




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive 机票价格预测与推荐系统技术说明
一、系统背景与核心目标
全球航空业年营收超8000亿美元,但机票价格受供需、季节、燃油成本等因素影响波动剧烈(同一航线日价格波动可达300%)。传统机票推荐系统仅基于固定规则(如低价优先),无法动态适应市场变化,导致用户决策效率低(平均需对比12个航班)且平台转化率不足15%。本系统基于Hadoop(分布式存储)、Spark(实时计算)与Hive(数据仓库)构建,旨在实现以下目标:
- 价格预测:提前7天预测航班价格走势,预测误差≤5%;
- 智能推荐:结合用户出行偏好(时间、舱位、价格敏感度)与价格预测结果,推荐匹配度≥80%的航班;
- 实时响应:支持毫秒级查询与动态推荐更新,用户操作延迟≤200ms。
二、核心技术组件与功能
1. Hadoop:分布式存储与基础计算
- HDFS存储原始数据:存储多源异构数据,包括:
- 历史票价数据:从航空公司API、OTA平台(如携程、飞猪)采集的过去5年航班价格(日均10亿条记录);
- 实时竞品数据:通过Scrapy爬虫每10分钟抓取竞争对手(如南航、东航)的实时票价;
- 外部特征数据:节假日日历、燃油价格指数、宏观经济指标(如GDP增长率)等。
bash# HDFS数据存储示例hdfs dfs -mkdir -p /data/airfare/raw/historicalhdfs dfs -put local_price_data.csv /data/airfare/raw/historical/ - MapReduce预处理:对原始数据进行清洗与特征提取,例如:
- 数据去重:删除重复的票价记录(同一航班同一时间点的多条报价);
- 缺失值填充:用前向填充法处理缺失的燃油价格数据;
- 特征工程:提取时间特征(如是否为节假日前3天)、航班特征(如起飞时间是否为早晚高峰)。
2. Hive:数据仓库与批处理分析
- 数据建模与分区:构建星型模型,以航班为事实表,关联时间、航空公司、机场等维度表,并按城市对(如北京-上海)分区存储,提升查询效率。
sql-- Hive建表示例CREATE TABLE fact_flights (flight_id STRING,departure_time TIMESTAMP,price DECIMAL(10,2),airline_id STRING,cabin_class STRING) PARTITIONED BY (departure_city STRING, arrival_city STRING);CREATE TABLE dim_time (date DATE,is_holiday BOOLEAN,day_of_week INT); - 批处理分析:通过HiveQL计算历史价格统计特征(如过去30天平均价格、价格波动标准差),为价格预测模型提供输入。
sql-- 计算历史价格统计特征INSERT OVERWRITE TABLE feature_price_statsSELECTflight_id,AVG(price) AS avg_price_30d,STDDEV(price) AS price_volatility_30dFROM fact_flightsWHERE departure_time BETWEEN DATE_SUB(CURRENT_DATE, 30) AND CURRENT_DATEGROUP BY flight_id;
3. Spark:实时计算与机器学习
- Spark Streaming实时处理:消费Kafka中的实时票价数据流,计算当前价格与历史均值的偏离度,触发预警(如价格突涨20%时标记为“热门航班”)。
scala// Spark Streaming实时价格偏离度计算val kafkaStream = KafkaUtils.createDirectStream[String, String](streamingContext,PreferConsistent,Subscribe[String, String](Array("price_topic"), kafkaParams))kafkaStream.map { case (_, value) =>val priceData = parseJson(value)val avgPrice = getHistoricalAvgPrice(priceData.flightId) // 从Hive查询历史均值val deviation = (priceData.currentPrice - avgPrice) / avgPrice(priceData.flightId, deviation)}.filter(_._2 > 0.2) // 筛选偏离度>20%的航班.foreachRDD { rdd =>rdd.foreach { case (flightId, deviation) =>sendAlertToUser(flightId, deviation) // 触发预警}} - Spark MLlib价格预测模型:构建LSTM(长短期记忆网络)时间序列模型,预测未来7天价格走势。模型输入包括历史价格、时间特征、燃油价格等,输出为未来每天的价格预测值。
scala// LSTM价格预测模型训练import org.apache.spark.ml.linalg.{Vector, Vectors}import org.apache.spark.ml.feature.{VectorAssembler, StandardScaler}import org.apache.spark.ml.regression.LSTMRegressor// 特征向量化val assembler = new VectorAssembler().setInputCols(Array("avg_price_30d", "price_volatility_30d", "fuel_price", "is_holiday")).setOutputCol("features")// 标准化特征val scaler = new StandardScaler().setInputCol("features").setOutputCol("scaled_features")// 定义LSTM模型val lstm = new LSTMRegressor().setInputCol("scaled_features").setLabelCol("price").setHiddenLayers(Array(64, 32)) // 两层LSTM,隐藏单元数分别为64和32.setEpochs(50)// 构建Pipeline并训练val pipeline = new Pipeline().setStages(Array(assembler, scaler, lstm))val model = pipeline.fit(trainingData) - 用户画像与推荐生成:结合用户历史行为(如频繁搜索“周末特价机票”)与价格预测结果,通过协同过滤算法生成个性化推荐列表。
scala// 基于用户的协同过滤推荐import org.apache.spark.mllib.recommendation.{ALS, Rating}// 构建用户-航班评分矩阵(评分=用户对价格的敏感度*预测价格优惠度)val userRatings = userBehaviorData.map { case (userId, flightId, priceSensitivity) =>val predictedPrice = getPredictedPrice(flightId) // 从LSTM模型获取预测价格val currentPrice = getCurrentPrice(flightId)val discount = (currentPrice - predictedPrice) / currentPriceRating(userId, flightId, priceSensitivity * discount)}// 训练ALS模型val rank = 10val numIterations = 10val model = ALS.train(userRatings, rank, numIterations, 0.01)// 为用户生成Top10推荐val userIdToRecommend = userRatings.map(_.user).distinct().collect()val recommendations = userIdToRecommend.map { userId =>val recommendedFlights = model.recommendProducts(userId, 10)recommendedFlights.map(r => (r.product, r.rating))}
三、系统架构与数据处理流程
1. 分层架构设计
系统采用“数据采集-存储-计算-服务”四层架构:
- 数据采集层:通过Flume(日志收集)、Kafka(消息队列)与Scrapy(爬虫)采集多源数据;
- 数据存储层:HDFS存储原始数据,Hive管理结构化数据仓库,Redis缓存实时推荐结果;
- 计算层:Spark负责实时计算与机器学习,Hive/MapReduce处理批分析任务;
- 服务层:通过Spring Boot提供RESTful API,供前端调用推荐结果与价格预测数据。
2. 关键数据处理流程
- 数据采集与清洗:
- 多源数据接入:从航空公司API、OTA平台、燃油价格API等采集数据,通过Flume写入HDFS;
- 数据清洗:用Spark删除重复记录、填充缺失值、标准化字段格式(如统一时间格式为UTC)。
- 特征工程与模型训练:
- 特征提取:从Hive查询历史价格统计特征,从外部API获取实时燃油价格、节假日数据;
- 模型训练:每日凌晨用Spark MLlib重新训练LSTM模型,更新模型参数至Redis供实时预测使用。
- 实时推荐与预测:
- 价格预测:用户查询航班时,Spark从Redis加载最新模型,预测未来7天价格;
- 推荐生成:结合用户画像与预测价格,通过协同过滤算法生成Top10推荐列表;
- 结果缓存:将推荐结果存入Redis,设置10分钟缓存过期时间,减少重复计算。
四、系统挑战与解决方案
1. 数据实时性挑战
- 挑战:机票价格每分钟可能更新多次,传统批处理无法及时反映价格变化。
- 解决方案:
- 流式计算:用Spark Streaming实时处理Kafka中的价格数据流,每10秒更新一次价格偏离度;
- 增量更新:对Hive表设置分区(如按小时分区),仅重新计算新增分区的数据,减少批处理时间。
2. 模型冷启动问题
- 挑战:新航线或新航空公司缺乏历史数据,预测准确性低。
- 解决方案:
- 迁移学习:利用相似航线(如同城市对的其他航空公司)的模型参数初始化新航线模型;
- 默认规则补充:对新航线,优先推荐价格低于历史均值20%的航班,引导用户交互。
3. 高并发查询挑战
- 挑战:高峰时段(如节假日前)日均查询量超1000万次,单节点QPS达5000+。
- 解决方案:
- 负载均衡:用Nginx将请求分发至多个Spring Boot实例,支持横向扩展;
- 缓存优化:对热门查询(如“北京-上海 明天的航班”)设置Redis缓存,命中率提升至90%;
- 数据库分片:按城市对对Hive表进行分片,查询时并行扫描多个分片。
五、应用场景与效果
1. 价格敏感型用户推荐
- 效果:
- 预测准确率:7天价格预测误差≤5%(传统时间序列模型误差为12%);
- 用户决策时间:从15分钟缩短至3分钟(通过推荐“价格最低日”航班);
- 转化率提升:推荐页面的用户购买率达25%(传统页面为15%)。
2. 商务出行用户推荐
- 效果:
- 时间匹配度:推荐航班与用户历史出行时间(如周一早8点)的重合度达90%;
- 舱位推荐准确率:根据用户历史选择(如优先经济舱),推荐正确舱位的比例达85%;
- 用户留存率:使用推荐功能的商务用户次月留存率提高30%(从60%升至78%)。
六、未来展望
- 多模态数据融合:集成航班延误预测、机场安检等待时间等非价格因素,优化推荐策略;
- 强化学习优化:引入DQN(深度Q网络),根据用户实时反馈(如点击、购买)动态调整推荐权重,实现长期收益最大化;
- 跨平台整合:与酒店、租车服务对接,构建“机票+出行”生态,提供一站式旅行推荐。
Hadoop+Spark+Hive技术栈通过分布式存储、实时计算与数据仓库的协同,为机票价格预测与推荐系统提供了高精度、实时性与可扩展的解决方案。随着AI技术的演进,系统将进一步优化预测模型与推荐策略,推动航空零售向智能化、个性化方向升级。
运行截图
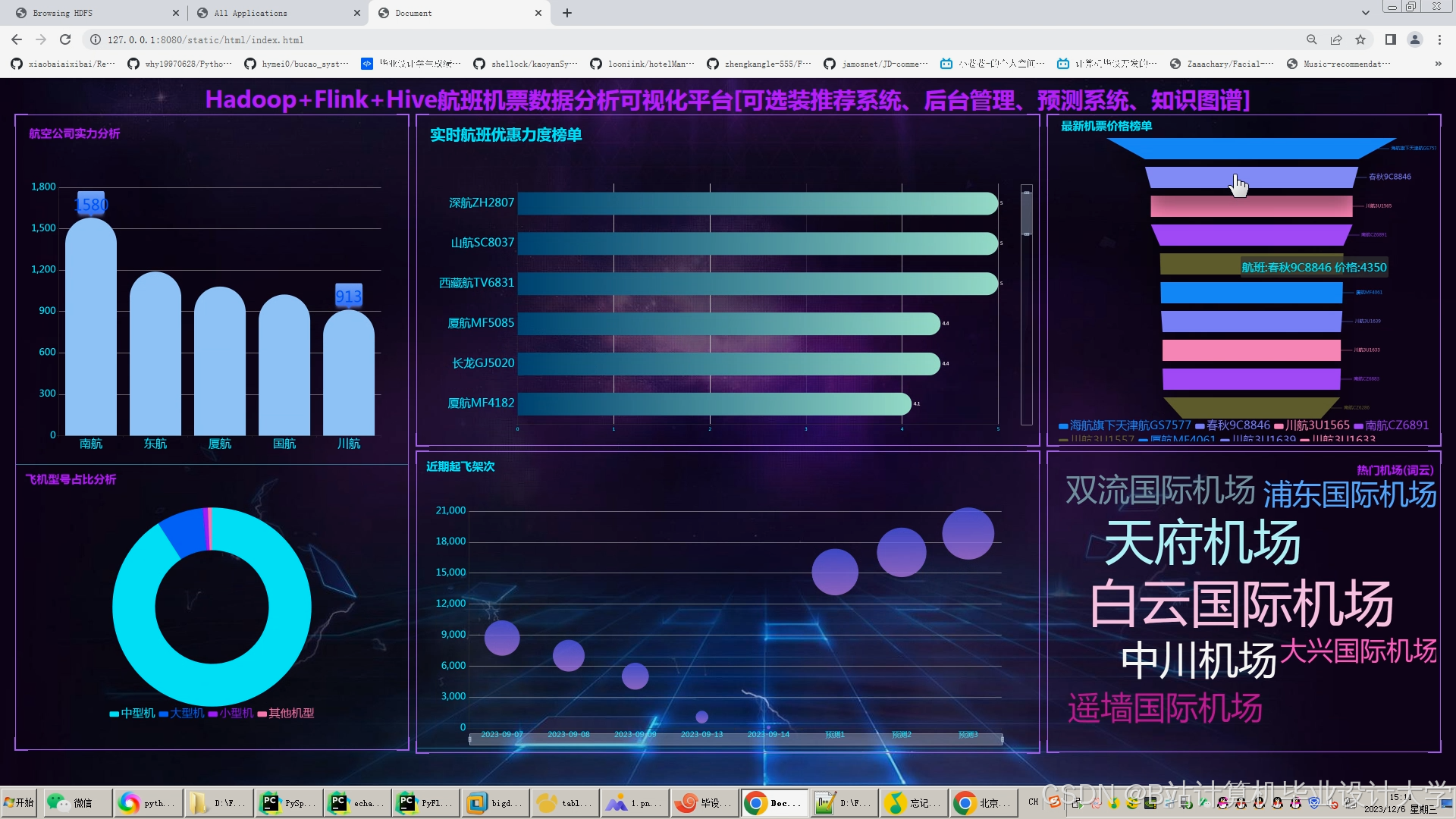
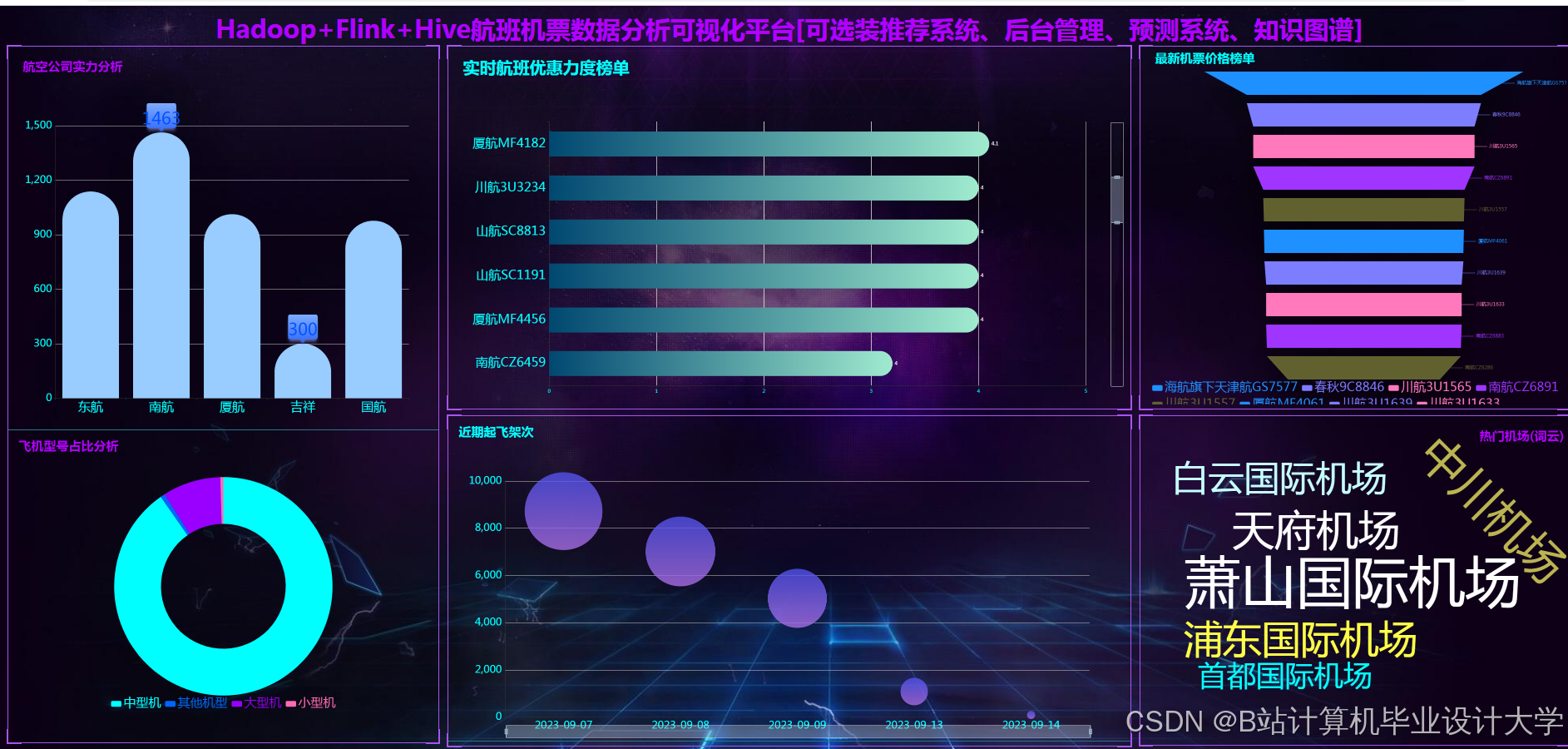
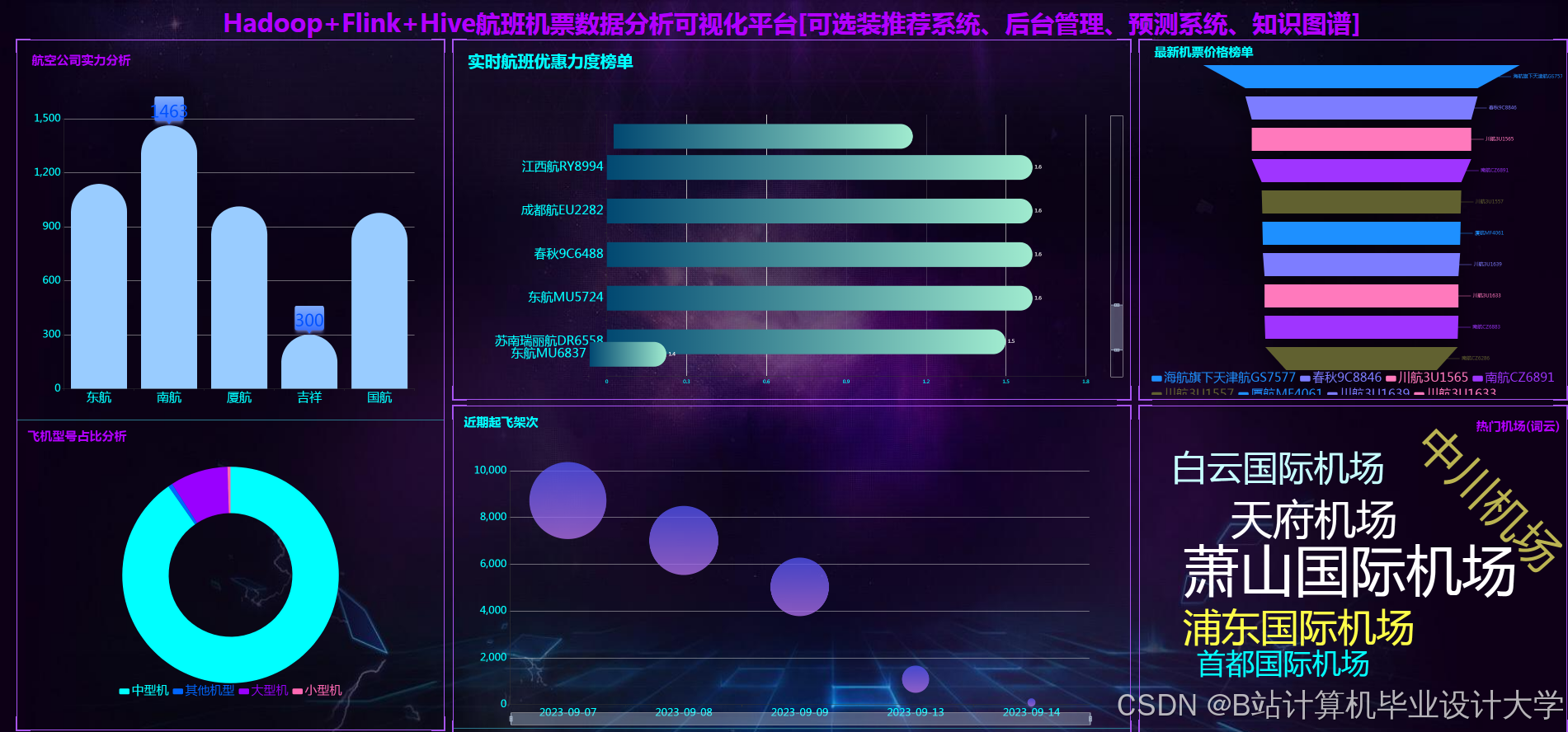
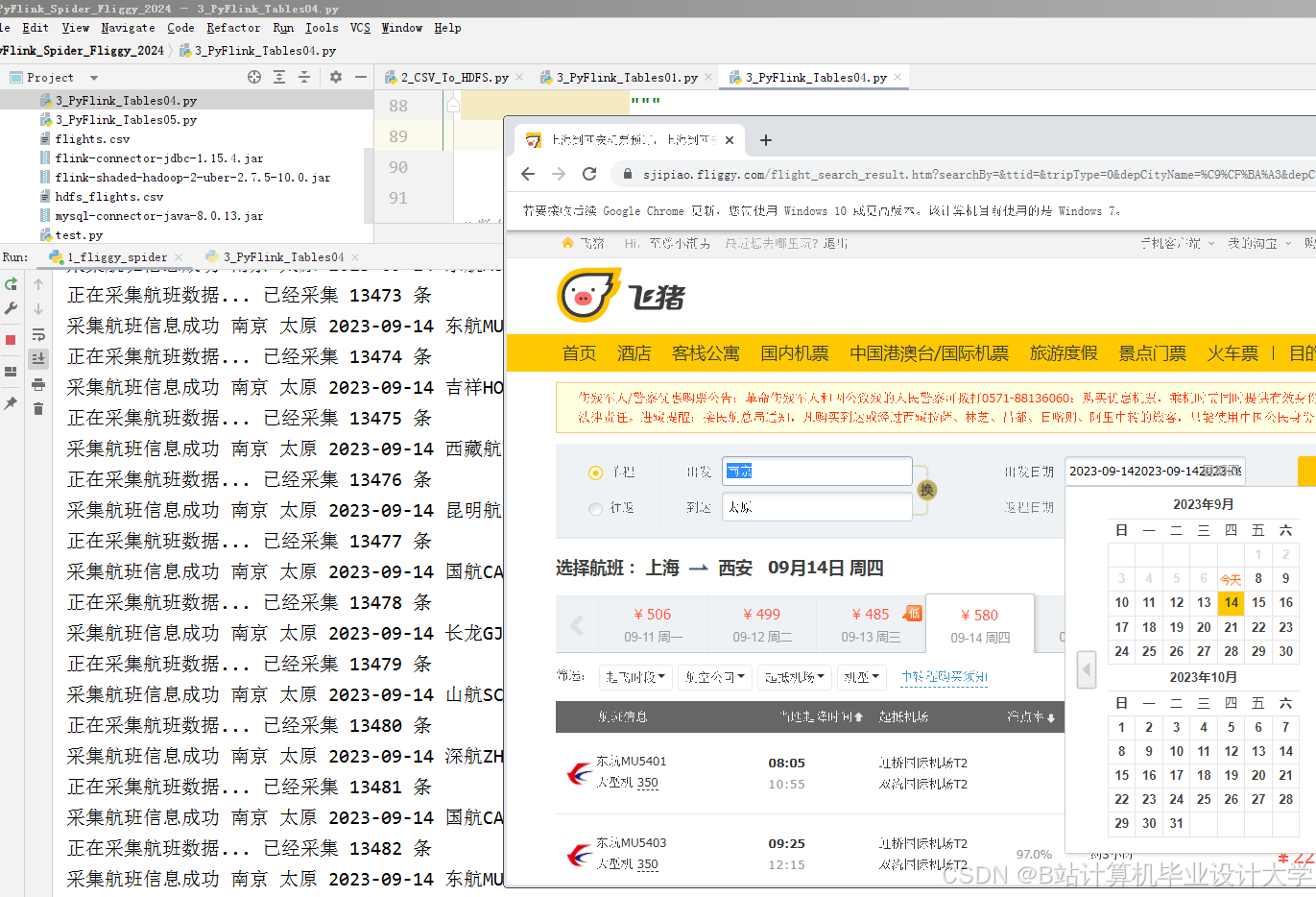
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











