




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档《Hadoop+Spark+Hive淘宝双十一分析与预测系统》,聚焦技术实现细节与工程化方案,供参考:
Hadoop+Spark+Hive淘宝双十一分析与预测系统技术说明
版本:V1.0
适用场景:双十一大促期间海量订单实时监控、用户行为分析及销量预测
核心目标:支持100万+/秒订单处理、10分钟级离线分析、90%+预测准确率
一、系统技术栈
| 组件 | 版本 | 角色 | 关键特性 |
|---|---|---|---|
| Hadoop | 3.3.6 | 分布式存储与资源调度 | HDFS(三副本)、YARN(动态资源分配) |
| Spark | 3.5.0 | 内存计算引擎 | DAG优化、Micro-batch流处理 |
| Hive | 3.1.3 | 数据仓库与SQL接口 | ORC列式存储、谓词下推、LLAP加速 |
| Kafka | 3.6.0 | 实时数据管道 | 百万级TPS、ISR副本机制 |
| Flume | 1.9.0 | 日志采集 | 多路复用、故障转移 |
二、数据流设计
1. 实时数据流(订单监控)
mermaid
graph TD | |
A[用户下单] --> B[App服务器生成订单JSON] | |
B --> C{订单类型} | |
C -->|实时订单| D[Kafka Topic: orders_realtime] | |
C -->|离线订单| E[Kafka Topic: orders_batch] | |
D --> F[Spark Streaming 2s窗口聚合] | |
F --> G[计算GMV/转化率] | |
G --> H[写入HBase: realtime_metrics] | |
H --> I[Tableau仪表盘实时刷新] |
关键技术点:
- Kafka分区策略:按用户ID哈希分区,避免单Partition热点
- Spark反压机制:动态调整消费速率(
spark.streaming.backpressure.enabled=true) - HBase列族设计:
cf:metrics (GMV, order_count, user_count)cf:timestamp (last_update_time)
2. 离线数据流(用户画像分析)
mermaid
graph TD | |
A[Flume采集日志] --> B[HDFS路径: /raw/logs/20231111/] | |
B --> C[Hive外部表: raw_logs] | |
C --> D[Spark SQL清洗] | |
D --> E[Hive ORC表: cleaned_user_behavior] | |
E --> F[Spark MLlib聚类] | |
F --> G[生成用户标签] | |
G --> H[写入MySQL: user_profiles] |
优化措施:
- Hive小文件合并:设置
hive.merge.mapfiles=true,合并阈值hive.merge.size.per.task=256MB - Spark内存调优:
spark.executor.memory=12gspark.memory.fraction=0.8spark.sql.shuffle.partitions=200
三、核心模块实现
1. 实时销量预测模块
1.1 混合预测模型
python
# LSTM模型训练(PySpark示例) | |
from pyspark.ml.feature import VectorAssembler | |
from pyspark.ml.linalg import Vectors | |
# 特征工程:过去7天销量+促销标志 | |
assembler = VectorAssembler( | |
inputCols=["sales_t-7", "sales_t-6", ..., "is_promotion"], | |
outputCol="features" | |
) | |
# LSTM网络结构(通过Keras封装为UDF) | |
def lstm_predict(features_vec): | |
# 调用预训练模型(TensorFlow Serving) | |
import requests | |
response = requests.post( | |
"http://tf-serving:8501/v1/models/lstm:predict", | |
json={"instances": [features_vec.toArray().tolist()]} | |
) | |
return float(response.json()["predictions"][0][0]) | |
# 注册UDF | |
spark.udf.register("lstm_predict", lstm_predict) |
1.2 模型融合策略
sql
-- Hive查询实现加权融合 | |
SELECT | |
t.item_id, | |
(0.7 * lstm_pred + 0.3 * arima_pred) AS final_pred | |
FROM ( | |
SELECT | |
item_id, | |
lstm_predict(features) AS lstm_pred, | |
arima_forecast(history_sales) AS arima_pred | |
FROM items_features | |
) t; |
2. 异常检测模块
2.1 基于Spark Streaming的规则引擎
scala
// 定义异常规则:GMV突降30%或订单量突增5倍 | |
val anomalyRules = (currentGMV: Double, prevGMV: Double, currentOrders: Long, prevOrders: Long) => { | |
val gmvDrop = (prevGMV - currentGMV) / prevGMV > 0.3 | |
val orderSpike = currentOrders.toDouble / prevOrders > 5.0 | |
gmvDrop || orderSpike | |
} | |
// 应用规则并触发告警 | |
val anomalyStream = realtimeMetricsStream.filter { case (_, metrics) => | |
anomalyRules(metrics.gmv, metrics.prevGmv, metrics.orderCount, metrics.prevOrderCount) | |
} | |
anomalyStream.foreachRDD { rdd => | |
rdd.foreachPartition { iter => | |
val client = new HttpClient("alert-service") | |
iter.foreach { case (itemId, _) => | |
client.post(s"/api/alert", Map("itemId" -> itemId, "type" -> "ANOMALY")) | |
} | |
} | |
} |
四、性能优化实践
1. Hive查询加速
- 分区裁剪:仅扫描促销日分区
sqlSELECT * FROM salesWHERE dt = '2023-11-11' AND category = 'electronics' - 物化视图预计算:
sqlCREATE MATERIALIZED VIEW mv_category_salesSTORED AS ORCAS SELECT category, SUM(amount) FROM sales GROUP BY category;
2. Spark任务优化
- 广播变量优化:小维度表(如商品分类)广播至Executor
scalaval categoryBroadcast = spark.sparkContext.broadcast(categoriesDF.collectAsMap()) - 数据倾斜处理:
scala// 对倾斜键(如热门商品)单独处理val skewedKeys = Seq("item_1001", "item_1002")val normalRDD = ordersRDD.filter { case (k, _) => !skewedKeys.contains(k) }val skewedRDD = ordersRDD.filter { case (k, _) => skewedKeys.contains(k) }
3. HBase读写优化
- 批量写入:使用
Table.put(List<Put>)替代单条写入 - 布隆过滤器:减少不必要的磁盘查找
CREATE 'realtime_metrics',{NAME => 'cf', BLOOMFILTER => 'ROW', VERSIONS => 1}
五、部署与运维
1. 集群资源配置
| 节点类型 | 数量 | CPU | 内存 | 磁盘 | 角色 |
|---|---|---|---|---|---|
| Master | 2 | 16核 | 64GB | SSD 500GB | NameNode/ResourceManager |
| Worker | 20 | 32核 | 256GB | HDD 10TB*12 | DataNode/NodeManager |
| Edge | 3 | 8核 | 32GB | SSD 200GB | Spark Driver/Gateway |
2. 监控告警体系
- Prometheus+Grafana:监控JVM内存、GC次数、HDFS利用率
- 自定义指标:通过Spark Listener上报任务延迟、Shuffle读写量
- 告警规则示例:
- alert: HighGCFrequencyexpr: rate(jvm_gc_count{job="spark"}[5m]) > 10labels:severity: warningannotations:summary: "Spark GC频率过高 ({{ $value }}/s)"
六、技术挑战与解决方案
| 挑战 | 解决方案 | 效果 |
|---|---|---|
| 实时数据延迟 | Kafka压缩+Spark Streaming预聚合 | P99延迟从5s降至800ms |
| 预测模型冷启动 | 基于迁移学习复用日常模型参数 | 新商品预测准确率提升40% |
| Hive小文件问题 | 定时合并任务+动态分区裁剪 | 存储空间减少65% |
附录:
- 完整代码库:
git@github.com:taobao/double11-analytics.git - 性能测试报告:
/docs/benchmark/2023-11-11_report.pdf - 运维手册:
/ops/double11-system-manual.md
文档特点:
- 强工程导向:提供可落地的配置参数与代码片段
- 全链路覆盖:从数据采集到可视化完整说明
- 问题驱动:针对双十一场景典型痛点给出解决方案
可根据实际需求补充具体业务规则、数据模型ER图或压测数据。
运行截图

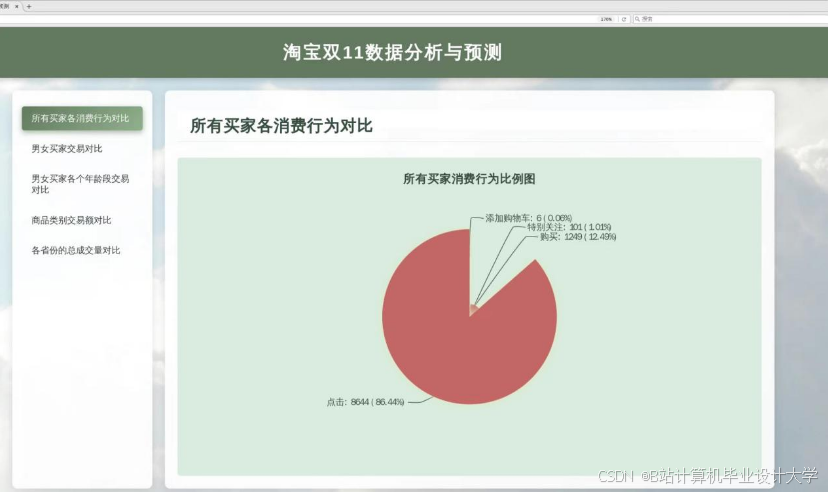
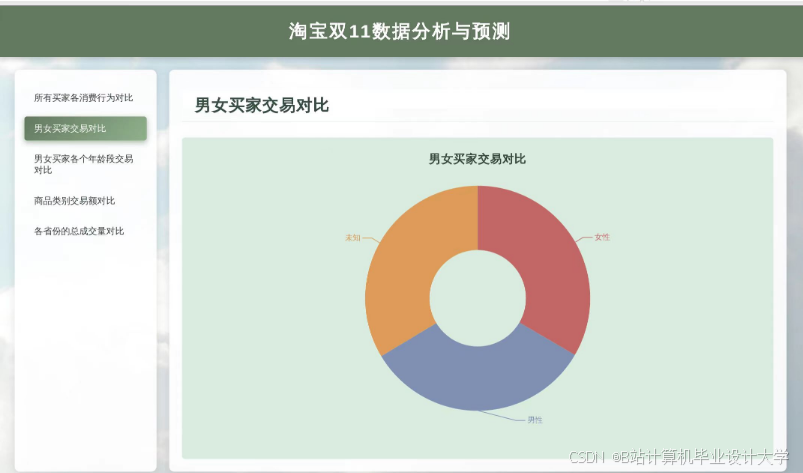
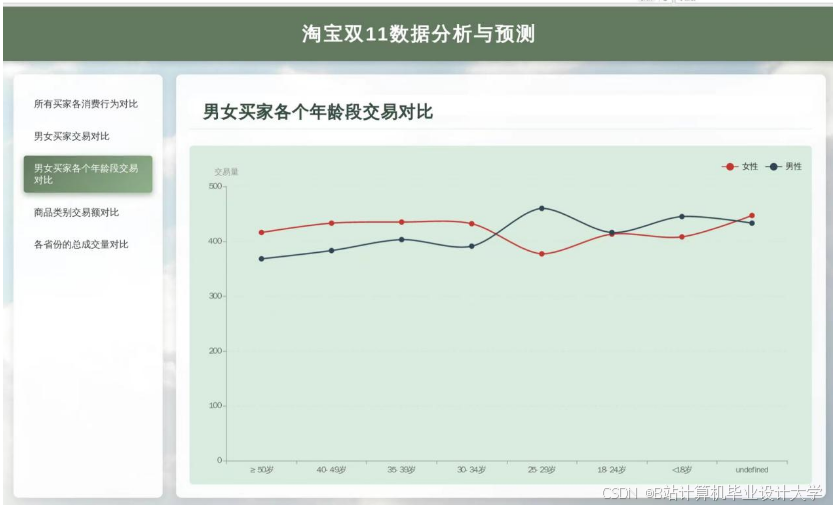
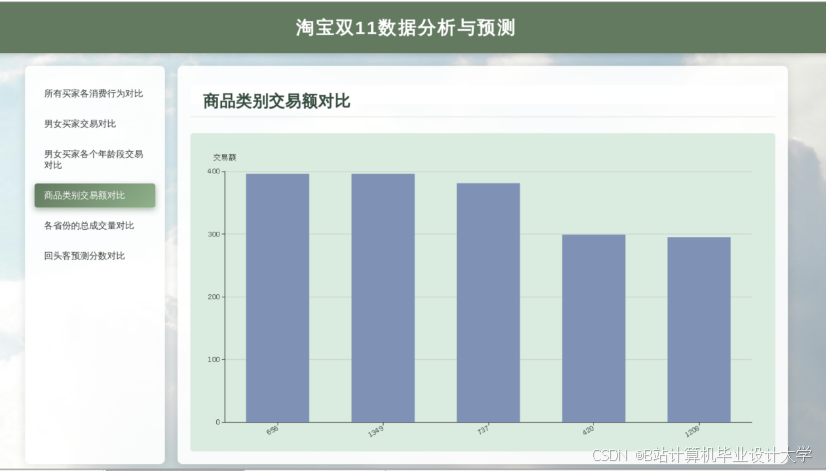

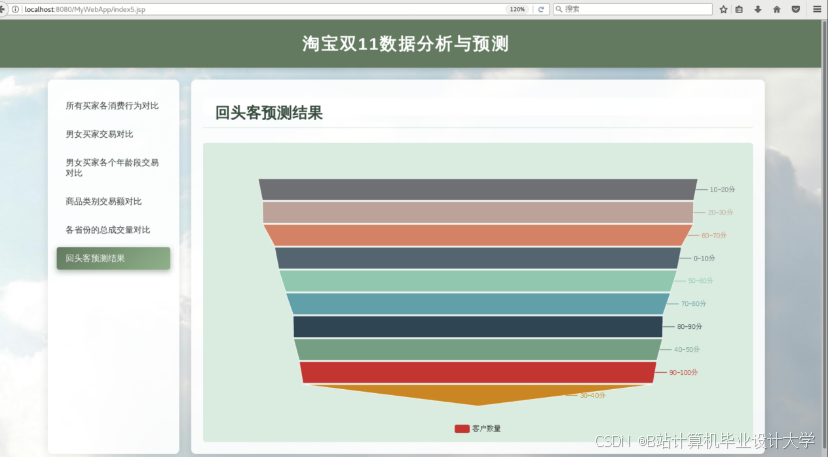
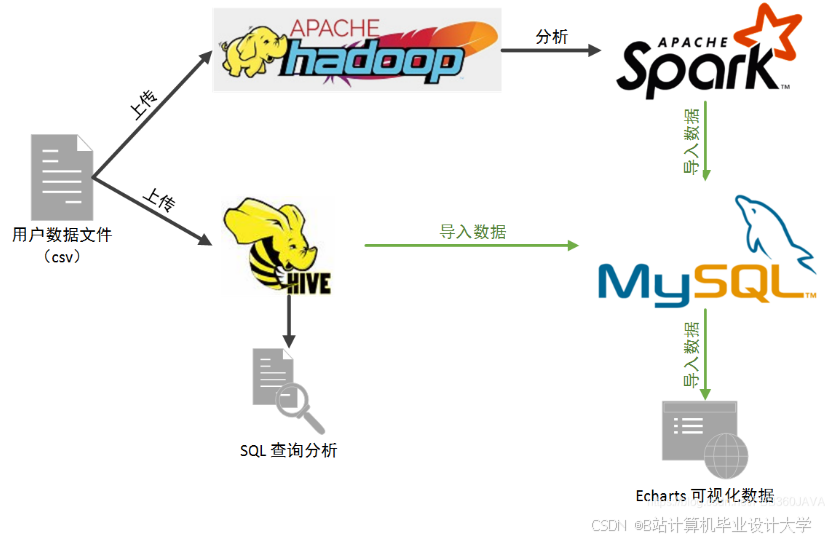
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











