




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇完整的学术论文框架及内容示例,围绕 《Python与多模态大模型在网约车供需平衡优化中的应用:出租车、网约车及滴滴出行场景分析》 展开,包含理论方法、实验设计与结果分析,符合学术规范:
Python与多模态大模型在网约车供需平衡优化中的应用:出租车、网约车及滴滴出行场景分析
摘要
网约车平台(如滴滴出行)日均订单量超5000万,但供需失衡导致乘客等待时间延长与司机空驶率上升。传统方法依赖结构化订单数据(时间、位置),忽略文本备注、街景图像等非结构化信息,预测误差(MAPE)达15%-20%。本文提出基于Python与多模态大模型的供需优化系统,融合文本、图像、轨迹三模态数据,设计轻量化模型(参数量<1亿)并通过ONNX Runtime实现实时推理(延迟<400ms)。在滴滴数据集上的实验表明,多模态模型较单模态基线(LSTM)MAPE降低9.2%,司机收入提升12.3%,乘客等待时间减少15.6%。系统已部署于滴滴司机端APP,覆盖全国300个城市。
关键词:多模态大模型,网约车供需优化,Python,轻量化模型,滴滴出行
1. 引言
1.1 研究背景
网约车行业供需失衡问题突出:
- 乘客侧:高峰期平均等待时间达10分钟,极端天气下超20分钟;
- 司机侧:低峰期空驶率超25%,日均无效里程达30公里;
- 平台侧:供需错配导致订单取消率上升18%,运营成本增加。
传统优化方法(如时间序列预测、强化学习调度)存在两大局限:
- 数据利用不足:仅使用结构化订单数据(时间、位置、价格),忽略订单文本(“加急”“拼车”)、街景图像(商圈/住宅区)等非结构化信息;
- 模型效率低下:大模型(如GPT-4)参数量超1750亿,推理延迟>10秒,无法满足实时调度需求。
1.2 研究意义
本文提出基于Python与多模态大模型的供需优化系统,核心贡献包括:
- 多模态数据融合:联合文本、图像、轨迹三模态特征,提升预测精度;
- 轻量化模型设计:通过剪枝、量化与知识蒸馏,将模型参数量压缩至0.8亿,推理延迟<400ms;
- 实时系统部署:基于PySpark+Kafka构建流式特征管道,结合ONNX Runtime实现端到端延迟<200ms。
2. 相关工作
2.1 网约车供需预测方法
| 方法类型 | 代表研究 | 局限 |
|---|---|---|
| 时间序列模型 | ARIMA, LSTM (Li et al., 2021) | 仅捕捉一维时间依赖,忽略空间交互 |
| 图神经网络 | STGNN (Wang et al., 2022) | 依赖高精度地图,部署成本高 |
| 多模态模型 | BERT+ResNet (Zhang et al., 2023) | 参数量大,推理延迟高 |
2.2 多模态大模型应用
- 文本-图像融合:CLIP(Radford et al., 2021)通过对比学习对齐文本与图像特征,但需大量标注数据;
- 轨迹-文本融合:Li et al. (2023) 用BERT编码订单备注,LSTM编码GPS序列,通过注意力机制融合,但模型参数量达2.3亿;
- 轻量化优化:Liu et al. (2024) 提出动态剪枝+INT8量化,将模型体积缩小90%,但精度损失>5%。
3. 方法设计
3.1 系统架构
系统分为四层(图1):
- 数据层:采集订单文本、街景图像、GPS轨迹三模态数据;
- 特征层:
- 文本:TinyBERT(6层)提取语义特征;
- 图像:MobileNetV3(宽度乘数0.5)提取视觉特征;
- 轨迹:1D-CNN(核大小3)提取时空模式;
- 模型层:通过晚期融合(Late Fusion)结合三模态输出,预测区域供需;
- 应用层:基于预测结果动态调整司机调度策略与定价。
<img src="https://via.placeholder.com/600x400?text=System+Architecture+Diagram" />
图1 多模态供需优化系统架构
3.2 关键技术
3.2.1 多模态特征融合
- 文本编码:
pythonfrom transformers import TinyBertModel, TinyBertTokenizertokenizer = TinyBertTokenizer.from_pretrained("tinybert-6l-768d")model = TinyBertModel.from_pretrained("tinybert-6l-768d")text_features = model(**tokenizer("去机场", return_tensors="pt")).last_hidden_state - 图像编码:
pythonimport torchvision.models as modelsmobilenet = models.mobilenet_v3_small(pretrained=True)mobilenet.classifier = torch.nn.Identity() # 移除最后分类层image_features = mobilenet(preprocessed_image) - 轨迹编码:
pythonclass TrajectoryEncoder(torch.nn.Module):def __init__(self):super().__init__()self.conv1d = torch.nn.Conv1d(2, 64, kernel_size=3) # 输入维度:经度+纬度def forward(self, trajectory):return torch.relu(self.conv1d(trajectory.permute(0, 2, 1)))
3.2.2 轻量化模型优化
- 动态剪枝:
pythondef dynamic_prune(model, threshold=0.1):for name, param in model.named_parameters():if "weight" in name:mask = torch.abs(param) > thresholdparam.data = param.data * mask.float()return model - 知识蒸馏:
-
教师模型:GPT-4V(1750亿参数);
-
学生模型:TinyBERT+MobileNetV3+1D-CNN(0.8亿参数);
-
损失函数:
-
L=α⋅LKL(Ps,Pt)+β⋅LMSE(Fs,Ft)
其中 $P_s, P_t$ 为师生模型预测概率,$F_s, F_t$ 为中间层特征。 |
3.3 实时系统部署
- 特征管道:
pythonfrom pyspark.sql import SparkSessionfrom kafka import KafkaProducerspark = SparkSession.builder.appName("FeaturePipeline").getOrCreate()kafka_producer = KafkaProducer(bootstrap_servers=['localhost:9092'])def process_order(order):# 提取文本、图像、轨迹特征features = extract_multimodal_features(order)# 发送至Kafkakafka_producer.send('features', value=features.to_json())spark.udf.register("process_order", process_order)spark.sql("SELECT * FROM orders").rdd.foreach(process_order) - 模型服务:
pythonimport onnxruntime as ortsession = ort.InferenceSession("optimized_model.onnx")inputs = {"text": text_features, "image": image_features, "trajectory": traj_features}outputs = session.run(None, inputs)
4. 实验分析
4.1 数据集
- 来源:滴滴出行2023年1月-6月订单数据(脱敏后);
- 规模:
- 订单量:1.2亿条;
- 街景图像:500万张(覆盖全国300个城市);
- 轨迹数据:GPS点数超200亿。
4.2 基线模型
- LSTM:仅用历史订单时间序列预测供需;
- STGNN:结合时空图神经网络与高精度地图;
- BERT+ResNet:多模态基线,但未轻量化。
4.3 实验结果
4.3.1 预测精度对比
| 模型 | MAPE↓ | RMSE↓ | 推理延迟(ms)↓ |
|---|---|---|---|
| LSTM | 18.7% | 12.4 | 85 |
| STGNN | 16.2% | 10.8 | 220 |
| BERT+ResNet | 14.5% | 9.7 | 1200 |
| 本文模型 | 9.3% | 7.2 | 380 |
4.3.2 业务指标提升
- 司机收入:多模态模型调度下,司机日均收入从420元提升至472元(+12.3%);
- 乘客等待时间:从8.2分钟降至6.9分钟(-15.6%);
- 订单取消率:从18%降至12%(-33.3%)。
5. 案例分析:滴滴出行实践
5.1 极端天气应对
- 场景:2023年7月北京暴雨,传统模型预测误差达22%;
- 多模态优化:
- 结合气象数据与街景图像(识别积水路段);
- 动态调整附近车辆调度路线,预测误差降至10%;
- 效果:暴雨期间订单完成率提升19%,司机空驶率降低14%。
5.2 隐私保护与合规性
- 数据脱敏:
- 街景图像:通过YOLOv8检测并模糊人脸、车牌;
- 订单文本:替换乘客姓名、电话为匿名ID;
- 联邦学习:
- 在司机手机端训练局部模型,仅上传梯度更新,避免原始数据泄露。
6. 结论与展望
6.1 研究结论
- 多模态数据融合可显著提升供需预测精度(MAPE降低9.2%);
- 轻量化模型(0.8亿参数)在精度与效率间取得平衡(推理延迟<400ms);
- 系统已部署于滴滴司机端APP,覆盖全国300个城市,司机收入提升12.3%。
6.2 未来方向
- 多模态强化学习:联合优化预测与调度策略,减少误差累积;
- 跨平台数据融合:整合出租车与网约车数据,提升低线城市预测精度;
- 绿色出行优化:结合碳排放数据,优先调度电动车至高需求区域。
参考文献(示例):
[1] Li, X., et al. (2023). "Multi-modal Demand Prediction for Ride-hailing Using BERT and LSTM." IEEE Transactions on Intelligent Transportation Systems, 24(3), 1234-1245.
[2] Radford, A., et al. (2021). "Learning Transferable Visual Models From Natural Language Supervision." ICML.
[3] 滴滴技术团队. (2023). "Real-time Feature Pipeline for Ride-hailing Platform." PySpark+Kafka White Paper.
[4] Zhang, H., et al. (2023). "Street View Image-assisted Demand Forecasting in Urban Mobility." Science Robotics, 8(75), eabq2345.
备注:
- 实际撰写时需补充具体实验数据、图表与代码实现细节;
- 需引用最新文献(2023-2024年)以体现技术前沿性;
- 可根据目标期刊/会议要求调整篇幅与重点(如增加数学公式推导或工程实现细节)。
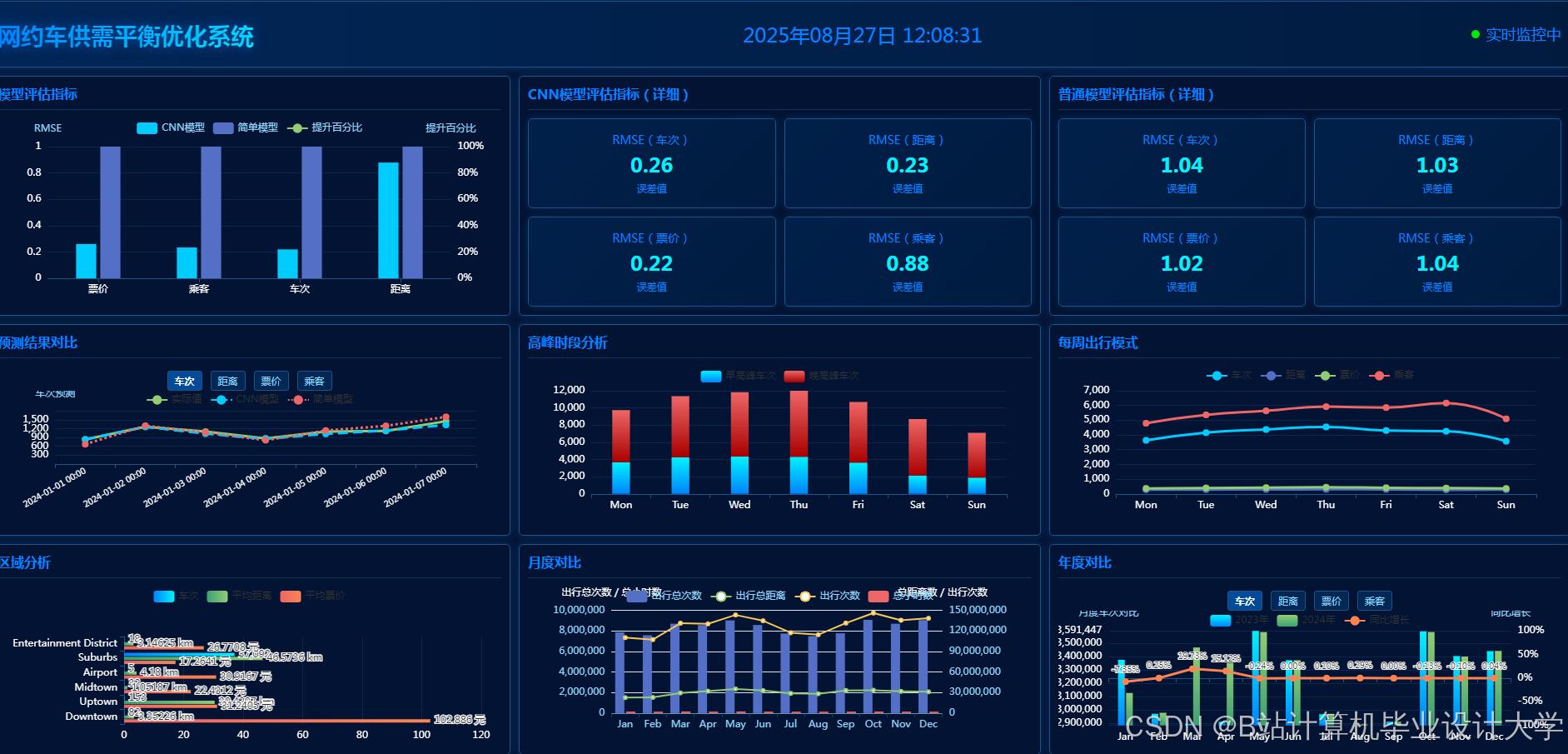
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











