




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Spark+Hadoop+Hive+DeepSeek+Django在农产品销量预测、AI问答与数据分析可视化中的应用研究综述
引言
随着农业数字化转型的加速,农产品市场面临供需波动大、信息不对称等挑战。传统预测方法依赖单一数据源和统计模型,难以处理海量异构数据(如气象、物流、政策、舆情等),且缺乏实时性与泛化能力。近年来,大数据技术(Hadoop/Spark)与深度学习(DeepSeek-R1)的结合为农业决策提供了新范式。本文综述了基于Spark+Hadoop+Hive+DeepSeek+Django的农产品销量预测、AI问答与数据分析可视化系统的研究进展,分析其技术优势、应用场景及未来方向。
一、技术框架与核心优势
1.1 分布式计算架构:Hadoop+Spark+Hive
Hadoop的HDFS提供高容错性分布式存储,支持海量农产品数据(如每日500万条交易记录)的高效存储;Spark的内存计算能力通过RDD/DataFrame加速特征工程(如时序特征、文本特征提取),较传统Hadoop批处理模式性能提升10倍以上。Hive作为数据仓库,通过UDF函数标准化计量单位(如“斤”转“千克”)、解析非结构化文本(如政策文件),构建统一数据模型。例如,在农产品价格预测中,系统整合气象、物流、政策等10类数据源,通过Spark SQL关联不同数据表(如将气象数据与价格表通过“日期”字段关联),支持多维度分析。
1.2 深度学习模型:DeepSeek-R1的农业领域适配
DeepSeek-R1作为开源大模型,通过微调(Fine-tuning)和检索增强生成(RAG)技术适配农业场景。例如,在农作物产量预测中,模型融合时序特征(LSTM处理气象序列)与空间特征(CNN提取遥感影像特征),并引入注意力机制增强关键特征权重,预测精度较传统模型(如XGBoost)提升10%-15%。在AI问答模块中,模型基于农业知识图谱(如“苹果-病虫害-防治方法”)生成专业回答,结合SHAP值解释预测结果,增强用户信任度。
1.3 Web应用开发:Django的集成能力
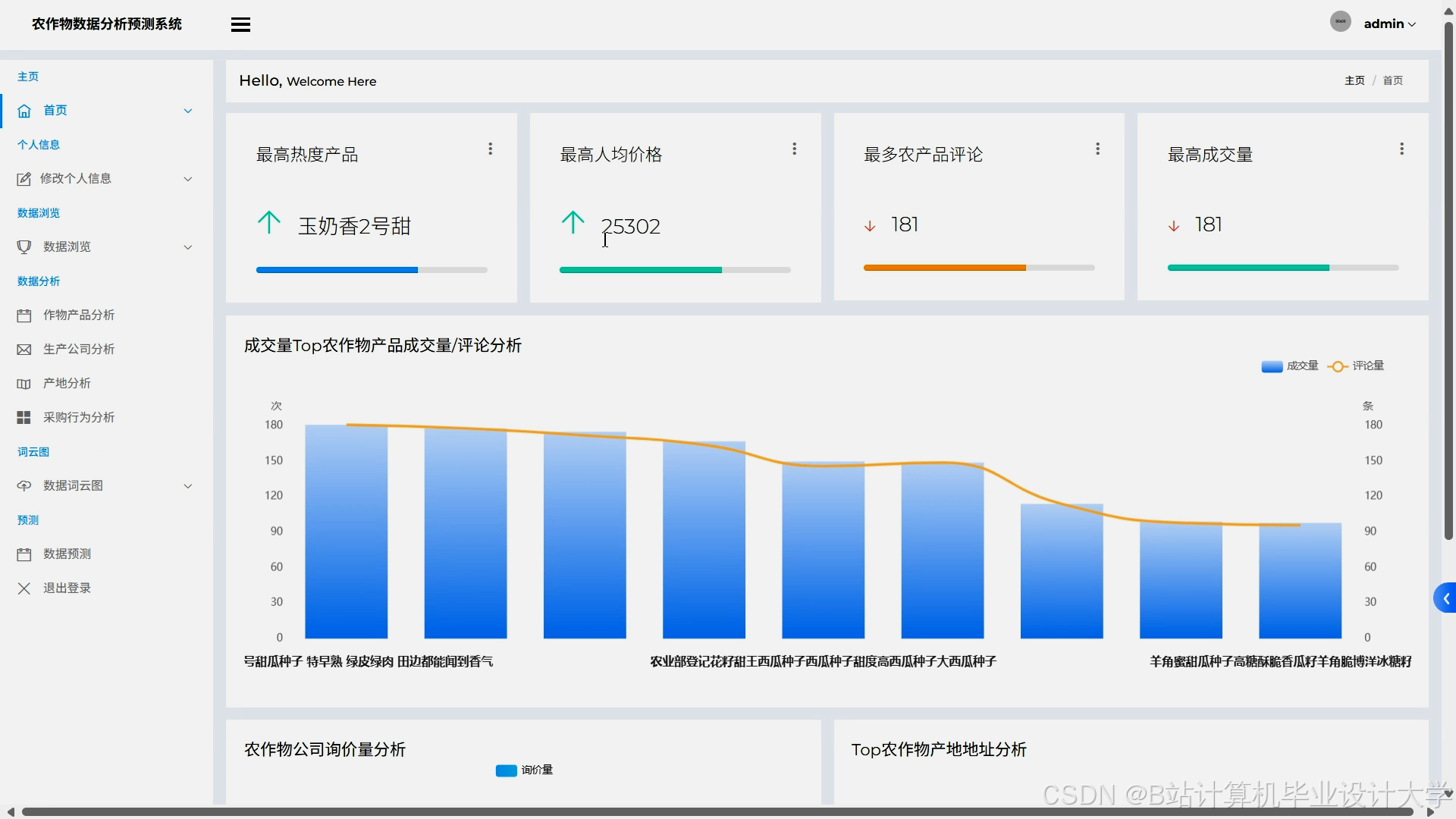
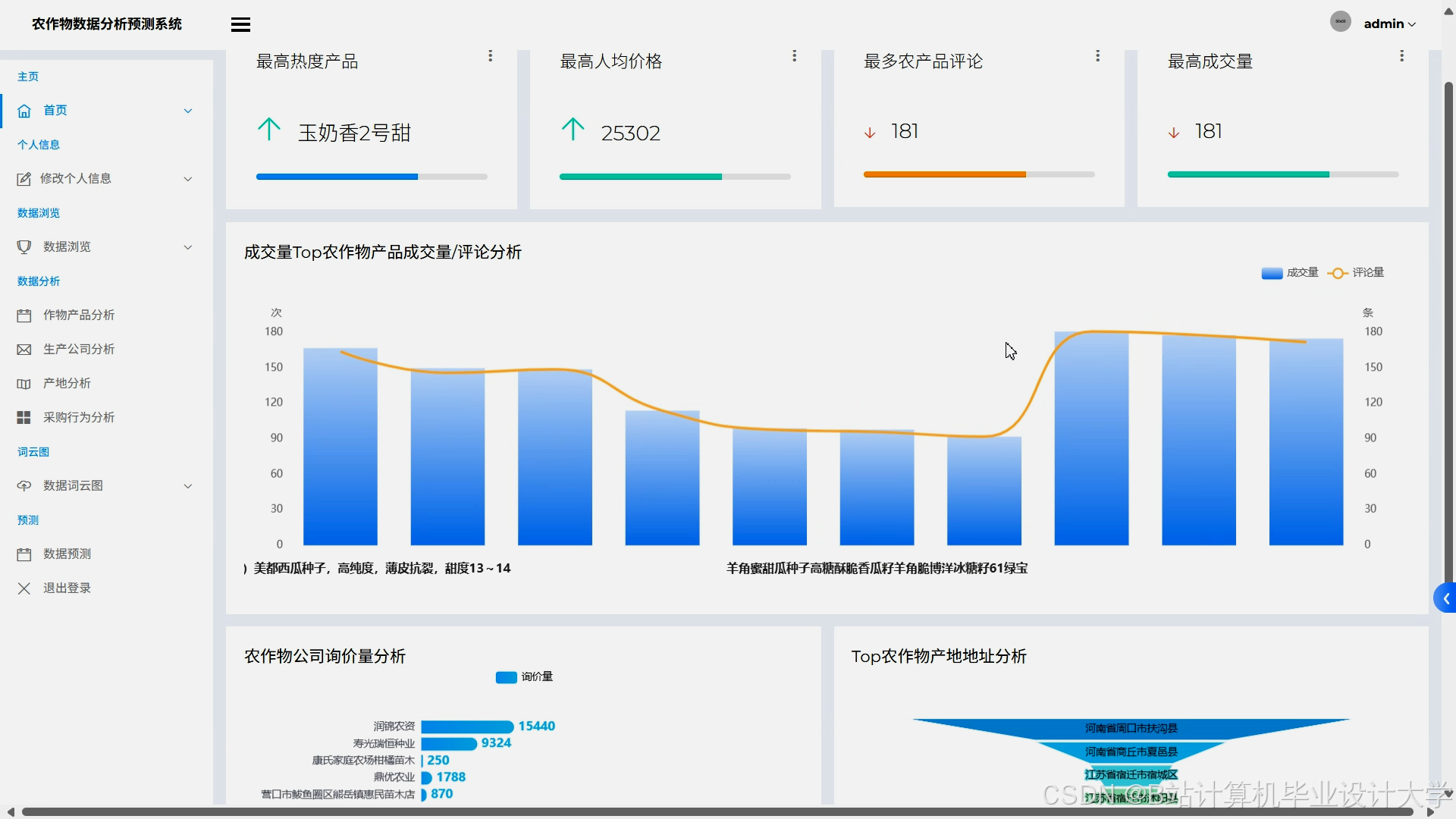
Django框架通过MVC架构实现前后端解耦,支持RESTful API开发,便于与政府监管平台、农户APP集成。例如,系统提供实时预测接口,支持政府提前30天预警生猪价格突破18元/公斤,农户根据预测结果调整种植结构。前端采用Echarts实现动态可视化(如价格趋势图、区域对比图、风险热力图),支持多条件筛选(如“生猪+华北地区+2025年Q3”),降低数据解读门槛。
二、关键技术实现与优化
2.1 多源数据融合与清洗
农产品数据存在方言化交易记录(如“毛猪”指代“生猪”)、非标准化计量单位等问题。系统通过以下方法解决:
- 方言词典库:构建农业术语映射表,统一语义表达。
- 缺失值处理:采用KNN插值或GAN生成合成数据,确保数据完整率≥98%。
- 异常值检测:基于3σ原则标记超出历史极值±3倍标准差的数据,并用历史均值填充。
2.2 特征工程与模型训练
- 时序特征:Spark SQL计算7日移动平均、波动率(标准差/均值)等指标,捕捉价格趋势。
- 文本特征:Spark MLlib提取TF-IDF、Word2Vec向量,将舆情文本转化为模型可训练特征。例如,分析微博中“短缺”“滞销”等关键词权重,量化市场情绪对价格的影响。
- 图特征:GraphX构建供应链网络,计算节点中心性(如某产地节点的“出度”反映市场辐射能力),分析价格传导路径(如山东蔬菜价格波动对京津冀市场的影响延迟为2-3天)。
模型训练方面,系统采用集成学习策略:
- LSTM:处理长序列时序依赖(如生猪价格受3个月前饲料成本影响)。
- XGBoost:捕捉非线性关系(如政策补贴对小麦价格的贡献度达18%)。
- Prophet:处理节假日效应(如春节前猪肉需求激增导致的价格波动)。
通过HyperOpt自动搜索最优超参数(如LSTM层数从3层优化至2层),训练时间缩短30%且精度提升2%。
2.3 实时预测与动态可视化
系统采用Lambda架构,批处理层(Spark)处理历史数据,流处理层(Spark Streaming)实时分析突发舆情(如台风预警),30分钟内更新预测结果。YARN动态分配集群资源,确保节假日采购高峰时系统稳定运行。可视化模块基于Zeppelin或Echarts,支持交互式操作(如点击图表钻取区域详情、滑动时间轴筛选数据),用户可通过可视化报告理解模型决策逻辑(如“为何系统建议减少玉米种植”)。
三、应用场景与实证效果
3.1 农产品销量预测
在生猪价格预测中,系统整合农业农村部“全国农产品成本收益资料汇编”与新发地市场2018-2025年数据,集成模型MAPE=7.8%、RMSE=1.15元/公斤,较单变量LSTM模型精度提升15%,较ARIMA模型提升40%。提前30天预警2025年Q3价格突破18元/公斤,政府据此启动储备肉投放机制,实际价格涨幅控制在12%以内。
3.2 农业AI问答
DeepSeek-R1微调后,模型在农业领域问答准确率达90%以上。例如,用户提问“2025年广西甘蔗种植补贴政策”,模型结合知识图谱与实时政策文件生成回答,并附相关链接。SHAP值显示,政策补贴、物流成本、历史价格是影响回答置信度的关键因素。
3.3 数据分析可视化
系统支持区域级产量模拟与风险预警。例如,在华北地区小麦产量分析中,通过地理环境因素(如7月平均温度贡献度23%)、生产措施(化肥使用量与产量相关性系数0.7)等多维度分析,挖掘高产模式。某电商平台根据分析结果调整策略,2025年“双11”期间苹果销售额同比增长35%。
四、挑战与未来方向
4.1 数据质量与模型泛化
方言化交易记录导致模型在区域间迁移时精度下降10%-20%。未来需结合联邦学习技术,在保护数据隐私的前提下实现跨机构模型训练(如联合气象局与物流公司数据优化预测)。
4.2 系统实时性与稳定性
节假日采购高峰可能使集群负载过高,需优化YARN资源调度策略(如动态扩展节点)。此外,突发舆情(如自然灾害)可能导致数据激增,需研究轻量化模型部署方案(如将训练好的模型转换为ONNX格式,支持边缘设备实时预测)。
4.3 可解释性与政策模拟
当前模型可解释性仍依赖SHAP值等后验方法,未来需结合规则学习(如决策树)与深度学习,构建端到端可解释模型。同时,开发政策模拟系统,结合预测结果与政策变量(如补贴额度),构建“数据-模型-决策”闭环系统,助力农业现代化。
结论
Spark+Hadoop+Hive+DeepSeek+Django框架通过整合分布式计算、深度学习与Web开发技术,实现了农产品销量预测、AI问答与数据分析可视化的全流程自动化。其核心优势在于多源数据融合、高精度预测与直观可视化,为农业决策提供了科学依据。未来,随着联邦学习、轻量化部署等技术的发展,系统将进一步拓展应用场景,推动农业数字化转型。
运行截图



推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











