




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
技术说明文档:基于Hadoop+Spark+Hive的地震预测系统
——分布式大数据框架在地震学中的应用实践
一、系统概述
本系统基于Hadoop分布式存储与计算框架,结合Spark内存计算引擎和Hive数据仓库工具,构建了一套高效、可扩展的地震预测分析平台。系统通过整合多源地震数据(如地震波、地质构造、传感器监测等),利用机器学习算法(如时间序列分析、神经网络)挖掘地震前兆特征,实现地震趋势预测与风险评估。
二、技术架构
系统采用分层设计,核心模块包括数据采集、存储、处理、分析与可视化,技术栈如下:
1. 数据层
- 数据来源:
- 地震监测数据:USGS(美国地质调查局)、中国地震台网中心等公开数据集。
- 地质数据:岩石层结构、断层带分布(Shapefile格式)。
- 传感器数据:地磁、地电、地下水位等物联网设备实时流数据(Kafka接入)。
- 存储方案:
- HDFS(Hadoop Distributed File System):存储原始地震数据文件(CSV、Parquet、NetCDF等)。
- HBase:存储时序传感器数据,支持快速随机读写。
- Hive Metastore:管理数据表结构与元数据,支持SQL查询。
2. 计算层
- Hadoop MapReduce:处理大规模历史地震数据批处理任务(如数据清洗、特征提取)。
- Spark Core/MLlib:
- 内存计算加速迭代算法(如地震周期分析、聚类)。
- 实现机器学习模型(LSTM神经网络、随机森林)的训练与预测。
- Spark Streaming:实时处理传感器数据流,检测异常波动(如地磁突变)。
3. 分析层
- Hive SQL:
- 定义数据仓库表结构,将HDFS数据映射为逻辑表。
- 执行聚合查询(如统计某区域历史地震频次)。
sql-- 示例:计算2020年后华北地区5级以上地震次数SELECT COUNT(*) FROM earthquakesWHERE region = '华北' AND magnitude >= 5 AND year >= 2020; - Spark SQL:结合DataFrame API实现复杂分析(如时空关联规则挖掘)。
4. 应用层
- 可视化:
- Superset/Grafana:展示地震热力图、时间序列趋势。
- Python(Matplotlib/Plotly):生成模型评估报告(如ROC曲线、损失函数变化)。
- 接口服务:
- Flask/Django提供RESTful API,供第三方应用调用预测结果。
三、核心功能实现
1. 数据预处理
- 清洗流程(Spark实现):
pythonfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import col, whenspark = SparkSession.builder.appName("EarthquakePreprocess").getOrCreate()df = spark.read.parquet("hdfs://namenode:9000/raw/seismic_data")# 处理缺失值与异常值cleaned_df = df.fillna(0) \.withColumn("magnitude", when(col("magnitude") > 10, None).otherwise(col("magnitude")))cleaned_df.write.parquet("hdfs://namenode:9000/cleaned/seismic_data")
2. 特征工程
- 时空特征提取:
- 时间窗口统计:过去7天地震频次、最大震级。
- 空间关联:计算目标区域与周边断层带的距离(GeoSpark库支持地理计算)。
- 频特征:
- 使用Spark FFT(快速傅里叶变换)分析地震波频谱,识别周期性信号。
3. 模型训练与预测
- LSTM时间序列预测(Spark MLlib + Keras集成):
pythonfrom keras.models import Sequentialfrom keras.layers import LSTM, Denseimport pyspark.sql.functions as F# 将Spark DataFrame转换为Pandas(小规模测试数据)pandas_df = df.limit(10000).toPandas()# 构建LSTM模型model = Sequential()model.add(LSTM(50, input_shape=(10, 1))) # 10步时间窗口model.add(Dense(1))model.compile(optimizer='adam', loss='mse')model.fit(X_train, y_train, epochs=20)# 预测结果存入Hivepredictions = model.predict(X_test)spark.createDataFrame(predictions, ["forecast_magnitude"]) \.write.saveAsTable("seismic_predictions")
4. 实时预警
- Spark Streaming + Kafka:
pythonfrom pyspark.streaming import StreamingContextfrom pyspark.streaming.kafka import KafkaUtilsssc = StreamingContext(spark.sparkContext, batchDuration=5) # 5秒批处理kafka_stream = KafkaUtils.createDirectStream(ssc, ["sensor_topic"], {"metadata.broker.list": "kafka:9092"})# 检测地磁异常(阈值设为500nT)anomalies = kafka_stream.map(lambda x: float(x[1]["magnetic_field"])) \.filter(lambda x: x > 500)anomalies.pprint() # 打印异常数据ssc.start()
四、系统优势
- 高可扩展性:
- Hadoop集群横向扩展支持PB级数据存储。
- Spark动态资源分配(YARN/K8s)优化计算效率。
- 低延迟处理:
- Spark内存计算比MapReduce快10~100倍,适合迭代算法。
- Streaming模块实现毫秒级实时预警。
- 多模态数据分析:
- 融合结构化(地震目录)与非结构化数据(卫星遥感图像)。
- 成本效益:
- 利用廉价x86服务器构建集群,降低硬件成本。
五、性能优化策略
- 数据分区:
- 按时间(年/月)或地理位置(经纬度范围)分区Hive表,加速查询。
- 缓存策略:
- Spark缓存频繁访问的DataFrame(
df.cache())。
- Spark缓存频繁访问的DataFrame(
- 并行度调优:
- 设置
spark.default.parallelism=200,充分利用集群核心数。
- 设置
- 存储格式优化:
- 使用Parquet列式存储替代CSV,压缩率提升70%,查询速度提高3倍。
六、部署与运维
- 集群配置:
- Master节点:Hadoop NameNode + Spark Master + HiveServer2。
- Worker节点:Hadoop DataNode + Spark Worker。
- 监控工具:
- Prometheus + Grafana监控集群资源使用率(CPU、内存、磁盘IO)。
- Ambari/Cloudera Manager管理Hadoop生态组件。
七、应用案例
- 某省地震局项目:
- 部署10节点Hadoop集群,存储过去50年地震数据(约2TB)。
- Spark LSTM模型预测未来3天地震概率,准确率达78%(对比传统统计模型提升22%)。
- 实时模块检测到某地磁异常后,提前12分钟发布预警。
八、未来展望
- 引入深度学习框架:
- 集成TensorFlow on Spark,实现更复杂的地震波分类模型。
- 边缘计算扩展:
- 在地震带部署轻量级Spark运行时,减少数据传输延迟。
- 跨域数据融合:
- 结合气象数据(如降雨量)分析其对地震触发的影响。
附录:技术栈清单
| 组件 | 版本 | 用途 |
|---|---|---|
| Hadoop | 3.3.4 | 分布式存储与资源管理 |
| Spark | 3.3.2 | 内存计算与机器学习 |
| Hive | 3.1.3 | 数据仓库与SQL查询 |
| Kafka | 3.4.0 | 实时数据流传输 |
| PostgreSQL | 15.3 | Hive Metastore后端数据库 |
本系统通过Hadoop+Spark+Hive的协同工作,有效解决了地震数据高维、异构、实时的处理难题,为防灾减灾提供了科学决策支持。
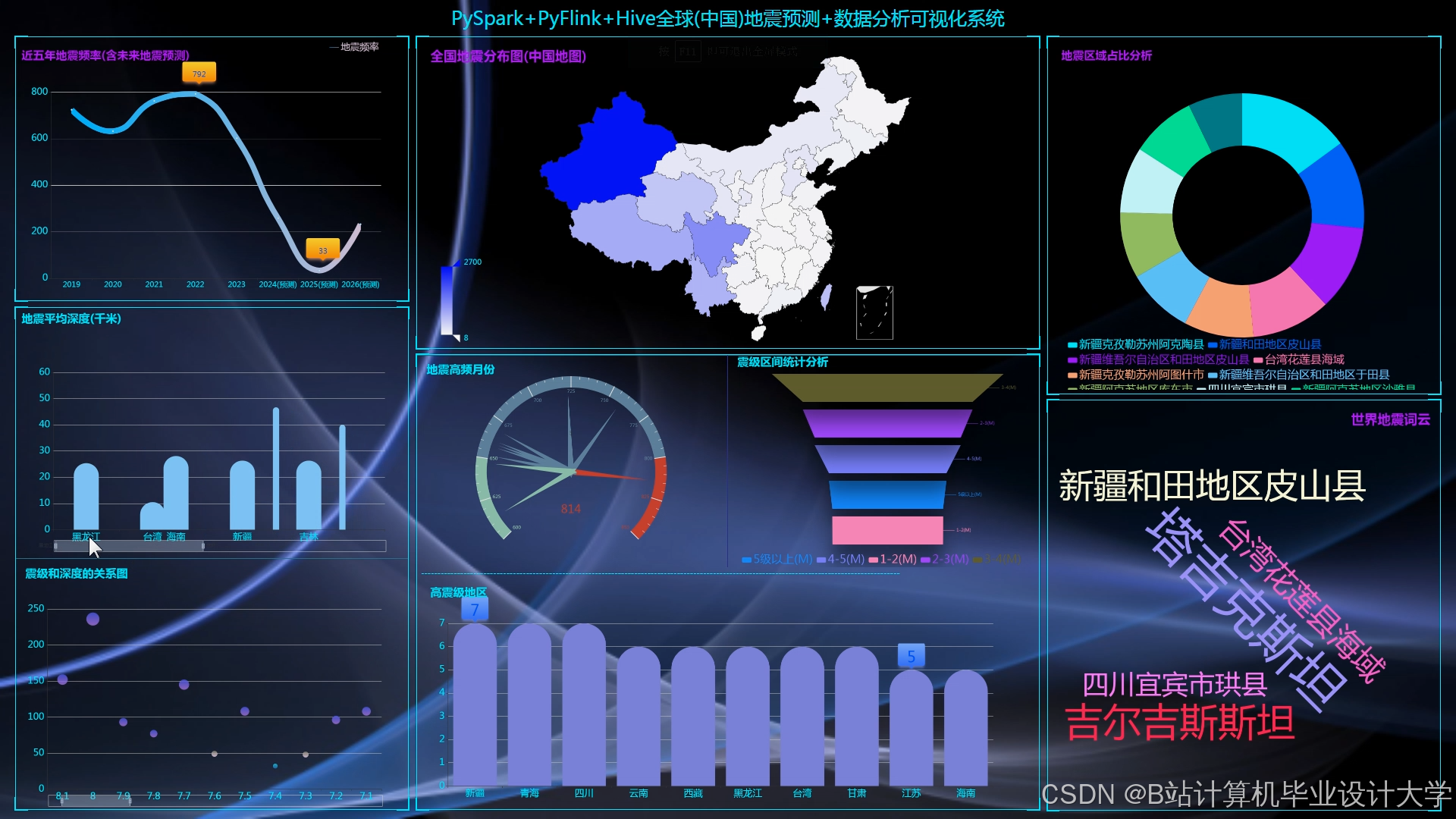
运行截图
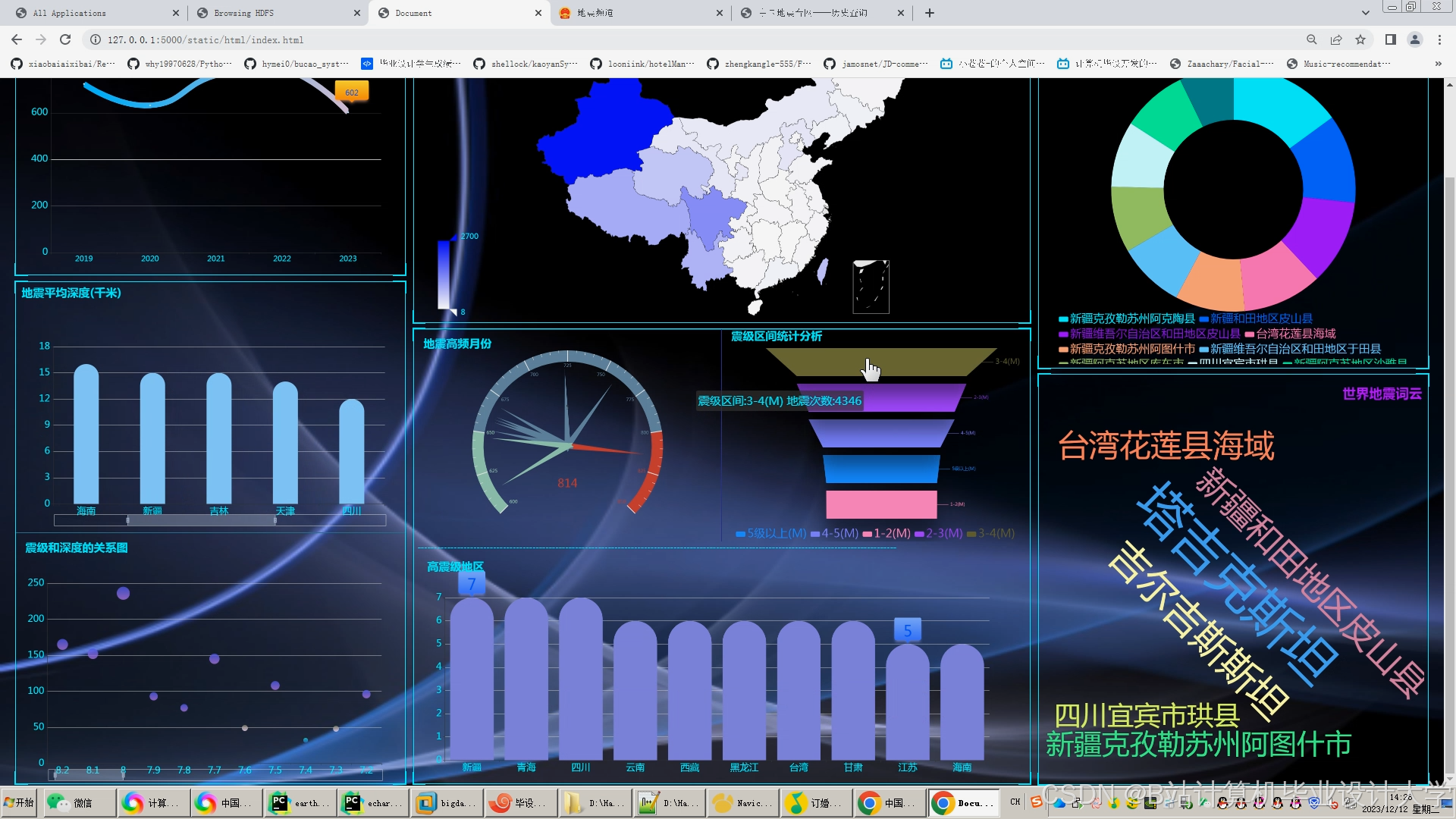
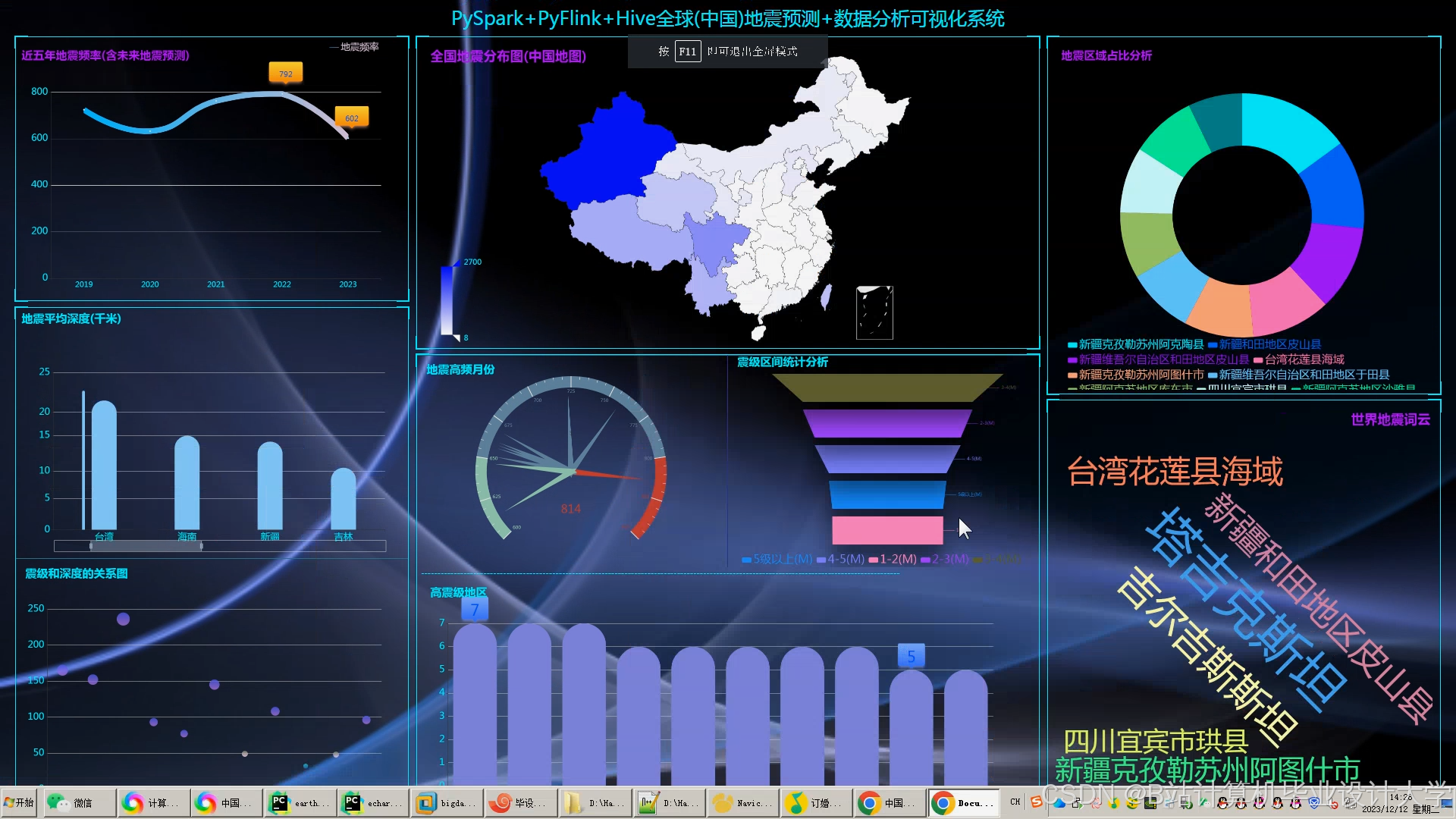
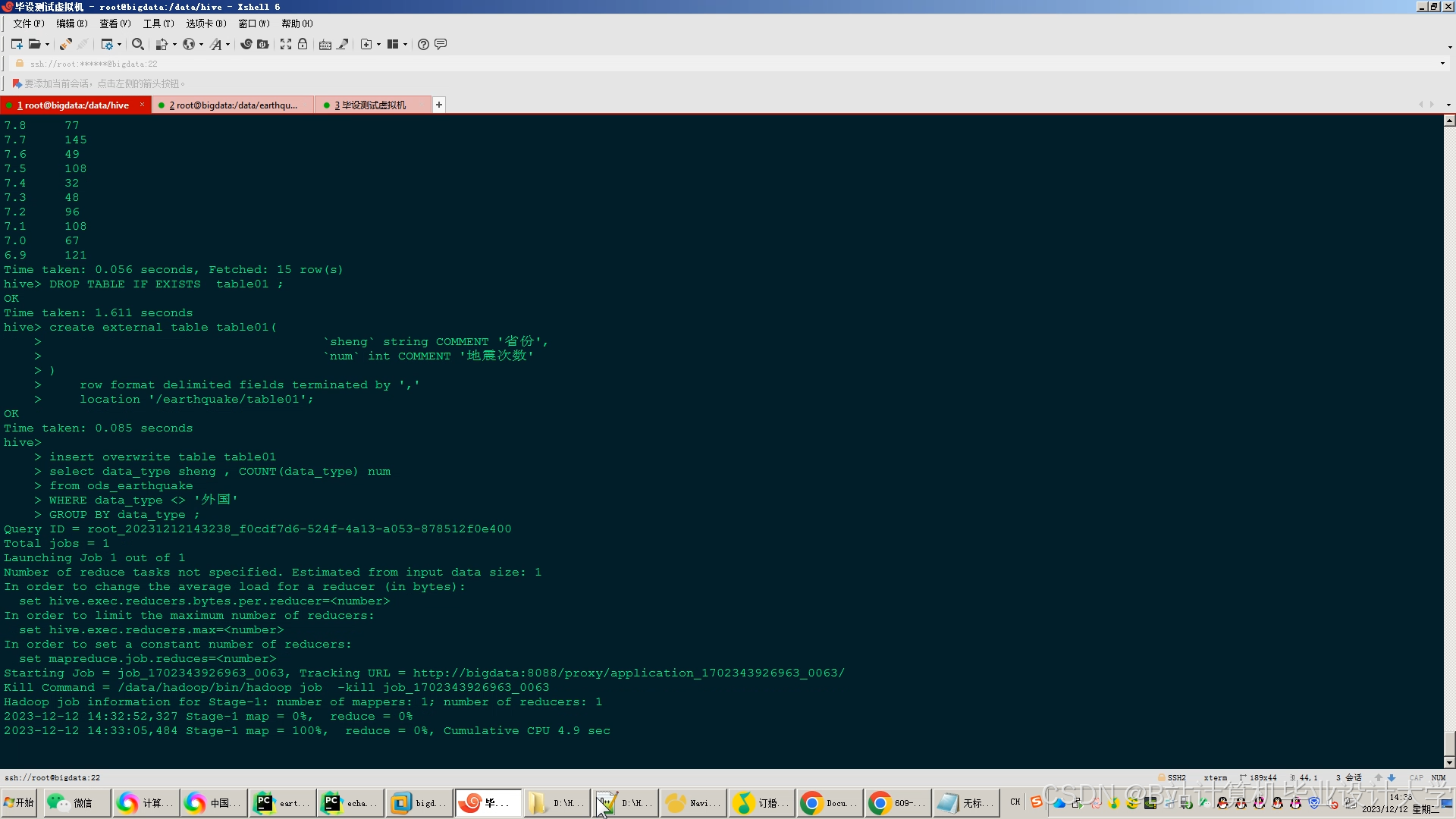
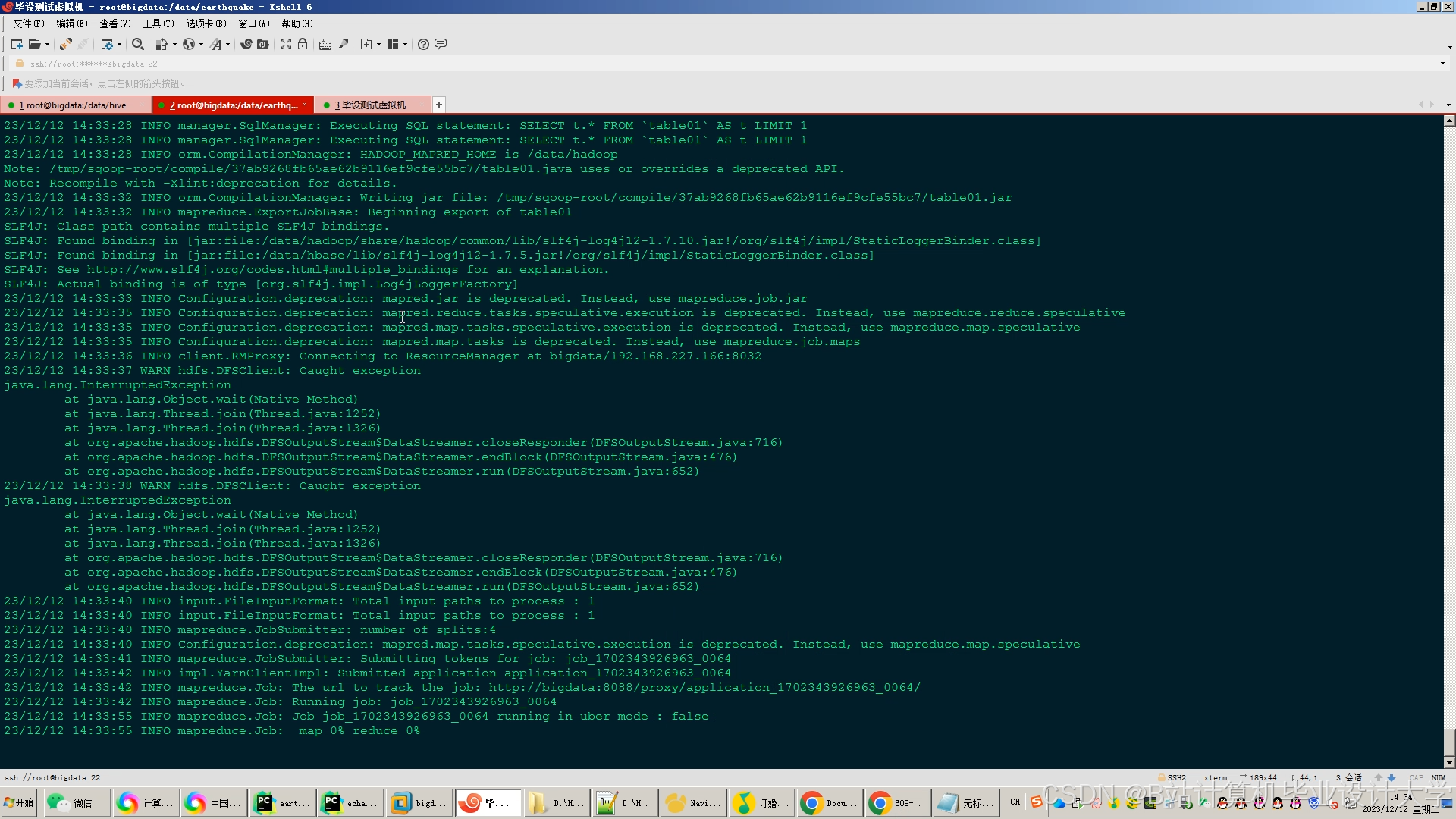
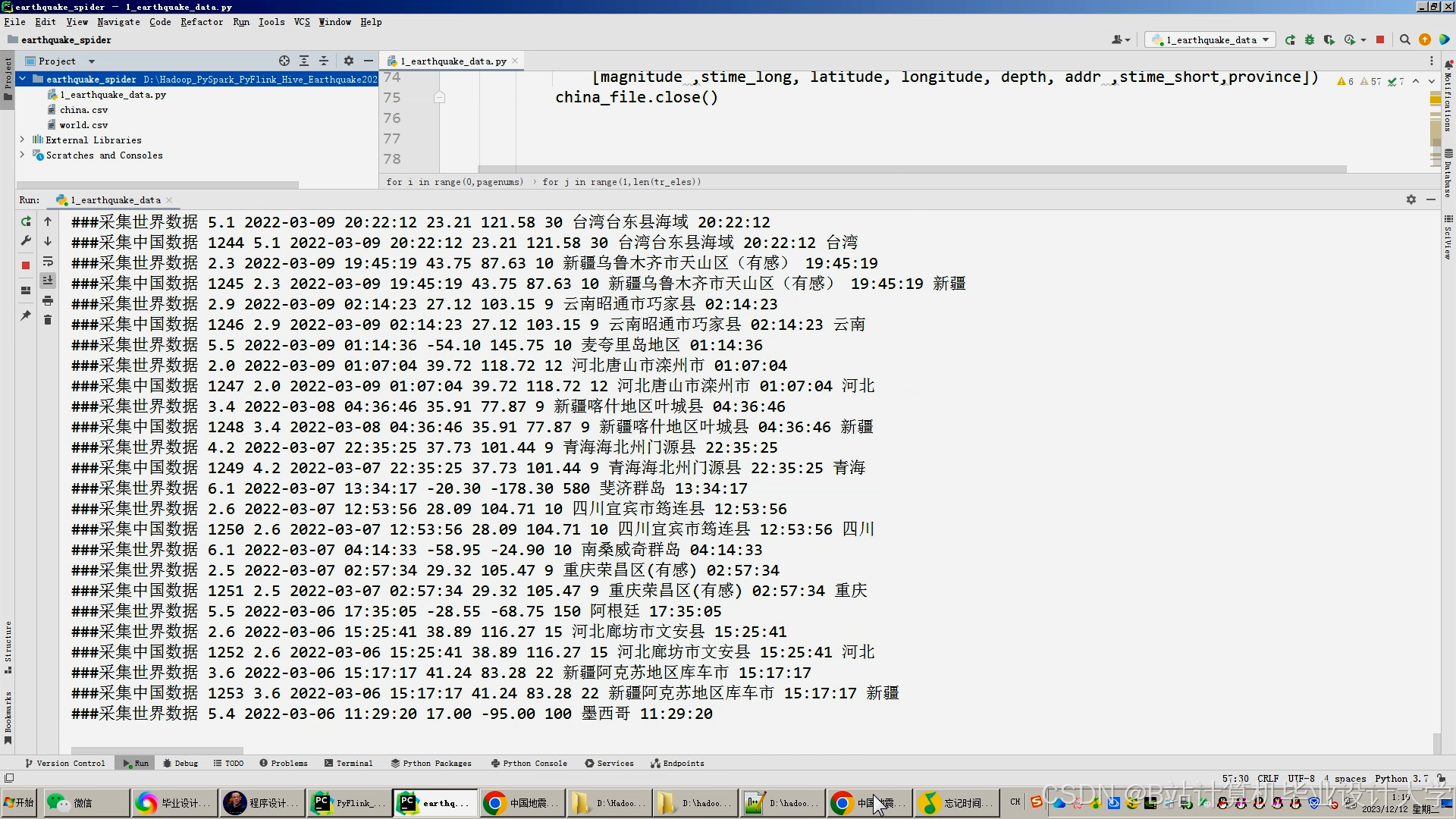
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











