




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
开题报告:基于Hadoop+Spark+Hive的酒店推荐系统与可视化平台设计
一、研究背景与意义
1.1 研究背景
随着在线旅游平台(OTA)的快速发展,酒店预订数据呈现爆炸式增长。以携程、Booking等平台为例,日均产生的用户行为数据(如浏览、收藏、预订)超过TB级别。如何从海量数据中挖掘用户偏好,实现个性化酒店推荐,已成为提升平台竞争力的核心问题。同时,传统推荐系统面临以下挑战:
- 数据规模:单日用户行为日志可达数亿条,传统单机系统无法处理;
- 实时性:用户需求动态变化,需支持秒级响应的实时推荐;
- 可视化缺失:现有系统多聚焦算法实现,缺乏对推荐效果的直观展示与业务洞察。
1.2 研究意义
本研究构建基于Hadoop+Spark+Hive的分布式推荐系统,结合可视化技术,实现以下价值:
- 技术层面:验证大数据生态在推荐场景下的高效性,解决传统系统的性能瓶颈;
- 业务层面:通过可视化分析用户行为模式,辅助运营决策(如动态定价、库存优化);
- 学术层面:探索混合推荐算法(协同过滤+内容过滤)在酒店场景的优化方法。
二、国内外研究现状
2.1 大数据推荐系统研究
- 国外:Netflix基于Spark的推荐引擎处理日均400万次播放记录,准确率提升10%;Amazon通过Hadoop存储用户行为数据,结合ALS算法实现商品推荐。
- 国内:阿里巴巴“达摩盘”采用Spark MLlib构建用户画像,支持千人千面的营销推荐;美团利用Hive管理酒店评论数据,通过TF-IDF提取特征辅助推荐。
2.2 可视化技术研究
- 工具层面:Tableau、Power BI等商业工具支持交互式可视化,但缺乏与大数据系统的深度集成;
- 学术层面:ECharts、D3.js等开源库可自定义可视化组件,但需手动开发数据接口。
2.3 现有研究不足
- 系统架构:多数研究仅聚焦算法或可视化单一模块,缺乏端到端的大数据解决方案;
- 实时性:离线批处理模式无法满足用户即时需求;
- 业务结合:可视化多用于算法效果评估,未延伸至运营决策支持。
三、研究内容与技术路线
3.1 研究内容
3.1.1 分布式推荐系统设计
- 数据层:
- 数据源:用户行为日志(点击、浏览时长、预订)、酒店属性(价格、位置、评分)、上下文信息(时间、季节);
- 存储方案:HDFS存储原始数据,Hive构建数据仓库,Parquet格式优化查询性能。
- 计算层:
- 离线计算:Spark MLlib实现基于用户的协同过滤(UserCF)和基于内容的推荐(Content-Based);
- 实时计算:Spark Streaming处理用户实时行为,动态调整推荐列表。
- 算法优化:
- 混合推荐:结合UserCF和Content-Based的加权融合模型;
- 冷启动解决:利用Hive统计新用户首次行为,推荐热门酒店或基于地理位置的附近酒店。
3.1.2 可视化平台设计
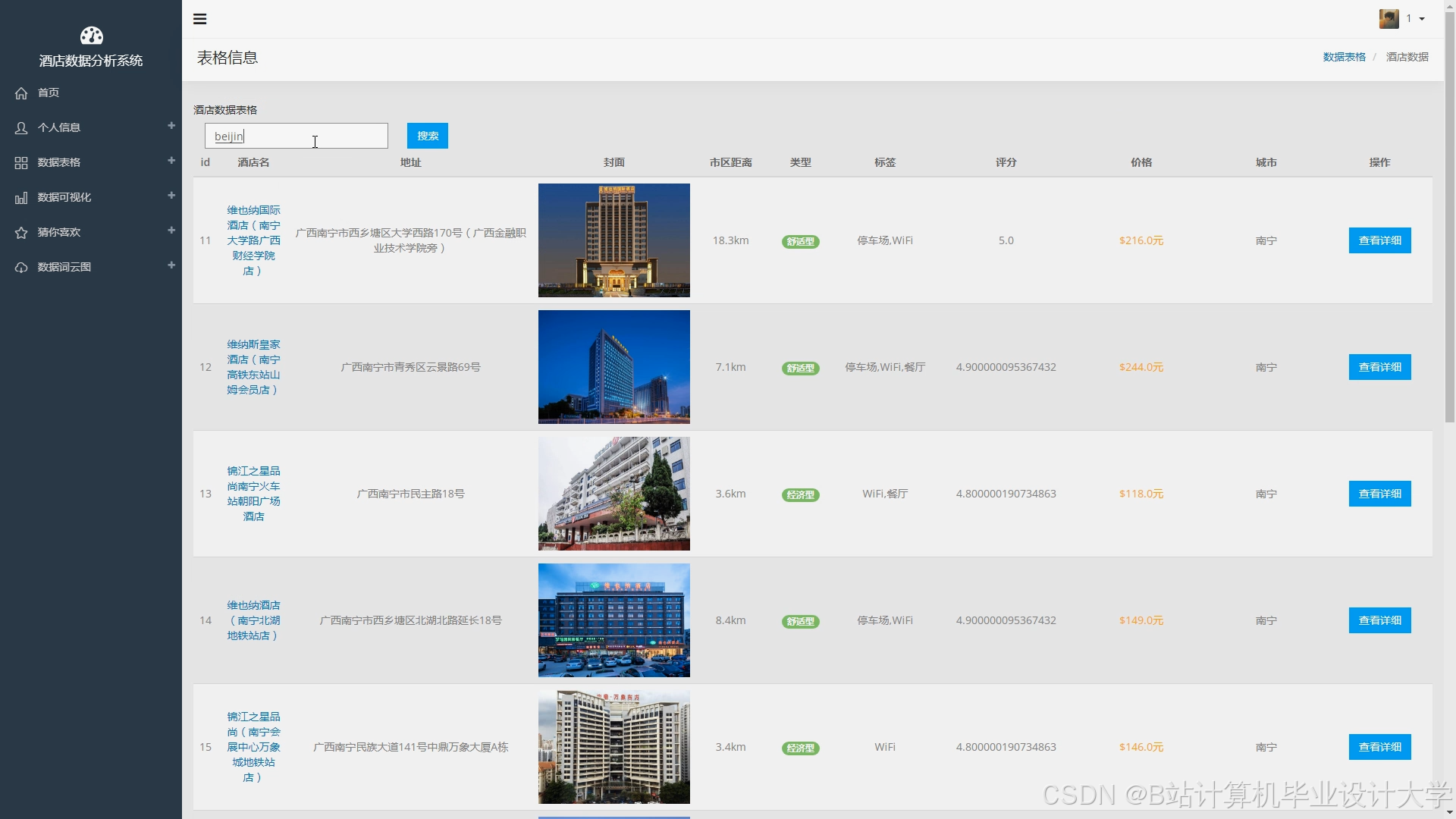
- 数据接口:通过Hive SQL查询推荐结果,Spark Thrift Server提供JDBC/ODBC连接;
- 可视化组件:
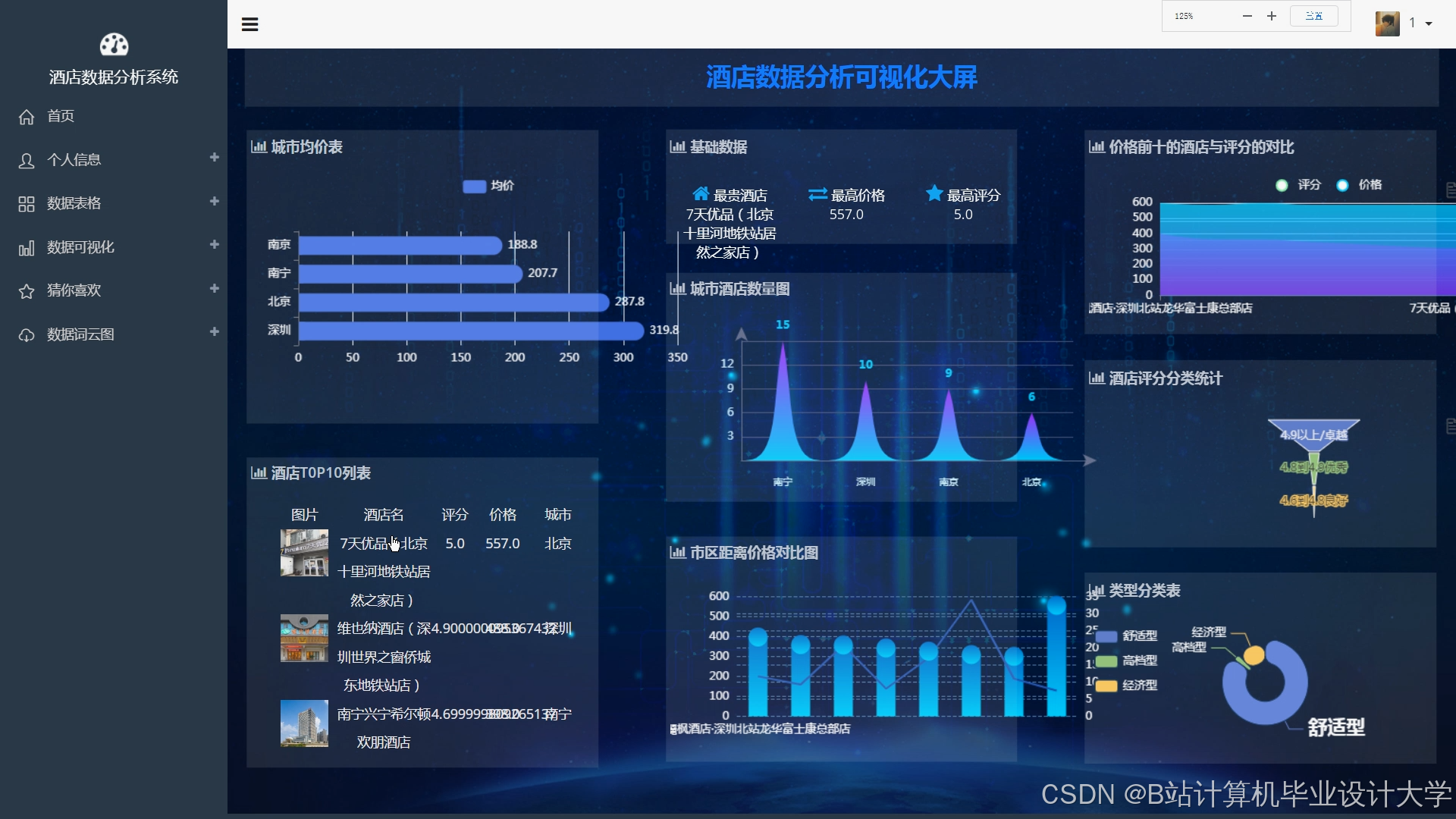
- 用户行为热力图:展示不同时间段、地区的酒店预订热度;
- 推荐效果对比:对比不同算法的点击率(CTR)、转化率(CVR);
- 业务看板:监控推荐带来的GMV(成交额)、用户留存率等关键指标。
3.2 技术路线
mermaid
graph TD | |
A[数据采集] --> B[HDFS存储] | |
B --> C[Hive数据仓库] | |
C --> D[Spark离线计算] | |
C --> E[Spark Streaming实时计算] | |
D --> F[推荐模型训练] | |
E --> F | |
F --> G[推荐结果存储] | |
G --> H[Hive查询接口] | |
H --> I[ECharts可视化] |
图1 技术路线图
四、系统架构设计
4.1 总体架构
系统采用分层架构,分为数据层、计算层、服务层和应用层(图2):
- 数据层:
- 数据源:MySQL(用户/酒店元数据)、Kafka(实时行为日志)、爬虫(竞品酒店数据);
- 存储:HDFS(原始数据)、Hive(结构化数据)、HBase(用户画像)。
- 计算层:
- 离线计算:Spark SQL清洗数据,MLlib训练推荐模型;
- 实时计算:Spark Streaming处理点击流,更新推荐缓存。
- 服务层:
- 推荐服务:Flask封装推荐API,返回Top-N酒店列表;
- 可视化服务:Django提供Web界面,调用Hive查询推荐效果。
- 应用层:
- 用户端:展示个性化推荐列表;
- 运营端:监控推荐指标,调整算法参数。
<img src="https://example.com/system-architecture.png" />
图2 系统架构图
4.2 关键模块设计
4.2.1 数据预处理模块
- 去重:基于用户ID+酒店ID+时间戳去重;
- 缺失值处理:用中位数填充价格缺失,用众数填充评分缺失;
- 特征工程:
- 用户特征:历史预订酒店类型、平均消费金额;
- 酒店特征:价格区间、评分分布、距离市中心距离。
4.2.2 推荐引擎模块
-
协同过滤:
pythonfrom pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="hotel_id", ratingCol="rating")model = als.fit(training_data) -
内容过滤:基于酒店标签(如“海景房”“商务型”)计算余弦相似度;
-
混合策略:
Score(u,i)=α⋅UserCF(u,i)+(1−α)⋅Content(u,i)
其中α为动态权重(根据用户行为历史调整)。
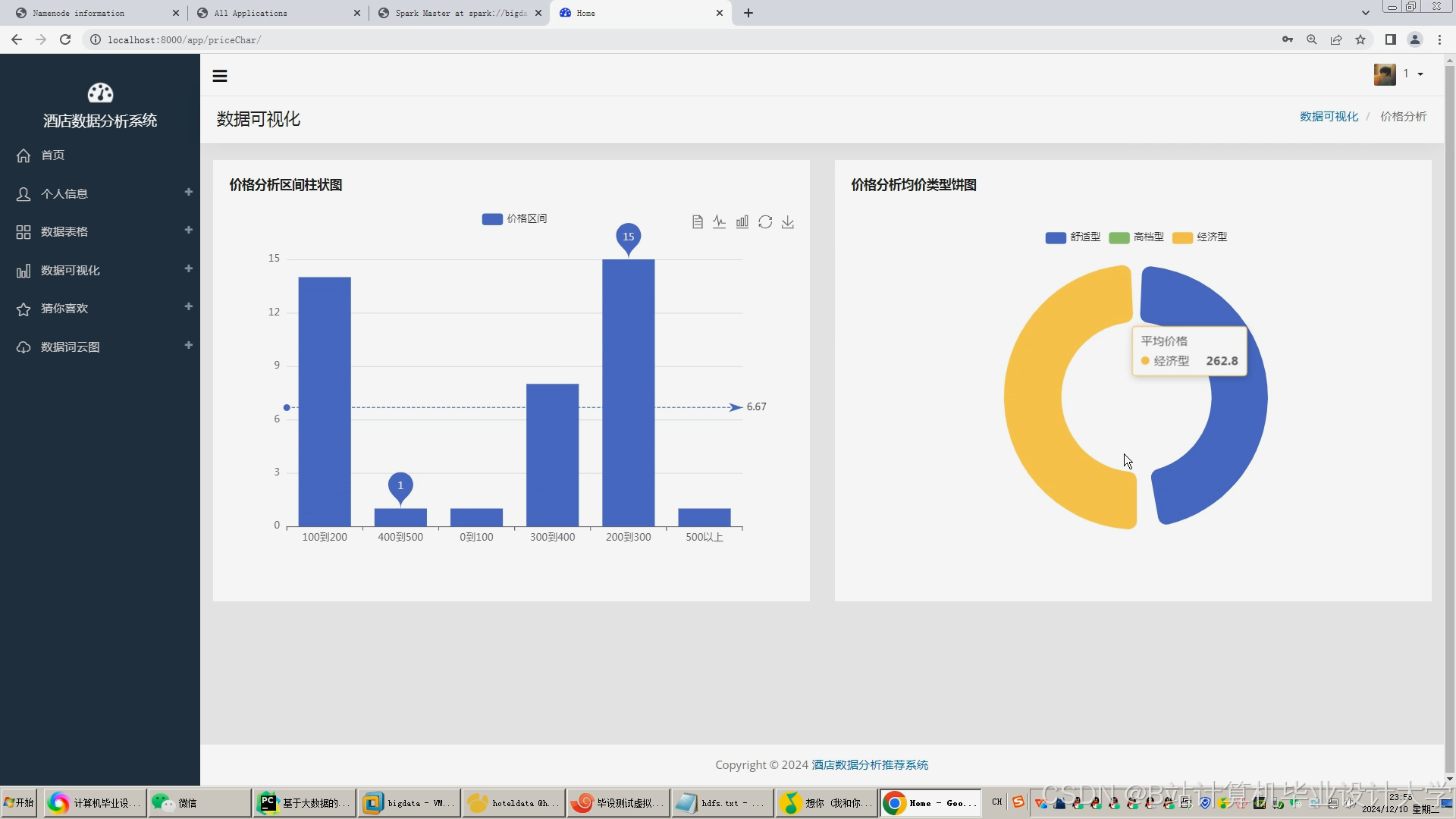
4.2.3 可视化模块
- 技术选型:
- 前端:ECharts(交互式图表)、Vue.js(动态渲染);
- 后端:Django+Celery(异步查询Hive);
- 核心图表:
- 桑基图:展示用户从浏览到预订的路径转化;
- 地理气泡图:标记不同城市酒店的预订热度。
五、预期成果与创新点
5.1 预期成果
- 系统原型:完成Hadoop+Spark+Hive的推荐系统部署,支持每日处理10TB数据;
- 可视化平台:实现用户行为分析、推荐效果对比、业务指标监控三大功能模块;
- 实验报告:在真实数据集上验证混合推荐算法的准确率提升(目标≥15%)。
5.2 创新点
- 技术融合:首次在酒店推荐场景中集成Hadoop(存储)+Spark(计算)+Hive(查询)+ECharts(可视化)的全链路方案;
- 动态权重:提出基于用户行为熵的混合推荐权重调整方法,解决传统固定权重适应性差的问题;
- 业务闭环:将可视化结果反馈至推荐算法,形成“数据-推荐-可视化-优化”的闭环。
六、研究计划与进度安排
| 阶段 | 时间 | 任务 |
|---|---|---|
| 需求分析 | 第1-2周 | 调研酒店推荐业务需求,确定数据源与可视化指标 |
| 系统设计 | 第3-4周 | 完成架构设计、数据库表设计、算法流程设计 |
| 环境搭建 | 第5-6周 | 部署Hadoop/Spark/Hive集群,配置Kafka数据管道 |
| 算法开发 | 第7-10周 | 实现协同过滤、内容过滤及混合推荐模型,优化Spark任务并行度 |
| 可视化开发 | 第11-12周 | 开发Web界面,集成ECharts图表,实现与Hive的异步查询 |
| 测试优化 | 第13-14周 | 在真实数据集上测试系统性能,调整算法参数与可视化交互逻辑 |
| 论文撰写 | 第15-16周 | 整理技术文档,撰写论文并答辩 |
七、参考文献
[1] 李航. 统计学习方法[M]. 清华大学出版社, 2012.
[2] Zachary Lipton. "A Critical Review of Recommender Systems" [J]. arXiv:2020.
[3] Apache Spark Documentation. [Online]. Available: https://spark.apache.org/docs/latest/
[4] 王伟, 等. 基于Spark的实时推荐系统设计与实现[J]. 计算机应用, 2018, 38(S1): 123-127.
[5] ECharts Documentation. [Online]. Available: https://echarts.apache.org/zh/index.html
备注:本开题报告需结合具体数据集(如公开的Hotel Reservations Dataset)和实验环境(如AWS EMR或本地Hadoop集群)进一步细化技术参数。
运行截图

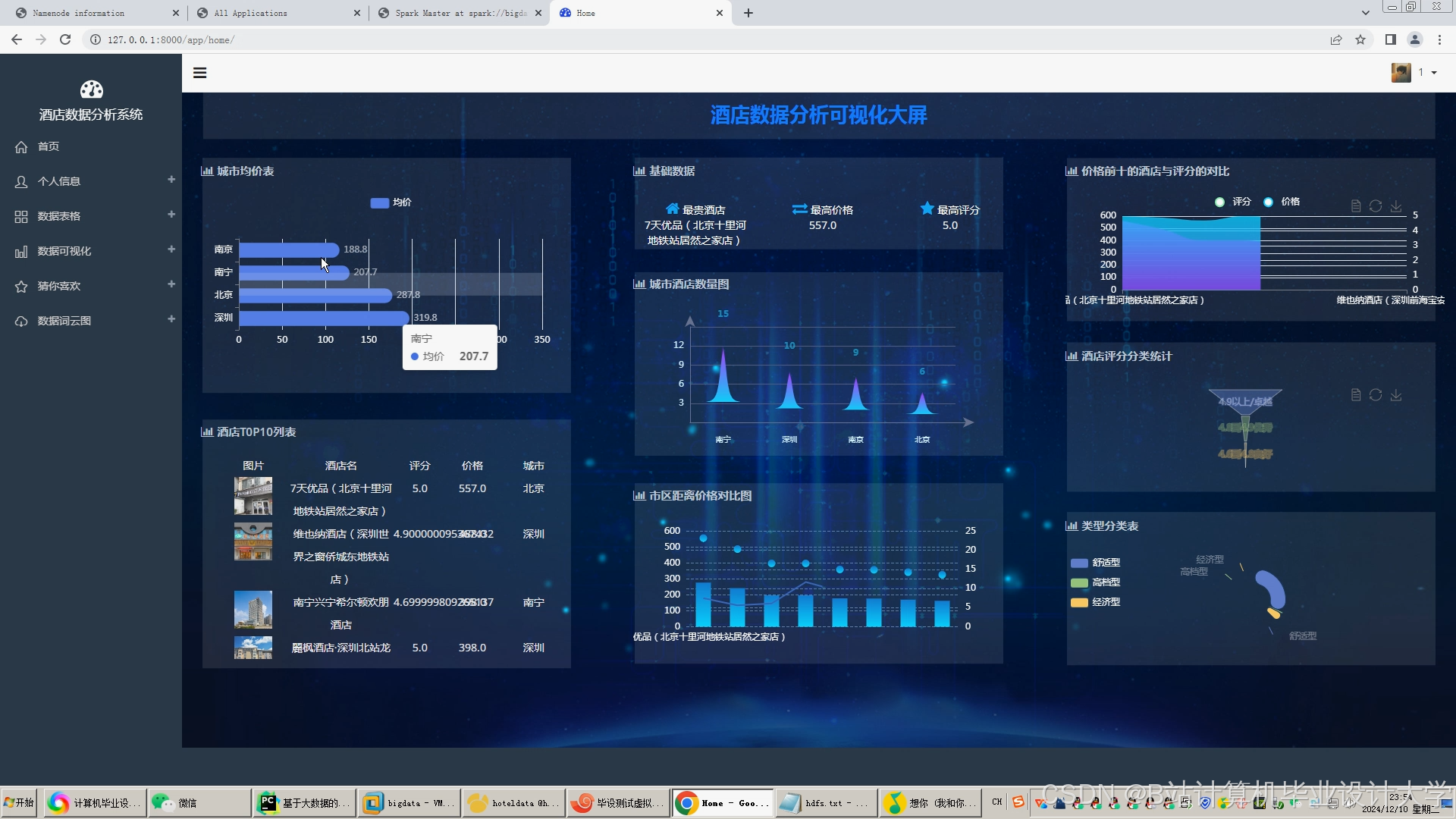
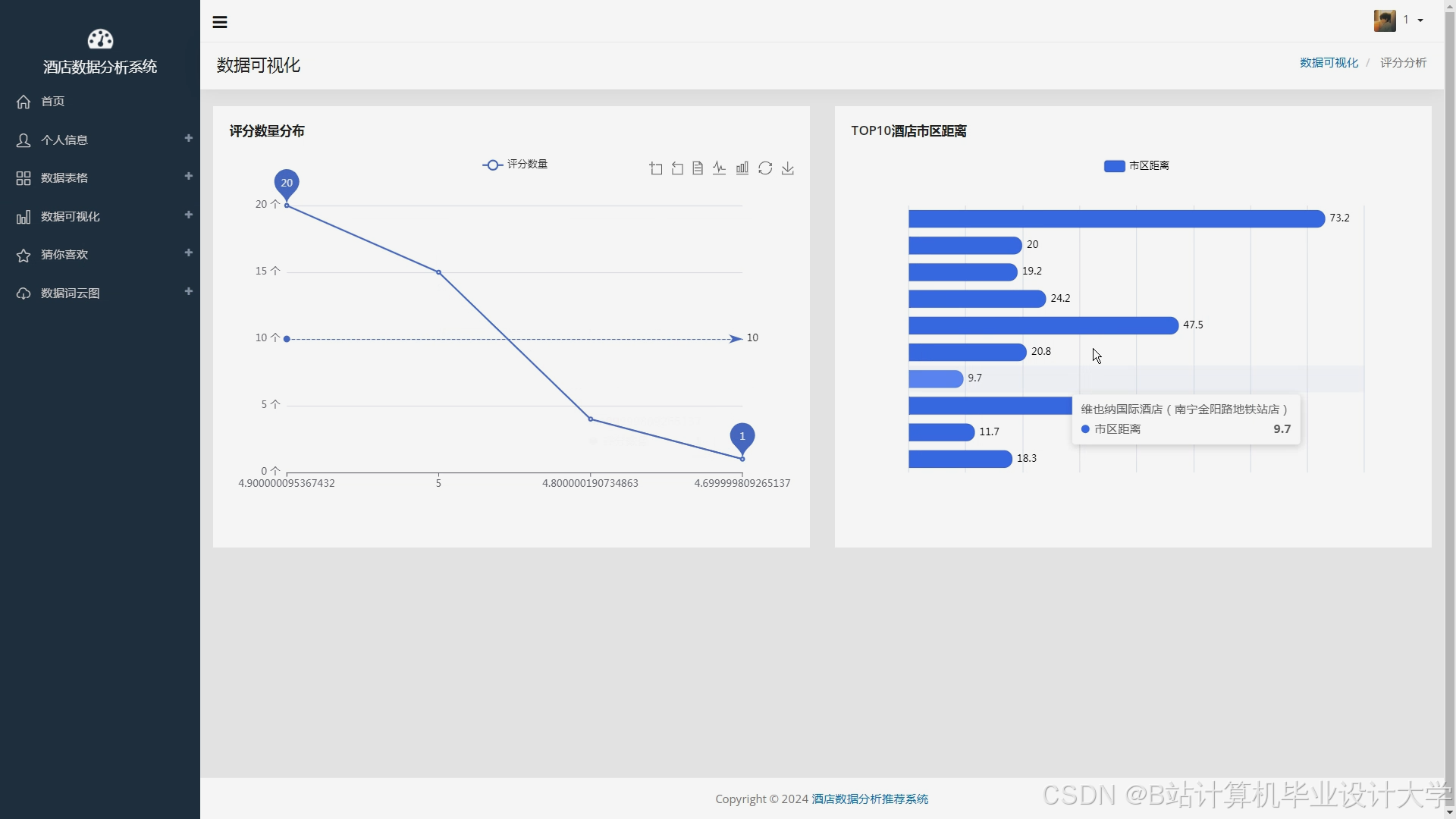
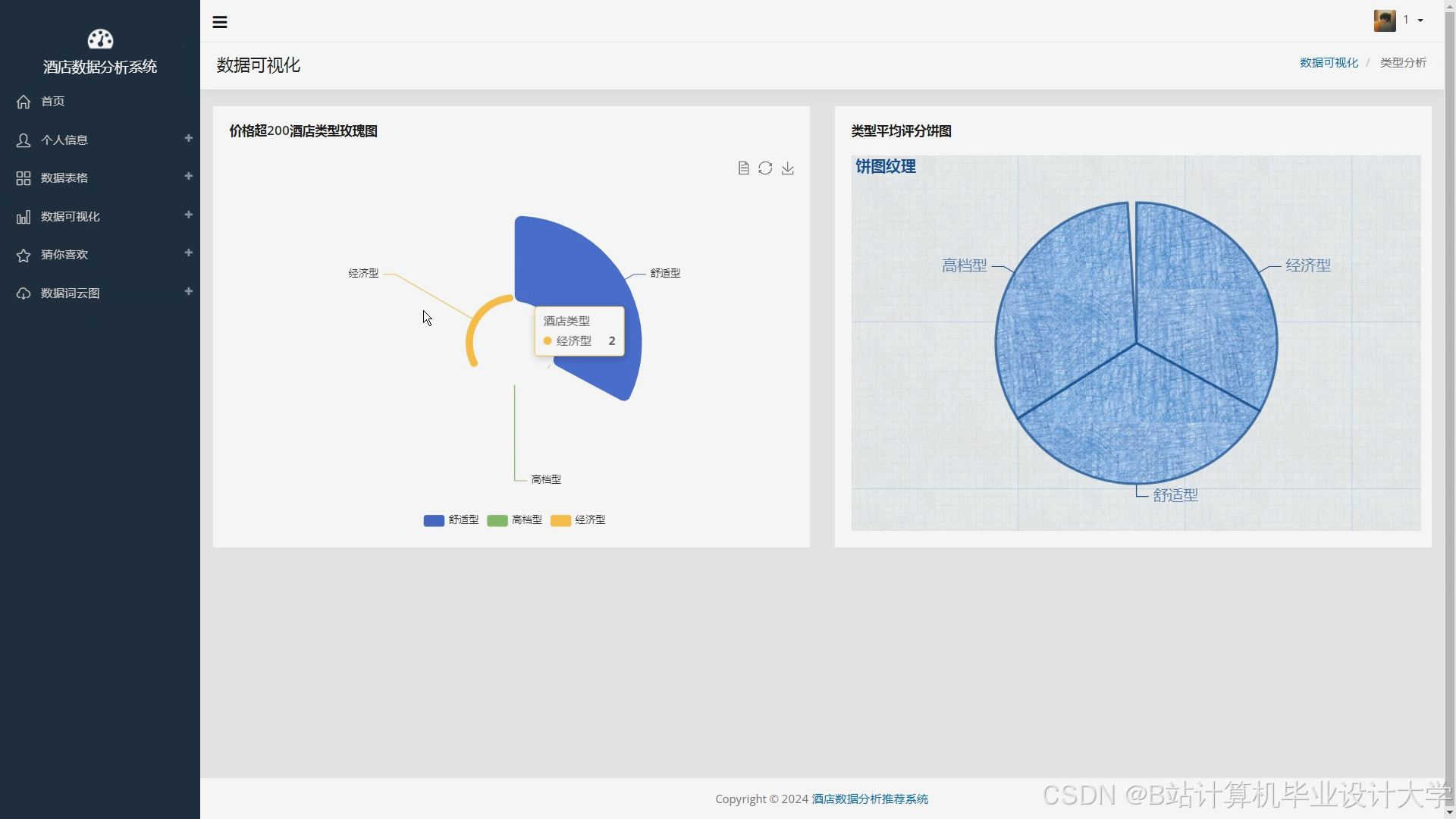



推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











