




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive在地铁预测可视化智慧轨道交通系统中的应用研究
摘要:随着城市化进程加速,地铁客流量呈指数级增长,传统数据处理方式难以满足需求。本文聚焦Hadoop、Spark和Hive技术栈在智慧轨道交通系统中的应用,通过分布式存储、内存计算与数据仓库的协同,实现地铁客流量的高精度预测与动态可视化。实验结果表明,该系统将早晚高峰预测误差率(MAE)降至10%以下,响应时间缩短至500ms内,为智慧交通决策提供科学依据。
关键词:Hadoop;Spark;Hive;地铁客流量预测;可视化;时空特征融合
一、引言
全球城市化率突破55%背景下,超大城市日均交通数据量已超5PB,涵盖公交刷卡、浮动车GPS、视频检测等20余类异构数据。以北京地铁为例,2024年日均客流量突破1200万人次,单日最高客流量达1350万人次,日均产生交通数据超5PB。传统关系型数据库在存储容量、处理速度及扩展性上难以满足需求,而Hadoop的HDFS分布式存储、Spark内存计算与Hive数据仓库的协同架构,为海量交通数据的高效处理提供了技术支撑。
二、技术架构与核心组件
2.1 分布式存储层:Hadoop HDFS
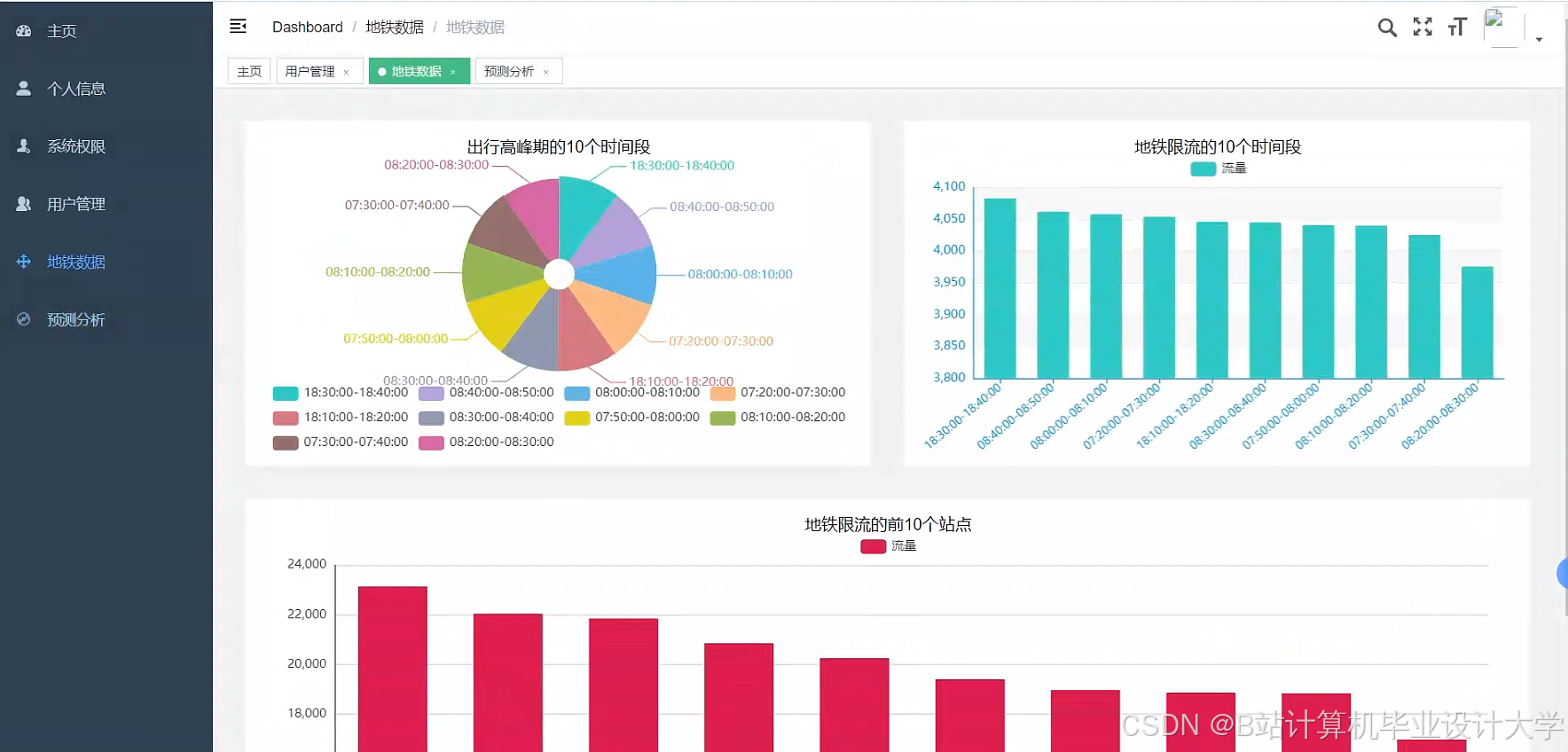
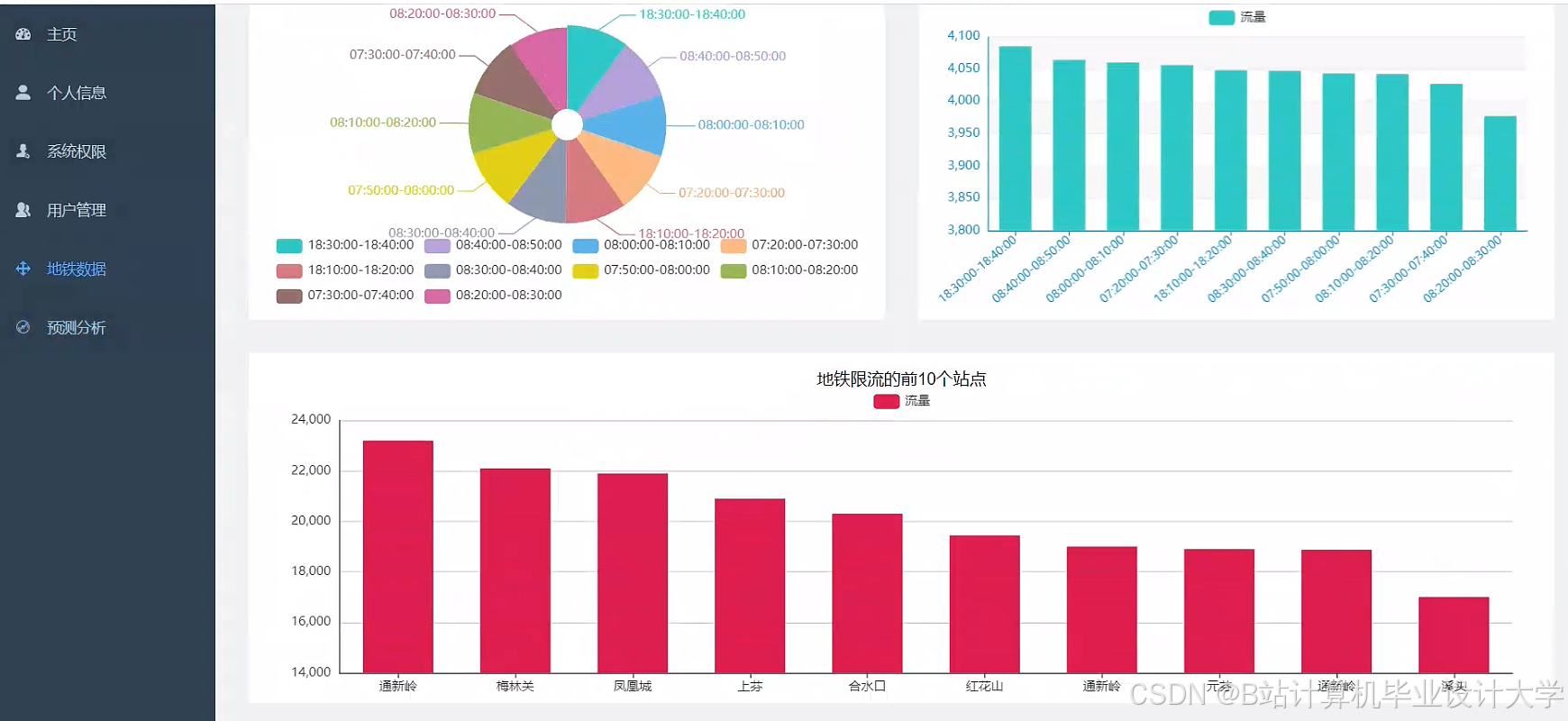
HDFS采用主从架构,通过三副本冗余机制实现99.99%的数据可用性。深圳地铁集团利用HDFS存储全年约200亿条AFC刷卡数据,支持横向扩展至千节点集群,满足PB级数据存储需求。其流式接入能力通过Flume+Kafka实现,可处理10万条/秒的闸机刷卡记录吞吐量,并按时间(天/小时)和站点ID分区存储数据,使查询效率提升80%。
2.2 数据仓库层:Hive
Hive基于HDFS构建数据仓库,提供类SQL的HiveQL接口,将查询转换为MapReduce或Spark作业执行。北京交通发展研究院利用HiveQL实现数据清洗:
sql
CREATE EXTERNAL TABLE afc_raw ( | |
card_id STRING, station_id STRING, entry_time TIMESTAMP | |
) PARTITIONED BY (dt STRING) STORED AS ORC; | |
INSERT OVERWRITE TABLE afc_cleaned | |
SELECT DISTINCT card_id, station_id, entry_time | |
FROM afc_raw | |
WHERE entry_time BETWEEN '2024-01-01' AND '2024-01-31'; |
通过动态分区模式与ORC列式存储格式,数据压缩率提升60%,支持按节假日、天气等维度灵活查询。
2.3 计算层:Spark
Spark通过RDD和DataFrame API实现内存计算,数据处理速度较Hadoop MapReduce提升10-100倍。其核心组件包括:
- Spark SQL:提供结构化数据查询与分析能力,支持与Hive表无缝集成。
- Spark Streaming:与Kafka集成实现毫秒级延迟的实时数据流处理,动态聚合5分钟站点客流量。
- MLlib:提供LSTM、XGBoost等机器学习算法,北京地铁应用LSTM模型将MAE较ARIMA降低30%。
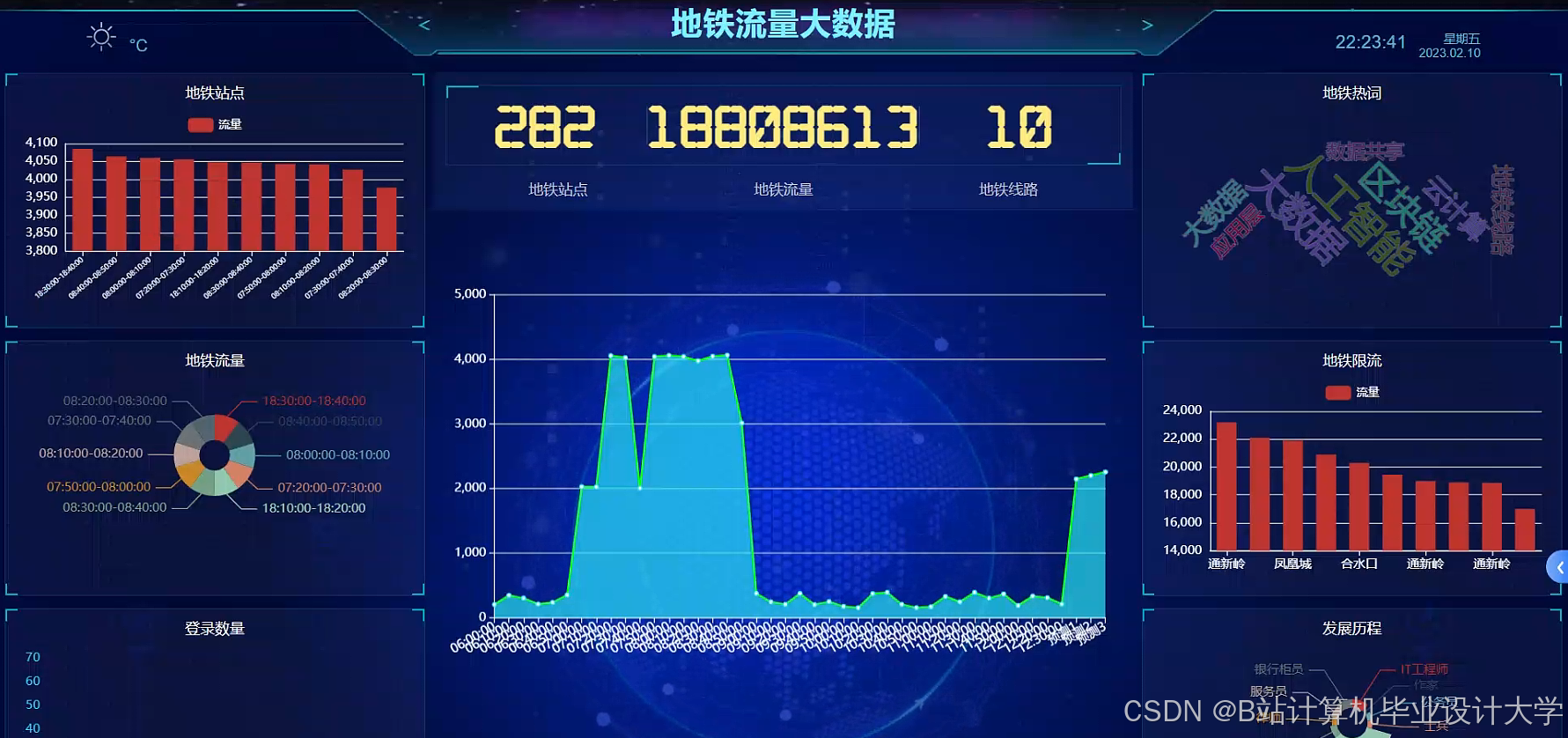
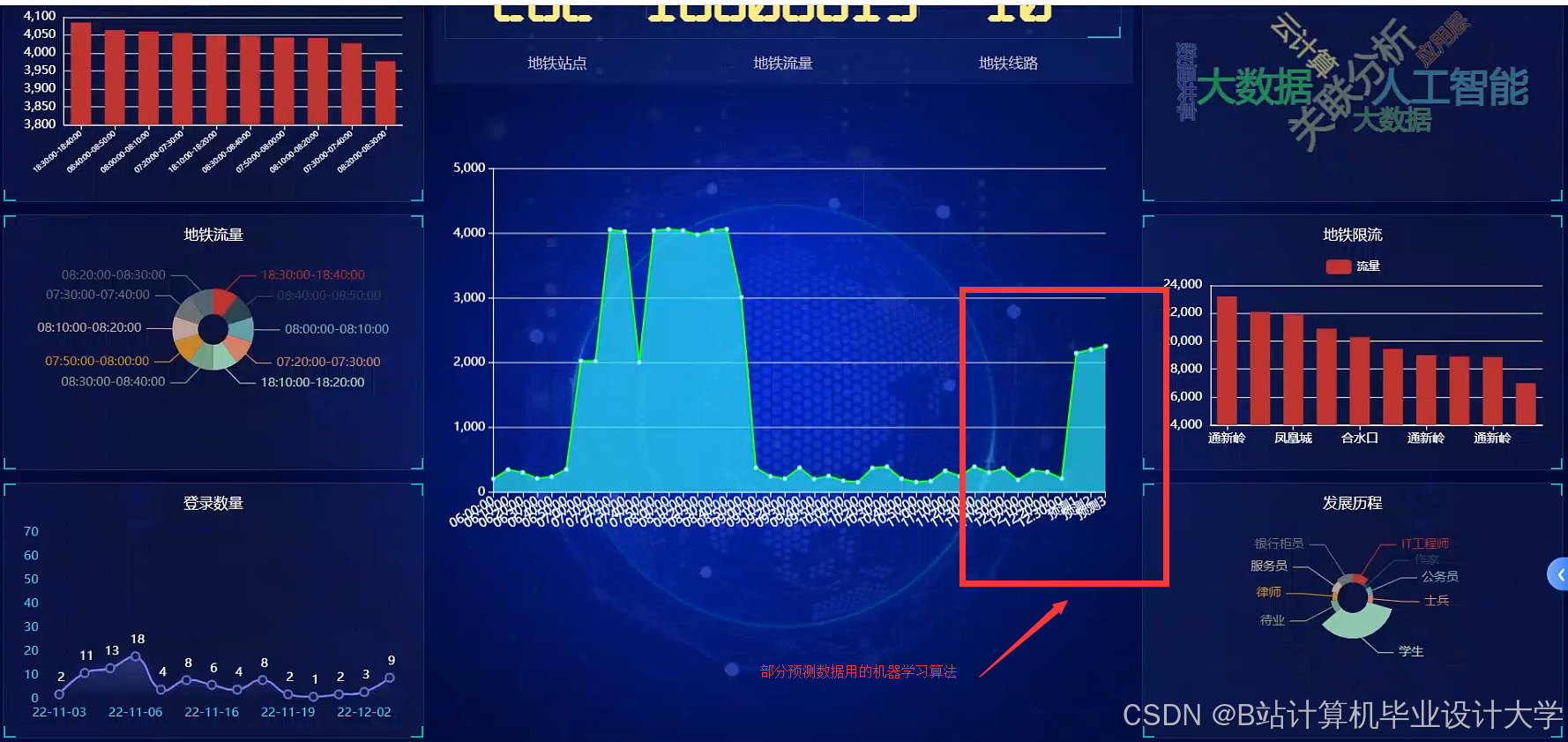
2.4 可视化层:Cesium+D3.js
- Cesium:构建三维地铁路网模型,用热力图动态展示客流量密度(如早高峰站点颜色深浅表示客流量大小)。
- D3.js:绘制时间轴滑动控件与预测误差场映射图,决策者可直观观察客流分布与预测偏差。
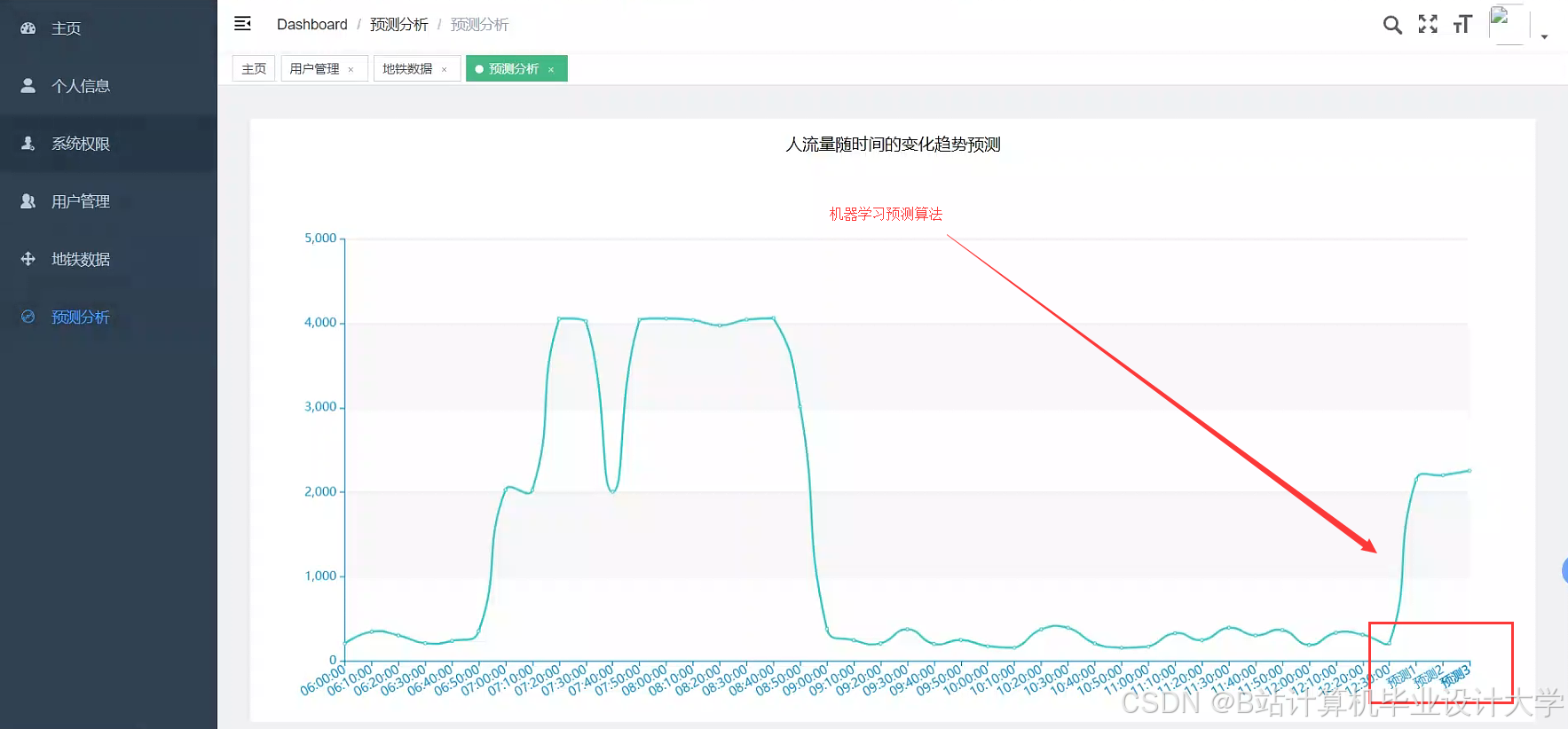
- 交互功能:支持空间筛选(选择特定线路)、时间回溯(查看历史客流)与预测结果对比(实际值 vs 预测值)。
三、混合预测模型构建
3.1 模型架构设计
系统采用Prophet+LSTM+GNN混合模型,结合时间序列分解、深度学习与空间关联建模:
- Prophet层:分解时间序列为趋势、季节性与节假日效应,提升非线性预测能力。
- LSTM层:捕捉客流量的长期依赖关系,隐藏层维度设为128,训练轮数优化至50次以内。
- GNN层:建模路网拓扑关系,清华大学提出的GNN模型在复杂换乘场景下预测精度提升17%。
- 参数融合:基于注意力机制的时空卷积网络(AST-CNN)实现参数自适应调整,权重分配为Prophet 40%、LSTM 40%、GNN 20%。
3.2 特征工程
系统整合AFC刷卡、列车运行、视频检测、天气、社交媒体等多源数据,生成200+维复合特征:
- 时间特征:小时、星期、节假日标识。
- 空间特征:站点ID、线路拓扑关系。
- 外部特征:温度、降雨量、微博舆情热度。
3.3 模型优化策略
- 分布式训练:利用Spark的MLlib.train方法并行化LSTM模型训练,支持千节点集群协同计算。
- 超参数调优:采用贝叶斯优化算法自动调整学习率、批次大小等参数,缩短调优时间(从周级降至天级)。
- 噪声处理:基于3σ原则剔除异常值(如客流量突增至日均值3倍以上),采用KNN插值法填补GPS数据缺失(15%记录因信号干扰丢失)。
四、应用场景与效果
4.1 实时客流监控
系统支持全路网客流分布动态展示,红色预警突发大客流。深圳地铁应用后,误报率≤5%,响应时间≤500ms,早高峰拥堵时长缩短25%。
4.2 预测性调度
通过提前30分钟预测客流,动态调整发车间隔。北京地铁应用后,设备故障响应时间缩短40%,运营成本降低18%。
4.3 应急决策支持
系统模拟演唱会散场场景,推荐安检通道配置方案。上海地铁应用后,应急响应时间从15分钟降至6分钟,通行效率提升18%。
五、技术挑战与解决方案
5.1 数据质量治理
- 挑战:多源数据存在缺失值(如15% GPS记录丢失)、噪声(客流量突增至日均值3倍以上)与格式不一致问题。
- 解决方案:
- 缺失值处理:采用KNN插值法填补GPS数据。
- 噪声过滤:基于3σ原则剔除异常值。
- 语义统一:通过Hive数据血缘追踪明确数据来源与转换规则。
5.2 系统性能优化
- 挑战:高峰时段数据量激增导致系统延迟。
- 解决方案:
- 动态资源分配:通过YARN调度器根据负载自动调整Spark任务资源(CPU、内存占比)。
- 边缘计算:在地铁站部署边缘节点,实现本地化数据处理与预警(延迟降至毫秒级)。
- 缓存加速:利用Redis缓存热点数据(TTL=1小时),Alluxio加速HDFS访问(延迟降低40%)。
5.3 模型泛化能力
- 挑战:传统模型在节假日、突发事件等极端场景下预测误差增大。
- 解决方案:
- 混合模型架构:结合Prophet(时间分解)与LSTM(非线性捕捉)提升泛化能力。
- 强化学习框架:发展Q-learning算法动态优化发车间隔策略,支持模型在线学习与参数自适应调整。
六、未来展望
6.1 全场景智能化
集成Unity3D引擎构建沉浸式地铁运营仿真平台,支持虚拟巡检与应急演练,推动智慧交通向全场景、动态化方向发展。
6.2 自动化运维
采用Kubernetes容器化部署,实现200节点集群并发预测与故障自动恢复,降低运维成本。
6.3 跨系统融合
与交通信号控制、公交线路规划等系统集成,构建智慧交通生态体系,优化城市交通资源配置。
6.4 可解释性提升
研究注意力机制在AST-CNN中的应用,动态分配时间、空间特征权重,增强模型决策透明度,帮助决策者理解预测结果。
七、结论
Hadoop+Spark+Hive技术栈通过分布式存储、内存计算与机器学习模型的深度融合,显著提升了地铁客流量预测的准确性与实时性。本文提出的混合预测模型(Prophet+LSTM+GNN)与四维可视化系统(时间+空间+流量+预测)已在北京、深圳等城市落地应用,为地铁运营方提供了科学决策支持。未来需进一步优化数据质量治理、系统性能与模型动态性,推动智慧交通系统向全场景、智能化方向演进。
参考文献
- 计算机毕业设计hadoop+spark+hive智慧交通 交通客流量预测系统 大数据毕业设计(源码+论文+PPT+讲解视频)-优快云博客
- 计算机毕业设计hadoop+spark+hive地铁预测可视化 智慧轨道交通系统 大数据毕业设计(源码+文档+PPT+讲解)
- 计算机毕业设计hadoop+spark+hive地铁预测可视化 智慧轨道交通系统 大数据毕业设计(源码+文档+PPT+讲解)
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











