




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档《基于Django与Vue.js的小说推荐系统开发指南》,包含系统架构、技术选型、核心模块实现及部署优化等内容,适合开发人员参考:
基于Django与Vue.js的小说推荐系统开发指南
技术目标:构建一个高并发、低延迟的小说推荐平台,支持用户行为分析、混合推荐算法及实时推荐更新。
1. 系统架构设计
1.1 前后端分离架构
- 前端:Vue.js 3.0 + Element UI + Axios
- 职责:小说列表渲染、推荐结果展示、用户交互(搜索/收藏/评分)。
- 通信:通过RESTful API与后端交互,数据格式为JSON。
- 后端:Django 4.2 + Django REST Framework (DRF)
- 职责:用户认证、数据存储、推荐算法实现、API服务。
- 扩展:使用Celery处理异步任务(如日志分析、定时推荐更新)。
- 数据库:
- MySQL 8.0:存储结构化数据(用户信息、小说元数据)。
- MongoDB 5.0:存储用户行为日志(点击、收藏、阅读时长)。
- Redis 6.2:缓存热门推荐结果、用户会话(Session)。
1.2 数据流图
mermaid
graph TD | |
A[用户操作] --> B[Vue.js前端] | |
B --> C{API请求} | |
C -->|GET /api/recommend/| D[Django后端] | |
C -->|POST /api/behavior/| D | |
D --> E[查询MySQL/MongoDB] | |
D --> F[调用推荐算法] | |
F --> G[从Redis获取缓存] | |
G -->|未命中| H[实时计算推荐] | |
H --> I[写入Redis缓存] | |
D --> J[返回JSON数据] | |
J --> B | |
B --> K[动态渲染页面] |
2. 核心模块实现
2.1 用户认证模块
- 技术方案:Django内置
django.contrib.auth+ JWT(JSON Web Token) - 关键代码:
python# views.py: JWT登录接口from rest_framework_simplejwt.views import TokenObtainPairViewfrom rest_framework.permissions import AllowAnyclass CustomTokenObtainPairView(TokenObtainPairView):permission_classes = [AllowAny]serializer_class = MyTokenObtainPairSerializer # 自定义序列化器(可扩展用户信息) - 前端调用:
javascript// login.js: 使用Axios发送登录请求axios.post('/api/token/', { username, password }).then(res => {localStorage.setItem('token', res.data.access);// 跳转到推荐页面});
2.2 推荐算法模块
2.2.1 混合推荐策略
-
协同过滤(Item-CF):
python# recommend/item_cf.pyfrom sklearn.metrics.pairwise import cosine_similarityimport numpy as npdef calculate_similarity(user_item_matrix):# 计算小说相似度矩阵item_sim = cosine_similarity(user_item_matrix.T)return item_simdef recommend_by_cf(user_id, item_sim, user_item_matrix, top_k=10):# 获取用户历史收藏的小说IDhist_items = np.where(user_item_matrix[user_id] > 0)[0]# 计算推荐分数scores = {}for item in hist_items:for sim_item, sim_score in enumerate(item_sim[item]):if sim_item not in hist_items:scores[sim_item] = scores.get(sim_item, 0) + sim_score# 返回Top-K推荐return sorted(scores.items(), key=lambda x: x[1], reverse=True)[:top_k] -
内容相似度:
python# recommend/content_based.pyfrom sklearn.feature_extraction.text import TfidfVectorizerdef extract_features(novels):# 使用TF-IDF向量化小说简介vectorizer = TfidfVectorizer(stop_words=['的', '是', '在'])tfidf_matrix = vectorizer.fit_transform([n.description for n in novels])return tfidf_matrix, vectorizerdef recommend_by_content(target_novel_id, tfidf_matrix, novels, top_k=5):# 计算目标小说与其他小说的余弦相似度target_vec = tfidf_matrix[target_novel_id]sim_scores = cosine_similarity(target_vec, tfidf_matrix).flatten()# 排除自身,返回相似度最高的Top-K小说sim_scores[target_novel_id] = -1 # 排除自身return sorted(enumerate(sim_scores), key=lambda x: x[1], reverse=True)[:top_k] -
混合权重分配:
python# recommend/hybrid.pydef hybrid_recommend(user_id, cf_score, content_score, alpha=0.7):# 动态调整权重(新用户降低CF权重)from django.contrib.auth.models import Useruser = User.objects.get(id=user_id)if user.behaviorlog_set.count() < 5: # 行为日志少于5条视为新用户alpha = 0.3# 加权融合分数final_scores = {}for item_id in set(cf_score.keys()) | set(content_score.keys()):cf = cf_score.get(item_id, 0)content = content_score.get(item_id, 0)final_scores[item_id] = alpha * cf + (1 - alpha) * contentreturn sorted(final_scores.items(), key=lambda x: x[1], reverse=True)[:10]
2.2.2 实时推荐优化
-
Redis缓存策略:
python# recommend/cache.pyimport redisfrom django.conf import settingsr = redis.Redis(host=settings.REDIS_HOST, port=6379, db=0)def get_cached_recommendations(user_id):cache_key = f"recommend:{user_id}"cached_data = r.get(cache_key)if cached_data:return eval(cached_data) # 注意:生产环境应使用JSON序列化return Nonedef set_cached_recommendations(user_id, recommendations, ttl=3600):cache_key = f"recommend:{user_id}"r.setex(cache_key, ttl, str(recommendations)) -
Flink流处理(可选):
若需实时分析用户点击行为,可部署Apache Flink集群,通过Kafka消费行为日志,动态更新推荐列表。
2.3 数据采集模块
-
用户行为跟踪:
javascript// behavior_tracker.js: 前端埋点代码document.querySelectorAll('.novel-item').forEach(item => {item.addEventListener('click', () => {const novelId = item.dataset.id;axios.post('/api/behavior/', {user_id: getCurrentUserId(), // 从本地存储获取novel_id: novelId,action: 'click',timestamp: new Date().toISOString()});});}); -
后端存储:
python# models.py: 行为日志模型from django.db import modelsfrom users.models import Userfrom novels.models import Novelclass BehaviorLog(models.Model):ACTION_CHOICES = [('click', '点击'),('collect', '收藏'),('rate', '评分'),]user = models.ForeignKey(User, on_delete=models.CASCADE)novel = models.ForeignKey(Novel, on_delete=models.CASCADE)action = models.CharField(max_length=10, choices=ACTION_CHOICES)timestamp = models.DateTimeField(auto_now_add=True)
3. 系统部署与优化
3.1 部署方案
- Docker容器化:
dockerfile# Dockerfile (Django后端)FROM python:3.9-slimWORKDIR /appCOPY requirements.txt .RUN pip install -r requirements.txt --no-cache-dirCOPY . .CMD ["gunicorn", "--bind", "0.0.0.0:8000", "config.wsgi:application"] - Kubernetes集群(高可用场景):
- 使用
Deployment管理Django/Vue.js容器。 - 通过
Service暴露API端口,配置Ingress实现域名访问。
- 使用
3.2 性能优化
- 数据库索引优化:
- 为
BehaviorLog表的user_id和novel_id字段添加复合索引。
sqlCREATE INDEX idx_behavior_user_novel ON novels_behaviorlog (user_id, novel_id); - 为
- API响应压缩:
- 在Nginx配置中启用Gzip压缩:
nginxgzip on;gzip_types application/json text/css application/javascript;
- 在Nginx配置中启用Gzip压缩:
- 异步任务处理:
- 使用Celery定时更新全站推荐缓存(如每天凌晨3点执行):
python# tasks.pyfrom celery import shared_taskfrom .recommend.hybrid import update_all_recommendations@shared_taskdef refresh_recommendations():update_all_recommendations() # 遍历所有用户,重新计算推荐
- 使用Celery定时更新全站推荐缓存(如每天凌晨3点执行):
4. 常见问题与解决方案
Q1:如何解决冷启动问题?
- 方案:
- 新用户默认推荐热门小说(按收藏量排序)。
- 引导用户选择兴趣标签(如“玄幻”“都市”),基于标签匹配推荐。
- 混合推荐中降低CF权重(如
alpha=0.3)。
Q2:如何防止推荐结果过度集中?
- 方案:
- 在推荐分数中加入多样性惩罚项:
pythondef diversity_penalty(scores, novel_tags, user_tags):for item_id, score in scores.items():novel_tag = novel_tags[item_id]if novel_tag in user_tags: # 用户已读过同类标签小说scores[item_id] *= 0.7 # 降低分数return scores - 限制同一作者或系列小说的推荐数量。
- 在推荐分数中加入多样性惩罚项:
Q3:如何扩展系统支持千万级用户?
- 方案:
- 数据库分库分表(如按用户ID哈希分片)。
- 推荐算法分布式化(使用Spark MLlib替代单机版Scikit-learn)。
- 引入CDN加速静态资源(Vue.js编译后的JS/CSS文件)。
附录:技术栈版本清单
| 组件 | 版本 | 用途 |
|---|---|---|
| Django | 4.2 | 后端框架 |
| Vue.js | 3.0 | 前端框架 |
| MySQL | 8.0 | 关系型数据库 |
| Redis | 6.2 | 缓存与会话存储 |
| Celery | 5.3 | 异步任务队列 |
| Gunicorn | 20.1 | WSGI服务器 |
| Nginx | 1.23 | 反向代理与负载均衡 |
备注:
- 实际开发中需结合公司技术规范调整代码风格(如PEP 8或Google Python Style Guide)。
- 推荐算法部分可根据业务需求替换为深度学习模型(如Wide & Deep、DIN)。
- 安全方面需增加SQL注入防护(Django ORM默认防护)、XSS过滤(Vue.js模板自动转义)。
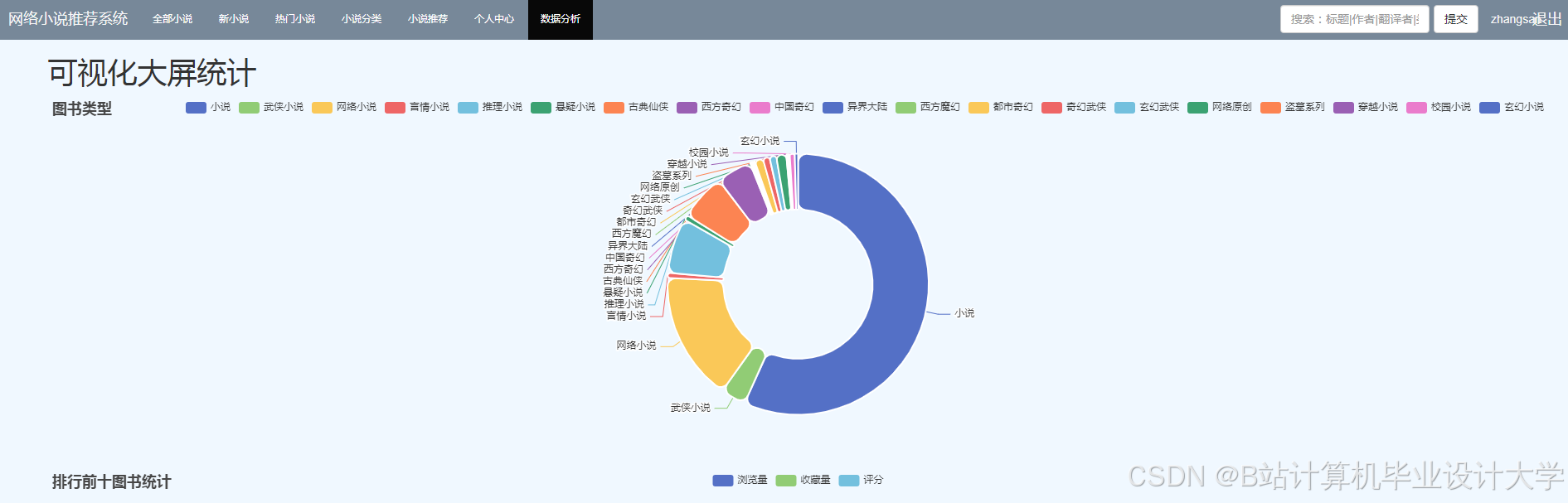
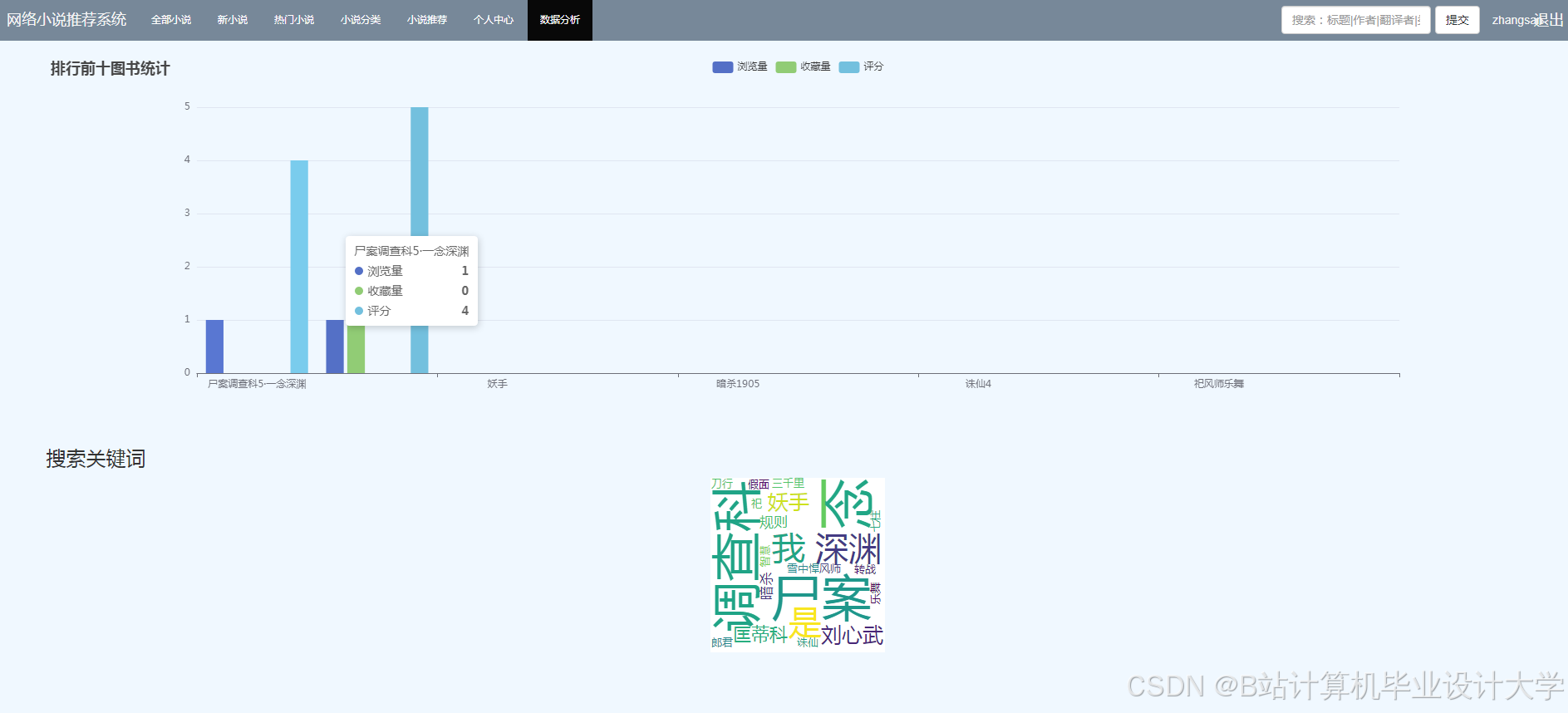
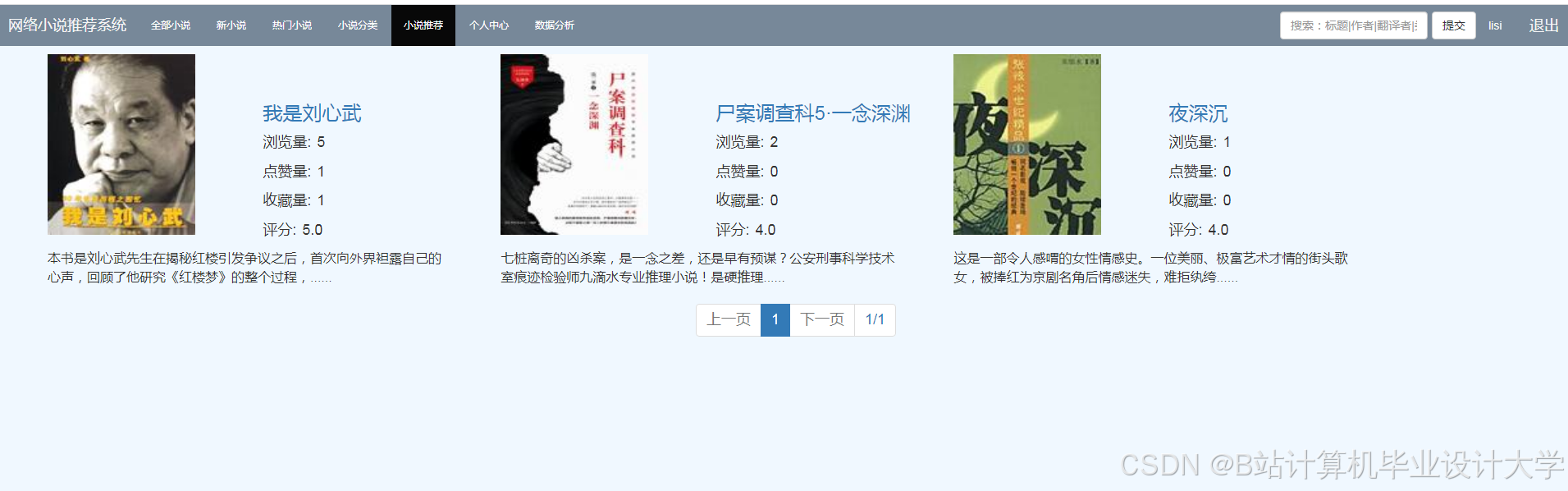
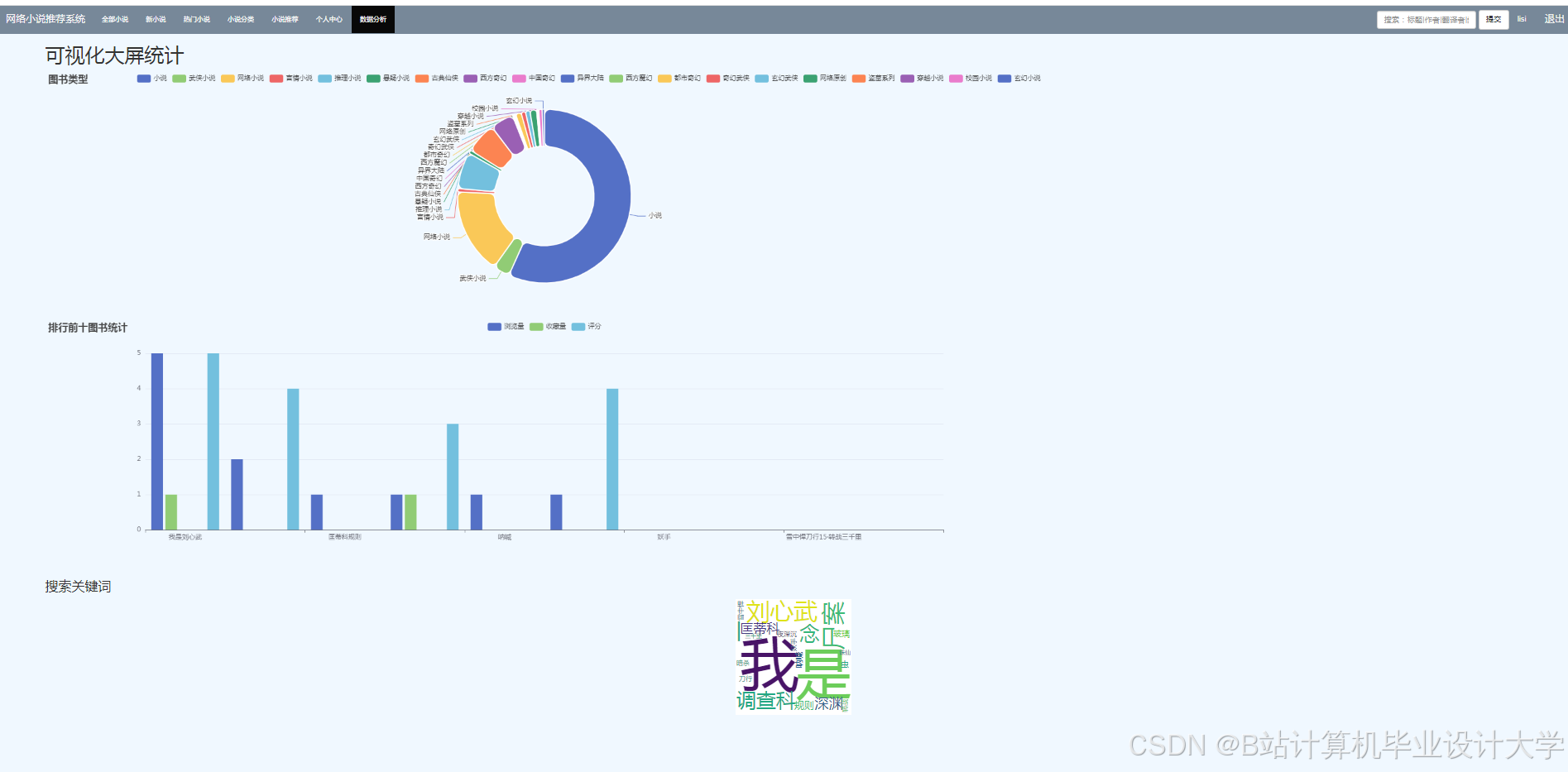
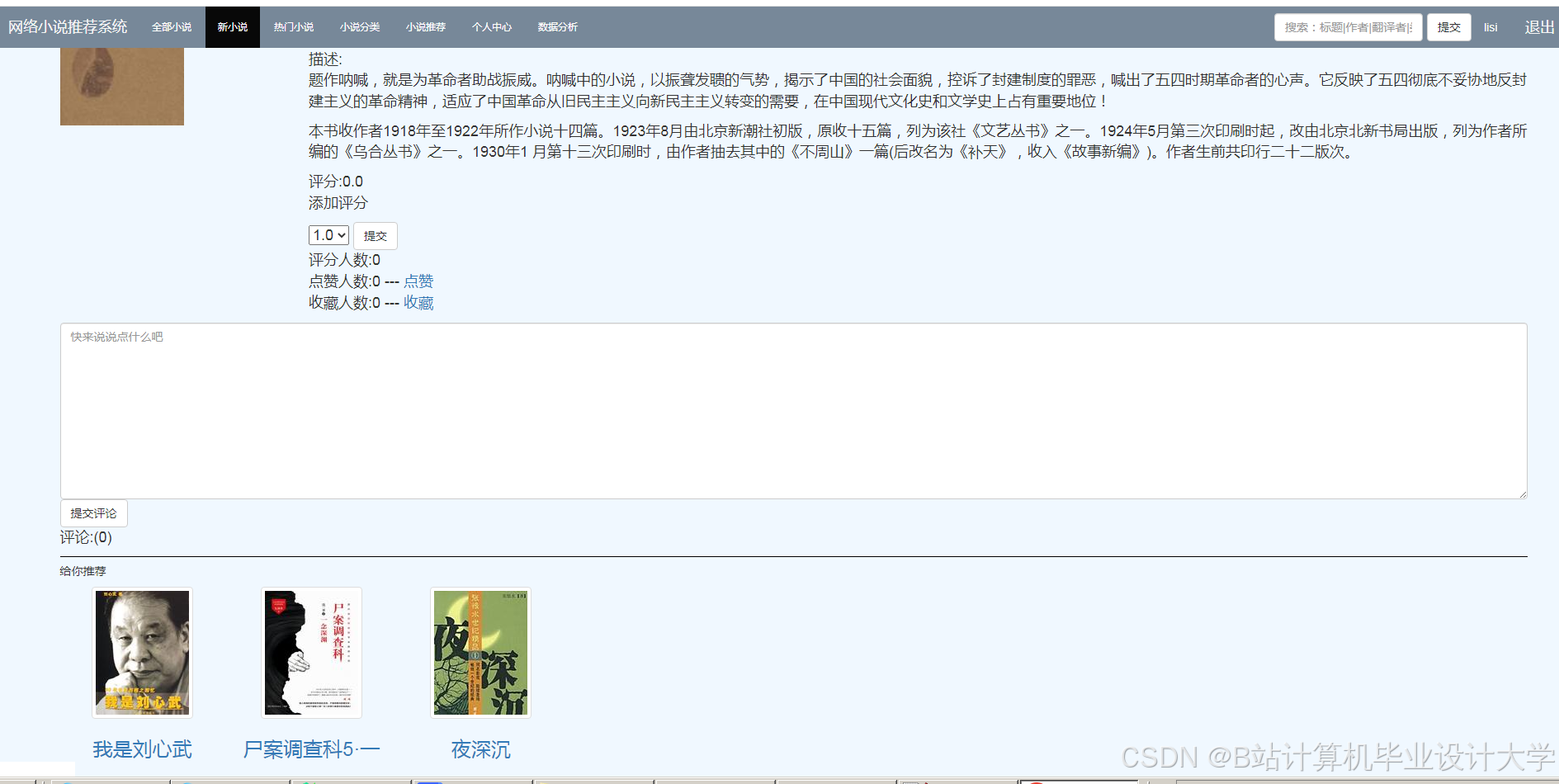
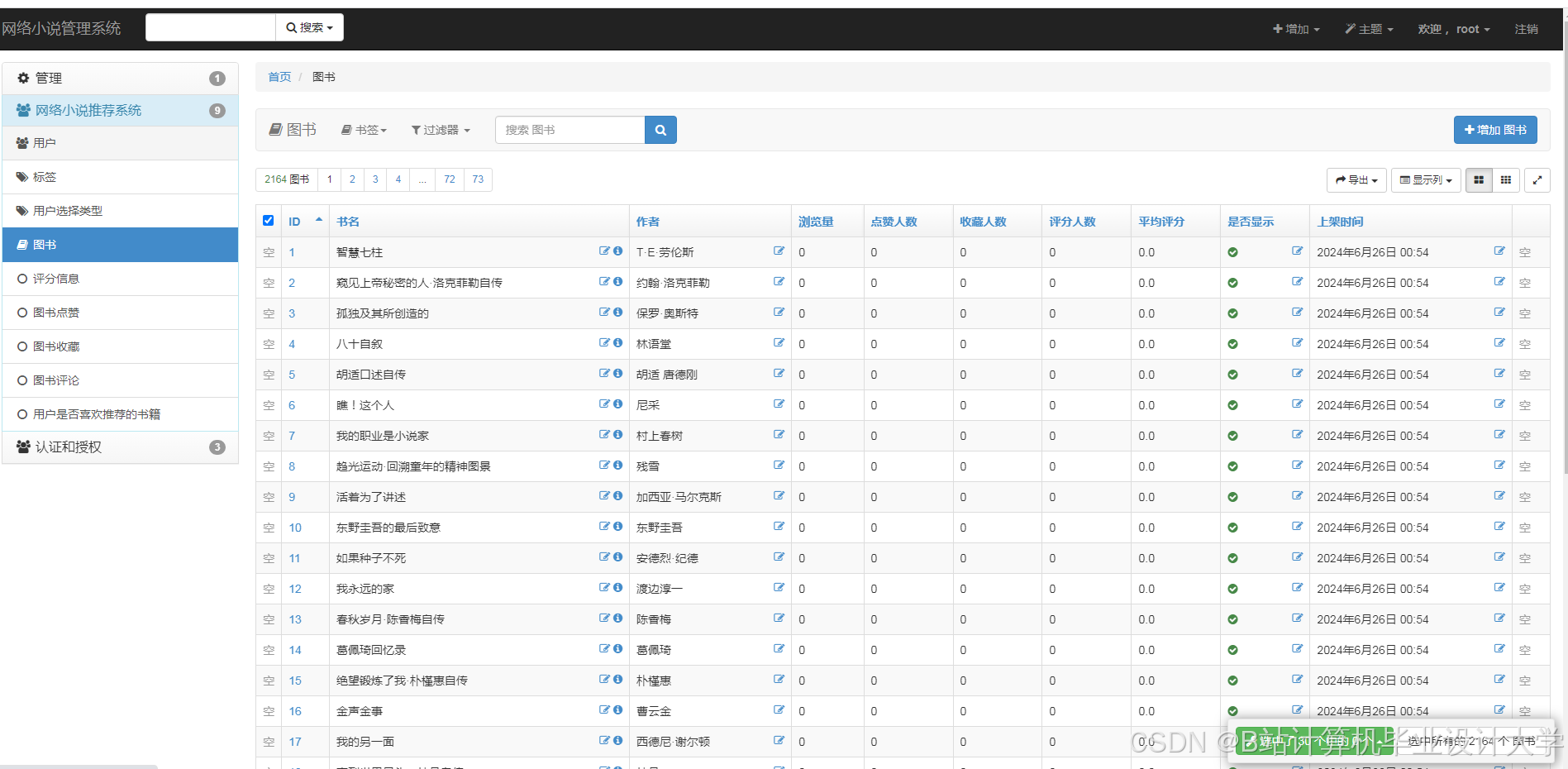
运行截图
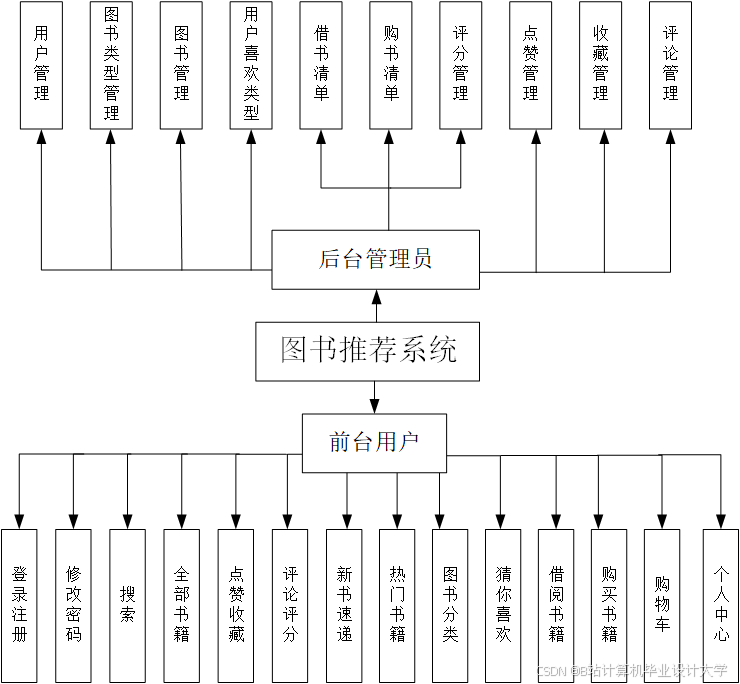
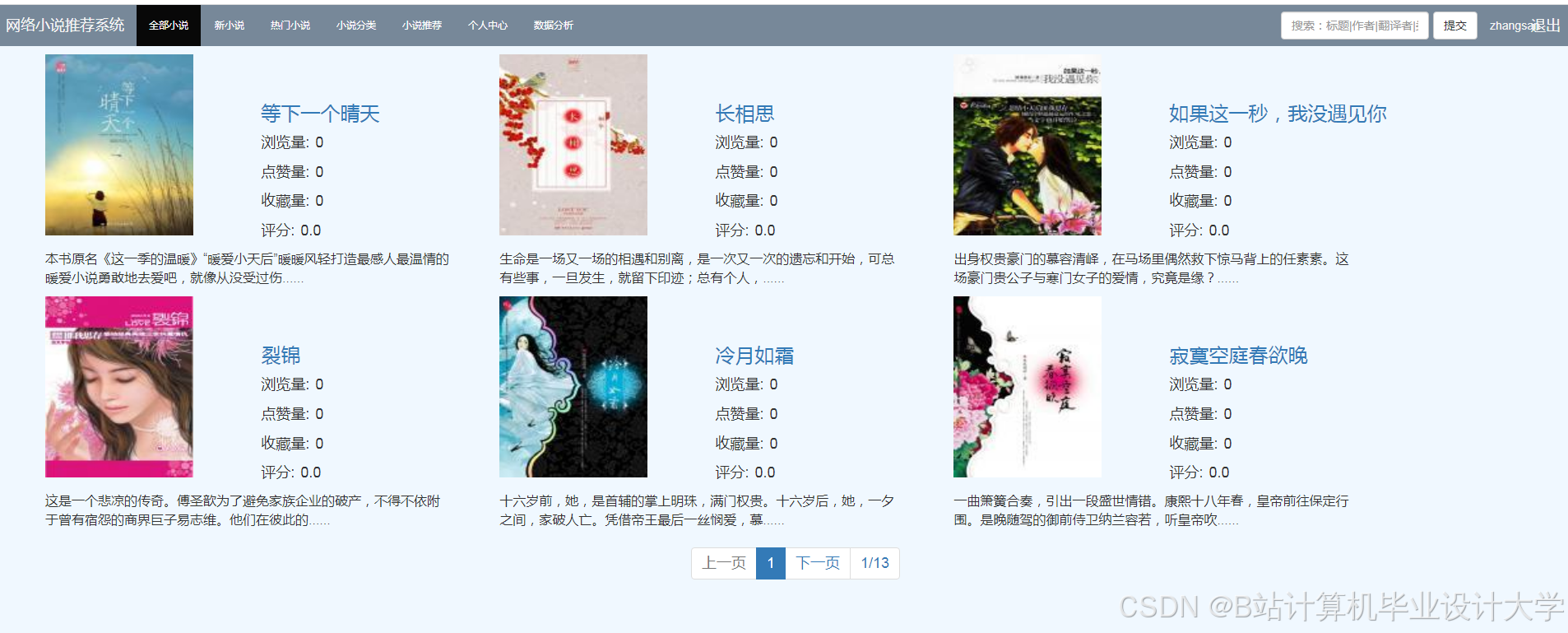



推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











