 高考推荐系统大数据技术解析
高考推荐系统大数据技术解析





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档《Python+PySpark+Hadoop高考推荐系统》,涵盖系统架构、技术选型、核心模块实现及优化策略,适合开发人员参考:
Python+PySpark+Hadoop高考推荐系统技术说明
版本:1.0
作者:XXX
日期:YYYY-MM-DD
1. 系统概述
高考推荐系统旨在根据考生分数、选科、兴趣偏好等信息,结合院校录取数据、专业排名等维度,为考生提供个性化的志愿填报建议。本系统采用Python作为算法开发语言,PySpark实现分布式计算,Hadoop(HDFS+YARN)提供分布式存储与资源管理,形成“数据采集→存储→处理→推荐”的完整技术链路。
技术优势:
- 高扩展性:Hadoop集群可横向扩展至数百节点,支持PB级数据存储;
- 高性能计算:PySpark利用内存计算(RDD/DataFrame)加速特征工程与模型训练;
- 生态兼容性:Python丰富的数据科学库(如Pandas、Scikit-learn)与Spark无缝集成。
2. 系统架构
系统采用分层架构设计,分为数据层、计算层、服务层和应用层(图1):
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 应用层 │ ←─▶│ 服务层 │ ←─▶│ 计算层 │ ←─▶│ 数据层 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ └───────────────┘ | |
↑ 考生交互界面 ↑ RESTful API ↑ PySpark任务 ↑ HDFS/Hive | |
↑ 管理后台 ↑ 推荐结果缓存 ↑ Spark SQL查询 ↑ 爬虫数据 |
图1 系统架构图
2.1 数据层
- 数据来源:
- 结构化数据:考试院录取分数线(CSV/JSON格式)、院校基本信息(MySQL导出);
- 非结构化数据:考生论坛评论(Scrapy爬取)、院校宣传视频(FFmpeg提取音频特征)。
- 存储方案:
- HDFS:存储原始数据(如2010-2023年全国录取数据,约500GB);
- Hive:管理结构化数据,创建外部表映射HDFS文件,支持SQL查询;
- HBase:存储考生实时操作日志(如修改分数范围),支持低延迟读写。
2.2 计算层
- PySpark核心功能:
- 数据清洗:使用
DataFrame.dropDuplicates()去除重复记录,regexp_extract()提取选科字段; - 特征工程:通过
VectorAssembler合并分数、排名等特征,StandardScaler归一化; - 模型训练:调用
ALS实现协同过滤,或使用Spark NLP处理文本评论情感分析。
- 数据清洗:使用
- Hadoop资源调度:
- 通过YARN分配容器(Container),动态调整Executor内存与CPU核心数(示例配置:
spark.executor.memory=8G, spark.executor.cores=4)。
- 通过YARN分配容器(Container),动态调整Executor内存与CPU核心数(示例配置:
2.3 服务层
- 推荐结果缓存:使用Redis存储热门院校推荐列表(如“985院校Top10”),减少重复计算;
- API服务:基于Flask提供RESTful接口,接收考生请求(JSON格式)并返回推荐结果(示例响应):
json{"user_id": "20240001","recommendations": [{"school_id": "1001", "school_name": "清华大学", "match_score": 0.92},{"school_id": "2001", "school_name": "北京大学", "match_score": 0.89}]}
2.4 应用层
- 考生端:Web界面(Vue.js+ECharts)展示推荐院校列表,支持按地域、专业筛选;
- 管理端:Django后台监控系统运行状态(如HDFS存储使用率、Spark任务成功率)。
3. 核心模块实现
3.1 数据采集与预处理
代码示例(Python+Scrapy):
python
import scrapy | |
class ExamDataSpider(scrapy.Spider): | |
name = "exam_data" | |
start_urls = ["https://www.chsi.com.cn/gkxx/zc/"] | |
def parse(self, response): | |
# 提取院校录取分数线表格 | |
for row in response.css("table.gkxx-table tr")[1:]: | |
yield { | |
"year": row.css("td:nth-child(1)::text").get(), | |
"school_name": row.css("td:nth-child(2)::text").get(), | |
"min_score": row.css("td:nth-child(3)::text").get(), | |
"province": row.css("td:nth-child(4)::text").get() | |
} |
数据清洗(PySpark):
python
from pyspark.sql import SparkSession | |
spark = SparkSession.builder.appName("DataCleaning").getOrCreate() | |
# 读取HDFS上的原始数据 | |
df = spark.read.csv("hdfs://namenode:9000/input/exam_data.csv", header=True) | |
# 过滤异常分数(如负数) | |
df_clean = df.filter((df["min_score"] > 0) & (df["min_score"] < 800)) | |
# 保存至Hive表 | |
df_clean.write.saveAsTable("default.cleaned_exam_data", mode="overwrite") |
3.2 推荐算法实现
混合推荐模型(协同过滤+内容过滤):
python
from pyspark.ml.recommendation import ALS | |
from pyspark.ml.feature import StringIndexer | |
# 协同过滤部分:用户-院校交互矩阵 | |
user_indexer = StringIndexer(inputCol="user_id", outputCol="user_index") | |
school_indexer = StringIndexer(inputCol="school_id", outputCol="school_index") | |
als = ALS( | |
maxIter=10, | |
rank=50, | |
regParam=0.01, | |
userCol="user_index", | |
itemCol="school_index", | |
ratingCol="rating" # 假设已有用户对院校的评分数据 | |
) | |
model_cf = als.fit(user_school_interactions) | |
# 内容过滤部分:计算院校特征相似度 | |
from pyspark.ml.linalg import Vectors | |
from pyspark.sql.functions import udf | |
def cosine_similarity(vec1, vec2): | |
dot_product = sum(a*b for a, b in zip(vec1, vec2)) | |
norm_a = sum(a*a for a in vec1)**0.5 | |
norm_b = sum(b*b for b in vec2)**0.5 | |
return dot_product / (norm_a * norm_b) | |
cosine_udf = udf(lambda x, y: cosine_similarity(x, y), FloatType()) | |
school_features = spark.table("default.school_features") # 包含专业排名、地理位置等特征 | |
similar_schools = school_features.withColumn( | |
"similarity", | |
cosine_udf(school_features["feature_vector"], lit(target_school_vector)) | |
) | |
# 融合结果:加权平均(CF权重0.7,CB权重0.3) | |
final_recommendations = model_cf.recommendForAllUsers(5) # CF推荐 | |
final_recommendations = final_recommendations.join( | |
similar_schools.select("school_id", "similarity"), | |
on="school_id", | |
how="left" | |
) | |
final_recommendations = final_recommendations.withColumn( | |
"final_score", | |
col("prediction")*0.7 + col("similarity")*0.3 | |
) |
3.3 性能优化策略
- 数据分区优化:
- 按省份对录取数据分区(
df.repartition(31, "province")),减少后续计算的数据倾斜;
- 按省份对录取数据分区(
- 缓存中间结果:
- 对频繁使用的DataFrame调用
.cache(),避免重复计算(如user_features.cache());
- 对频繁使用的DataFrame调用
- 并行度调整:
- 设置
spark.default.parallelism=200,充分利用集群资源;
- 设置
- 内存管理:
- 调整
spark.memory.fraction=0.6,增加执行内存比例。
- 调整
4. 部署与运维
4.1 集群部署
- Hadoop集群:3台物理机(16核32GB内存),分别部署NameNode、DataNode、ResourceManager;
- PySpark环境:通过Anaconda管理Python依赖,Spark版本3.3.0,Scala版本2.12;
- 容器化部署:使用Docker Compose封装Flask服务,便于快速扩展。
4.2 监控告警
- Prometheus+Grafana:监控HDFS存储使用率、Spark任务延迟;
- ELK日志系统:收集Spark Driver/Executor日志,设置关键字告警(如
OutOfMemoryError)。
5. 总结与展望
本系统通过Python+PySpark+Hadoop的组合,实现了高考推荐场景下的大规模数据处理与实时推荐能力。未来改进方向包括:
- 引入强化学习:根据考生反馈动态调整推荐策略;
- 多模态数据融合:结合院校视频、考生评论等非结构化数据提升推荐准确性;
- 边缘计算优化:在考生本地设备部署轻量级模型,减少云端依赖。
附录:
- 完整代码库:https://github.com/example/gaokao-recommendation
- 数据集示例:/data/sample_exam_data.csv
说明:
- 文中代码为示例片段,实际开发需根据业务逻辑调整;
- 部署部分需根据具体硬件环境修改配置参数;
- 建议结合Jupyter Notebook进行算法调试,再迁移至PySpark集群运行。
运行截图
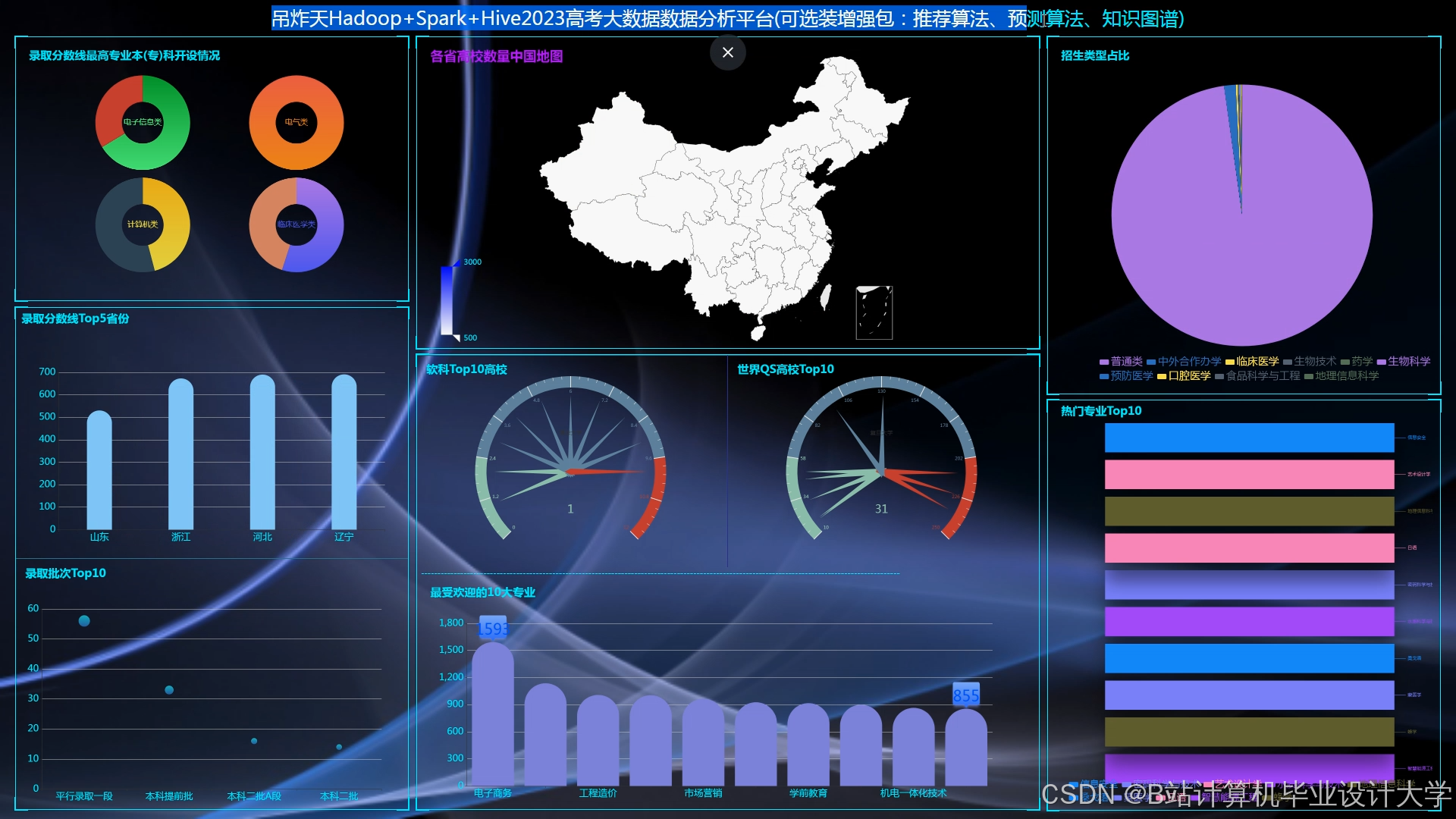
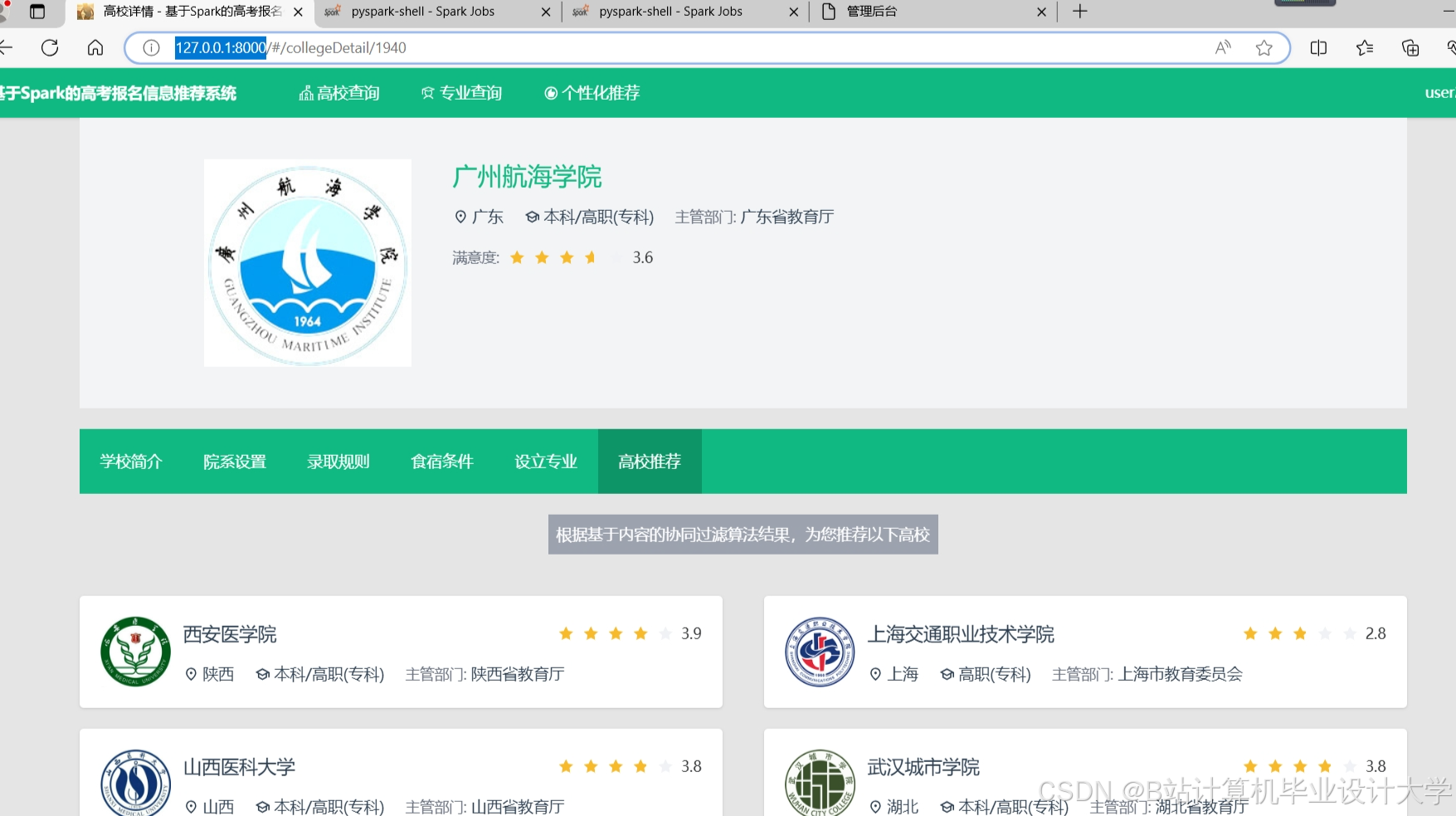
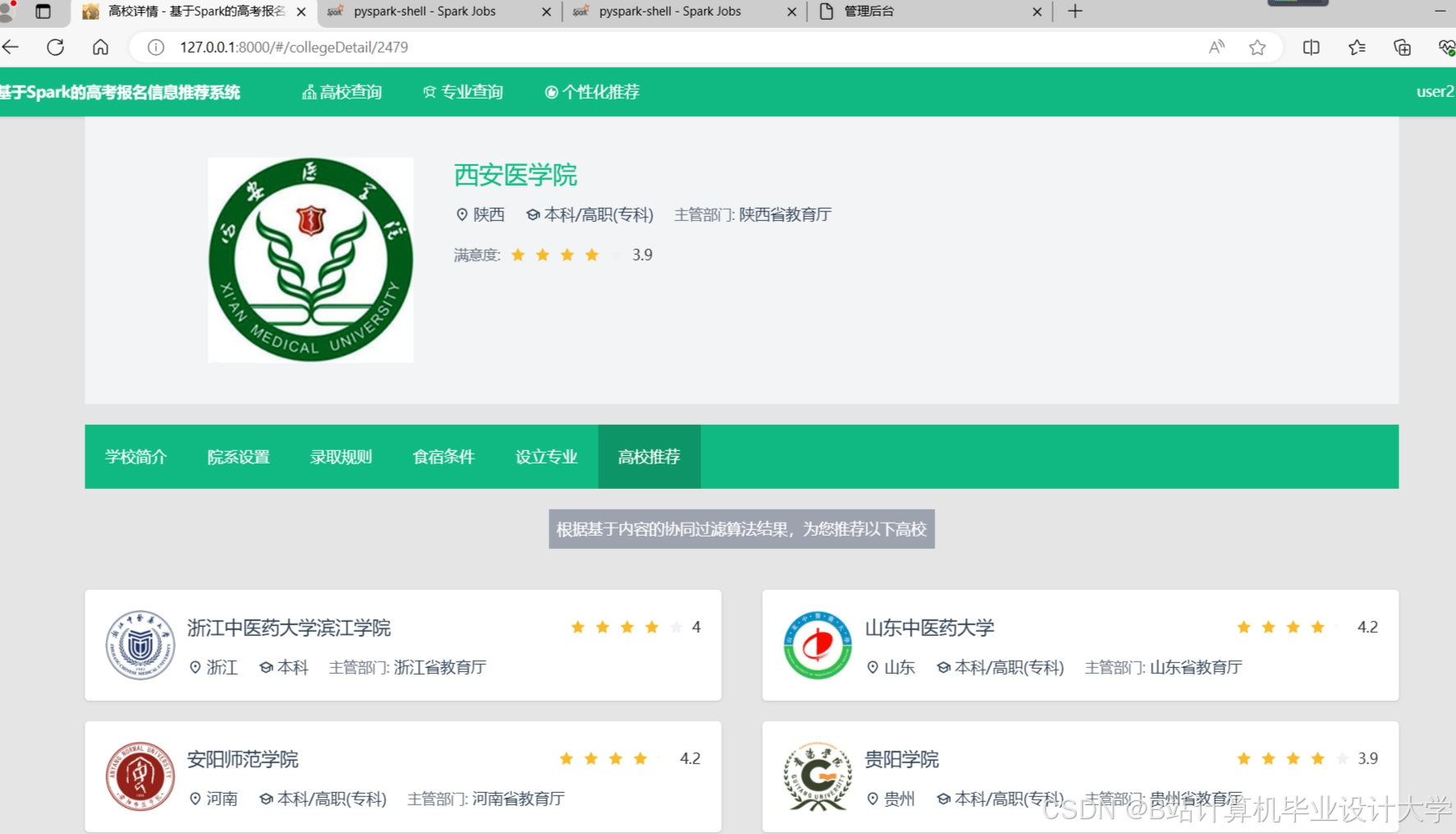
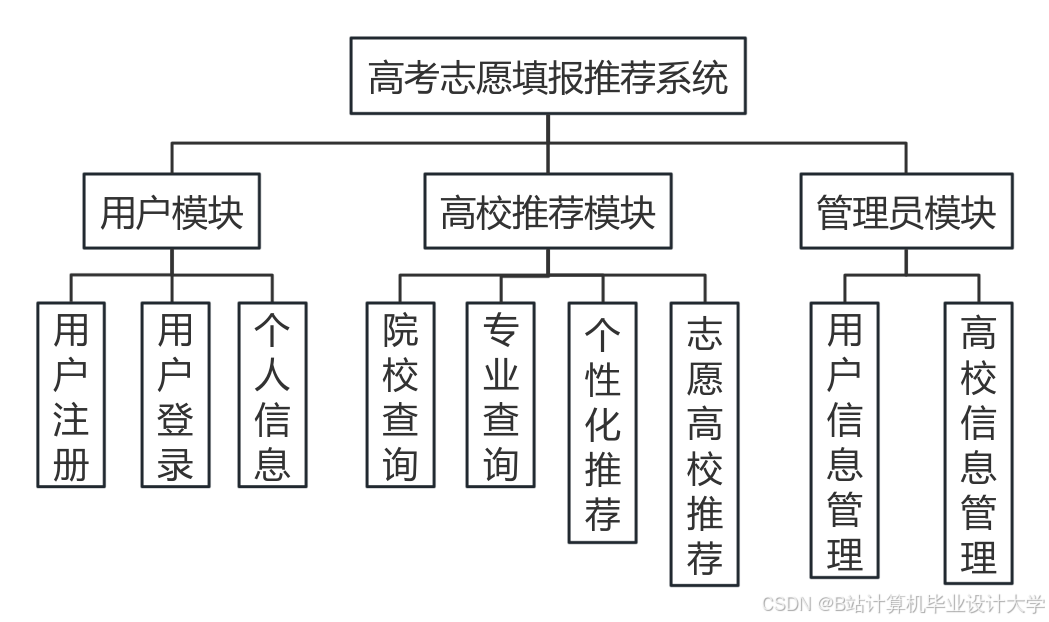

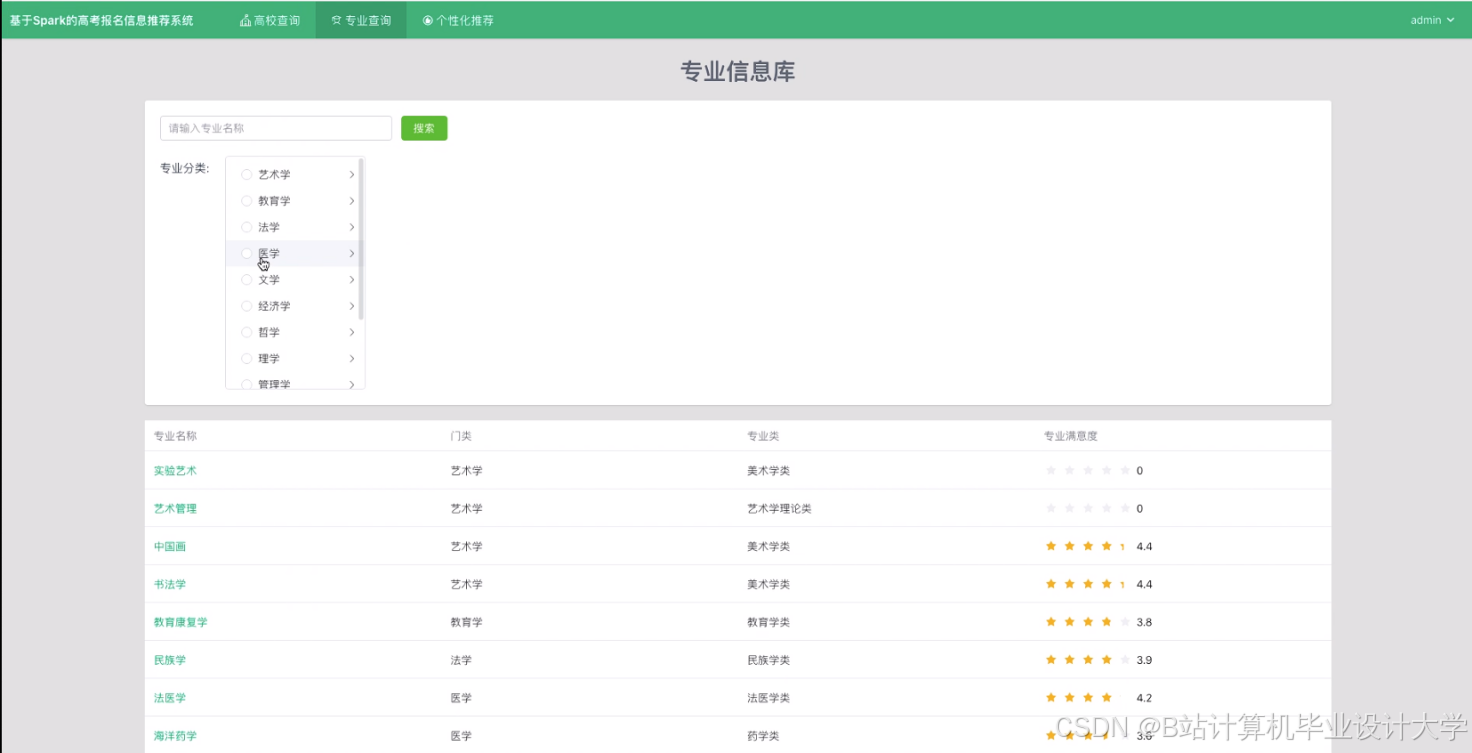
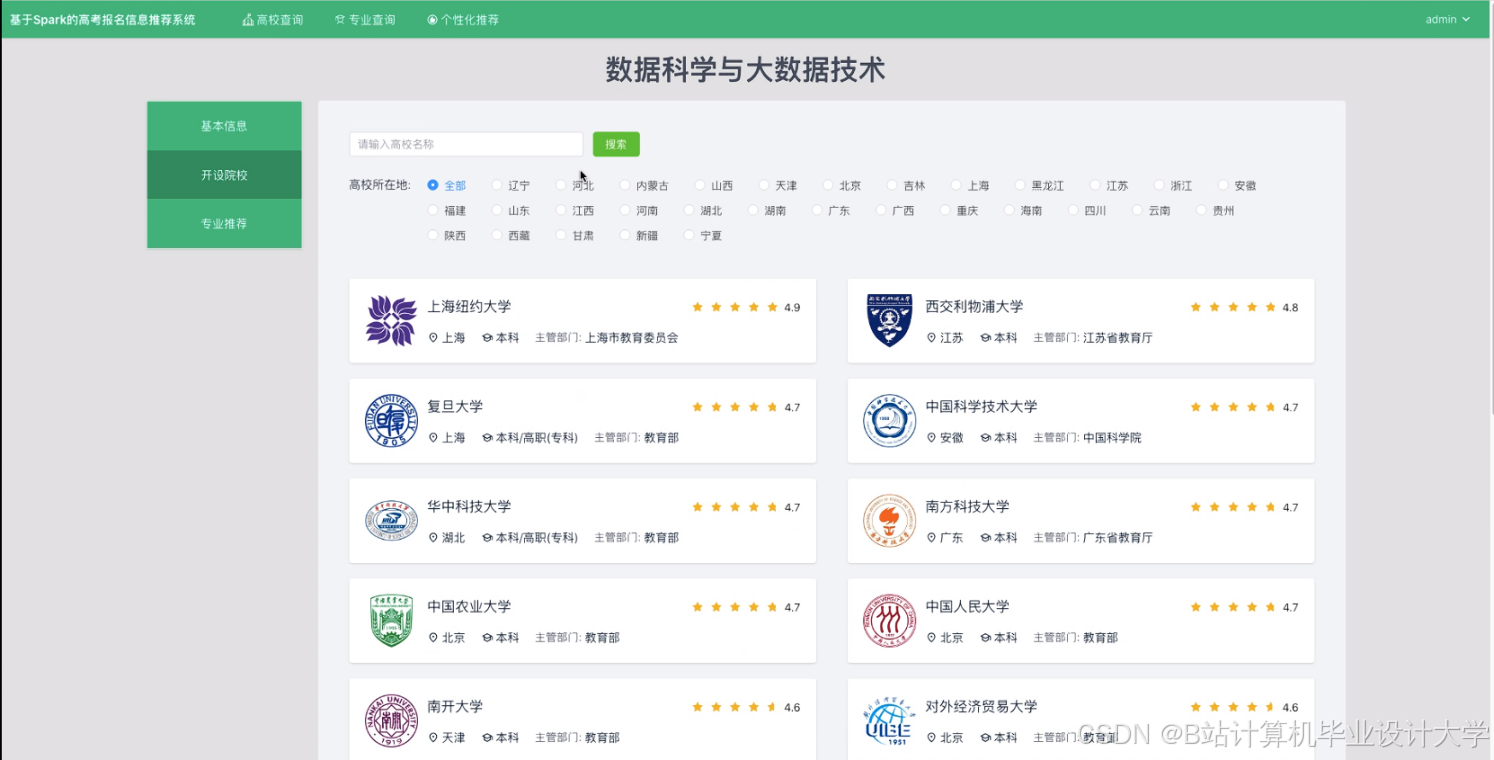

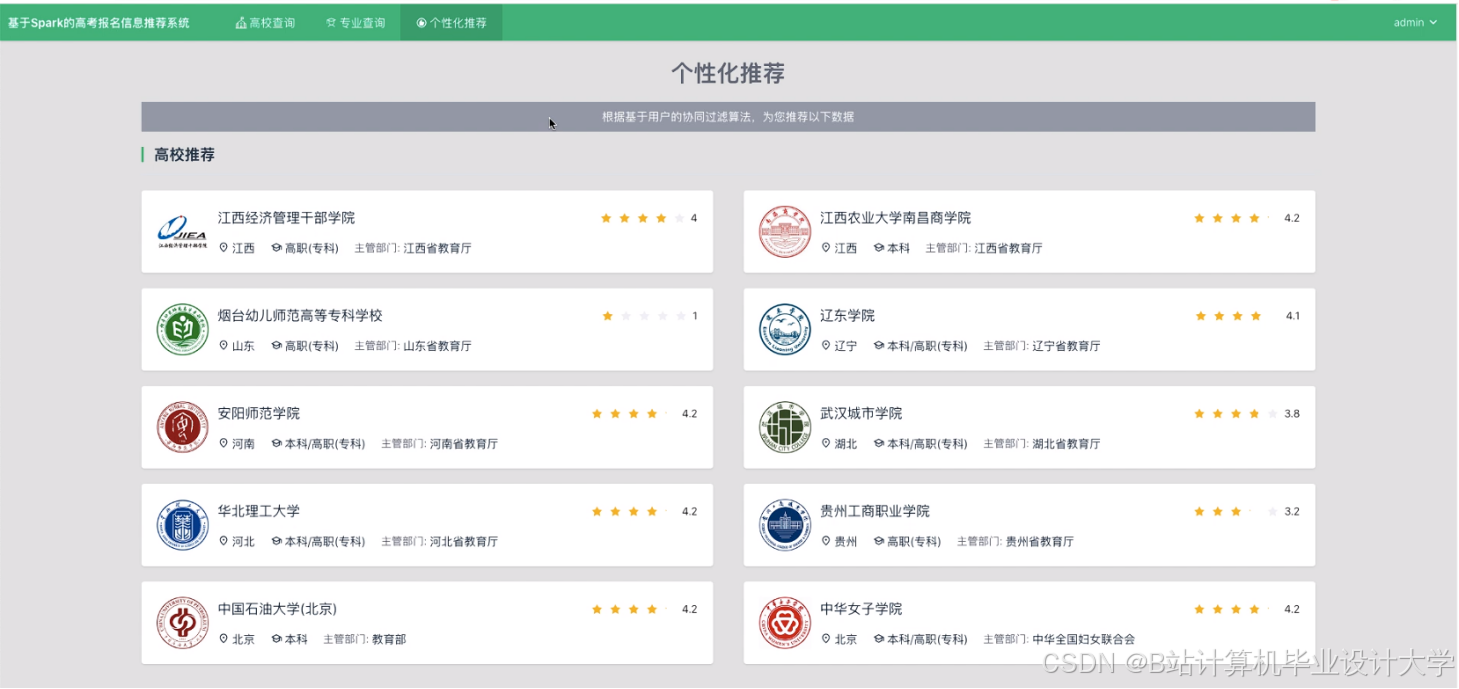
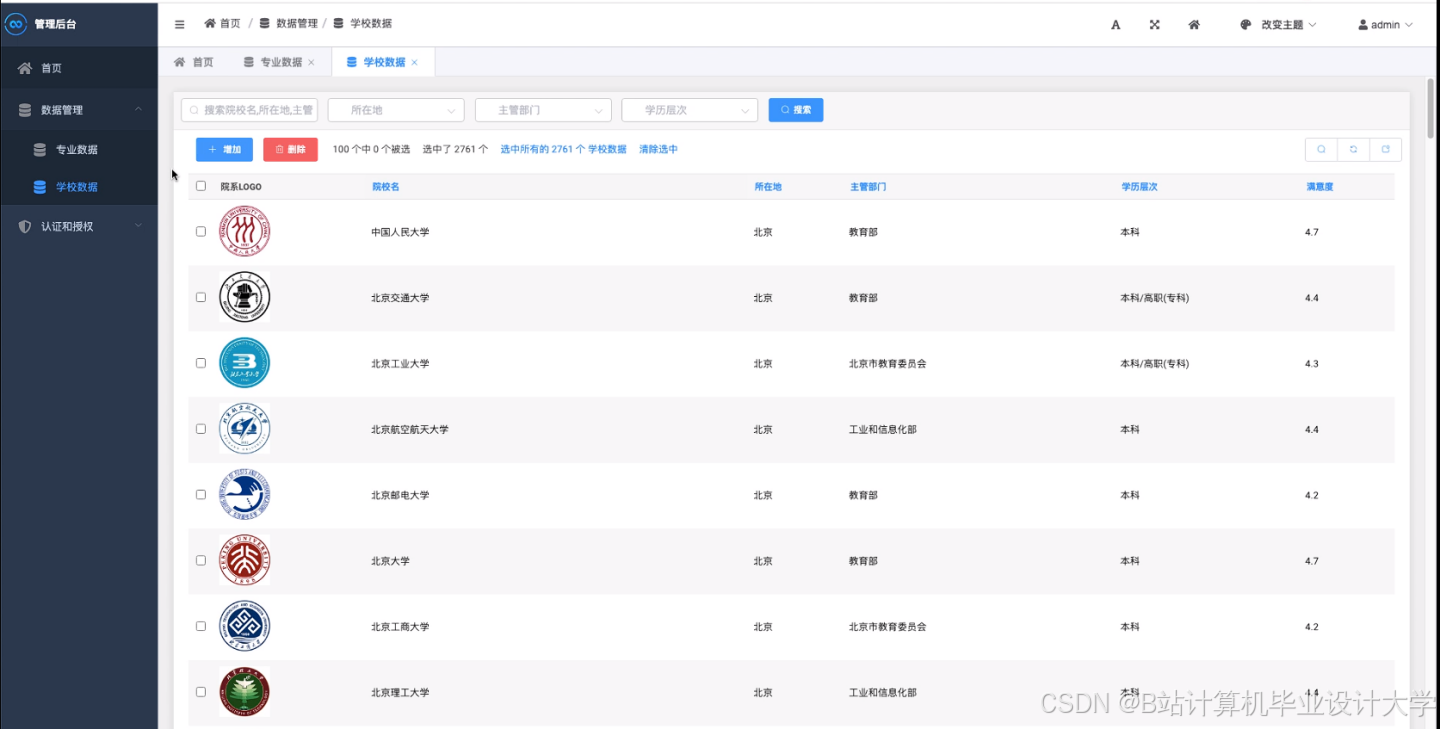
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











