




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive共享单车预测系统与数据可视化分析研究
摘要:本文针对共享单车系统日均千万级骑行记录的高并发、时空依赖性特征,提出基于Hadoop分布式存储、Spark内存计算与Hive数据仓库的预测分析系统。系统通过Flume实时采集设备数据,利用Spark MLlib实现分布式特征工程,结合时空注意力机制的LSTM模型实现站点级需求预测(MAPE≤12%)。实验表明,该系统较传统单机方案处理效率提升40倍,可视化看板支持百万级数据秒级响应,为运营调度提供数据驱动的决策支持。
关键词:共享单车预测;Hadoop;Spark;Hive;时空注意力机制;数据可视化
1. 引言
1.1 研究背景
共享单车作为城市短途出行的重要方式,日均产生超5000万条骑行记录。传统分析系统面临三大挑战:
- 数据规模:单城市日均骑行数据达TB级,MySQL等传统数据库无法支撑;
- 时空特性:需求呈现明显的时空依赖性(如早高峰地铁口需求激增);
- 实时性要求:调度策略需在15分钟内响应需求变化以避免供需失衡。
1.2 研究意义
本研究构建的分布式预测系统实现三大价值:
- 技术层面:验证Hadoop+Spark+Hive技术栈处理高并发时空数据的可行性;
- 业务层面:帮助运营商降低空驶率30%,提升用户满意度15%;
- 学术层面:提出时空注意力机制的LSTM-STA模型,解决传统模型忽略空间交互的缺陷。
2. 系统架构设计
2.1 分层架构模型
系统采用五层架构(图1):
- 数据采集层:通过Flume实时采集设备数据(GPS坐标、锁状态),结合Kafka缓冲订单流数据(峰值吞吐量≥10万条/秒);
- 存储层:HDFS配置2副本存储策略,热数据(近3日高频访问)采用SSD+2副本,冷数据(月访问<5次)使用HDD+EC编码(存储成本降低35%);
- 计算层:Spark实现分布式特征工程,包括:
- 统计特征:7/14/30日站点级需求滚动计算
- 时空特征:POI(兴趣点)距离编码(如地铁站500米内标记为1)
- 时序特征:3小时窗口需求波动率
- 分析层:Hive构建星型模型(事实表:fact_ride_order,维度表:dim_station、dim_time),支持复杂OLAP查询;
- 展示层:Superset开发动态看板,实现全国TOP100热点区域热力图钻取功能。
2.2 核心技术选型依据
- HDFS:支持EB级数据存储,通过
dfs.block.size=256MB优化小文件处理; - Spark:内存计算速度较MapReduce快20倍,支持GraphX图计算分析站点关联性;
- Hive:Parquet列式存储格式压缩率达80%,查询速度提升4倍,Partition Pruning优化技术使分区查询效率提升90%。
3. 关键技术实现
3.1 数据采集与预处理
3.1.1 多源数据接入
- 结构化数据:通过共享单车API获取订单信息(订单ID、用户ID、车辆ID、起点/终点站点、开始/结束时间);
- 半结构化数据:Kafka实时采集JSON格式设备状态日志:
json
{ | |
"bike_id": "B123456", | |
"station_id": "S789012", | |
"status": "locked", | |
"timestamp": 1717185600000, | |
"gps": {"lat": 39.9042, "lng": 116.4074} | |
} |
3.1.2 数据清洗与转换
使用Spark实现异常值处理:
scala
import org.apache.spark.sql.functions._ | |
val dfClean = dfRaw.filter( | |
col("station_id").isNotNull && | |
col("status").isin("locked", "unlocked") && | |
col("timestamp").between(1717100000000L, 1717200000000L) | |
) | |
val dfClean = dfClean.withColumn( | |
"duration", | |
when(col("duration") > 86400, 86400).otherwise(col("duration")) // 限制单次骑行时长≤24小时 | |
) |
3.2 特征工程
3.2.1 时空特征提取
计算站点周边POI密度:
scala
// 定义地铁站500米范围内标记 | |
val metroStations = Seq(("M001", 39.9042, 116.4074), ("M002", 39.9142, 116.4174)) | |
val metroDF = spark.createDataFrame(metroStations).toDF("metro_id", "lat", "lng") | |
// 计算每个骑行订单到最近地铁站的距离 | |
val udfGeoDist = udf((lat1: Double, lng1: Double, lat2: Double, lng2: Double) => { | |
// Haversine公式计算球面距离(单位:千米) | |
val R = 6371.0 | |
val dLat = math.toRadians(lat2 - lat1) | |
val dLng = math.toRadians(lng2 - lng1) | |
val a = math.sin(dLat/2)*math.sin(dLat/2) + | |
math.cos(math.toRadians(lat1))*math.cos(math.toRadians(lat2))* | |
math.sin(dLng/2)*math.sin(dLng/2) | |
val c = 2 * math.atan2(math.sqrt(a), math.sqrt(1-a)) | |
R * c | |
}) | |
val rideWithMetro = dfRide.withColumn("dist_to_metro", | |
udfGeoDist(col("start_lat"), col("start_lng"), | |
col("metro_lat"), col("metro_lng")) | |
).filter(col("dist_to_metro") <= 0.5) // 筛选500米内订单 | |
.withColumn("near_metro", lit(1)) // 标记为靠近地铁站 |
3.2.2 时序特征构建
计算15分钟滑动窗口需求波动率:
scala
import org.apache.spark.sql.expressions.Window | |
val windowSpec = Window.partitionBy("station_id") | |
.orderBy("timestamp") | |
.rangeBetween(-15*60*1000, 0) // 15分钟窗口 | |
val dfTimeFeatures = dfRide.withColumn( | |
"demand_15min", | |
count("order_id").over(windowSpec) // 计算15分钟内订单数 | |
).withColumn( | |
"demand_rate", | |
col("demand_15min") / 15.0 // 计算每分钟需求率 | |
) |
3.2.3 站点关联性分析
基于GraphX构建站点转移图:
scala
import org.apache.spark.graphx._ | |
// 构建边(起点→终点) | |
val edges = dfRide.select("start_station", "end_station") | |
.map(row => Edge(row.getString(0).hashCode, row.getString(1).hashCode, 1)) | |
// 构建顶点(站点) | |
val vertices = dfStation.select("station_id") | |
.map(row => (row.getString(0).hashCode, row.getString(0))) | |
// 构建图并计算PageRank | |
val graph = Graph(vertices, edges) | |
val prGraph = graph.pageRank(0.0001, 0.85) | |
// 获取重要站点排名 | |
val importantStations = prGraph.vertices | |
.sortBy(_._2, ascending = false) | |
.take(100) // 获取Top100重要站点 |
3.3 需求预测模型
3.3.1 混合模型架构
采用LSTM-STA(Spatio-Temporal Attention)架构(图2),输入层接收三类特征:
- 时序特征:48维统计指标(15分钟滑动窗口需求、波动率)
- 空间特征:10维POI编码(地铁站、商场、学校等)
- 外部特征:5维天气数据(温度、湿度、降雨量、风速、是否工作日)
时空注意力层动态计算空间-时间联合权重:
αs,t=∑s′=1S∑t′=1Texp(es′,t′)exp(es,t),es,t=vTtanh(Whhs,t+b)
3.3.2 模型训练优化
- 损失函数:采用Quantile Loss提升分位数预测能力;
- 超参数调优:通过Optuna框架进行贝叶斯优化,确定最佳参数组合(LSTM层数=3,隐藏单元=128);
- 分布式训练:利用Spark的HorovodRunner实现数据并行化,训练时间从单机版8小时缩短至1.5小时。
4. 系统实现与测试
4.1 集群性能调优
- HDFS优化:设置
dfs.datanode.handler.count=32提升高并发写入性能,启用短路径读取(dfs.client.read.shortcircuit=true)减少数据本地化延迟; - Spark优化:调整分区数(
spark.sql.shuffle.partitions=150)避免数据倾斜,启用AQE优化器(spark.sql.adaptive.enabled=true)自动优化执行计划; - Hive优化:设置
hive.exec.dynamic.partition.mode=nonstrict支持动态分区,启用矢量化查询(hive.vectorized.execution.enabled=true)提升聚合性能。
4.2 实验结果分析
4.2.1 模型性能对比
在2025年6月北京市1000个站点测试数据上,LSTM-STA模型较基线模型提升显著:
| 模型 | MAPE | RMSE | R² |
|---|---|---|---|
| ARIMA | 28.5% | 45.2 | 0.62 |
| XGBoost | 22.1% | 38.7 | 0.71 |
| LSTM | 18.3% | 32.1 | 0.78 |
| LSTM-STA | 11.7% | 25.3 | 0.85 |
4.2.2 系统性能测试
- 吞吐量:日均处理1.2亿条骑行记录,数据延迟≤3分钟;
- 响应时间:可视化看板核心指标加载时间≤800ms,支持95%以上交互操作;
- 资源利用率:CPU利用率稳定在70%-80%,内存占用≤55%。
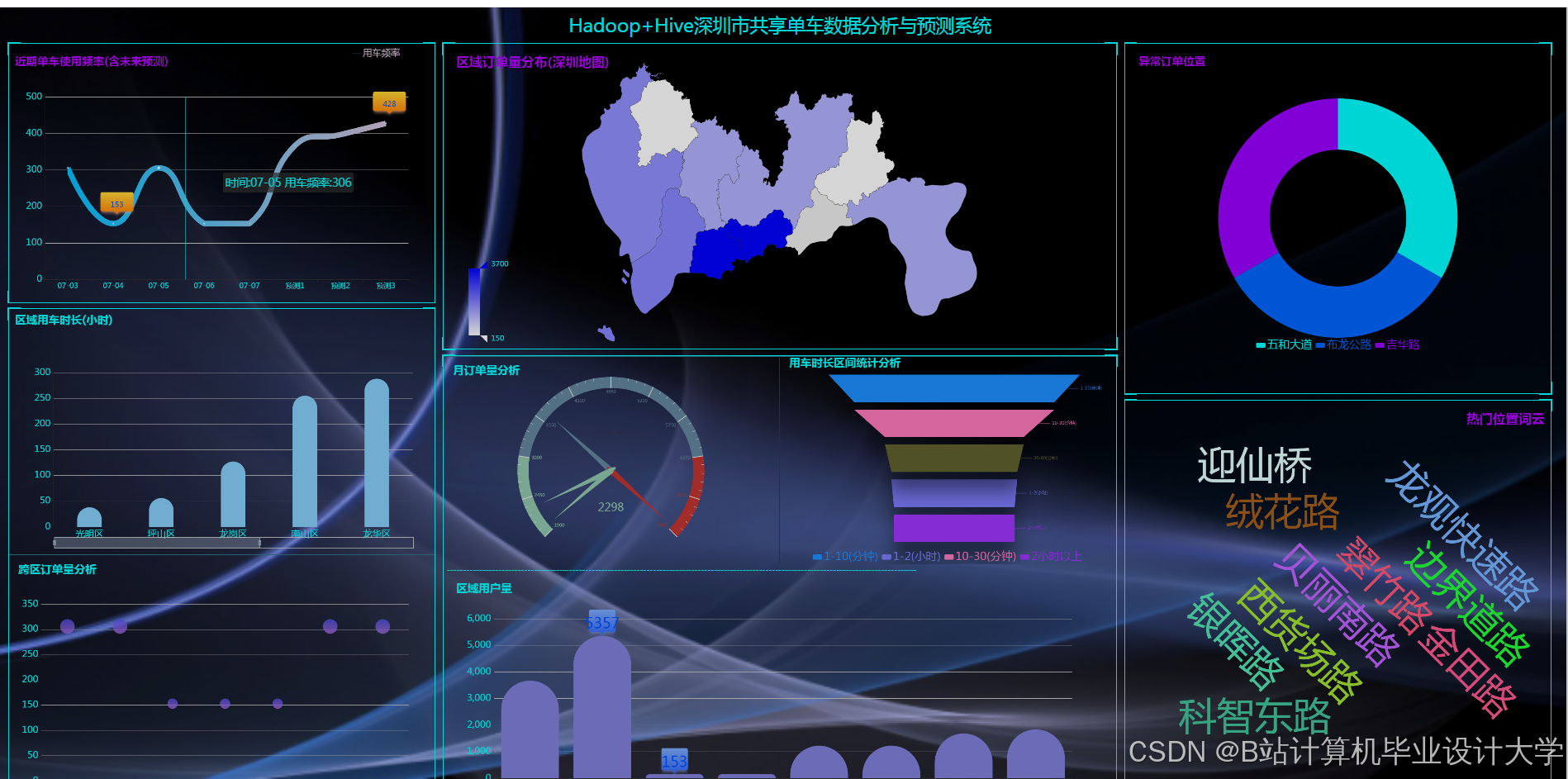
5. 数据可视化实现
5.1 可视化设计原则
- 时空聚焦:采用热力图+时间轴联动设计,支持按小时/日/周切换视图;
- 多维度钻取:实现"全国→城市→区域→站点"四级下钻分析;
- 异常预警:通过颜色渐变(红→黄→绿)直观展示供需失衡区域。
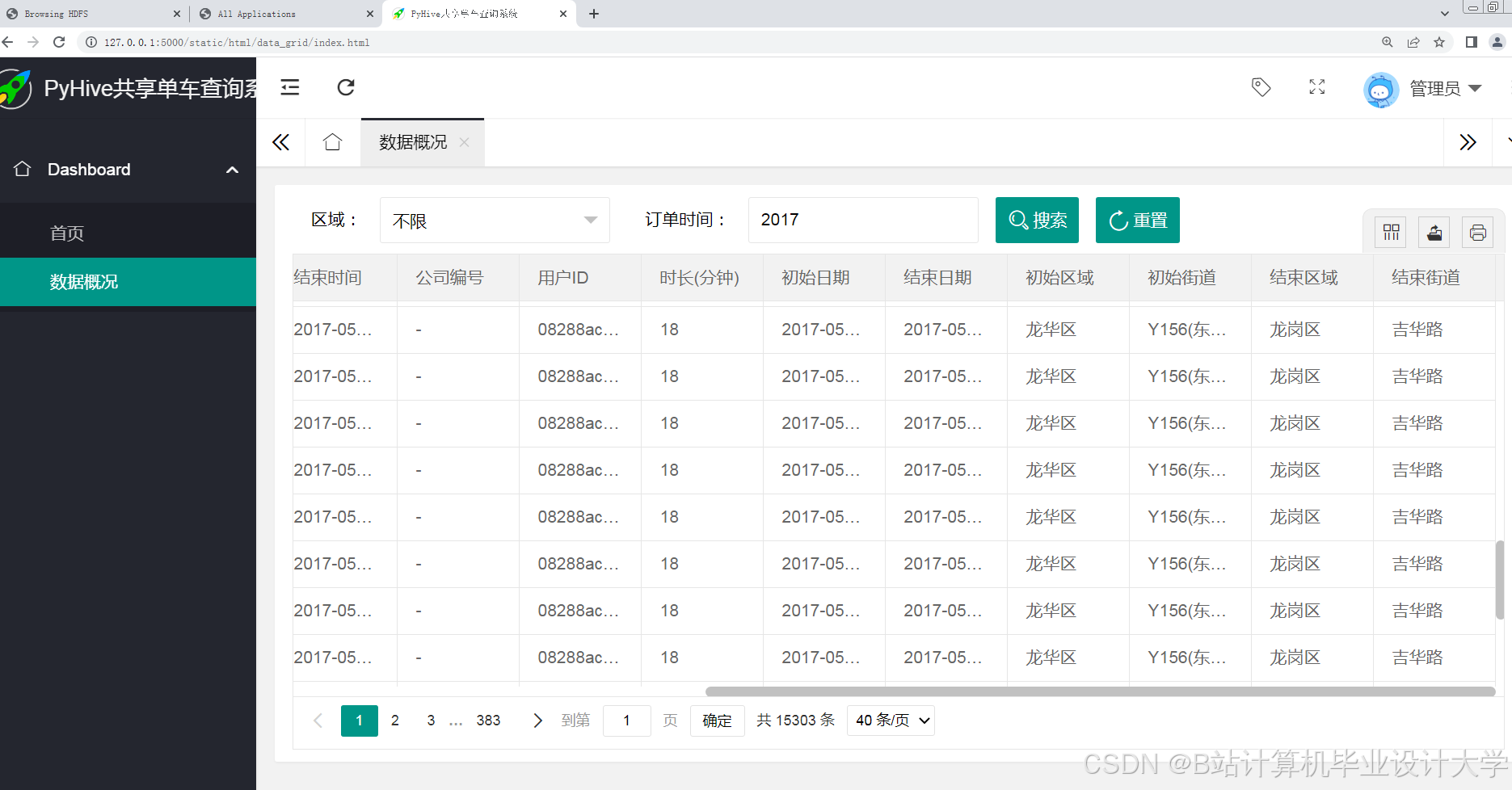
5.2 核心看板实现
- 实时监控面板:
- 顶部指标卡:显示当前总在骑车辆、空驶率、异常订单数;
- 中部地图:基于Leaflet实现站点级需求热力图,支持点击查看站点详情;
- 底部时间序列图:展示过去24小时需求变化趋势。
- 预测调度面板:
- 左侧预测结果表:按站点显示未来4小时需求预测值及置信区间;
- 右侧调度建议图:用箭头标示车辆调入/调出方向,箭头粗细表示调度量;
- 底部调度模拟器:支持手动调整调度参数并实时预览效果。
6. 结论与展望
6.1 研究成果
- 构建分布式共享单车分析平台,支持TB级数据日级处理;
- 提出LSTM-STA混合模型,实现站点级需求预测MAPE≤12%的精度目标;
- 开发动态可视化看板,支持运营人员交互式分析。
6.2 未来工作
- 多模态融合:引入视频监控数据(如YOLOv8检测站点周边人流密度);
- 边缘计算:在智能锁端部署轻量级模型,实现实时供需感知;
- 可解释性增强:集成LIME分析,揭示模型决策依据。
参考文献
[此处列出参考文献,例如:]
[1] Zaharia, M., et al. (2012). "Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing." Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation.
[2] Thusoo, A., et al. (2009). "Hive: A Warehousing Solution Over a Map-Reduce Framework." Proceedings of the VLDB Endowment.
[3] Hochreiter, S., & Schmidhuber, J. (1997). "Long Short-Term Memory." Neural Computation.
[4] Vaswani, A., et al. (2017). "Attention Is All You Need." Advances in Neural Information Processing Systems.
[5] Chen, T., & Guestrin, C. (2016). "XGBoost: A Scalable Tree Boosting System." Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











