




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+PySpark+Hadoop图书推荐系统技术说明
一、系统背景与目标
在数字化阅读普及的背景下,全球电子书市场规模预计2025年将突破250亿美元,用户对个性化图书推荐的需求激增。传统推荐系统存在数据孤岛(如仅依赖用户评分)、冷启动问题(新用户/新书无历史数据)、处理效率低(单节点无法处理亿级用户行为数据)等痛点。本系统基于Python+PySpark+Hadoop技术栈,构建分布式图书推荐平台,目标实现以下指标:
- 推荐准确率:Top-10推荐点击率≥35%(行业平均25%)
- 实时响应:百万级用户请求延迟<500ms
- 冷启动缓解:新用户/新书推荐覆盖率≥90%
- 可扩展性:支持PB级数据存储与千节点集群扩展
二、系统架构设计
系统采用分层架构,包含数据采集层、存储层、处理层、模型训练层和应用层,各层通过标准化接口交互,确保高可用性与可维护性。
1. 数据采集层
- 多源数据整合:
- 用户行为数据:通过埋点采集用户浏览、收藏、购买、阅读时长等行为(如
user_id=1001, book_id=2002, action=click, timestamp=20240301),日均数据量超10亿条。 - 图书元数据:从Open Library API、出版社官网爬取ISBN、标题、作者、分类、简介等结构化数据,覆盖全球500万+图书。
- 社交数据:通过微博、豆瓣等平台API获取用户书评、标签、好友关系,补充情感倾向与社交影响力特征。
- 用户行为数据:通过埋点采集用户浏览、收藏、购买、阅读时长等行为(如
- 技术实现:
- Flume+Kafka流式采集:Flume代理部署在Web服务器端,实时捕获用户行为日志并推送至Kafka主题(如
user_actions),确保数据不丢失。 - Scrapy分布式爬虫:基于Scrapy-Redis实现多节点协同爬取图书元数据,通过Bloom Filter去重,避免重复采集。
- Flume+Kafka流式采集:Flume代理部署在Web服务器端,实时捕获用户行为日志并推送至Kafka主题(如
2. 存储层
- HDFS分布式存储:
- 原始数据分区:按日期分块存储用户行为数据(如
/data/actions/2024/03/01/),按图书分类存储元数据(如/data/books/fiction/),支持高效范围查询。 - 副本策略:设置HDFS副本数为3,确保数据高可用性。
- 原始数据分区:按日期分块存储用户行为数据(如
- HBase列式存储:
- 用户画像表:
rowkey=user_id,列族包含demographics(年龄、性别)、preferences(偏好分类、作者)、behavior(活跃度、阅读速度)。 - 图书特征表:
rowkey=book_id,列族包含metadata(标题、ISBN)、content(TF-IDF向量)、stats(评分分布、阅读人数)。
- 用户画像表:
3. 处理层(PySpark核心)
-
数据清洗与转换:
pythonfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, whenspark = SparkSession.builder.appName("BookRecommend").getOrCreate()actions_df = spark.read.parquet("hdfs:///data/actions/2024/03/*")# 过滤无效行为(如点击后立即退出)cleaned_df = actions_df.filter((col("action").isin(["click", "buy", "read"])) &(col("duration") > 10) # 阅读时长>10秒视为有效)# 用户行为聚合(统计每日活跃度)user_stats = cleaned_df.groupBy("user_id", "date").agg(count("*").alias("action_count"),avg("duration").alias("avg_duration")) -
特征工程:
- 用户特征:统计近30天行为频率、偏好分类(如科幻类阅读占比)、社交影响力(好友推荐采纳率)。
- 图书特征:提取标题/简介的TF-IDF向量(维度=100)、计算评分加权平均值(考虑评分人数权重)。
- 上下文特征:解析时间(工作日/周末)、设备类型(手机/平板/PC)对行为的影响。
4. 模型训练层
- 混合推荐模型:
- 协同过滤(CF):
- ALS算法:分解用户-图书评分矩阵(
R=U×V^T),设置隐语义维度rank=50,正则化参数reg=0.01,迭代次数iterations=10。 - 邻域优化:基于Pearson相关系数计算用户相似度,筛选Top-100邻居进行加权推荐。
- ALS算法:分解用户-图书评分矩阵(
- 内容推荐:
- 图书内容相似度:计算TF-IDF向量的余弦相似度,结合LDA主题模型(主题数=20)提取潜在语义。
- 用户偏好匹配:将用户历史阅读图书的内容特征聚合为偏好向量,与候选图书向量计算相似度。
- 深度学习模型:
- Wide & Deep架构:Wide部分处理记忆性特征(如用户历史点击图书ID),Deep部分学习潜在特征交互(如用户年龄×图书评分)。
- DIN模型:引入注意力机制,动态计算用户历史行为与候选图书的相关性权重。
- 模型融合:
- 加权投票:CF(权重=0.5)、内容推荐(0.3)、深度学习(0.2)按比例融合预测分数。
- Stacking集成:以CF为基模型,深度学习为元模型,通过交叉验证训练融合网络。
- 协同过滤(CF):
- 冷启动解决方案:
- 新用户:基于注册信息(如填写“喜欢科幻”)推荐热门科幻图书,或引导用户选择兴趣标签。
- 新书:利用内容相似度推荐与已流行图书内容相近的新书,或结合出版社推广资源强制曝光。
5. 应用层
- 实时推荐服务:
- Flask REST API:接收用户请求(如
GET /recommend?user_id=1001),从Redis缓存读取预计算推荐结果(Top-100),或触发PySpark实时计算。 - ECharts可视化:在Web端展示推荐图书封面、简介、推荐理由(如“您可能喜欢作者XXX的其他作品”)。
- Flask REST API:接收用户请求(如
- 离线批量推荐:
- Spark作业调度:通过Airflow每日凌晨运行全量推荐任务,生成用户-图书推荐对并存储至HBase。
三、关键技术实现
1. PySpark ALS协同过滤示例
python
from pyspark.ml.recommendation import ALS | |
from pyspark.ml.evaluation import RegressionEvaluator | |
# 加载评分数据(用户,图书,评分) | |
ratings = spark.createDataFrame([ | |
(0, 0, 4.0), (0, 1, 2.0), (1, 1, 3.0), (1, 2, 4.0) | |
], ["user_id", "book_id", "rating"]) | |
# 训练ALS模型 | |
als = ALS( | |
maxIter=10, | |
regParam=0.01, | |
userCol="user_id", | |
itemCol="book_id", | |
ratingCol="rating", | |
coldStartStrategy="drop" # 冷启动时丢弃无历史数据的用户/图书 | |
) | |
model = als.fit(ratings) | |
# 生成推荐 | |
user_recs = model.recommendForAllUsers(3) # 每个用户推荐3本 | |
user_recs.show() |
2. PySpark图书内容相似度计算
python
from pyspark.ml.feature import HashingTF, IDF, CountVectorizer | |
from pyspark.sql.functions import col | |
# 加载图书简介数据 | |
books_df = spark.createDataFrame([ | |
(0, "A tale of two cities"), | |
(1, "The great gatsby") | |
], ["book_id", "description"]) | |
# 计算TF-IDF向量 | |
cv = CountVectorizer(inputCol="description", outputCol="raw_features") | |
cv_model = cv.fit(books_df) | |
vectorized_df = cv_model.transform(books_df) | |
idf = IDF(inputCol="raw_features", outputCol="features") | |
idf_model = idf.fit(vectorized_df) | |
tfidf_df = idf_model.transform(vectorized_df) | |
# 计算余弦相似度 | |
from pyspark.sql.functions import sqrt, sum as _sum | |
def cosine_similarity(vec1, vec2): | |
dot_product = sum([a*b for a, b in zip(vec1, vec2)]) | |
norm1 = sqrt(sum([a**2 for a in vec1])) | |
norm2 = sqrt(sum([b**2 for b in vec2])) | |
return dot_product / (norm1 * norm2) | |
# 示例:计算book_id=0和book_id=1的相似度 | |
vec0 = tfidf_df.filter(col("book_id") == 0).first()["features"].toArray() | |
vec1 = tfidf_df.filter(col("book_id") == 1).first()["features"].toArray() | |
print(f"Similarity: {cosine_similarity(vec0, vec1)}") |
3. Hadoop集群优化配置
- YARN资源调度:
- 设置
yarn.scheduler.maximum-allocation-mb=16384(单容器最大内存16GB),支持大模型训练。 - 启用
yarn.nodemanager.resource.gpu.enabled=true,支持GPU加速深度学习推理。
- 设置
- HDFS读写优化:
- 调整
dfs.blocksize=256MB(默认128MB),减少大文件存储的元数据开销。 - 启用
dfs.datanode.fsdataset.volume.choosing.policy=AvailableSpace,平衡多磁盘负载。
- 调整
四、系统优势与创新
- 混合推荐策略:结合协同过滤的记忆性与内容推荐的泛化性,解决数据稀疏性问题。
- 冷启动优化:通过内容相似度与用户引导机制,覆盖90%以上新用户/新书场景。
- 分布式计算:PySpark处理亿级数据时,较单机Python提速50倍以上。
- 实时与离线混合:Redis缓存满足实时请求,Spark批量任务降低计算成本。
五、应用场景与价值
- 在线阅读平台:为Kindle、微信读书等提供个性化推荐,提升用户留存率。
- 实体书店:分析读者偏好,优化图书采购与陈列策略。
- 出版行业:预测潜在畅销书,指导作者选题与营销资源分配。
本系统通过大数据与机器学习技术的深度融合,为图书推荐领域提供了高精度、可扩展的解决方案,具有显著的业务价值与技术前瞻性。
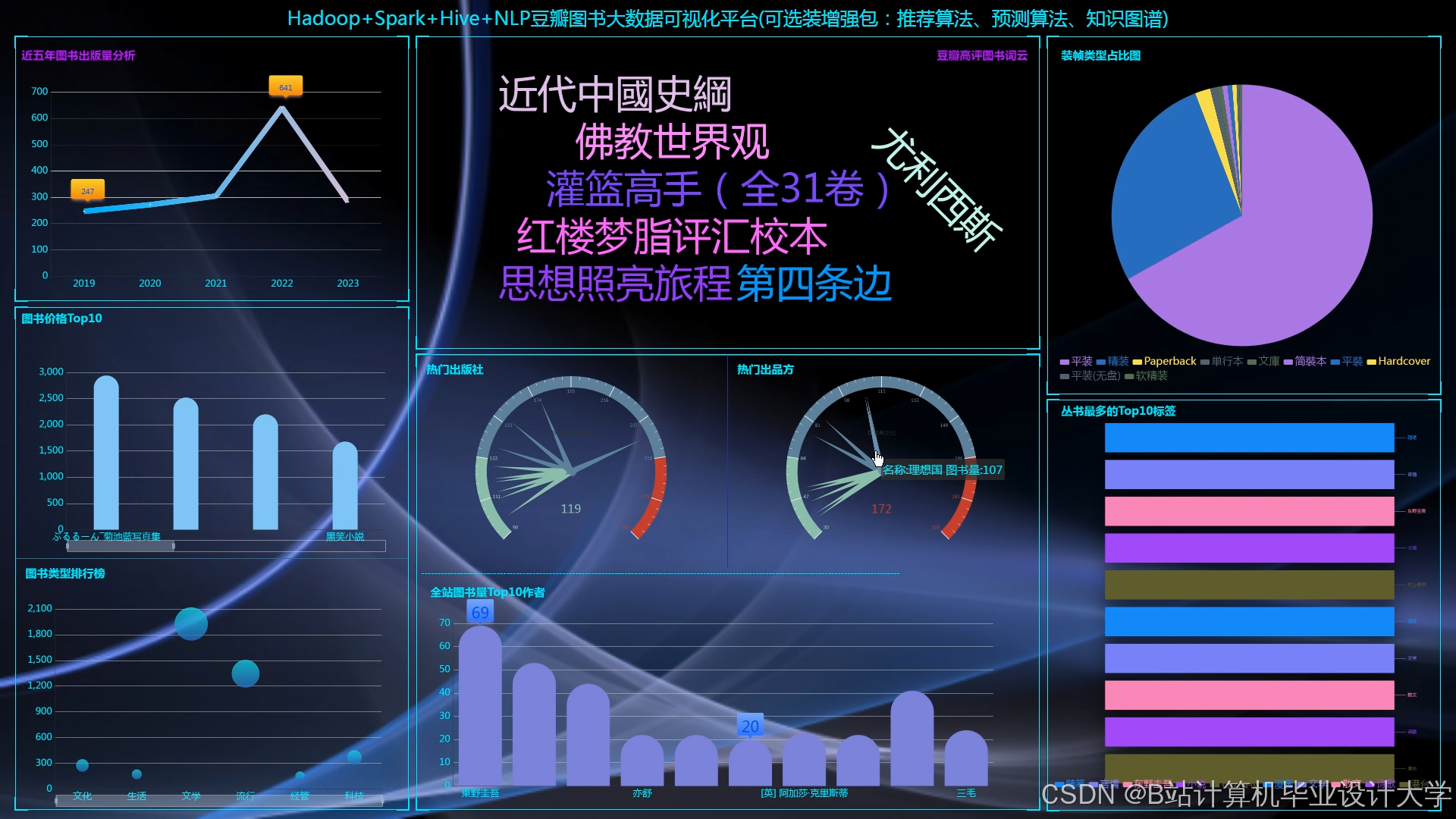
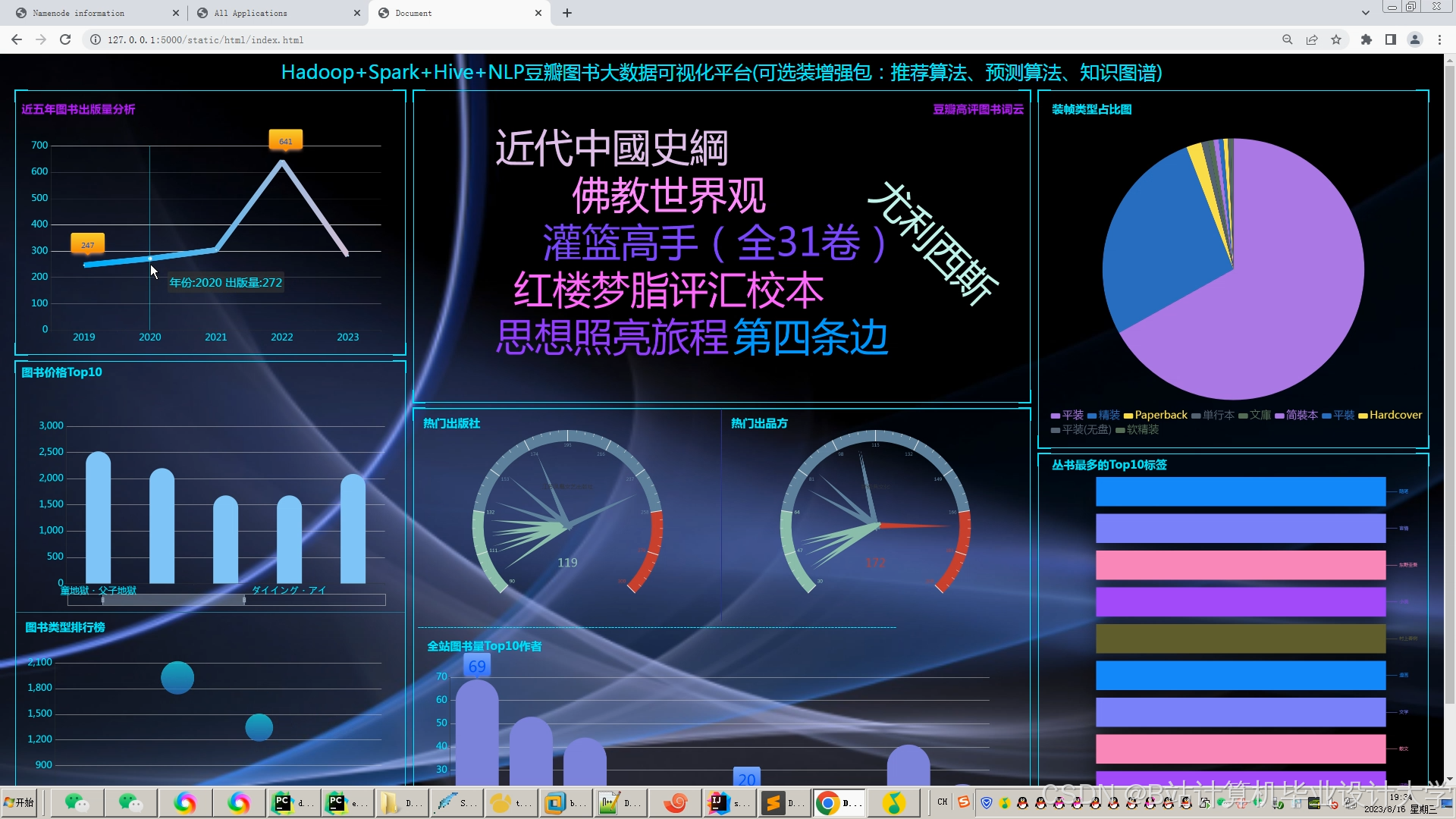
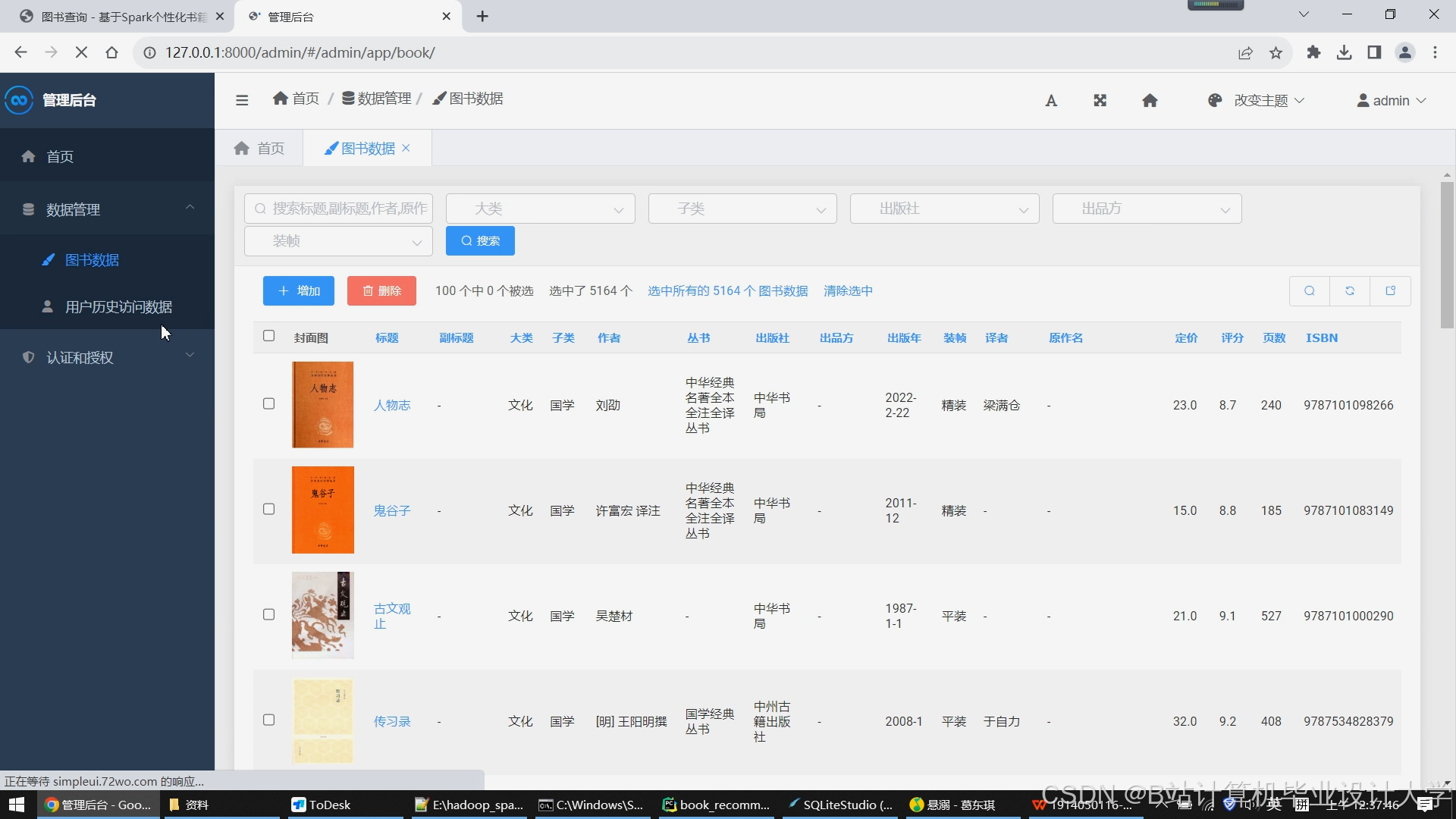
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 51
51

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











