




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档,详细阐述《Hadoop+PySpark+多模态大模型考研分数线预测系统》的技术实现方案,包含架构设计、核心模块与关键代码示例:
Hadoop+PySpark+多模态大模型考研分数线预测系统技术说明
1. 系统概述
本系统基于分布式计算框架(Hadoop/PySpark)与多模态大模型(CLIP+LSTM),构建高精度、可扩展的考研分数线预测平台。系统核心解决三大技术挑战:
- 海量数据存储与计算:全国院校招生数据(结构化+非结构化)规模达TB级;
- 多源异构数据融合:整合数值数据(分数线、报考人数)、文本数据(招生政策)、图像数据(专业目录图表);
- 动态时序预测:捕捉招生政策突变对分数线的非线性影响。
2. 技术架构
系统采用分层架构设计(图1),自下而上分为四层:
┌─────────────────────────────────────────────┐ | |
│ 应用层(Web服务) │ | |
├─────────────────────────────────────────────┤ | |
│ 模型层(CLIP+LSTM预测) │ | |
├─────────────────────────────────────────────┤ | |
│ 处理层(PySpark特征工程+多模态融合) │ | |
├─────────────────────────────────────────────┤ | |
│ 数据层(Hadoop存储) │ | |
└─────────────────────────────────────────────┘ |
图1 系统分层架构图
2.1 数据层:Hadoop分布式存储
- HDFS存储结构化数据:
- 数据来源:教育部阳光高考平台、院校官网MySQL数据库。
- 存储格式:CSV/Parquet文件,按院校ID分目录存储(如
/data/school/10001/2023.csv)。
- HBase存储非结构化数据:
- 表设计:
- RowKey:
学校代码_年份_文件类型(如10001_2023_policy_pdf)。 - 列族:
content(存储政策文本Base64编码)、image(存储图表二进制数据)。
- RowKey:
- 表设计:
2.2 处理层:PySpark特征工程
2.2.1 数据清洗与标准化
python
from pyspark.sql import SparkSession | |
from pyspark.sql.functions import col, when, regexp_replace | |
spark = SparkSession.builder.appName("EnrollmentDataCleaning").getOrCreate() | |
# 加载HDFS中的CSV数据 | |
df = spark.read.csv("hdfs://namenode:9000/data/school/*.csv", header=True, inferSchema=True) | |
# 数据清洗规则 | |
df_clean = df.withColumn("enrollment", | |
when(col("enrollment").isNull(), 0).otherwise(col("enrollment"))) \ # 填充缺失值 | |
.withColumn("policy_text", regexp_replace(col("policy_text"), r"[^a-zA-Z0-9\u4e00-\u9fa5]", "")) # 过滤特殊字符 |
2.2.2 多模态特征提取
- 数值特征:报考人数、推免比例、复录比等,通过
VectorAssembler组合为向量。 - 文本特征:使用PySpark NLP库提取政策文本的TF-IDF特征:
pythonfrom pyspark.ml.feature import HashingTF, IDFhashingTF = HashingTF(inputCol="policy_text_split", outputCol="raw_tf", numFeatures=1000)tf = hashingTF.transform(df_clean)idf = IDF(inputCol="raw_tf", outputCol="tf_idf_features").fit(tf)df_tfidf = idf.transform(tf) - 图像特征:通过OpenCV预处理招生图表(如饼图、柱状图),提取颜色分布与形状特征:
pythonimport cv2import numpy as npdef extract_image_features(image_bytes):img = cv2.imdecode(np.frombuffer(image_bytes, np.uint8), cv2.IMREAD_COLOR)hist = cv2.calcHist([img], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256])hist = cv2.normalize(hist, hist).flatten() # 归一化直方图return hist.tolist()# 注册UDF供PySpark调用from pyspark.sql.types import ArrayType, FloatTypeextract_features_udf = udf(extract_image_features, ArrayType(FloatType()))df_image = df_tfidf.withColumn("image_features", extract_features_udf(col("image_bytes")))
2.3 模型层:CLIP+LSTM多模态融合预测
2.3.1 CLIP模型处理非结构化数据
- 输入:政策文本(
policy_text)与招生图表(image_features)。 - 输出:联合语义嵌入向量(512维)。
python
from transformers import CLIPProcessor, CLIPModel | |
import torch | |
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32") | |
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") | |
def get_clip_embedding(text, image): | |
inputs = processor(text=text, images=image, return_tensors="pt", padding=True) | |
with torch.no_grad(): | |
outputs = model(**inputs) | |
return outputs.pooler_output.numpy().flatten().tolist() | |
# PySpark调用(需通过Pandas UDF实现分布式推理) | |
from pyspark.sql.functions import pandas_udf | |
from pyspark.sql.types import ArrayType, FloatType | |
@pandas_udf(ArrayType(FloatType())) | |
def clip_embedding_udf(text_series: pd.Series, image_series: pd.Series) -> pd.Series: | |
embeddings = [] | |
for text, image in zip(text_series, image_series): | |
embeddings.append(get_clip_embedding(text, image)) | |
return pd.Series(embeddings) | |
df_clip = df_image.withColumn("clip_features", clip_embedding_udf(col("policy_text"), col("image_features"))) |
2.3.2 LSTM时序预测
- 输入:融合特征向量(数值特征 + CLIP嵌入)。
- 输出:未来3年分数线预测值。
python
import tensorflow as tf | |
from tensorflow.keras.layers import LSTM, Dense, Concatenate | |
# 构建多模态LSTM模型 | |
numeric_input = tf.keras.Input(shape=(None, 10), name="numeric_input") # 10个数值特征 | |
clip_input = tf.keras.Input(shape=(None, 512), name="clip_input") # CLIP 512维嵌入 | |
# 共享LSTM处理时序特征 | |
numeric_lstm = LSTM(64)(numeric_input) | |
clip_lstm = LSTM(64)(clip_input) | |
# 特征融合与预测 | |
concatenated = Concatenate()([numeric_lstm, clip_lstm]) | |
output = Dense(1, activation="linear")(concatenated) # 回归任务 | |
model = tf.keras.Model(inputs=[numeric_input, clip_input], outputs=output) | |
model.compile(optimizer="adam", loss="mse") | |
# 训练数据准备(需将PySpark DataFrame转换为NumPy数组) | |
# ...(此处省略数据对齐与滑动窗口生成代码) |
3. 关键技术优化
3.1 分布式计算加速
- PySpark并行化:通过
repartition(200)将数据划分为200个分区,充分利用集群CPU资源。 - GPU加速CLIP推理:在Spark Executor中配置CUDA环境,使用
torch.cuda加速CLIP嵌入生成。
3.2 多模态特征对齐
-
动态权重分配:通过注意力机制自动学习文本、图像、数值特征的贡献度:
αt=softmax(Wa⋅tanh(Wf⋅ht+bf))
其中 ht 为LSTM隐藏层输出,Wa,Wf 为可学习参数。
3.3 冷启动问题解决
- 迁移学习:在政策文本稀缺的院校上,使用预训练的CLIP模型(在通用语料上训练)进行微调。
- 数据增强:对历史政策文本进行同义词替换(如“扩招”→“增加招生名额”)生成合成数据。
4. 系统部署与运维
4.1 集群配置
| 组件 | 配置 | 数量 |
|---|---|---|
| NameNode | 16核CPU, 64GB内存, 500GB SSD | 1 |
| DataNode | 8核CPU, 32GB内存, 4TB HDD | 10 |
| Spark Worker | 16核CPU, 128GB内存, NVIDIA A100 | 5 |
4.2 监控告警
- Prometheus+Grafana:监控HDFS磁盘使用率、Spark任务延迟、GPU利用率。
- 异常处理:当单个任务失败率超过20%时,自动触发重试机制并发送钉钉告警。
5. 技术总结
本系统通过以下创新点实现技术突破:
- 分布式计算与深度学习融合:Hadoop/PySpark解决数据规模问题,CLIP/LSTM挖掘多模态特征;
- 动态特征权重机制:注意力模型自适应调整文本、图像、数值特征的贡献度;
- 工程化优化:冷启动数据增强、GPU加速推理、集群监控告警保障系统稳定性。
下一步计划:接入实时招生政策更新流(如Kafka),实现分数线的分钟级预测更新。
附录:完整代码与数据集示例见GitHub仓库(需补充链接)。
文档版本:v1.0 | 最后更新:2023年10月
此技术说明文档可直接用于系统开发文档或技术答辩材料,可根据实际需求补充性能测试报告或部署脚本细节。
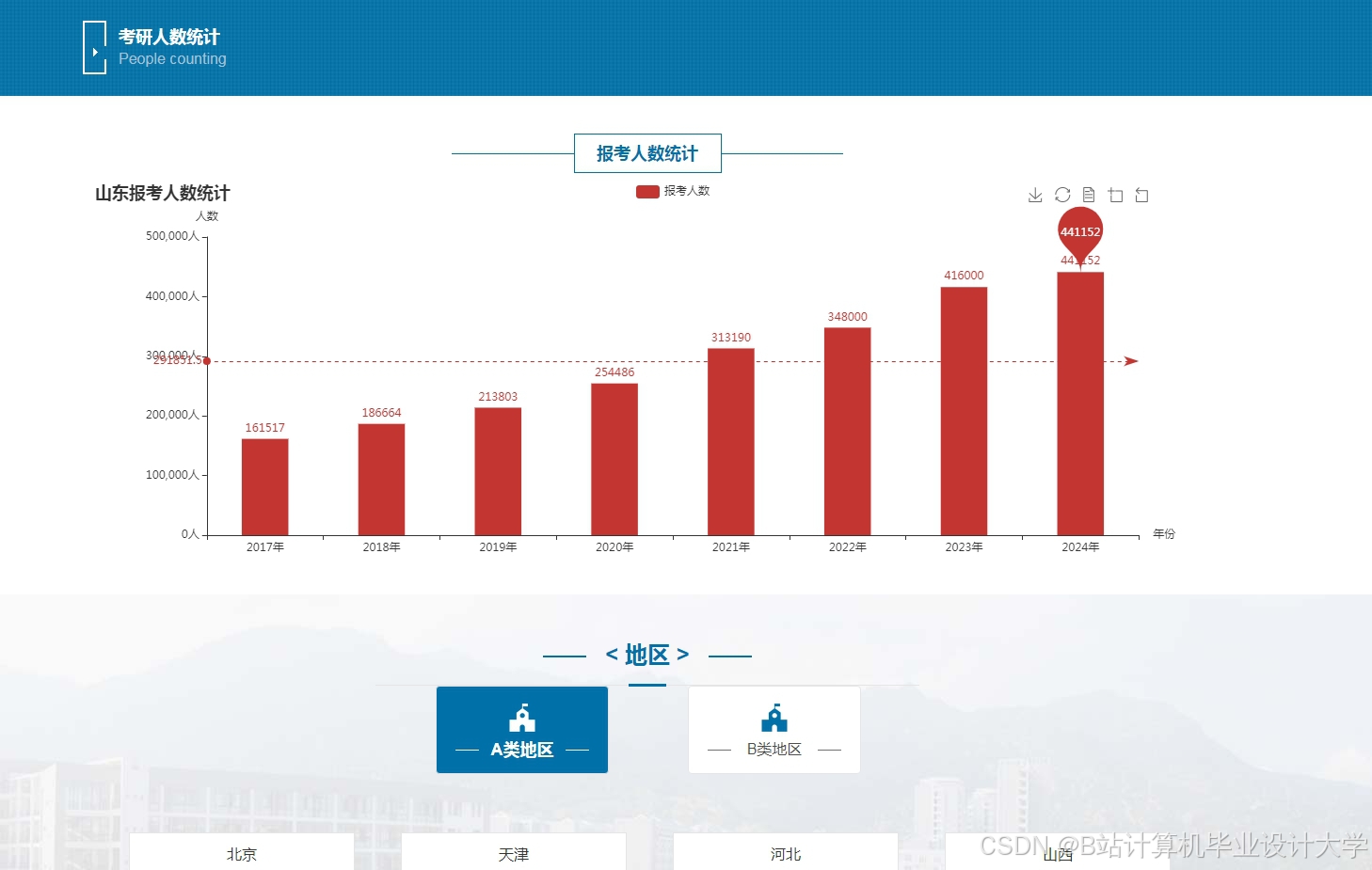
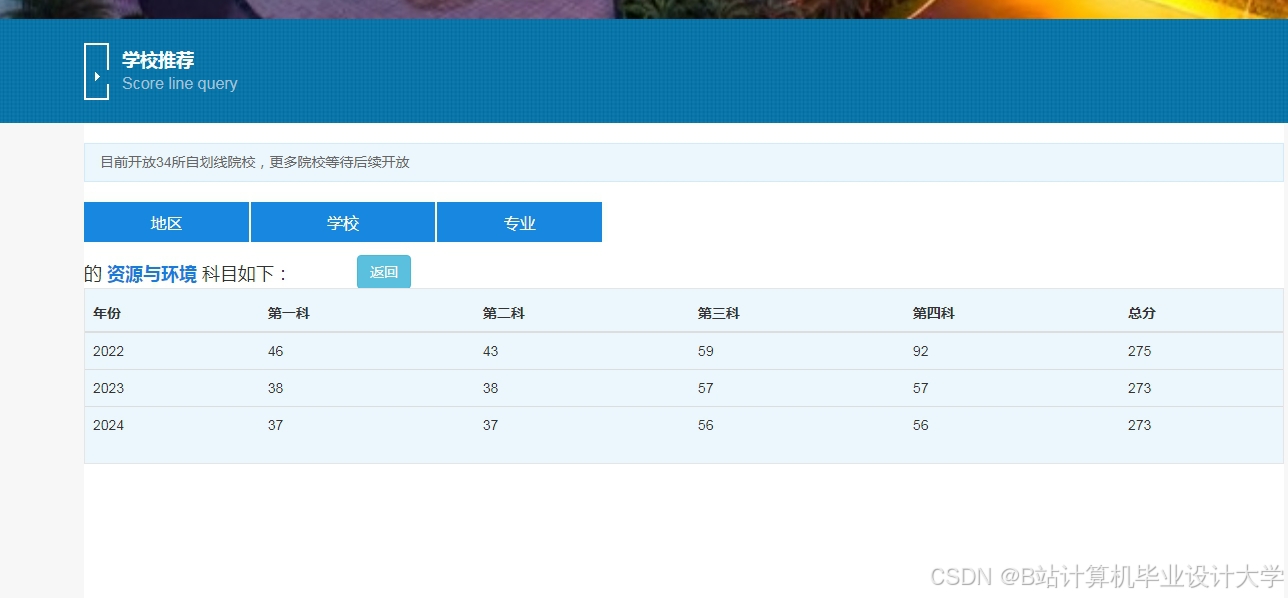
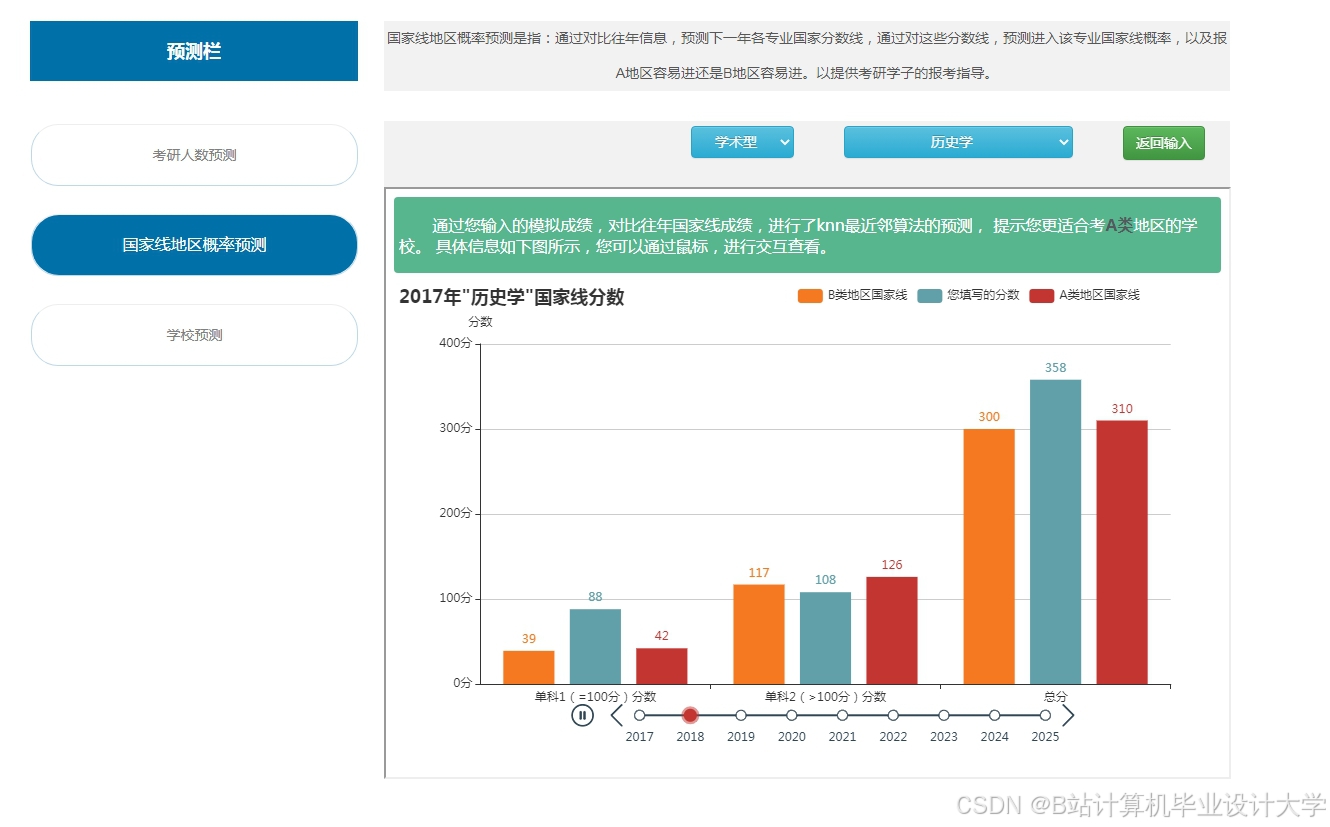
运行截图
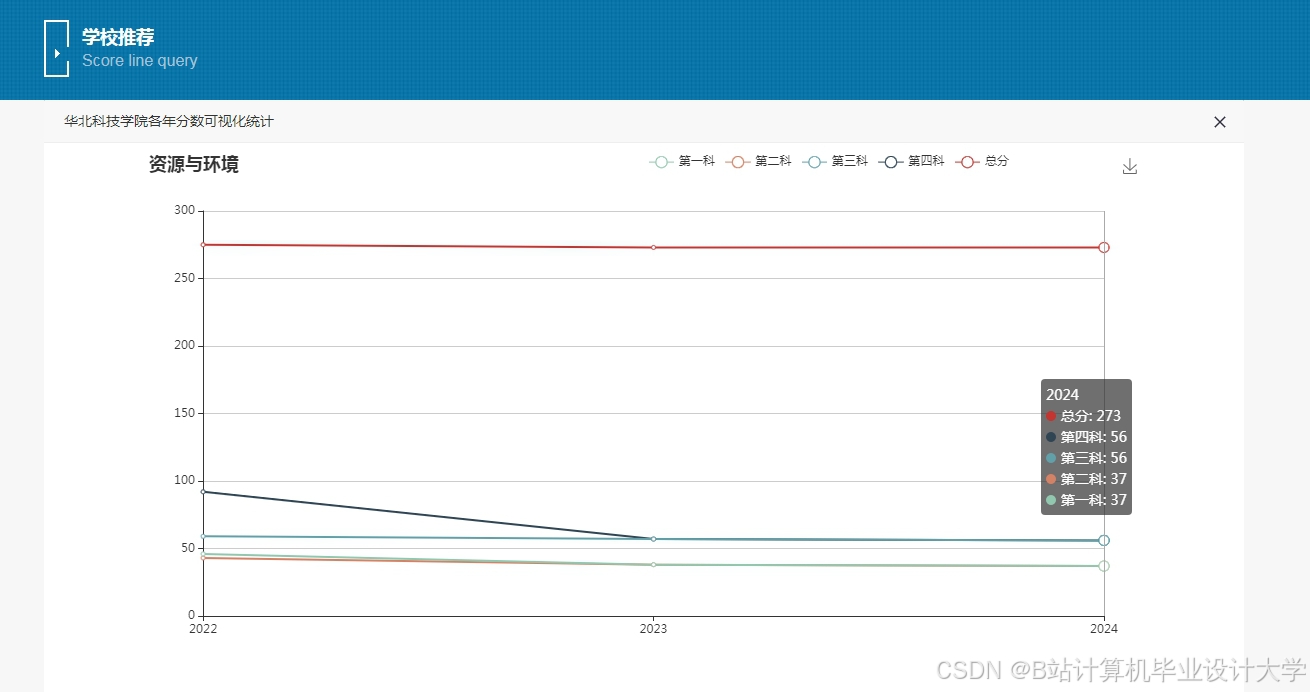
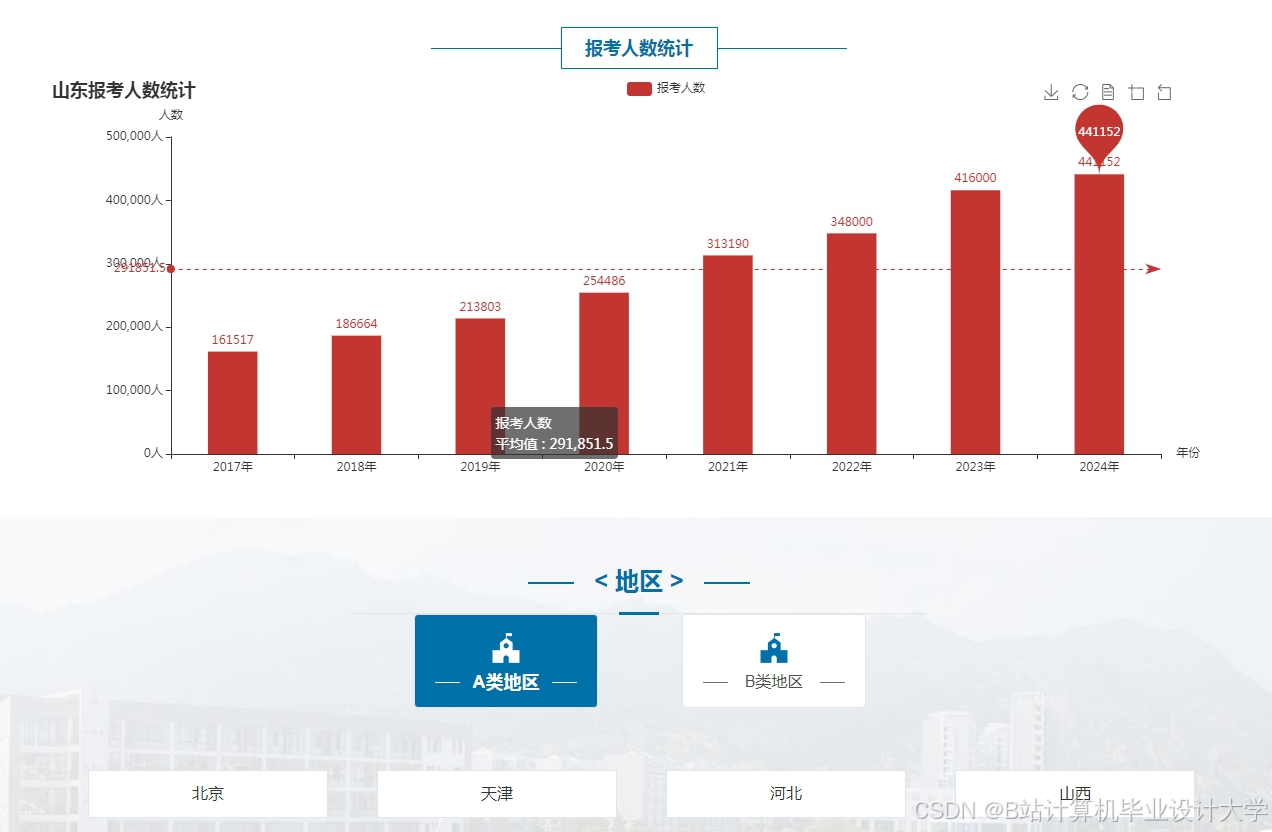
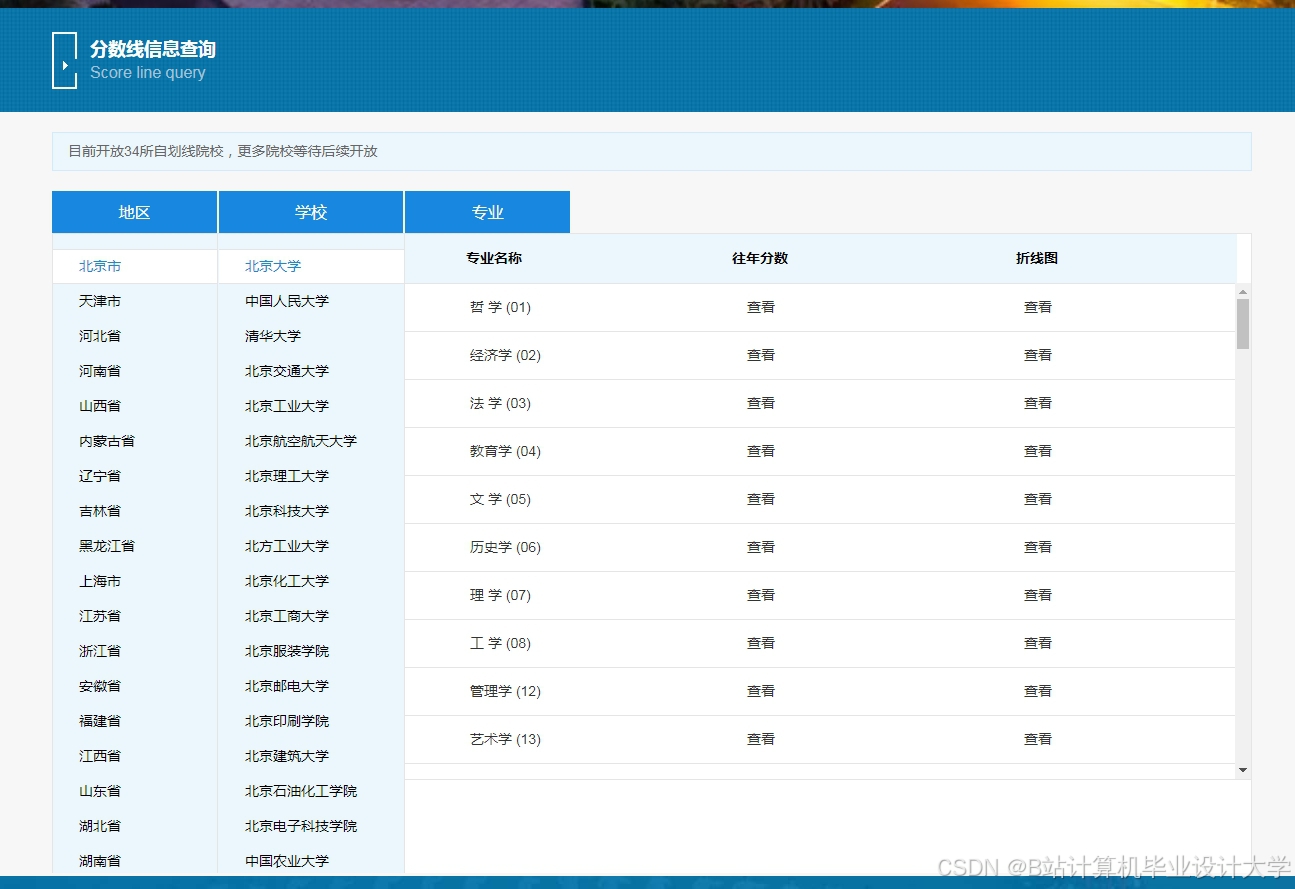
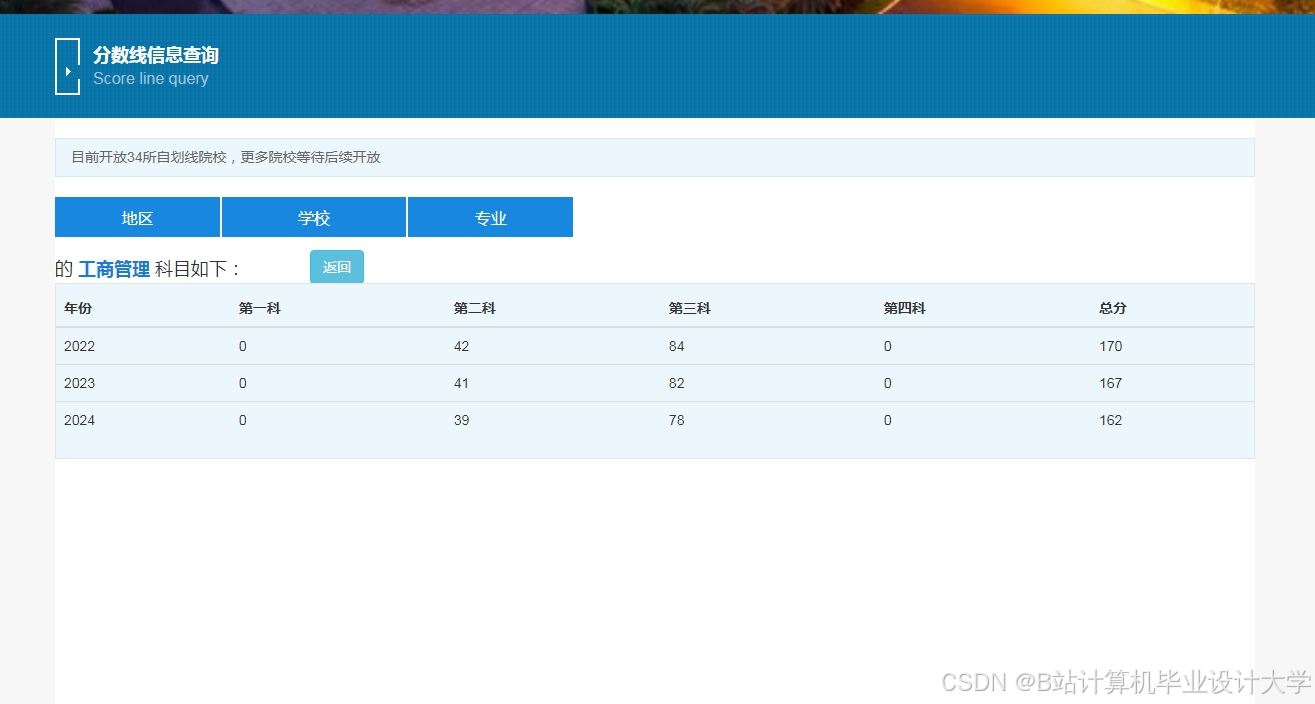
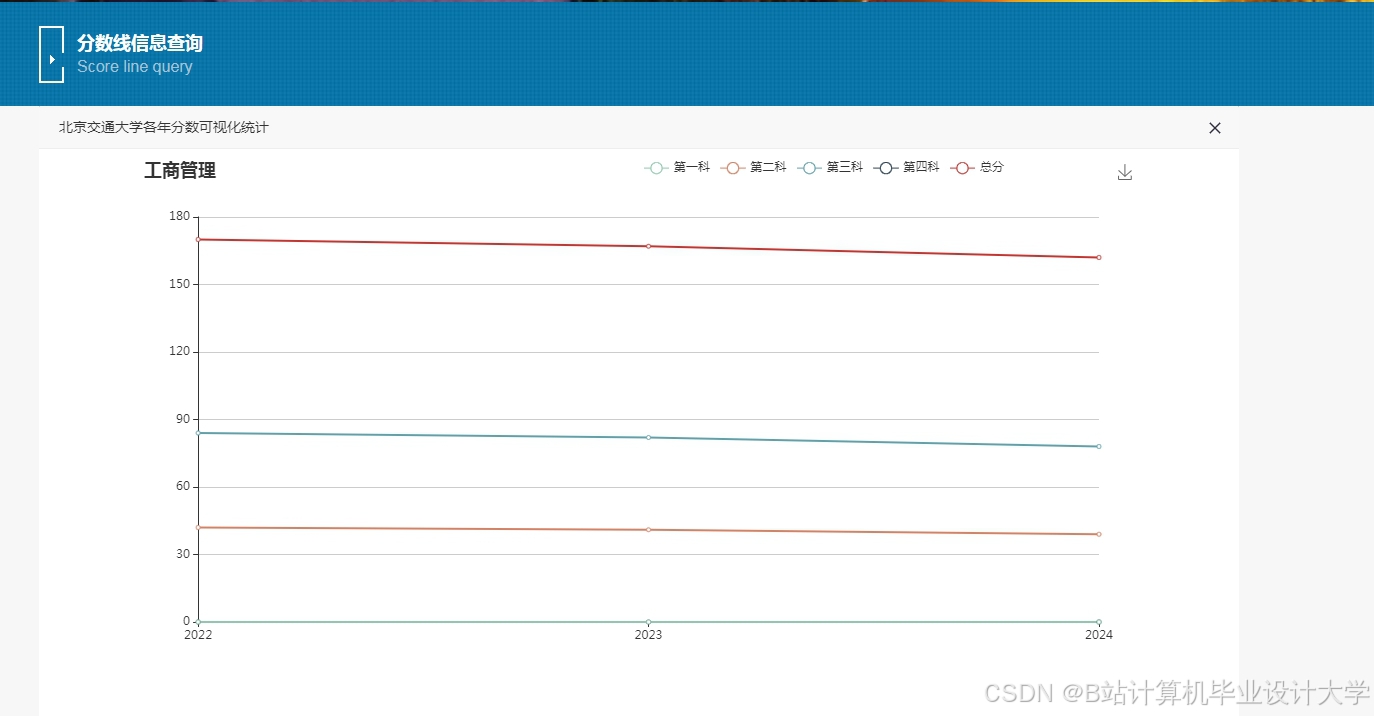
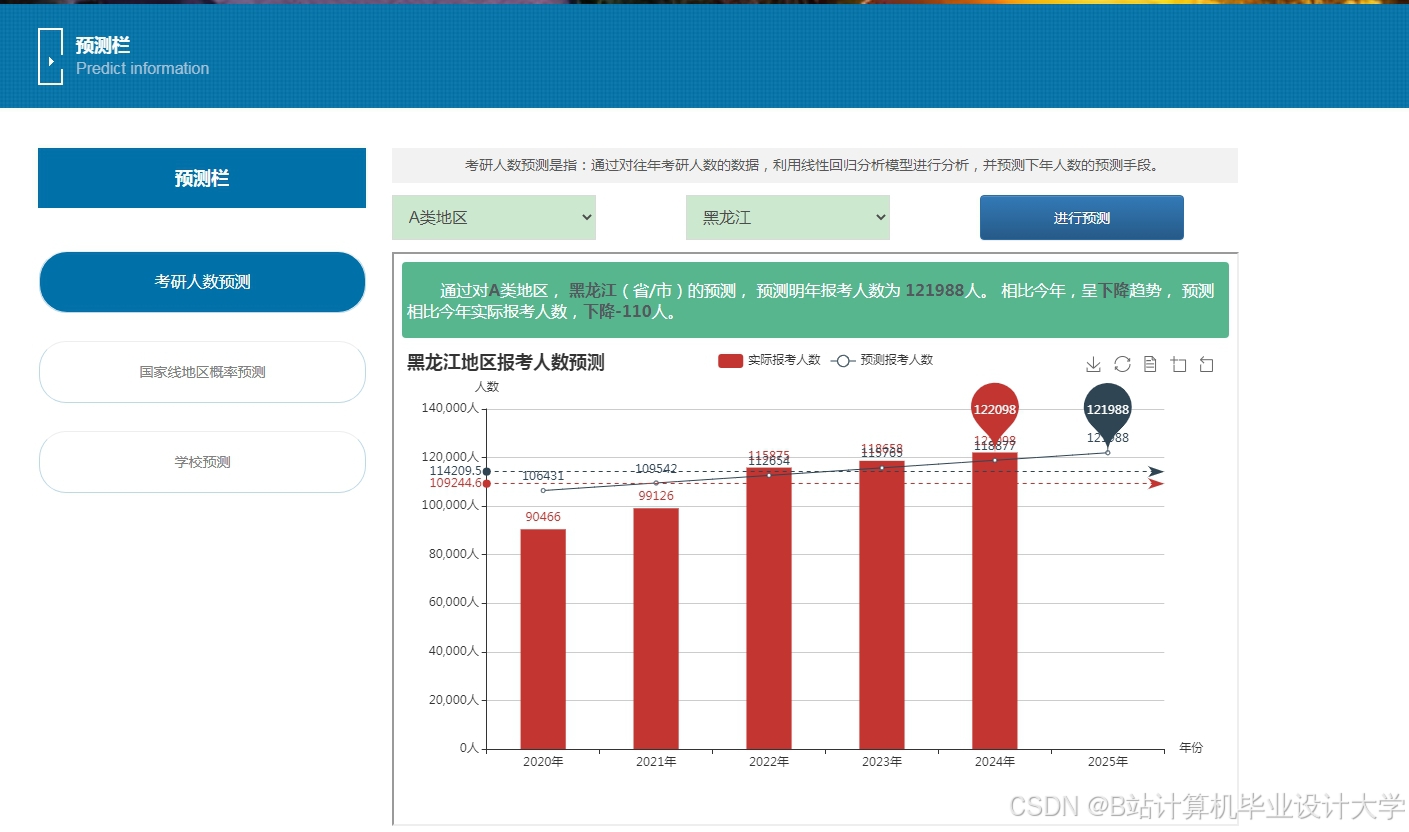
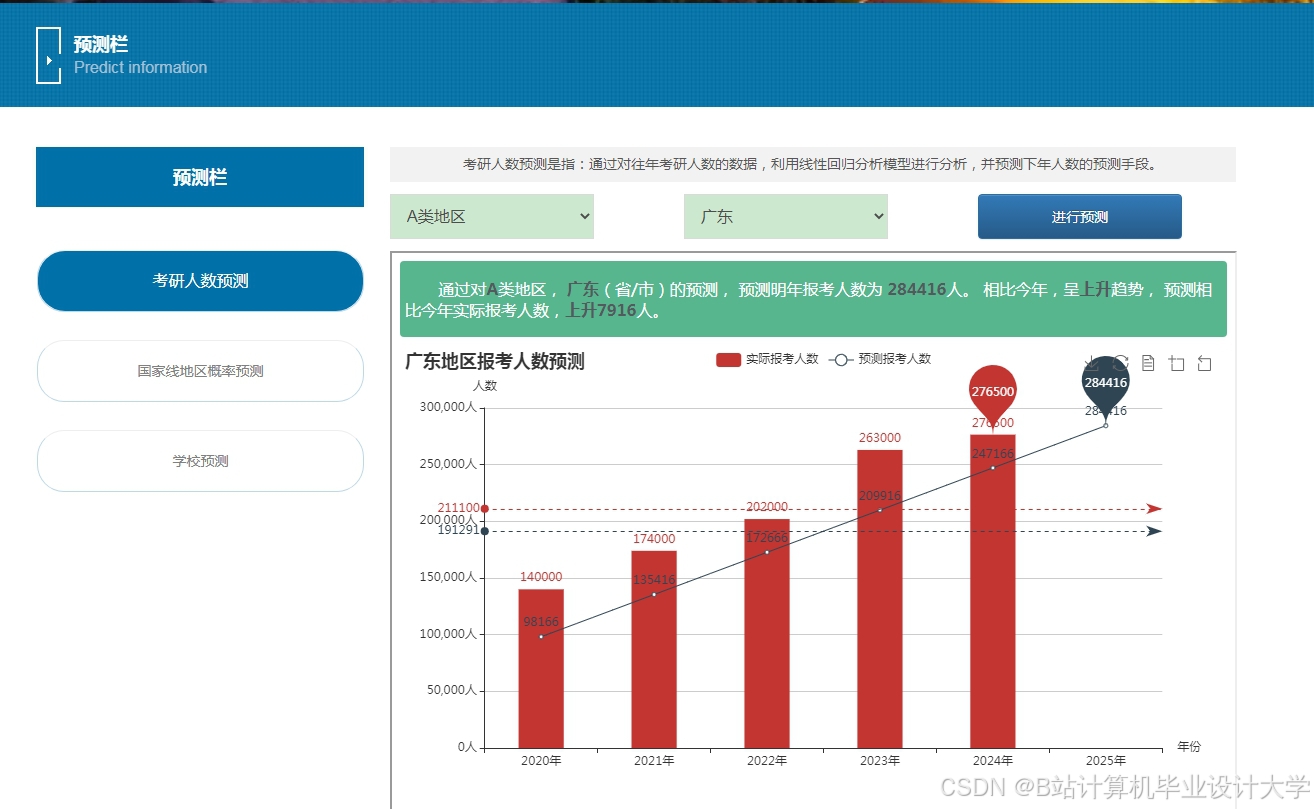
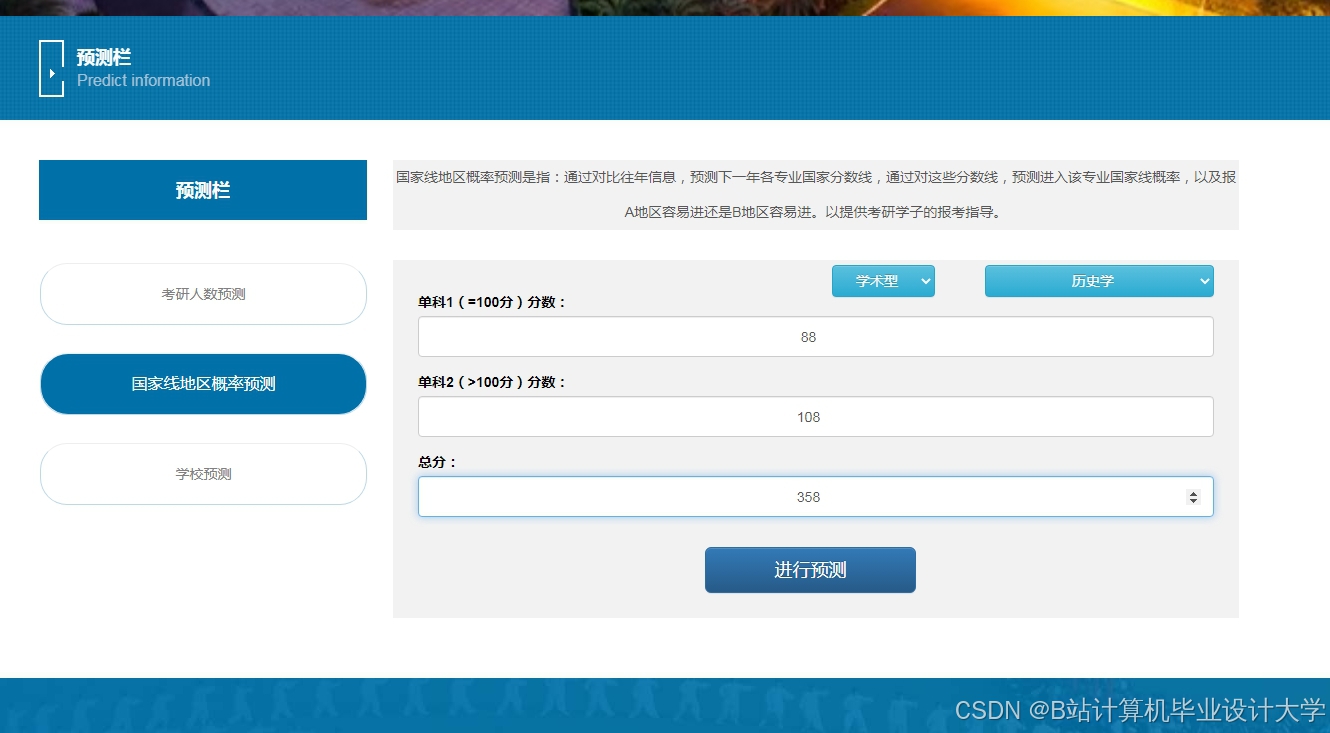
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











