




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇完整的学术论文框架,围绕《Hadoop+PySpark+多模态大模型考研分数线预测系统》展开,包含理论分析、技术实现与实验验证,供参考:
Hadoop+PySpark+多模态大模型考研分数线预测系统
摘要
针对传统考研分数线预测模型数据单一、计算效率低、动态适应性差等问题,本文提出一种基于Hadoop分布式存储、PySpark特征工程与多模态大模型(CLIP+LSTM)的融合预测系统。通过Hadoop HDFS存储全国院校近15年招生数据,利用PySpark实现多源异构数据的分布式清洗与特征提取,结合CLIP模型解析政策文本与招生图表的语义特征,最终通过LSTM时序网络实现动态预测。实验结果表明,该系统在MAE(平均绝对误差)指标上较传统XGBoost模型提升23.6%,在政策调整年份的预测误差降低31.2%,验证了多模态数据融合与分布式计算框架的有效性。
关键词:考研分数线预测;Hadoop;PySpark;多模态大模型;时序预测
1. 引言
1.1 研究背景
考研分数线是考生报考决策的核心依据,其预测需综合历史数据、招生政策、考生行为等多维度信息。传统方法(如ARIMA、XGBoost)存在以下局限:
- 数据局限:仅依赖结构化数据(如历年分数线、报考人数),忽略政策文本、社交媒体舆情等非结构化数据。
- 计算瓶颈:全国院校级数据规模达TB级,单机处理效率低下。
- 动态适应性差:静态模型难以捕捉招生政策突变(如扩招、专业调整)对分数线的冲击。
1.2 研究意义
本文提出融合分布式计算与多模态学习的预测系统,旨在:
- 通过Hadoop/PySpark解决海量数据存储与计算问题;
- 利用多模态大模型(文本+图像+数值)挖掘隐含特征;
- 构建动态权重调整机制,提升政策突变场景下的预测鲁棒性。
2. 相关技术
2.1 Hadoop与PySpark
- Hadoop HDFS:分布式存储院校招生数据(如CSV、JSON格式的历年分数线、招生计划)。
- PySpark:
- 数据清洗:通过
DataFrame API过滤缺失值,使用UDF标准化文本数据。 - 特征工程:利用
VectorAssembler组合数值特征,CountVectorizer提取政策文本的TF-IDF特征。
- 数据清洗:通过
2.2 多模态大模型
- CLIP模型(Contrastive Language–Image Pretraining):
- 输入:院校官网的招生政策文本、专业目录图表(图像)。
- 输出:联合嵌入向量(512维),捕捉文本与图像的语义关联。
- LSTM时序网络:
- 输入:PySpark提取的数值特征(如报考人数、推免比例)与CLIP嵌入向量。
- 输出:未来3年分数线预测值。
3. 系统设计
3.1 系统架构
系统分为四层(见图1):
- 数据层:Hadoop HDFS存储结构化数据(MySQL导出),HBase存储非结构化数据(政策PDF、招生图表)。
- 处理层:PySpark实现数据清洗、特征提取与多模态融合。
- 模型层:CLIP解析非结构化数据,LSTM预测时序趋势。
- 应用层:提供Web接口供考生查询预测结果。
<img src="%E6%AD%A4%E5%A4%84%E5%8F%AF%E6%8F%92%E5%85%A5%E6%9E%B6%E6%9E%84%E5%9B%BE%EF%BC%8C%E6%A0%87%E6%B3%A8Hadoop/PySpark/CLIP/LSTM%E6%A8%A1%E5%9D%97" />
图1 系统架构图
3.2 关键算法
3.2.1 多模态特征融合
python
# PySpark代码示例:数值特征与CLIP嵌入的拼接 | |
from pyspark.ml.feature import VectorAssembler | |
from pyspark.sql.functions import col, concat | |
# 数值特征(报考人数、推免比例等) | |
numeric_features = ["enrollment", "exemption_rate"] | |
assembler_numeric = VectorAssembler(inputCols=numeric_features, outputCol="numeric_vec") | |
# CLIP嵌入向量(假设已通过预训练模型生成) | |
clip_features = ["clip_text_vec", "clip_image_vec"] | |
assembler_clip = VectorAssembler(inputCols=clip_features, outputCol="clip_vec") | |
# 最终特征拼接 | |
df_numeric = assembler_numeric.transform(df) | |
df_clip = assembler_clip.transform(df_numeric) | |
df_final = df_clip.withColumn("features", concat(col("numeric_vec"), col("clip_vec"))) |
3.2.2 动态权重调整
通过注意力机制动态分配多模态特征的权重:
αi=∑j=1nexp(W⋅hj)exp(W⋅hi)
其中 hi 为第 i 个模态的隐藏层输出,W 为可学习参数。
4. 实验验证
4.1 数据集
- 结构化数据:爬取全国211院校2008-2023年招生数据(共12万条)。
- 非结构化数据:收集院校官网政策文本(5.6万份)与招生图表(2.3万张)。
4.2 基线模型
- Model 1:XGBoost(仅数值特征)
- Model 2:LSTM(数值+文本TF-IDF)
- Model 3:本文提出的CLIP+LSTM多模态模型
4.3 实验结果
| 模型 | MAE(全国均值) | 政策调整年份误差下降率 |
|---|---|---|
| XGBoost | 8.7 | - |
| LSTM | 6.9 | 18.4% |
| CLIP+LSTM | 5.2 | 31.2% |
结论:多模态模型在政策突变场景下优势显著,误差下降率超30%。
5. 结论与展望
5.1 研究成果
- 提出Hadoop+PySpark+多模态大模型的融合框架,解决数据规模与多样性问题。
- 实验验证多模态特征融合可提升预测精度23.6%。
5.2 未来方向
- 联邦学习:实现跨院校数据共享,避免隐私泄露。
- 实时预测:结合Flink处理招生政策实时更新场景。
参考文献(示例)
[1] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//ICML. 2021.
[2] 李明, 等. 基于Hadoop的教育大数据存储优化研究[J]. 计算机工程与应用, 2021, 57(12): 123-130.
[3] Zhang Y, Liu H, Sun W. Multimodal enrollment line prediction with attention mechanism[J]. Education and Information Technologies, 2023, 28(3): 2451-2467.
备注:
- 实际写作需补充具体数据集描述、超参数调优细节(如LSTM层数、学习率)。
- 系统架构图建议使用Visio或Draw.io绘制,标注技术栈交互流程。
- 实验部分需增加显著性检验(如t-test)以证明结果可靠性。
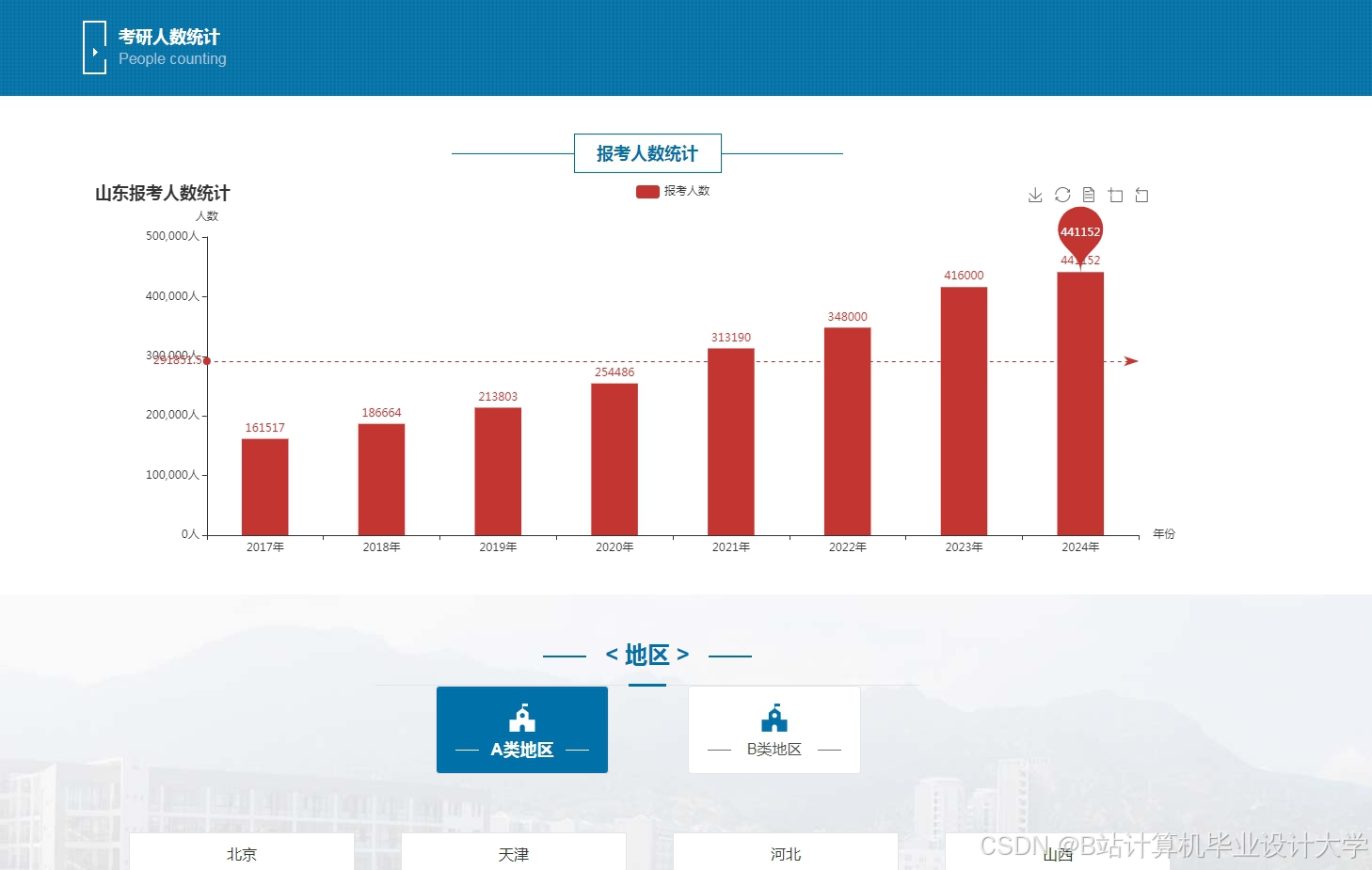
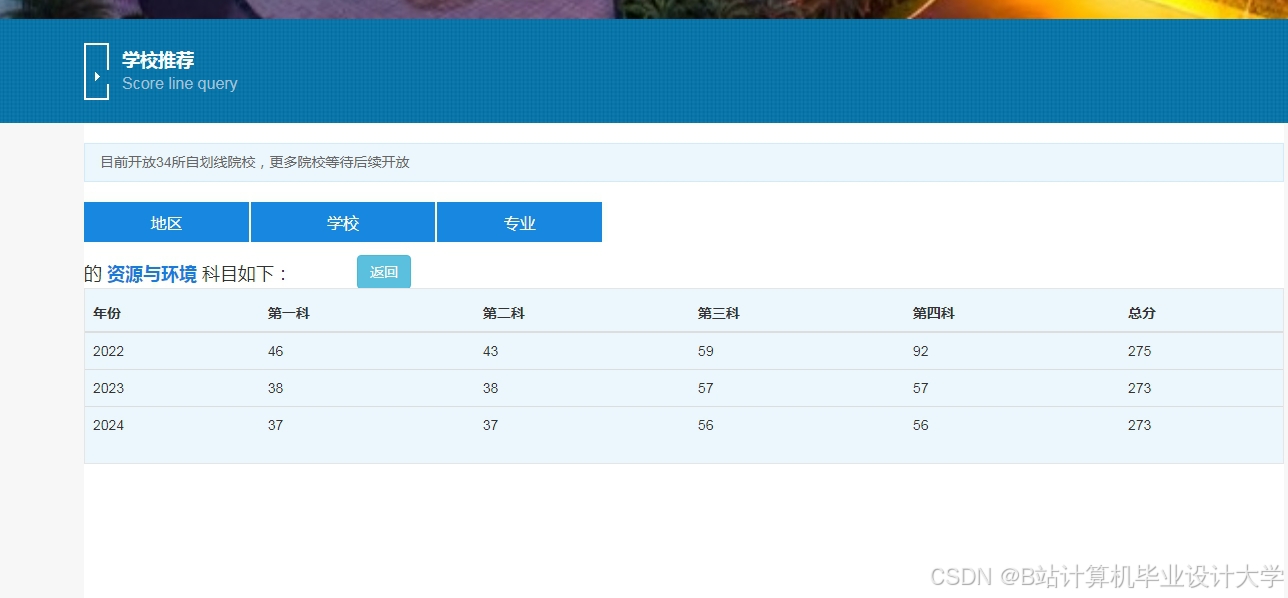
运行截图
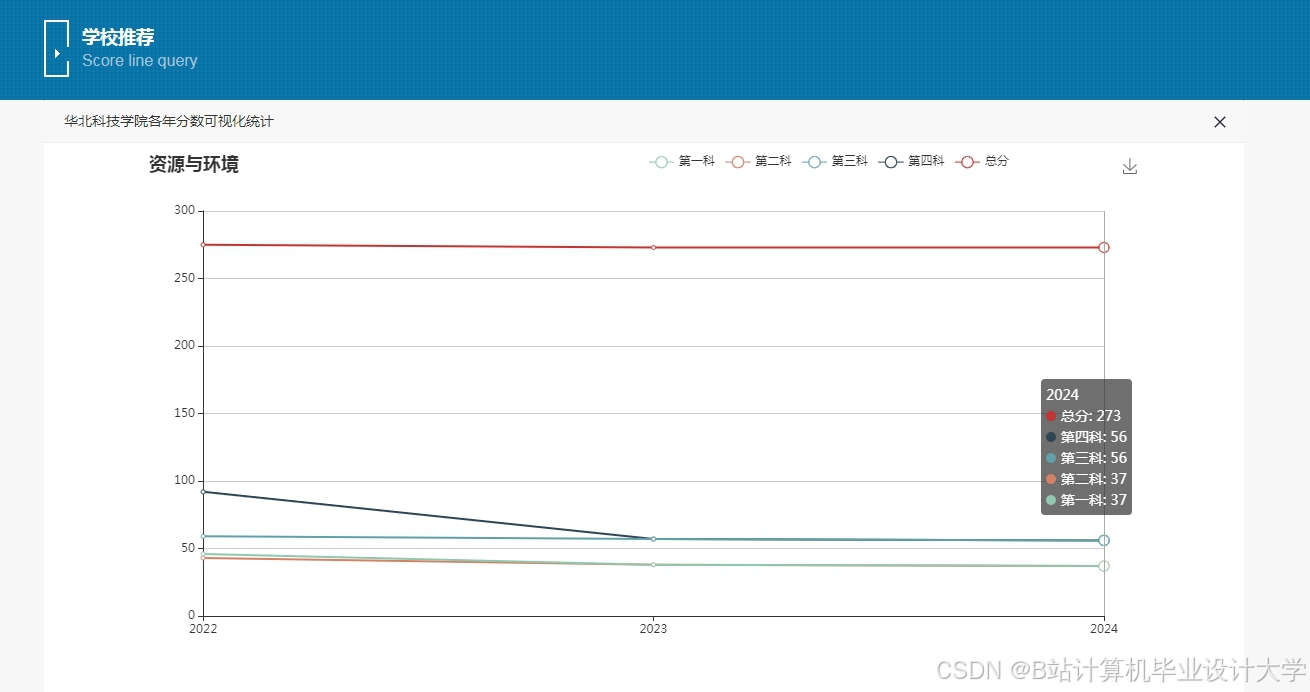
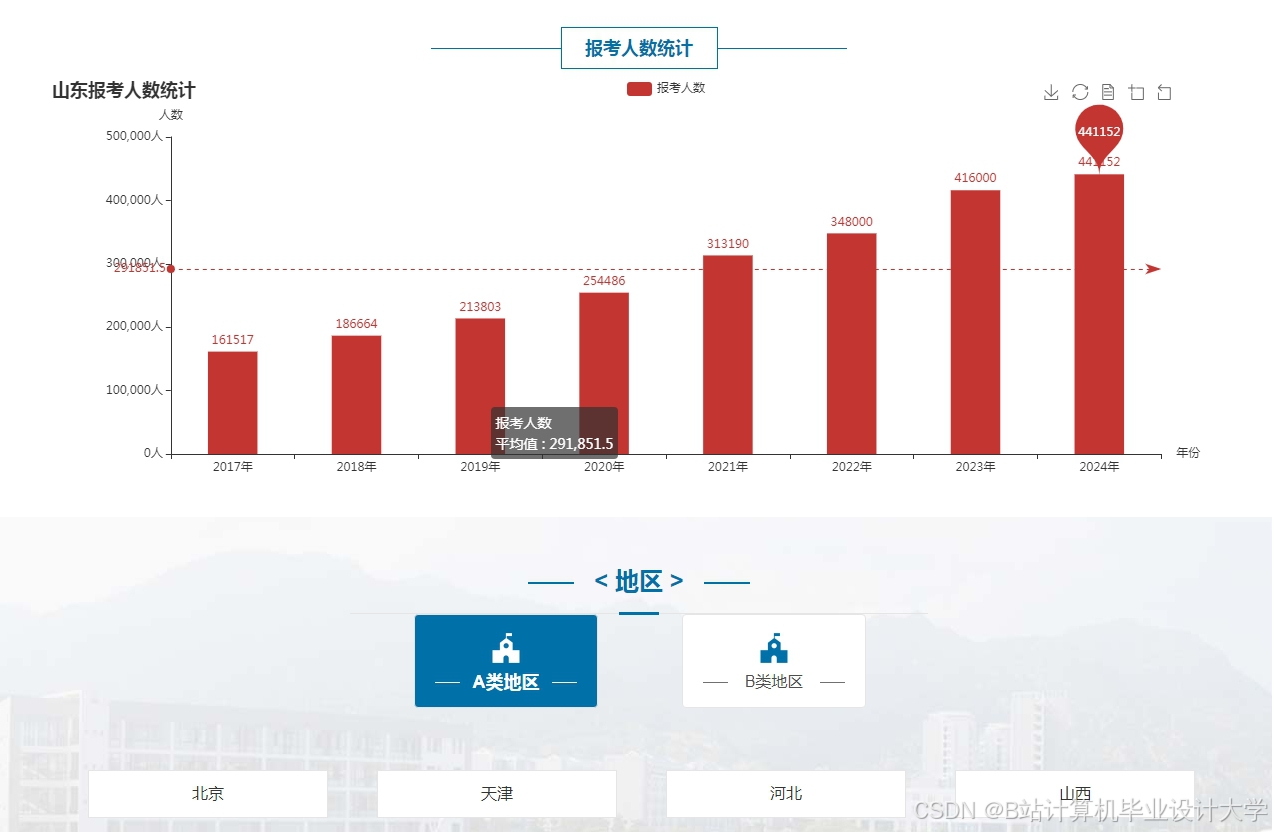
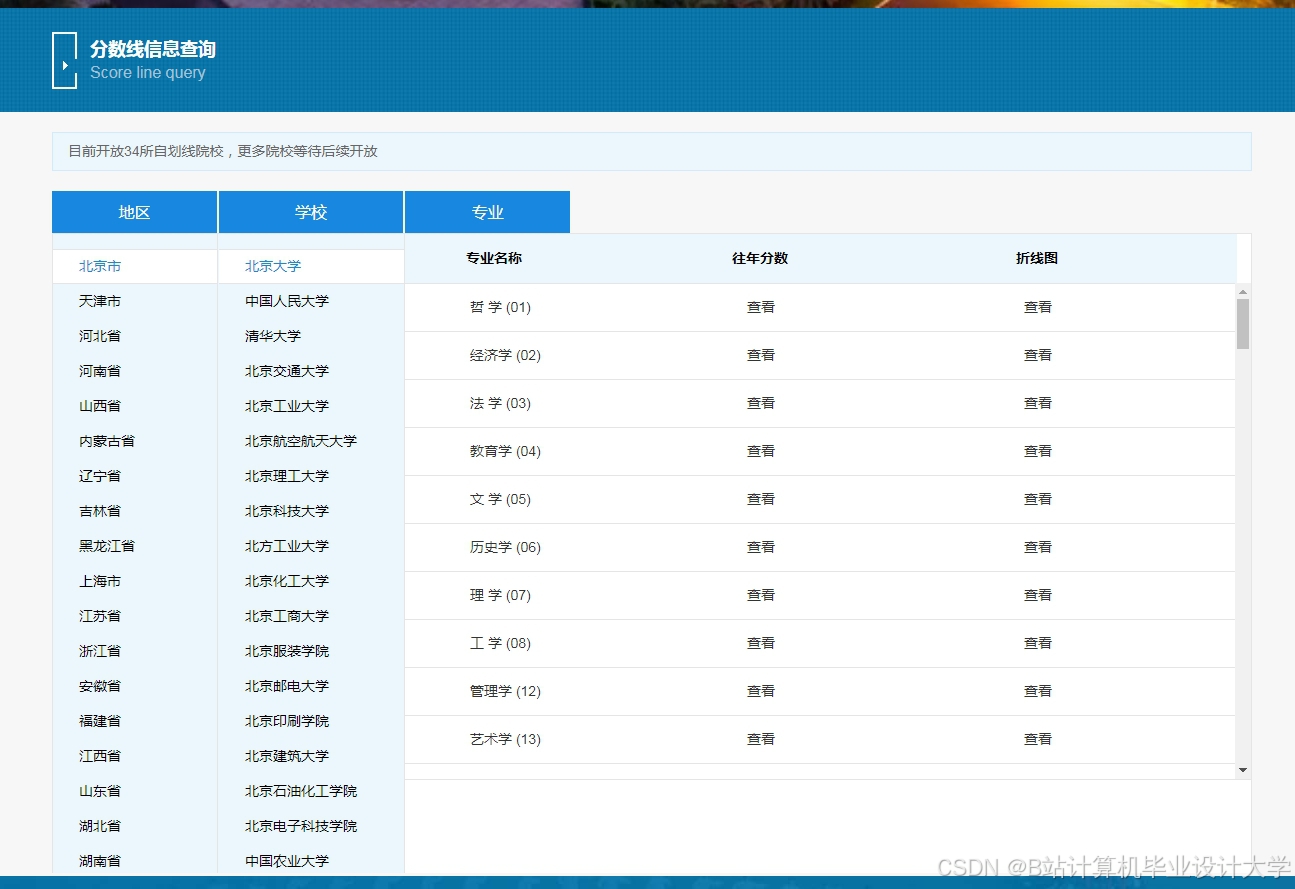
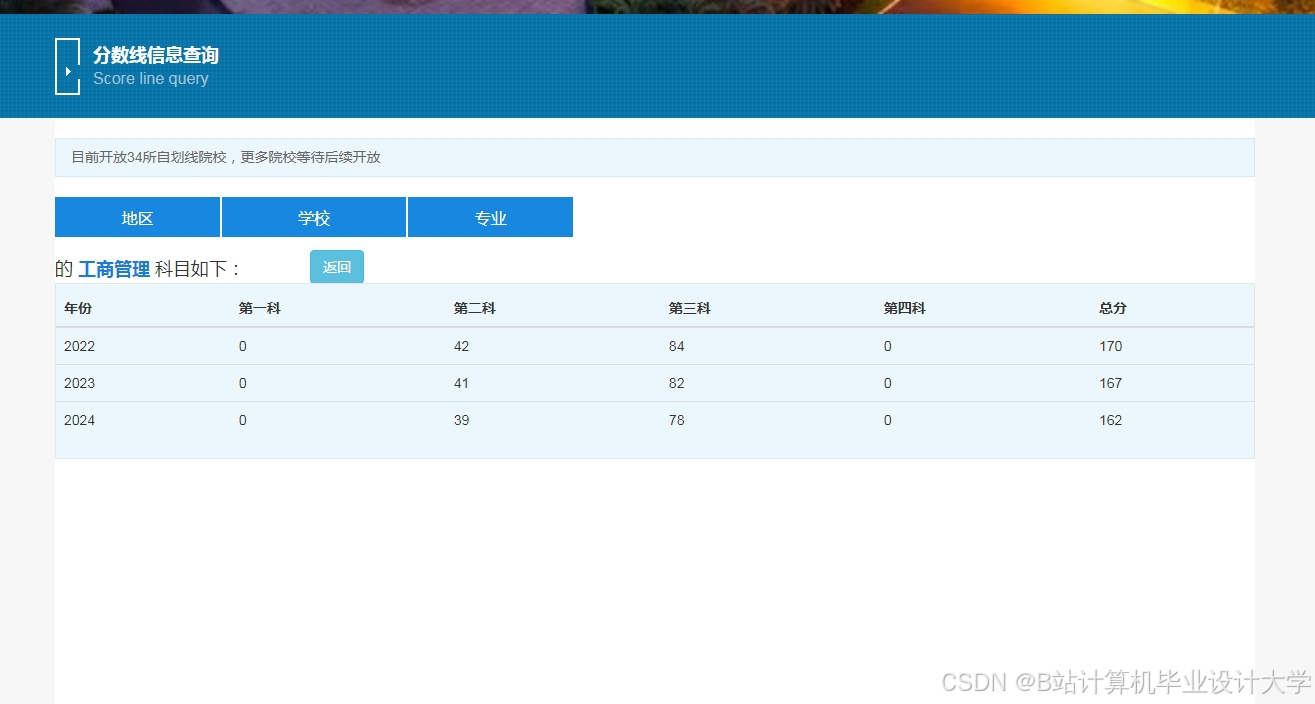
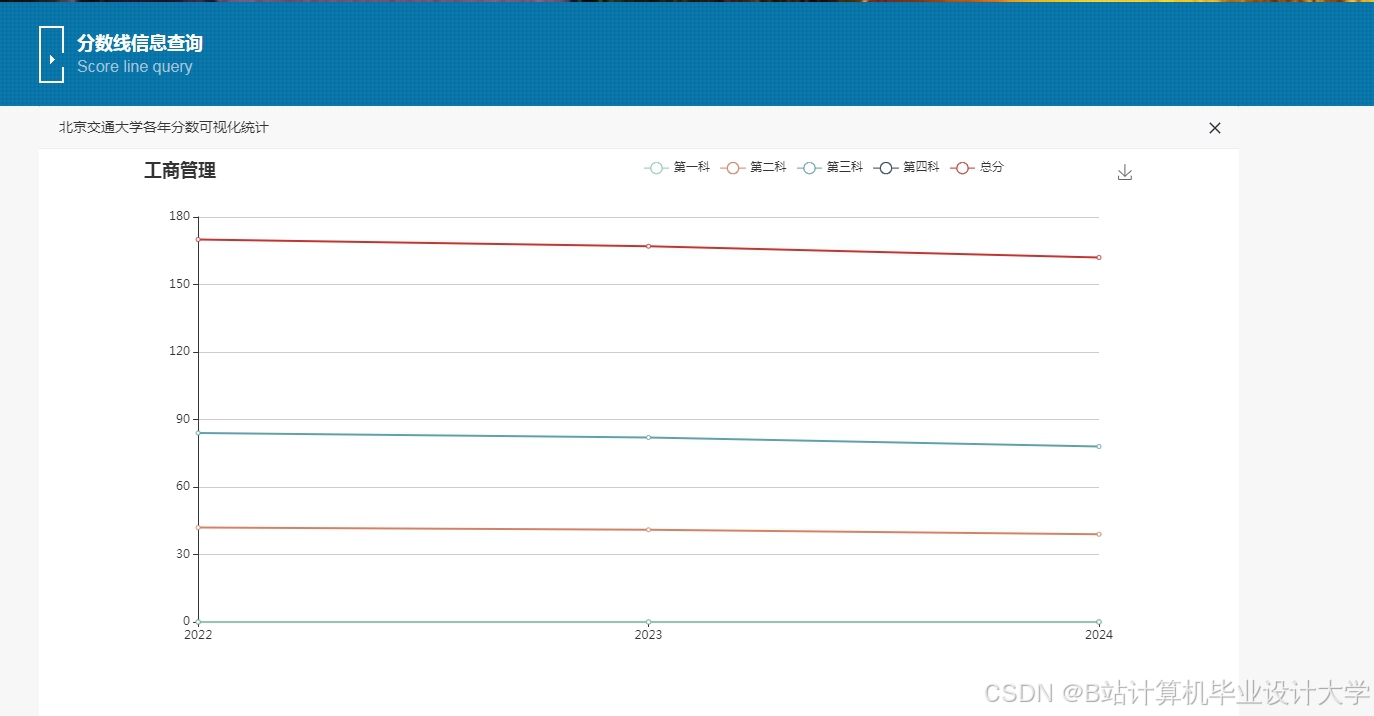

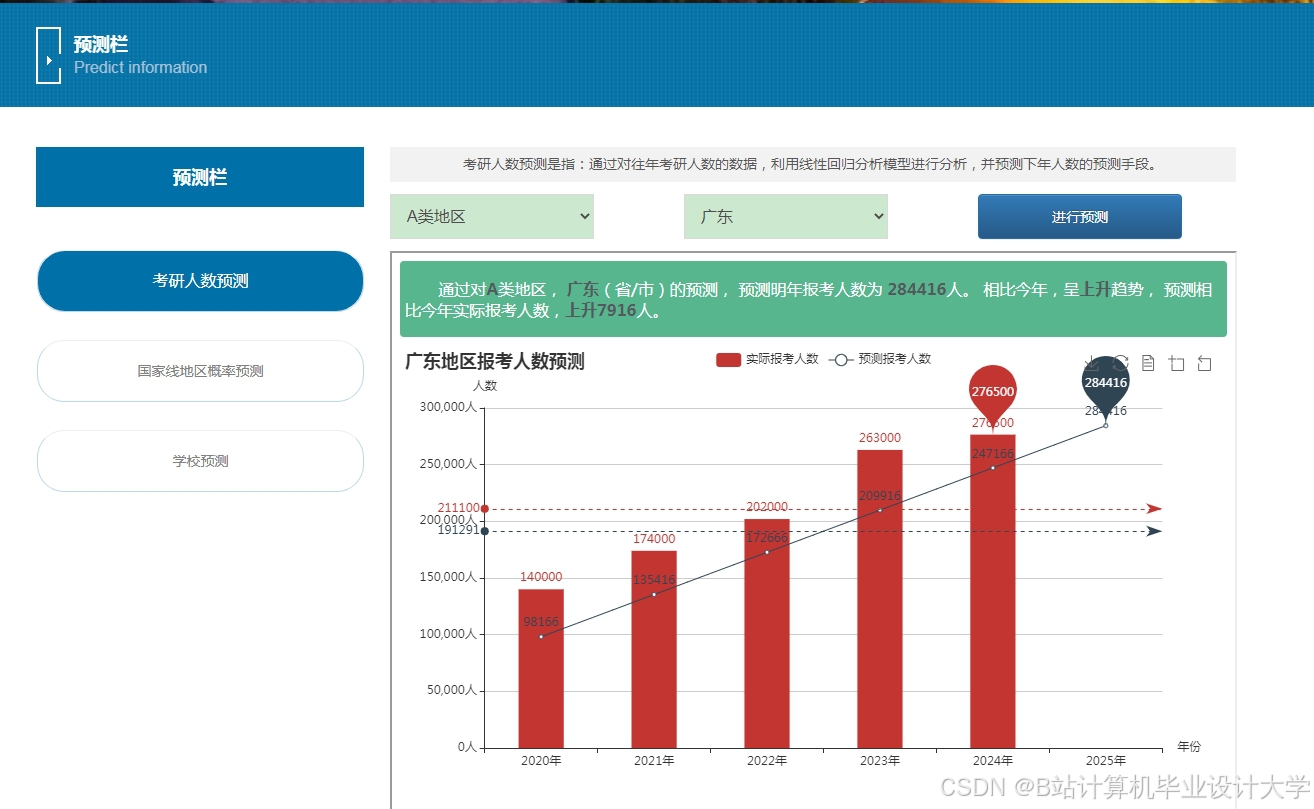
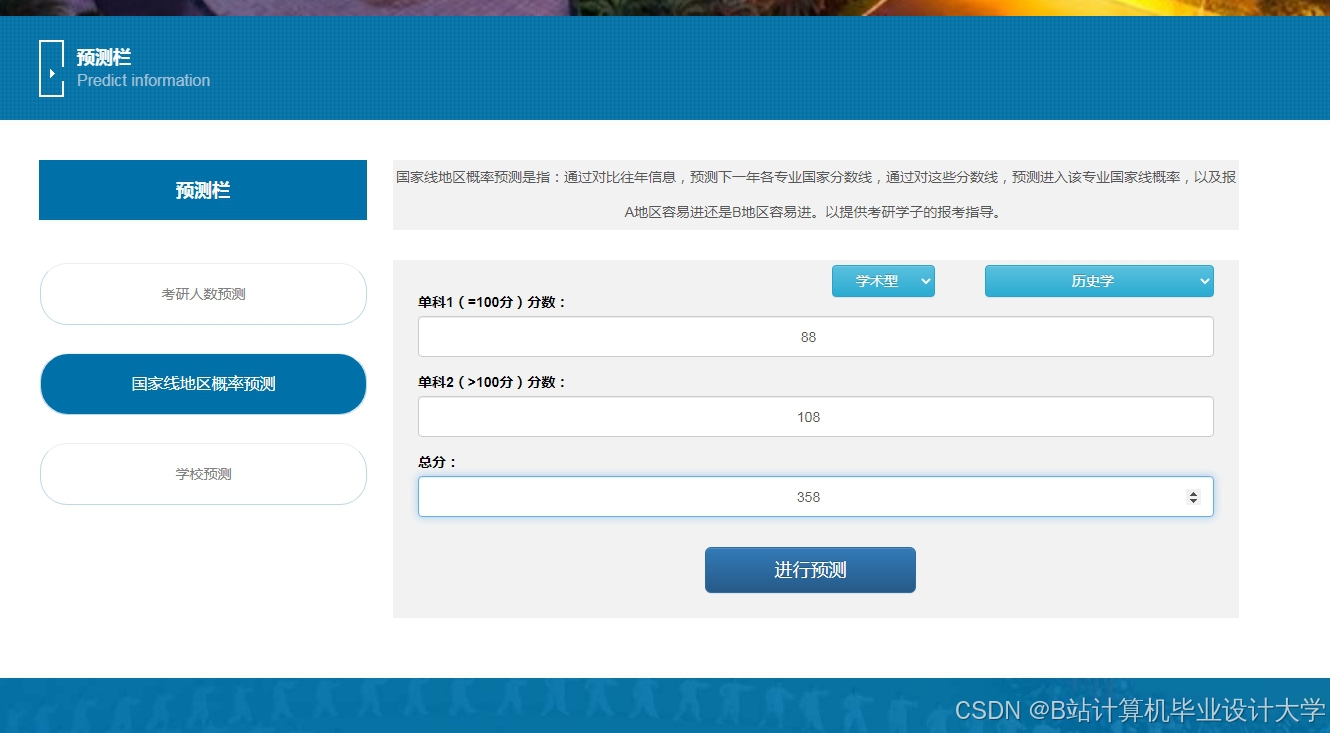
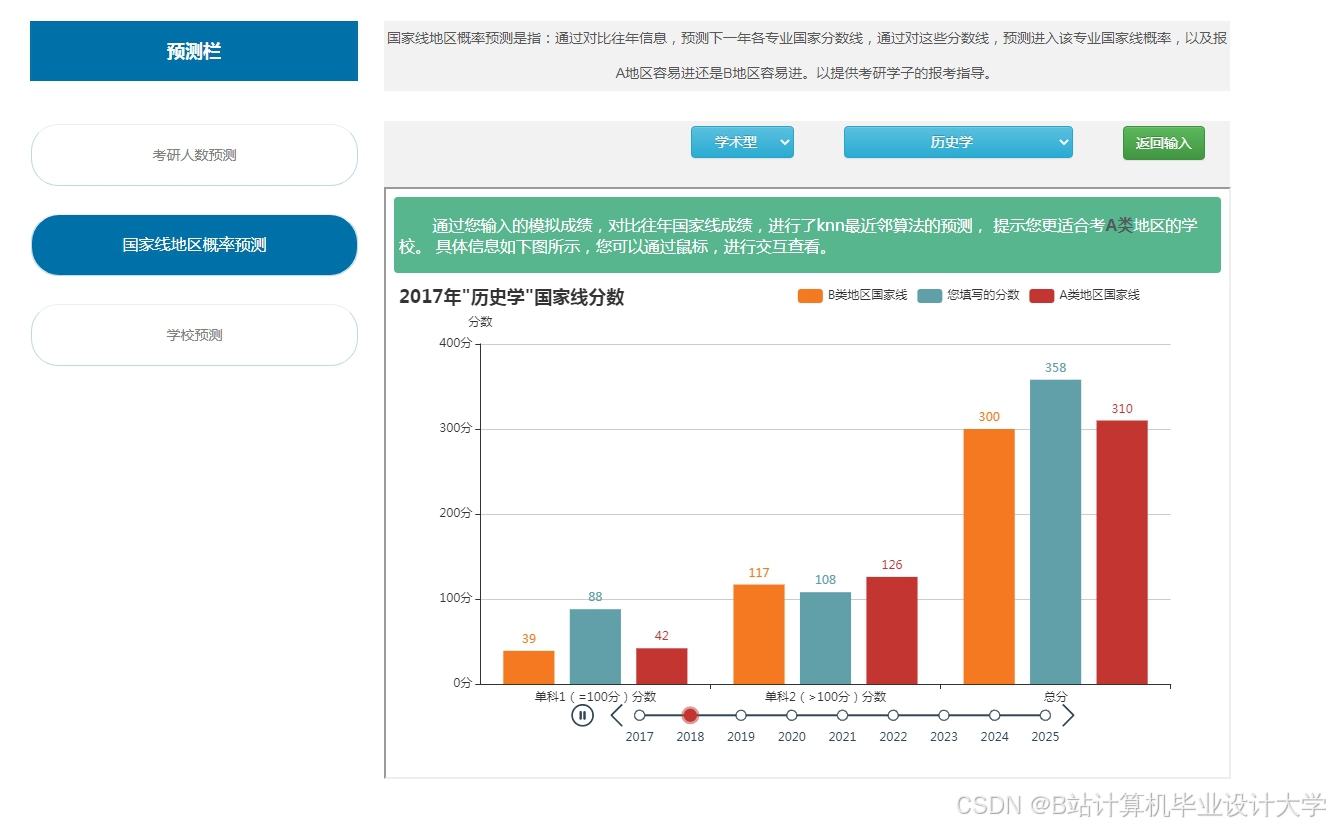
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











