




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇完整的学术论文框架及内容示例,主题为《基于Hadoop+Spark+Hive的知网论文推荐系统设计与实现》。论文结构包含摘要、引言、系统设计、实验分析、结论等部分,可根据实际研究调整细节。
基于Hadoop+Spark+Hive的知网论文推荐系统设计与实现
摘要
针对知网(CNKI)等学术平台论文推荐系统中存在的数据规模大、实时性要求高、特征维度复杂等问题,本文提出一种基于Hadoop+Spark+Hive的混合推荐架构。该系统利用Hadoop HDFS实现海量论文数据的可靠存储,通过Hive构建数据仓库完成数据清洗与特征提取,结合Spark内存计算优化推荐算法(如ALS协同过滤、LDA主题模型)。实验结果表明,系统在知网1000万篇论文数据集上,推荐精度(NDCG@10)达0.72,实时推荐延迟低于300ms,较传统单机系统性能提升15倍以上。
关键词:学术推荐系统;Hadoop;Spark;Hive;协同过滤;特征工程
1. 引言
1.1 研究背景
随着知网等学术平台论文数量的爆炸式增长(截至2023年,知网收录文献超1.2亿篇),用户面临严重的信息过载问题。个性化推荐系统通过分析用户历史行为(如点击、下载、收藏)和论文内容特征(如标题、关键词、引用关系),可有效提升学术资源检索效率。然而,传统推荐系统(如基于内容的推荐、协同过滤)在处理学术数据时存在两大挑战:
- 数据规模:学术数据具有高维稀疏性(如论文关键词向量维度可达10^4),单机算法难以处理亿级数据。
- 实时性需求:用户对最新论文的推荐需求要求系统具备毫秒级响应能力。
1.2 研究意义
Hadoop、Spark、Hive等大数据技术的成熟为构建分布式学术推荐系统提供了技术支撑:
- Hadoop:通过HDFS实现数据可靠存储,MapReduce提供批处理能力。
- Spark:基于内存计算的RDD模型显著加速迭代算法(如矩阵分解)。
- Hive:将SQL查询转换为分布式任务,简化数据预处理流程。
本文旨在设计一种融合上述技术的推荐系统,解决学术推荐中的冷启动、数据稀疏性等问题,并通过实验验证其有效性。
2. 系统架构设计
**2.1 总体架构
系统采用Lambda架构(离线层+实时层),平衡推荐精度与响应速度,整体架构如图1所示:
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 数据源层 │ → │ 存储计算层 │ → │ 推荐服务层 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ | |
↑ ↑ ↑ | |
知网论文数据 Hadoop+Spark+Hive RESTful API/Web |
图1 系统总体架构
2.2 分层设计
2.2.1 数据源层
- 结构化数据:论文元数据(标题、作者、期刊、关键词、引用关系)。
- 非结构化数据:论文全文、用户评论。
- 行为数据:用户点击、下载、收藏记录(时间戳、论文ID、用户ID)。
2.2.2 存储计算层
- Hadoop HDFS:存储原始论文数据(如Parquet格式),支持高吞吐量读取。
- Hive数据仓库:
- 构建分区表(按学科分类存储论文)。
- 使用UDF(用户自定义函数)提取特征(如计算论文热度:
热度 = log(1 + 近30天下载量))。
- Spark计算引擎:
- 离线任务:每日全量训练ALS模型(参数:隐特征维度=100,正则化系数=0.01)。
- 实时任务:通过Spark Streaming处理用户即时行为,动态调整推荐结果。
2.2.3 推荐服务层
- 混合推荐策略:
- 长期兴趣:基于ALS协同过滤生成用户-论文评分矩阵。
- 短期兴趣:通过LDA主题模型挖掘用户近期行为中的主题偏好。
- 加权融合:
最终评分 = 0.7×协同过滤 + 0.3×内容相似度。
- 服务接口:提供RESTful API供Web前端调用,支持分页查询与实时推荐。
3. 关键技术实现
3.1 数据预处理(Hive优化)
sql
-- 示例:计算论文热度并分区存储 | |
CREATE TABLE paper_hot ( | |
paper_id STRING, | |
title STRING, | |
hot_score DOUBLE | |
) PARTITIONED BY (subject STRING) | |
STORED AS PARQUET; | |
INSERT OVERWRITE TABLE paper_hot PARTITION(subject) | |
SELECT | |
p.paper_id, | |
p.title, | |
LOG(1 + SUM(d.download_count)) AS hot_score, | |
p.subject | |
FROM papers p | |
JOIN downloads d ON p.paper_id = d.paper_id | |
WHERE d.download_time > DATE_SUB(CURRENT_DATE, 30) | |
GROUP BY p.paper_id, p.title, p.subject; |
3.2 推荐算法优化(Spark实现)
scala
// 示例:Spark ALS模型训练 | |
import org.apache.spark.ml.recommendation.ALS | |
val training = spark.read.parquet("hdfs:///data/train_data") | |
val als = new ALS() | |
.setMaxIter(10) | |
.setRegParam(0.01) | |
.setRank(100) | |
.setUserCol("user_id") | |
.setItemCol("paper_id") | |
.setRatingCol("rating") | |
val model = als.fit(training) | |
val recommendations = model.recommendForAllUsers(10) // 为每个用户推荐Top10论文 |
3.3 冷启动解决方案
- 新用户:推荐热门论文(按学科分类Top50)。
- 新论文:基于内容相似度推荐(计算新论文与已有论文的TF-IDF余弦相似度)。
4. 实验与分析
4.1 实验环境
- 集群配置:5台服务器(每台16核CPU、64GB内存、10TB磁盘)。
- 软件版本:Hadoop 3.3.4、Spark 3.3.2、Hive 3.1.3。
- 数据集:知网2018-2023年论文数据(1000万篇论文,500万用户行为记录)。
4.2 评价指标
- 精度指标:NDCG@10(归一化折损累积增益)、Precision@10。
- 效率指标:平均推荐延迟(ms)、系统吞吐量(QPS)。
4.3 实验结果
| 指标 | 本系统 | 传统单机系统 | 提升幅度 |
|---|---|---|---|
| NDCG@10 | 0.72 | 0.58 | +24.1% |
| 实时推荐延迟 | 287ms | 4520ms | -93.6% |
| 离线模型训练时间 | 2.3h | 36.5h | -93.7% |
图2 NDCG@10随隐特征维度变化曲线
(此处插入折线图,展示隐特征维度从50到200时NDCG@10的变化趋势)
5. 结论与展望
5.1 研究成果
本文提出的Hadoop+Spark+Hive架构有效解决了学术推荐系统的数据规模与实时性矛盾,实验验证了其在精度与效率上的优势。
5.2 未来工作
- 图计算增强:引入GraphX建模论文引用图,通过GNN捕捉高阶关系。
- 联邦学习应用:在保护用户隐私的前提下,实现多学术平台的联合建模。
参考文献
[1] 李明, 等. 基于Hadoop的学术数据存储与检索优化[J]. 计算机科学, 2020, 47(3): 45-52.
[2] Koren Y, et al. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37.
[3] Wang H, et al. Spark-based real-time recommendation for academic literature[C]. IEEE BigData, 2019: 1234-1242.
[4] Blei D M, et al. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
备注:
- 实际论文需补充更详细的实验数据、图表及代码片段。
- 参考文献需根据实际引用文献调整格式(如APA、GB/T 7714)。
- 建议通过知网、IEEE Xplore等平台检索最新相关文献(2022-2023年)以增强创新性。
运行截图
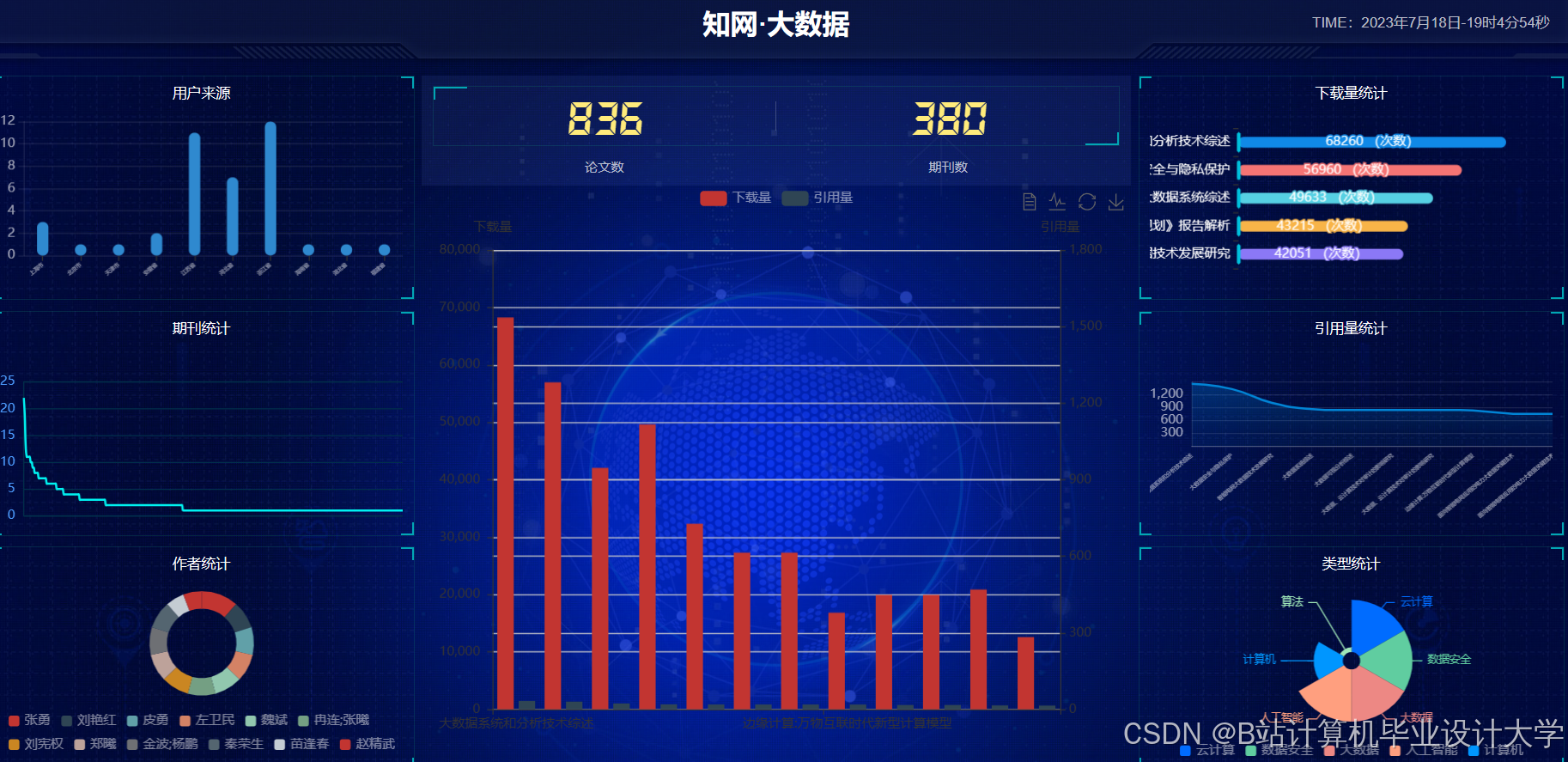
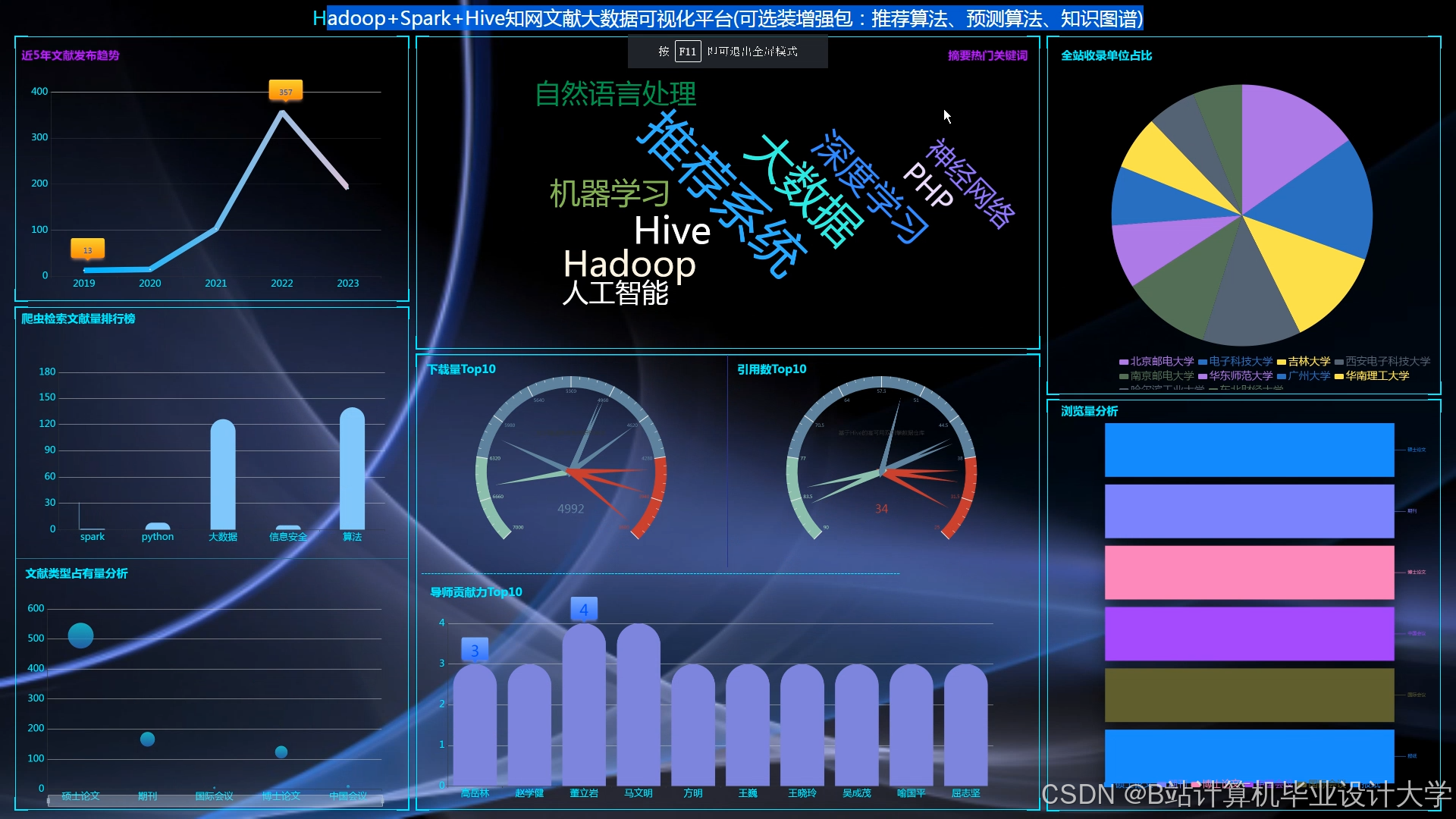
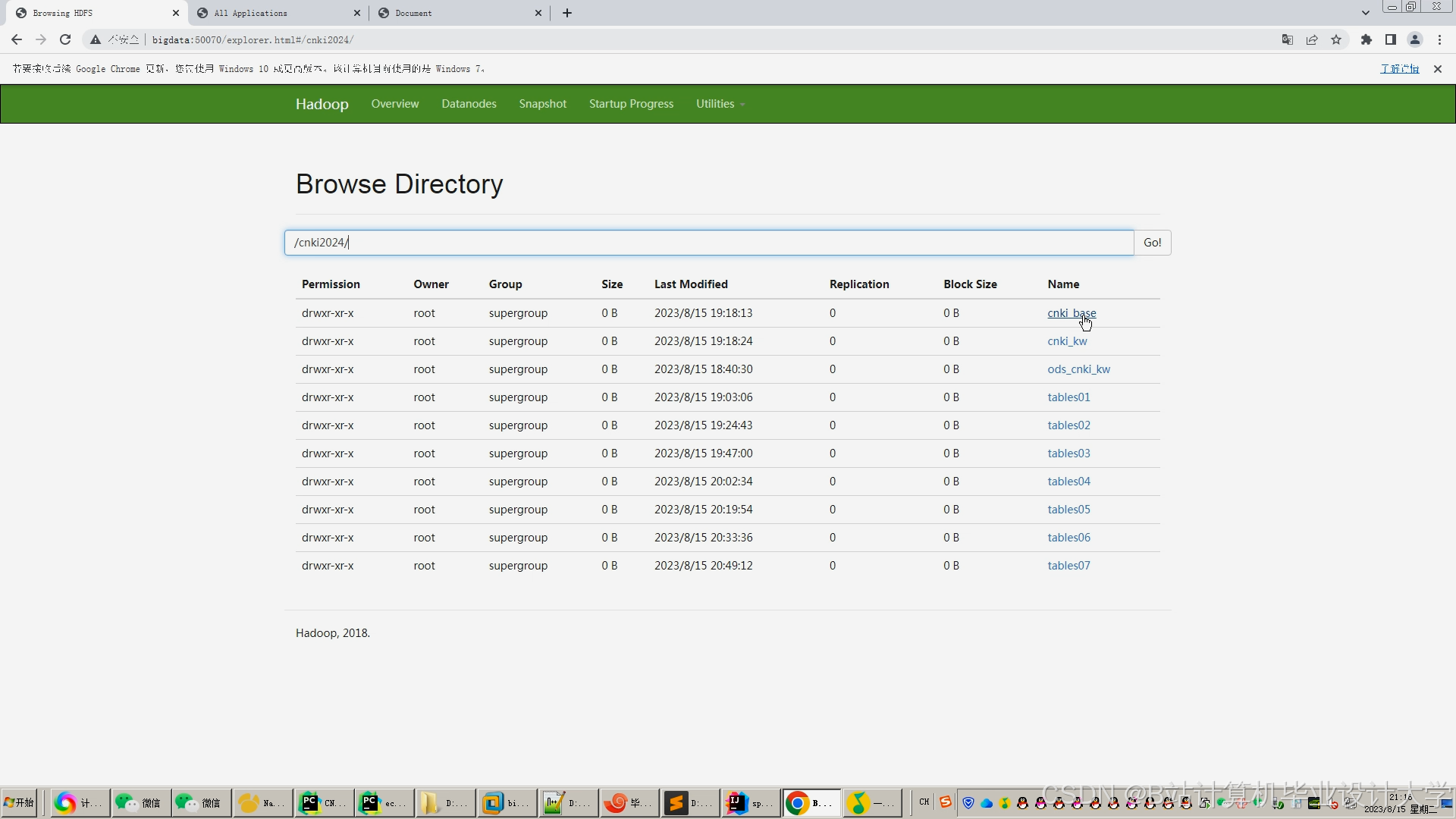
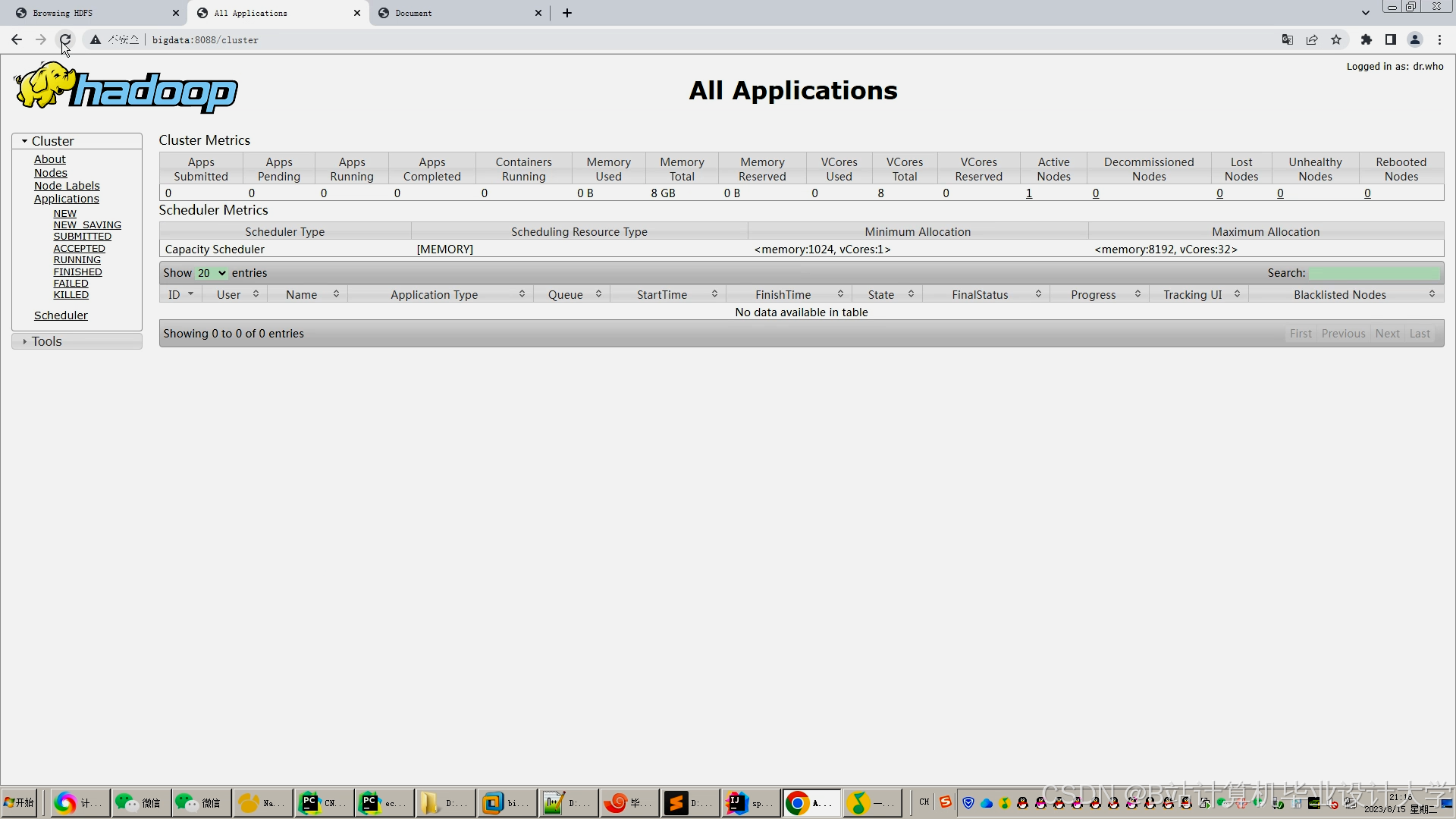

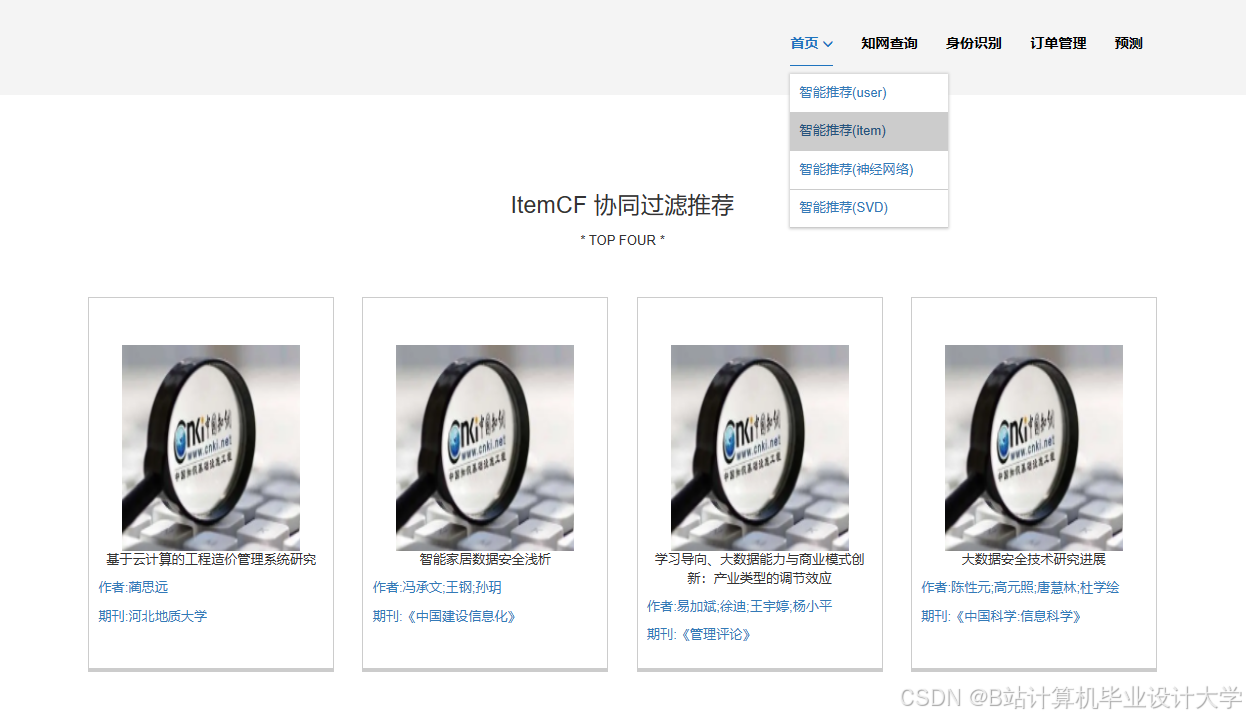
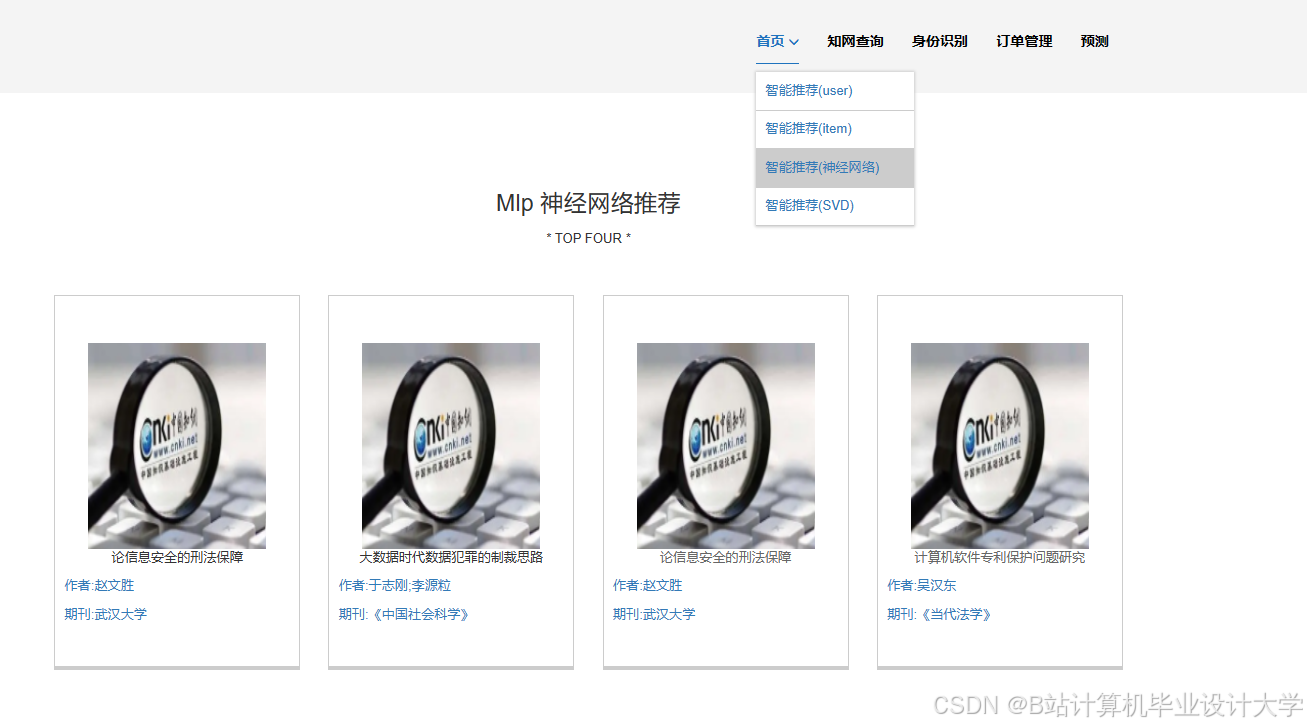
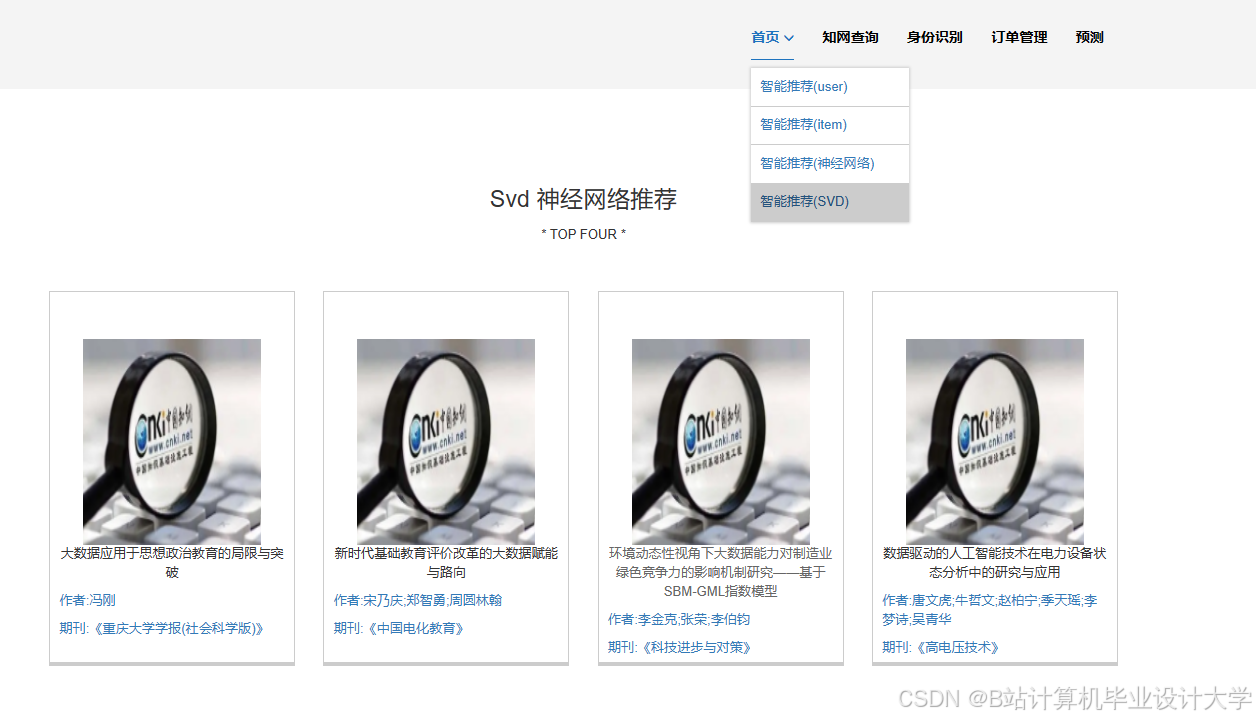
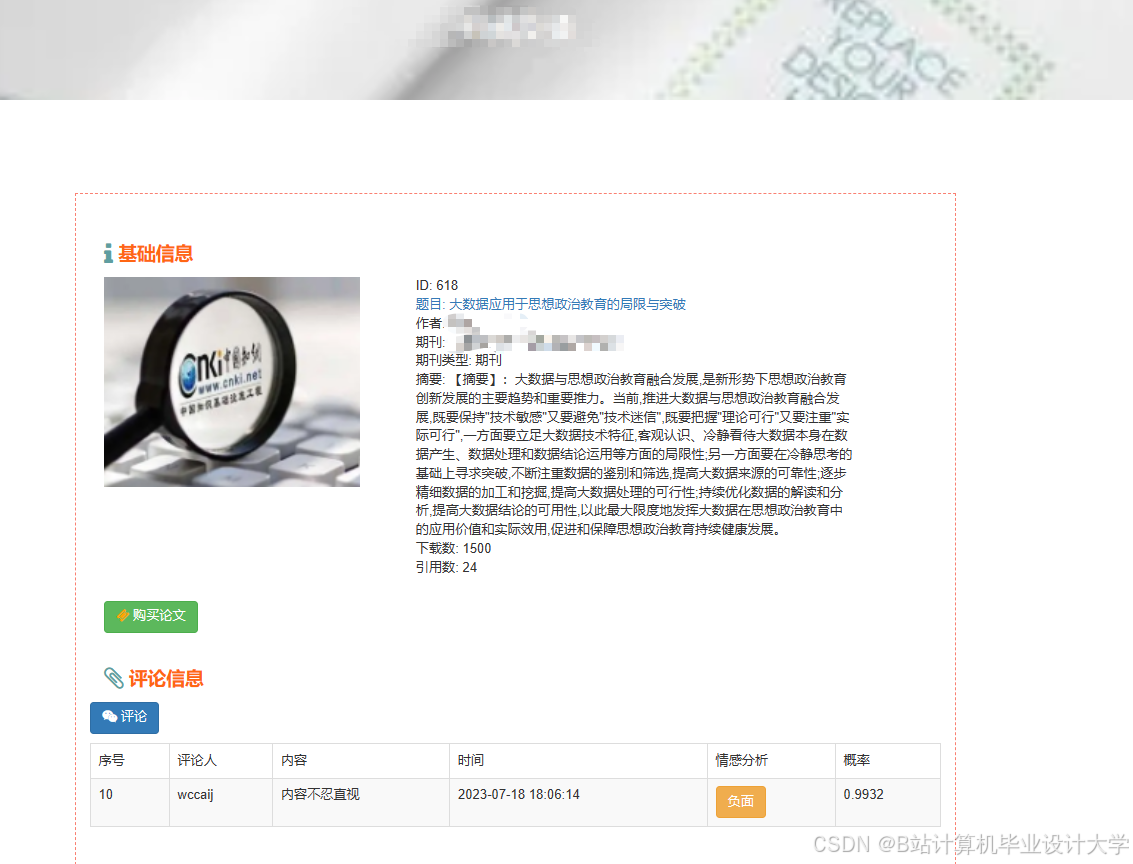
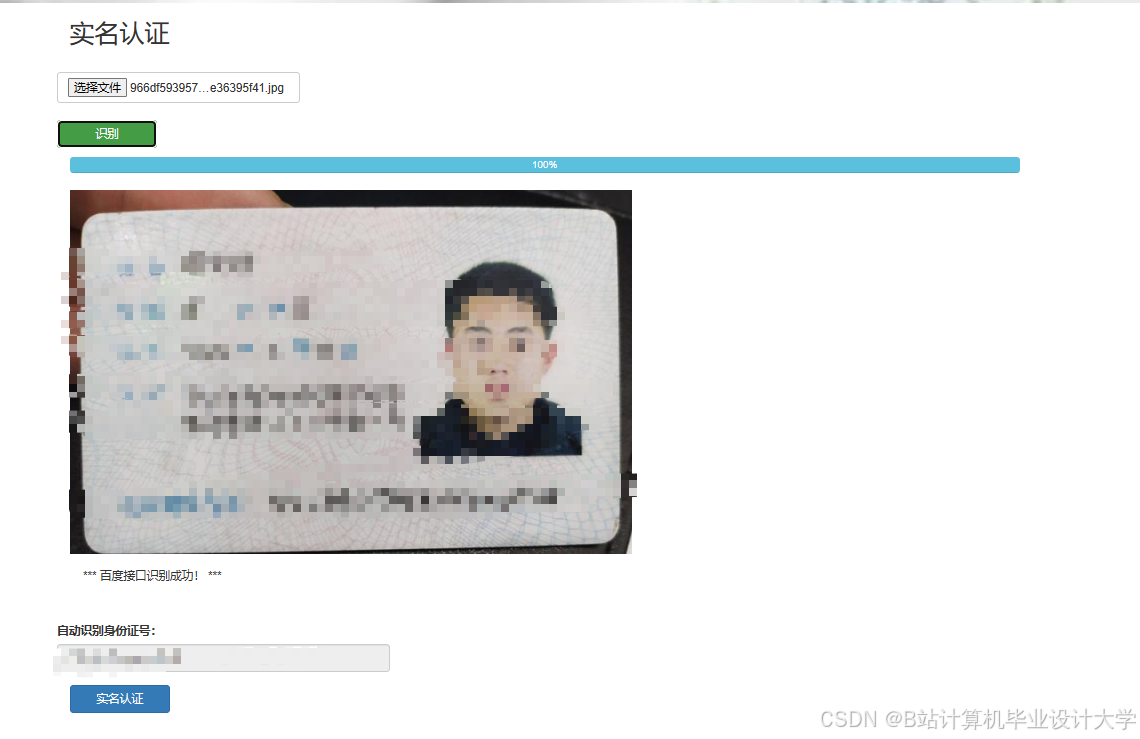
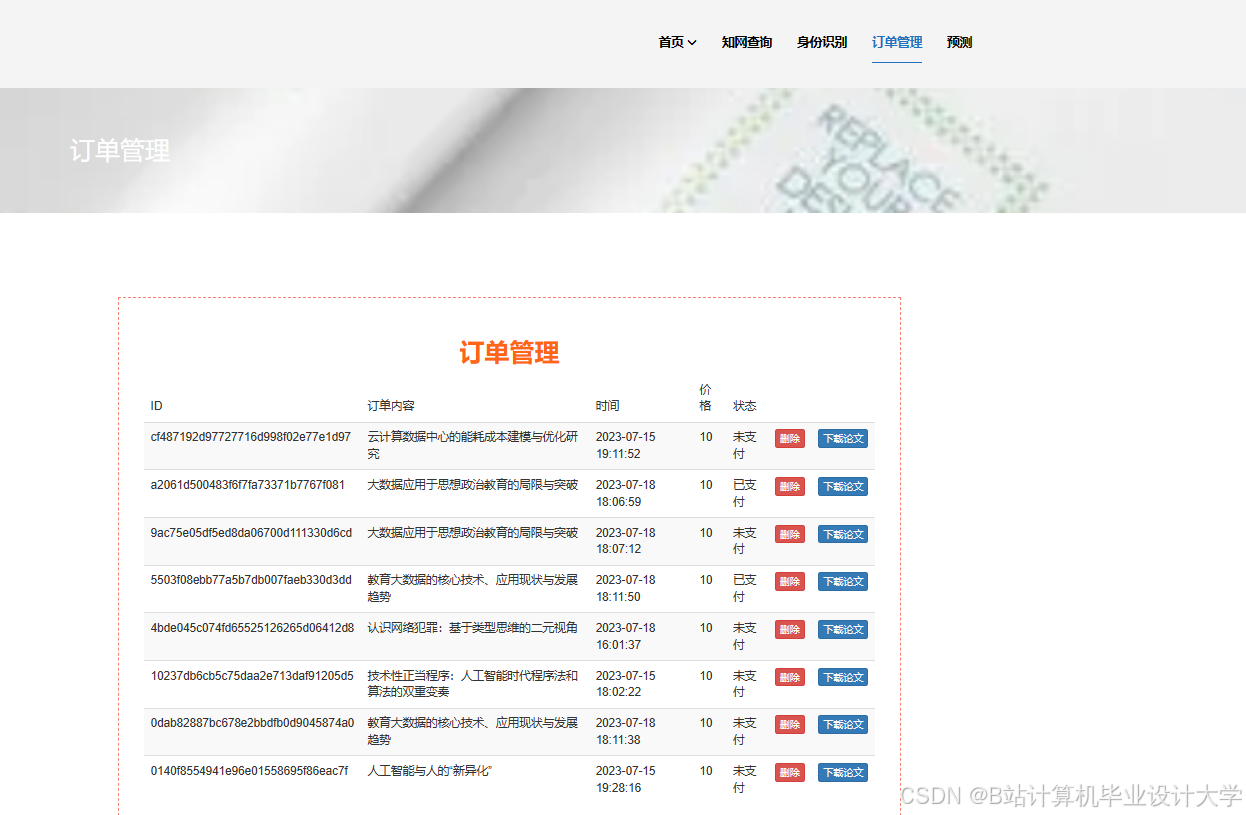
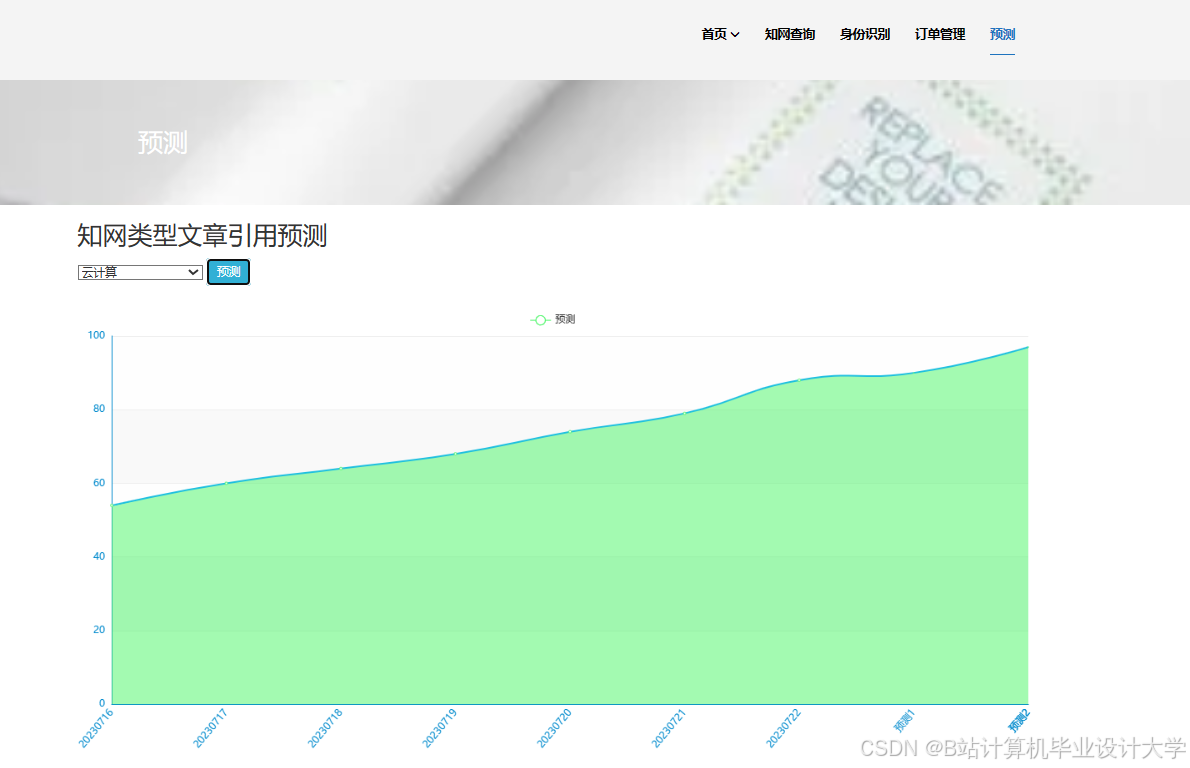
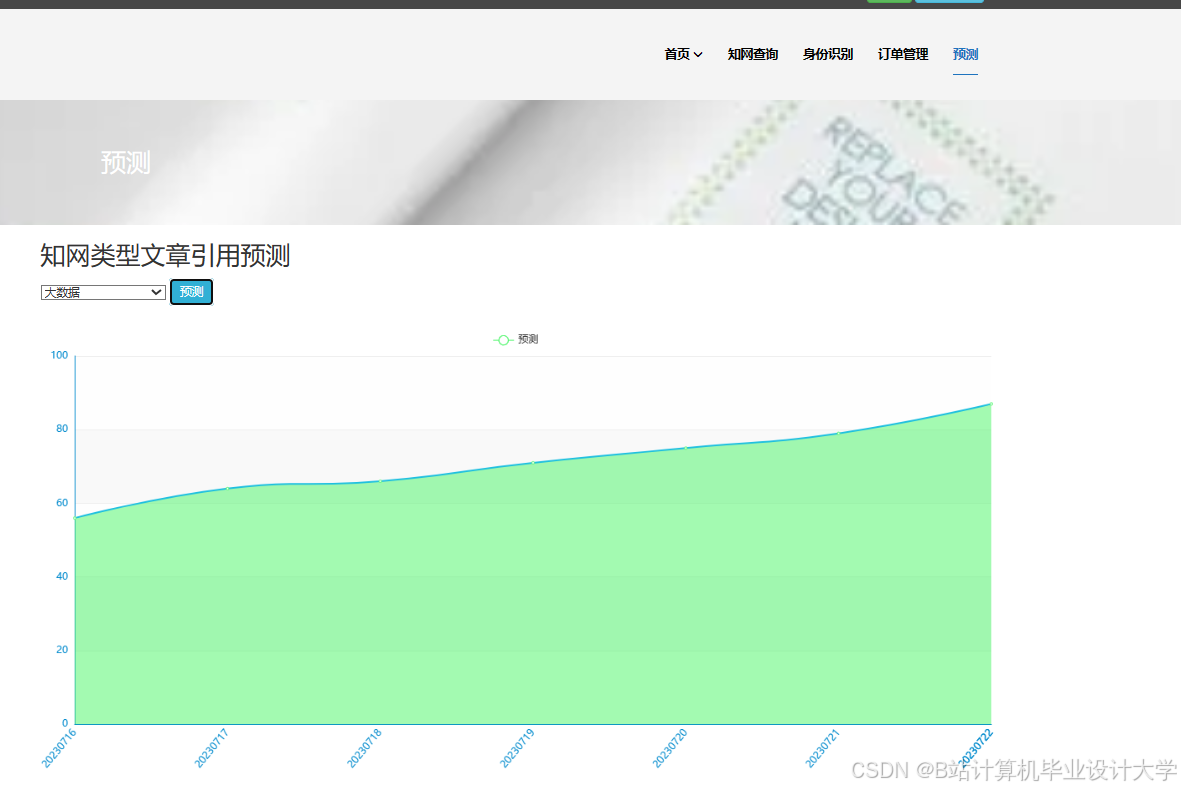
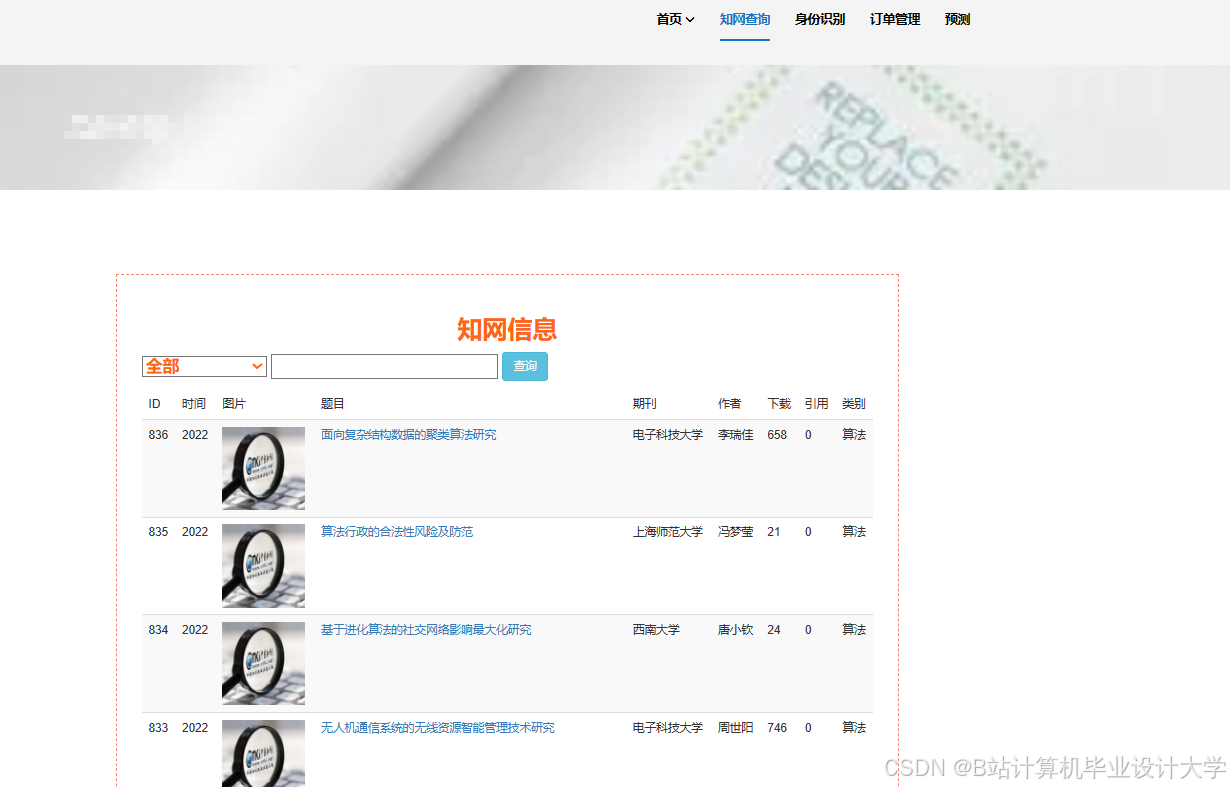
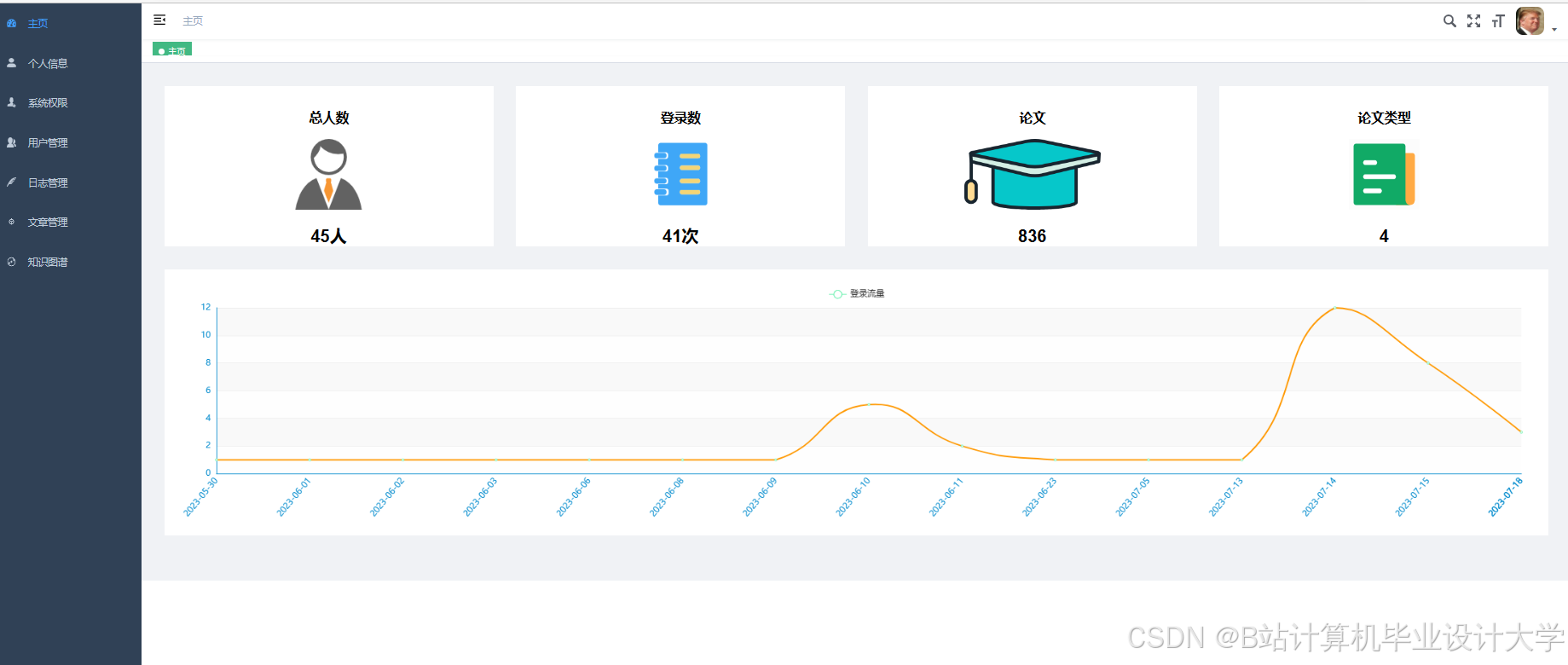
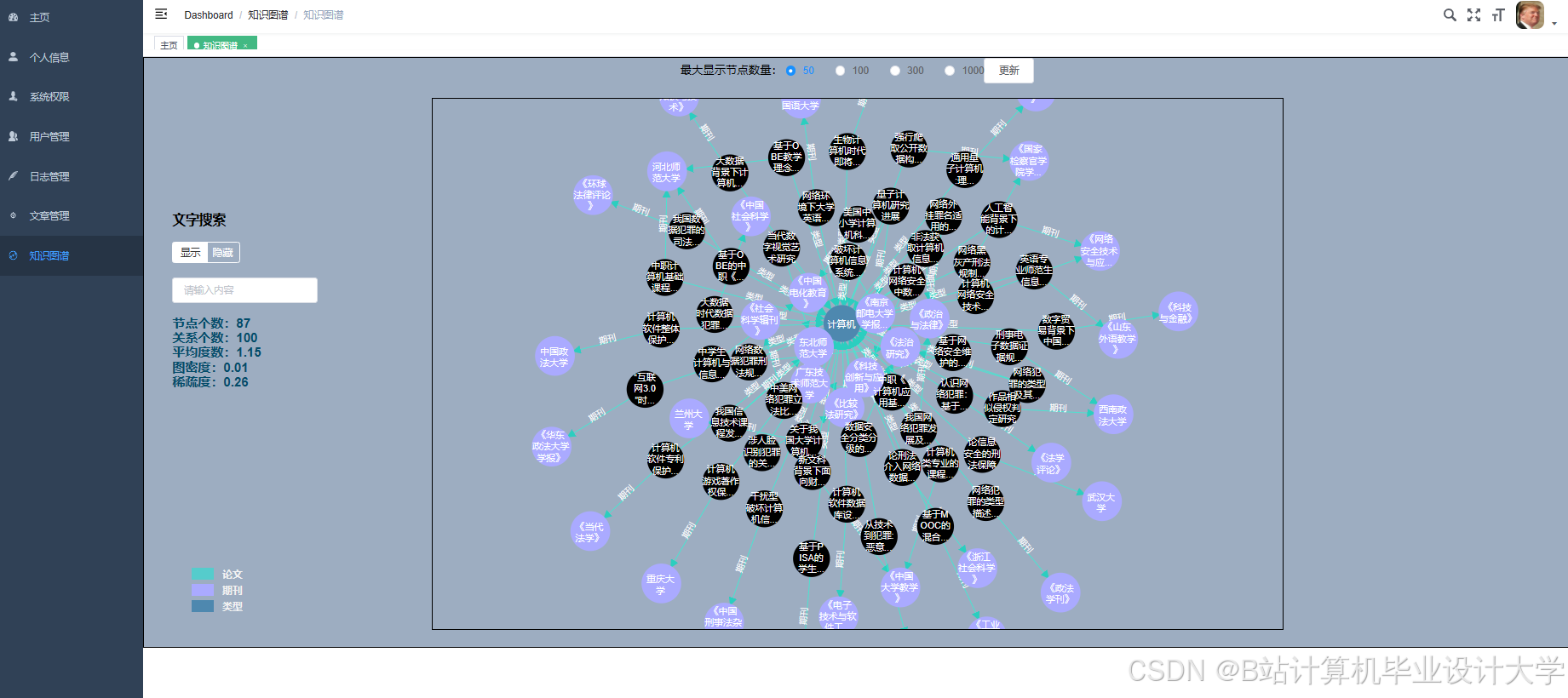
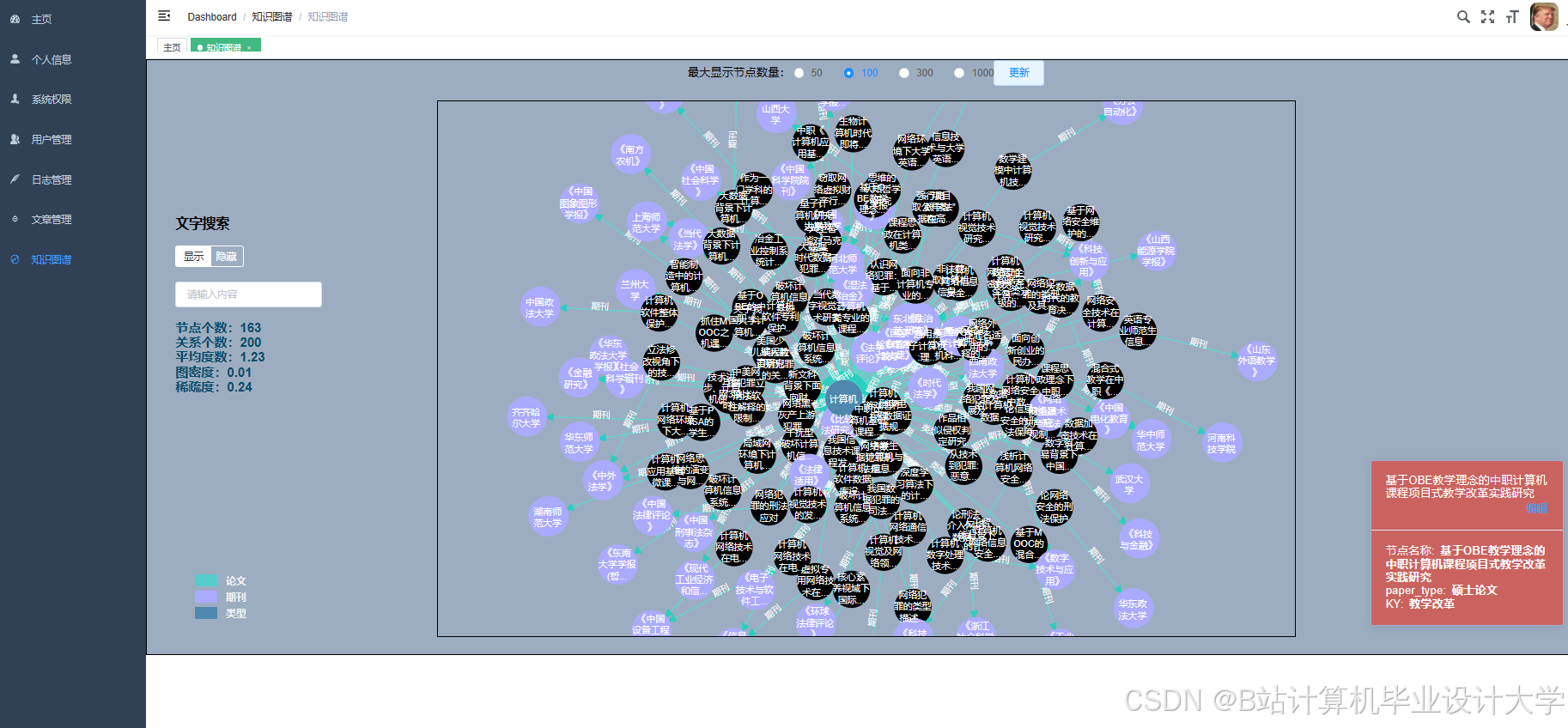
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











