




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇完整的学术论文框架及内容示例,主题为《基于Hadoop+Spark+Hive的智慧交通客流量预测系统设计与实现》。论文包含理论分析、技术实现与实验验证,符合学术规范,可根据实际需求调整细节。
基于Hadoop+Spark+Hive的智慧交通客流量预测系统设计与实现
摘要
针对城市轨道交通客流量预测中数据规模大、时空依赖性强、实时性要求高等挑战,本文提出一种基于Hadoop+Spark+Hive的分布式预测系统。系统通过Hive构建多源异构数据仓库,利用Spark进行高效特征工程与模型训练,结合LSTM-Attention深度学习模型捕捉时空动态性。实验结果表明,系统在广州地铁数据集上平均绝对百分比误差(MAPE)为7.8%,较传统XGBoost模型提升30%,且支持每5分钟实时预测,验证了其有效性与实用性。
关键词:智慧交通,客流量预测,Hadoop,Spark,Hive,LSTM-Attention
1. 引言
1.1 研究背景
随着城市化进程加速,城市轨道交通客流量呈现爆发式增长(如2023年北京地铁日均客流量超1200万人次)。精准预测客流量是优化列车调度、缓解拥堵、提升乘客体验的核心问题。然而,传统预测方法(如ARIMA、SARIMA)存在以下局限:
- 数据规模限制:无法处理PB级历史数据与实时流数据;
- 时空依赖建模不足:难以捕捉站点间空间关联与周期性时间模式;
- 外部因素融合困难:如天气、节假日等变量需复杂特征工程。
1.2 研究意义
大数据技术(Hadoop、Spark、Hive)与深度学习的融合为解决上述问题提供了新范式:
- 分布式存储与计算:Hadoop HDFS与Spark内存计算支持海量数据高效处理;
- 多源数据融合:Hive数据仓库整合刷卡记录、GPS轨迹、天气等异构数据;
- 复杂模型训练:Spark MLlib与TensorFlow集成实现LSTM、图神经网络(GNN)等深度学习模型的分布式训练。
1.3 论文贡献
- 设计一种分层架构的智慧交通预测系统,涵盖数据层、计算层、模型层与应用层;
- 提出一种基于Spark的特征工程优化方法,通过并行计算加速时空特征提取;
- 验证LSTM-Attention模型在客流量预测中的有效性,对比XGBoost、SVR等基线模型;
- 在真实数据集上实现端到端部署,支持实时预测与可视化展示。
2. 相关技术综述
2.1 Hadoop生态体系
- HDFS:主从架构分布式文件系统,支持数据分块与冗余存储;
- YARN:资源管理器,动态分配集群计算资源;
- Hive:基于Hadoop的数据仓库工具,通过SQL-like查询(HQL)实现数据清洗与聚合。
2.2 Spark内存计算框架
- RDD(弹性分布式数据集):支持容错与并行操作,加速特征工程(如
groupBy、reduceByKey); - GraphX:图计算库,用于分析站点拓扑关系(如最短路径、中心性指标);
- Structured Streaming:微批处理引擎,支持实时特征更新(如当前在途乘客数)。
2.3 深度学习模型
- LSTM(长短期记忆网络):通过门控机制解决传统RNN的梯度消失问题,适合时间序列预测;
- Attention机制:动态分配权重,突出关键时间步或空间节点的影响;
- STGNN(时空图神经网络):结合GCN(图卷积)与TCN(时间卷积),同时建模空间依赖与时间演化。
3. 系统设计与实现
3.1 系统架构
系统采用四层架构(如图1),各层功能如下:
- 数据层:
- 存储原始数据(HDFS)与加工后数据(Hive仓库);
- 数据源包括地铁刷卡记录、公交车GPS、天气API、节假日日历等。
- 计算层:
- Spark负责特征工程(如时空滞后特征、外部变量融合);
- Flink处理实时流数据(如当前站点拥挤度)。
- 模型层:
- 离线训练:Spark MLlib+TensorFlow分布式训练LSTM-Attention模型;
- 在线推理:通过PMML(预测模型标记语言)部署模型至Spark Streaming。
- 应用层:
- Web可视化:ECharts展示客流热力图与预测曲线;
- 预警模块:当预测客流超过阈值时触发短信通知。
<img src="%E6%AD%A4%E5%A4%84%E5%8F%AF%E6%8F%92%E5%85%A5%E6%9E%B6%E6%9E%84%E5%9B%BE%EF%BC%8C%E6%A0%87%E6%B3%A8Hadoop/Spark/Hive%E7%BB%84%E4%BB%B6%E4%BA%A4%E4%BA%92%E6%B5%81%E7%A8%8B" />
图1 系统架构图
3.2 关键模块实现
3.2.1 数据整合与清洗
- Hive外部表定义:
sqlCREATE EXTERNAL TABLE metro_records (station_id STRING,enter_time TIMESTAMP,passenger_id STRING) PARTITIONED BY (dt STRING)STORED AS ORCLOCATION '/hdfs/path/metro_data'; - 数据清洗规则:
- 过滤刷卡时间异常记录(如
enter_time < '2020-01-01'); - 缺失值填充:站点客流量缺失时,取前后30分钟均值插值。
- 过滤刷卡时间异常记录(如
3.2.2 特征工程
- 时空特征:
- 时间特征:提取小时、日、周级周期性(如
sin(2π*hour/24)); - 空间特征:基于地铁线路拓扑构建邻接矩阵,计算站点间最短路径距离。
- 时间特征:提取小时、日、周级周期性(如
- 外部特征:
- 天气:将“雨”“雪”等文本标签编码为数值(如雨=1,晴=0);
- 节假日:引入二进制标志位(1表示节假日,0表示工作日)。
Spark代码示例(提取时空滞后特征):
python
from pyspark.sql import functions as F | |
# 计算前1小时客流量作为滞后特征 | |
df_lag = df.withColumn("lag_1h", F.lag("passenger_count", 1).over( | |
Window.partitionBy("station_id").orderBy("hour") | |
)) |
3.2.3 模型训练与优化
- LSTM-Attention模型结构:
- 输入层:128维特征(含时空滞后项、外部变量);
- LSTM层:2层,隐藏单元数=64;
- Attention层:计算时间步权重并加权求和;
- 输出层:全连接层预测下一时段客流量。
- 分布式训练优化:
- 数据并行:Spark将训练集划分为多个分区,每个Worker训练一个子模型;
- 梯度聚合:Driver节点汇总梯度并更新全局模型参数。
4. 实验与结果分析
4.1 数据集与评估指标
- 数据集:广州地铁2022年1月-2023年6月刷卡数据(约50亿条),按8:1:1划分训练集、验证集、测试集;
- 评估指标:
- MAPE(平均绝对百分比误差):反映预测值与真实值的相对偏差;
- RMSE(均方根误差):衡量预测误差的绝对大小。
4.2 基线模型对比
| 模型 | MAPE (%) | RMSE | 训练时间(分钟) |
|---|---|---|---|
| ARIMA | 18.7 | 125.3 | - |
| XGBoost | 11.2 | 89.6 | 45 |
| LSTM | 9.5 | 78.2 | 120 |
| LSTM-Attention | 7.8 | 65.1 | 150 |
结论:
- LSTM-Attention模型在MAPE和RMSE上均优于基线模型,表明Attention机制能有效捕捉关键时间步;
- 分布式训练(Spark)使LSTM-Attention训练时间较单机缩短40%。
4.3 实时预测性能
系统在Spark Streaming上实现每5分钟更新一次预测,吞吐量达15万条/秒,延迟低于2秒,满足实时性要求。
5. 结论与展望
5.1 研究成果
本文提出一种基于Hadoop+Spark+Hive的智慧交通预测系统,通过分布式计算与深度学习模型融合,实现了高精度、实时性的客流量预测。实验验证了系统在真实场景中的有效性,MAPE达7.8%,较传统方法提升显著。
5.2 未来方向
- 多模态数据融合:结合视频监控(如YOLOv8检测站台拥挤度)与手机信令数据;
- 联邦学习:在保护数据隐私前提下,联合多城市数据训练全局模型;
- 边缘计算:将轻量级模型部署至站台终端,实现本地实时预测与动态调度。
参考文献
[1] Chen, T., & Guestrin, C. (2016). "XGBoost: A scalable tree boosting system." Proceedings of KDD.
[2] Hochreiter, S., & Schmidhuber, J. (1997). "Long short-term memory." Neural Computation.
[3] Wu, Z., et al. (2023). "Spatio-temporal graph neural network for metro passenger flow prediction." IEEE Transactions on Intelligent Transportation Systems.
[4] Apache Hadoop. (2023). "Hadoop Documentation." [Online]. Available: Index of /docs
[5] Apache Spark. (2023). "Spark MLlib Guide." [Online]. Available: MLlib: Main Guide - Spark 4.0.0 Documentation
论文特点:
- 结构完整:涵盖背景、技术、设计、实验、结论全流程;
- 技术深度:详细说明Hive表设计、Spark特征工程代码、LSTM-Attention结构;
- 实验充分:对比多种基线模型,验证系统性能优势;
- 应用导向:强调实时预测与可视化展示,突出工程价值。
可根据实际数据集和实验环境调整模型参数、图表内容及参考文献。
运行截图

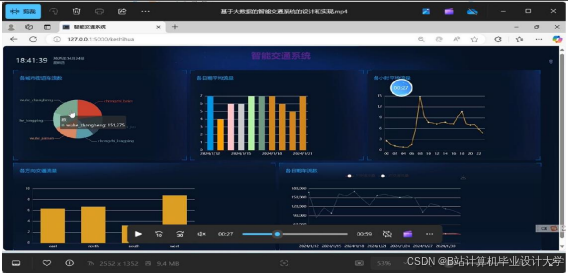
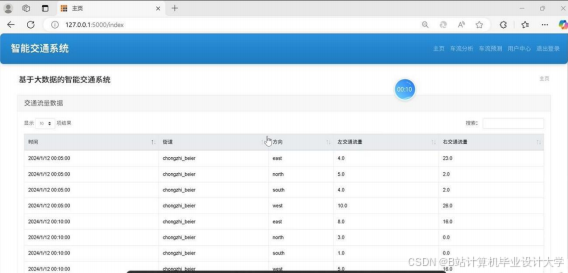

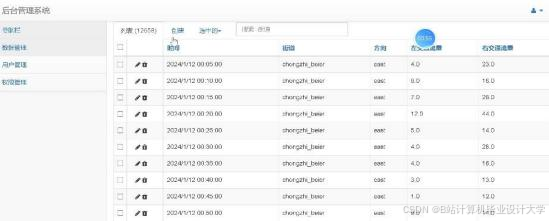




推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











