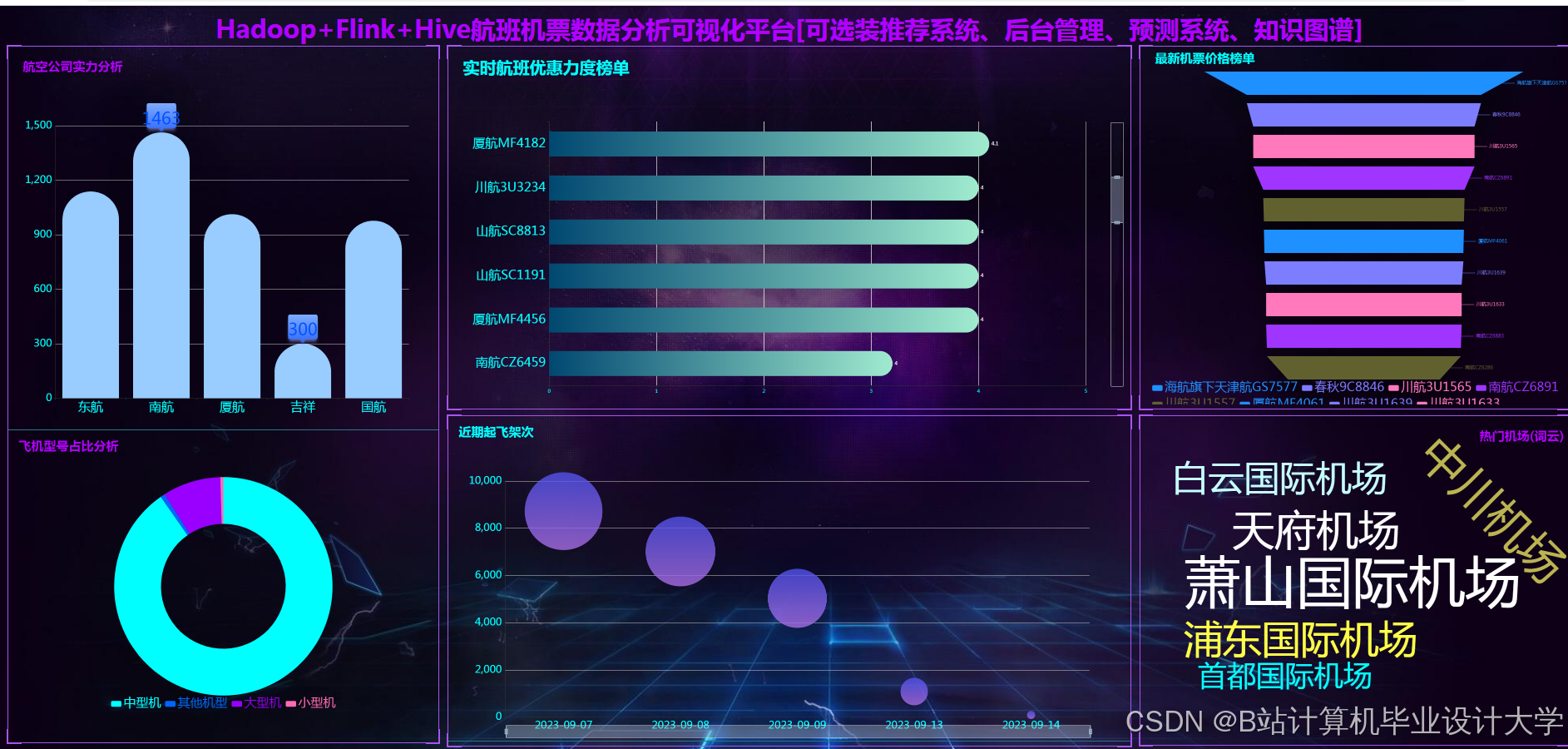
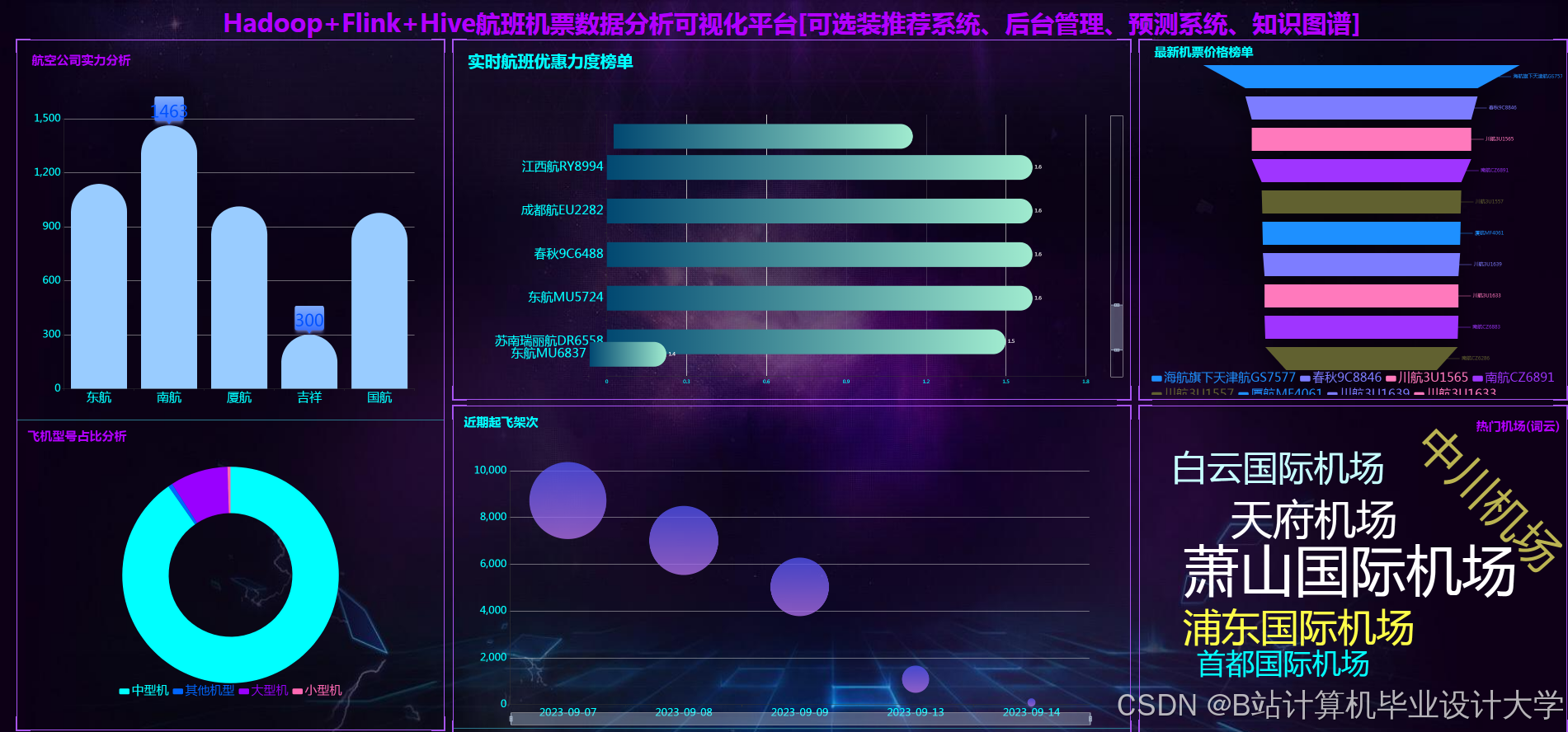
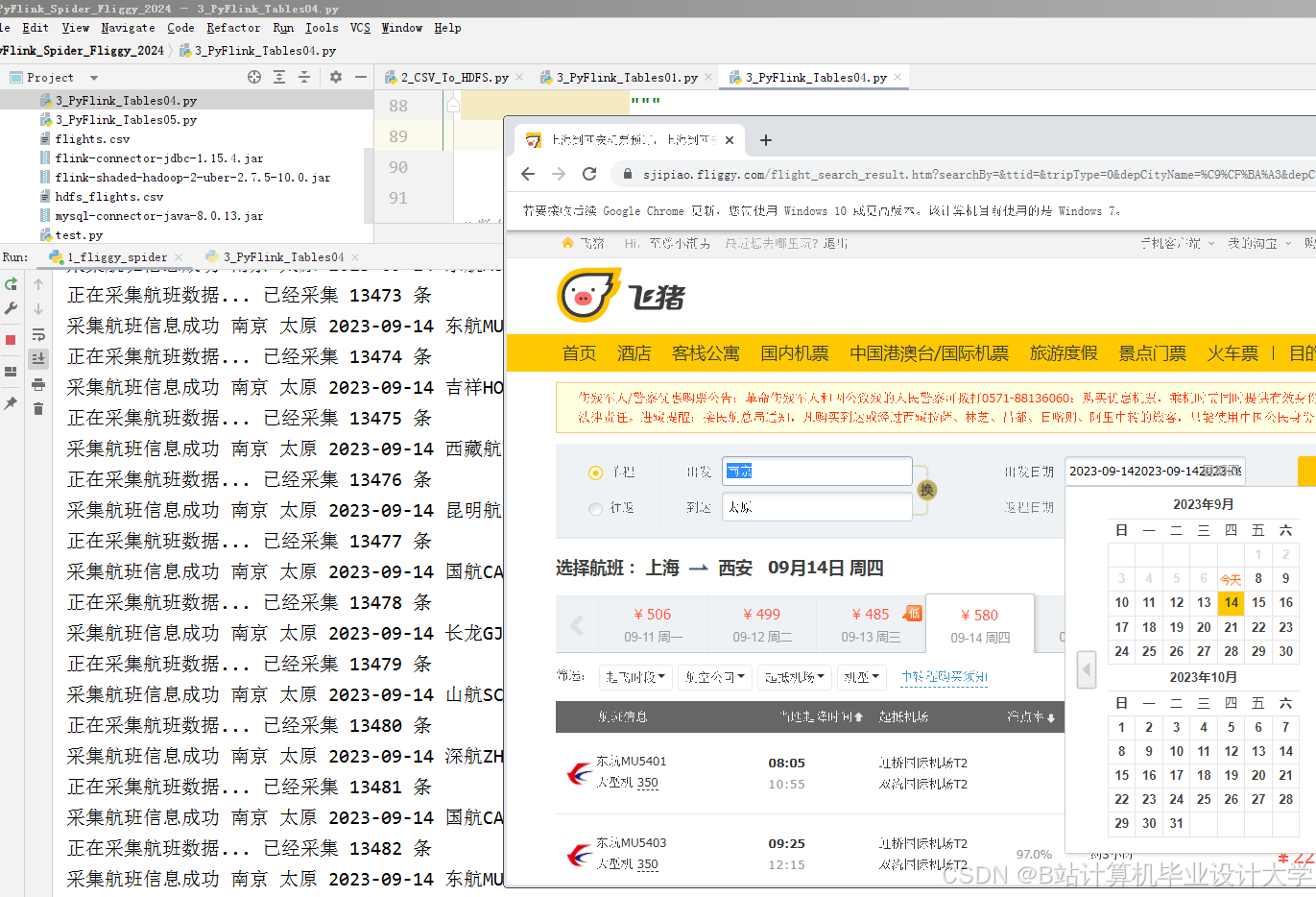
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











