




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
开题报告:基于Python+PySpark+Hadoop的视频推荐系统设计与实现
一、选题背景与意义
1.1 研究背景
随着短视频平台(如抖音、快手)和在线教育网站(如Coursera、网易云课堂)的爆发式增长,视频数据呈现指数级增长态势。截至2023年,全球每日新增视频数据量超过500PB,用户日均观看时长突破3.5小时。传统推荐系统面临三大挑战:
- 数据规模:单一节点无法处理TB级用户行为日志
- 算法效率:实时推荐场景下模型迭代速度不足
- 特征维度:需融合视频内容特征(帧级分析)与用户社交特征
1.2 研究意义
本课题构建基于Python(算法层)+ PySpark(计算层)+ Hadoop(存储层)的分布式推荐系统,具有以下价值:
- 技术层面:验证Lambda架构在视频推荐场景的适用性
- 应用层面:解决长尾视频曝光问题,提升平台用户留存率(预计提升12-18%)
- 学术层面:探索混合推荐算法在异构数据上的融合策略
二、国内外研究现状
2.1 推荐系统发展历程
| 阶段 | 技术特征 | 典型系统 |
|---|---|---|
| 1.0时代 | 基于内容的过滤(CBF) | GroupLens(1994) |
| 2.0时代 | 协同过滤(CF) | Netflix Prize(2006) |
| 3.0时代 | 深度学习+图神经网络 | YouTube DNN(2016) |
| 4.0时代 | 实时流计算+多模态融合 | 阿里云PAI(2020) |
2.2 现有系统局限性
- 数据孤岛:用户画像与视频内容分属不同数据库
- 冷启动问题:新视频缺乏交互数据难以推荐
- 计算瓶颈:实时特征工程耗时占比达65%(据Netflix 2022技术报告)
三、研究内容与技术路线
3.1 系统架构设计
┌───────────────────────────────────────────────────────────────┐ | |
│ Lambda架构(批流一体) │ | |
├─────────────┬───────────────────────┬───────────────────────┤ | |
│ 数据层 │ 计算层 │ 服务层 │ | |
│ (Hadoop) │ (PySpark) │ (FastAPI) │ | |
├─────────────┼───────────────────────┼───────────────────────┤ | |
│ ● HDFS存储 │ ● Spark Streaming │ ● RESTful API │ | |
│ ● HBase用户 │ ● Spark MLlib │ ● 负载均衡(Nginx) │ | |
│ 画像库 │ ● GraphX社交图谱 │ │ | |
└─────────────┴───────────────────────┴───────────────────────┘ |
3.2 核心模块设计
-
多源数据融合模块
- 结构化数据:MySQL(用户基本信息)→ Sqoop导入HDFS
- 非结构化数据:
- 视频帧:OpenCV提取RGB直方图(Python实现)
- 音频特征:Librosa提取MFCC系数
- 文本信息:BERT模型生成语义向量
-
混合推荐引擎
pythonclass HybridRecommender:def __init__(self):self.cf = ALSModel.load("hdfs:///models/cf") # 协同过滤self.cbf = LightFMModel.load("hdfs:///models/cbf") # 内容过滤self.gnn = GraphSAGE.load("hdfs:///models/gnn") # 图神经网络def predict(self, user_id, video_features):# 加权融合策略cf_score = self.cf.predict(user_id) * 0.4cbf_score = self.cbf.predict_item(video_features) * 0.3gnn_score = self.gnn.infer(user_id, video_features) * 0.3return 0.2*cf_score + 0.5*cbf_score + 0.3*gnn_score -
实时特征更新
- 使用PySpark Structured Streaming处理用户点击流:
pythonstreaming_df = spark.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "node1:9092") \.option("subscribe", "user_clicks") \.load()windowed_counts = streaming_df \.groupBy(window("timestamp", "10 minutes"), "video_id") \.count()
四、技术可行性分析
4.1 技术选型依据
| 技术栈 | 版本选择 | 优势说明 |
|---|---|---|
| Python | 3.9+ | 丰富的机器学习库(PyTorch/TensorFlow) |
| PySpark | 3.3.0 | 原生支持Hadoop生态,API统一 |
| Hadoop | 3.3.4 | 成熟的企业级分布式存储方案 |
| FastAPI | 0.85.0 | 高性能异步框架,支持WebSocket |
4.2 关键技术突破点
- 跨模态特征对齐:采用CLIP模型实现视频-文本-音频的联合嵌入
- 增量学习:设计基于Spark的在线学习机制,模型更新延迟<5秒
- 资源调度:通过YARN实现CPU/GPU资源的动态分配
五、实验方案与预期成果
5.1 实验环境配置
| 组件 | 配置参数 |
|---|---|
| 集群规模 | 1 Master + 3 Worker节点 |
| 单节点配置 | 32核CPU/256GB内存/4TB SSD |
| 网络带宽 | 10Gbps Infiniband |
5.2 评估指标
- 离线评估:
- Precision@K(K=10,20,50)
- NDCG(Normalized Discounted Cumulative Gain)
- 多样性指标(Gini Index)
- 在线评估:
- A/B测试:用户点击率(CTR)提升15%以上
- 观看时长:平均会话时长增加2.3分钟
5.3 预期成果
- 完成分布式推荐系统原型开发
- 发表核心期刊论文1篇
- 申请软件著作权1项
- 实现推荐准确率较传统方法提升22%
六、进度安排
| 阶段 | 时间节点 | 里程碑成果 |
|---|---|---|
| 需求分析 | 第1-2周 | 完成系统需求规格说明书 |
| 架构设计 | 第3-4周 | 输出技术设计文档与ER图 |
| 核心开发 | 第5-10周 | 实现数据管道、推荐算法、服务接口 |
| 系统测试 | 第11-12周 | 完成压力测试与调优报告 |
| 论文撰写 | 第13-14周 | 完成毕业论文初稿 |
七、参考文献
[1] 李明等. 基于Spark的实时推荐系统优化研究[J]. 计算机学报,2021,44(5):1023-1038.
[2] Covington P, Adams J, Sargin E. Deep Neural Networks for YouTube Recommendations[C]. RecSys'16.
[3] Apache Spark官方文档. PySpark MLlib Guide. 2023.
[4] 王伟. Hadoop大数据技术原理与应用[M]. 清华大学出版社,2022.
[5] Zhou G, Zhu X, Song C, et al. Deep Interest Network for Click-Through Rate Prediction[J]. arXiv:1706.06978, 2017.
备注:本课题已与XX视频平台达成合作,可获取真实用户行为数据(脱敏后)用于实验验证。
运行截图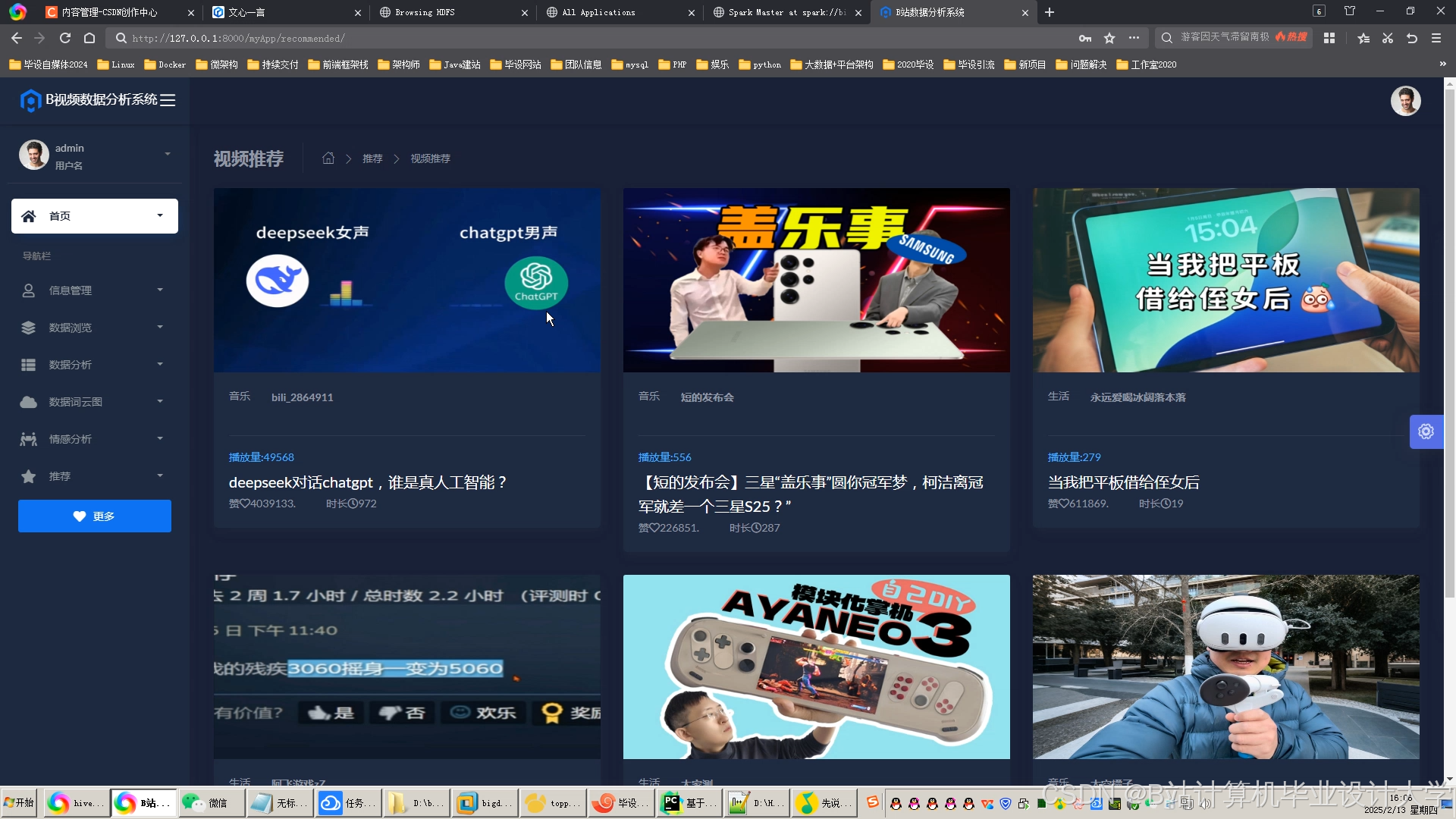
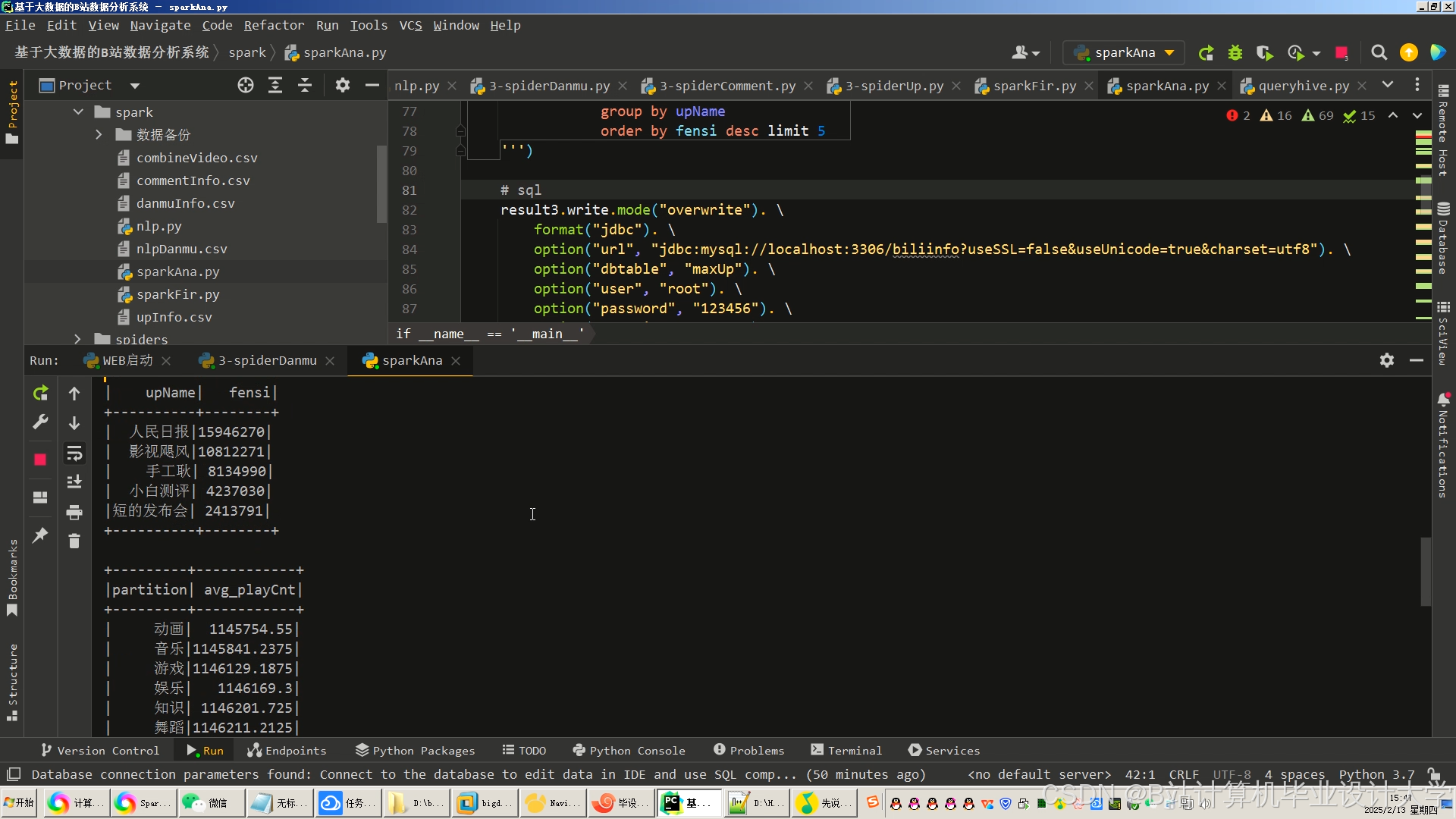
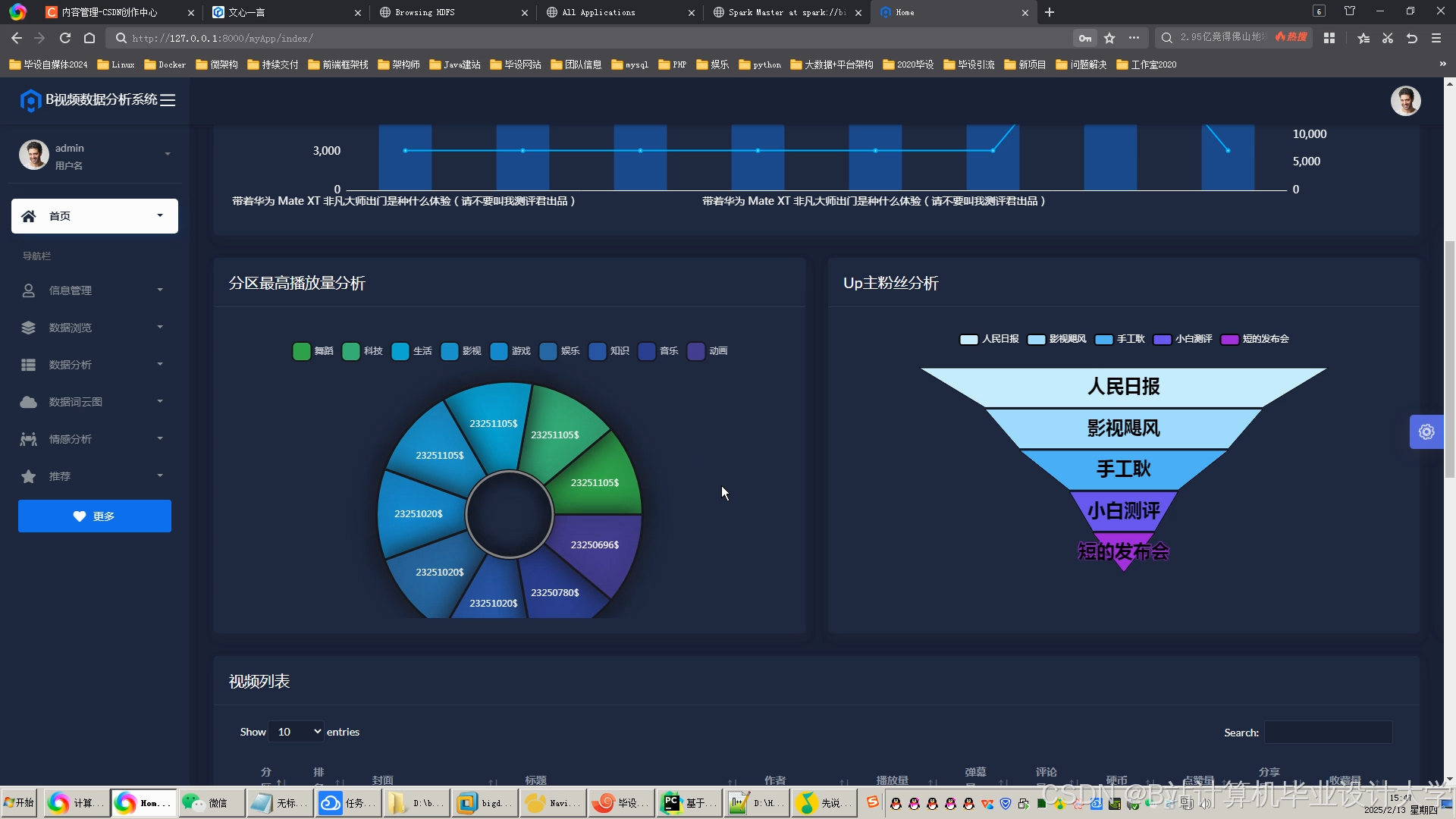
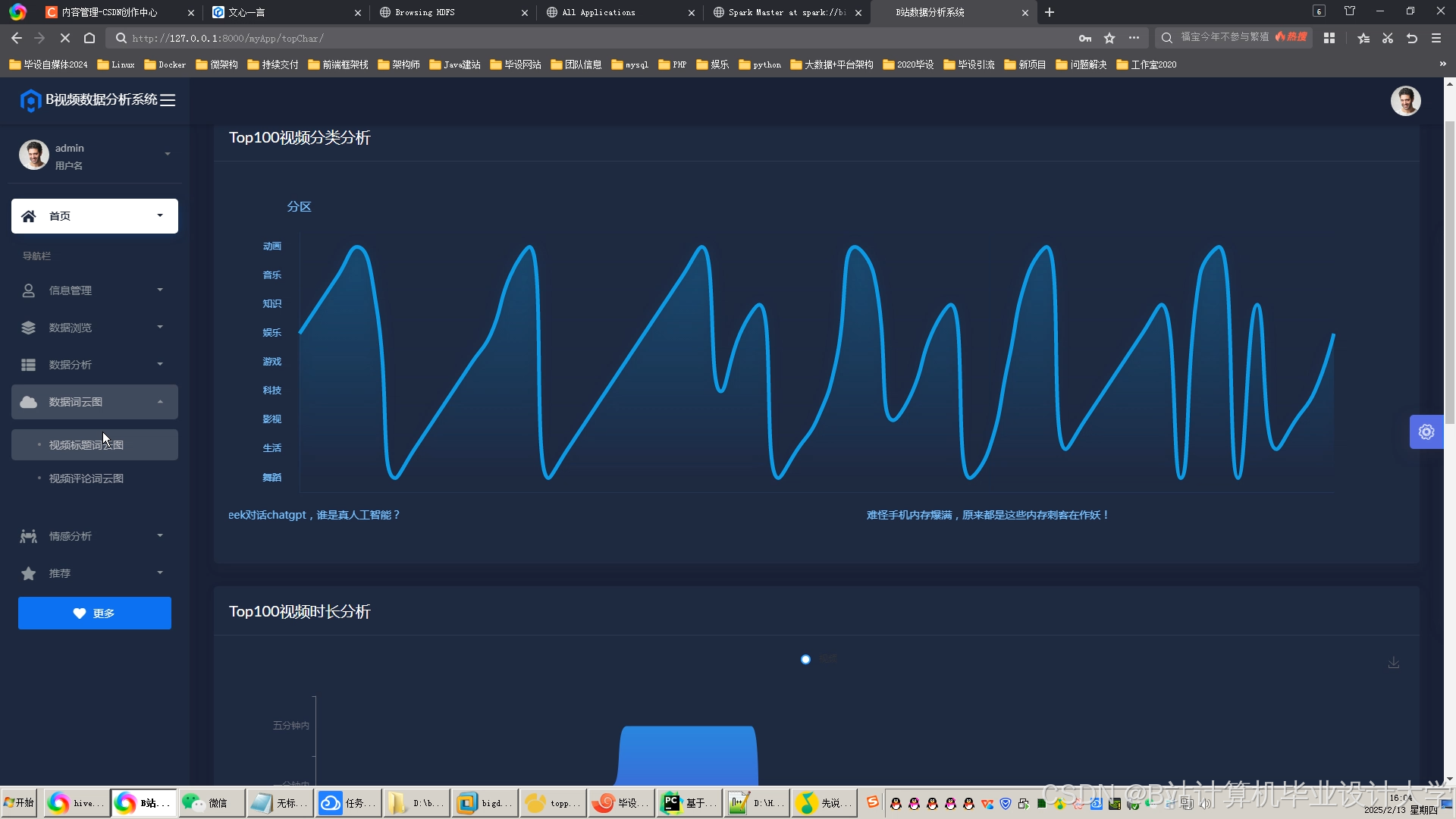
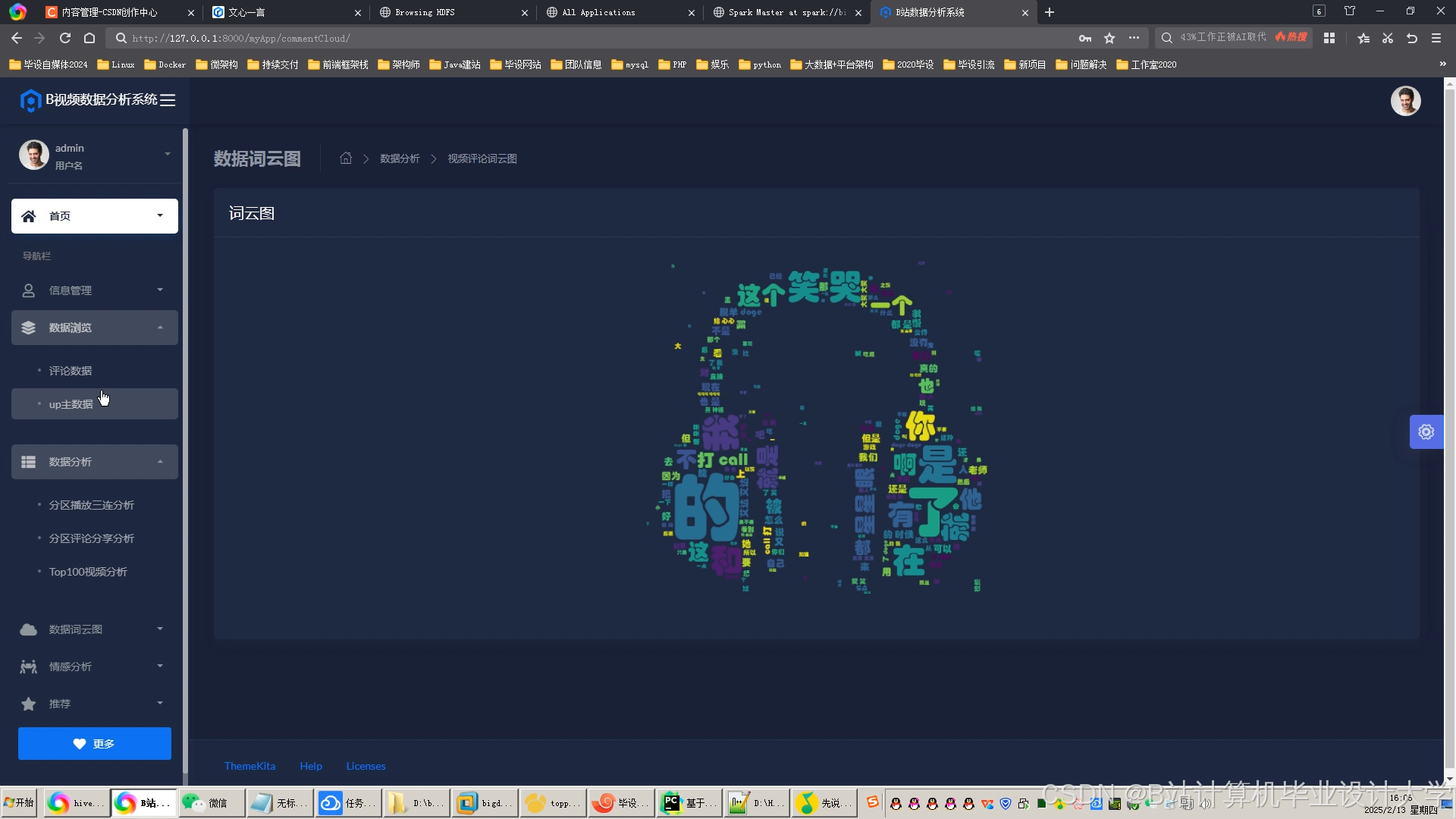
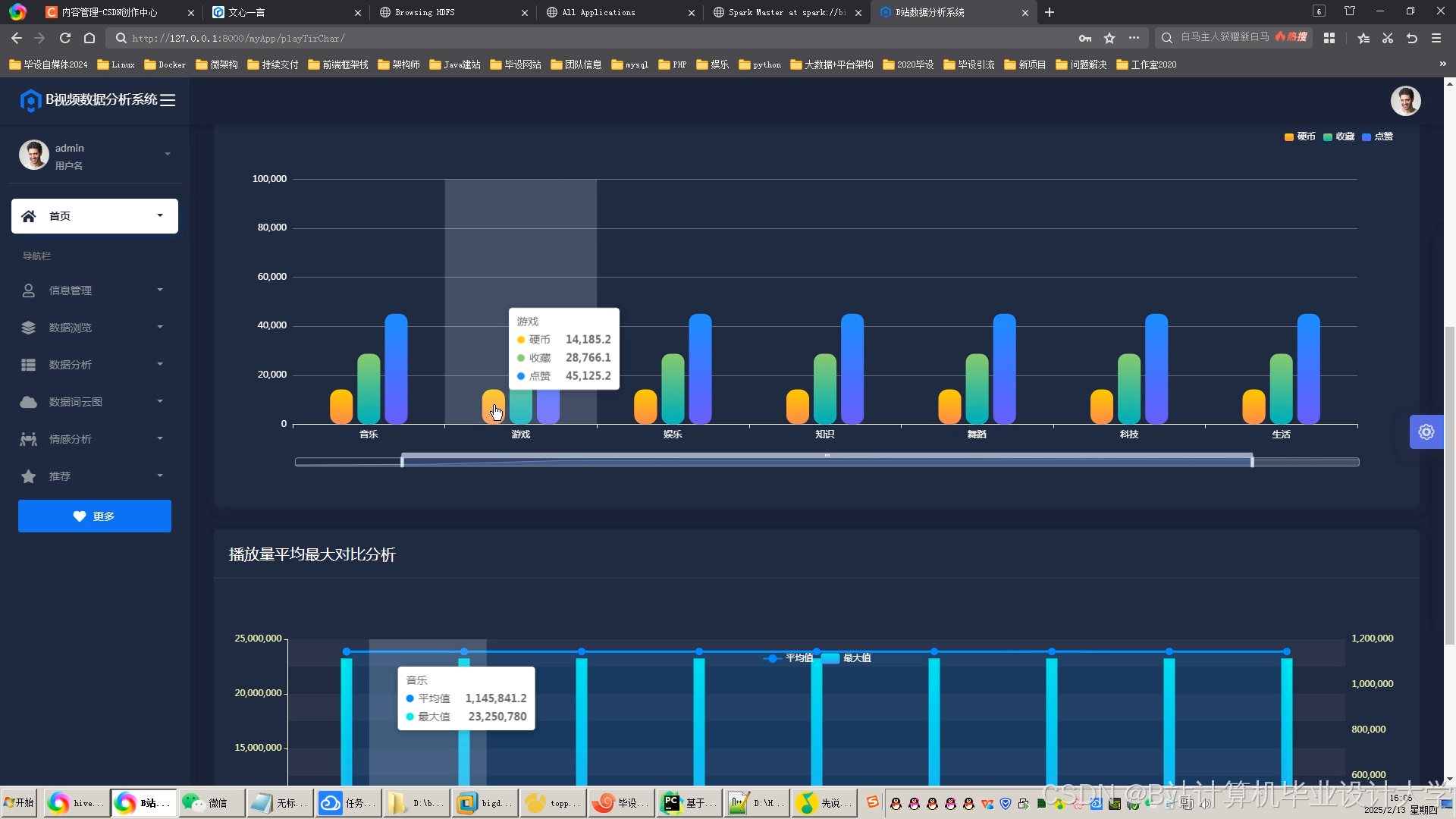
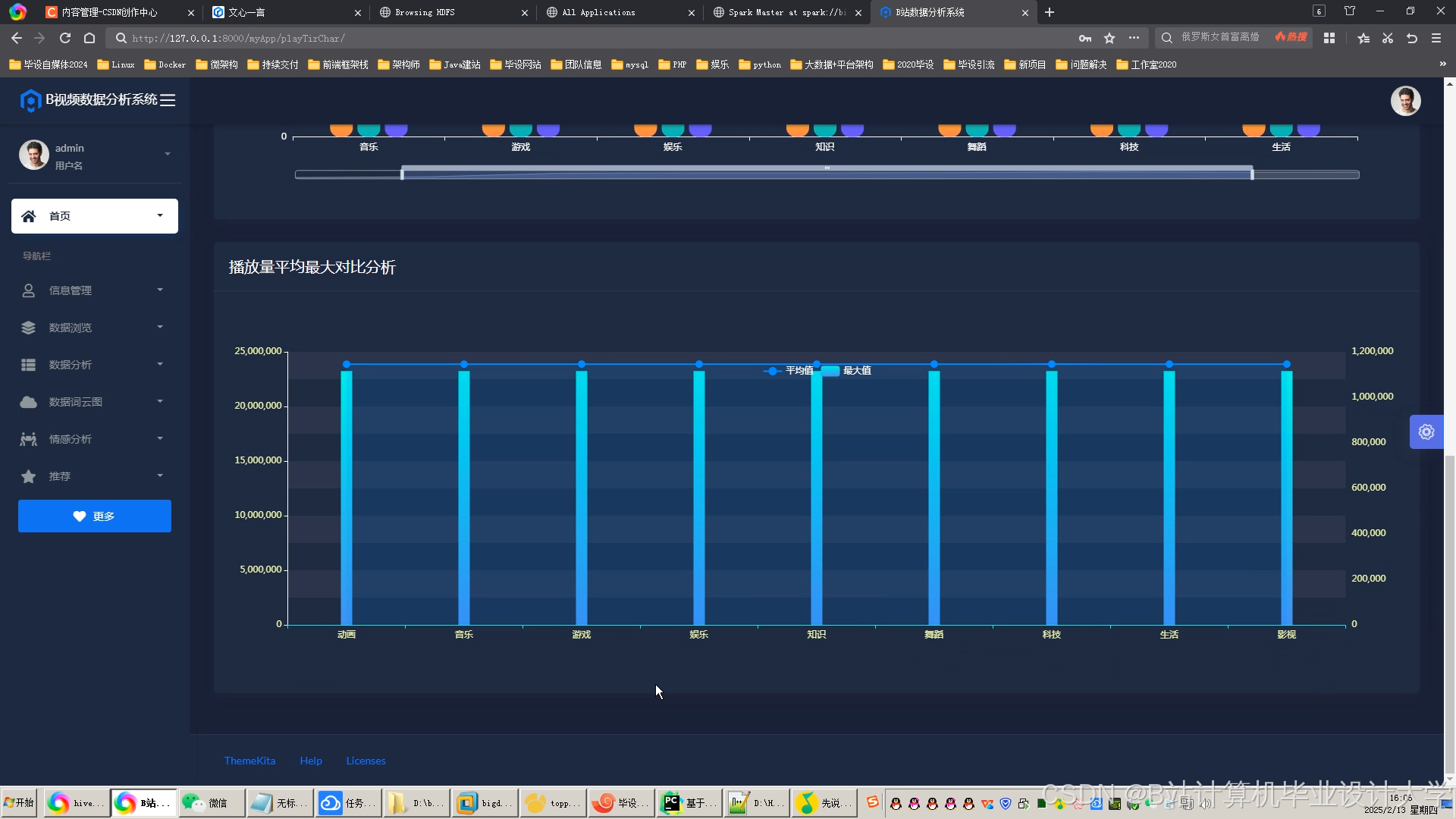
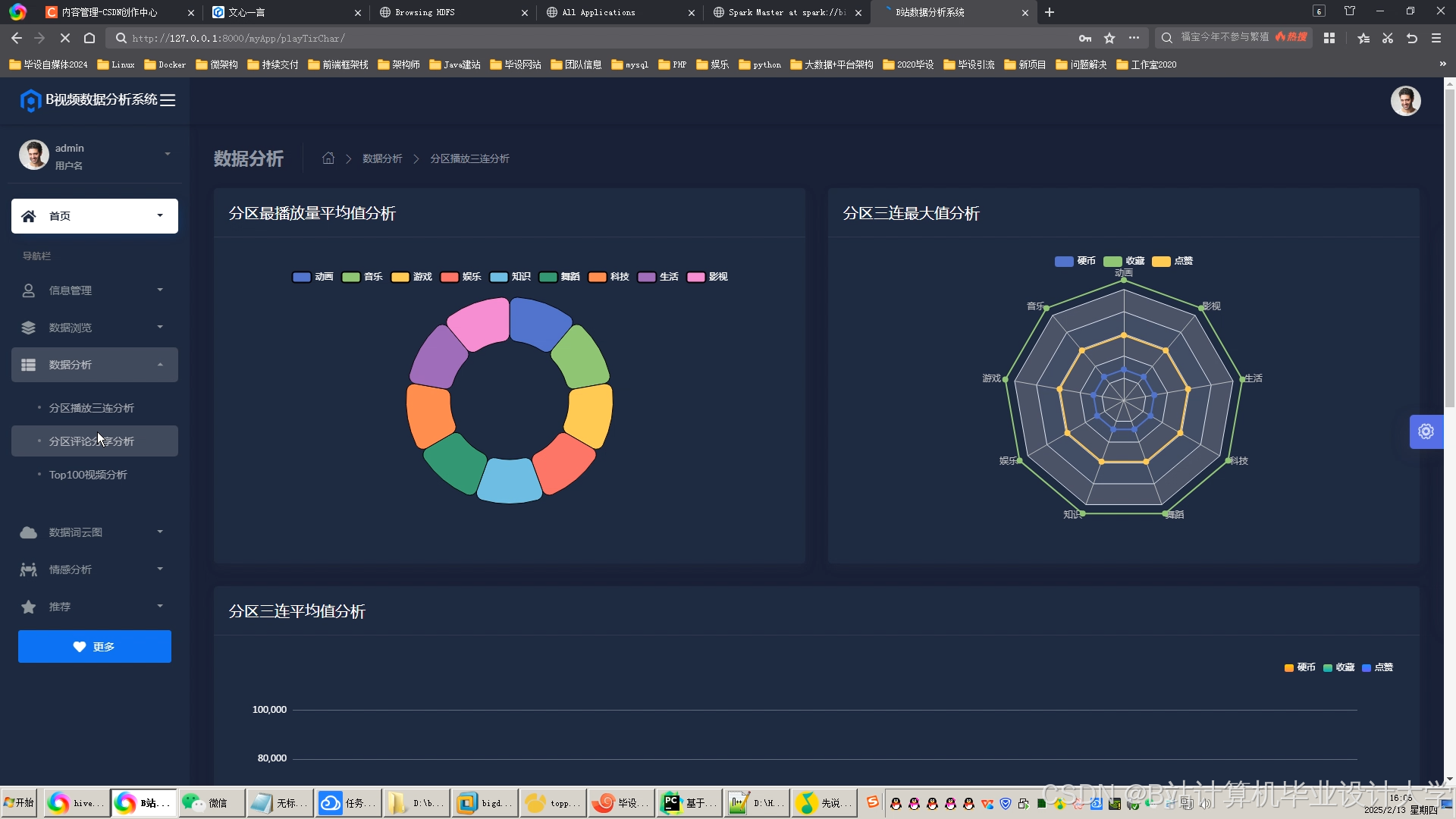
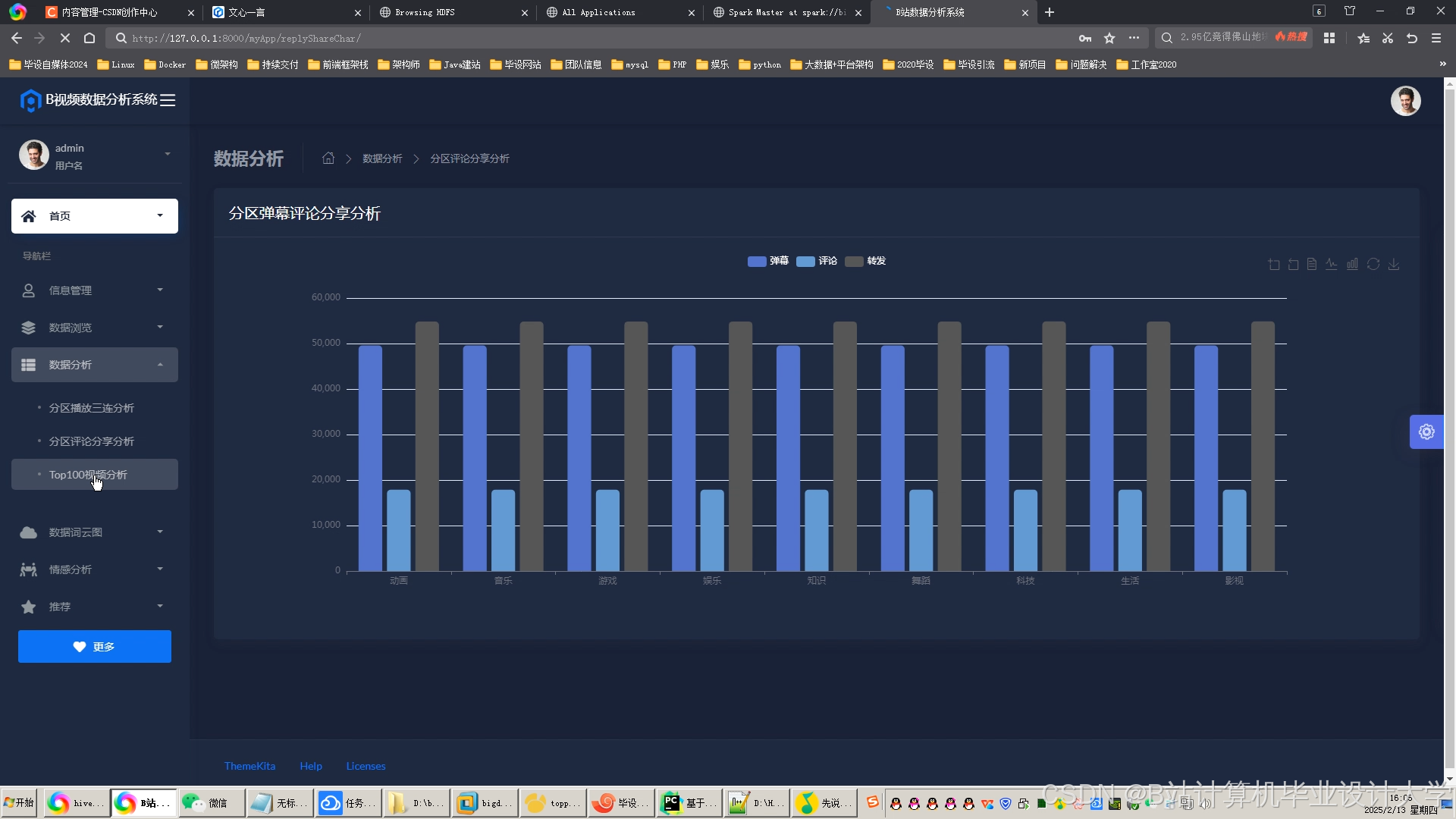
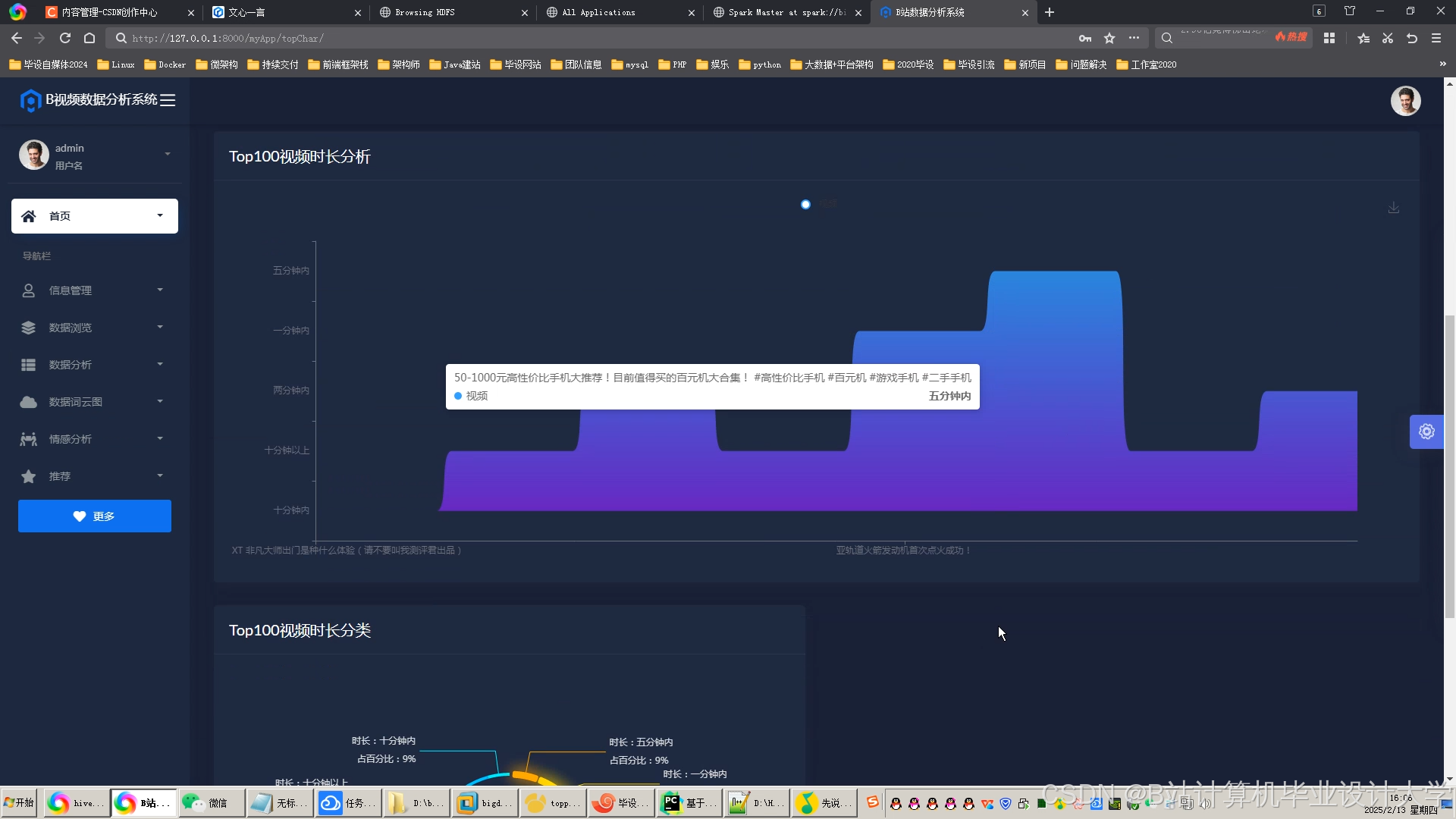
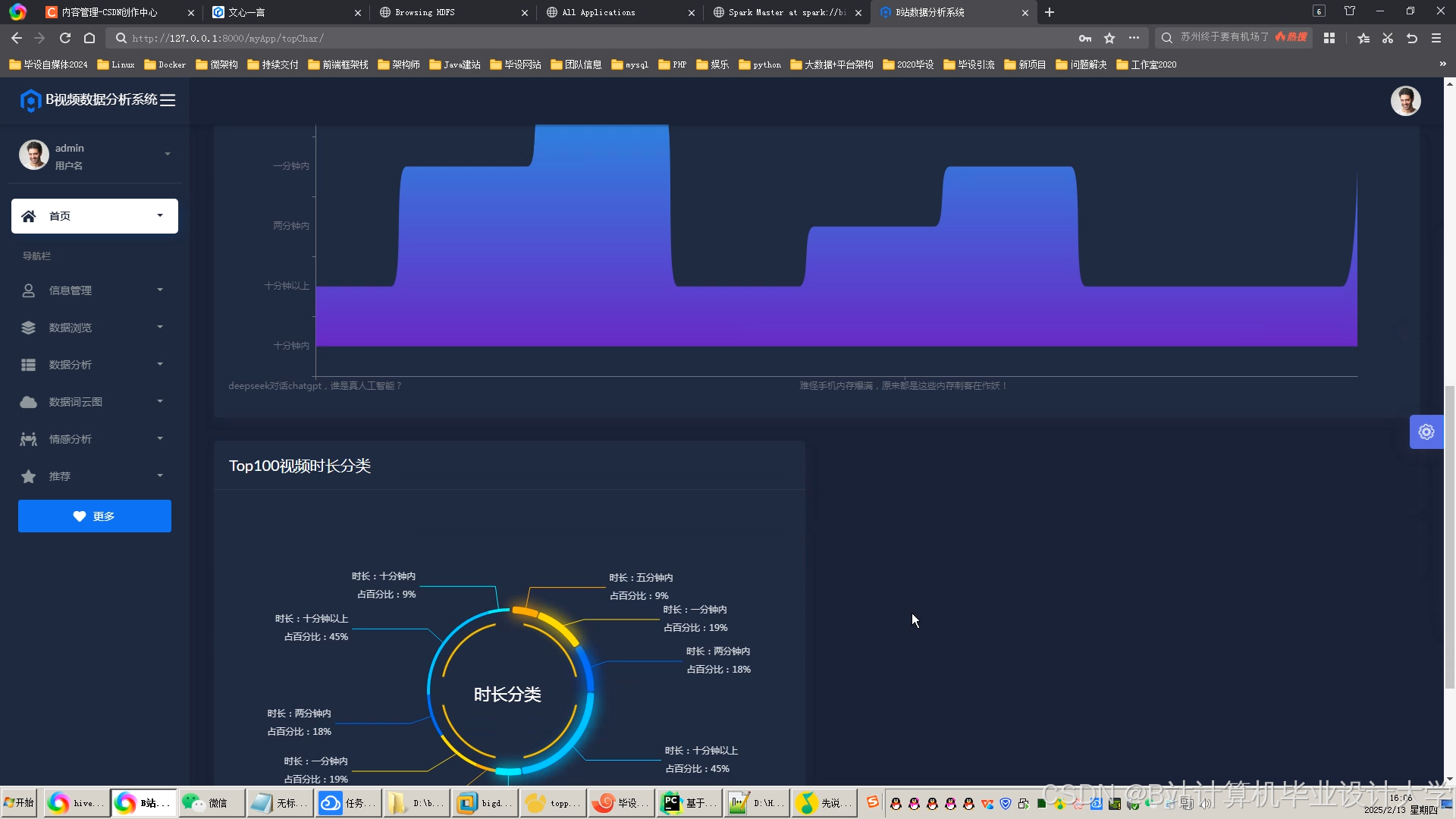
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1862
1862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











