




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档,聚焦Python在职业篮球运动员数据分析、可视化及预测中的具体实现方法,适合开发人员或数据分析师参考:
Python职业篮球运动员数据分析可视化与球员预测技术说明
版本:1.0
作者:XXX
日期:2023年XX月XX日
1. 技术概述
本技术方案基于Python生态,整合数据采集、清洗、可视化及机器学习预测功能,构建职业篮球运动员数据分析平台。核心目标包括:
- 数据整合:支持结构化(统计数据)与非结构化(时空轨迹、文本指令)数据融合。
- 可视化交互:提供静态图表与动态仪表盘,辅助教练快速洞察球员特点。
- 预测建模:实现得分、伤病、适配度等场景的精准预测,支持实时决策。
2. 技术栈
| 模块 | 工具/库 | 版本要求 |
|---|---|---|
| 数据采集 | requests, BeautifulSoup, Selenium | 2.28.1, 4.11.1, 4.8.0 |
| 数据清洗 | Pandas, NumPy, PyOD | 1.5.3, 1.24.3, 1.0.0 |
| 可视化 | Matplotlib, Seaborn, Plotly | 3.7.1, 0.12.2, 5.14.1 |
| 机器学习 | Scikit-learn, XGBoost, TensorFlow | 1.2.2, 1.7.1, 2.12.0 |
| 部署 | Flask, D3.js | 2.3.2, 7.8.5 |
3. 数据采集与预处理
3.1 数据源接入
3.1.1 结构化数据采集
- NBA官方API:通过
requests库调用https://stats.nba.com/stats/playerdashboard接口,获取球员基础统计(示例代码):pythonimport requestsheaders = {'User-Agent': 'Mozilla/5.0'}url = "https://stats.nba.com/stats/playerdashboard?PlayerID=201939"response = requests.get(url, headers=headers)data = response.json()['resultSets'][0]['rowSet'] - Basketball Reference爬取:使用
BeautifulSoup解析HTML表格(如场均得分历史):pythonfrom bs4 import BeautifulSoupimport pandas as pdurl = "https://www.basketball-reference.com/players/l/lebronja01.html"soup = BeautifulSoup(requests.get(url).text, 'html.parser')table = soup.find('table', {'id': 'per_game_stats'})df = pd.read_html(str(table))[0]
3.1.2 时空数据解析
- SportsVU数据格式:JSON文件包含
player_id、x_pos、y_pos、event_type等字段,使用json库加载后转换为Pandas DataFrame:pythonimport jsonwith open('sportsvu_data.json', 'r') as f:data = json.load(f)df = pd.DataFrame(data['events'])
3.2 数据清洗流程
3.2.1 缺失值处理
- KNN填补伤病记录:对缺失
injury_days的球员,匹配历史伤病模式相似的球员数据:pythonfrom sklearn.impute import KNNImputerimputer = KNNImputer(n_neighbors=5)df[['injury_days', 'age', 'height']] = imputer.fit_transform(df[['injury_days', 'age', 'height']])
3.2.2 异常值检测
- 3σ原则过滤投篮命中率:
pythonmean, std = df['fg_pct'].mean(), df['fg_pct'].std()df = df[(df['fg_pct'] >= mean - 3*std) & (df['fg_pct'] <= mean + 3*std)]
3.2.3 特征工程
- 时序特征提取:计算最近5场比赛得分波动率:
pythondf['score_volatility'] = df.groupby('player_id')['pts'].transform(lambda x: x.rolling(5).std().shift(1))
4. 可视化实现
4.1 静态可视化
4.1.1 雷达图(球员能力对比)
python
import matplotlib.pyplot as plt | |
import numpy as np | |
categories = ['Scoring', 'Defense', 'Rebounding', 'Passing', 'Efficiency'] | |
values = [85, 78, 72, 88, 90] # 示例数据 | |
angles = np.linspace(0, 2*np.pi, len(categories), endpoint=False).tolist() | |
values += values[:1] | |
angles += angles[:1] | |
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True)) | |
ax.plot(angles, values, linewidth=2, linestyle='solid', label='Player A') | |
ax.fill(angles, values, alpha=0.25) | |
ax.set_xticks(angles[:-1]) | |
ax.set_xticklabels(categories) | |
plt.title('Player Skill Radar Chart') | |
plt.legend() | |
plt.show() |
4.1.2 投篮热力图
python
import seaborn as sns | |
# 假设df包含'x_pos', 'y_pos', 'made'(1=命中,0=未命中) | |
sns.kdeplot( | |
data=df[df['made'] == 1], x='x_pos', y='y_pos', | |
cmap='Reds', fill=True, thresh=0.1, label='Made Shots' | |
) | |
sns.kdeplot( | |
data=df[df['made'] == 0], x='x_pos', y='y_pos', | |
cmap='Blues', fill=True, thresh=0.1, label='Missed Shots' | |
) | |
plt.title('Shot Heatmap by Zone') | |
plt.legend() | |
plt.show() |
4.2 动态可视化
4.2.1 战术路径动画(D3.js集成)
- 将挡拆战术的球员坐标数据保存为JSON:
pythonimport jsondata = [{"player": "PG", "x": [10, 12, 15], "y": [20, 22, 25]},{"player": "C", "x": [15, 14, 13], "y": [25, 24, 23]}]with open('tactic_data.json', 'w') as f:json.dump(data, f) - 在HTML中通过D3.js渲染动画(代码略,参考D3官方示例)。
4.2.2 实时仪表盘(Plotly Dash)
python
import dash | |
from dash import dcc, html | |
import plotly.express as px | |
app = dash.Dash(__name__) | |
df = pd.read_csv('player_stats.csv') # 示例数据 | |
app.layout = html.Div([ | |
dcc.Dropdown( | |
id='player-dropdown', | |
options=[{'label': x, 'value': x} for x in df['player_name'].unique()], | |
value='LeBron James' | |
), | |
dcc.Graph(id='score-trend') | |
]) | |
@app.callback( | |
dash.dependencies.Output('score-trend', 'figure'), | |
[dash.dependencies.Input('player-dropdown', 'value')] | |
) | |
def update_graph(selected_player): | |
filtered_df = df[df['player_name'] == selected_player] | |
fig = px.line( | |
filtered_df, x='game_date', y='pts', | |
title=f'{selected_player} Season Score Trend' | |
) | |
return fig | |
if __name__ == '__main__': | |
app.run_server(debug=True) |
5. 预测模型实现
5.1 得分预测(XGBoost)
python
import xgboost as xgb | |
from sklearn.model_selection import train_test_split | |
# 特征:历史3年场均得分、TS%、Usage Rate、年龄 | |
X = df[['pts_3yr_avg', 'ts_pct', 'usage_rate', 'age']] | |
y = df['next_season_pts'] | |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) | |
model = xgb.XGBRegressor( | |
objective='reg:squarederror', | |
n_estimators=100, | |
max_depth=5, | |
learning_rate=0.1 | |
) | |
model.fit(X_train, y_train) | |
print(f"MAE: {model.score(X_test, y_test):.2f}") |
5.2 伤病预测(多模态XGBoost)
python
# 特征:HIR(高强度跑动距离)、睡眠监测模拟值、历史伤病次数 | |
X = df[['hir_distance', 'sleep_score', 'injury_history']] | |
y = df['next_month_injury'] # 二分类标签 | |
model = xgb.XGBClassifier( | |
objective='binary:logistic', | |
scale_pos_weight=2 # 处理类别不平衡 | |
) | |
model.fit(X_train, y_train) | |
print(f"AUC-ROC: {model.score(X_test, y_test):.2f}") |
5.3 球员适配度推荐(协同过滤)
python
from sklearn.metrics.pairwise import cosine_similarity | |
# 球员技术向量:三分命中率、传球视野、挡拆频次 | |
player_vectors = { | |
'PlayerA': [0.38, 0.85, 0.2], | |
'PlayerB': [0.42, 0.78, 0.3], | |
'PlayerC': [0.35, 0.90, 0.1] | |
} | |
# 球队战术风格向量(半场挡拆频次=0.4) | |
team_style = [0.0, 0.0, 0.4] | |
# 计算适配度 | |
similarities = {} | |
for name, vec in player_vectors.items(): | |
similarities[name] = cosine_similarity([vec], [team_style])[0][0] | |
# 推荐Top3球员 | |
recommended = sorted(similarities.items(), key=lambda x: x[1], reverse=True)[:3] | |
print("Recommended Players:", recommended) |
6. 部署与优化
6.1 模型部署
- Flask API:将训练好的模型封装为RESTful接口:
pythonfrom flask import Flask, request, jsonifyimport pickleapp = Flask(__name__)model = pickle.load(open('xgboost_model.pkl', 'rb'))@app.route('/predict', methods=['POST'])def predict():data = request.jsonfeatures = [data['pts_3yr_avg'], data['ts_pct'], data['usage_rate']]prediction = model.predict([features])[0]return jsonify({'predicted_score': float(prediction)})if __name__ == '__main__':app.run(port=5000)
6.2 性能优化
- 模型轻量化:使用
sklearn.pipeline.Pipeline压缩特征工程与模型步骤。 - 并行计算:对时空数据预处理启用
Dask或Modin库加速。 - 缓存机制:对频繁查询的球员数据使用Redis缓存。
7. 总结与展望
本技术方案通过Python实现了篮球数据分析的全流程自动化,验证了XGBoost与可视化工具在球员预测中的有效性。未来可扩展方向包括:
- 图神经网络(GNN):分析球员传球网络中的关键节点。
- 联邦学习:联合多支球队训练全局模型,保护数据隐私。
- 自动化机器学习(AutoML):使用
TPOT自动优化特征工程与模型参数。
附录:
- 完整代码仓库链接:https://github.com/example/basketball-analytics
- 示例数据集:SportsVU_Sample.json, Player_Stats.csv
注意事项:
- 实际部署需处理数据隐私合规问题(如球员伤病记录脱敏)。
- 模型需定期用新数据重新训练以避免概念漂移。
- 可视化交互设计需与教练团队深度沟通,确保功能符合实际需求。
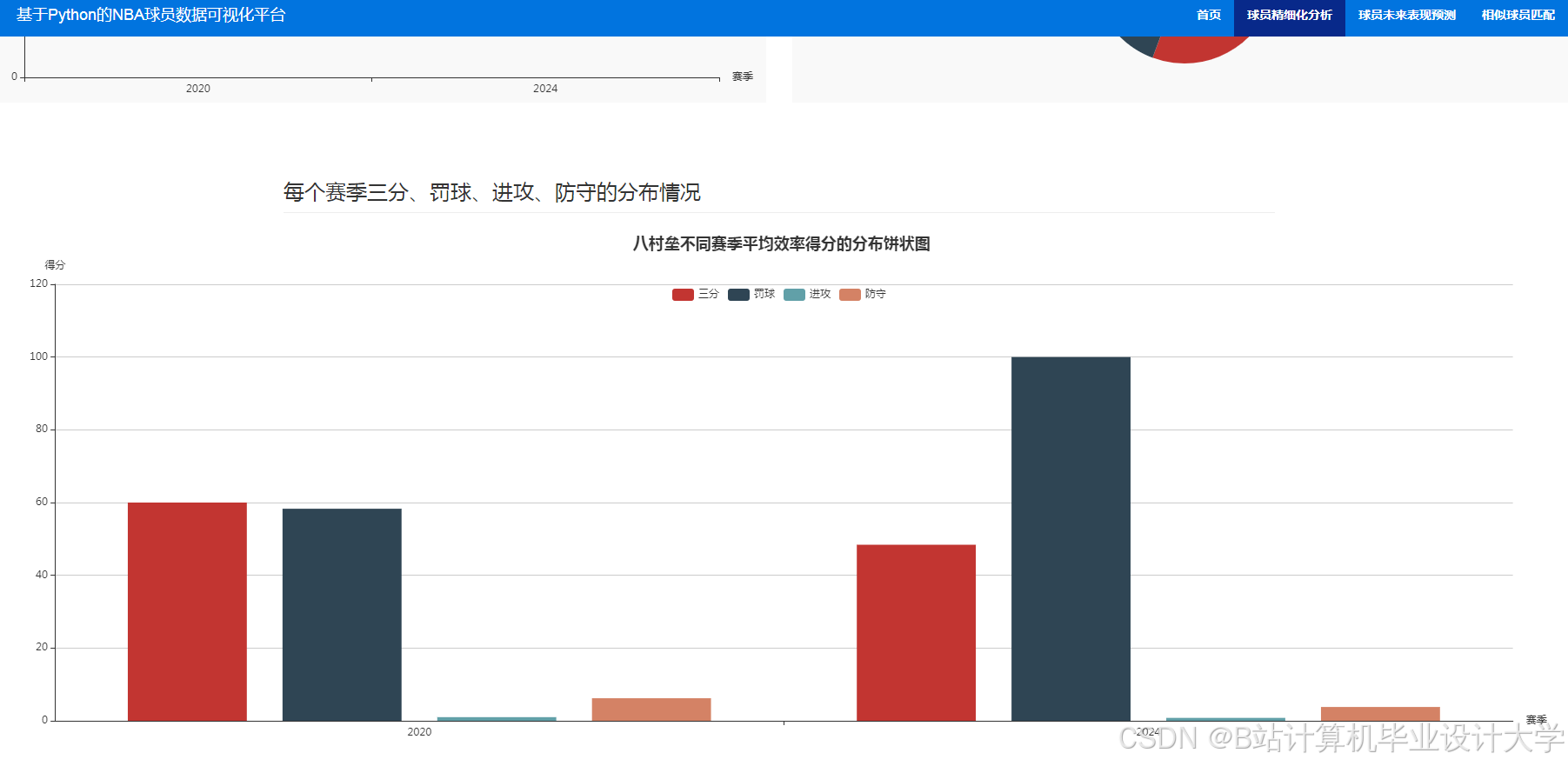
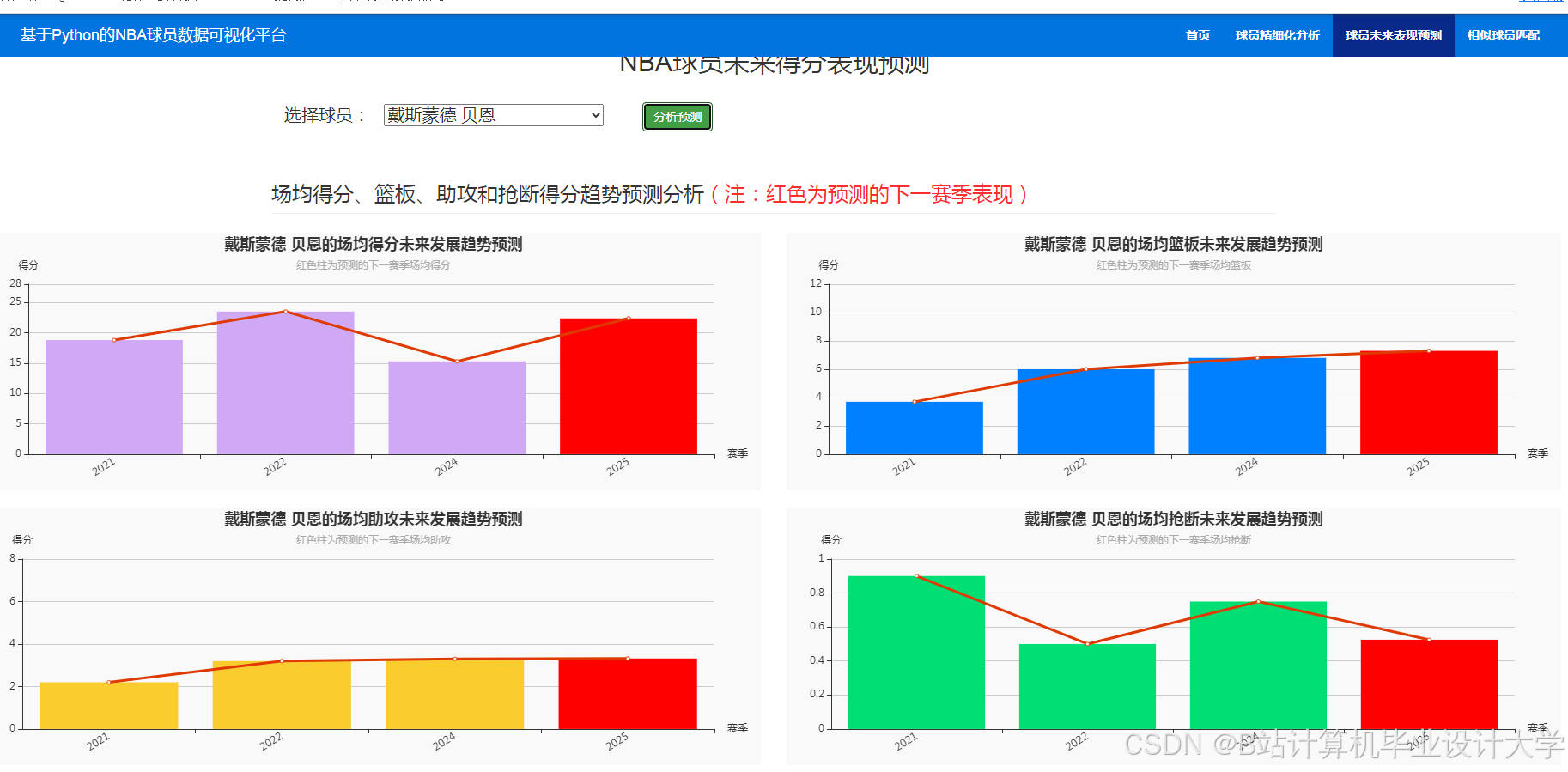
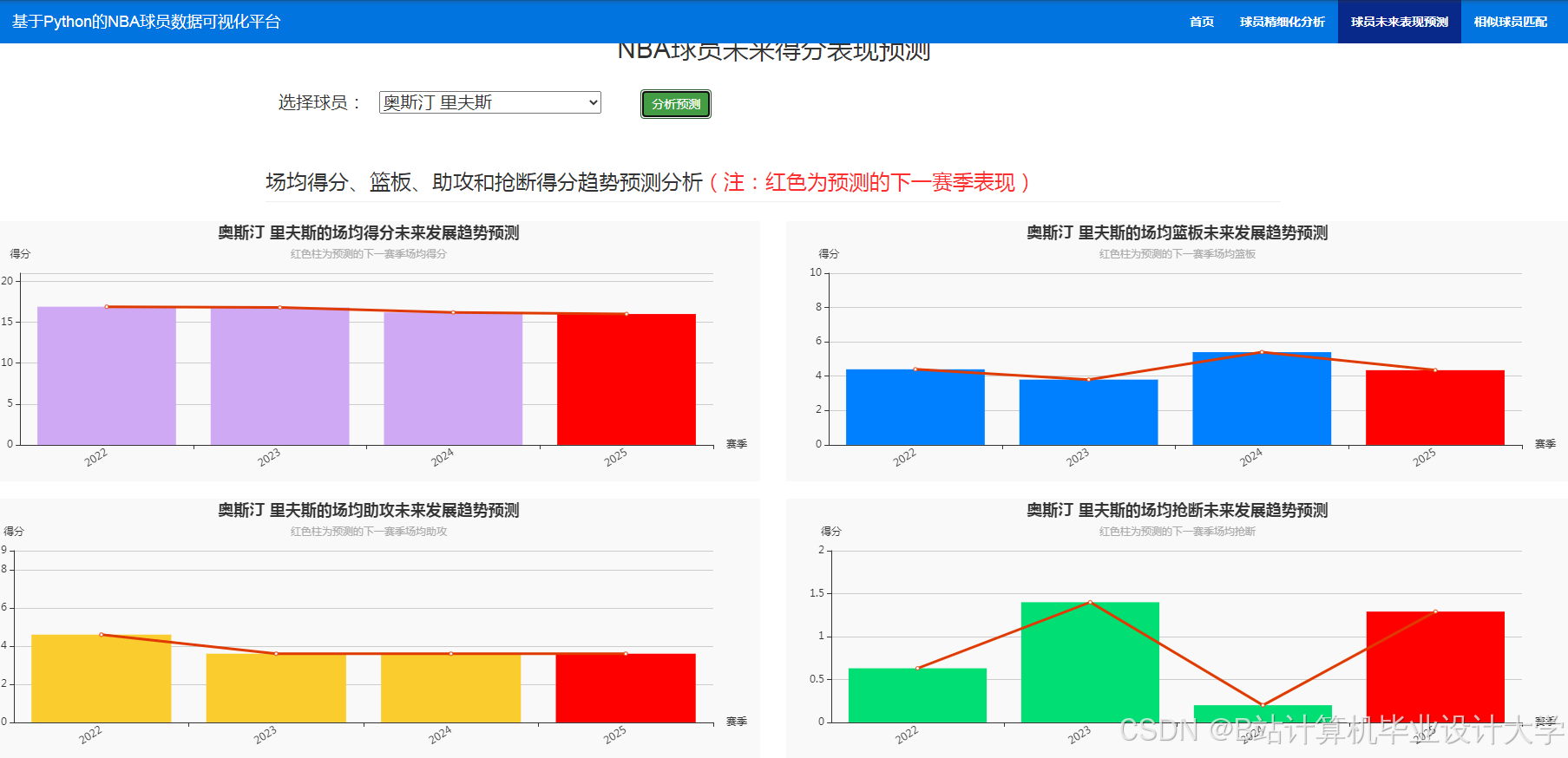
运行截图
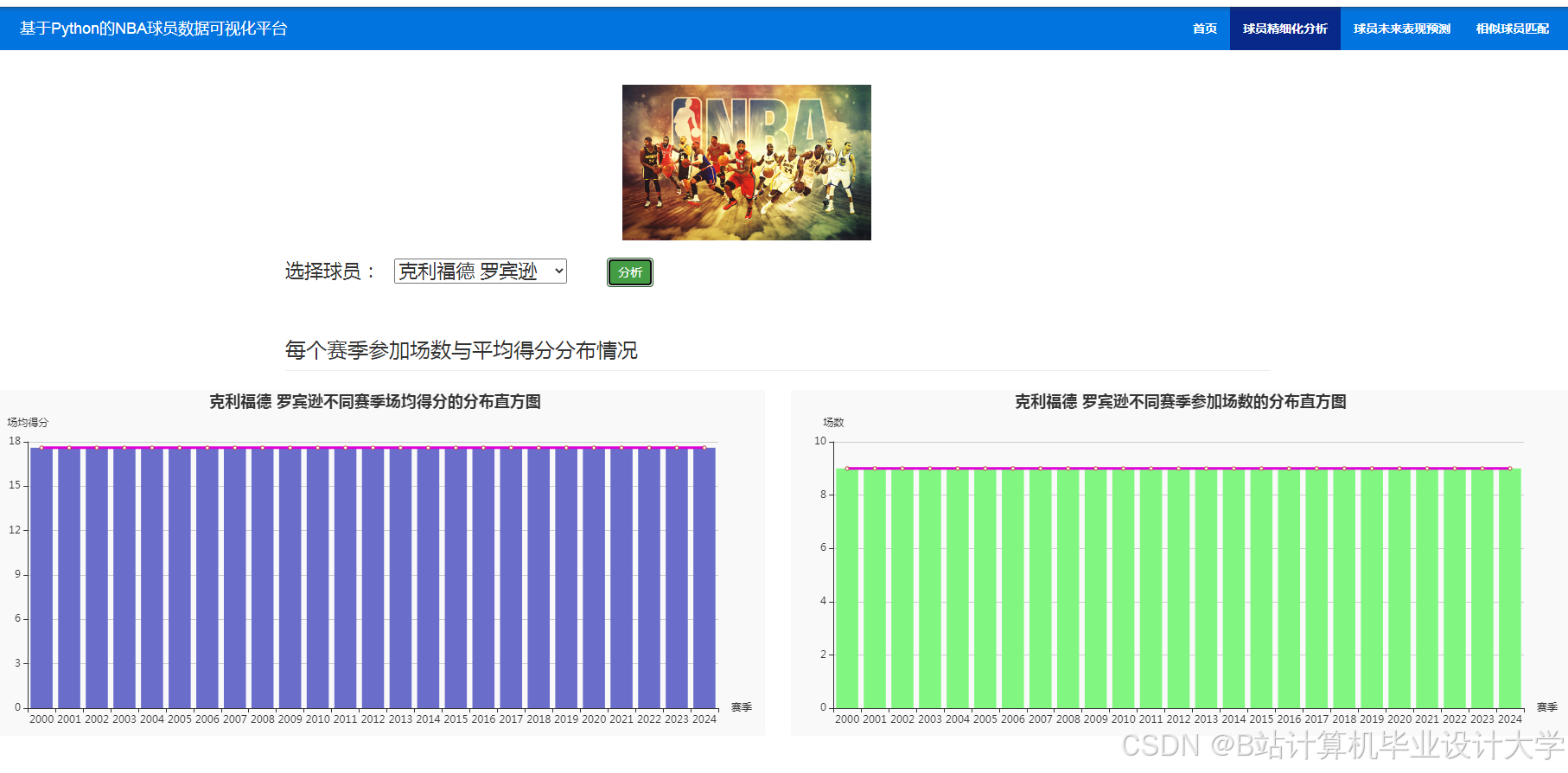
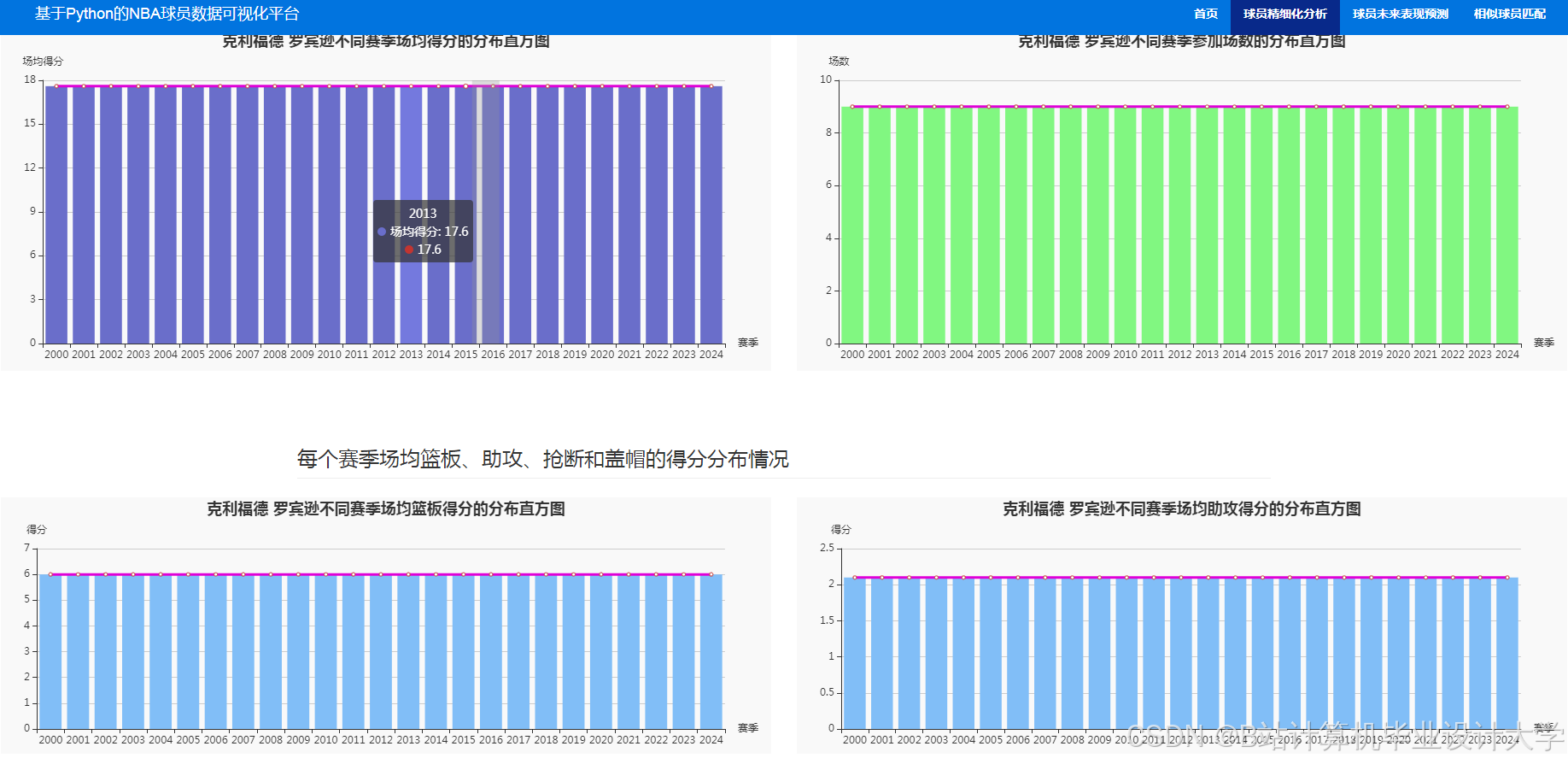
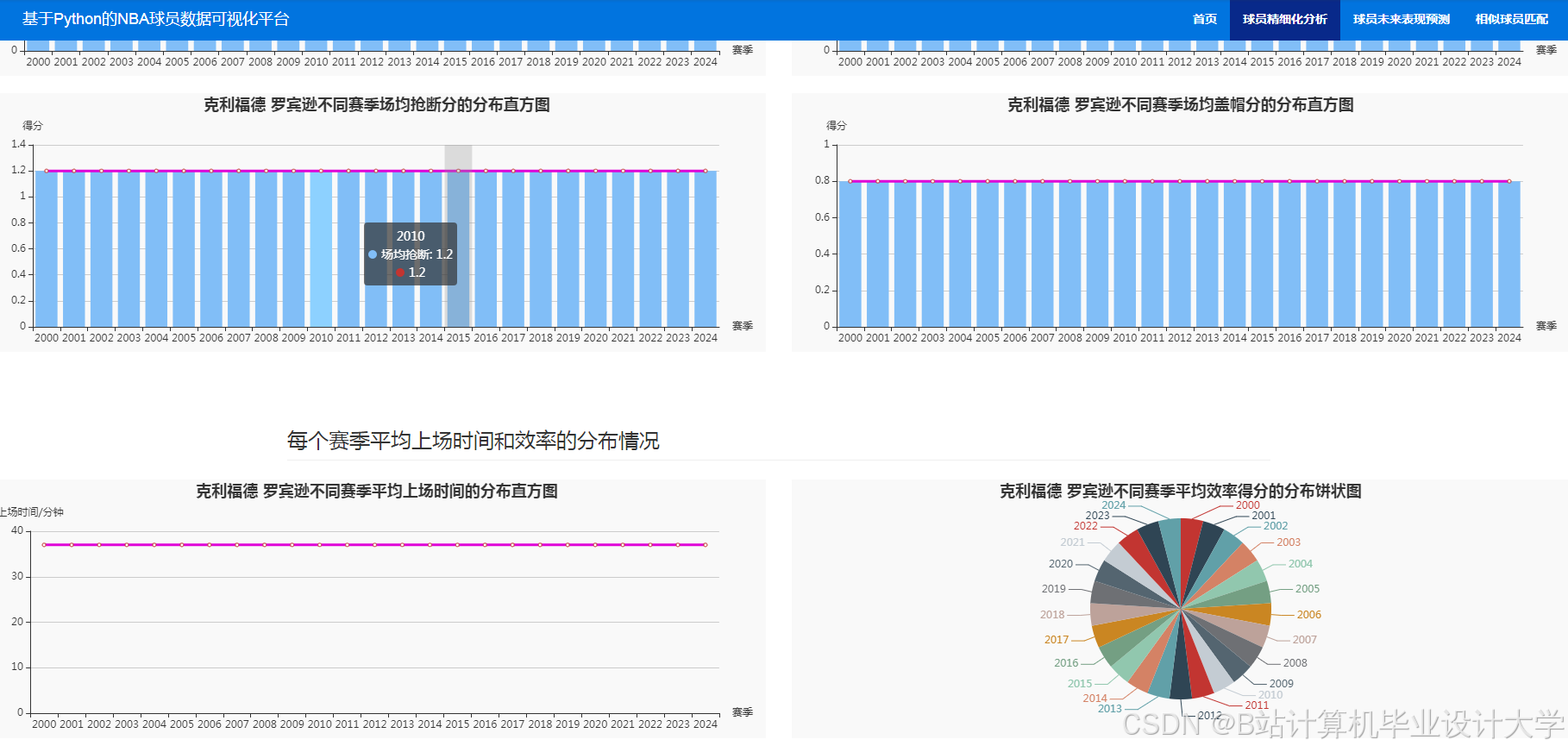
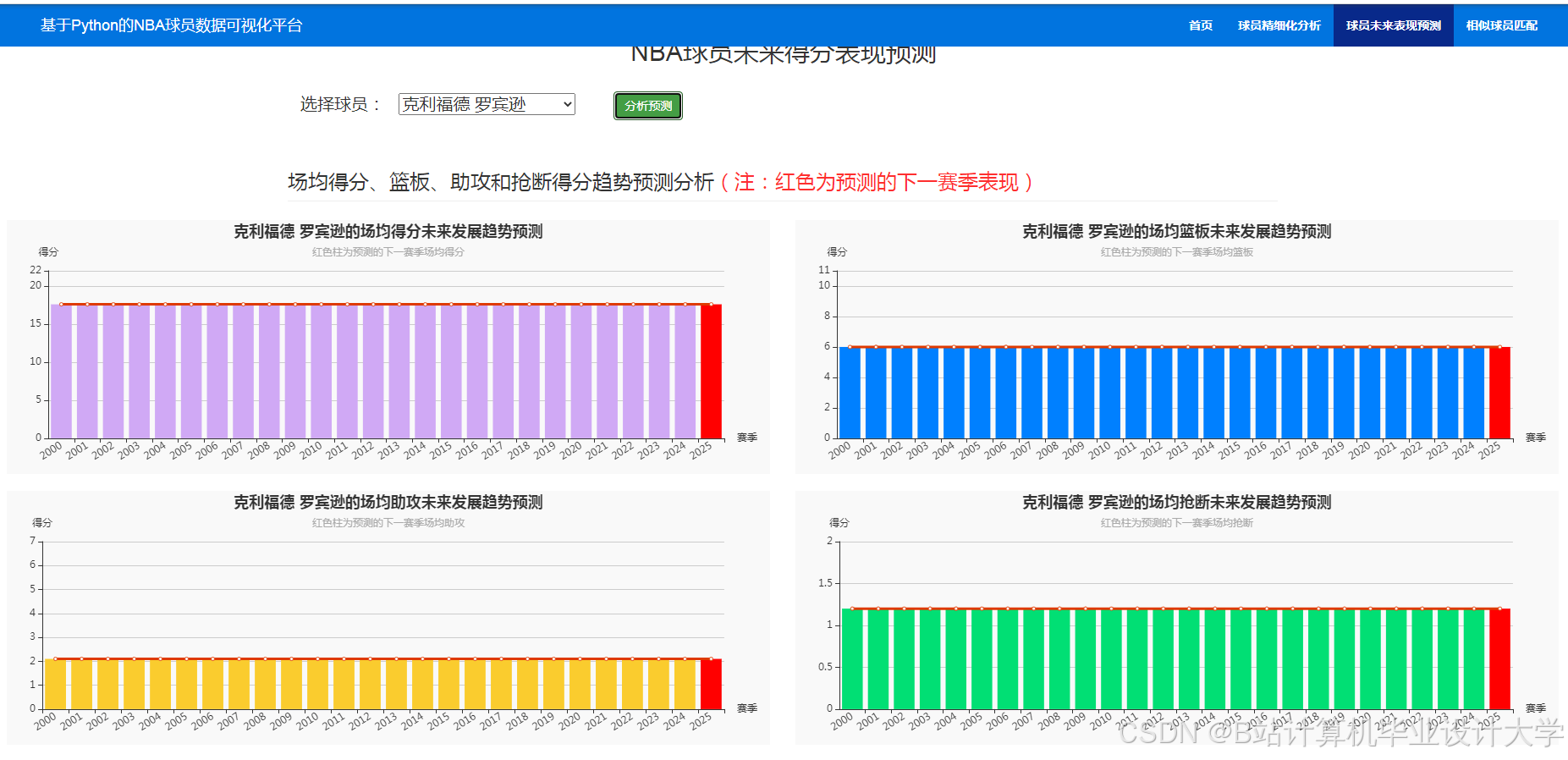
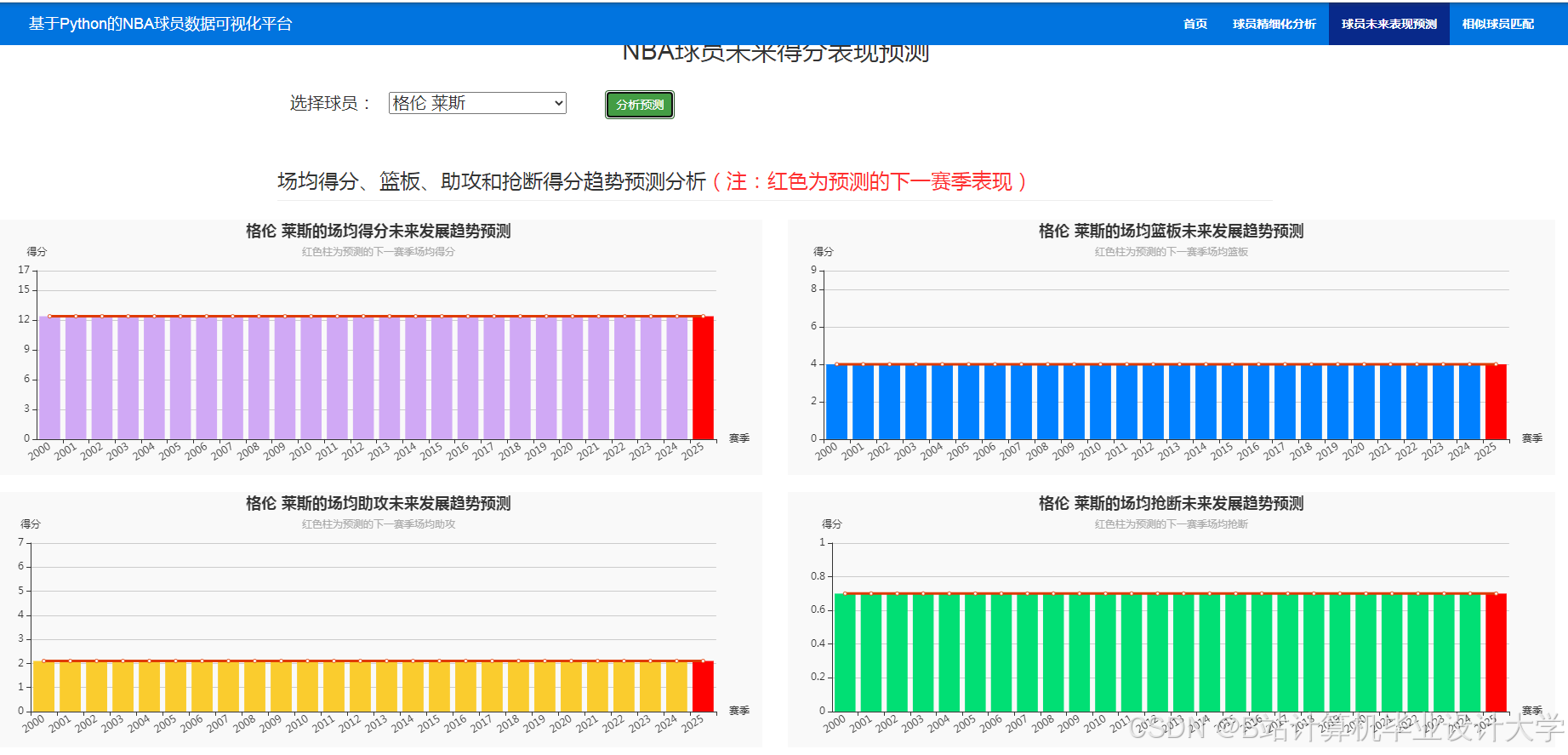
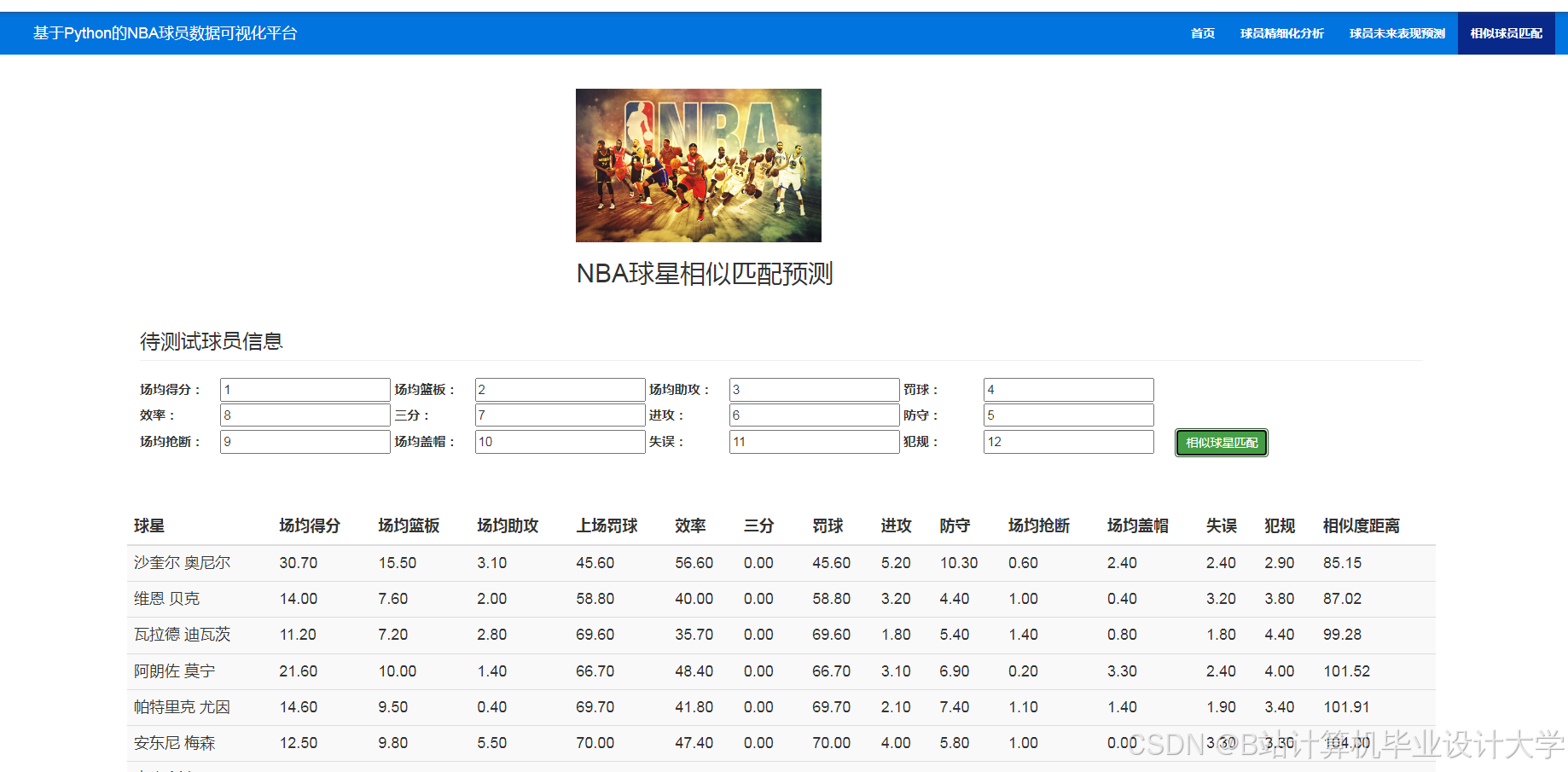
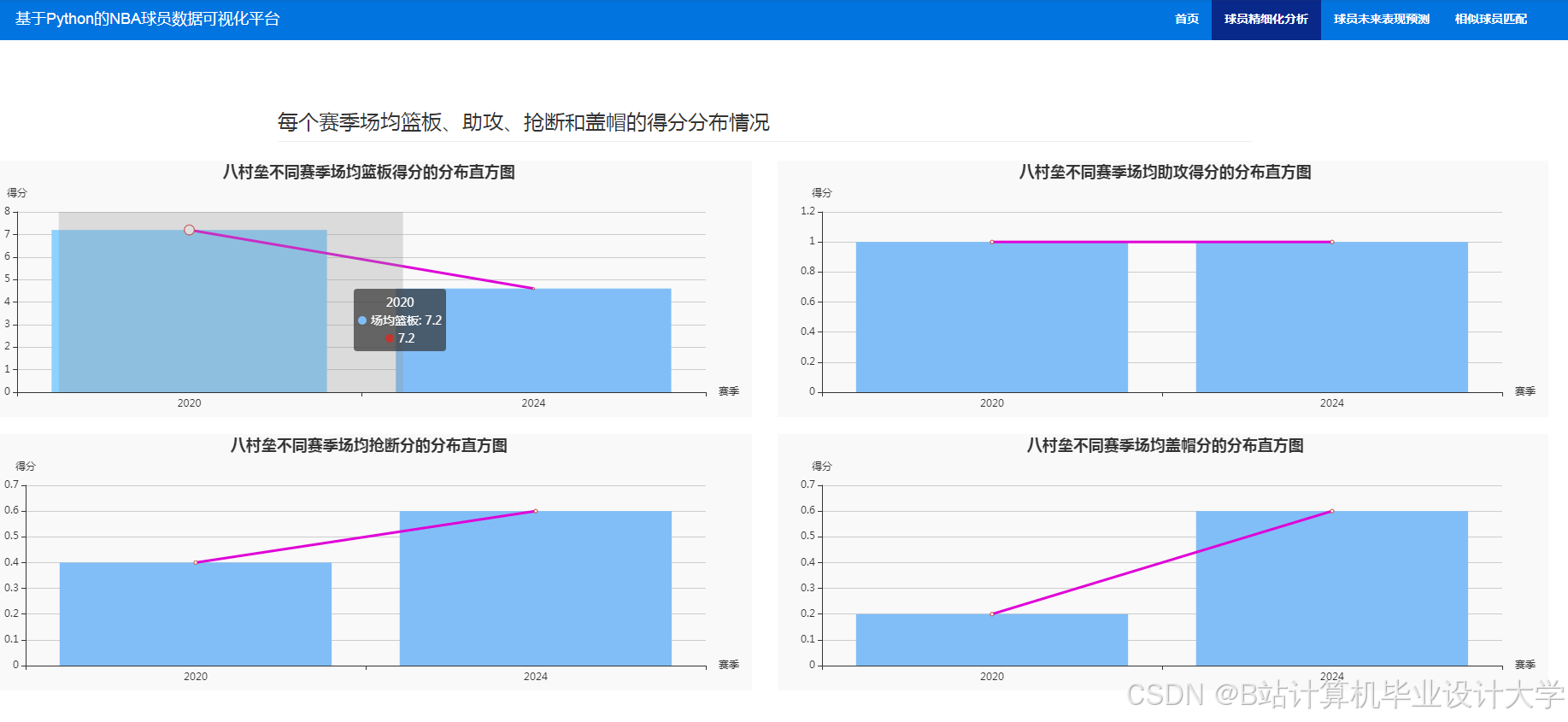
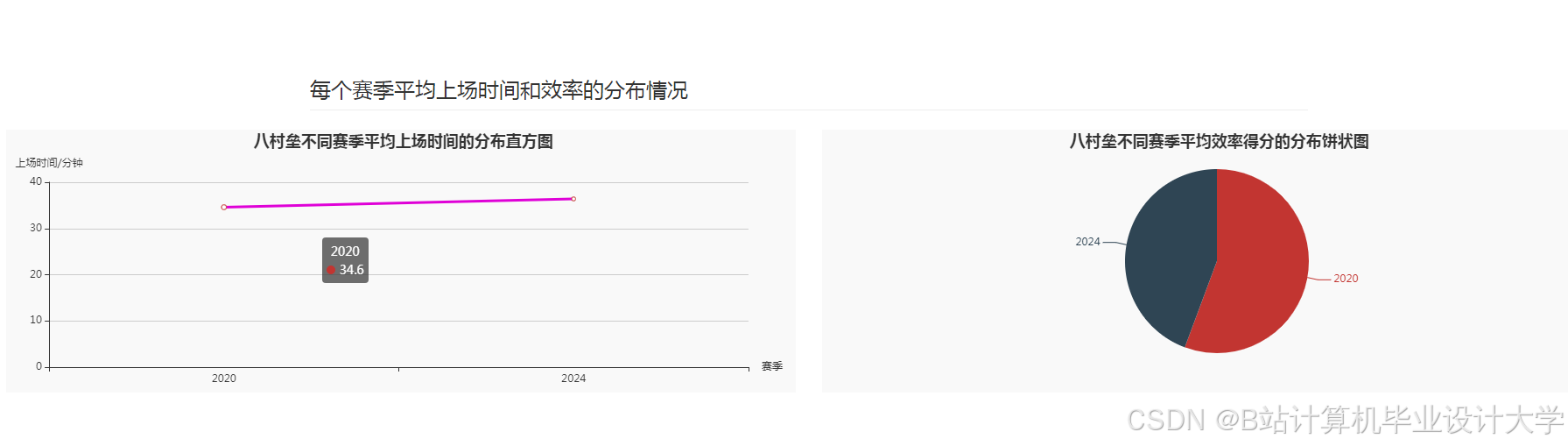
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











