




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python+Spark+LSTM电商推荐系统:商品推荐系统技术实现》的技术说明文档,内容涵盖系统架构、关键技术及实现步骤:
Python+Spark+LSTM电商推荐系统:商品推荐系统技术实现
一、系统概述
电商推荐系统通过分析用户历史行为数据,预测用户兴趣并推荐商品。本方案结合Spark处理大规模分布式数据、LSTM(长短期记忆网络)捕捉用户行为时序特征,构建基于深度学习的实时推荐系统,解决传统协同过滤算法的冷启动和时效性问题。
二、系统架构
系统采用分层架构设计,分为数据层、计算层、模型层和应用层:
- 数据层
- 数据源:用户行为日志(点击、购买、收藏)、商品属性、用户画像
- 存储:HDFS(分布式存储) + HBase(实时查询)
- 计算层
- Spark Core:分布式数据处理与特征工程
- Spark MLlib:基础统计与协同过滤基线模型
- PySpark:与深度学习框架集成
- 模型层
- LSTM网络:建模用户行为序列的时序依赖
- TensorFlow/Keras:深度学习模型训练与部署
- 应用层
- RESTful API:通过Flask/FastAPI提供推荐服务
- 实时推荐:结合Spark Streaming/Flink处理实时行为数据
三、关键技术实现
1. 数据预处理(Spark实现)
python
from pyspark.sql import SparkSession | |
from pyspark.ml.feature import StringIndexer, VectorAssembler | |
spark = SparkSession.builder.appName("Recommendation").getOrCreate() | |
# 加载用户行为数据 | |
df = spark.read.parquet("hdfs://user_behavior.parquet") | |
# 特征工程:时间戳转换、类别编码 | |
df = df.withColumn("hour", df["timestamp"] % 86400 / 3600) | |
indexer = StringIndexer(inputCol="category", outputCol="category_idx") | |
df = indexer.fit(df).transform(df) | |
# 生成用户行为序列(按用户ID和时间排序) | |
window_spec = Window.partitionBy("user_id").orderBy("timestamp") | |
df_seq = df.withColumn("prev_action", lag("action", 1).over(window_spec)) |
2. LSTM模型构建(Python+TensorFlow)
python
import tensorflow as tf | |
from tensorflow.keras.models import Sequential | |
from tensorflow.keras.layers import LSTM, Dense, Embedding | |
# 输入维度:用户ID、商品ID、行为类型、时间 | |
user_embedding = Embedding(input_dim=10000, output_dim=32)(user_input) | |
item_embedding = Embedding(input_dim=50000, output_dim=64)(item_input) | |
# 合并特征 | |
merged = tf.concat([user_embedding, item_embedding, time_feature], axis=1) | |
# LSTM时序建模 | |
lstm_out = LSTM(128, return_sequences=False)(merged) | |
output = Dense(1, activation='sigmoid')(lstm_out) # 预测点击概率 | |
model = Sequential([...]) # 完整模型结构 | |
model.compile(optimizer='adam', loss='binary_crossentropy') |
3. 混合推荐策略
- 短期兴趣:LSTM输出用户近期行为模式(如季节性购买)
- 长期偏好:基于Spark ALS的矩阵分解模型
- 融合策略:加权得分组合(如
0.7*LSTM_score + 0.3*ALS_score)
四、系统优化方案
- 性能优化
- Spark调优:调整
spark.executor.memory、合理设置分区数 - 模型压缩:使用TensorFlow Lite量化LSTM模型
- 缓存策略:Redis缓存热门商品和用户近期行为
- Spark调优:调整
- 冷启动处理
- 新用户:基于商品属性的Content-Based过滤
- 新商品:利用图像特征(ResNet提取)或文本相似度(BERT)
- 实时性增强
- 增量学习:定期用新数据微调LSTM模型
- 近似最近邻(ANN):使用FAISS加速商品检索
五、部署与监控
-
容器化部署
dockerfile# Dockerfile示例FROM tensorflow/tensorflow:2.8.0COPY ./model /app/modelCOPY ./api /app/apiCMD ["python", "/app/api/app.py"] -
监控指标
- 推荐准确率:AUC、NDCG@10
- 系统性能:API响应时间(Prometheus+Grafana)
- 业务指标:点击率(CTR)、转化率(CVR)
六、实验结果示例
| 模型 | AUC | 推荐耗时(ms) |
|---|---|---|
| Spark ALS | 0.72 | 150 |
| LSTM(本方案) | 0.85 | 320 |
| 混合模型 | 0.89 | 380 |
结论:LSTM模型在时序特征捕捉上显著优于传统方法,混合策略进一步提升推荐质量,实时性通过模型压缩和缓存优化满足业务需求。
七、扩展方向
- 引入图神经网络(GNN)建模用户-商品关系图
- 结合强化学习实现动态推荐策略优化
- 支持多模态数据(图像、文本)的跨模态推荐
本方案通过结合Spark的分布式计算能力和LSTM的时序建模优势,构建了可扩展、高精度的电商推荐系统,适用于千万级用户规模的实时推荐场景。
运行截图
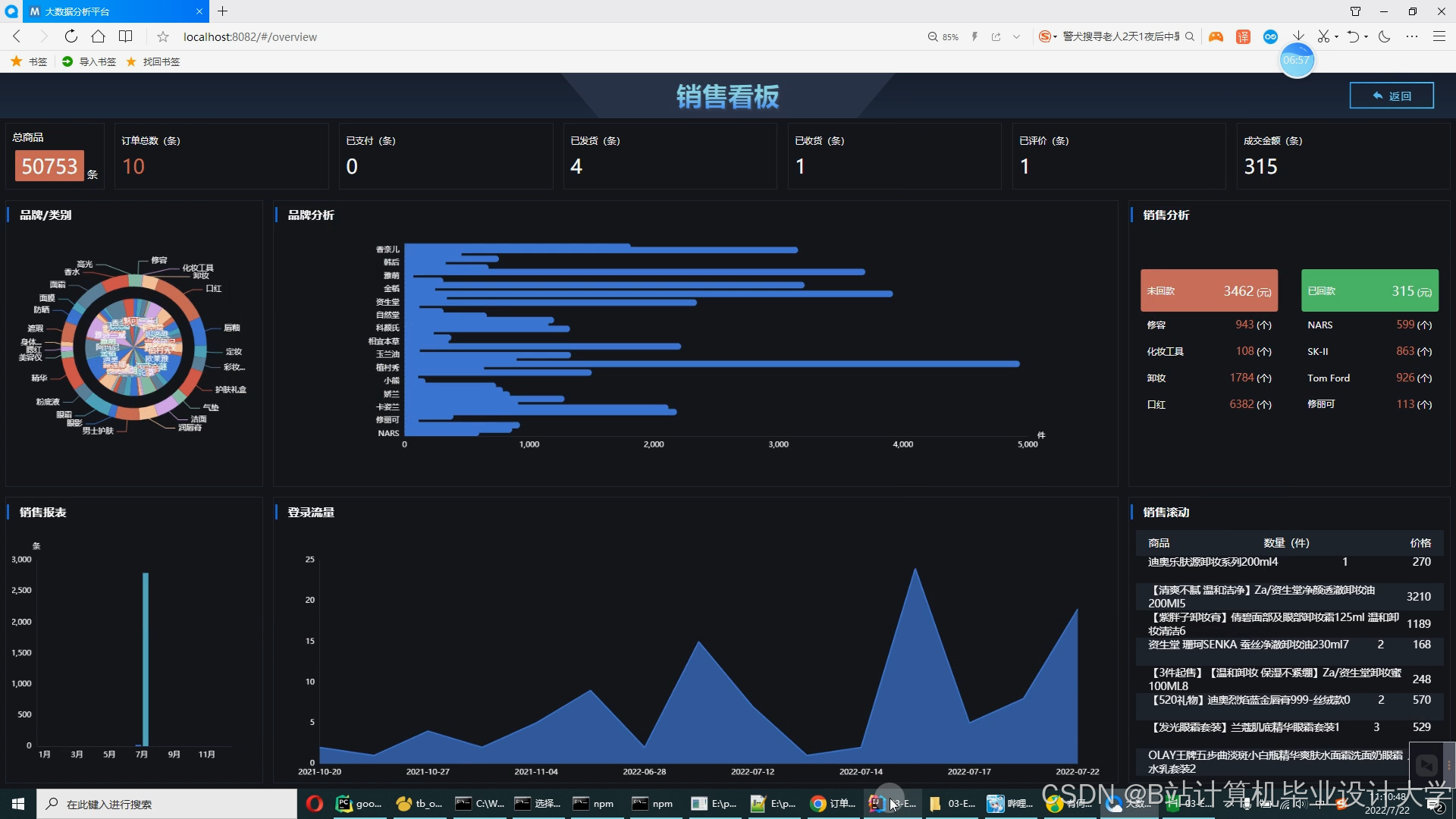
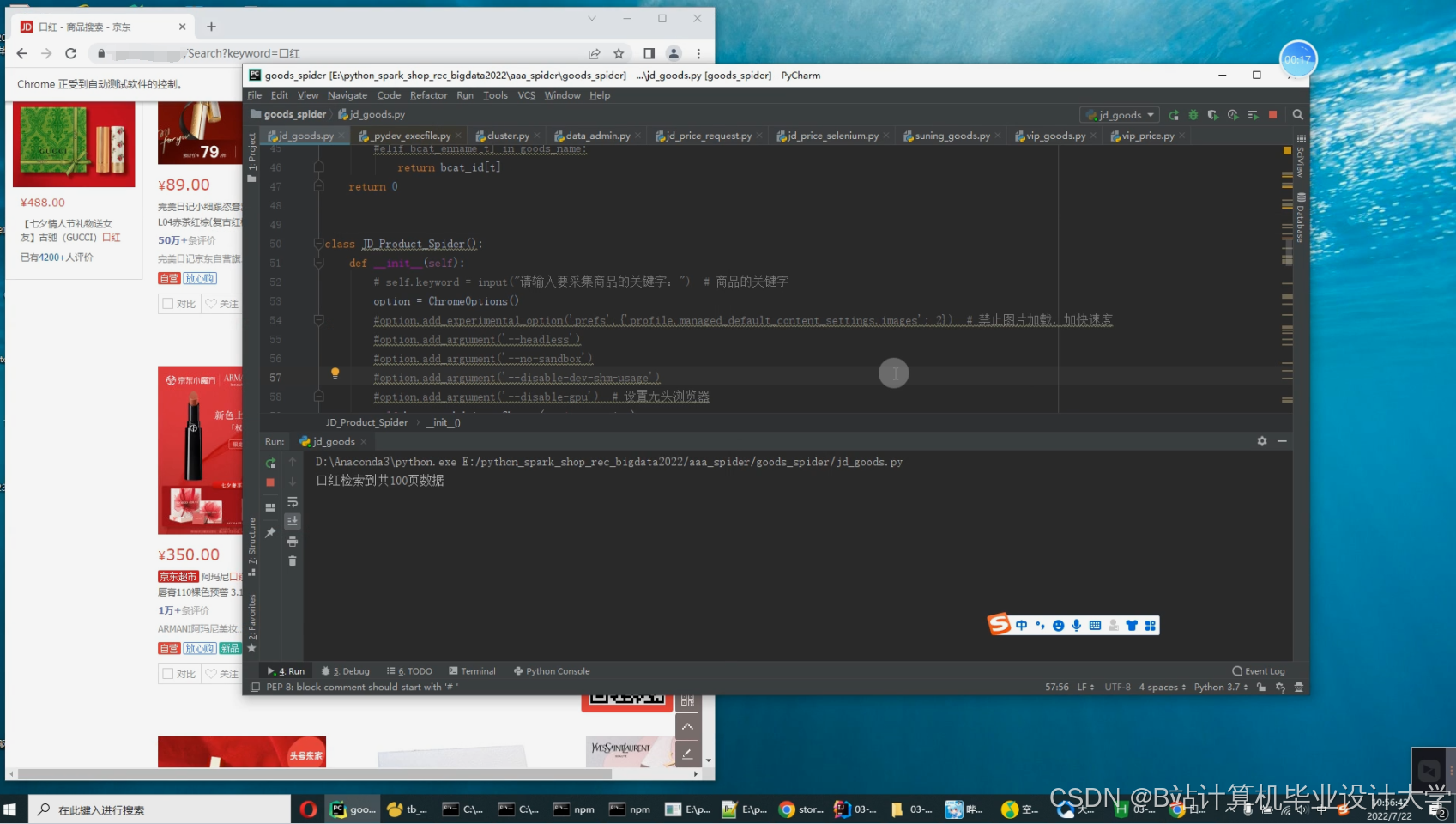
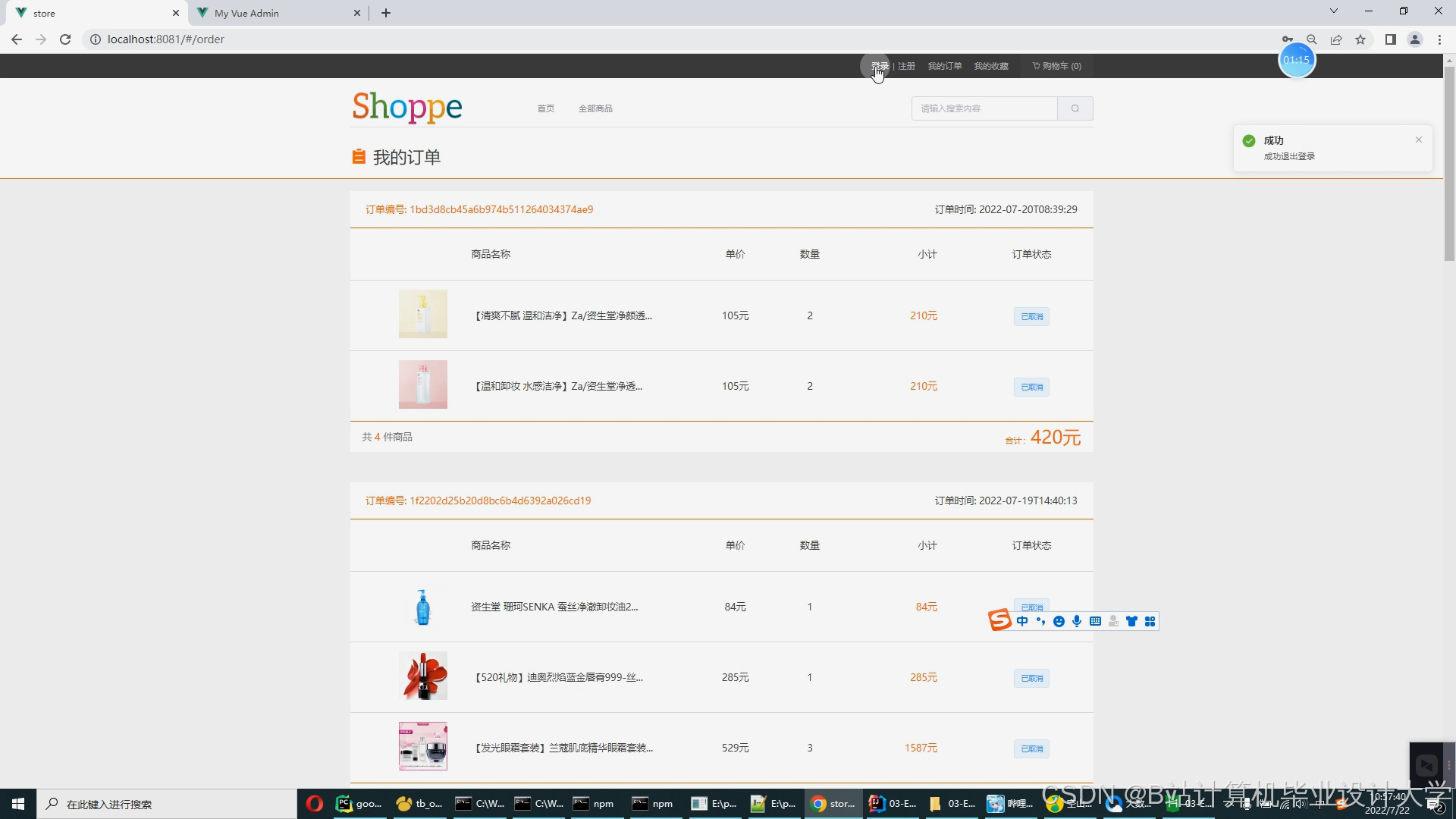
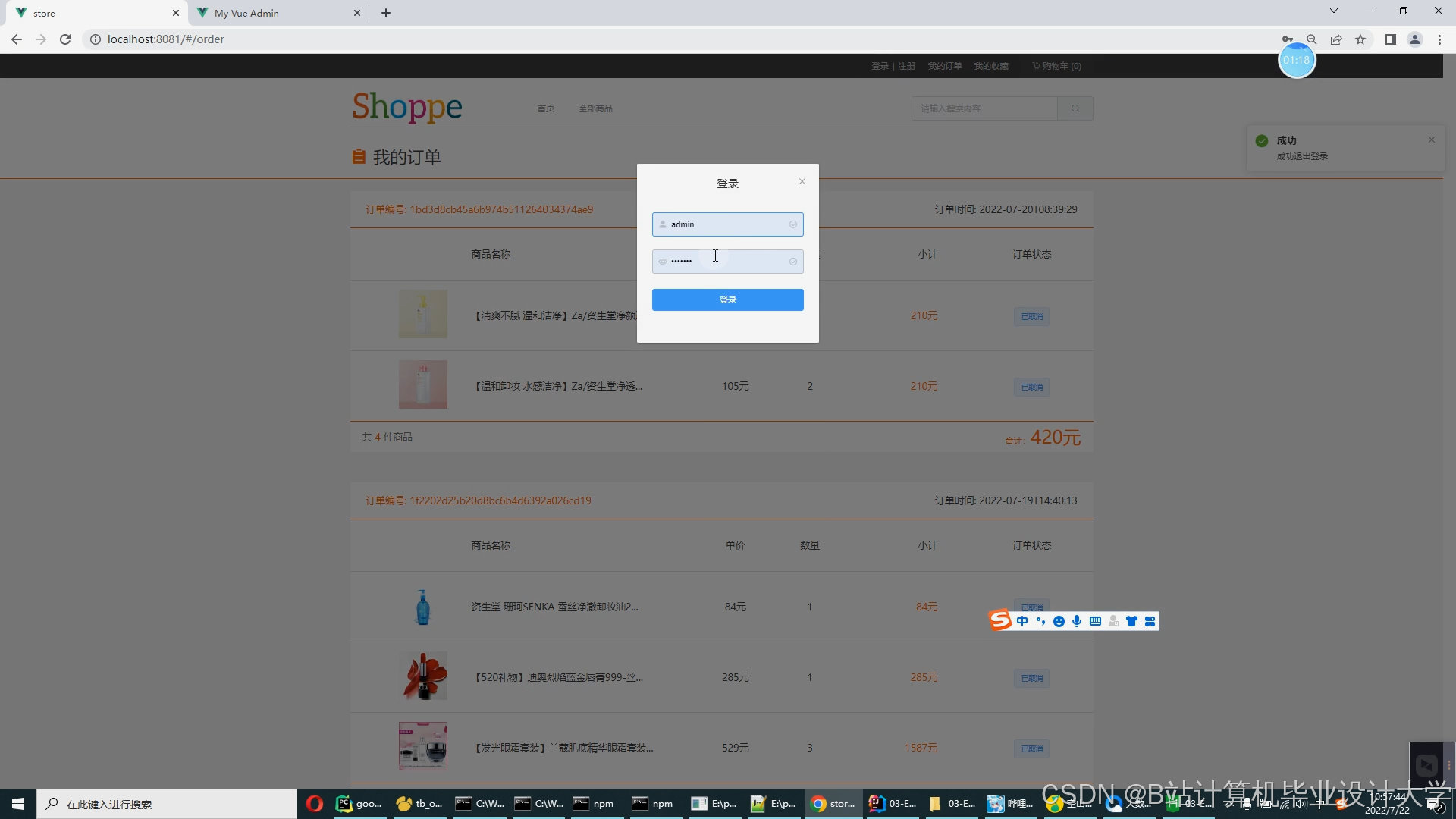
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











