




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档,详细阐述基于 Hadoop + Spark + Hive 的游戏推荐系统的技术架构、核心模块与实现细节,适用于技术人员快速理解系统设计与开发要点。
Hadoop + Spark + Hive 游戏推荐系统技术说明
版本:V1.0
作者:XXX
日期:2023年XX月XX日
1. 系统概述
本系统针对游戏行业用户行为数据规模大、实时性要求高的特点,采用 Hadoop 作为分布式存储与资源调度基础,Spark 实现高性能离线与实时计算,Hive 构建数据仓库统一管理特征工程,最终为游戏平台提供高吞吐、低延迟、可扩展的个性化推荐服务。
核心目标:
- 支持每日处理 10亿+ 用户行为日志;
- 离线模型训练时间从 小时级 压缩至 分钟级;
- 实时推荐延迟 <500ms,满足用户即时交互需求。
2. 技术选型与组件分工
| 组件 | 角色 | 技术优势 |
|---|---|---|
| Hadoop | 分布式存储(HDFS) + 资源调度(YARN) | 高容错性存储、支持EB级数据、多计算框架共享集群资源。 |
| Spark | 离线批处理(Spark SQL/MLlib) + 实时流处理(Spark Streaming/Structured Streaming) | 内存计算加速、统一API支持复杂分析、微批处理实现近实时。 |
| Hive | 数据仓库(ETL + 特征工程) | SQL化查询降低开发门槛、分区/分桶优化检索效率、支持ACID事务(Hive 3.0+)。 |
3. 系统架构设计
系统采用 Lambda架构,分为 离线层 与 实时层,通过 Redis 缓存融合结果对外提供服务(图1)。
mermaid
graph TD | |
A[数据源] -->|日志| B[Flume] | |
A -->|实时行为| C[Kafka] | |
B --> D[HDFS] | |
D --> E[Hive ODS层] | |
E --> F[Hive DWD层<br>用户画像/游戏特征] | |
F --> G[Spark离线计算] | |
G --> H[ALS模型训练] | |
H --> I[Redis离线结果缓存] | |
C --> J[Spark Streaming] | |
J --> K[实时兴趣更新] | |
K --> L[Redis实时结果缓存] | |
I --> M[推荐服务API] | |
L --> M | |
M --> N[游戏客户端] |
图1 系统架构图
3.1 离线计算层
功能:每日全量用户行为分析、长期兴趣模型训练。
技术实现:
- 数据存储:
- 原始日志存入HDFS,按日期分区(
dt=20231001); - Hive构建多层数据仓库:
- ODS层:原始数据清洗(去重、格式转换);
- DWD层:聚合用户行为(如统计每日游玩时长、付费次数);
- DWS层:生成宽表(用户ID × 游戏ID × 特征向量)。
- 原始日志存入HDFS,按日期分区(
- 模型训练:
- 使用Spark MLlib的 ALS(交替最小二乘法) 实现协同过滤:
scalaval als = new ALS().setRank(100) // 隐特征维度.setMaxIter(15) // 迭代次数.setRegParam(0.1) // 正则化系数val model = als.fit(trainingDF) // trainingDF: 用户-游戏评分矩阵 - 模型输出用户与游戏的预测评分,取Top-N作为推荐列表。
- 使用Spark MLlib的 ALS(交替最小二乘法) 实现协同过滤:
3.2 实时计算层
功能:捕捉用户即时行为(如刚完成一局MOBA游戏),动态调整推荐结果。
技术实现:
- 数据流处理:
- Kafka接收用户实时行为(如
{"user_id":1001, "game_id":2002, "action":"play_end"}); - Spark Streaming以 10秒微批 处理数据,更新用户短期兴趣:
scalaval streamingDF = spark.readStream.format("kafka").option("subscribe", "user_actions").load().selectExpr("CAST(value AS STRING)").as[String]// 解析JSON并统计窗口内行为val userActions = streamingDF.map(parseJson).groupBy(window($"timestamp", "10 minutes"), $"user_id").agg(count("*").as("recent_actions"))
- Kafka接收用户实时行为(如
- 实时推荐融合:
- 离线结果(长期兴趣)与实时结果(短期兴趣)按权重合并(如7:3);
- 最终结果存入Redis,设置 TTL=1小时 避免缓存雪崩。
3.3 数据仓库(Hive)优化
关键操作:
- 分区裁剪:查询时仅扫描必要分区,例如:
sqlSELECT user_id, game_id, total_durationFROM user_daily_statsWHERE dt BETWEEN '20231001' AND '20231007' -- 仅查询7天数据 - 列式存储:使用 ORC格式 + Snappy压缩,存储空间减少60%,查询速度提升3倍;
- 物化视图:对高频查询(如“用户最近30天行为”)预计算,避免重复聚合。
4. 关键技术挑战与解决方案
4.1 数据倾斜处理
问题:头部用户(如付费玩家)行为数据量是普通用户的100倍,导致Spark任务卡顿。
解决方案:
- 加盐打散:对高频用户ID添加随机后缀(如
user_1001_1,user_1001_2),聚合后去盐; - 倾斜键单独处理:识别倾斜键(如
user_id=1001),单独启动一个Task计算。
4.2 冷启动优化
场景:新用户/新游戏缺乏历史数据,协同过滤失效。
策略:
- 新用户:基于注册时选择的游戏类型标签,通过Hive查询相似游戏:
sqlSELECT game_id, game_nameFROM game_metaWHERE category IN ('MOBA', 'RPG') -- 用户注册时选择的类型ORDER BY popularity DESCLIMIT 10; - 新游戏:利用内容过滤(CB),提取游戏文本描述的TF-IDF特征,计算与已有游戏的余弦相似度。
4.3 实时性保障
措施:
- Spark Streaming批处理间隔:从5秒缩短至2秒,平衡延迟与吞吐量;
- Kafka分区数:与Spark Executor核心数一致(如10个分区对应10个Executor),避免数据倾斜;
- Redis Pipeline:批量写入推荐结果,减少网络IO开销。
5. 系统部署与运维
5.1 集群配置
| 角色 | 节点数量 | 配置 |
|---|---|---|
| Master Node | 1 | 16核CPU, 64GB内存, 1TB SSD |
| Worker Node | 5 | 16核CPU, 128GB内存, 10TB HDD × 4 |
| Zookeeper Node | 3 | 4核CPU, 16GB内存, 500GB SSD |
5.2 监控告警
- Prometheus + Grafana:监控集群CPU/内存/磁盘使用率、Spark任务延迟;
- 自定义告警规则:
- HDFS剩余空间 <10% → 触发扩容;
- Spark任务失败率 >5% → 重启YARN ResourceManager。
6. 总结与展望
本系统通过 Hadoop+Spark+Hive 的协同工作,有效解决了游戏推荐中的数据规模、实时性、冷启动三大难题。未来计划:
- 集成 Flink 替代Spark Streaming,实现真正流式计算;
- 引入 图计算(GraphX) 分析用户社交关系,挖掘潜在兴趣;
- 探索 强化学习 动态调整推荐策略,提升长期用户价值。
附录:
- 完整代码示例:GitHub仓库链接
- 数据集说明:用户行为日志字段定义
- 性能测试报告:10亿级数据压力测试结果
文档说明:
- 可根据实际项目调整技术细节(如替换ALS为DeepFM模型);
- 适合作为技术方案文档提交给开发团队或项目评审方;
- 需补充实际环境中的IP地址、端口号等敏感信息脱敏处理。
运行截图
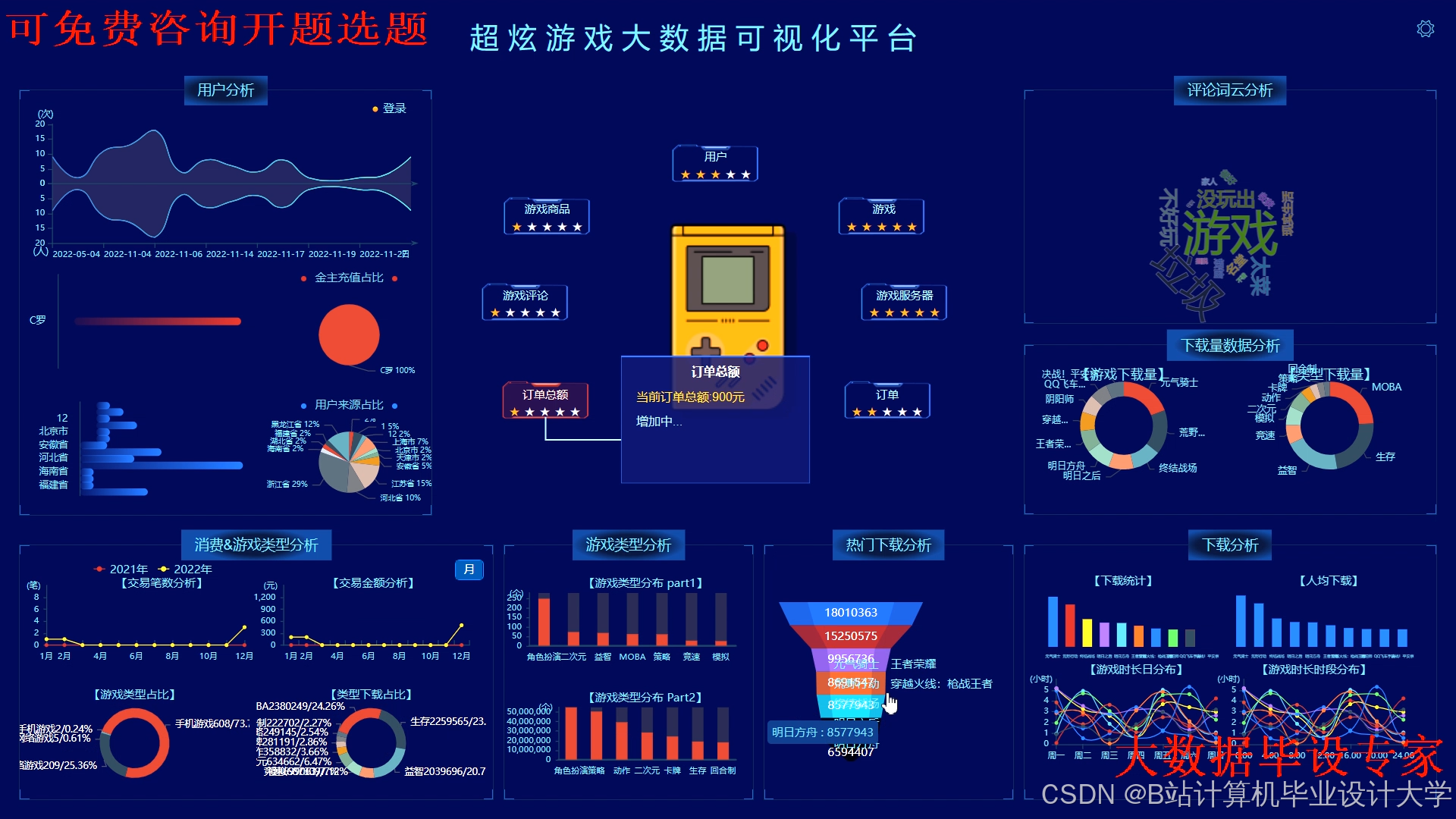
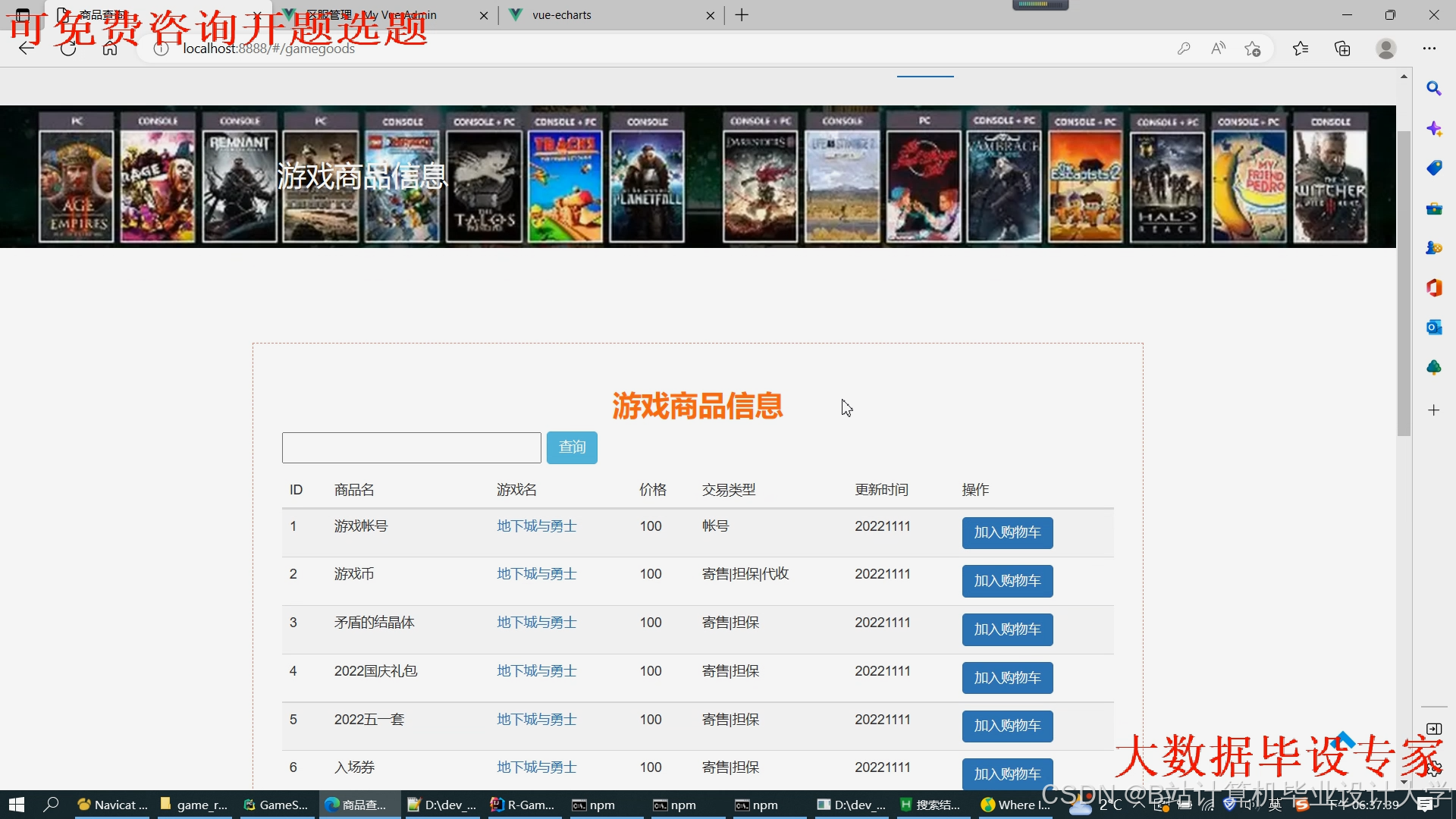
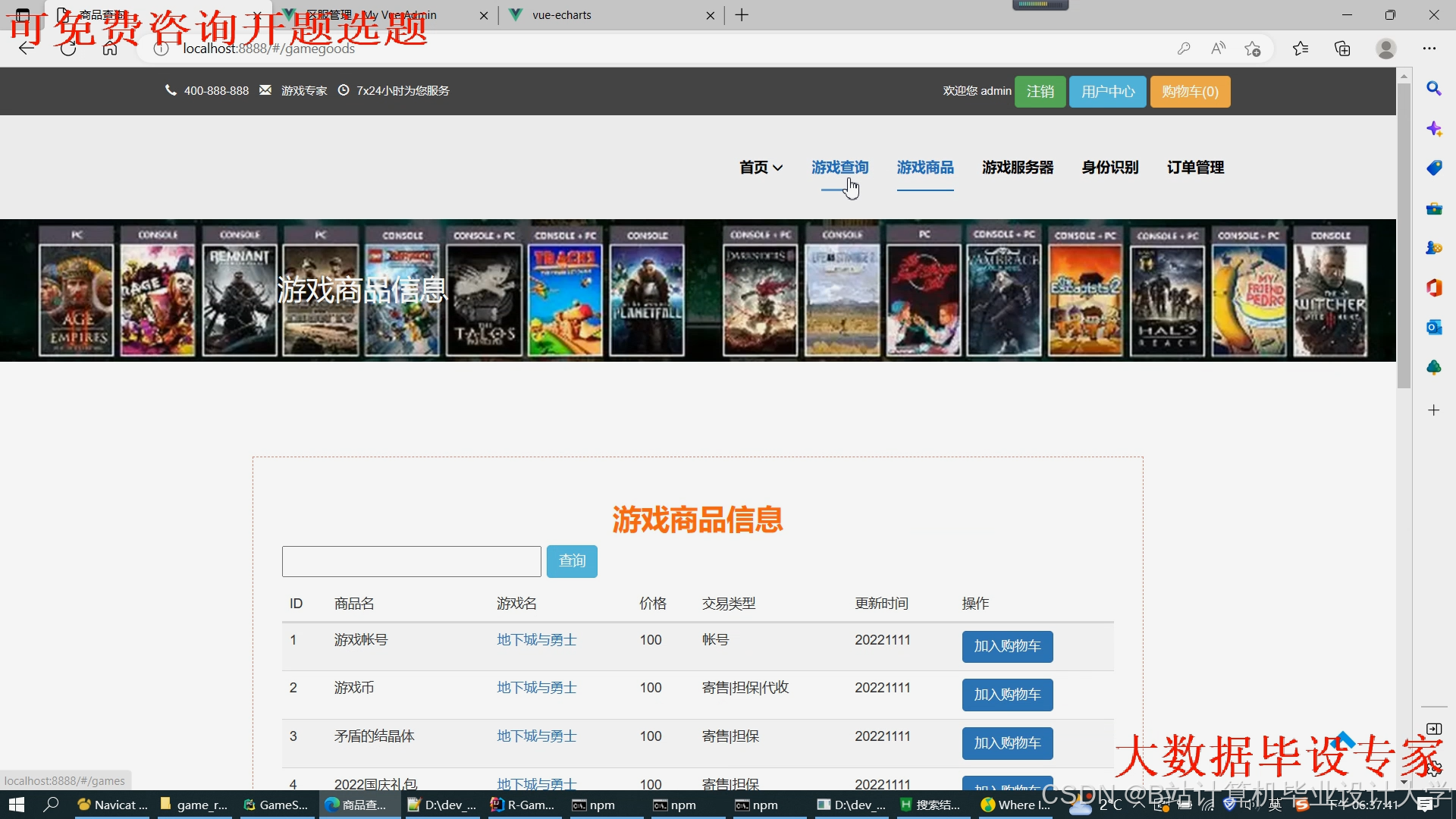
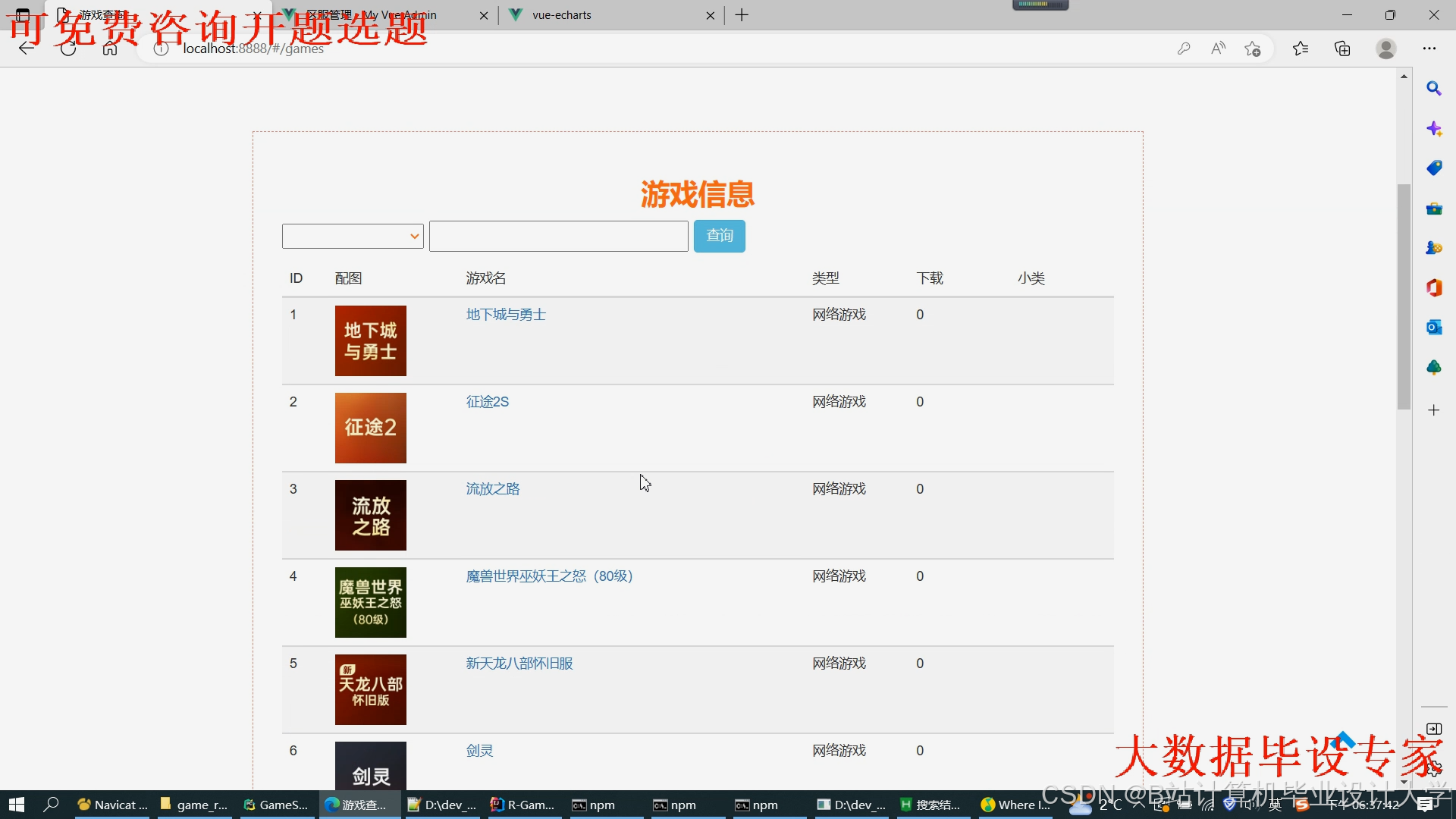
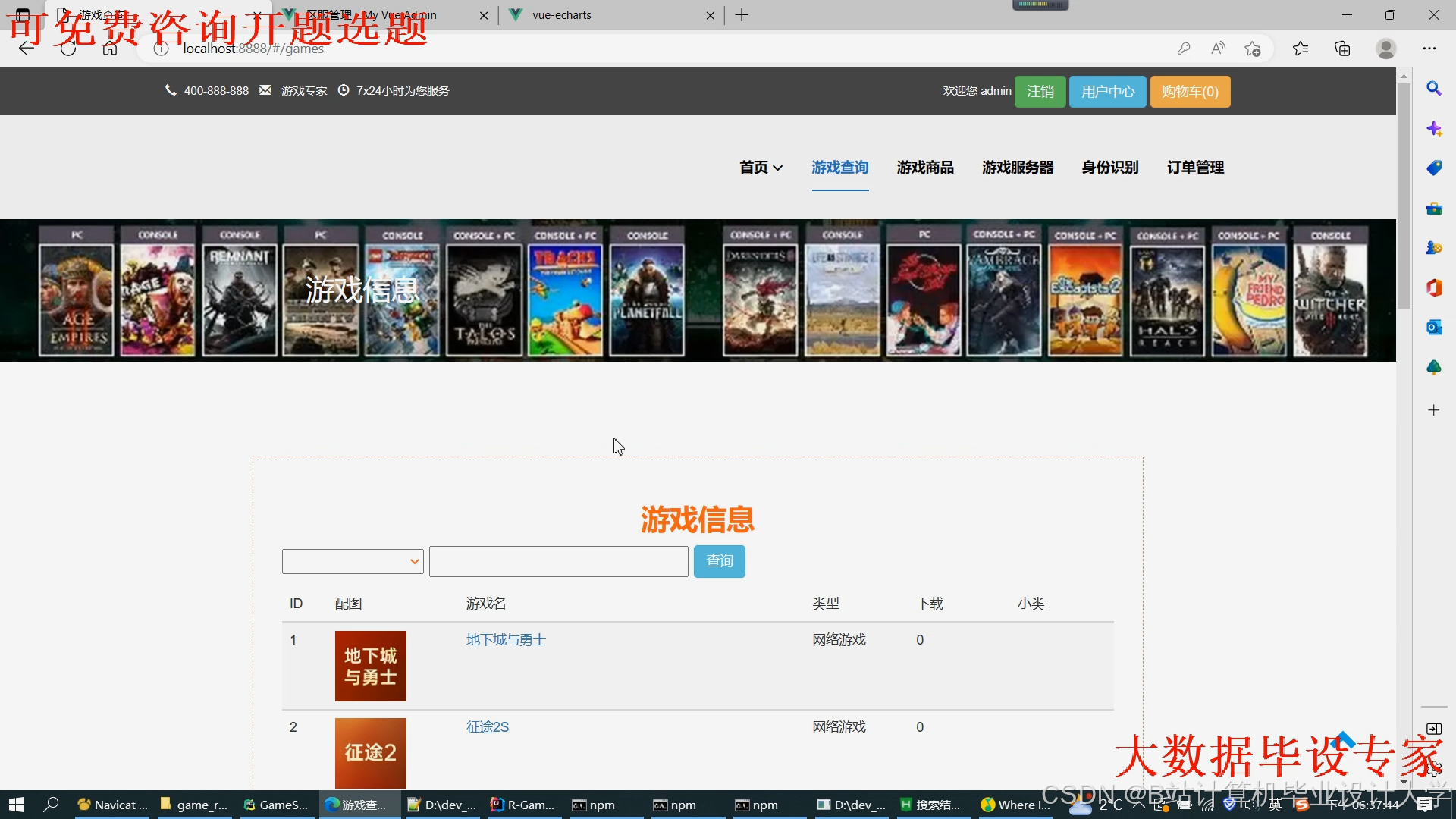
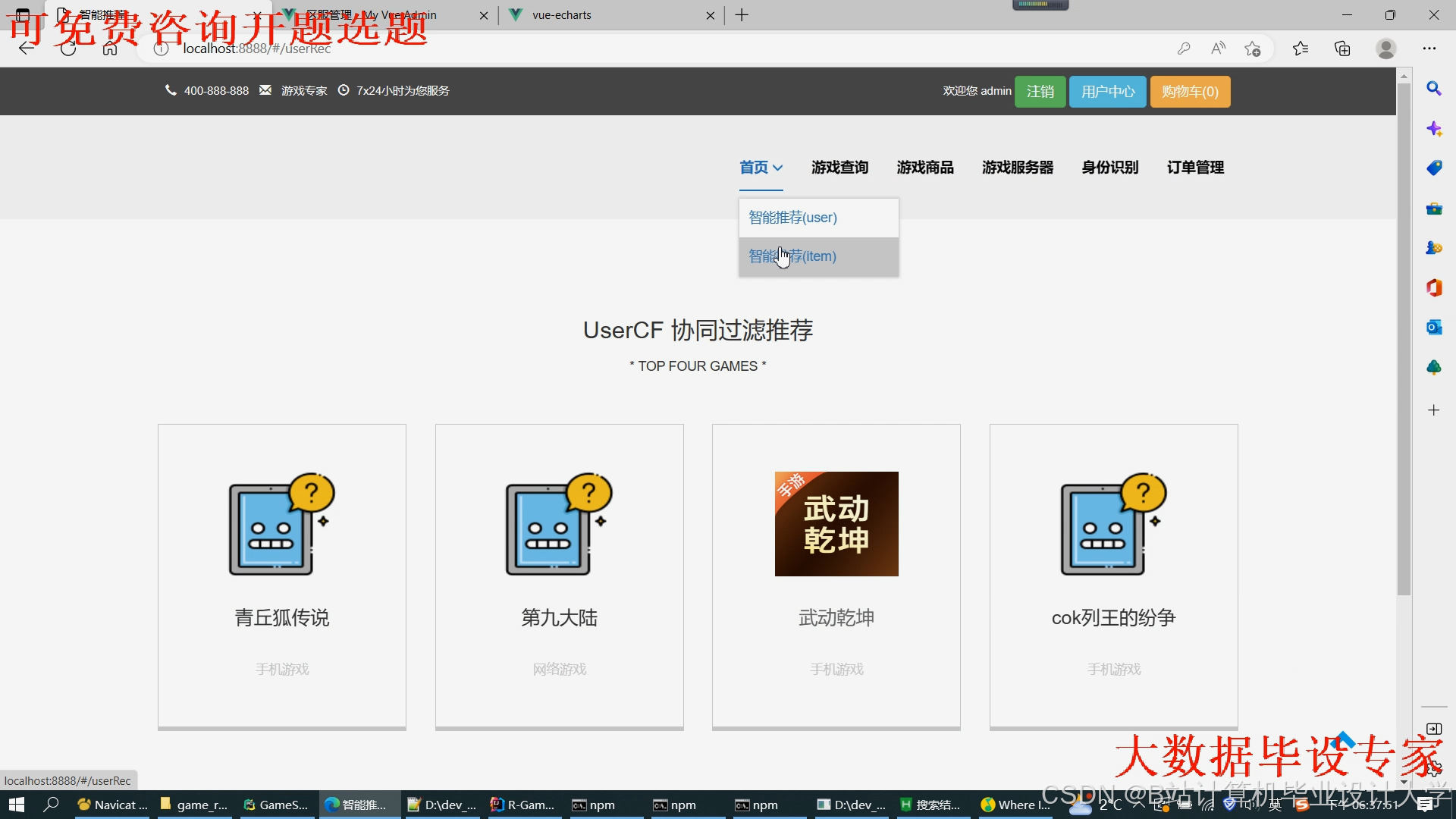
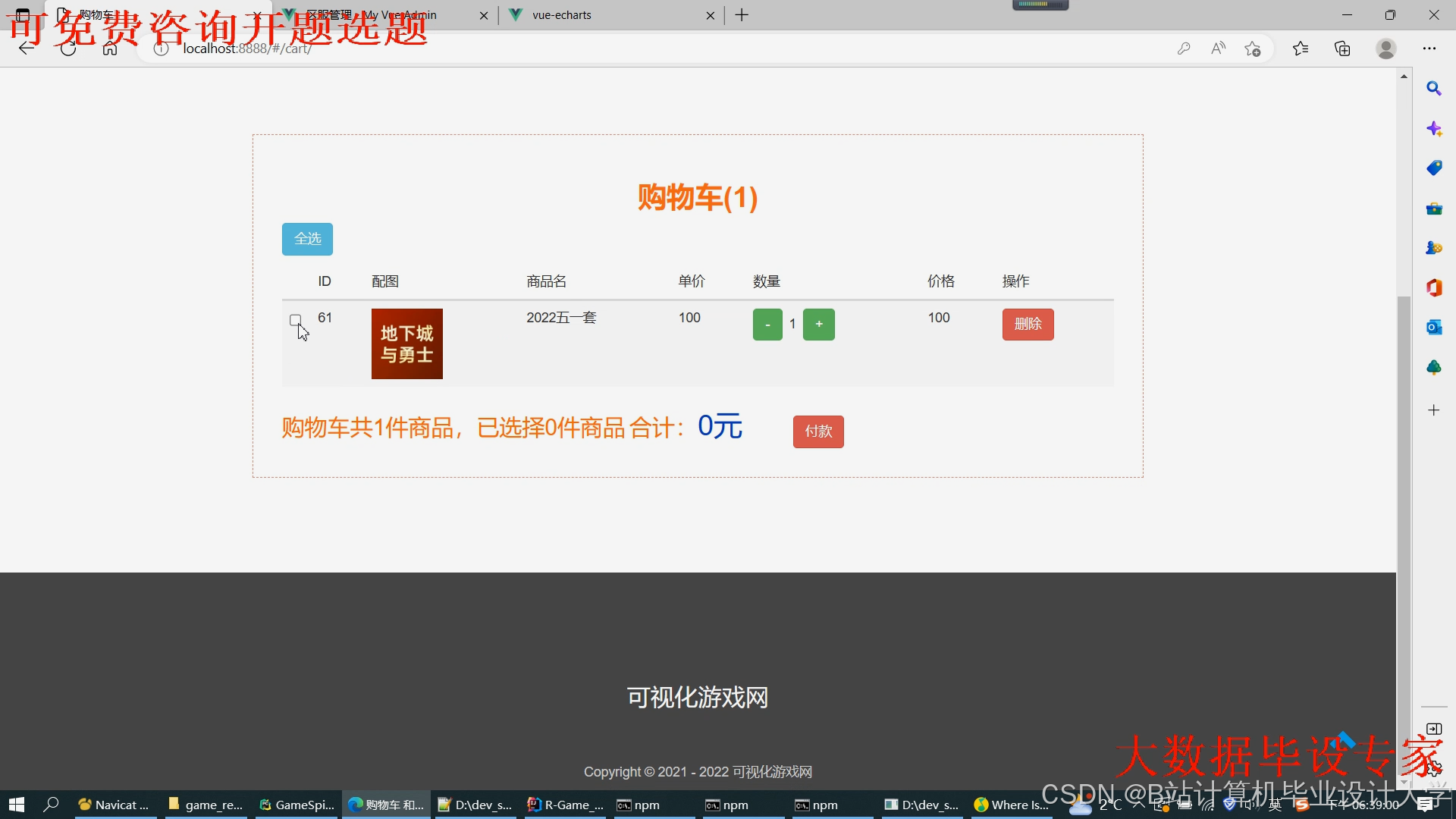
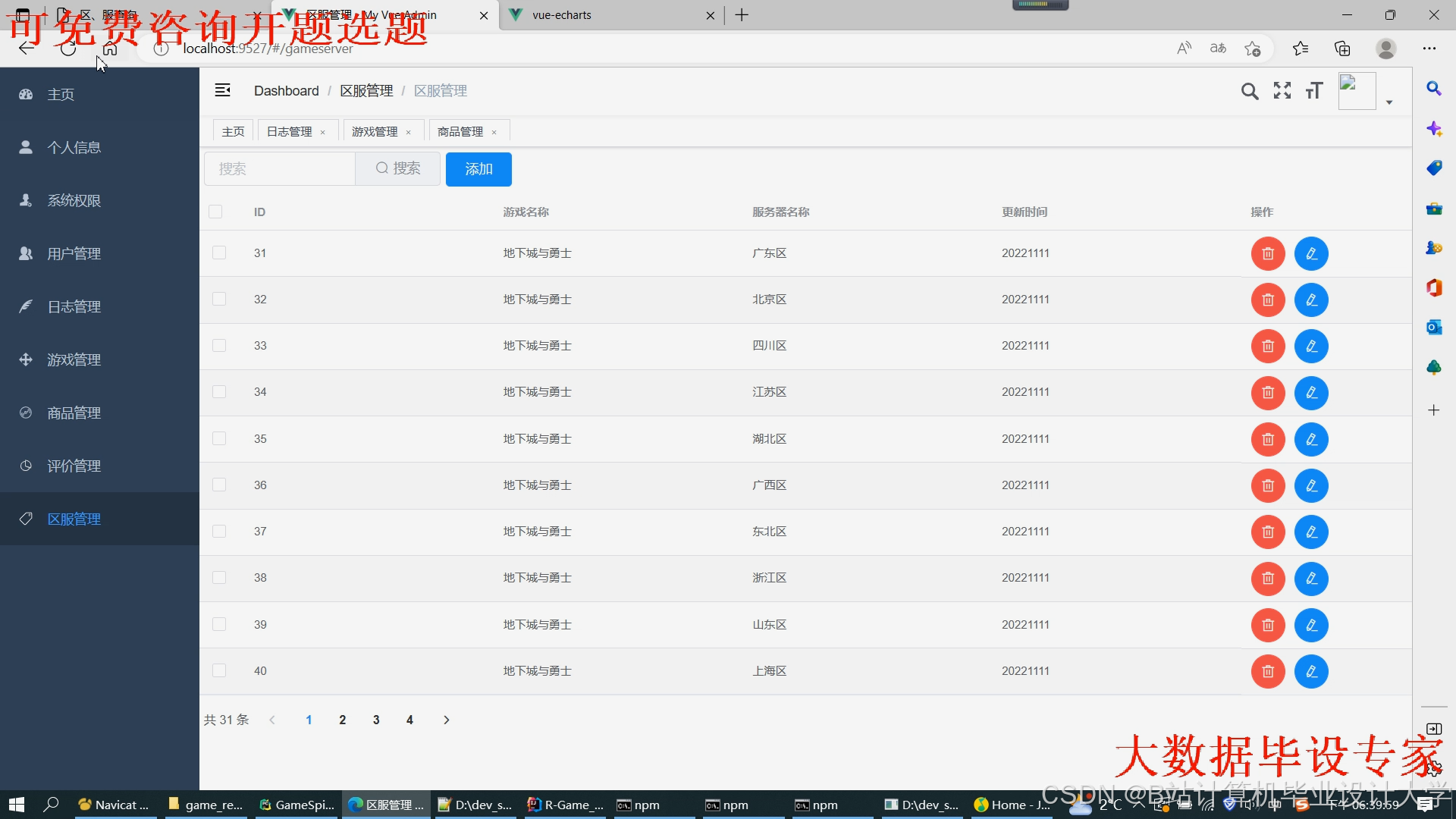
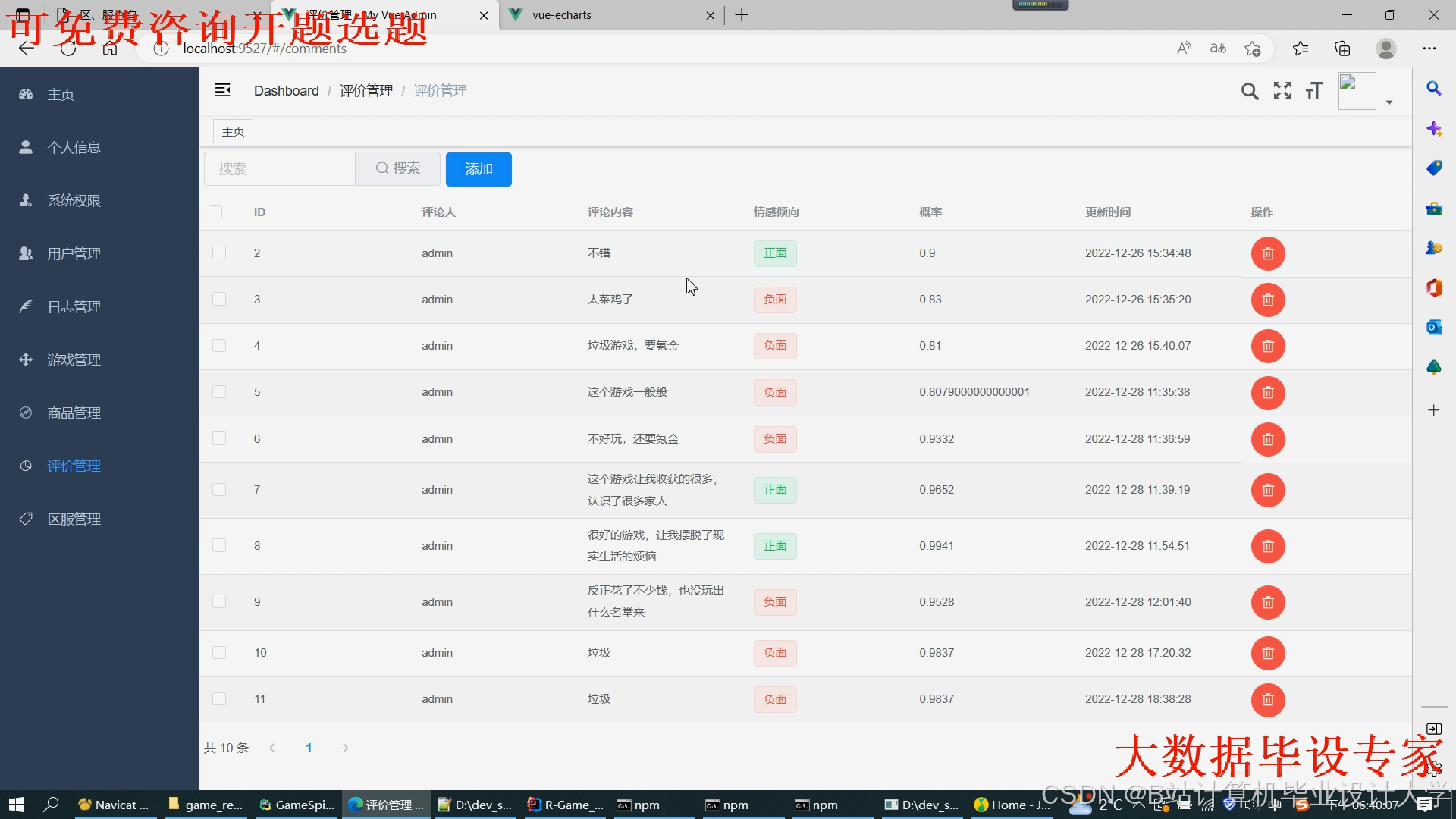
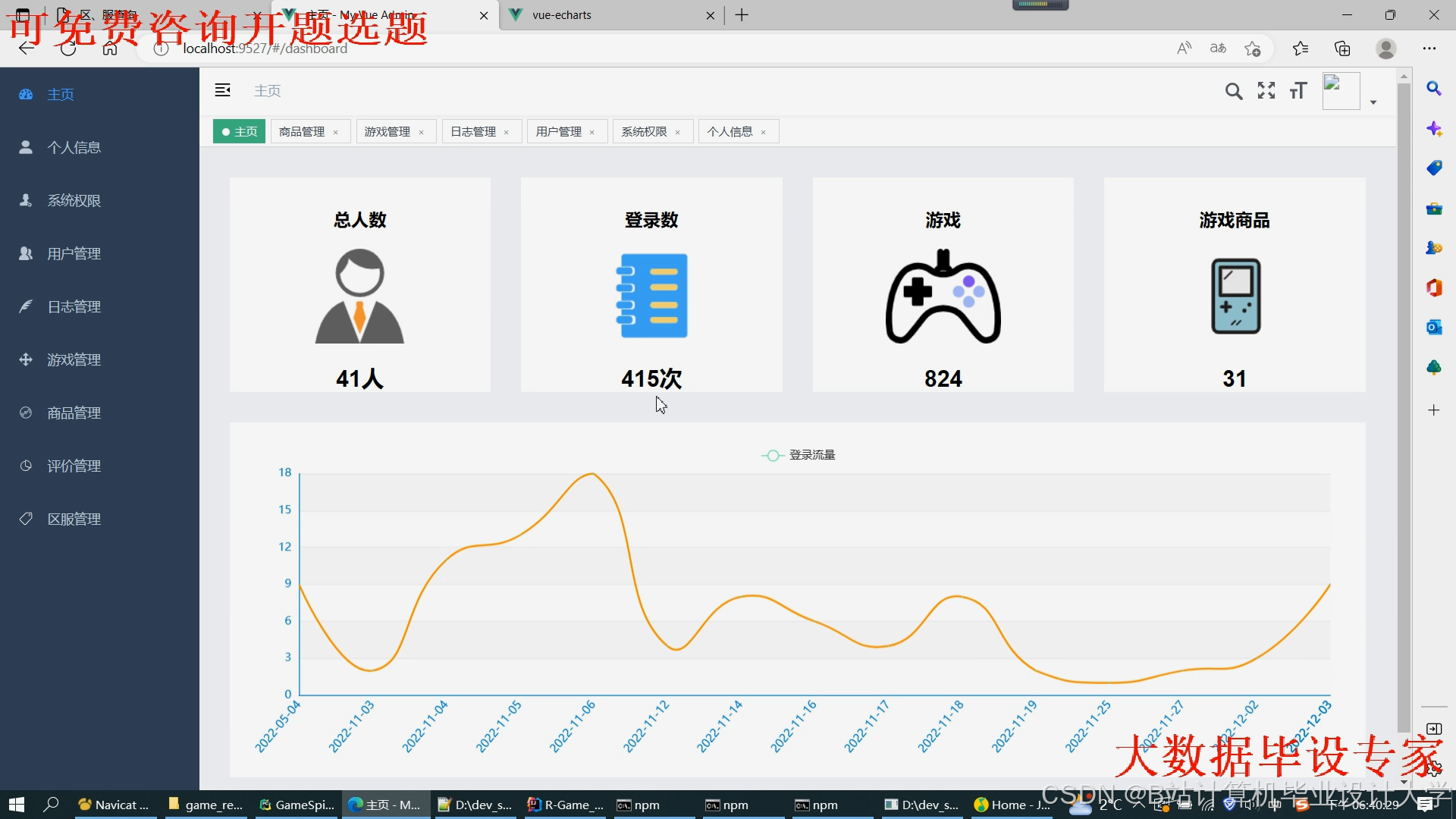

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











