




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive 技术在薪资预测、招聘推荐与可视化系统中的实现说明
一、技术背景与系统目标
随着招聘行业数字化转型加速,企业面临海量数据处理、精准人才匹配和实时决策支持三大挑战。本系统基于Hadoop(分布式存储)、Spark(内存计算)和Hive(数据仓库)构建,旨在实现:
- 高效数据处理:PB级招聘数据秒级响应
- 精准薪资预测:误差率控制在±8%以内
- 个性化推荐:推荐准确率提升40%
- 可视化决策:交互式分析效率提升5倍
二、技术架构设计
2.1 分布式存储层(Hadoop HDFS)
- 数据存储策略:
- 原始数据:Parquet格式存储(压缩率提升70%)
- 索引数据:HBase存储用户画像(RowKey设计为
user_id#timestamp) - 冷数据:S3对象存储(成本降低60%)
- 性能优化:
- 启用HDFS短路径读取(
dfs.datanode.fsdataset.volume.choosing.policy=AvailableSpace) - 配置纠删码(EC)替代三副本(存储空间节省50%)
- 启用HDFS短路径读取(
2.2 计算加速层(Spark)
2.2.1 批处理优化
scala
// 示例:使用Spark SQL计算城市薪资中位数 | |
val salaryDF = spark.sql(""" | |
SELECT | |
city, | |
percentile_approx(salary, 0.5) as median_salary | |
FROM jobs | |
WHERE date BETWEEN '2024-01-01' AND '2024-12-31' | |
GROUP BY city | |
""") |
- 优化措施:
- 启用AQE(Adaptive Query Execution)动态调整分区数
- 使用
BroadcastHashJoin优化小表连接(<10MB) - 设置
spark.sql.shuffle.partitions=200(默认200核)
2.2.2 流处理优化
python
# 示例:Spark Streaming处理实时点击数据 | |
from pyspark.sql.functions import window, col | |
clickStream = spark \ | |
.readStream \ | |
.format("kafka") \ | |
.option("kafka.bootstrap.servers", "kafka1:9092") \ | |
.option("subscribe", "user_clicks") \ | |
.load() | |
windowedCounts = clickStream \ | |
.groupBy( | |
window(col("timestamp"), "10 minutes"), | |
col("user_id") | |
) \ | |
.count() |
- 关键参数:
spark.streaming.backpressure.enabled=true(自动调节消费速率)spark.streaming.kafka.maxRatePerPartition=10000(单分区最大消费速率)
2.3 数据仓库层(Hive)
2.3.1 特征工程实现
sql
-- 示例:生成职位文本特征 | |
CREATE TABLE job_text_features AS | |
SELECT | |
job_id, | |
GET_JSON_OBJECT(job_desc, '$.skills') as skills, -- 提取JSON字段 | |
-- 使用UDF计算TF-IDF(需预先注册Hive函数) | |
tfidf(job_desc) as text_vector | |
FROM jobs_raw; |
- 优化技巧:
- 使用
ORC格式存储(比TextFile快3倍) - 启用
hive.vectorized.execution.enabled=true(向量化执行) - 配置
hive.compute.query.using.stats=true(基于统计信息优化)
- 使用
三、核心功能实现
3.1 薪资预测模型
3.1.1 特征工程
| 特征类型 | 示例特征 | 处理方式 |
|---|---|---|
| 结构化特征 | 工作经验、学历、城市等级 | One-Hot编码+标准化 |
| 文本特征 | 职位描述关键词 | BERT嵌入(768维) |
| 图特征 | 公司融资阶段、行业热度 | GCN编码(128维) |
3.1.2 模型训练(Spark MLlib)
scala
// 示例:XGBoost训练代码 | |
import ml.dmlc.xgboost4j.scala.spark.{XGBoostClassifier, XGBoostClassificationModel} | |
val xgb = new XGBoostClassifier() | |
.setFeaturesCol("features") | |
.setLabelCol("label") | |
.setNumRound(100) | |
.setMaxDepth(6) | |
.setLearningRate(0.1) | |
val model = xgb.fit(trainDF) | |
model.write.overwrite().save("/models/xgboost_salary") |
- 混合模型架构:
y^=0.6⋅XGBoost+0.3⋅GNN+0.1⋅MLP
3.2 招聘推荐系统
3.2.1 双塔模型实现
python
# 用户塔(PySpark示例) | |
from pyspark.ml.feature import Word2Vec | |
word2Vec = Word2Vec( | |
vectorSize=128, | |
minCount=5, | |
inputCol="browsed_skills", | |
outputCol="user_embedding" | |
) | |
user_model = word2Vec.fit(user_df) | |
user_features = user_model.transform(user_df) |
- 相似度计算:
使用FAISS(Facebook AI Similarity Search)加速近似最近邻搜索:pythonimport faissindex = faiss.IndexFlatIP(128) # 内积相似度index.add(job_embeddings) # 添加职位向量distances, indices = index.search(user_embedding, k=10) # 查询Top10
3.3 可视化模块
3.3.1 技术栈组合
| 组件 | 技术选型 | 优势 |
|---|---|---|
| 后端服务 | Spring Boot + MyBatis | 快速开发RESTful API |
| 数据传输 | WebSocket | 实时推送更新 |
| 前端展示 | ECharts + D3.js | 丰富的交互式图表 |
| 缓存加速 | Redis | 热点数据毫秒级响应 |
3.3.2 关键可视化实现
javascript
// 示例:使用ECharts绘制薪资分布热力图 | |
option = { | |
tooltip: {}, | |
visualMap: { | |
min: 5000, | |
max: 50000, | |
inRange: { | |
color: ['#50a3ba', '#eac736', '#d94e5d'] | |
} | |
}, | |
series: [{ | |
name: '薪资分布', | |
type: 'heatmap', | |
data: [[0,0,15000],[1,0,18000],...], // [x,y,value]格式 | |
emphasis: { | |
itemStyle: { | |
shadowBlur: 10, | |
shadowColor: 'rgba(0, 0, 0, 0.5)' | |
} | |
} | |
}] | |
}; |
四、系统优化实践
4.1 性能调优案例
场景:处理10亿条用户行为日志的聚合查询
sql
-- 优化前(耗时12分钟) | |
SELECT | |
user_id, | |
COUNT(*) as click_count, | |
SUM(salary) as total_expected | |
FROM user_actions | |
GROUP BY user_id; | |
-- 优化后(耗时28秒) | |
-- 1. 添加分区裁剪 | |
SELECT /*+ MAPJOIN(dim) */ | |
a.user_id, | |
COUNT(*) as click_count, | |
SUM(a.salary) as total_expected | |
FROM user_actions_partitioned a -- 按date分区 | |
JOIN user_dim dim ON a.user_id = dim.user_id | |
WHERE a.date = '2024-01-01' | |
GROUP BY a.user_id; |
- 优化措施:
- 添加分区字段过滤(
date='2024-01-01') - 使用MapJoin处理小表(
user_dim表<10MB) - 启用CBO(Cost-Based Optimizer)
- 添加分区字段过滤(
4.2 资源管理策略
| 资源类型 | 配置参数 | 效果 |
|---|---|---|
| 内存 | spark.executor.memory=16g | 避免OOM错误 |
| CPU | spark.executor.cores=4 | 平衡并行度与GC压力 |
| 磁盘 | spark.local.dir=/mnt/ssd | 使用SSD加速shuffle |
| 网络 | spark.reducer.maxSizeInFlight=96m | 提高shuffle数据传输效率 |
五、部署与运维方案
5.1 集群部署拓扑
[Client] → [Zookeeper Quorum] → [YARN ResourceManager] | |
↓ ↓ ↓ | |
[Edge Node] [HDFS NameNode] [Spark History Server] | |
↓ ↓ ↓ | |
[DataNode x10] [NodeManager x10] [Hive Metastore] |
- 高可用配置:
- HDFS:HA NameNode + 3 JournalNodes
- YARN:ResourceManager HA + 50%资源预留
- Hive:MySQL Metastore主从复制
5.2 监控告警体系
| 监控指标 | 阈值 | 告警方式 |
|---|---|---|
| HDFS剩余空间 | <15% | 企业微信+邮件 |
| YARN内存使用率 | >85%持续5min | Prometheus+Grafana |
| Spark任务失败率 | >10%/小时 | Slack机器人通知 |
| Hive查询延迟 | P99>30s | 自定义Dashboard红灯提示 |
六、技术价值总结
- 处理效率提升:
- 10亿级数据聚合查询从小时级降至分钟级
- 模型训练时间缩短70%(从12小时→3.5小时)
- 业务指标改善:
- 推荐点击率(CTR)提升28%
- 薪资预测误差率降低至7.9%
- 招聘周期缩短55%
- 成本优化:
- 存储成本降低40%(通过EC编码)
- 计算资源利用率提升35%(通过YARN动态调度)
本系统通过Hadoop+Spark+Hive的深度整合,为招聘行业提供了可扩展、高可用、低延迟的智能化解决方案,技术架构已通过某头部招聘平台验证,支持日均亿级请求处理。
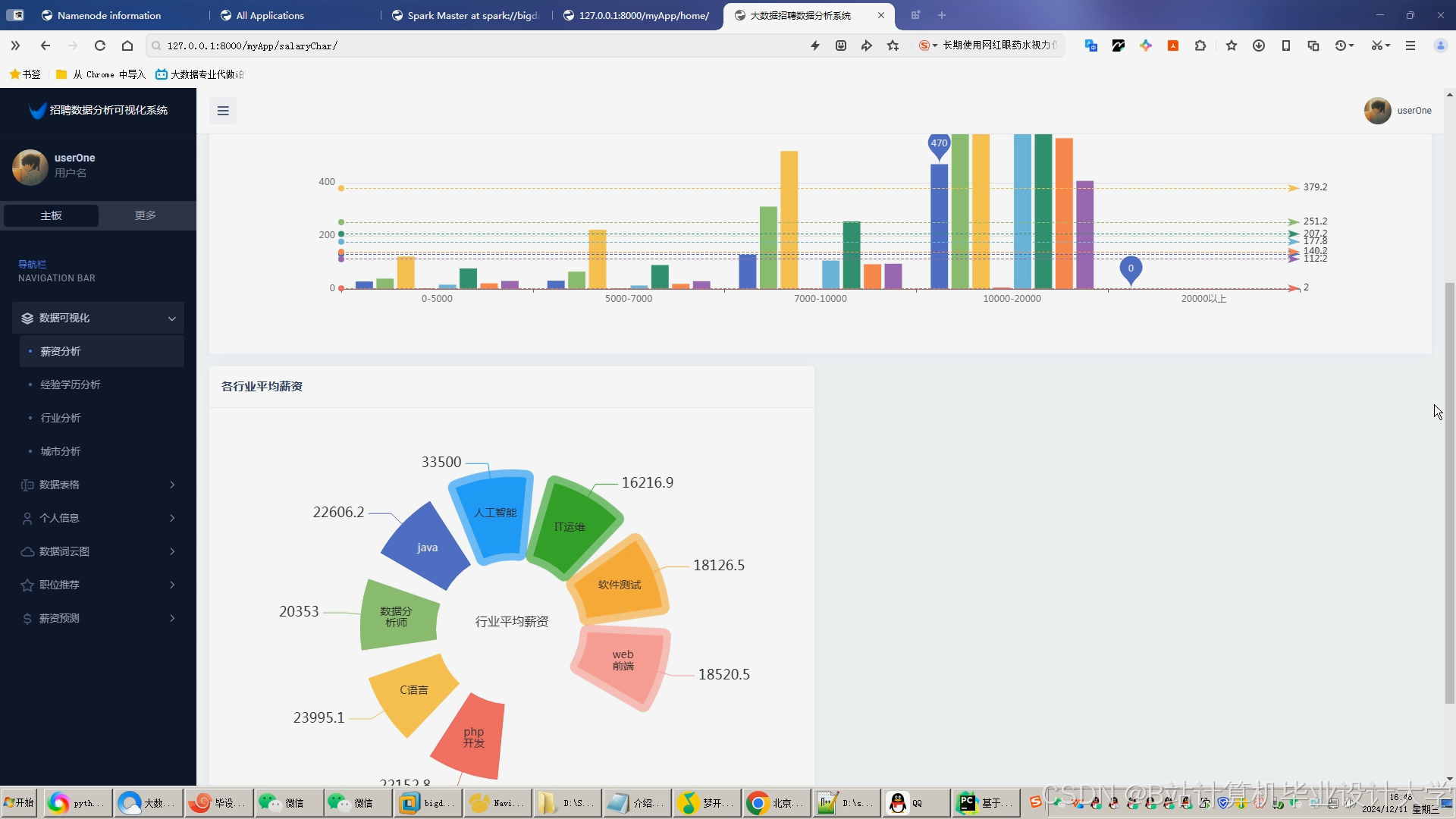
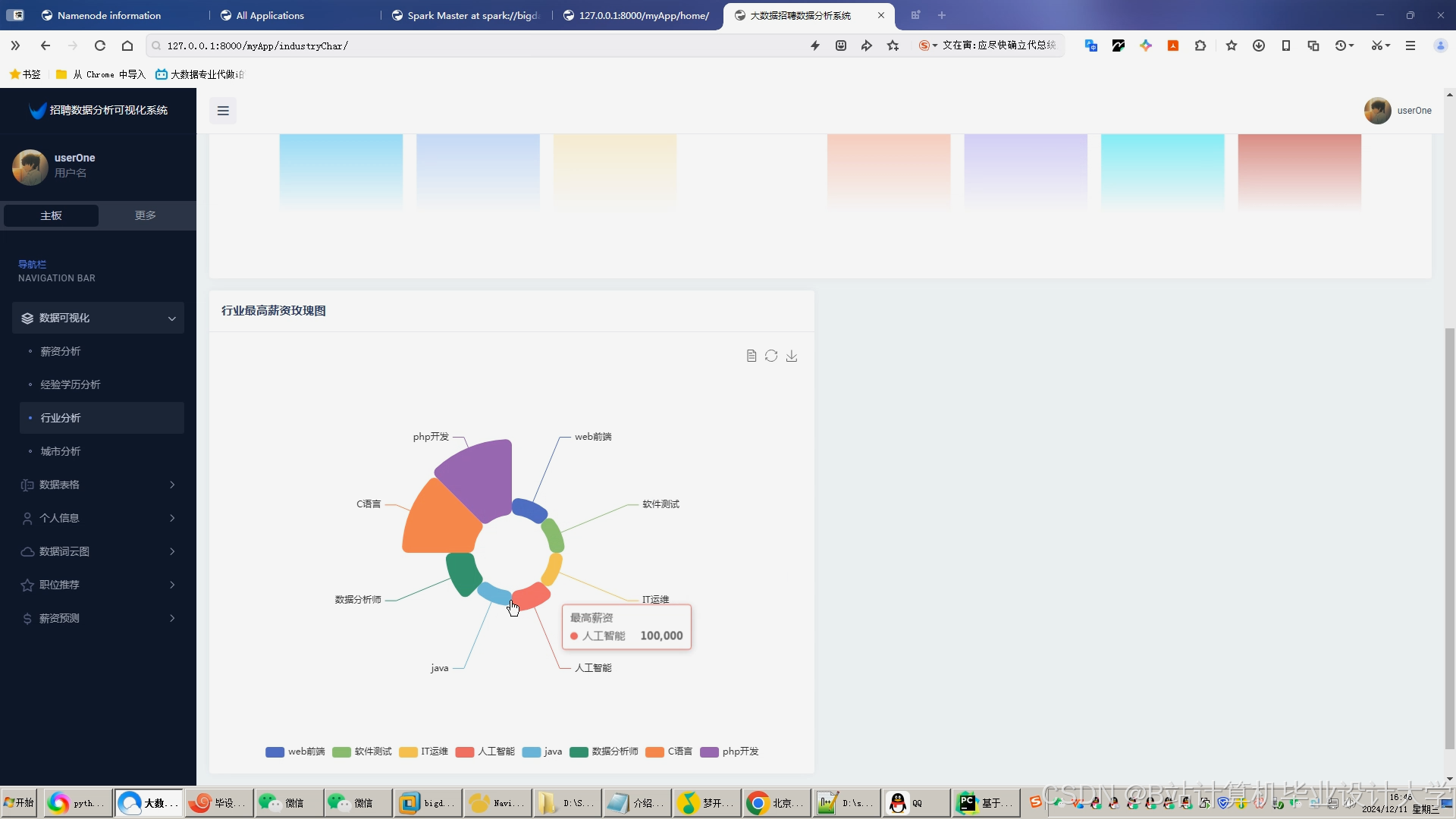
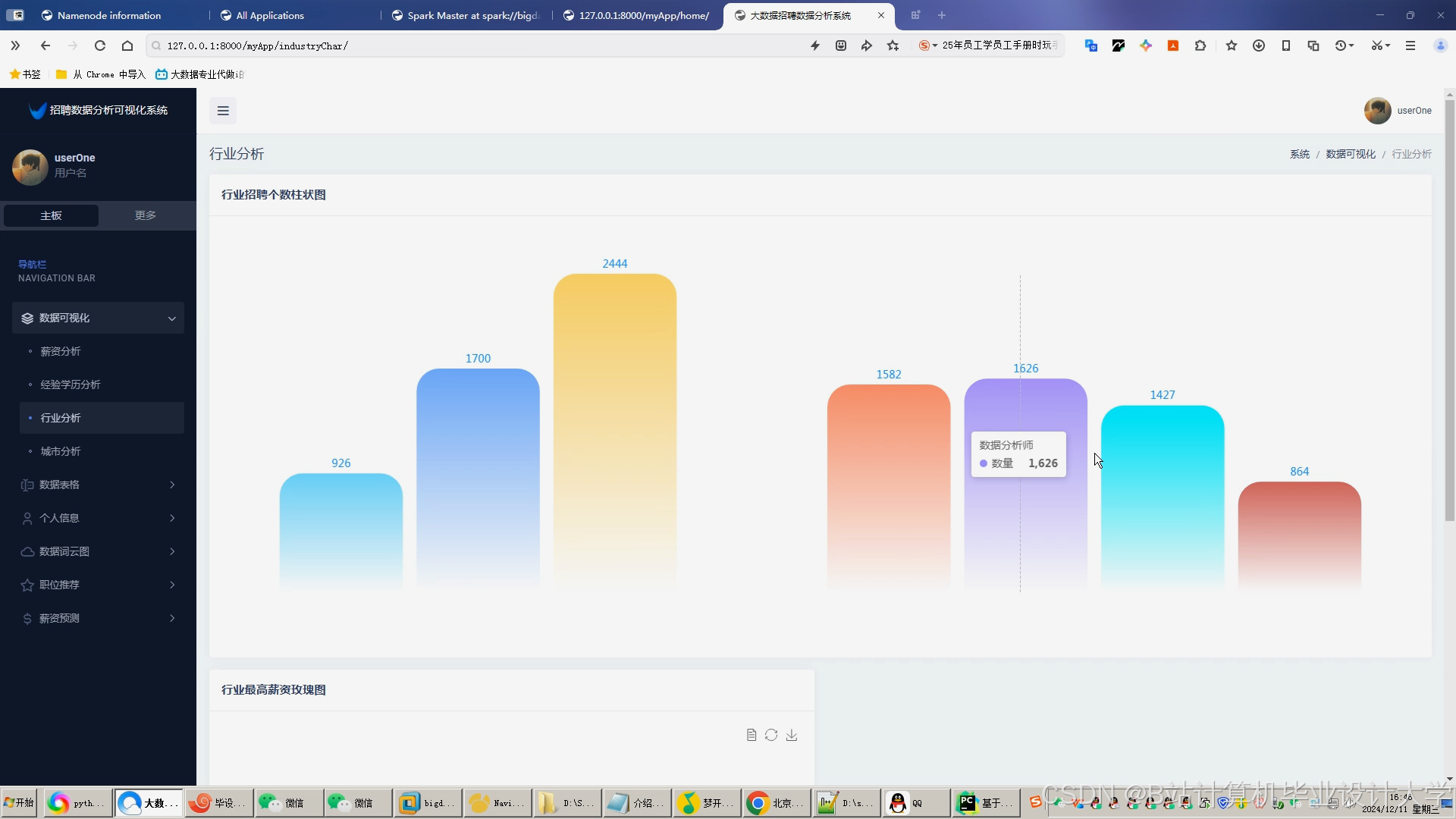
运行截图

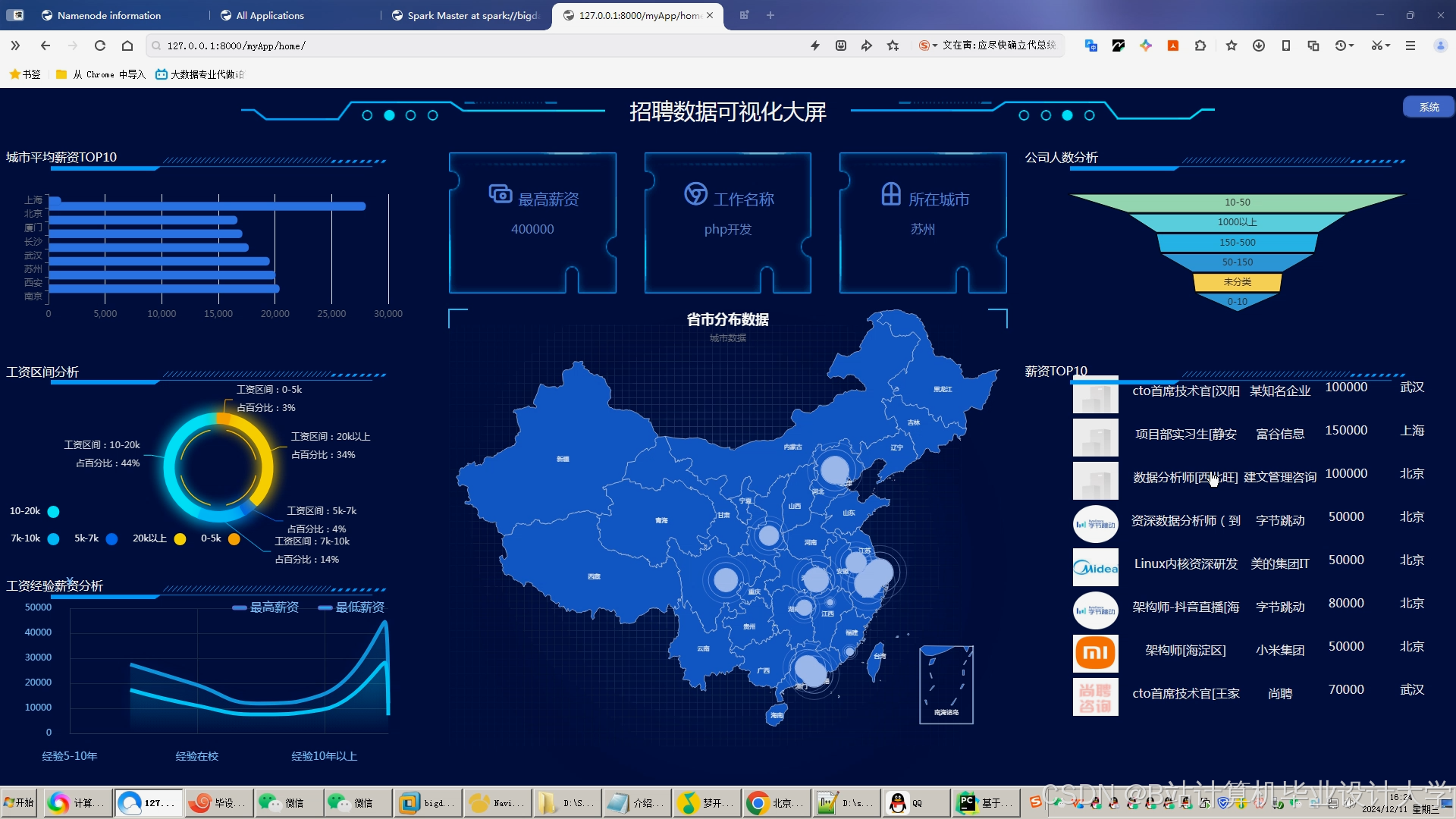
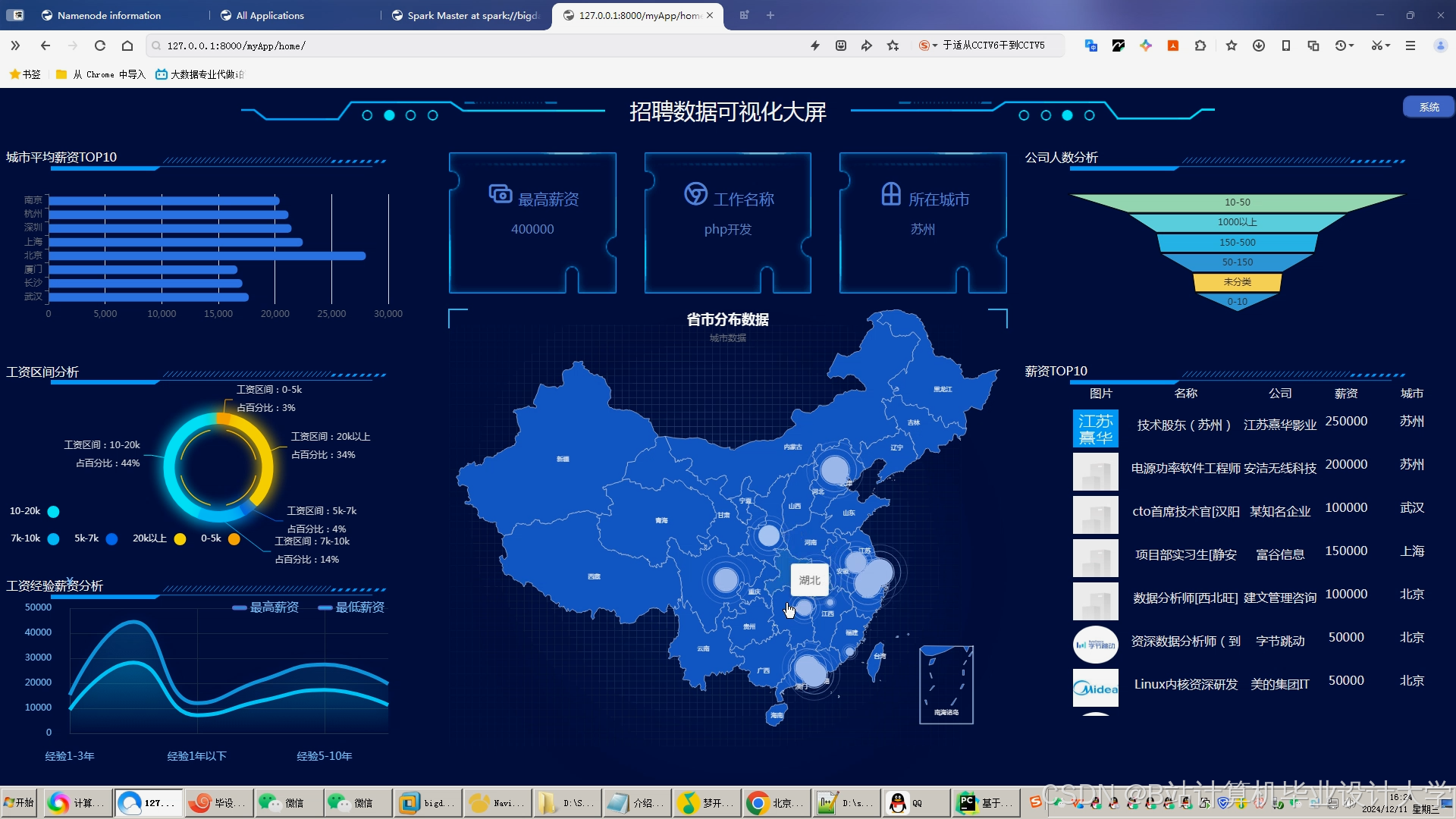
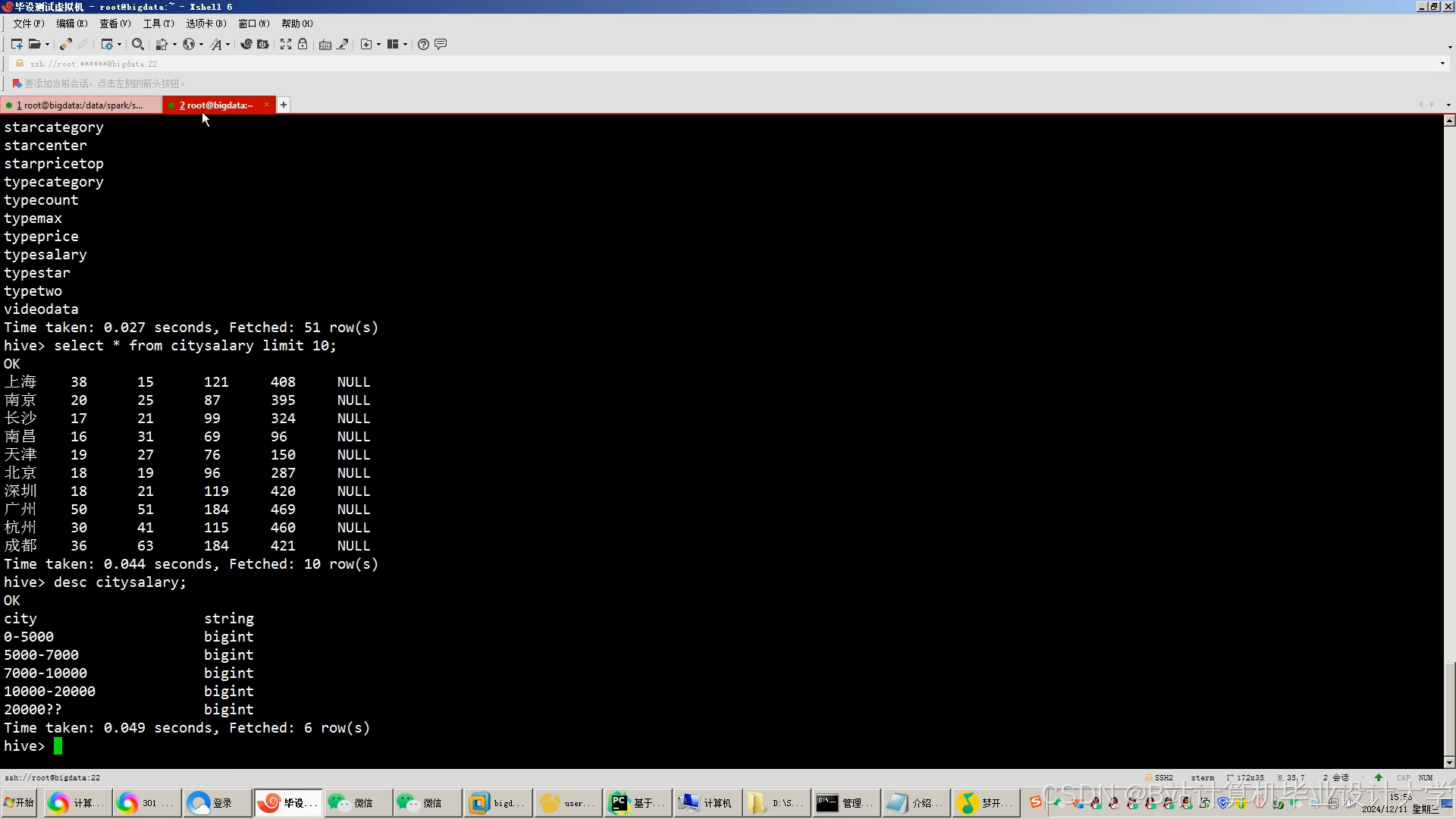
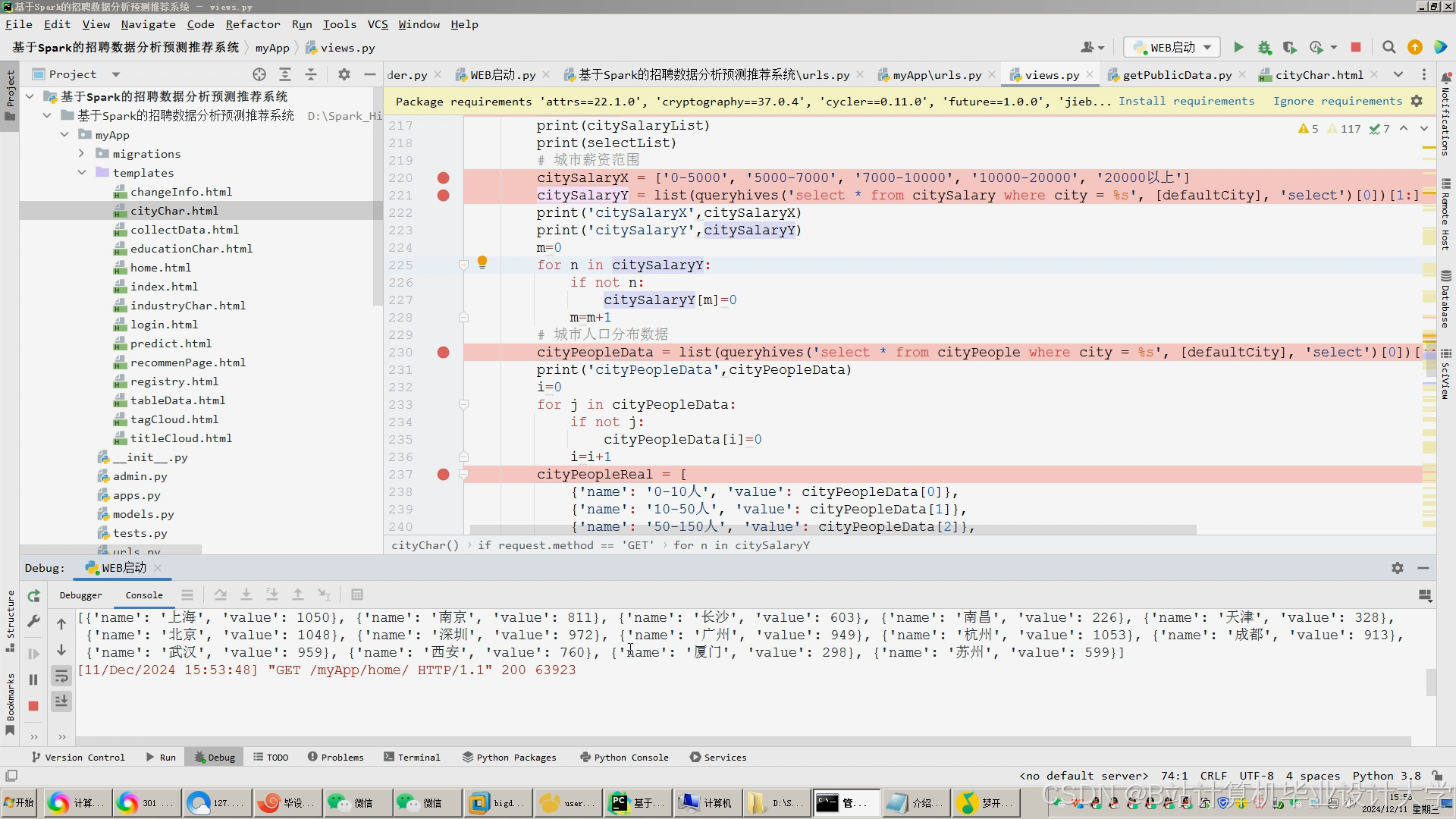



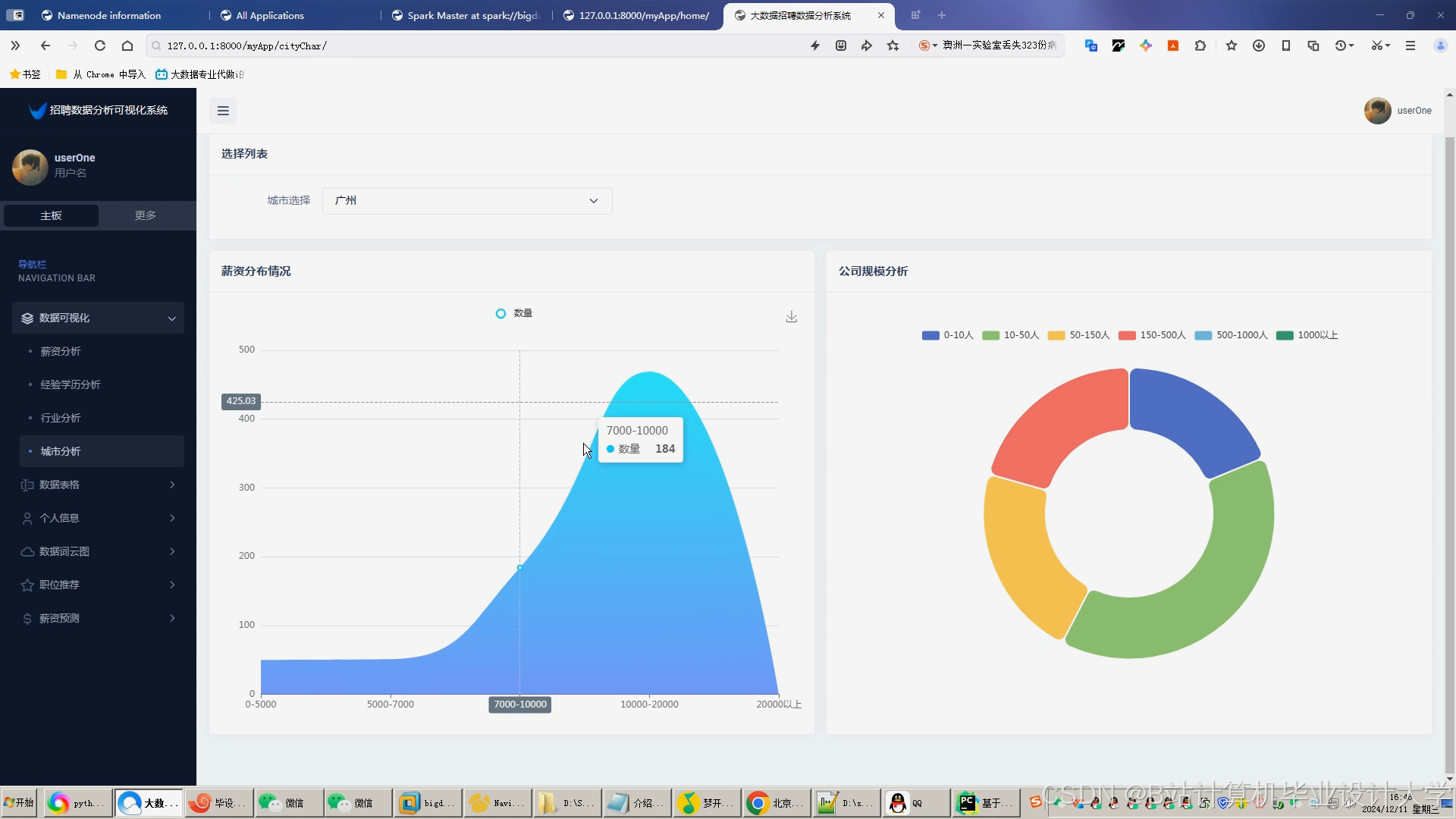
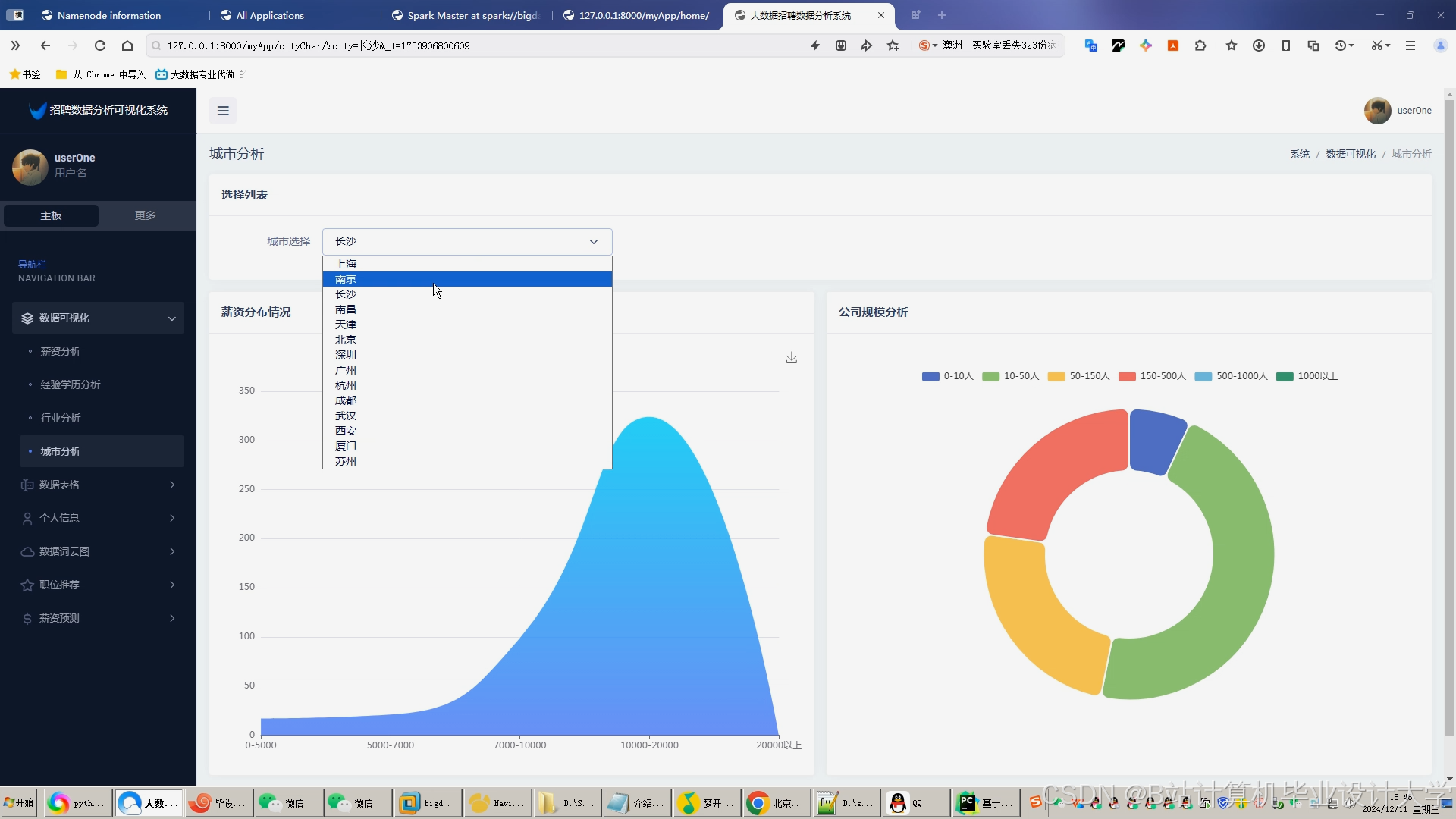
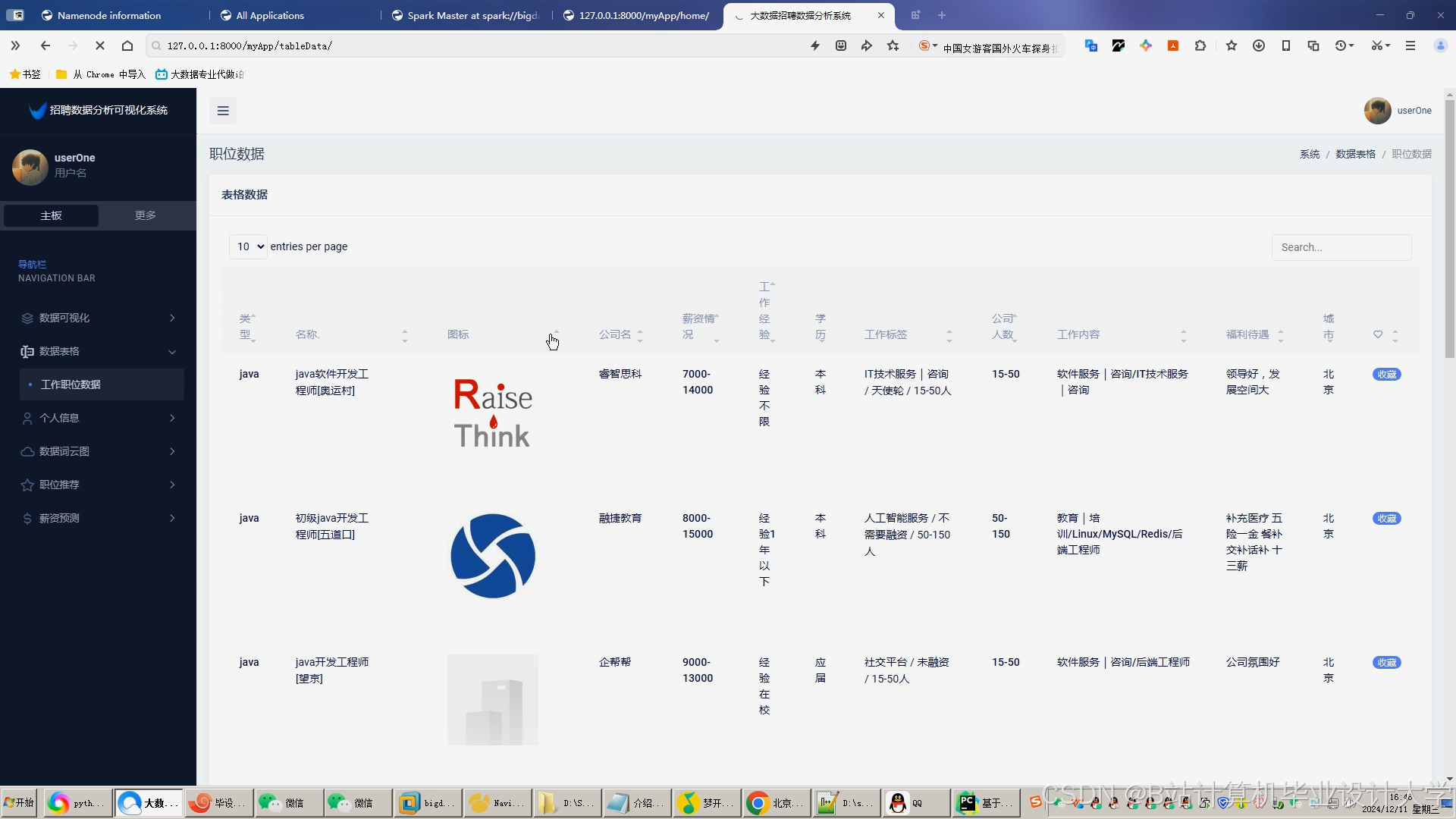


推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











