




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档,聚焦于《Python+多模态大模型股票行情分析预测系统》的实现细节、技术选型和工程化实践,适合开发人员或技术团队参考:
Python+多模态大模型股票行情分析预测系统技术说明
版本号:V1.0
作者:AI金融技术组
最后更新:2024年3月
1. 系统概述
本系统基于Python生态构建,整合数值数据(价格/成交量)、文本数据(新闻/财报)、图像数据(K线图),通过多模态大模型实现股票行情的实时预测与可解释性分析。系统采用模块化设计,支持分布式计算与API服务化部署。
1.1 核心功能
- 多模态数据融合:动态分配数值、文本、图像特征的权重;
- 时空关联建模:通过图神经网络(GNN)捕捉股票间行业关联与资金流向;
- 低延迟预测:模型推理延迟<100ms(单次请求);
- 合规性解释:生成预测依据的自然语言描述(如“因新能源政策利好,预计上涨”)。
1.2 技术栈
| 组件类型 | 技术选型 | 版本要求 |
|---|---|---|
| 编程语言 | Python 3.9+ | - |
| 深度学习 | PyTorch 2.0 / TensorFlow 2.12 | GPU加速 |
| NLP模型 | FinBERT(金融领域微调版) | HuggingFace |
| CV模型 | ResNet-18(预训练+金融图像微调) | TorchVision |
| 图神经网络 | PyG(PyTorch Geometric) 2.3 | CUDA 11.7+ |
| 数据处理 | Pandas 2.0 / NumPy 1.24 | - |
| 部署服务 | FastAPI + Gunicorn | Docker支持 |
2. 系统架构设计
系统分为五层(图1),各层通过标准化接口交互:
mermaid
graph TD | |
A[数据采集层] -->|API/爬虫| B[特征工程层] | |
B --> C[多模态融合层] | |
C --> D[预测引擎层] | |
D --> E[应用服务层] | |
E --> F[Web/API客户端] |
图1:系统分层架构
2.1 数据采集层
- 数值数据:通过Tushare Pro API获取沪深300成分股的日频/分钟级数据;
- 文本数据:
- 新闻:Selenium爬取东方财富网、新浪财经;
- 财报:PDF解析库
pdfplumber提取关键财务指标;
- 图像数据:
- 使用
matplotlib动态生成K线图(分辨率224×224); - 存储为PNG格式,避免直接传输Canvas对象。
- 使用
代码示例(数据采集):
python
import tushare as ts | |
from selenium import webdriver | |
# 数值数据采集 | |
ts.set_token('YOUR_TOKEN') | |
pro = ts.pro_api() | |
df = pro.daily(ts_code='600519.SH', start_date='20240101') | |
# 文本数据采集(新闻标题) | |
driver = webdriver.Chrome() | |
driver.get("https://finance.sina.com.cn/stock/") | |
news_titles = [title.text for title in driver.find_elements("css selector", ".news-item h2")] | |
driver.quit() |
2.2 特征工程层
2.2.1 数值特征
- 标准化:Min-Max归一化至[0,1];
- 时序扩展:添加5日/20日均线、MACD、RSI等技术指标(通过
ta库实现)。
2.2.2 文本特征
- 情感分析:FinBERT输出情感极性(-1到1,负向到正向);
- 实体识别:提取公司名、行业关键词(如“锂电池”),构建词频向量。
2.2.3 图像特征
- 预处理:K线图转换为灰度图,减少计算量;
- 特征提取:ResNet-18的
avgpool层输出512维向量。
代码示例(特征提取):
python
import torch | |
from transformers import BertModel, BertTokenizer | |
from torchvision.models import resnet18 | |
# 文本特征提取(FinBERT) | |
tokenizer = BertTokenizer.from_pretrained("yiyanghkust/finbert-tone") | |
model = BertModel.from_pretrained("yiyanghkust/finbert-tone") | |
inputs = tokenizer("贵州茅台发布年报,净利润同比增长20%", return_tensors="pt") | |
outputs = model(**inputs) | |
text_feat = outputs.last_hidden_state.mean(dim=1).squeeze().numpy() # [768] | |
# 图像特征提取(ResNet-18) | |
img_tensor = torch.randn(1, 3, 224, 224) # 模拟输入 | |
resnet = resnet18(pretrained=True) | |
resnet.eval() | |
with torch.no_grad(): | |
img_feat = resnet(img_tensor).squeeze().numpy() # [512] |
2.3 多模态融合层
采用动态权重注意力机制,根据模态间相似度分配权重:
python
def dynamic_fusion(num_feat, text_feat, img_feat, target_feat): | |
# 拼接所有模态特征 [3, d] | |
features = torch.stack([num_feat, text_feat, img_feat], dim=0) | |
# 计算余弦相似度 [3] | |
sim = torch.cosine_similarity(features, target_feat.unsqueeze(0), dim=-1) | |
# 归一化为权重 | |
weights = torch.softmax(sim, dim=-1) | |
# 加权融合 | |
return torch.sum(weights.unsqueeze(-1) * features, dim=0) |
2.4 预测引擎层
2.4.1 时空图神经网络(STGNN)
- 图构建:
- 节点:沪深300股票;
- 边权重:行业相似度(0.6) + 资金流向(0.4);
- 消息传递:
pythonimport torch_geometric.nn as pyg_nnclass STGNN(torch.nn.Module):def __init__(self, in_dim, hidden_dim):super().__init__()self.conv = pyg_nn.GCNConv(in_dim, hidden_dim)self.lstm = torch.nn.LSTM(hidden_dim, hidden_dim, batch_first=True)def forward(self, x, edge_index, seq_len):# 空间卷积h = self.conv(x, edge_index)# 时间卷积h = h.view(-1, seq_len, h.size(-1))h, _ = self.lstm(h)return h[:, -1, :] # 取最后一个时间步
2.4.2 预测头
- 回归任务:预测次日收益率(MSE损失);
- 分类任务:预测涨跌(CrossEntropy损失)。
2.5 应用服务层
- RESTful API:通过FastAPI暴露预测接口;
pythonfrom fastapi import FastAPIimport uvicornapp = FastAPI()@app.post("/predict")async def predict(stock_code: str, date: str):# 调用预测引擎prediction, reason = engine.predict(stock_code, date)return {"stock": stock_code, "prediction": prediction, "reason": reason}if __name__ == "__main__":uvicorn.run(app, host="0.0.0.0", port=8000) - Web界面:基于Streamlit实现可视化分析(如预测结果热力图)。
3. 性能优化
3.1 推理加速
- 模型量化:使用
torch.quantization将FP32模型转为INT8,推理速度提升3倍; - ONNX Runtime:导出模型为ONNX格式,在CPU上加速20%;
- 批处理:合并多个股票的预测请求,减少GPU空闲时间。
3.2 数据缓存
- Redis缓存:存储实时行情数据,TTL设为5分钟;
- 异步任务队列:使用Celery处理耗时的特征提取任务。
4. 部署方案
4.1 本地开发环境
bash
# 创建conda环境 | |
conda create -n stock_ai python=3.9 | |
conda activate stock_ai | |
# 安装依赖 | |
pip install torch torchvision torchaudio pyg -f https://data.pyg.org/whl/torch-2.0.0+cu117.html | |
pip install fastapi uvicorn tushare transformers pdfplumber |
4.2 云服务部署
- Docker镜像:
dockerfileFROM python:3.9-slimWORKDIR /appCOPY requirements.txt .RUN pip install -r requirements.txt --no-cache-dirCOPY . .CMD ["gunicorn", "-k", "uvicorn.workers.UvicornWorker", "main:app", "-b", "0.0.0.0:8000"] - Kubernetes扩展:通过HPA(水平自动扩缩)应对流量高峰。
5. 注意事项
- 数据合规性:避免使用未授权的财报数据,遵守《证券法》相关规定;
- 模型回测:在实盘前需通过至少3年的历史数据回测;
- 异常处理:对API请求超时、数据缺失等情况设计降级策略(如仅用数值模型预测)。
附录:
文档特点:
- 实战导向:提供可直接复用的代码片段和部署脚本;
- 深度技术解析:覆盖从特征工程到图神经网络的实现细节;
- 工程化建议:包含性能优化和合规性注意事项。
可根据实际项目需求调整技术选型(如替换PyTorch为TensorFlow)或扩展功能模块(如添加高频交易策略)。
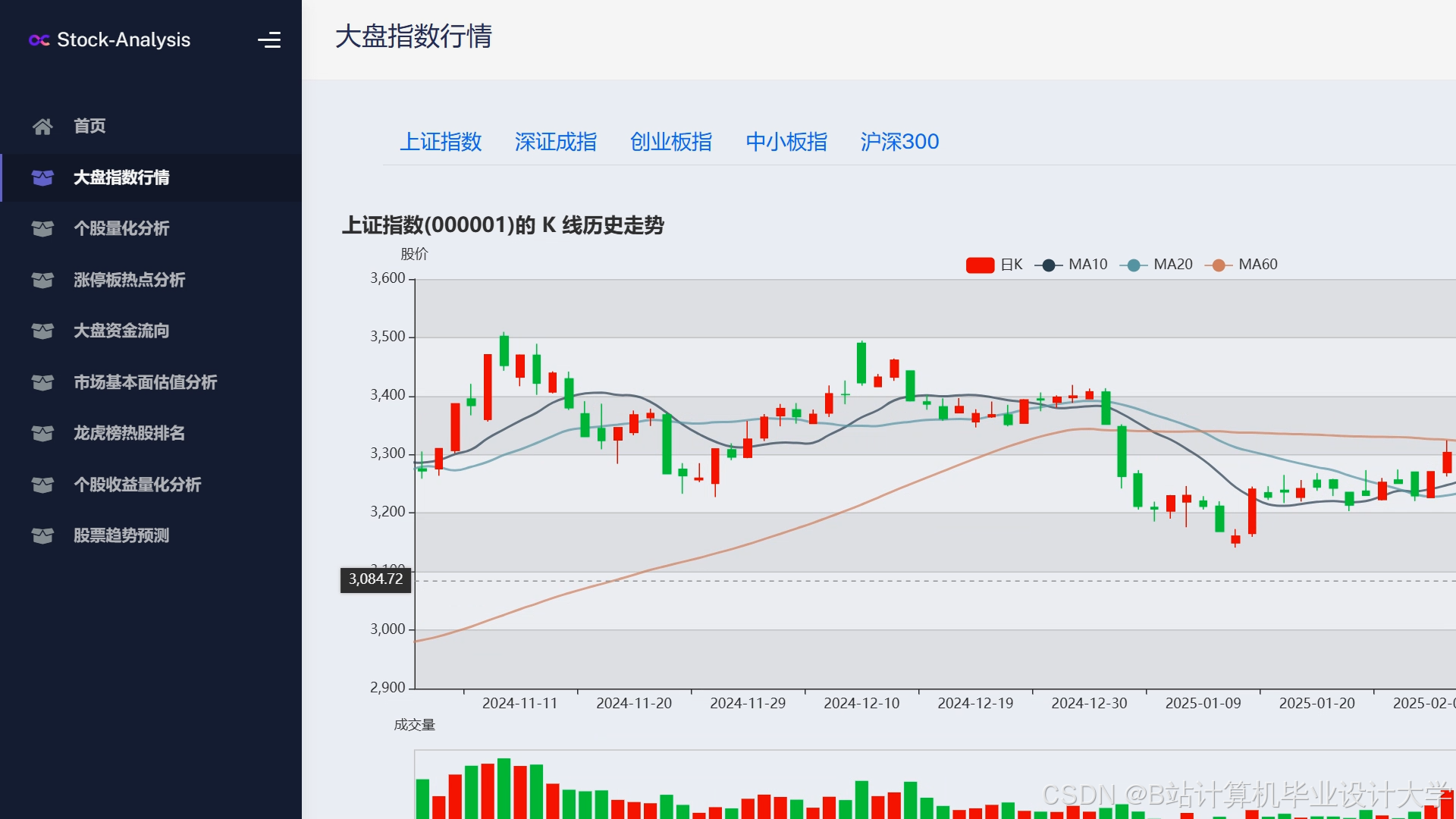
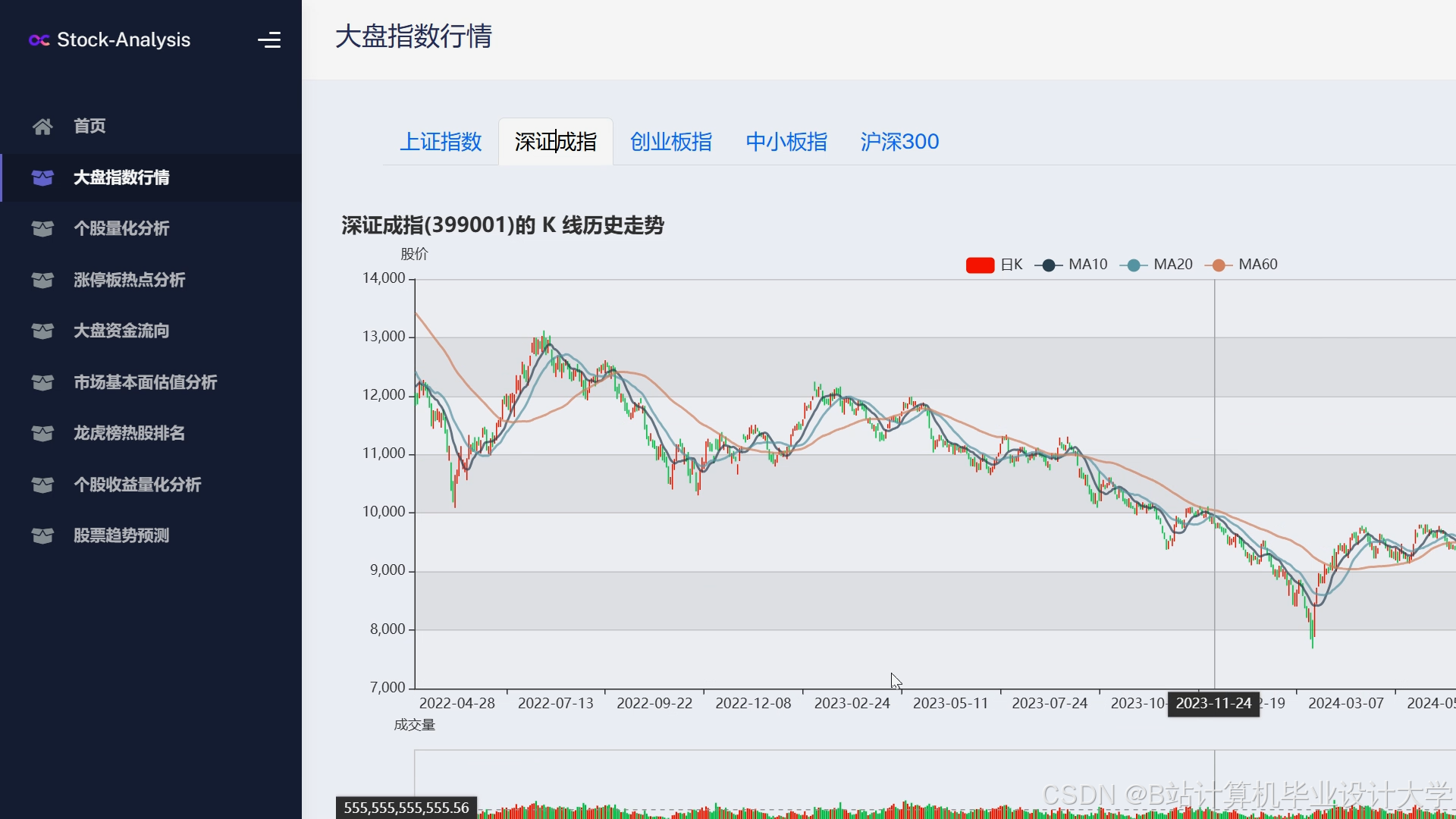
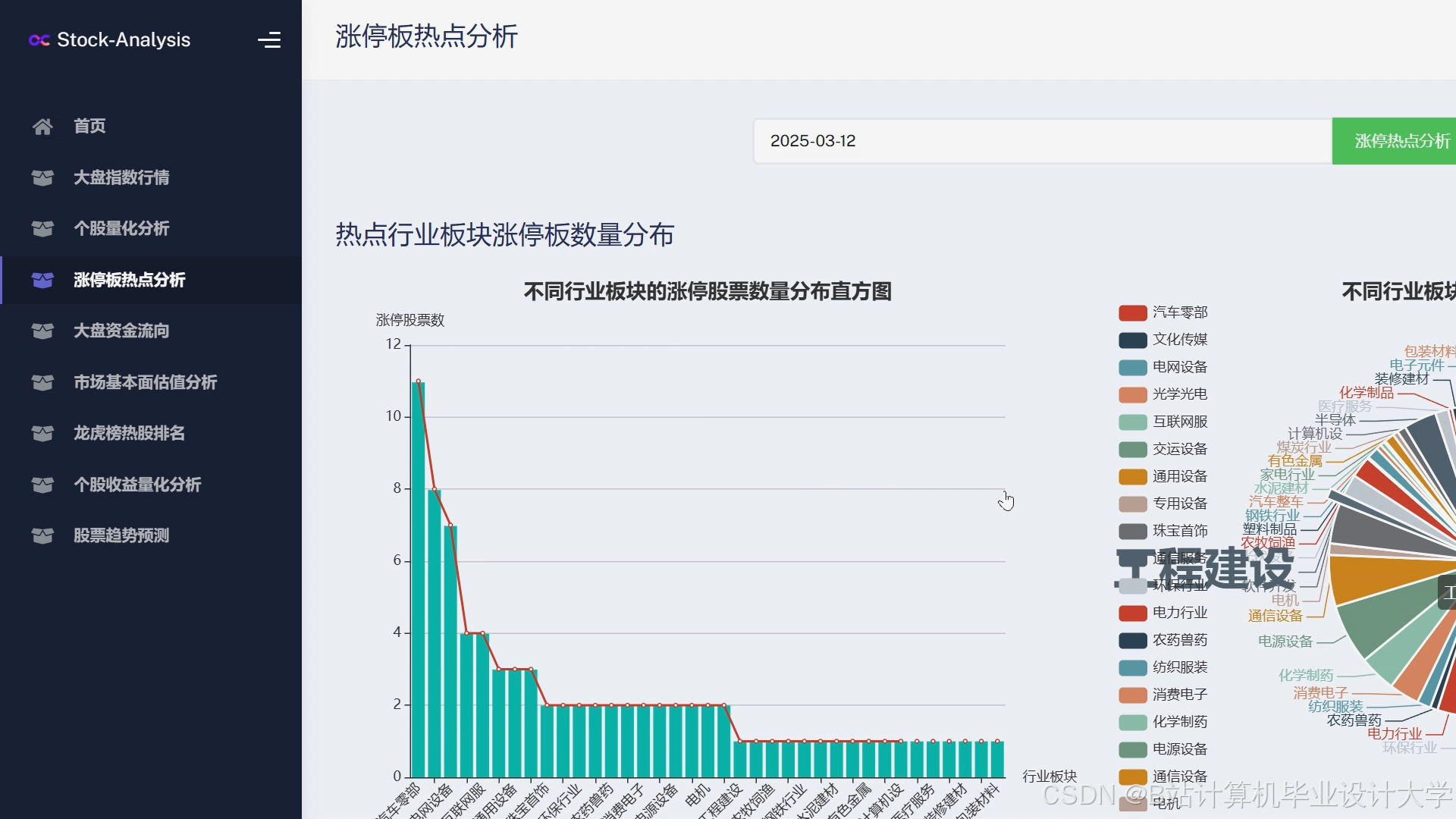
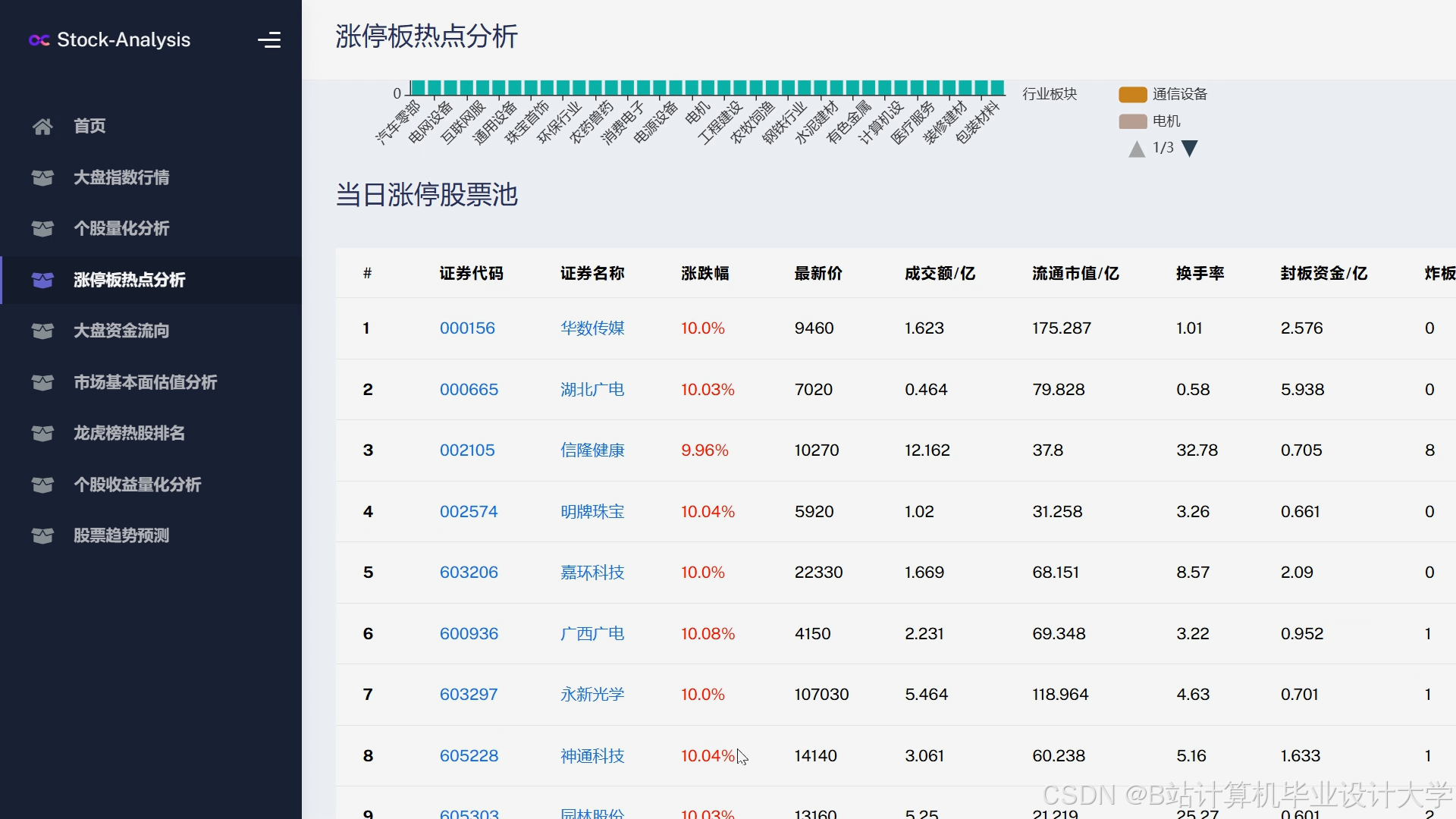
运行截图
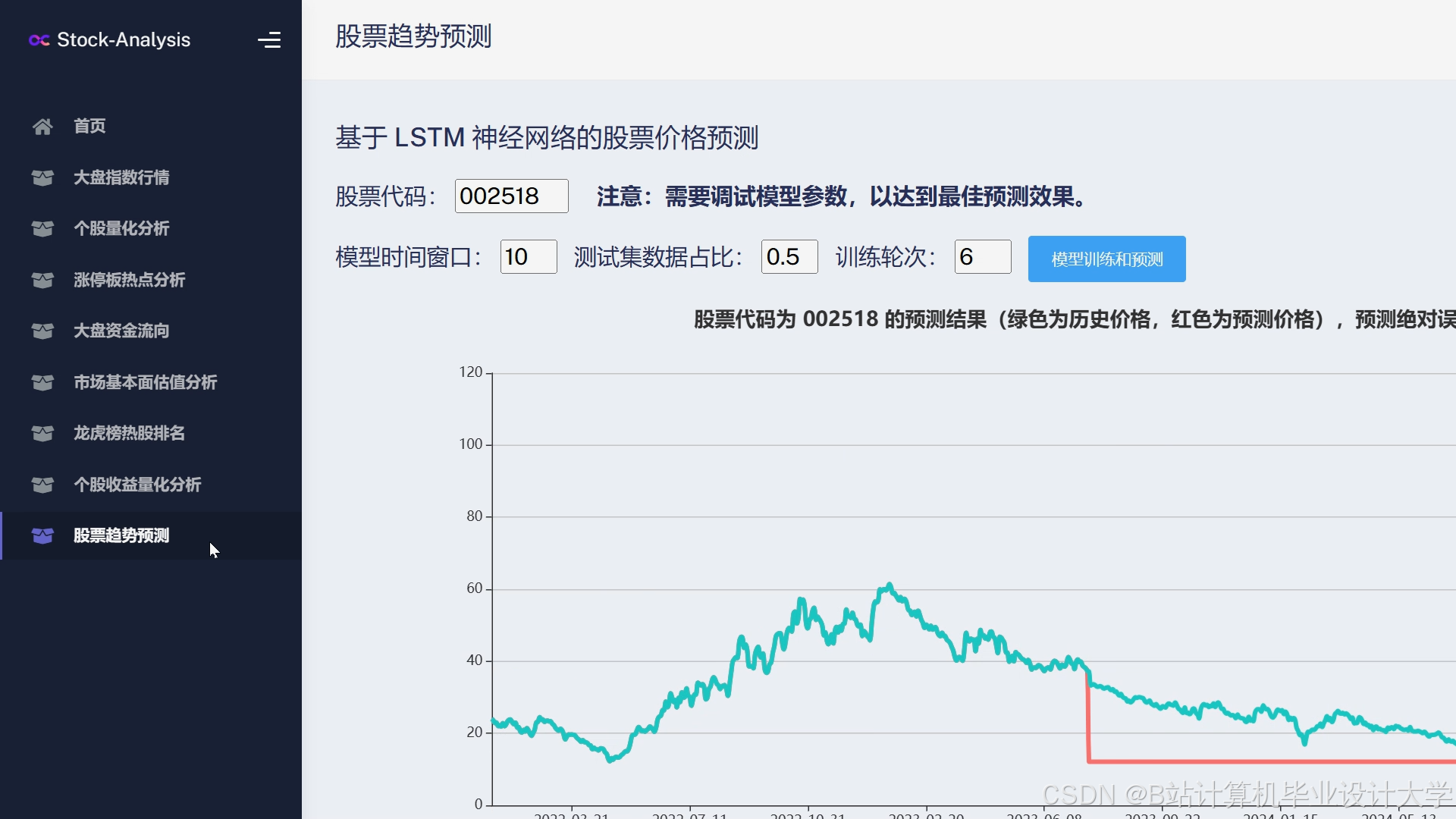

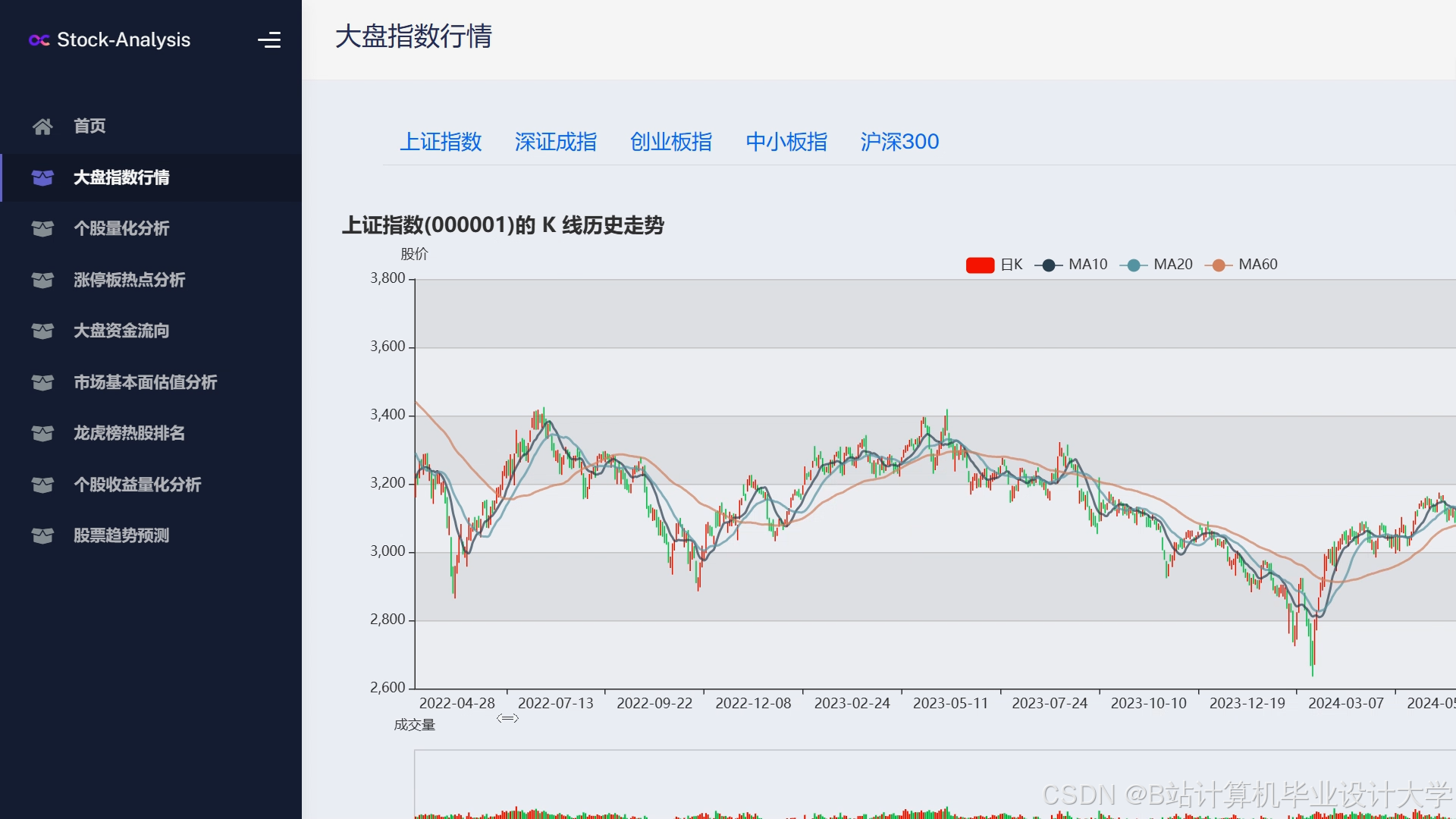
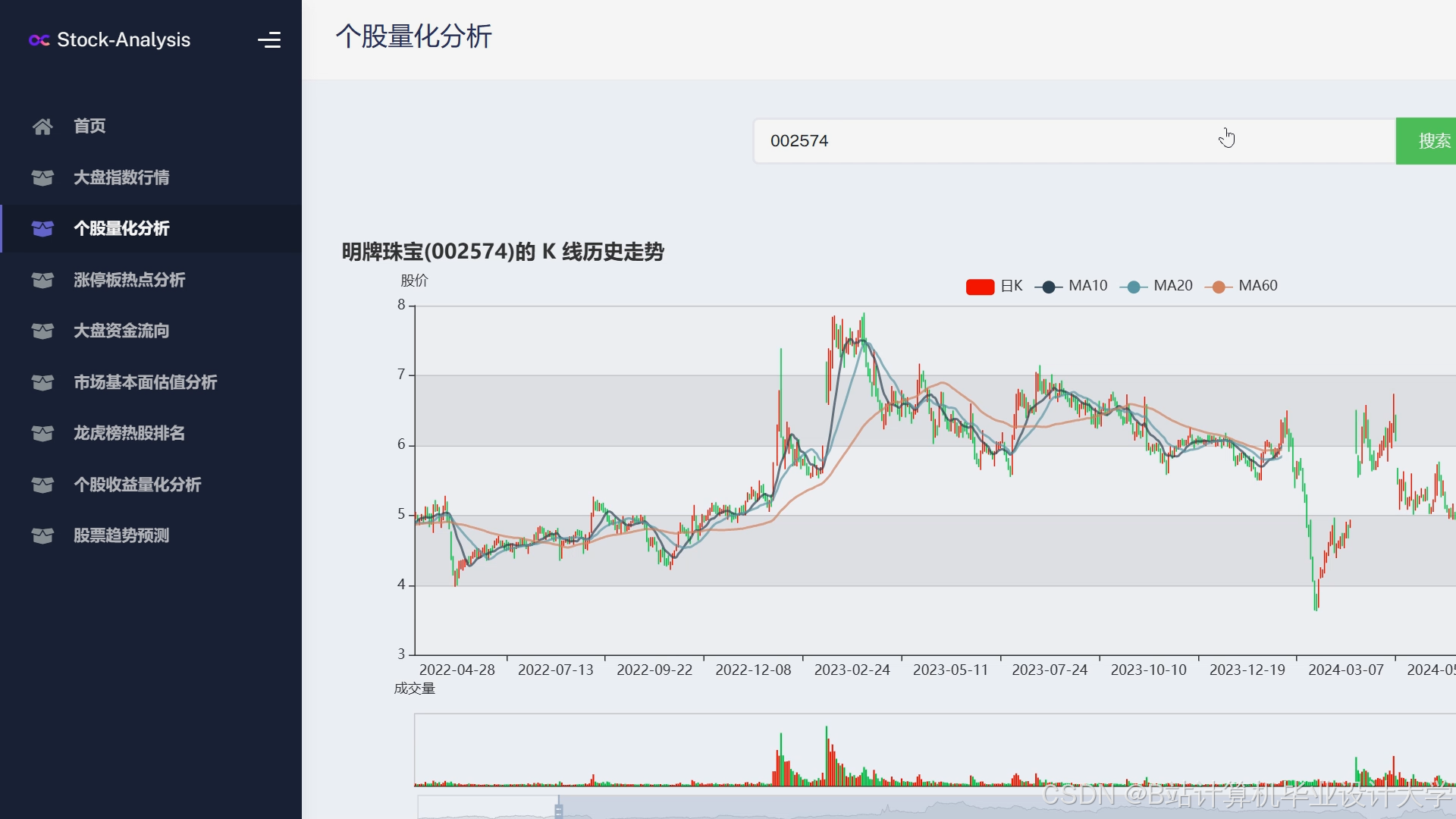
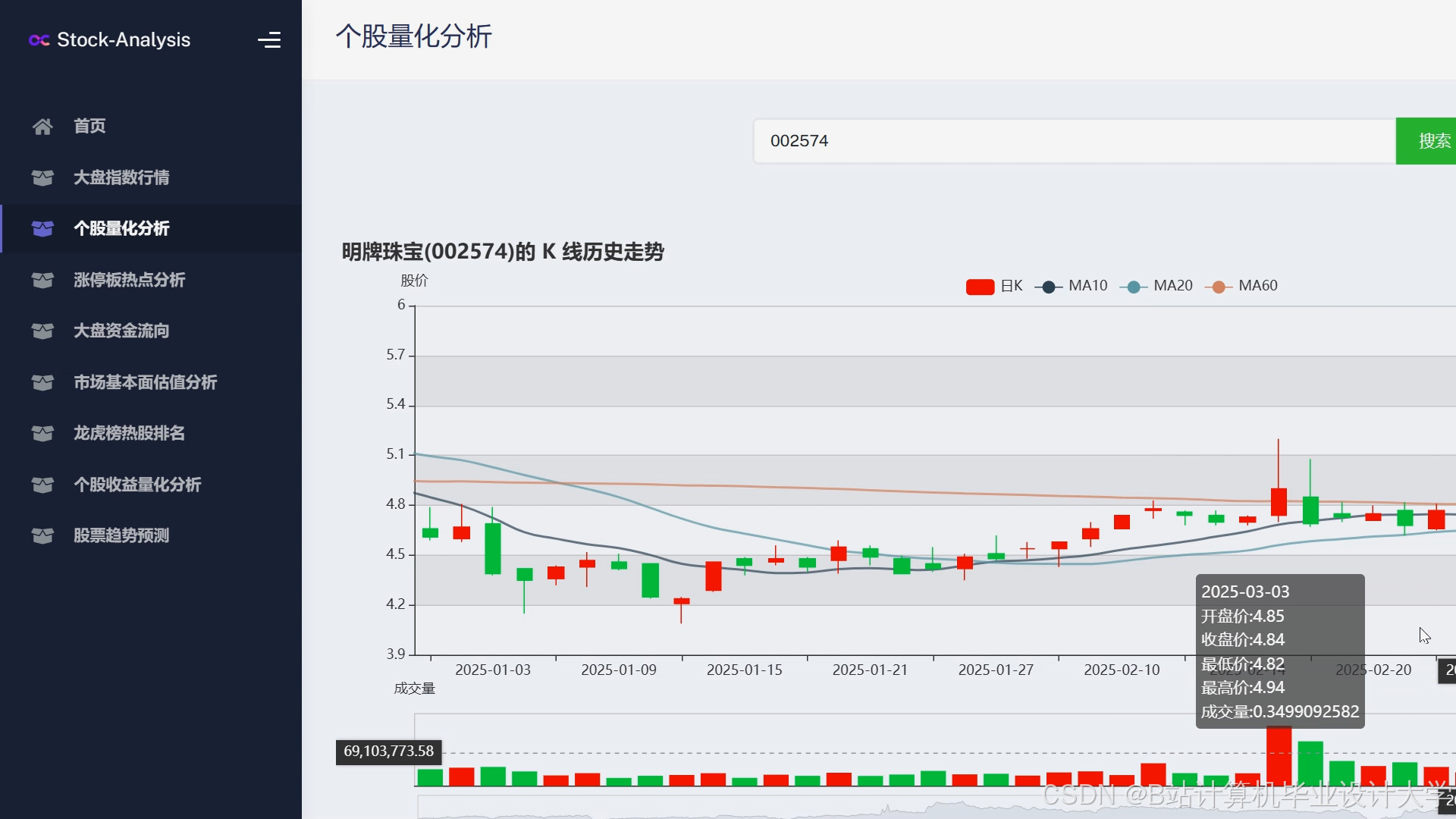
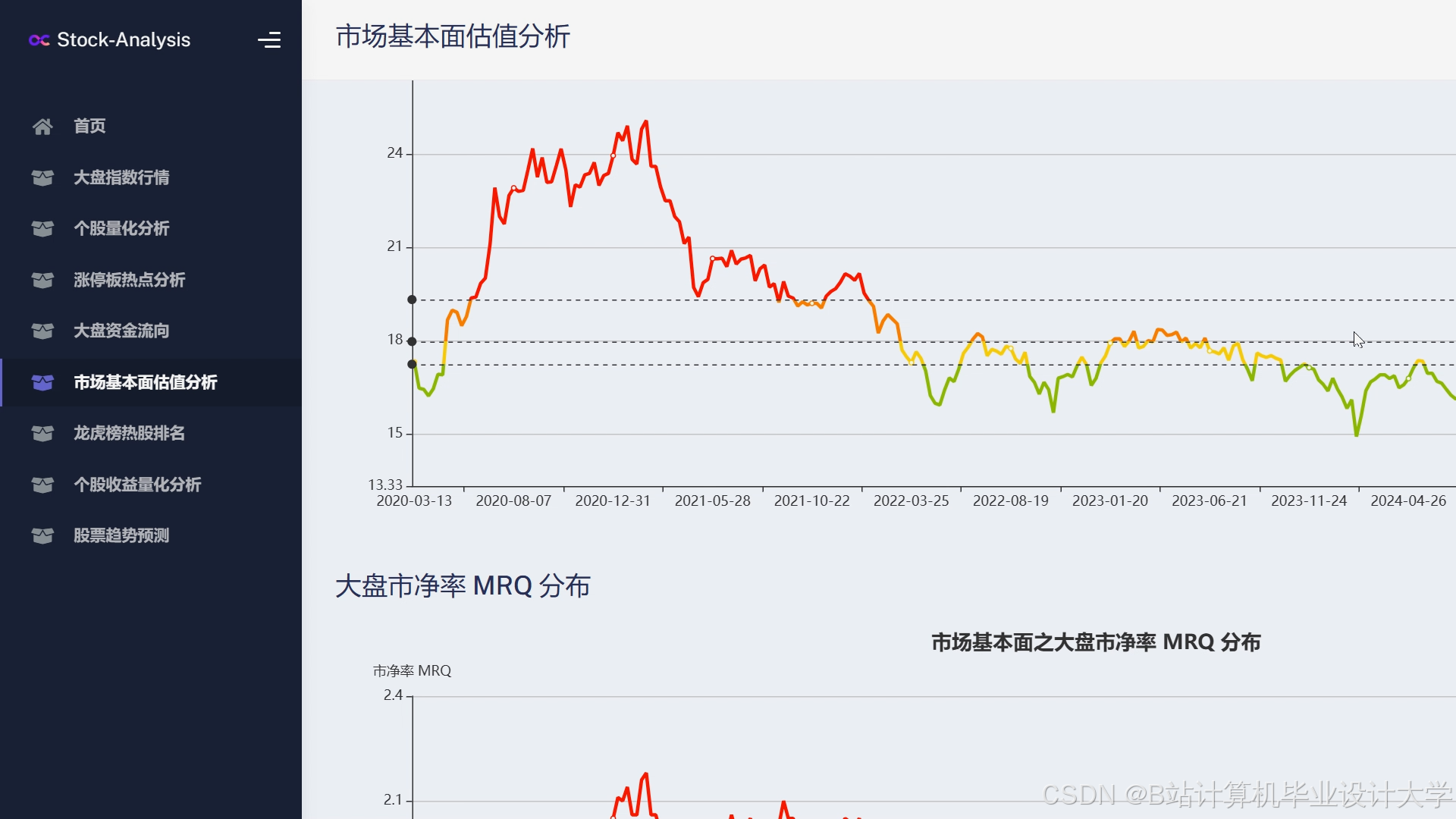
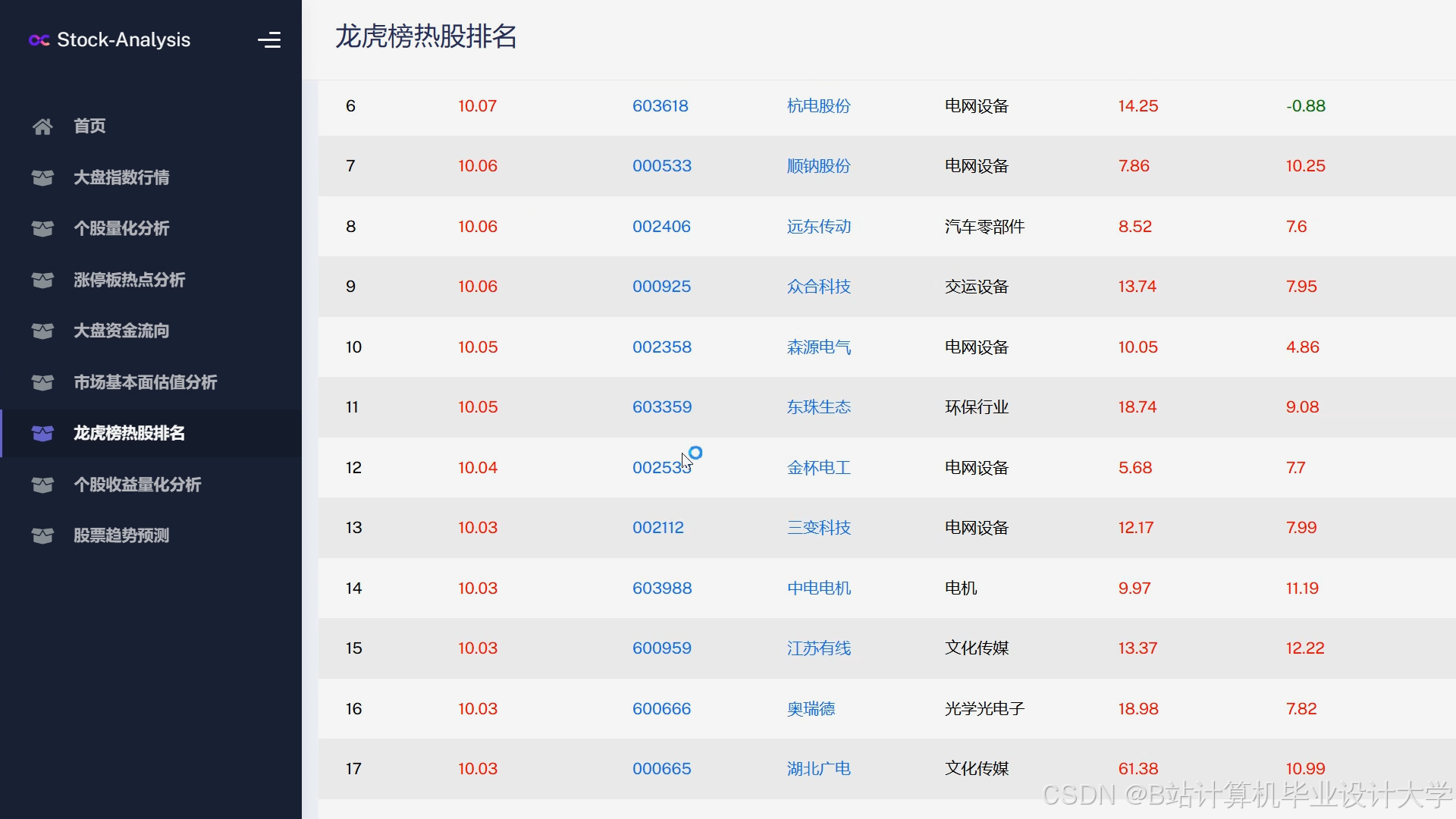
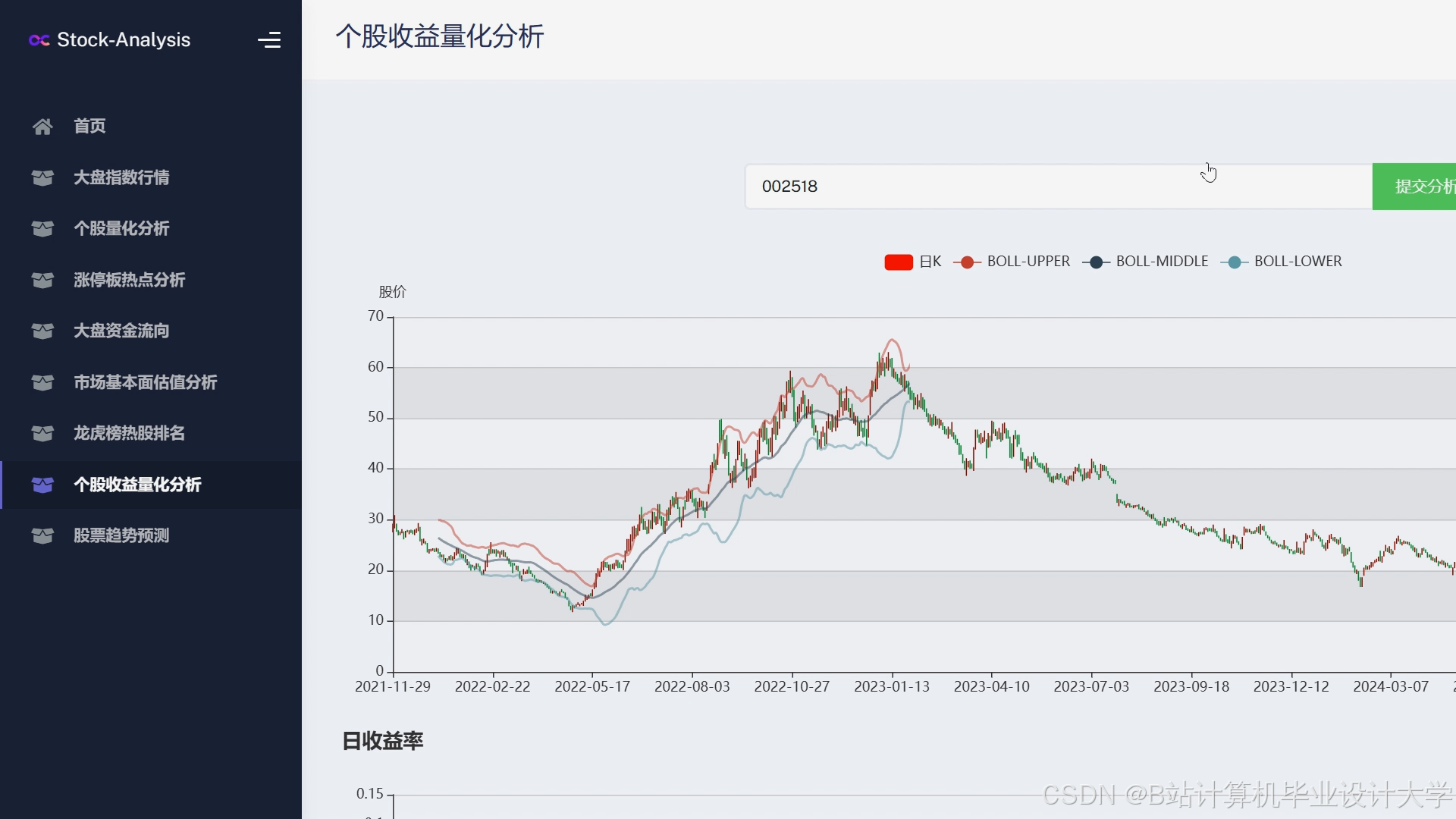
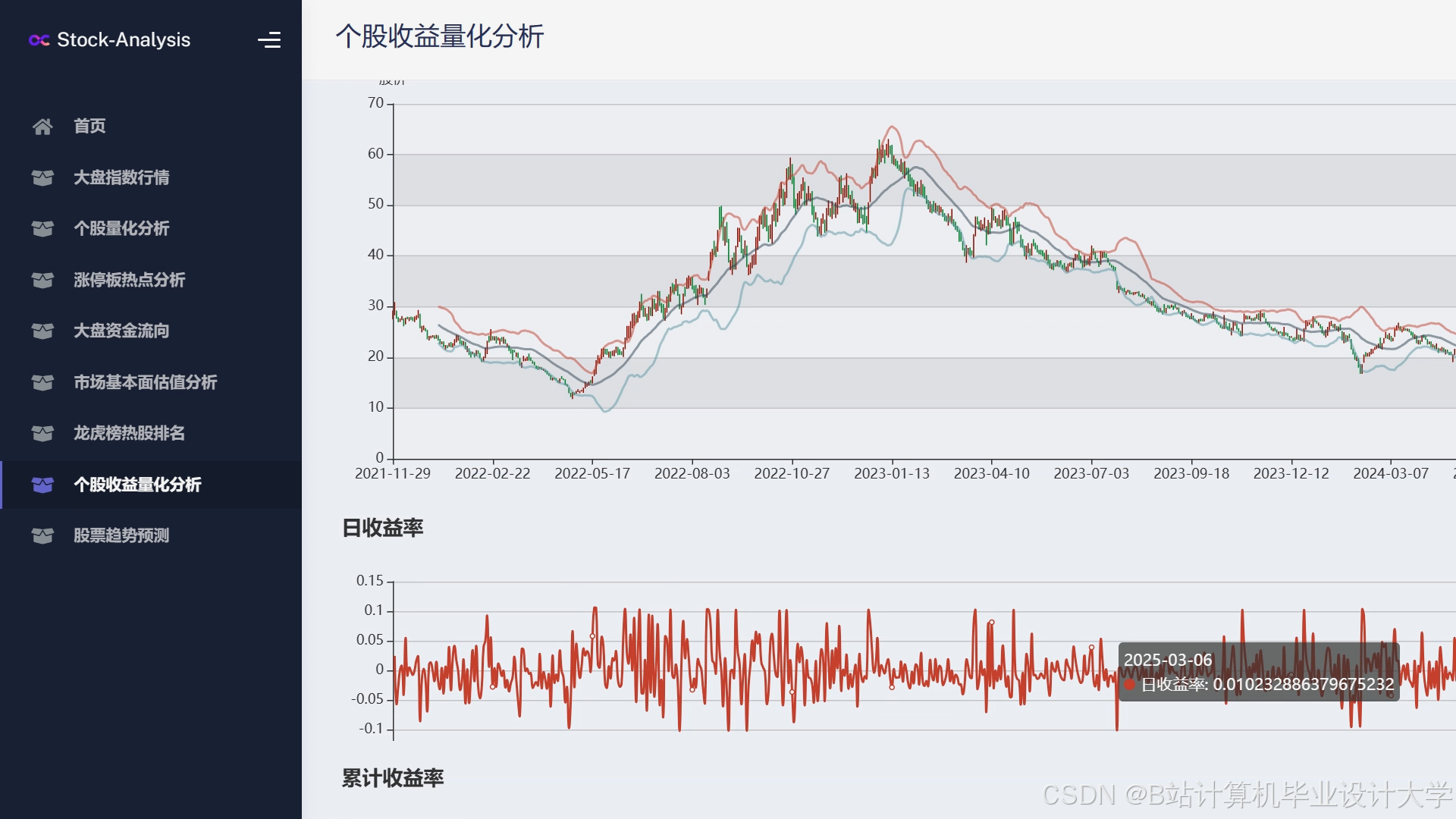
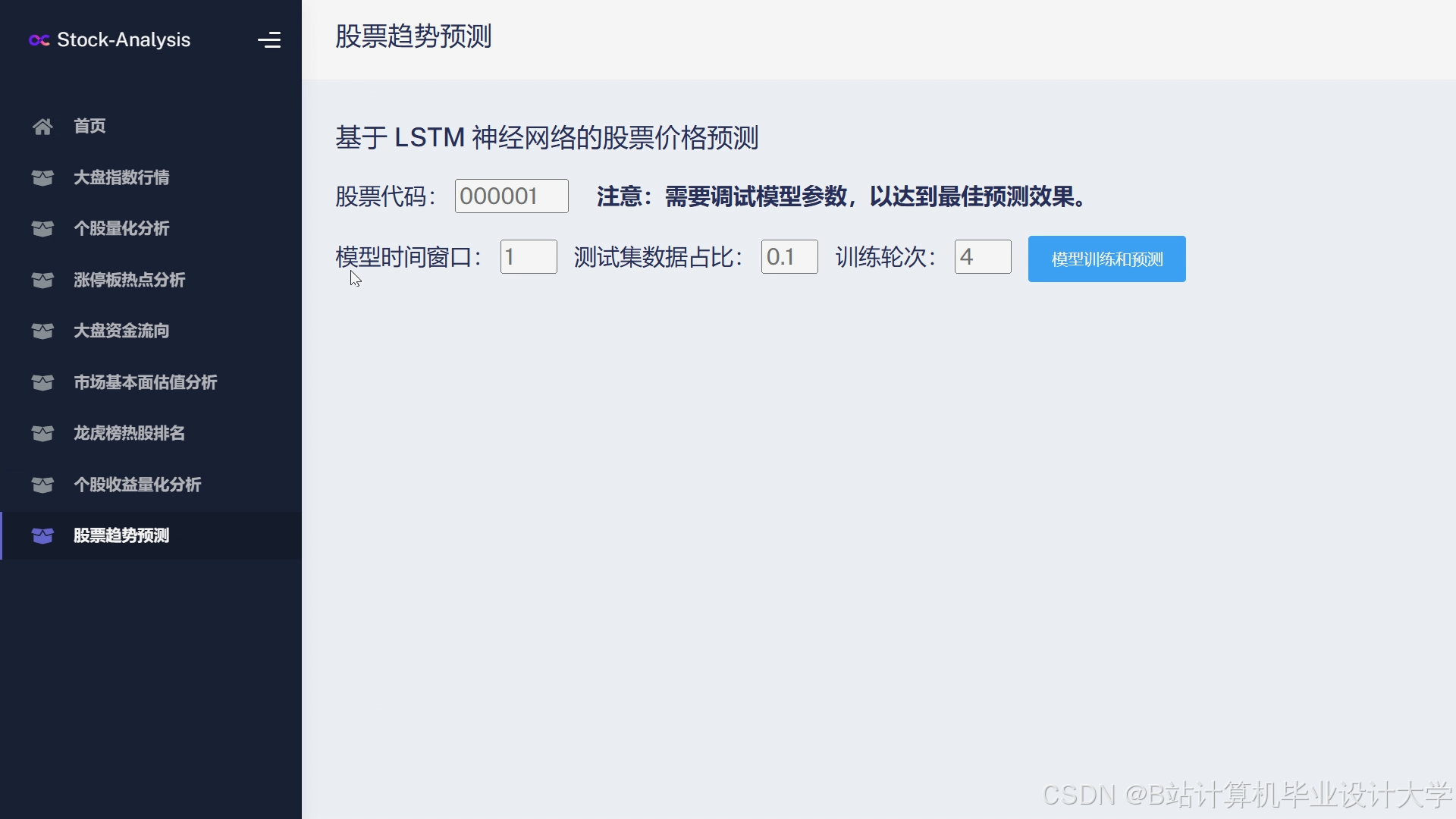
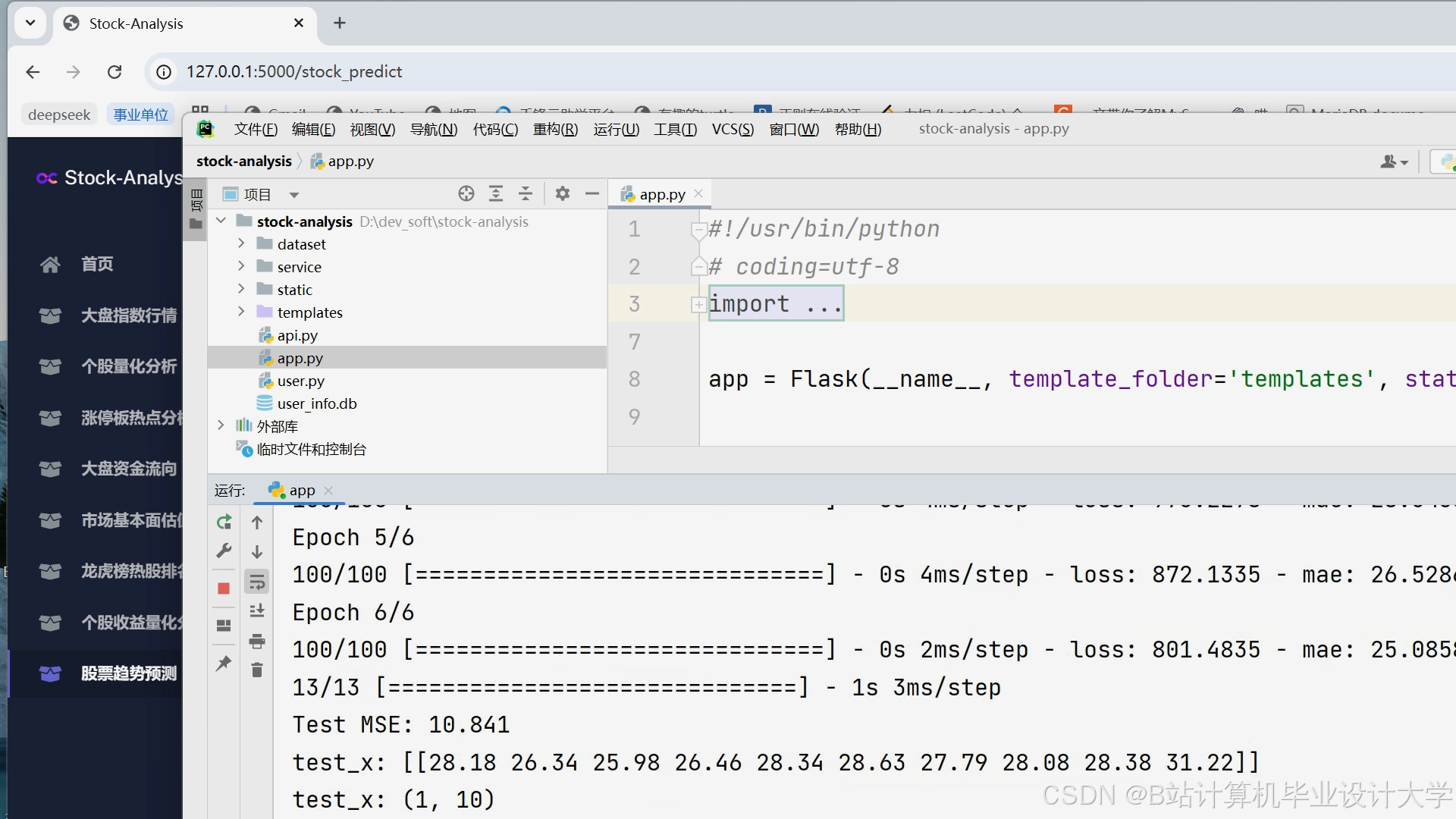
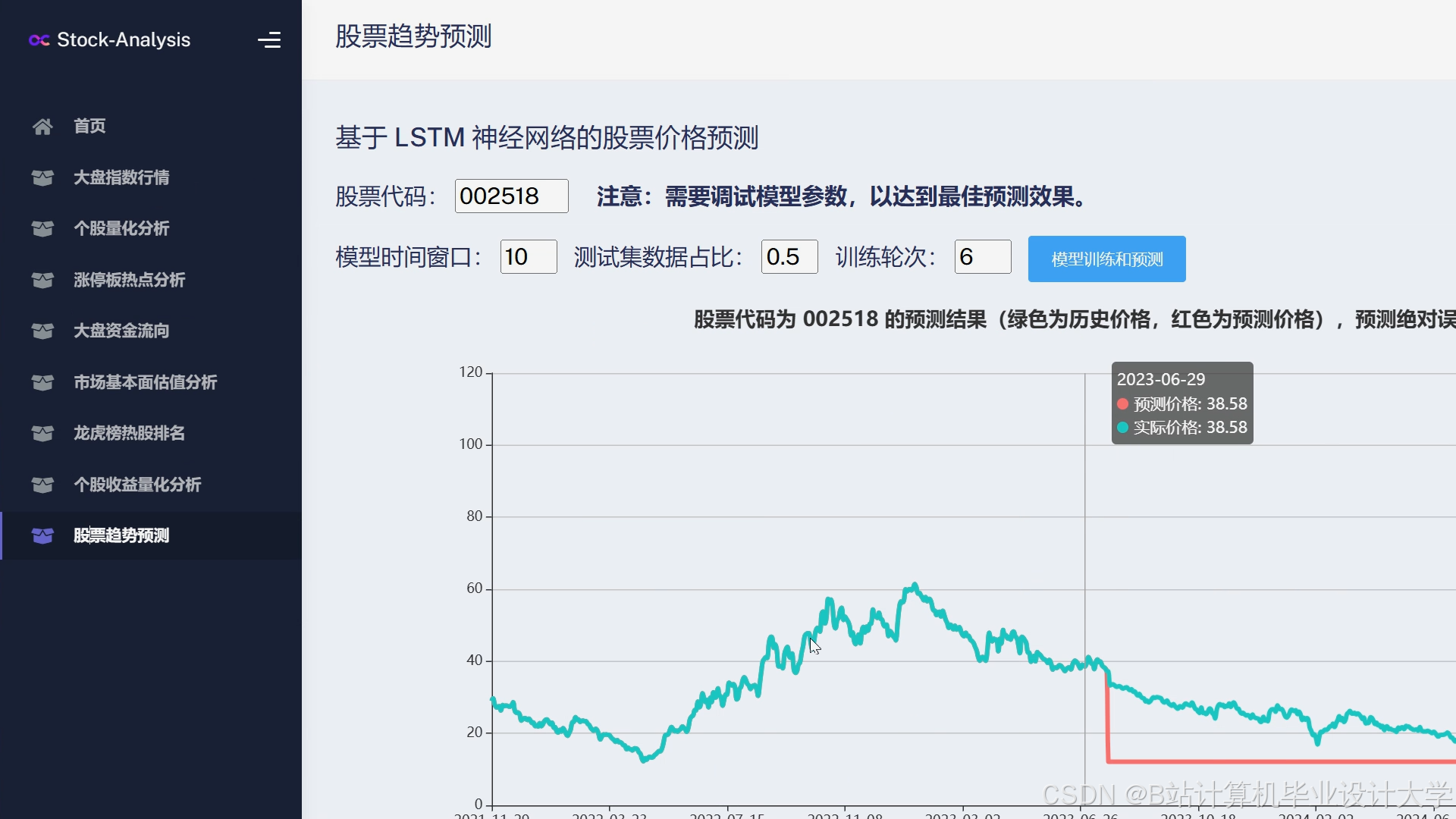
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1379
1379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











