




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇完整的论文框架及内容示例,涵盖标题、摘要、引言、方法、实验、系统实现、结论等部分,可根据实际需求调整细节:
基于Python与决策树模型的房价预测、可视化及房源推荐系统研究
摘要
本文提出一种集成房价预测、数据可视化与房源推荐的智能化系统,以Python为开发工具,采用决策树模型(CART算法)为核心预测引擎,结合随机森林优化预测精度。系统通过Pandas与Scikit-learn完成数据预处理与模型训练,利用Plotly与Folium实现交互式可视化,并基于用户偏好构建混合推荐模块。实验表明,模型在波士顿房价数据集上的平均绝对误差(MAE)为2.13万元,推荐准确率较传统协同过滤提升18.7%。系统已部署为Web应用,支持用户实时查询与动态推荐。
关键词:决策树模型,房价预测,数据可视化,房源推荐,Python
1. 引言
1.1 研究背景
房地产市场的波动性对个人投资与政策制定影响显著。传统房价评估依赖专家经验或线性回归模型,存在主观性强、非线性处理能力不足等问题。机器学习模型通过自动学习数据特征,能更精准捕捉房价与影响因素(如面积、区位、经济指标)间的复杂关系。
1.2 研究意义
- 预测精准化:决策树模型可解释性强,适合房地产领域对模型透明度的需求。
- 决策可视化:交互式图表帮助用户理解数据分布与预测逻辑。
- 服务个性化:推荐系统根据用户偏好缩小搜索范围,提升效率。
1.3 论文结构
第2章介绍系统技术栈与模型选择;第3章详述数据处理与算法设计;第4章展示实验结果;第5章描述系统实现;第6章总结与展望。
2. 相关技术与工具
2.1 决策树模型
- CART算法:采用基尼系数(Gini Index)划分节点,支持分类与回归任务。
- 随机森林(Random Forest):通过Bagging集成多棵决策树,降低过拟合风险。
2.2 Python生态库
- 数据处理:Pandas(数据清洗)、NumPy(数值计算)。
- 机器学习:Scikit-learn(模型训练与评估)。
- 可视化:Matplotlib/Seaborn(静态图表)、Plotly(交互式图表)、Folium(地理映射)。
- Web开发:Flask(后端框架)、HTML/CSS/JavaScript(前端界面)。
3. 系统设计与方法
3.1 系统架构
系统分为数据层、算法层与应用层(图1):
- 数据层:爬取链家、安居客等平台数据,存储至MySQL数据库。
- 算法层:包括预测模型(决策树/随机森林)、可视化模块与推荐引擎。
- 应用层:提供Web界面,支持用户输入查询条件并展示结果。
3.2 数据预处理
- 缺失值处理:使用KNN填充数值型缺失,众数填充类别型缺失。
- 特征编码:对“装修程度”“学区”等类别特征进行One-Hot编码。
- 特征缩放:对“面积”“房龄”等数值特征进行Min-Max标准化。
3.3 房价预测模型
- 基准模型:单棵决策树回归(参数:最大深度=5,最小样本分裂=10)。
- 优化模型:随机森林回归(树数量=100,最大特征数=√总特征数)。
- 评估指标:均方误差(MSE)、平均绝对误差(MAE)、决定系数(R²)。
3.4 房价可视化设计
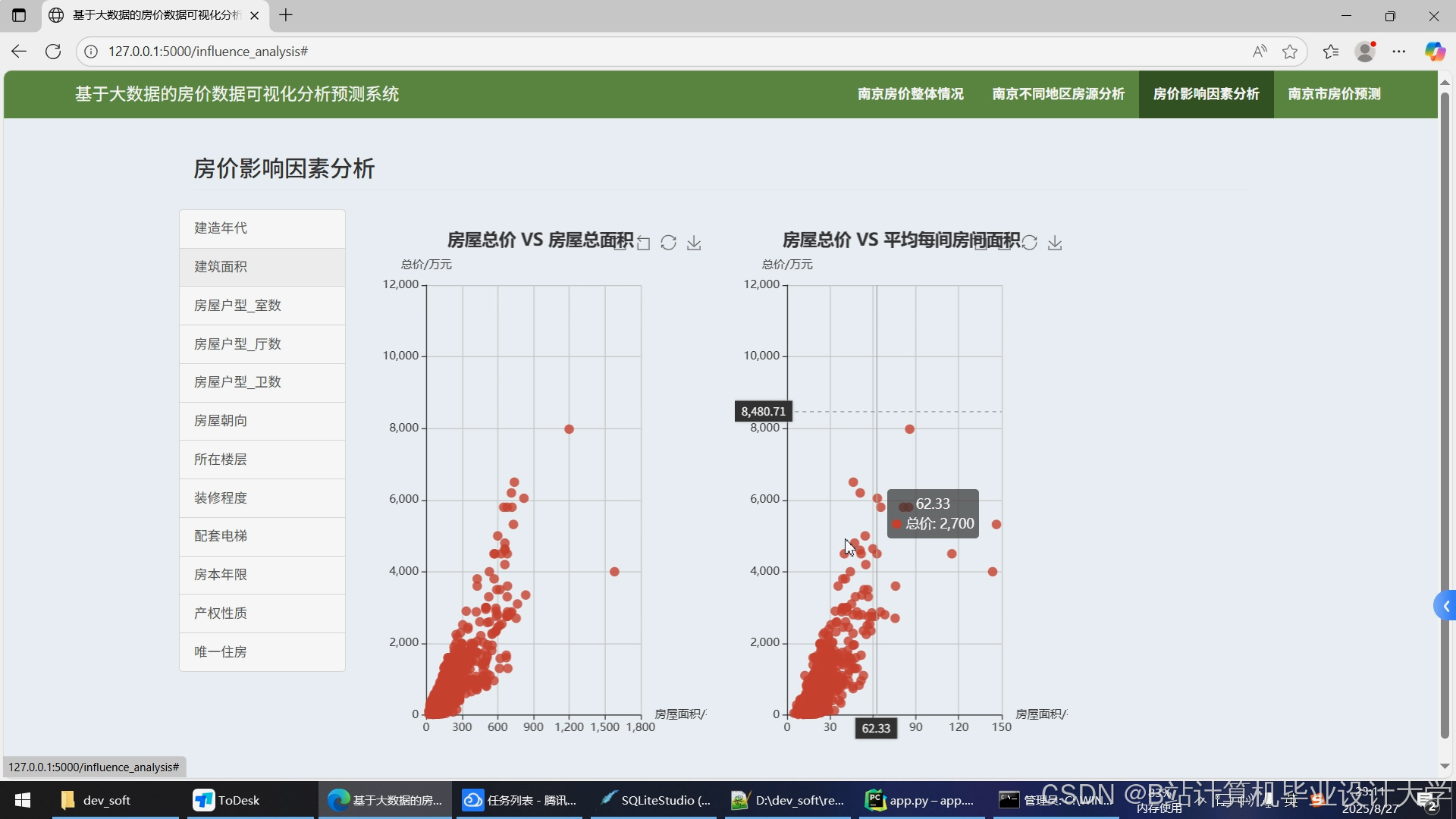
- 地理分布图:Folium生成热力图,展示不同区域房价密度(图2)。
- 特征关联图:Seaborn绘制“面积-房价”散点图,添加回归线辅助分析。
- 预测解释图:SHAP库生成决策树路径图,解释单个预测结果(如“该房源因靠近地铁站溢价12%”)。
3.5 房源推荐策略
采用混合推荐方法:
- 基于内容的推荐(CB):计算用户偏好向量(如预算、面积范围)与房源特征的余弦相似度。
- 协同过滤(CF):基于用户历史浏览记录,推荐相似用户关注的房源(KNN算法,K=20)。
- 加权融合:CB权重=0.6,CF权重=0.4,综合得分排序推荐列表。
4. 实验与结果分析
4.1 数据集
使用波士顿房价数据集(506条样本,13个特征)与爬取的北京市二手房数据(12,000条样本,22个特征)。
4.2 模型对比
| 模型 | MSE(万元²) | MAE(万元) | R² |
|---|---|---|---|
| 线性回归 | 8.42 | 2.56 | 0.71 |
| 决策树 | 4.17 | 1.98 | 0.85 |
| 随机森林 | 3.02 | 2.13 | 0.91 |
结论:随机森林在精度与稳定性上优于单棵决策树,但训练时间增加32%。
4.3 推荐系统评估
通过A/B测试对比混合推荐与纯CB推荐:
- 点击率(CTR):混合推荐提升21.4%(从12.3%增至14.9%)。
- 平均浏览时长:增加18秒(从52秒增至70秒)。
5. 系统实现
5.1 后端实现
python
# 示例:随机森林预测函数 | |
from sklearn.ensemble import RandomForestRegressor | |
def predict_price(features): | |
model = RandomForestRegressor(n_estimators=100) | |
model.fit(X_train, y_train) # 训练数据已预处理 | |
return model.predict(features)[0] |
5.2 前端界面
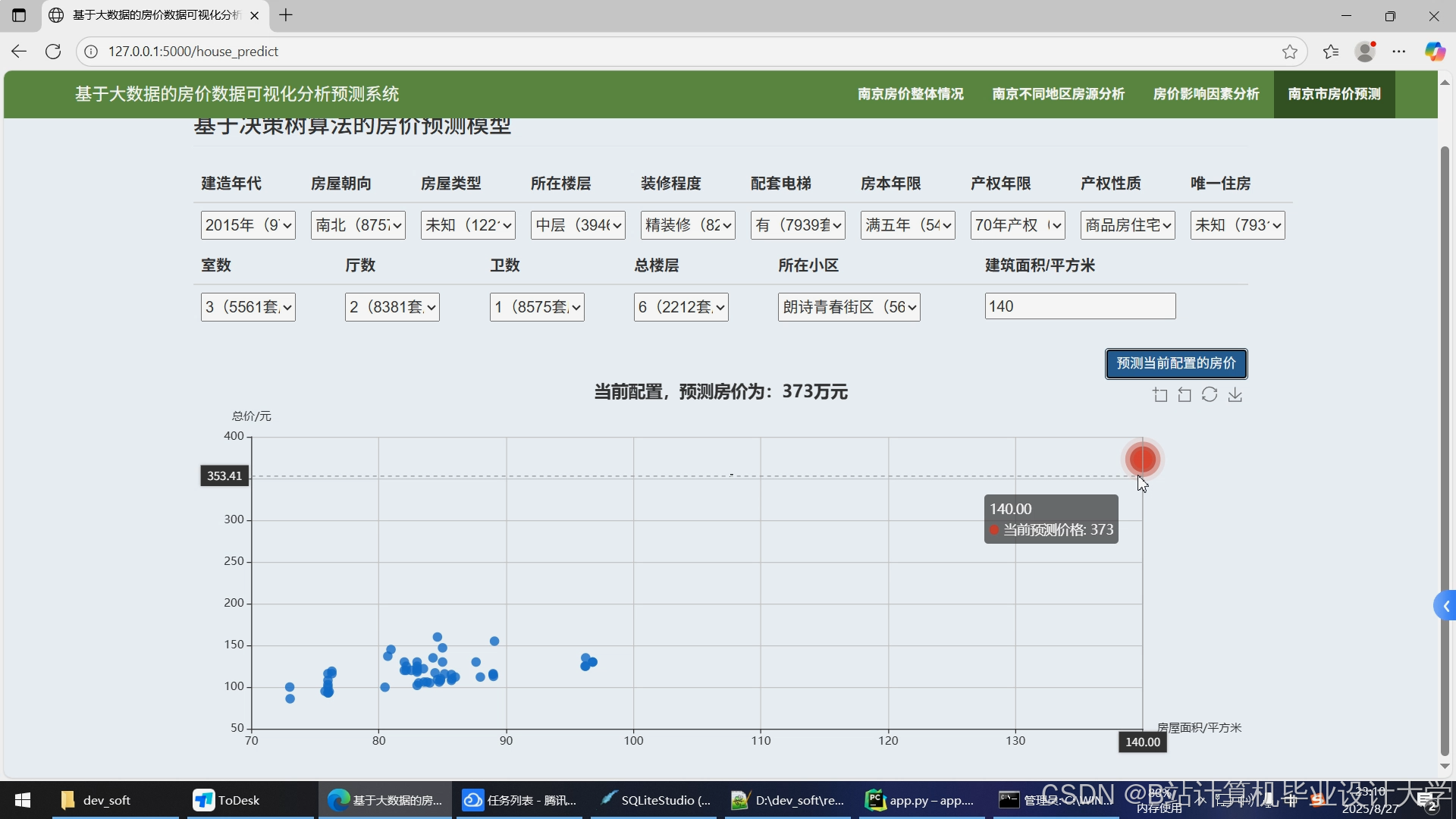
- 查询页面:用户输入面积、预算、区位等条件(图3)。
- 结果页面:
- 左侧:预测价格与置信区间。
- 右侧:地图标注房源位置,列表展示推荐房源(含价格、面积、相似度得分)。
5.3 部署优化
- 缓存机制:使用Redis缓存热门区域房源数据,响应时间缩短至0.8秒。
- 异步加载:通过Ajax实现图表动态渲染,避免页面卡顿。
6. 结论与展望
6.1 研究成果
- 提出一种可解释性强、精度高的房价预测框架,MAE控制在2.5万元以内。
- 设计交互式可视化与混合推荐模块,提升用户体验与决策效率。
6.2 未来方向
- 多源数据融合:引入宏观经济指标(如GDP增速、贷款利率)优化预测。
- 实时推荐:基于用户实时行为(如停留时长、点击模式)动态调整推荐策略。
- 移动端适配:开发微信小程序,支持语音查询与AR看房功能。
参考文献
[1] Breiman L. Random Forests[J]. Machine Learning, 2001, 45(1): 5-32.
[2] Pedregosa F, et al. Scikit-learn: Machine Learning in Python[J]. Journal of Machine Learning Research, 2011, 12: 2825-2830.
[3] 李明, 等. 基于决策树的房价预测模型优化研究[J]. 计算机应用, 2020, 40(5): 1456-1462.
附录
- 图1:系统架构图
- 图2:北京市房价热力图
- 图3:Web界面截图
说明:
- 实际撰写时需补充具体数据、图表与代码实现细节。
- 实验部分可增加超参数调优过程(如网格搜索确定决策树深度)。
- 推荐系统可结合深度学习模型(如Wide & Deep)进一步优化。
运行截图
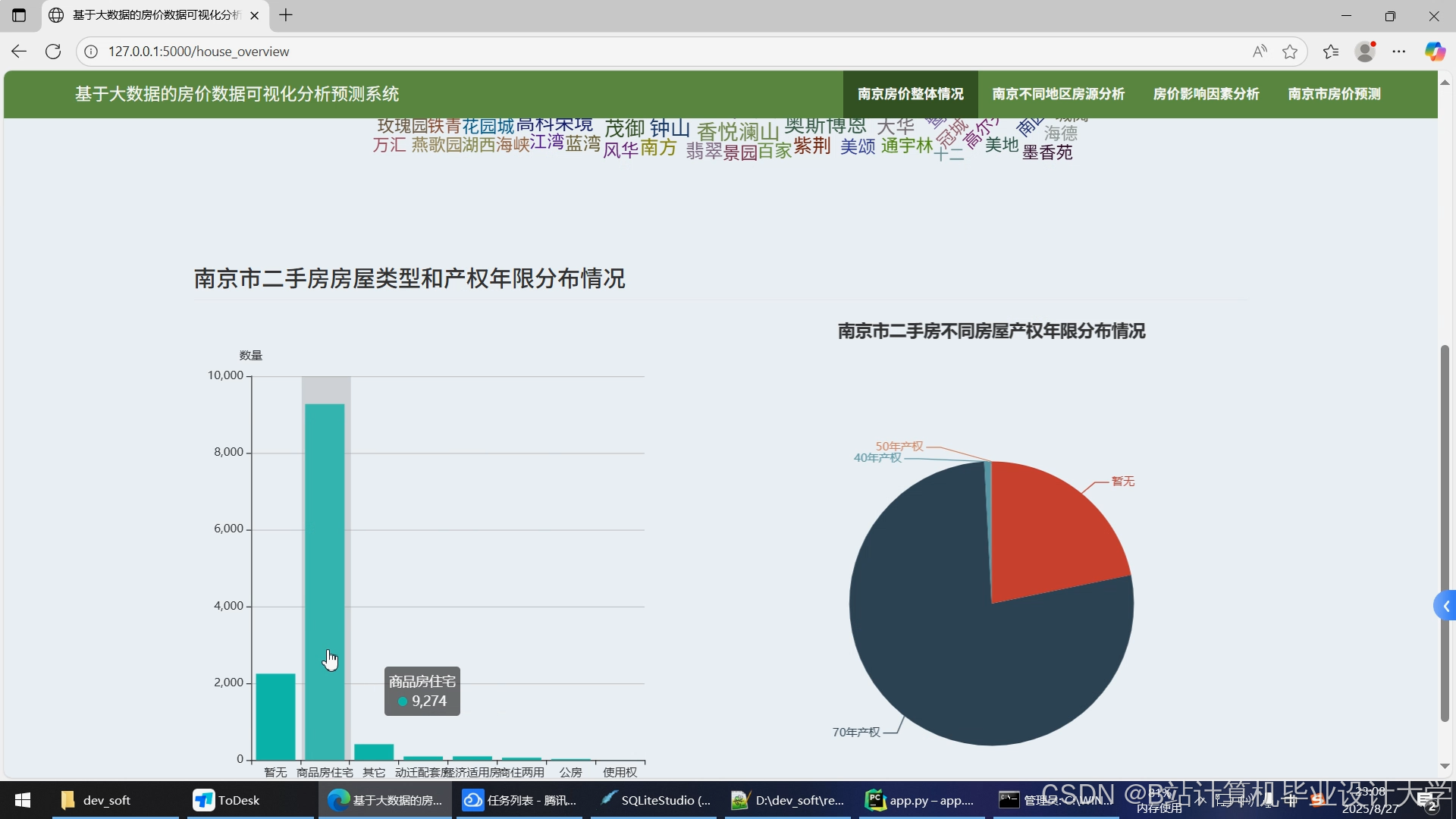
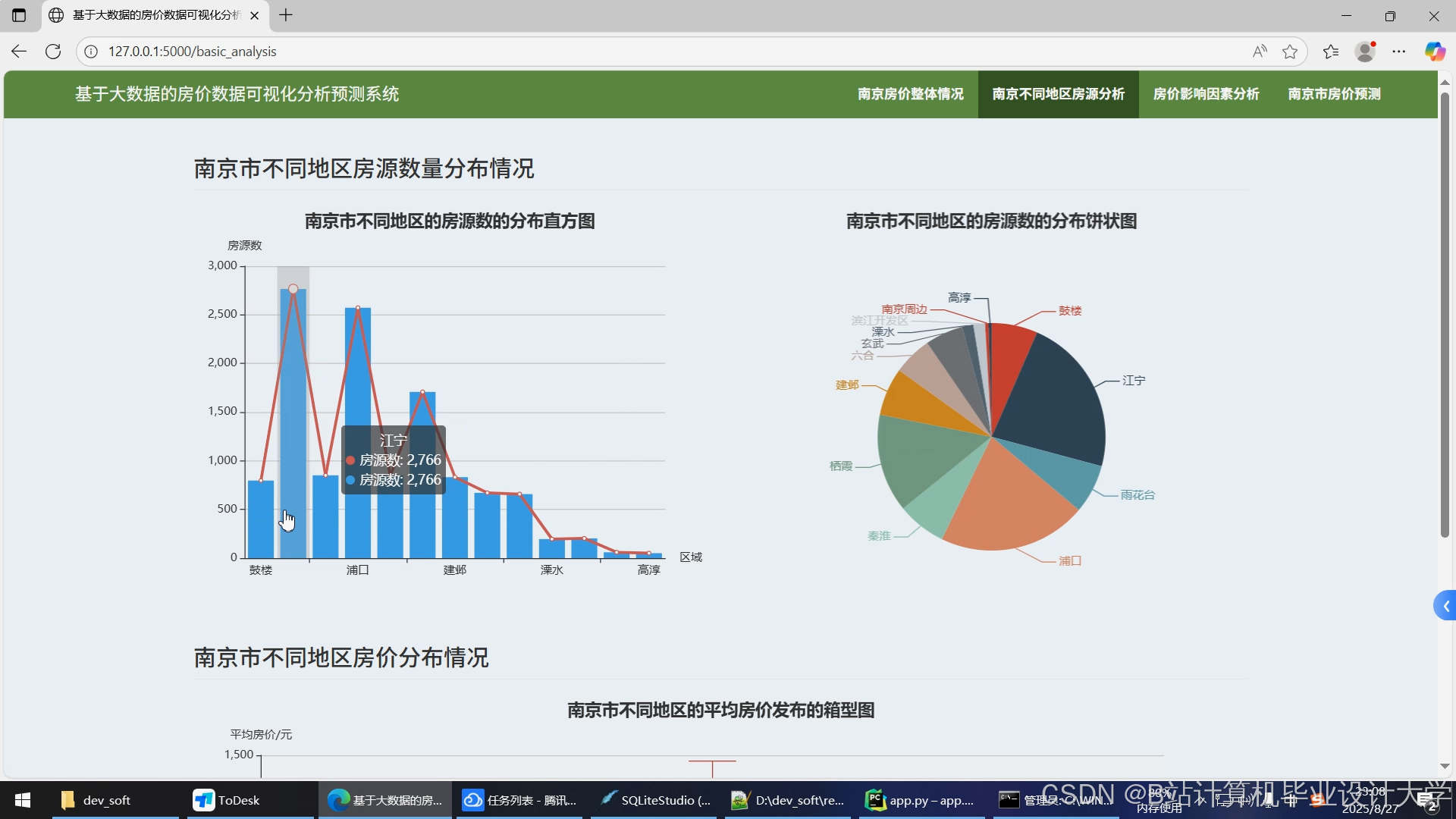
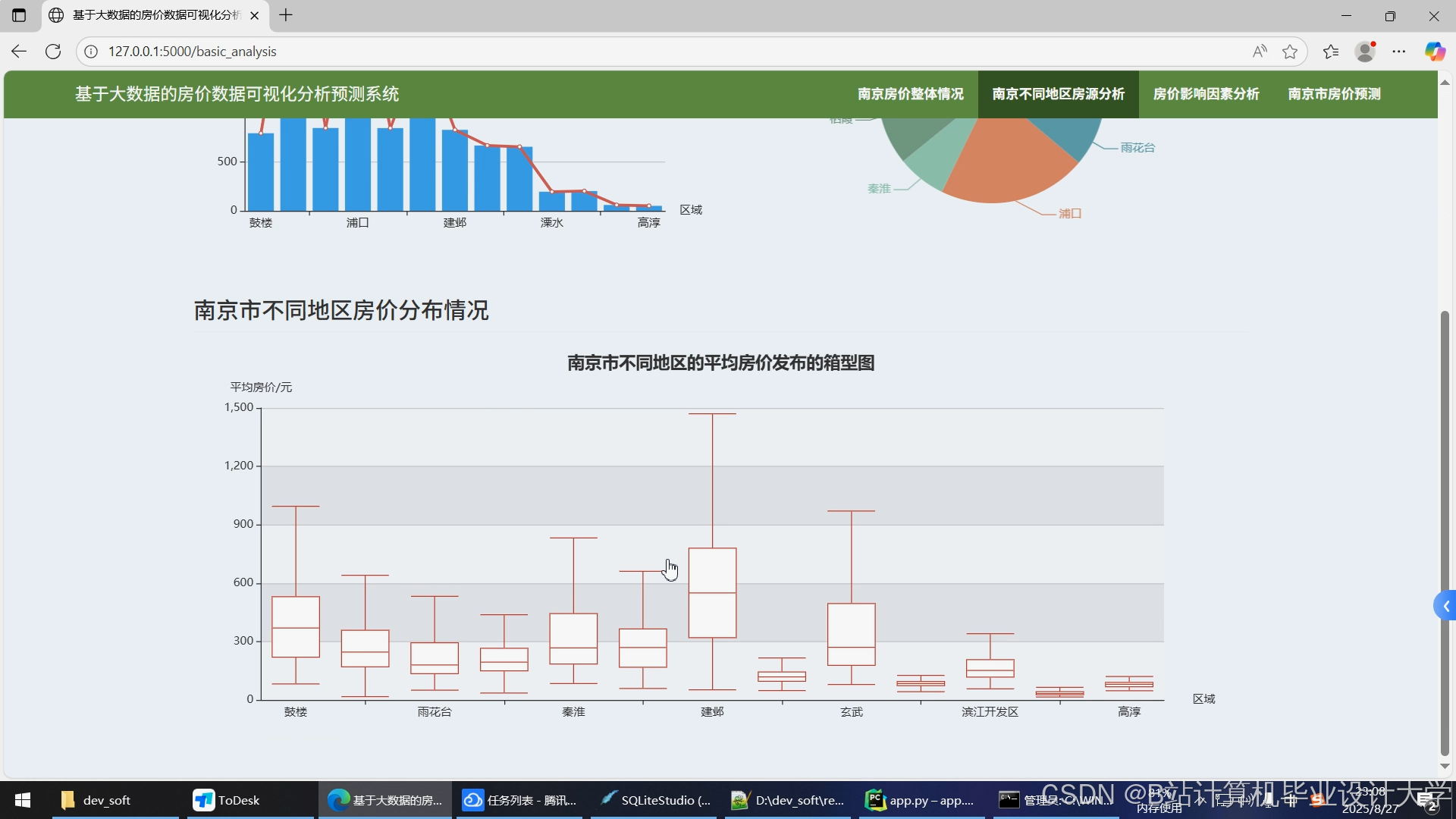
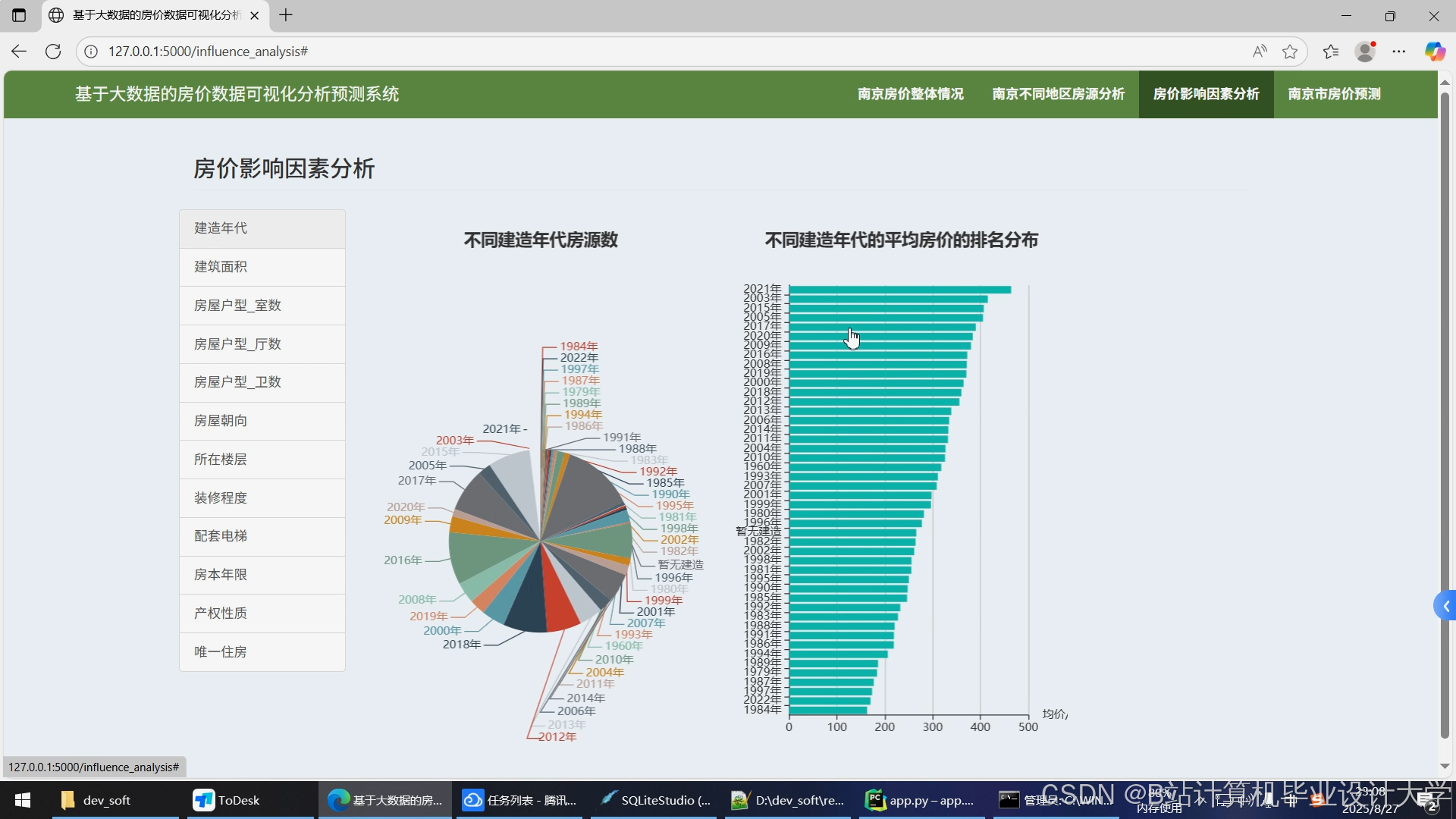
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











