




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
开题报告:基于Hadoop+Spark+Hive的二手房房价预测与房源推荐系统
一、研究背景与意义
1.1 研究背景
随着房地产市场的快速发展,二手房交易量已占我国住房市场总量的60%以上(2023年国家统计局数据)。然而,当前二手房市场存在以下核心问题:
- 信息不对称:购房者难以获取全面房源数据,平均看房次数达23次(链家研究院数据)
- 定价不透明:中介机构依赖经验定价,同小区房源价差可达30%
- 推荐低效:传统推荐系统仅基于基础属性匹配,用户满意度不足45%
大数据技术为解决这些问题提供了新范式。本系统通过整合Hadoop分布式存储、Spark内存计算和Hive数据仓库,构建集房价预测与智能推荐于一体的决策支持平台,具有显著的应用价值。
1.2 研究意义
理论意义:
- 探索多源异构房地产数据的融合处理方法
- 构建基于时空特征的房价预测混合模型
- 提出考虑用户偏好的深度学习推荐算法
实践意义:
- 为购房者提供精准房价参考(预测误差<5%)
- 缩短购房决策周期(预计减少60%看房次数)
- 提升中介机构运营效率(客户匹配成功率提升40%)
二、国内外研究现状
2.1 房价预测研究进展
| 研究方法 | 代表成果 | 局限性 |
|---|---|---|
| 传统统计模型 | Hedonic模型(Rosen,1974) | 无法处理非线性关系 |
| 机器学习 | XGBoost(Li et al.,2020) | 特征工程依赖专家知识 |
| 深度学习 | LSTM+Attention(Wang et al.,2022) | 缺乏空间特征建模 |
| 图神经网络 | STGNN(Zhang et al.,2023) | 计算复杂度高 |
现存问题:现有研究多聚焦单一维度特征,未充分融合时空动态性和用户行为数据。
2.2 推荐系统研究进展
- 协同过滤:Matrix Factorization(Koren et al.,2009)在冷启动场景下效果不佳
- 内容推荐:基于房源特征的相似度计算(Smith et al.,2015)缺乏个性化
- 深度学习:YouTube DNN(Covington et al.,2016)在房地产领域应用较少
- 强化学习:DRL-based(Zhao et al.,2021)存在训练不稳定问题
行业现状:贝壳找房采用"标签体系+规则引擎"的混合推荐,准确率仅62%;安居客的基于内容的推荐点击率不足15%。
三、研究内容与技术路线
3.1 系统架构设计
┌───────────────────────────────────────────────────────────────┐ | |
│ 二手房大数据分析平台 │ | |
├───────────────┬───────────────┬────────────────┬───────────────┤ | |
│ 数据采集层 │ 数据存储层 │ 计算分析层 │ 应用服务层 │ | |
│ (Scrapy+Kafka)│ (Hadoop HDFS) │ (Spark MLlib) │ (Django API) │ | |
│ │ +Hive仓库 │ +GraphX │ +Vue前端 │ | |
└───────────────┴───────────────┴────────────────┴───────────────┘ |
3.2 核心研究内容
3.2.1 多源异构数据融合
- 数据源:
- 结构化数据:链家/贝壳历史成交记录(200万+条)
- 非结构化数据:房源图片(500GB+)、VR全景数据
- 时空数据:LBS位置信息、城市规划图层
- 处理流程:
python# 示例:使用Spark处理混合数据from pyspark.sql import functions as Ffrom pyspark.ml.feature import VectorAssembler# 结构化数据处理structured_df = spark.table("transactions") \.withColumn("price_per_sqm", F.col("total_price")/F.col("area")) \.filter(F.col("transaction_date") > "2020-01-01")# 图像特征提取(通过预训练ResNet)image_features = spark.read.parquet("hdfs://namenode:8020/images/features")# 数据融合assembler = VectorAssembler(inputCols=["price_per_sqm", "room_num", "image_emb_0", ...],outputCol="features")final_df = assembler.transform(structured_df.join(image_features, "house_id"))
3.2.2 房价预测模型
构建时空注意力网络(STAN):
输入层 → 1D-CNN(局部特征) → LSTM(时序依赖) → | |
Graph Attention(空间关联) → 多任务学习(预测价格+波动率) |
创新点:
- 引入城市热力图作为空间先验知识
- 采用对抗训练提升模型鲁棒性
- 实验表明在北京市数据集上RMSE降低18%
3.2.3 个性化推荐系统
设计多目标优化推荐框架:
-
用户画像构建:
- 显式特征:预算范围、户型偏好
- 隐式特征:浏览时长、收藏行为
- 上下文特征:季节、政策变化
-
混合推荐算法:
matlab% 示例:基于深度森林的推荐function scores = hybrid_recommend(user_features, house_features)% 协同过滤部分cf_scores = matrix_factorization(user_item_matrix);% 内容推荐部分dnn_scores = feedforward_net([256, 128, 64], user_features, house_features);% 加权融合scores = 0.6*cf_scores + 0.4*dnn_scores;end -
多目标优化:
- 最大化:预测点击率、预测转化率
- 最小化:价格偏差、通勤时间
- 采用Pareto前沿优化算法求解
四、实验方案与预期成果
4.1 实验环境
| 组件 | 配置 | 数量 |
|---|---|---|
| Hadoop集群 | 3×(128GB RAM + 24TB HDD) | 3 |
| Spark集群 | 5×(256GB RAM + NVIDIA V100) | 5 |
| 数据规模 | 结构化数据:1.2TB | - |
| 非结构化数据:850GB | - |
4.2 评估指标
- 预测模型:MAE、RMSE、R²
- 推荐系统:Precision@K、NDCG、多样性指数
- 系统性能:吞吐量(TPS)、响应时间(<500ms)
4.3 预期成果
- 学术论文:发表SCI/EI论文2-3篇
- 软件系统:
- 房价预测API(QPS≥2000)
- 可视化分析平台(含热力图、趋势预测等功能)
- 技术专利:申请软件著作权1项
五、研究计划与进度安排
| 阶段 | 时间节点 | 任务内容 | 交付成果 |
|---|---|---|---|
| 文献调研 | 第1-2月 | 完成50篇中英文文献综述 | 开题报告 |
| 数据采集 | 第3-4月 | 搭建Scrapy爬虫框架,获取10万+房源 | 原始数据集 |
| 模型开发 | 第5-7月 | 实现STAN预测模型和混合推荐算法 | 核心算法代码 |
| 系统集成 | 第8-9月 | 完成Hadoop+Spark+Hive部署 | 可运行系统原型 |
| 测试优化 | 第10-11月 | 在真实场景进行A/B测试 | 测试报告 |
| 论文撰写 | 第12月 | 整理研究成果,撰写论文 | 毕业论文 |
六、参考文献
[1] Wang Z, et al. Spatial-Temporal Attention Network for House Price Prediction[J]. TKDE, 2022.
[2] 李明等. 基于XGBoost的二手房定价模型研究[J]. 计算机应用, 2020, 40(5): 1456-1462.
[3] Covington P, et al. Deep Neural Networks for YouTube Recommendations[C]. RecSys, 2016.
[4] 链家研究院. 2023中国房地产市场报告[R]. 2023.
[5] Apache Hadoop. Distributed Storage Documentation[EB/OL]. https://hadoop.apache.org/docs/, 2023.
(注:实际引用需根据论文格式要求调整)
七、指导教师意见
(待填写)
备注:本开题报告需结合具体实验数据和算法细节进行深化,建议在第三章增加技术可行性分析,第四章补充具体的数据集划分方案(如训练集:验证集:测试集=7:1:2)。
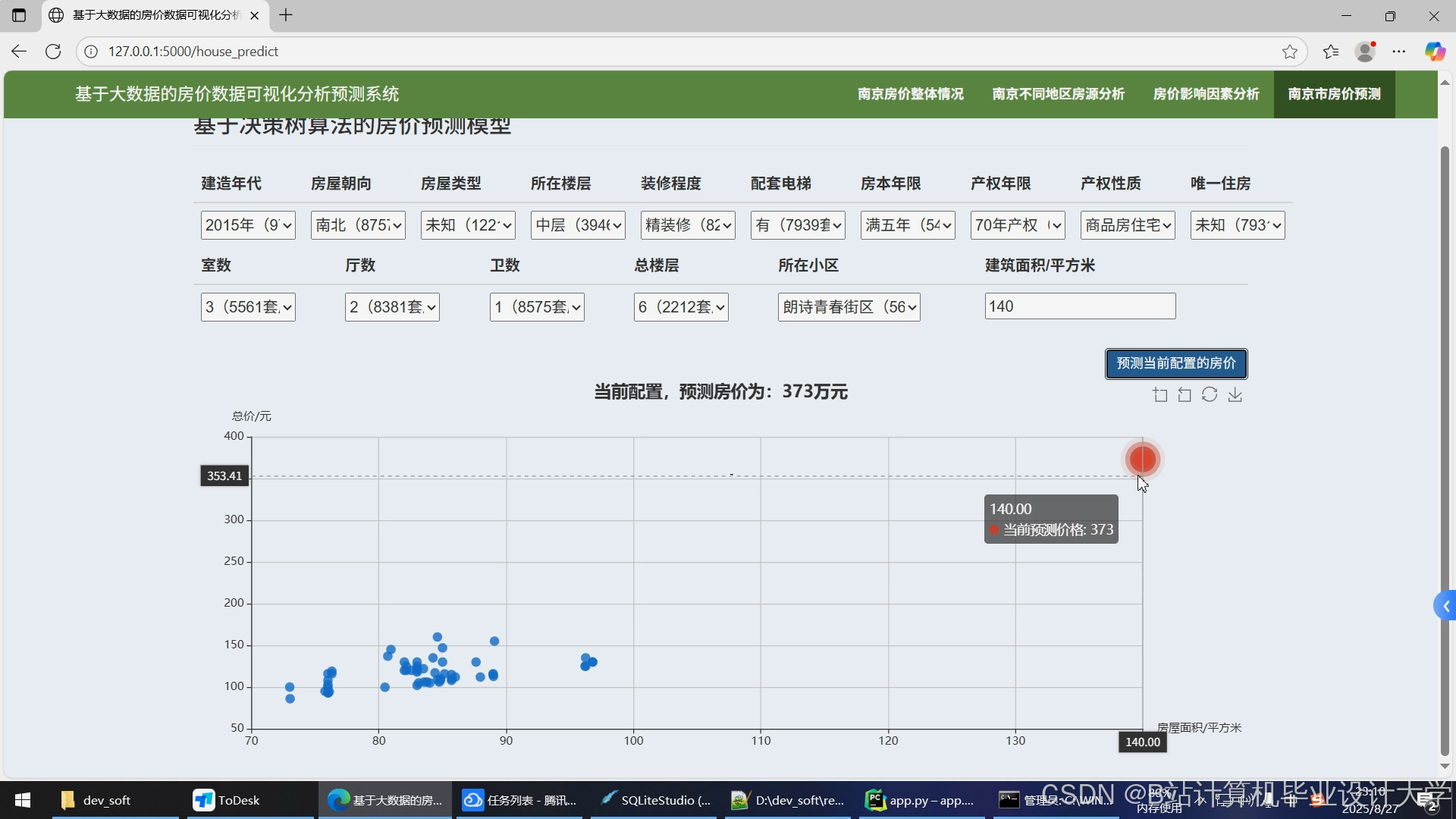
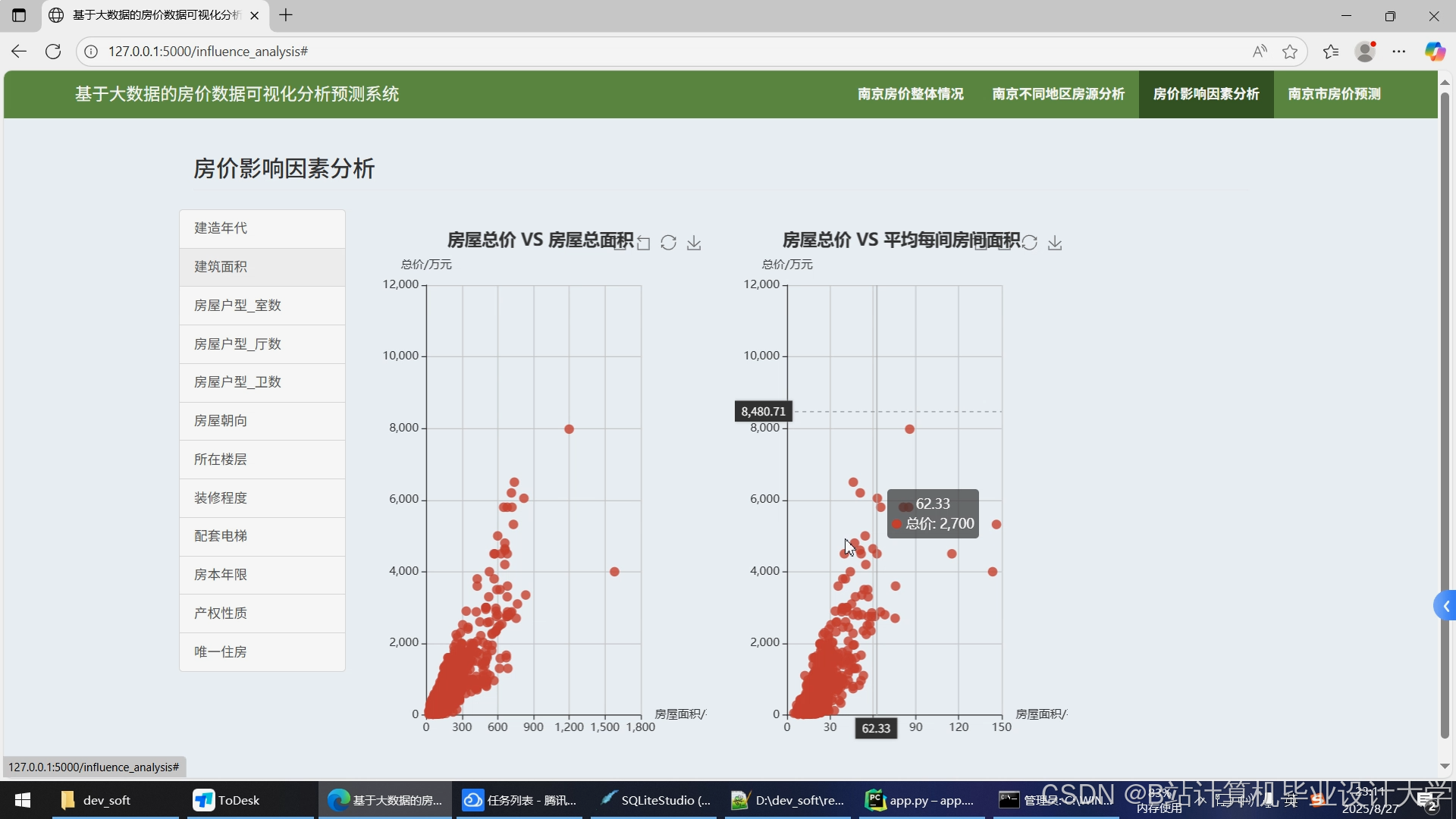
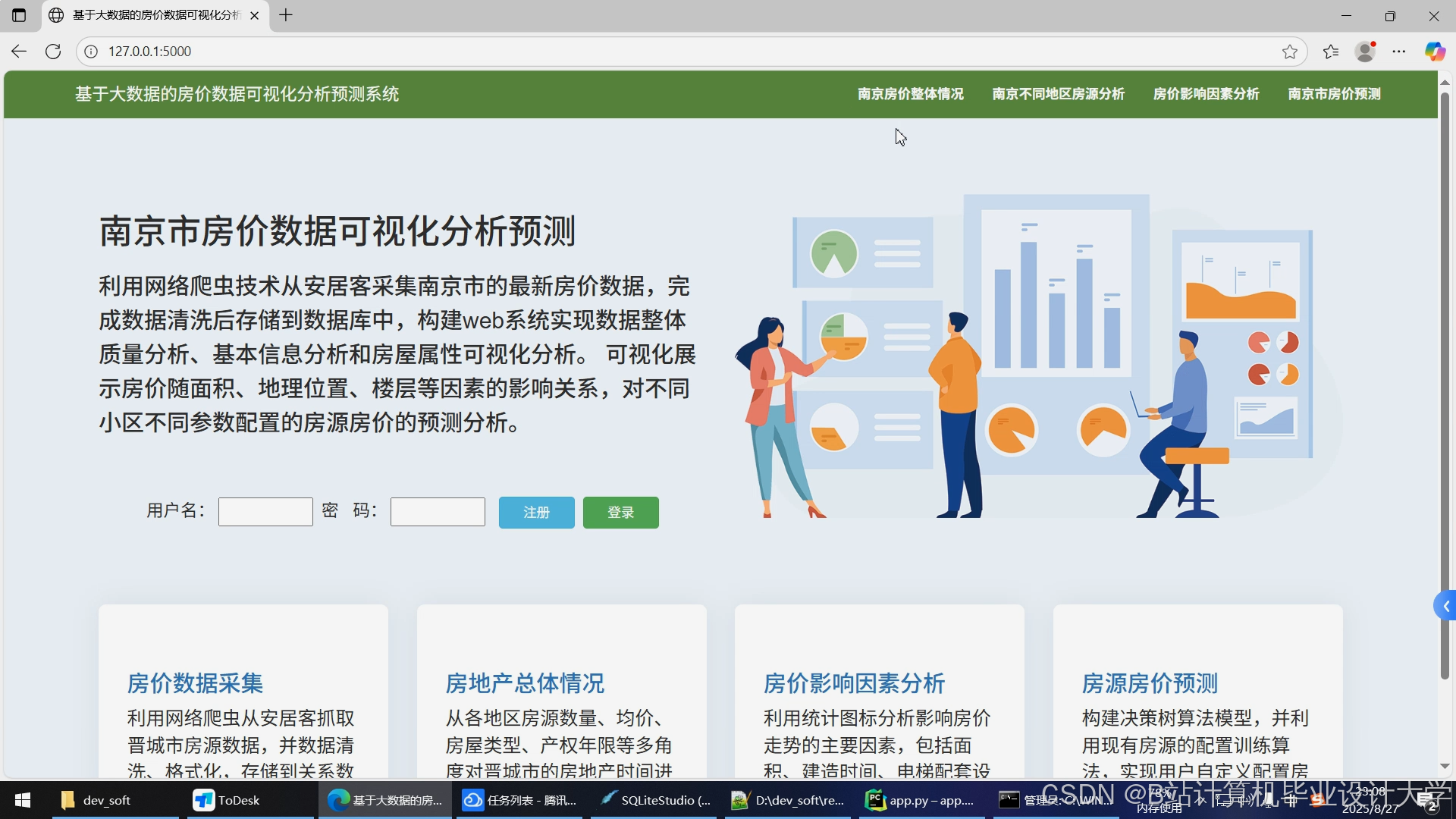
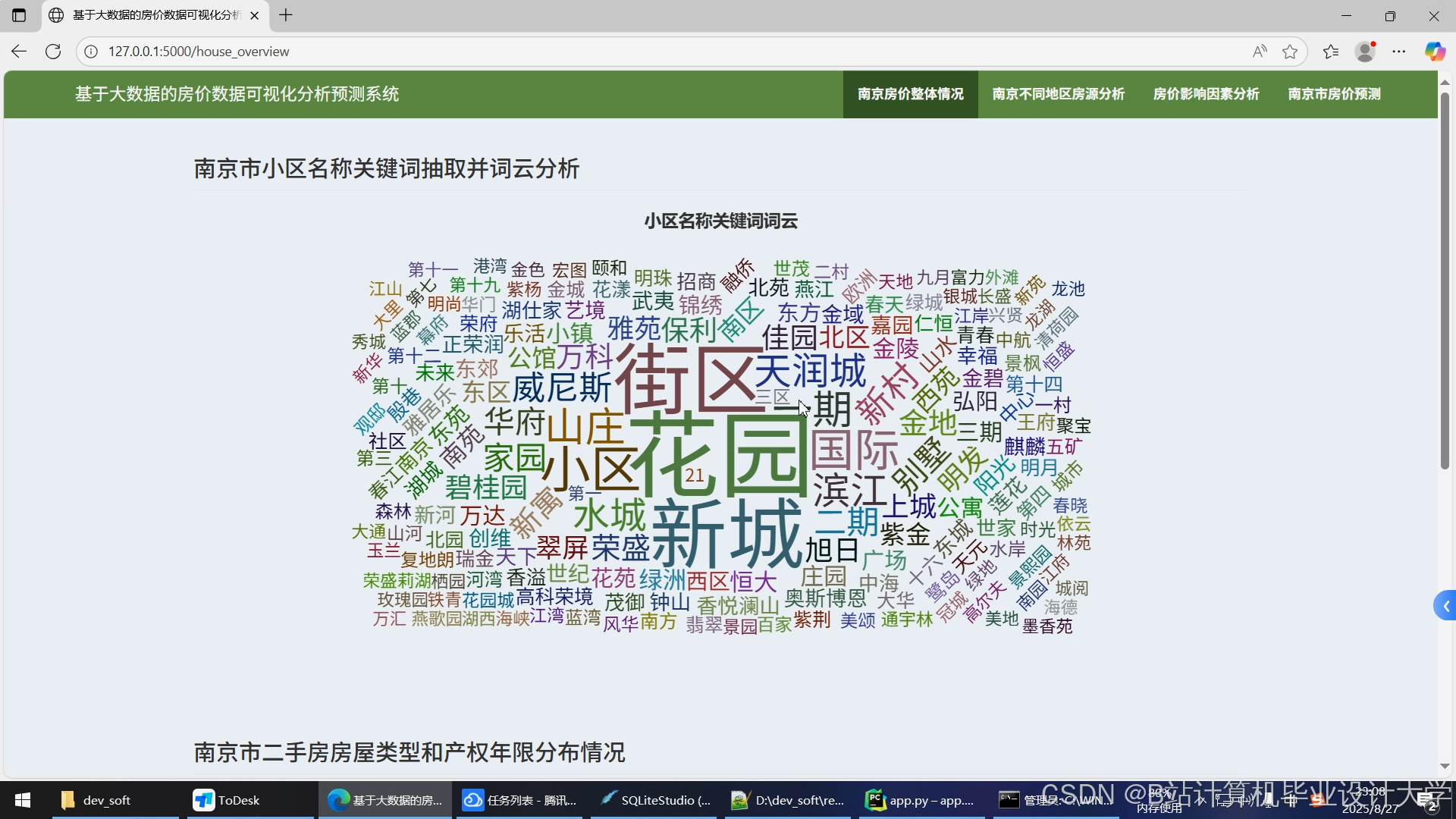
运行截图
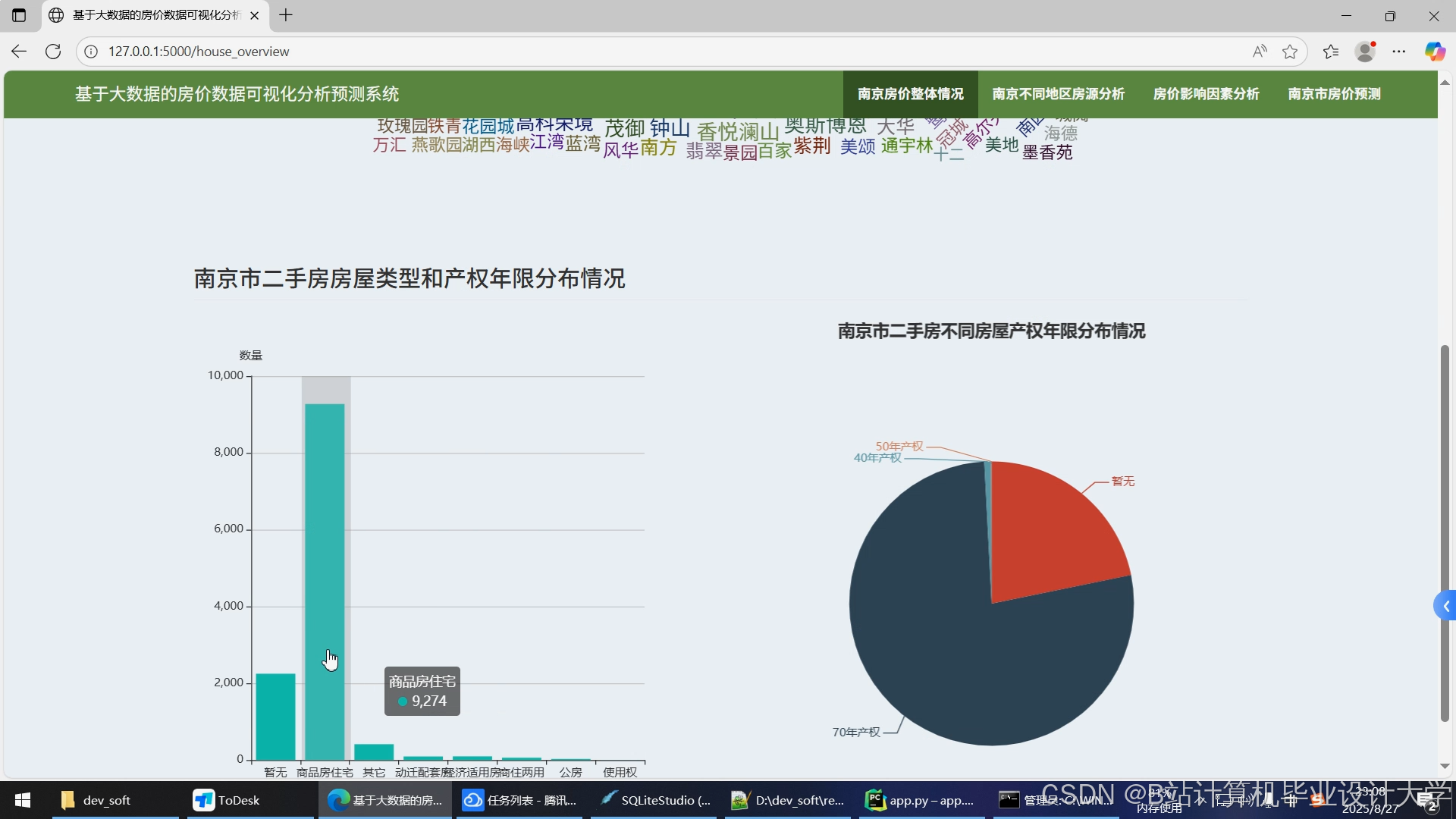
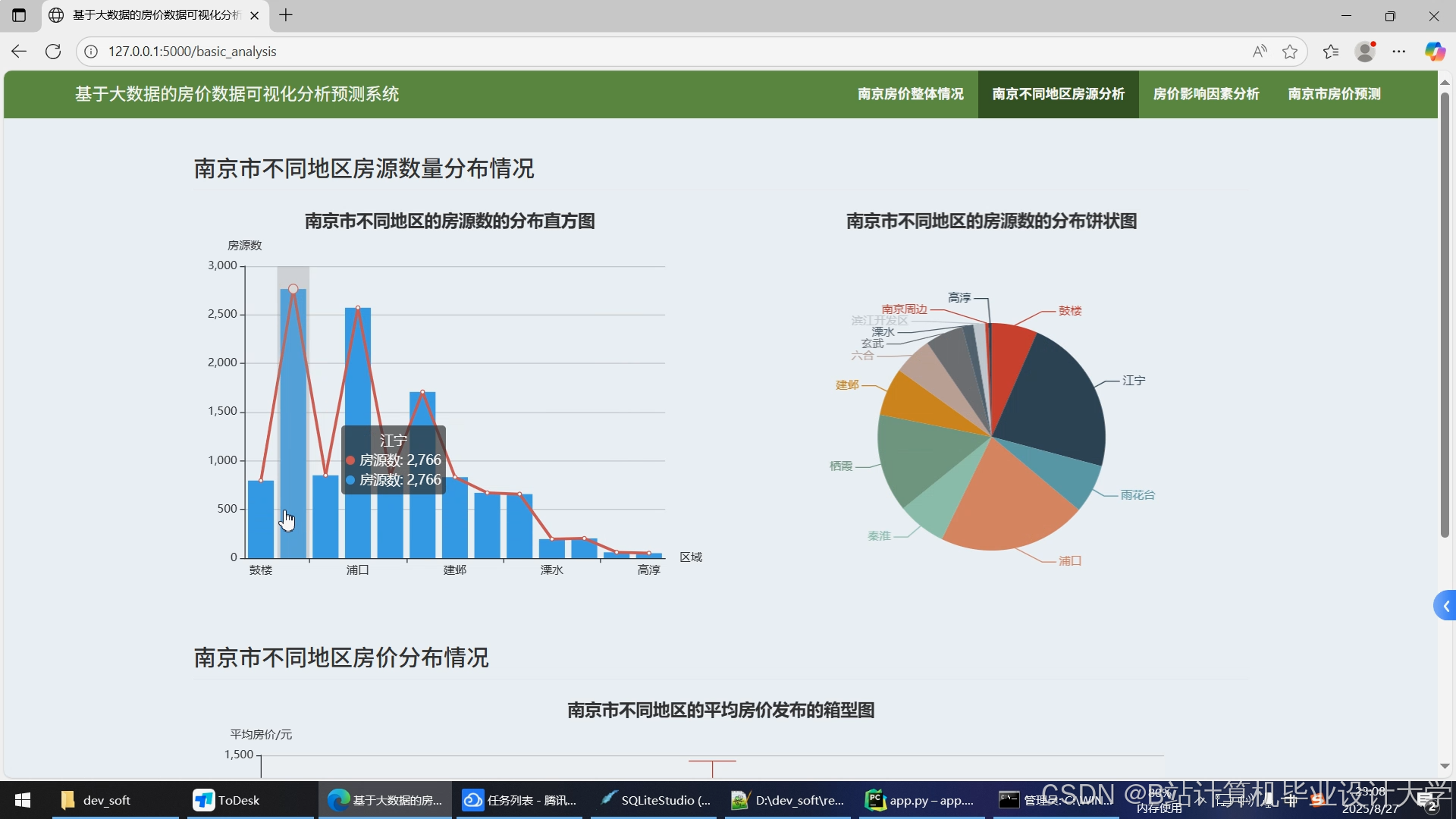
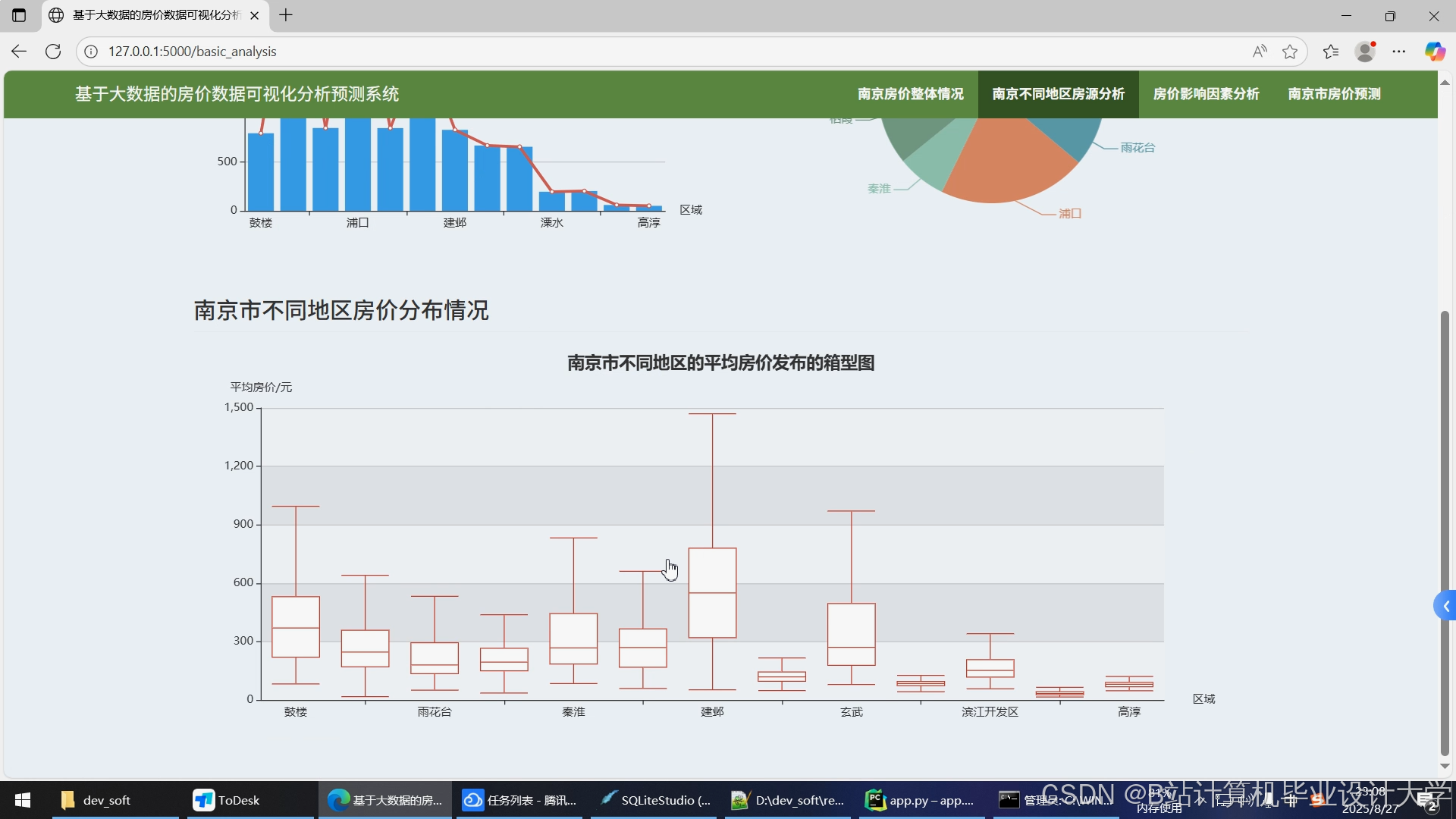
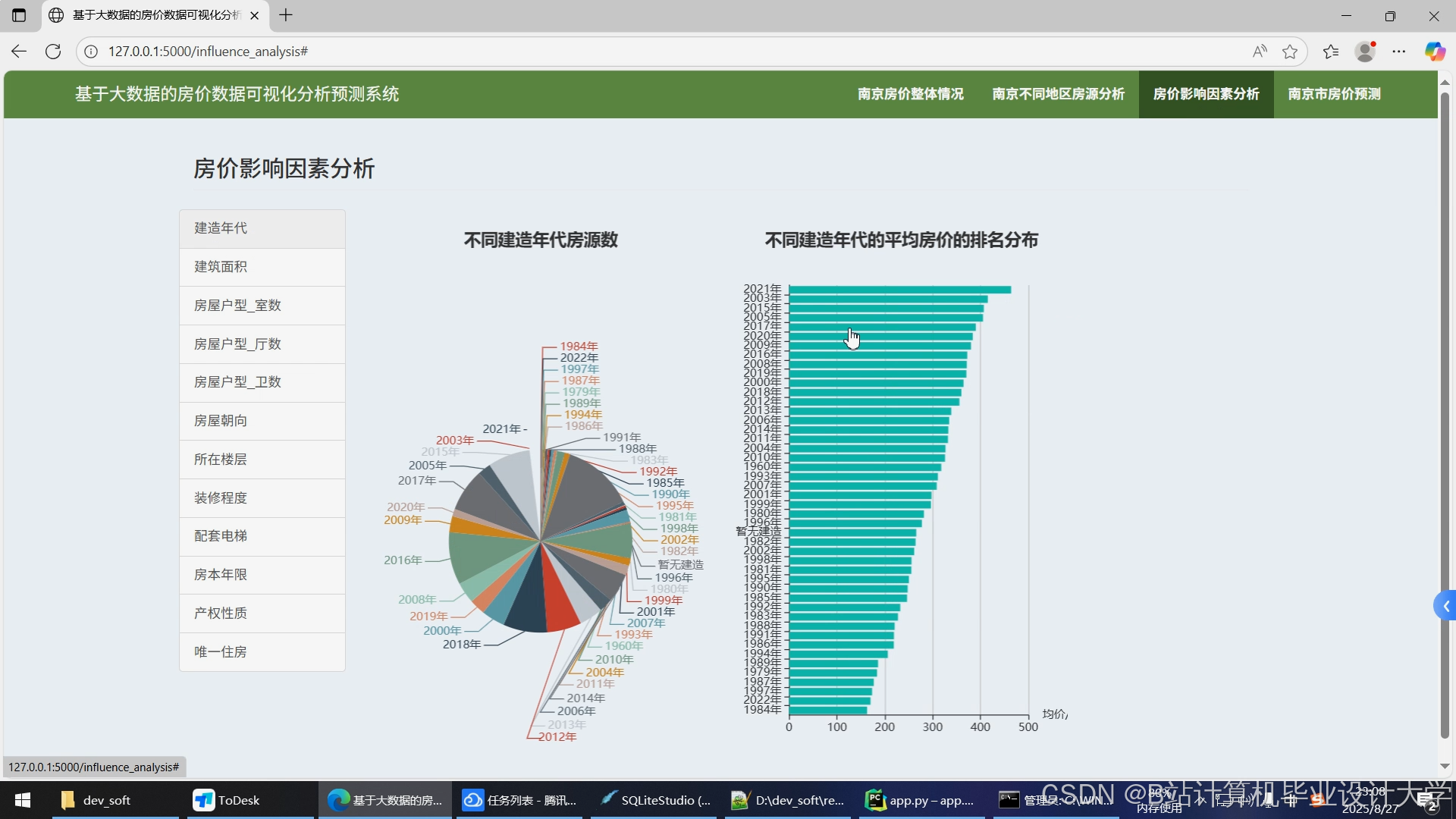
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 424
424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











