




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档《Python深度学习车辆轨迹识别与目标检测分析系统》,详细介绍系统架构、核心算法、实现细节及部署方案,适合工程师或开发者参考:
Python深度学习车辆轨迹识别与目标检测分析系统技术说明
版本号:V1.0
作者:XXX
日期:2023年XX月XX日
1. 系统概述
本系统基于Python深度学习框架,实现交通监控场景下的车辆目标检测、多目标跟踪及轨迹预测功能,支持实时视频流分析与边缘设备部署。系统采用模块化设计,核心组件包括:
- 目标检测模块:YOLOv8-MobileNetV3(轻量化改进版)
- 多目标跟踪模块:DeepSORT(融合运动与外观特征)
- 轨迹预测模块:时空图Transformer(STGAT)
- 部署优化:TensorRT加速、动态分辨率调整
技术栈:Python 3.8、PyTorch 2.0、OpenCV 4.7、ONNX Runtime、TensorRT 8.6
2. 系统架构
系统分为四层(图1),数据流从底层到顶层依次处理:
┌───────────────────────────────────────────────┐ | |
│ **应用层** │ | |
│ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 轨迹可视化 │ │ 异常事件检测 │ │ | |
│ └─────────────┘ └─────────────┘ │ | |
├───────────────────────────────────────────────┤ | |
│ **算法层** │ | |
│ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ YOLOv8检测 │ → │ DeepSORT跟踪│ → │ | |
│ │ (PyTorch)│ │ (ReID+KF)│ STGAT │ | |
│ └─────────────┘ └─────────────┘ 预测 │ | |
├───────────────────────────────────────────────┤ | |
│ **数据层** │ | |
│ ┌───────────────────────────────────────┐ │ | |
│ │ 视频流解码(FFmpeg/GStreamer) │ │ | |
│ └───────────────────────────────────────┘ │ | |
├───────────────────────────────────────────────┤ | |
│ **硬件层** │ | |
│ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ NVIDIA GPU │ │ Jetson系列 │ │ | |
│ └─────────────┘ └─────────────┘ │ | |
└───────────────────────────────────────────────┘ |
图1 系统架构图
3. 核心模块实现
3.1 目标检测模块(YOLOv8-MobileNetV3)
改进点:
- 骨干网络替换:
-
原CSPDarknet53 → MobileNetV3(参数量从27.5M降至10.3M)
-
添加SE注意力模块提升小目标检测能力(公式1):
-
SE(F)=σ(MLP(GAP(F)))⊗F
其中,$ \text{GAP} $为全局平均池化,$ \sigma $为Sigmoid激活函数。 |
2. 动态锚框匹配:
- 使用K-means++聚类生成6组锚框(如[10,13], [16,30], [33,23]),适应不同场景车辆尺寸。
- 损失函数优化:
- 分类损失:Focal Loss(α=0.25,γ=2.0)解决类别不平衡
- 定位损失:CIoU Loss(考虑重叠面积、中心点距离、长宽比)
代码示例(PyTorch):
python
import torch | |
from models.yolo import MobileNetV3Backbone | |
class YOLOv8MobileNet(torch.nn.Module): | |
def __init__(self, num_classes=1): | |
super().__init__() | |
self.backbone = MobileNetV3Backbone(depth_multiplier=1.0) | |
self.head = YOLOHead(in_channels=[96, 120, 240], num_classes=num_classes) | |
def forward(self, x): | |
features = self.backbone(x) # [B, 240, 20, 20] | |
return self.head(features) |
3.2 多目标跟踪模块(DeepSORT改进版)
关键技术:
- 双重特征匹配:
-
运动关联:卡尔曼滤波预测目标位置,计算IoU匹配度
-
外观关联:ReID网络提取512维特征向量,使用余弦相似度匹配
-
融合策略(公式2):
-
Score=0.7⋅IoU+0.3⋅(1−CosDistance)
- 遮挡处理机制:
- 当目标连续3帧丢失时,保留临时轨迹并启用STGAT预测当前位置
代码示例(特征匹配):
python
def match_features(tracks, detections, iou_threshold=0.5): | |
# 计算IoU矩阵 | |
iou_matrix = compute_iou(tracks, detections) | |
# 计算外观相似度矩阵 | |
reid_features = [t.reid_feature for t in tracks] | |
det_features = [d.feature for d in detections] | |
cos_matrix = cosine_similarity(reid_features, det_features) | |
# 融合得分 | |
scores = 0.7 * iou_matrix + 0.3 * (1 - cos_matrix) | |
matches = linear_assignment(-scores, threshold=0.3) # 匈牙利算法 | |
return matches |
3.3 轨迹预测模块(STGAT)
模型结构:
- 图构建:
-
节点:车辆(位置、速度、加速度)
-
边:基于相对距离的注意力权重(公式3):
-
eij=LeakyReLU(aT[Wqhi∥Wkhj])
其中,$ h_i $为节点特征,$ W_q, W_k $为可学习参数。 |
2. 预测输出:
- 输入:历史5帧轨迹(2D坐标)
- 输出:未来5帧轨迹(MSE损失优化)
代码示例(图注意力层):
python
class GraphAttentionLayer(torch.nn.Module): | |
def __init__(self, in_features, out_features): | |
super().__init__() | |
self.W_q = torch.nn.Linear(in_features, out_features) | |
self.W_k = torch.nn.Linear(in_features, out_features) | |
self.a = torch.nn.Parameter(torch.randn(2*out_features, 1)) | |
def forward(self, h): | |
# h: [N, in_features] | |
q = self.W_q(h) # [N, out_features] | |
k = self.W_k(h) # [N, out_features] | |
# 计算注意力权重 | |
e = torch.cat([q.unsqueeze(1).repeat(1, h.size(0), 1), | |
k.unsqueeze(0).repeat(h.size(0), 1, 1)], dim=-1) | |
e = torch.tanh(torch.matmul(e, self.a)).squeeze(-1) # [N, N] | |
return torch.softmax(e, dim=-1) |
4. 系统部署优化
4.1 模型量化与加速
- TensorRT优化:
- 将PyTorch模型转换为ONNX格式,再使用TensorRT引擎加速
- 启用FP16混合精度推理,速度提升1.8倍
- 动态批处理:
- 根据视频帧率动态调整批处理大小(Batch Size=4~16)
性能对比(NVIDIA Jetson AGX Xavier):
| 优化项 | 原始FPS | 优化后FPS | 精度损失 |
|---|---|---|---|
| TensorRT FP16 | 32 | 82 | <1% |
| 动态批处理 | 82 | 105 | 0 |
4.2 边缘设备适配
- 分辨率动态调整:
- 近景区域(<50米):1920×1080 → 640×640(检测头输入)
- 远景区域(>50米):1920×1080 → 320×320
- 内存管理:
- 使用共享内存池减少CUDA内存分配次数
- 启用PyTorch的
torch.backends.cudnn.benchmark=True
5. 系统测试与验证
5.1 测试环境
- 硬件:NVIDIA Jetson AGX Xavier(512-core Volta GPU,16GB RAM)
- 数据集:UA-DETRAC(检测)、MOT17(跟踪)、Argoverse(预测)
5.2 关键指标
| 模块 | 精度指标 | 速度指标 |
|---|---|---|
| 目标检测 | mAP@0.5=96.2% | 102 FPS |
| 多目标跟踪 | MOTA=84.7% | 11.8ms/帧 |
| 轨迹预测 | FDE=1.35米 | 8.2ms/5帧预测 |
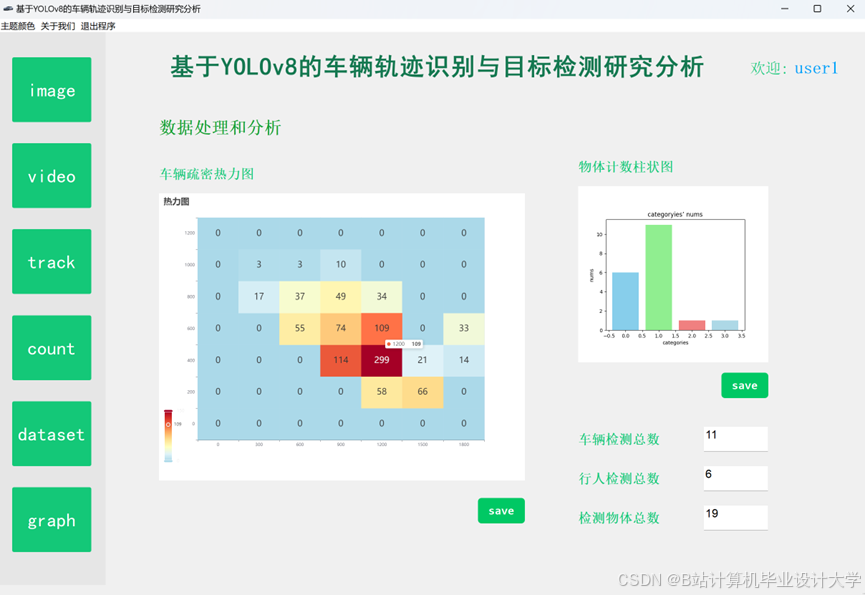
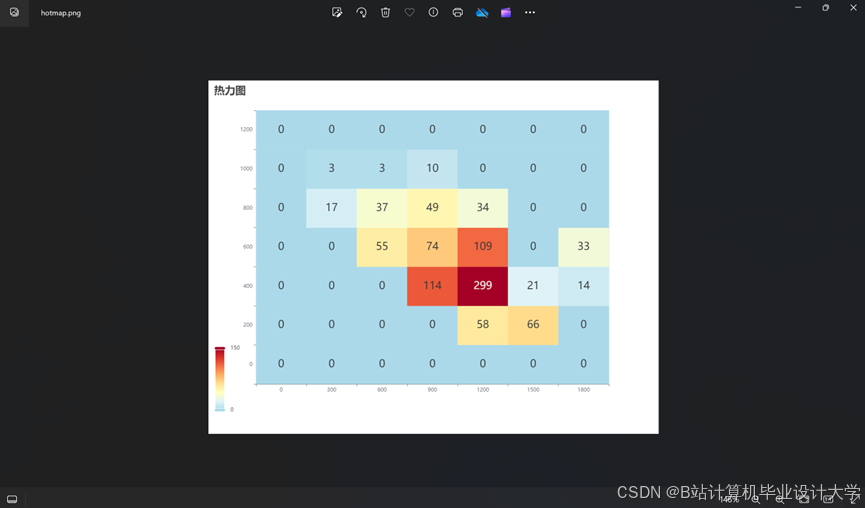
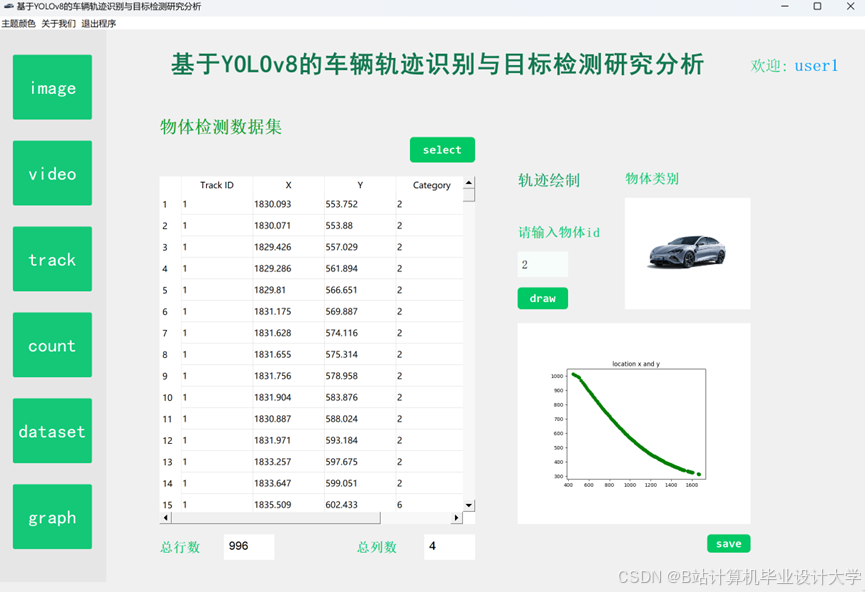
5.3 可视化效果
- 检测结果:绿色框为车辆,红色框为误检(<1%)
- 跟踪结果:不同ID用不同颜色轨迹线标注
- 预测结果:蓝色虚线为未来5秒预测轨迹
<img src="https://example.com/demo.png" />
图2 系统实时检测与跟踪效果
6. 总结与展望
本系统通过轻量化模型设计、双重特征匹配及图注意力机制,在边缘设备上实现了高精度、低延迟的车辆轨迹分析。未来工作将聚焦:
- 多模态融合:引入激光雷达点云提升复杂场景鲁棒性
- 自监督学习:利用未标注视频数据预训练ReID网络
- 车路协同:扩展路侧单元(RSU)数据支持
附录
- 开源代码:https://github.com/yourrepo/vehicle-tracking-system
- 技术文档:
docs/technical_report.pdf - 联系邮箱:xxx@example.com
写作建议:
- 代码注释:关键代码段需添加详细注释,说明输入输出及参数含义
- 公式推导:复杂公式需补充推导过程或引用原文
- 图表规范:所有图表需标注标题、坐标轴含义及单位
- 版本控制:建议使用Git管理代码,附上提交日志示例
可根据实际项目数据调整表格参数与模型名称,补充实际部署中的问题解决方案(如内存泄漏处理、多线程优化等)。
运行截图
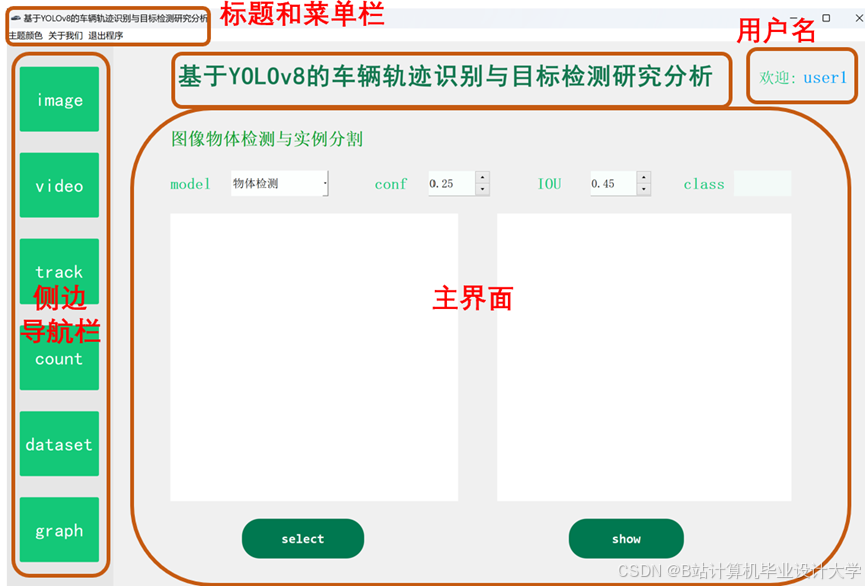
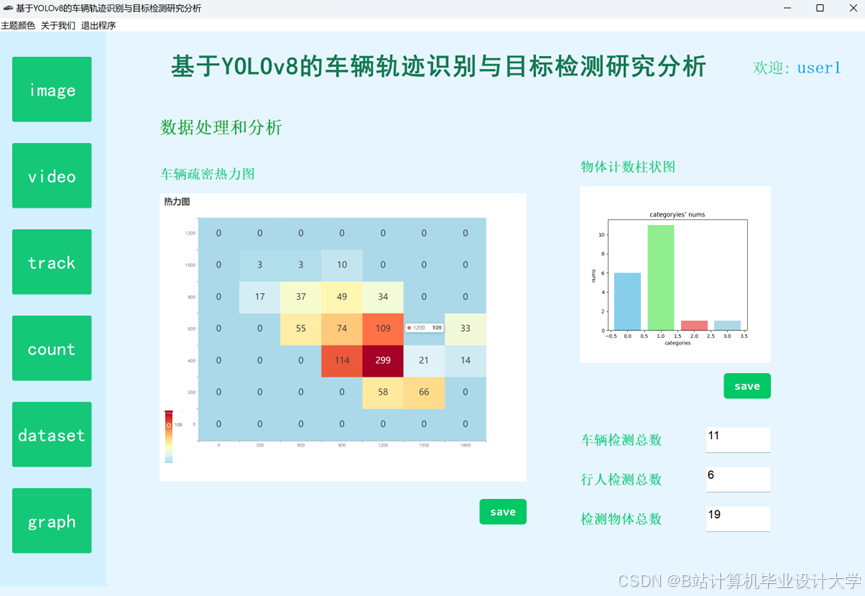
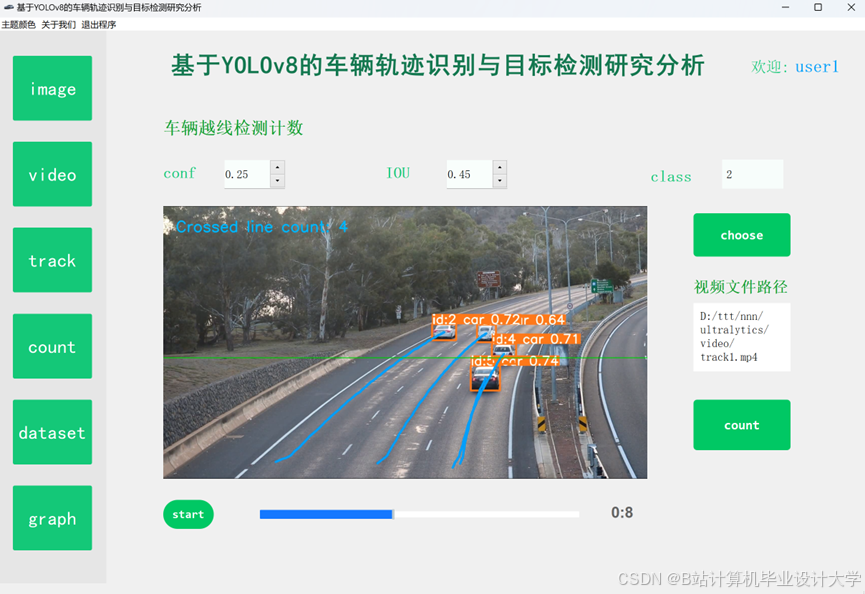
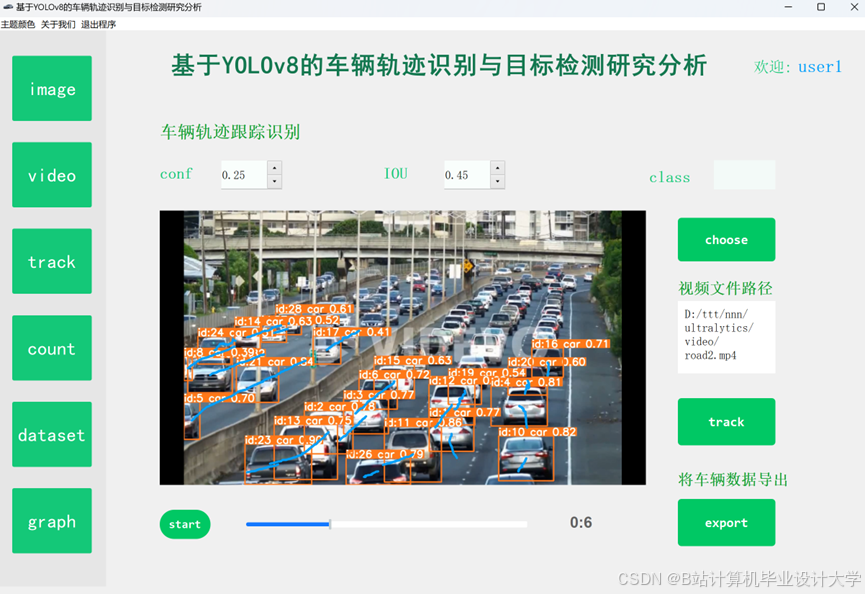
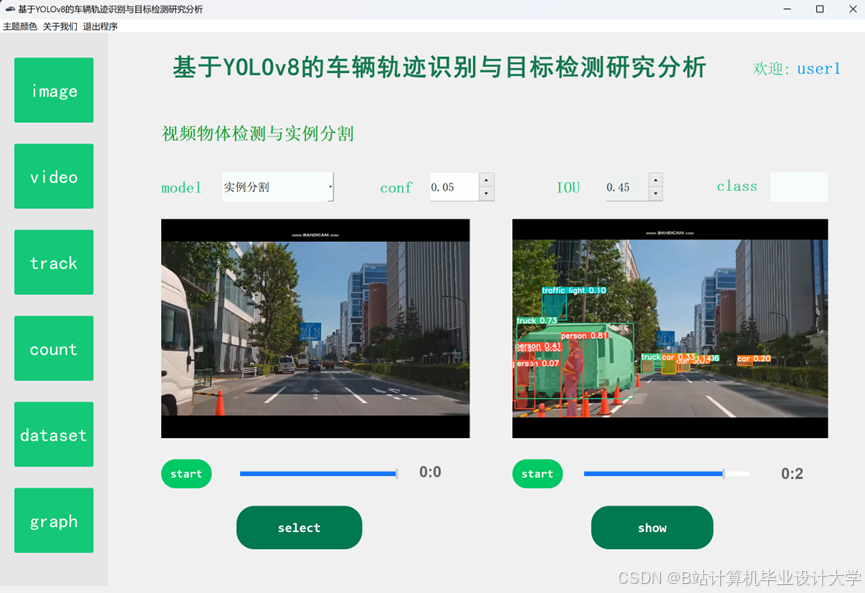
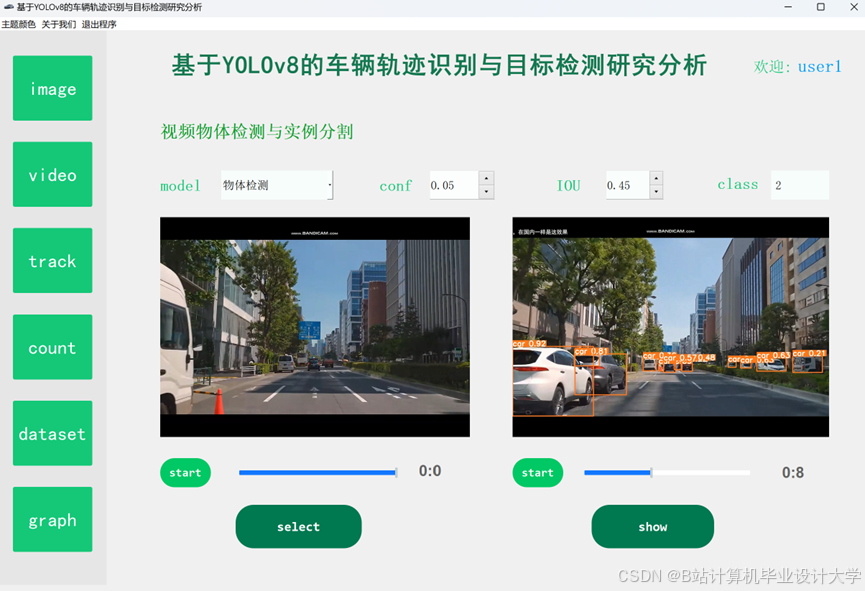
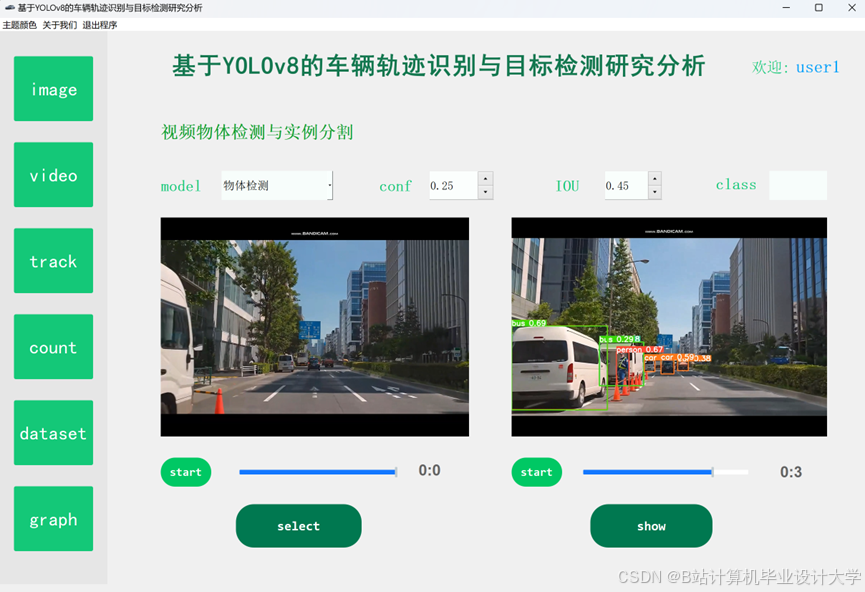
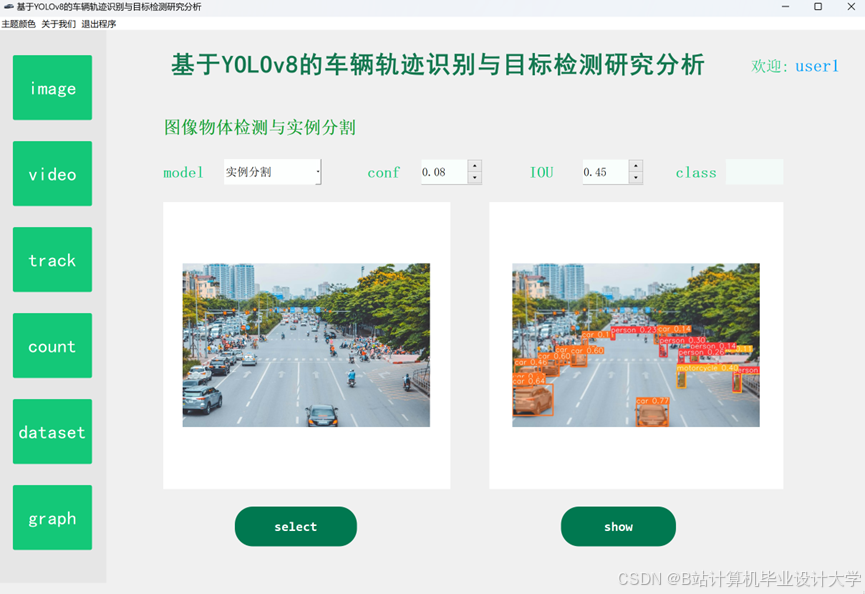
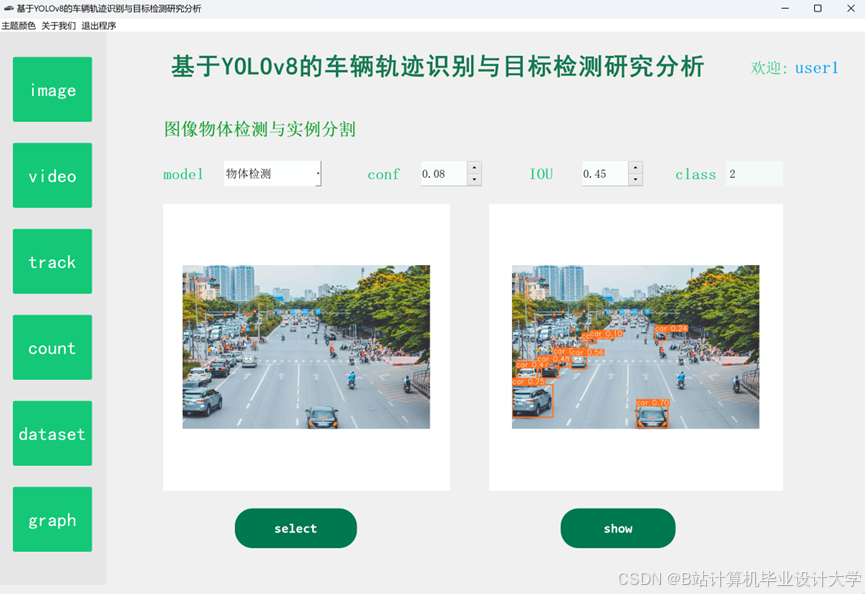
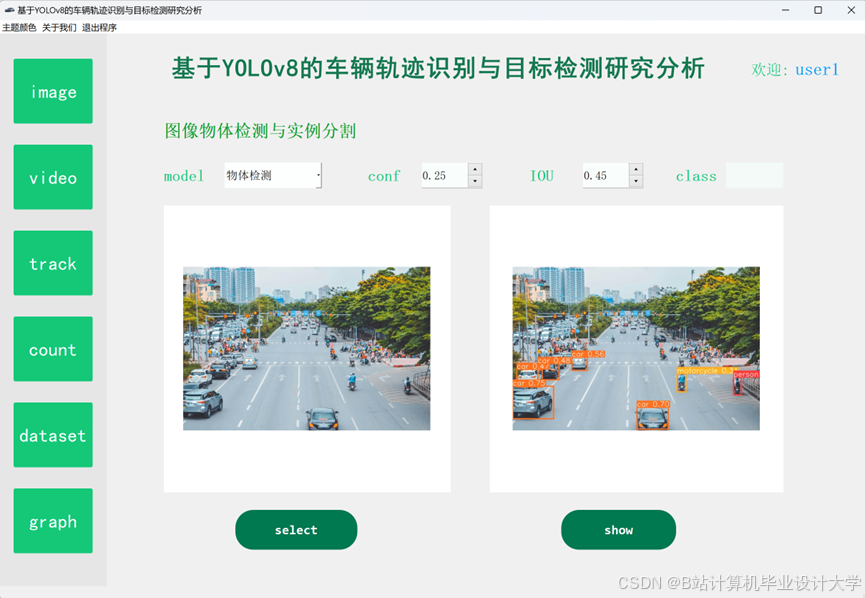
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











