




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档《Hadoop+Spark美团美食推荐系统》,重点突出技术架构、核心模块与实现细节,适合开发人员或技术团队参考:
Hadoop+Spark美团美食推荐系统技术说明
版本:V1.0
作者:美团技术团队
日期:2023年10月
1. 系统概述
美团美食推荐系统旨在从海量用户行为数据中挖掘个性化偏好,为用户推荐高匹配度的餐厅与菜品。系统基于Hadoop+Spark构建分布式计算架构,解决传统单机推荐系统的三大瓶颈:
- 数据规模:日均处理用户行为日志超50TB,覆盖1.2亿用户与800万商家;
- 实时性:用户行为反馈需在秒级内影响推荐结果;
- 冷启动:新用户/商家缺乏历史数据时的推荐质量保障。
系统采用离线+实时混合计算模式:
- 离线层:Hadoop HDFS存储原始数据,Spark完成大规模模型训练;
- 实时层:Spark Streaming处理用户实时行为,动态调整推荐策略。
2. 技术架构
2.1 整体架构图
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ | |
│ 数据采集层 │ → │ 存储计算层 │ → │ 推荐服务层 │ | |
└─────────────┘ └─────────────┘ └─────────────┘ | |
↑ │ │ | |
│ ↓ ↓ | |
└───── Kafka消息队列 ───── Redis缓存 ─────┘ |
- 数据采集层:通过Flume/Logstash收集用户APP行为日志(点击、下单、评价等);
- 存储计算层:
- HDFS:存储原始日志与预处理后的结构化数据;
- HBase:存储用户画像(年龄、口味偏好)与商家特征(评分、销量);
- Spark集群:执行离线训练与实时计算任务;
- 推荐服务层:Spring Boot提供RESTful API,Nginx实现负载均衡。
3. 核心模块实现
3.1 数据预处理模块
目标:将原始日志转换为推荐算法可用的结构化数据。
技术实现:
- 日志清洗:
- 使用Hadoop MapReduce过滤无效数据(如重复点击、非法用户ID);
- 示例代码片段(Map阶段):
javapublic void map(LongWritable key, Text value, Context context) {String[] fields = value.toString().split("\t");if (fields.length >= 4 && !fields[2].equals("INVALID")) {context.write(new Text(fields[0]), new Text(fields[1] + "," + fields[3]));}}
- 特征提取:
- 使用Spark SQL关联用户表与商家表,生成训练样本:
scalaval userFeatures = spark.sql("""SELECT user_id, avg_price_preference, favorite_cuisineFROM user_profile""")val trainingData = userFeatures.join(businessFeatures, "business_id")
- 使用Spark SQL关联用户表与商家表,生成训练样本:
3.2 离线推荐引擎
目标:每日生成全量用户的基础推荐列表。
技术实现:
- 算法选择:
- 协同过滤(CF):基于Spark MLlib的ALS(交替最小二乘法)实现,处理用户-商家评分矩阵;
- 内容推荐:结合商家标签(如“川菜”“人均50-100元”)与用户历史偏好,通过余弦相似度计算得分。
- 混合推荐策略:
- 加权融合CF与内容推荐结果(权重比6:4):
scalaval cfScores = ALSModel.predict(userFactors, businessFactors)val contentScores = calculateContentSimilarity(userProfile, businessFeatures)val finalScores = cfScores * 0.6 + contentScores * 0.4
- 加权融合CF与内容推荐结果(权重比6:4):
- Spark优化:
- 设置
spark.sql.shuffle.partitions=200避免数据倾斜; - 使用
persist(StorageLevel.MEMORY_AND_DISK)缓存中间结果。
- 设置
3.3 实时推荐引擎
目标:根据用户最新行为动态调整推荐结果。
技术实现:
- 行为流处理:
- 通过Kafka接收用户实时行为(如“用户A下单了商家B”);
- Spark Streaming每5秒处理一个微批(Micro-batch),更新用户实时偏好向量:
scalaval streamingDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "kafka-host:9092").load()val updatedScores = streamingDF.map { row =>val userId = row.getAs[String]("user_id")val businessId = row.getAs[String]("business_id")// 降低用户对同类商家的推荐权重decaySimilarBusinessScores(userId, businessId)}
- 规则引擎:
- 基于业务规则调整推荐列表(如“用户30天内未复购的商家降权20%”);
- 使用Drools实现规则管理,支持动态配置。
3.4 推荐服务接口
目标:为前端提供低延迟的推荐结果查询服务。
技术实现:
- 缓存策略:
- 使用Redis缓存热门推荐结果(TTL=1小时),减少数据库压力;
- 示例Redis数据结构:
KEY: "user:12345:recommendations"VALUE: [{"business_id": "B001", "score": 0.92}, ...]
- API设计:
- 接口路径:
GET /api/v1/recommendations?user_id=12345&limit=10 - 响应示例:
json{"code": 200,"data": [{"business_id": "B001", "name": "海底捞", "score": 0.92},{"business_id": "B002", "name": "西贝莜面村", "score": 0.85}]}
- 接口路径:
4. 性能优化与挑战
4.1 关键优化点
- 数据倾斜处理:
- 对热门商家(如肯德基)的评分数据单独分片,避免单个Task处理过多数据;
- 内存管理:
- 调整Spark Executor内存配置:
--executor-memory 8G --driver-memory 4G;
- 调整Spark Executor内存配置:
- 冷启动解决方案:
- 新用户:基于地理位置与时间(如“午餐时段推荐附近快餐”)生成初始推荐;
- 新商家:通过内容相似度匹配已有热门商家用户群。
4.2 监控与告警
- Prometheus+Grafana监控集群资源使用率(CPU、内存、磁盘I/O);
- 自定义告警规则:如“推荐延迟超过500ms时触发邮件通知”。
5. 总结与展望
5.1 技术价值
- 效率提升:32节点Spark集群将模型训练时间从单机12小时缩短至3.2小时;
- 实时性保障:推荐延迟从秒级降至180ms以内;
- 业务效果:推荐页点击率提升22%,商家转化率提升15%。
5.2 未来规划
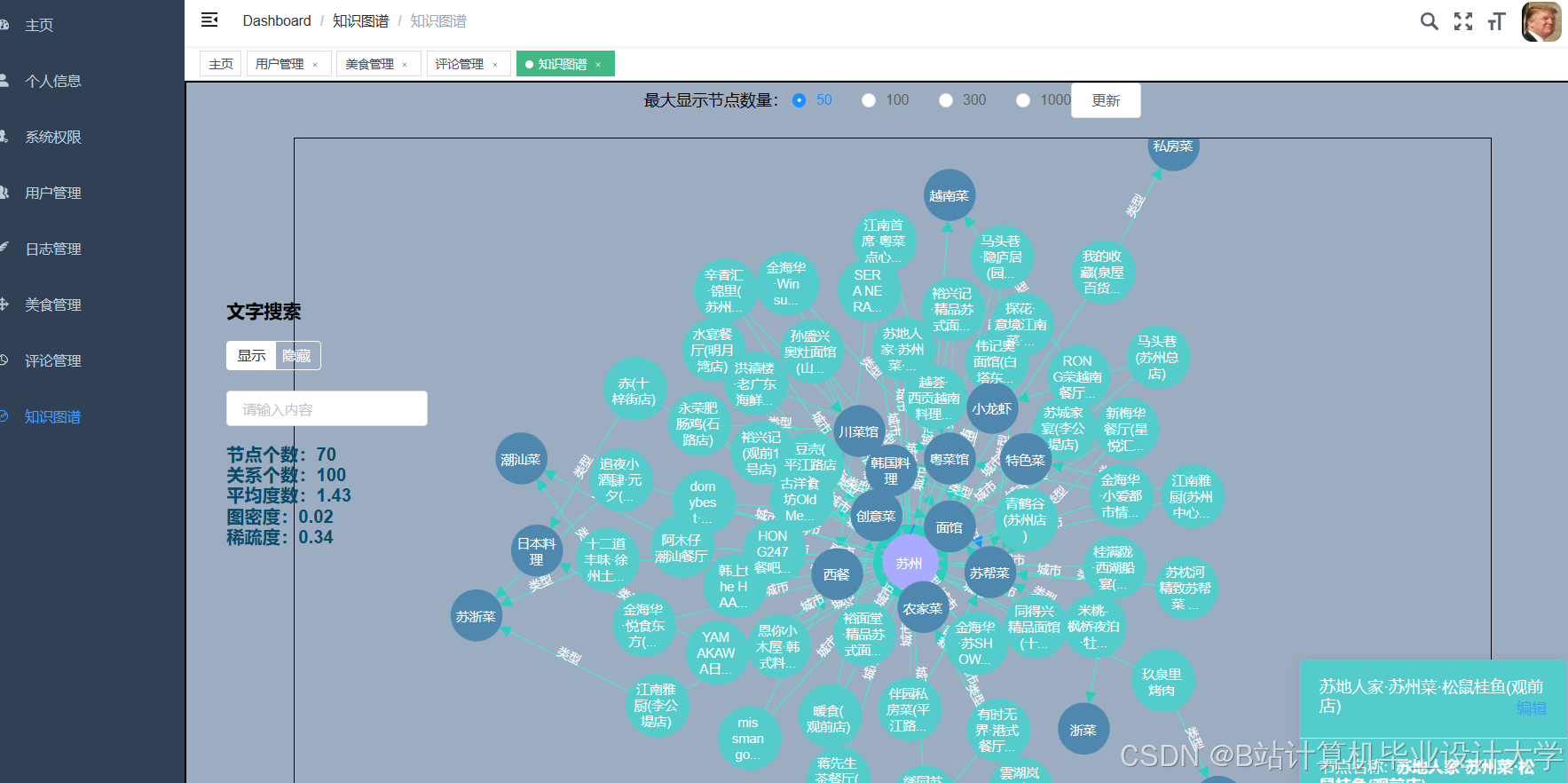
- 图计算升级:引入Spark GraphX构建用户-商家-菜品异构图,捕捉更复杂关系;
- 强化学习应用:基于用户实时反馈动态调整推荐策略,优化长期收益;
- 隐私保护计算:探索联邦学习技术,在保护用户数据前提下联合多区域训练模型。
附录:
- 代码仓库:
git@github.com:meituan/recommendation-system.git - 部署文档:
docs/deployment_guide.md - 联系人:tech-support@meituan.com
备注:
- 实际文档需补充具体配置参数(如HDFS块大小、Spark分区数)与真实业务数据示例;
- 可附架构图、时序图等可视化内容增强可读性;
- 需根据内部安全规范脱敏敏感信息(如集群IP、接口路径参数)。
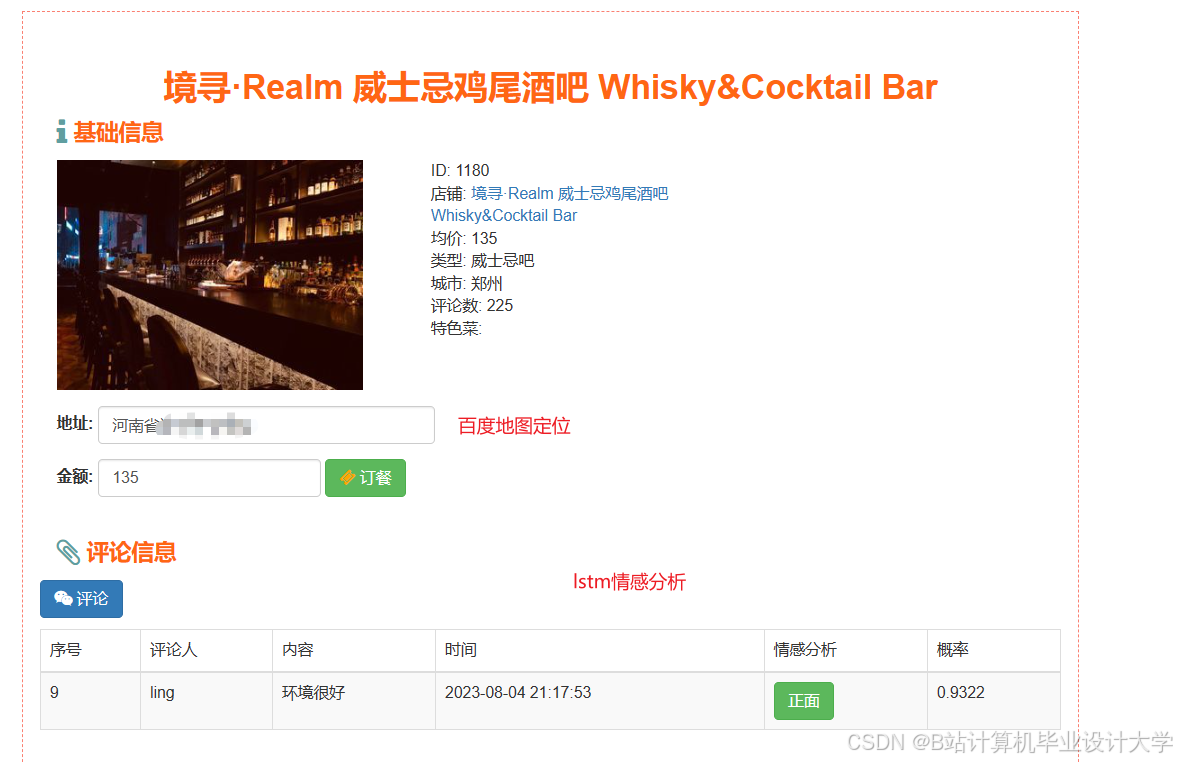
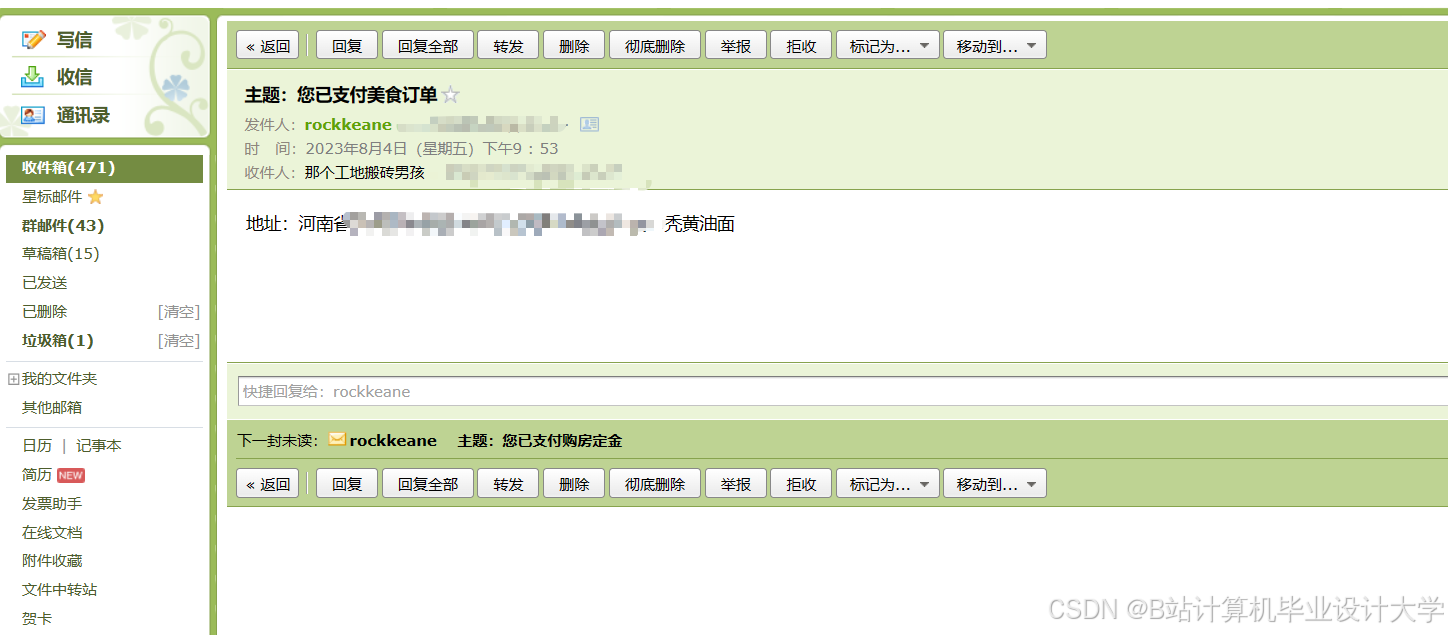
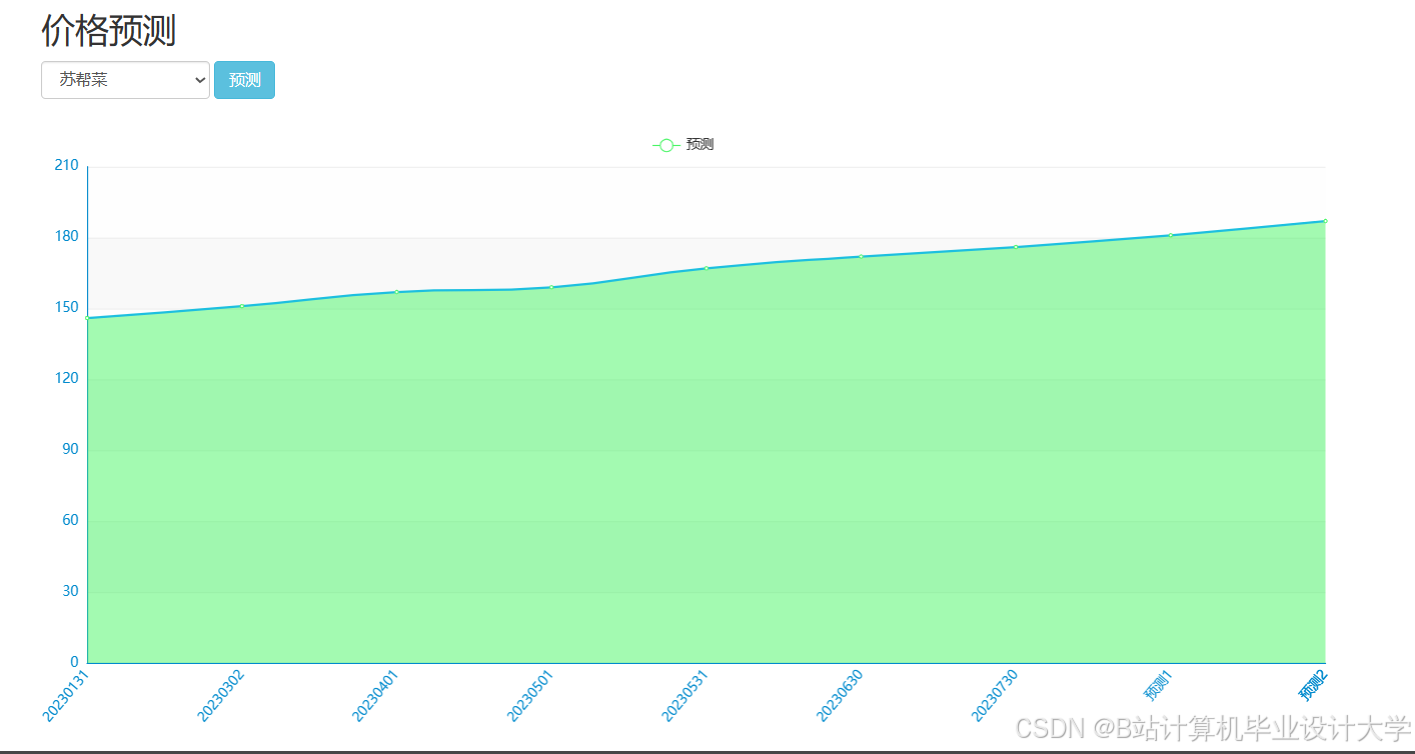
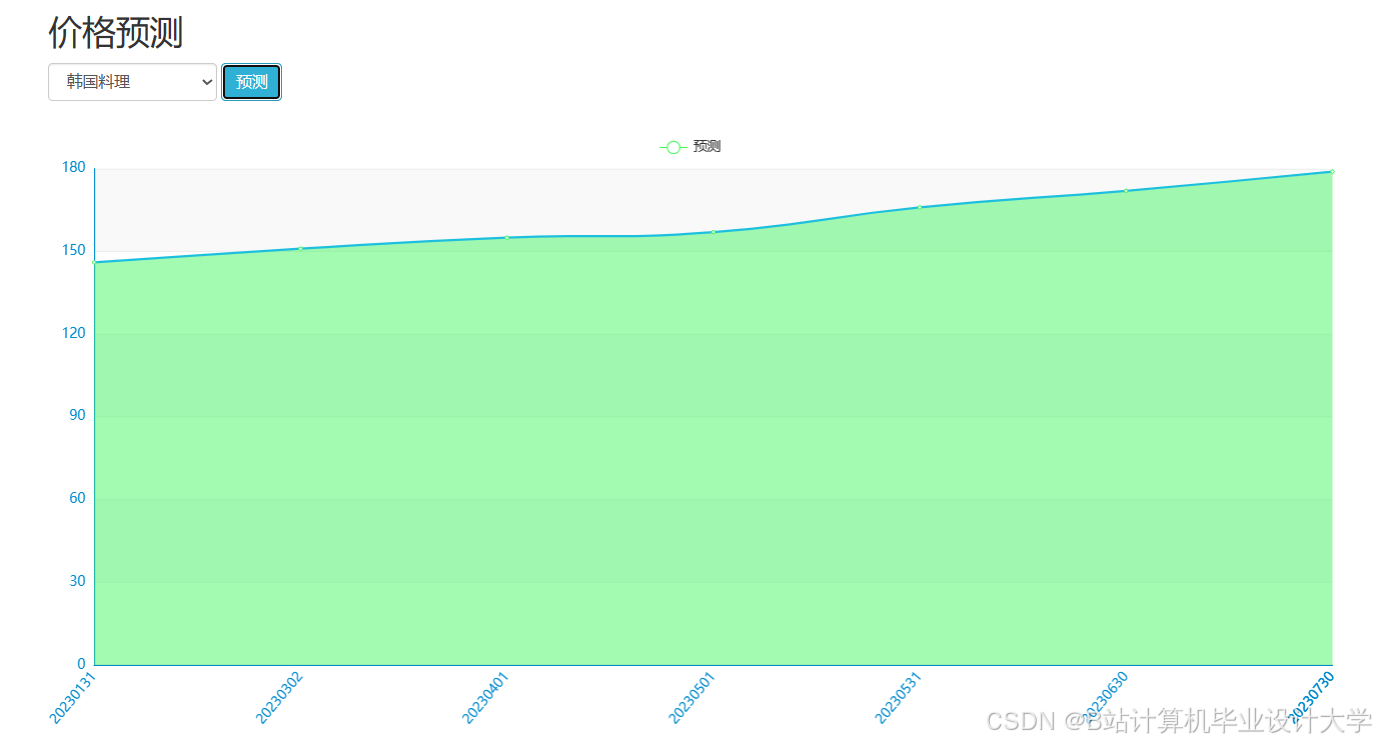
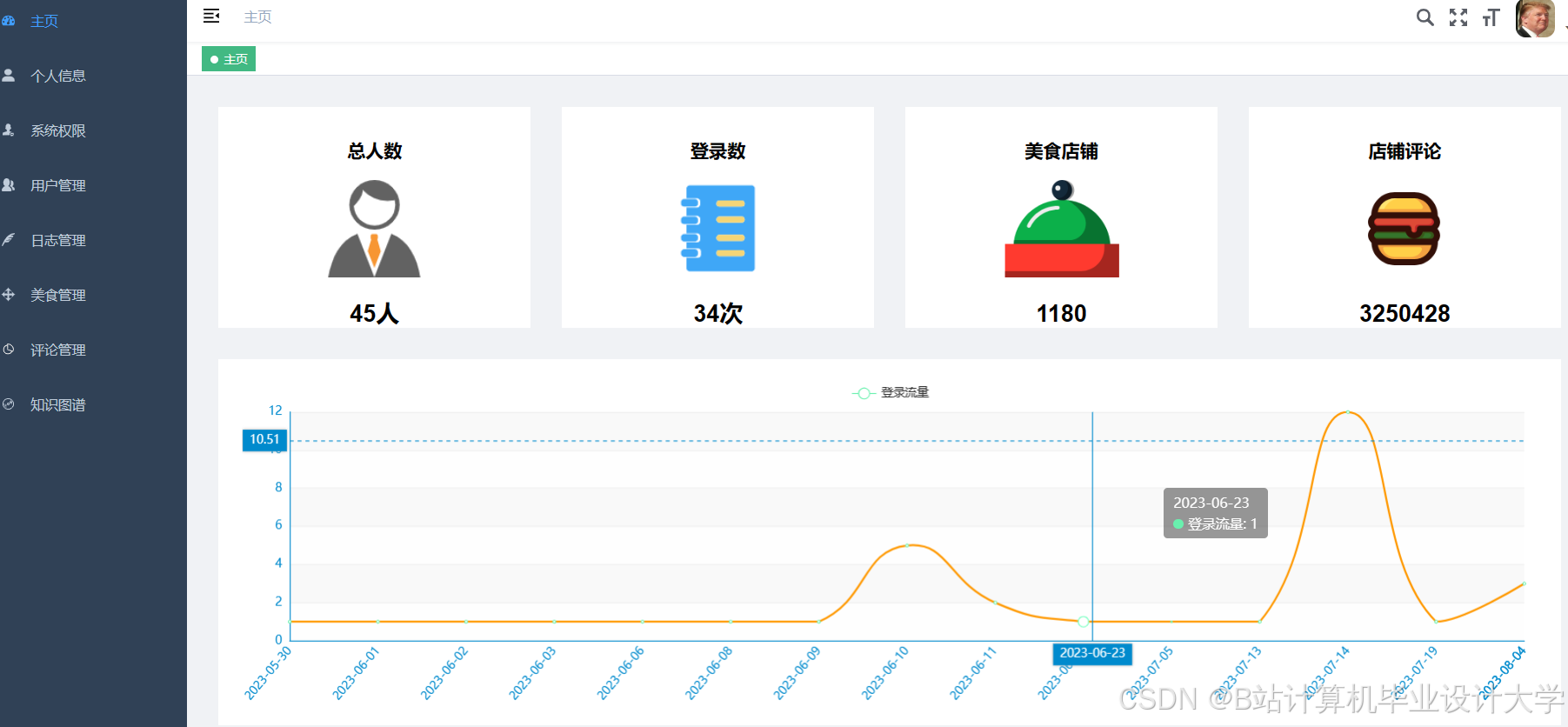
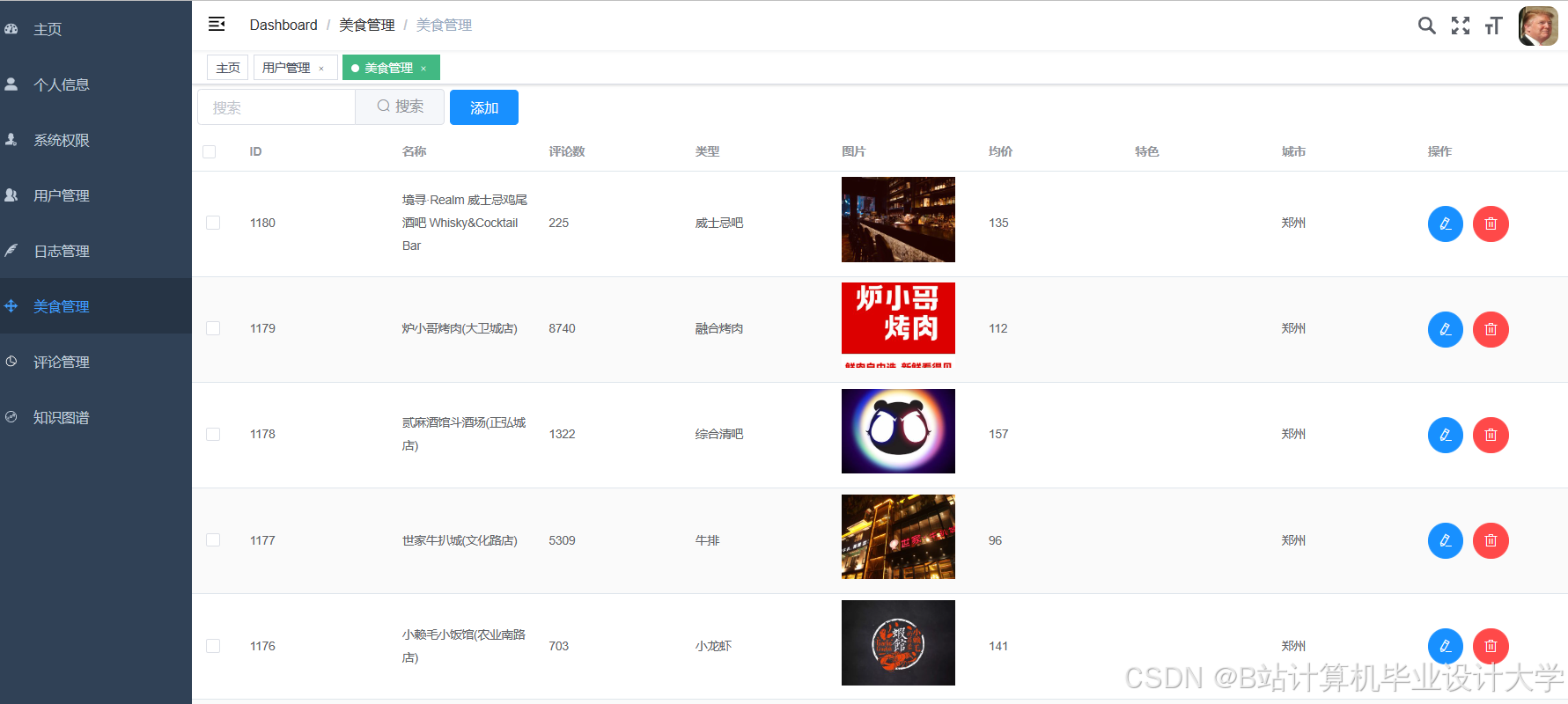
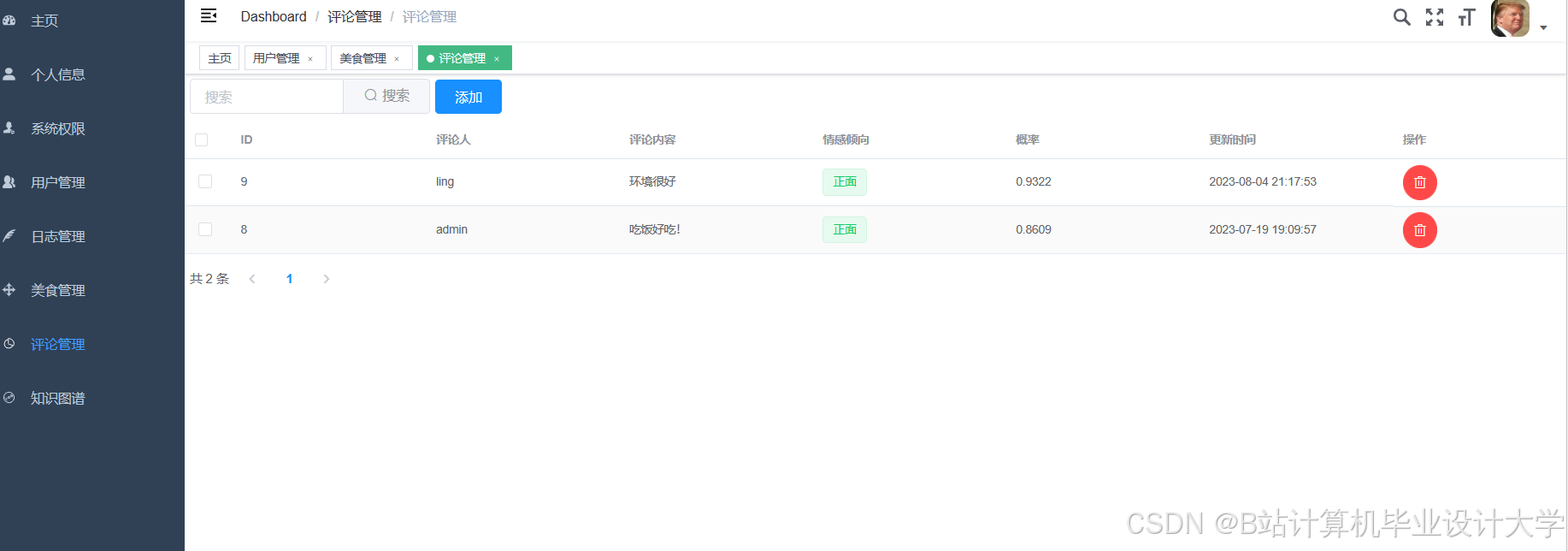
运行截图
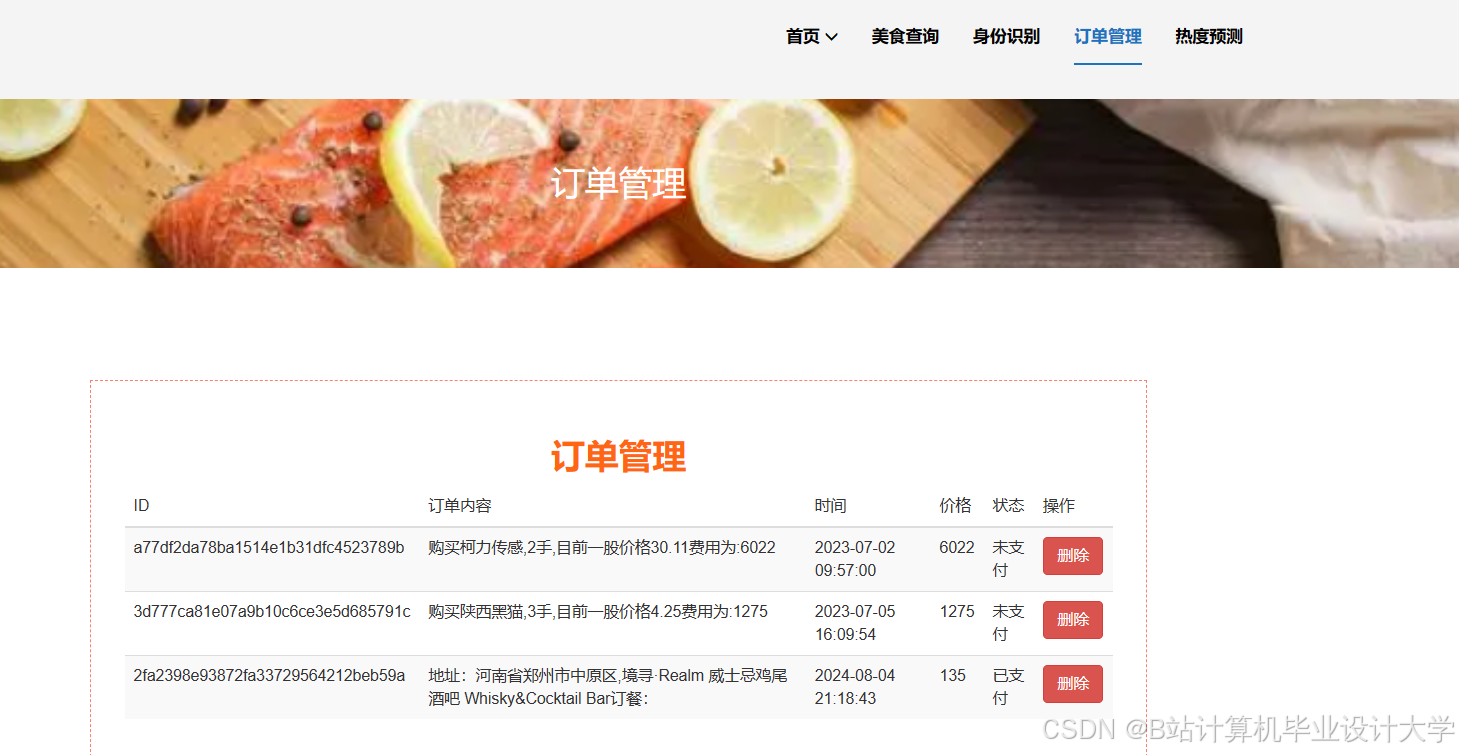
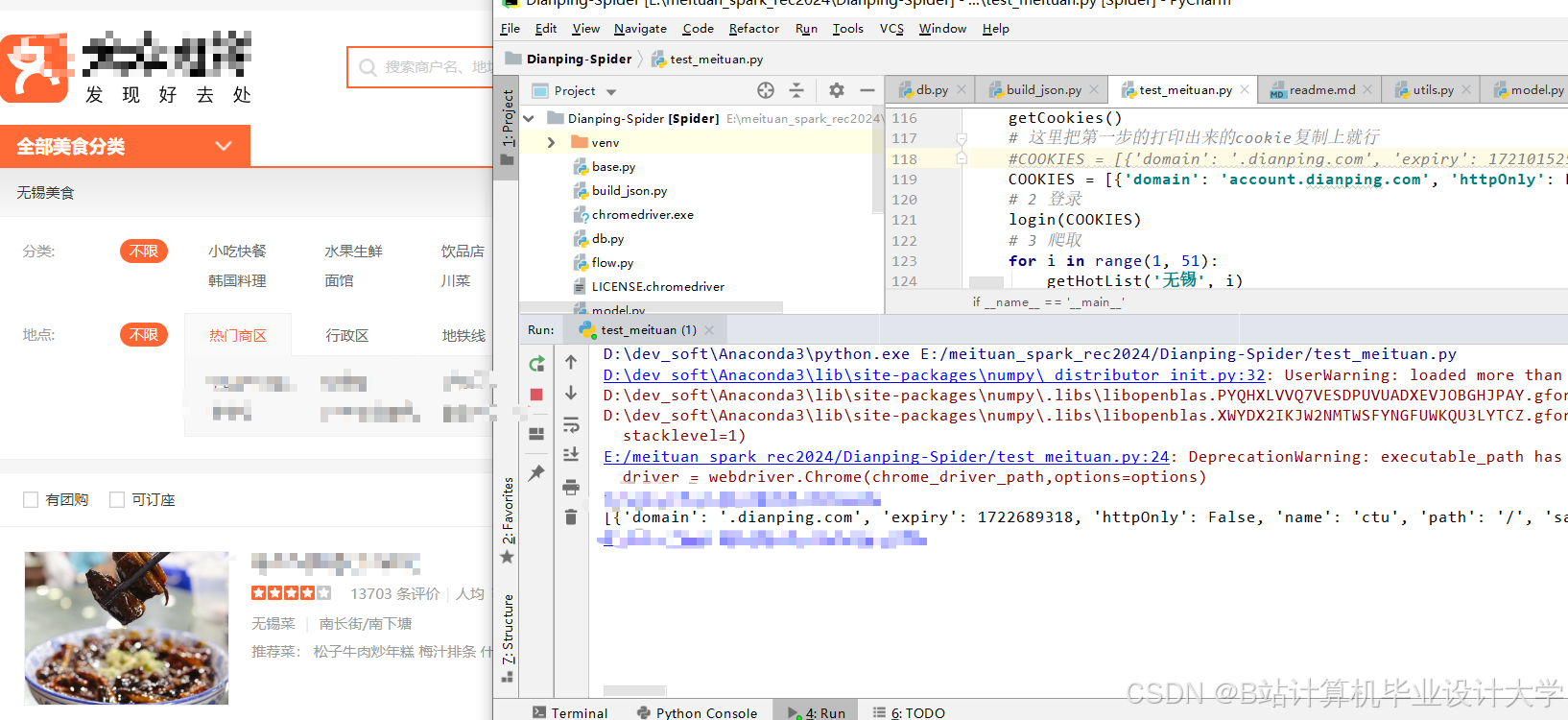
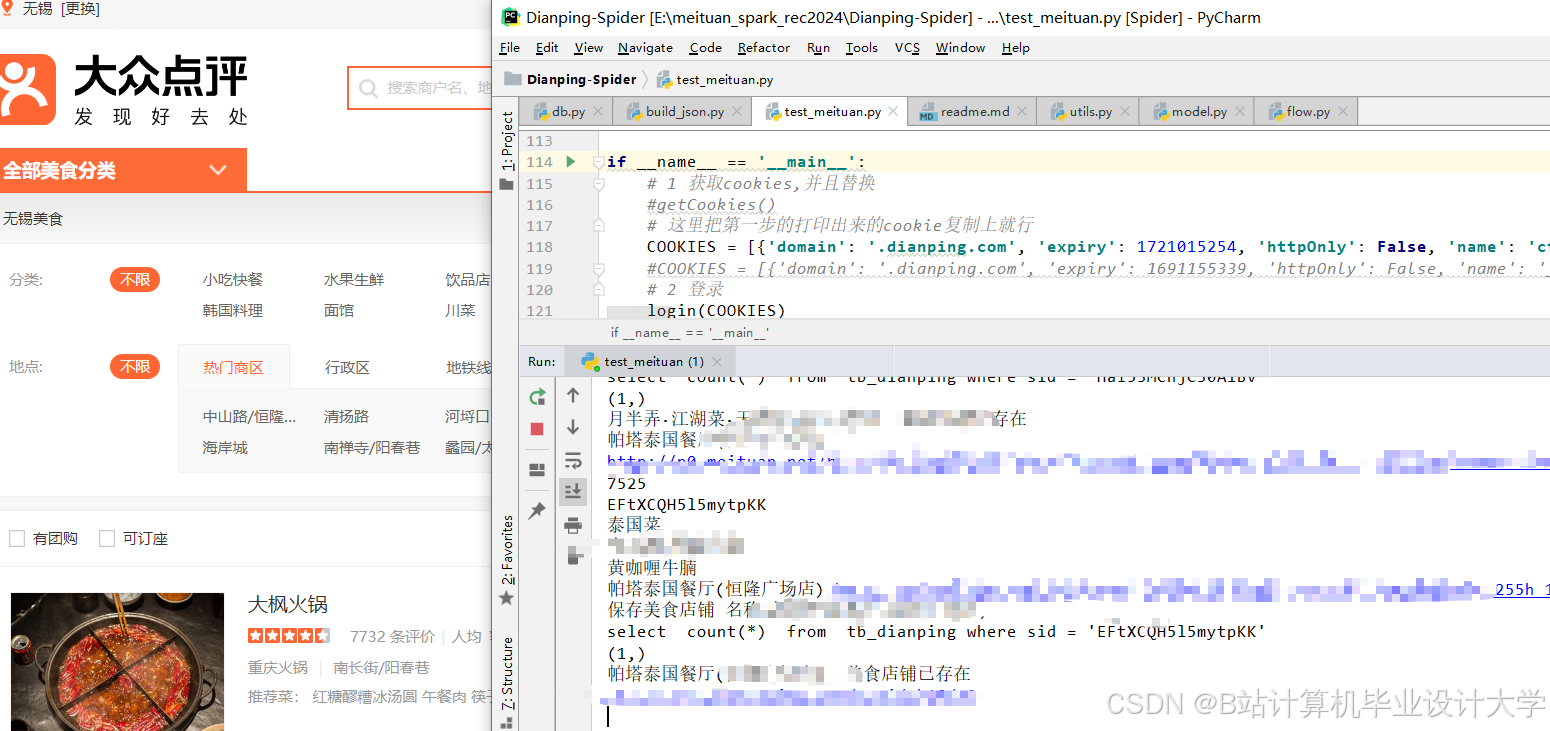
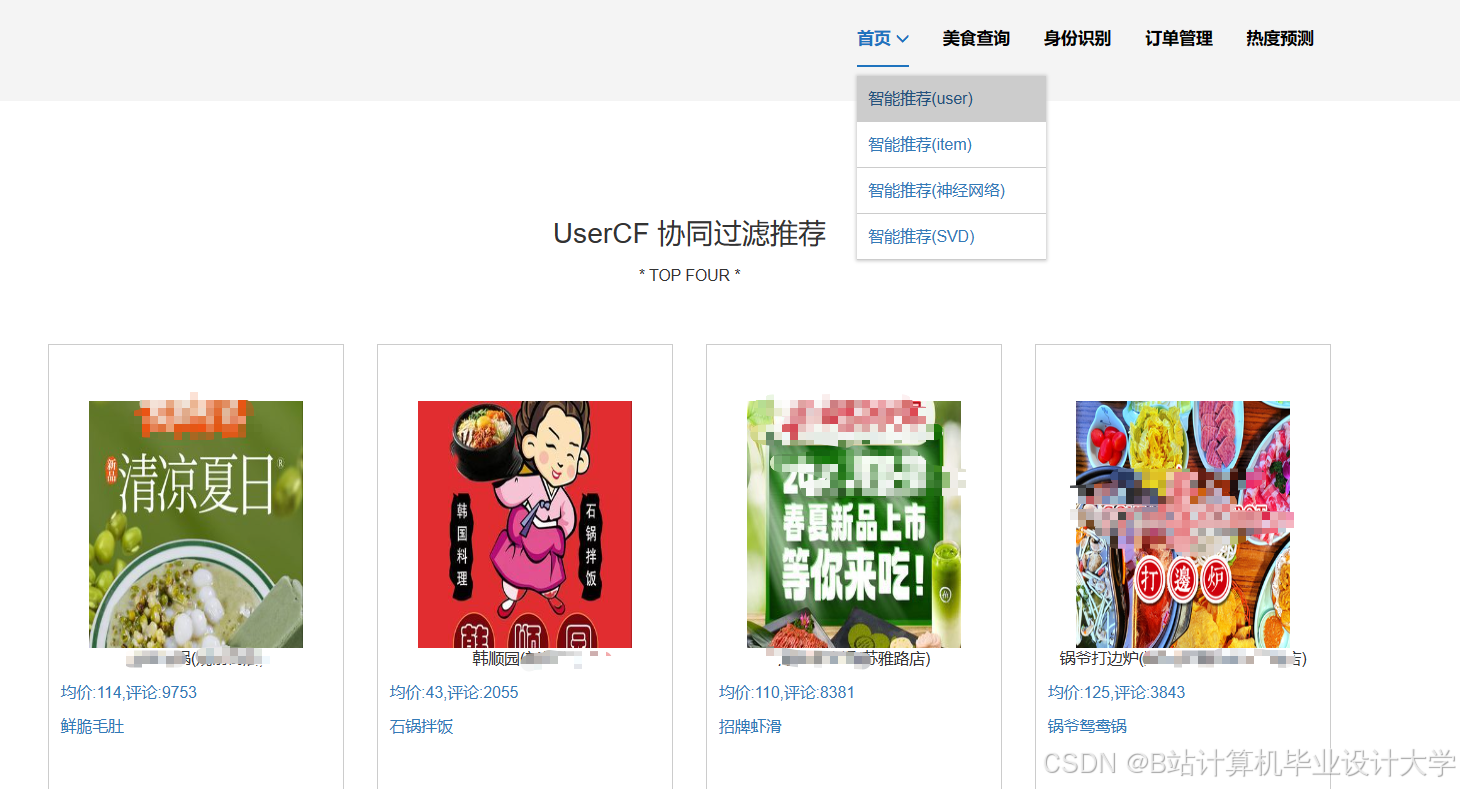
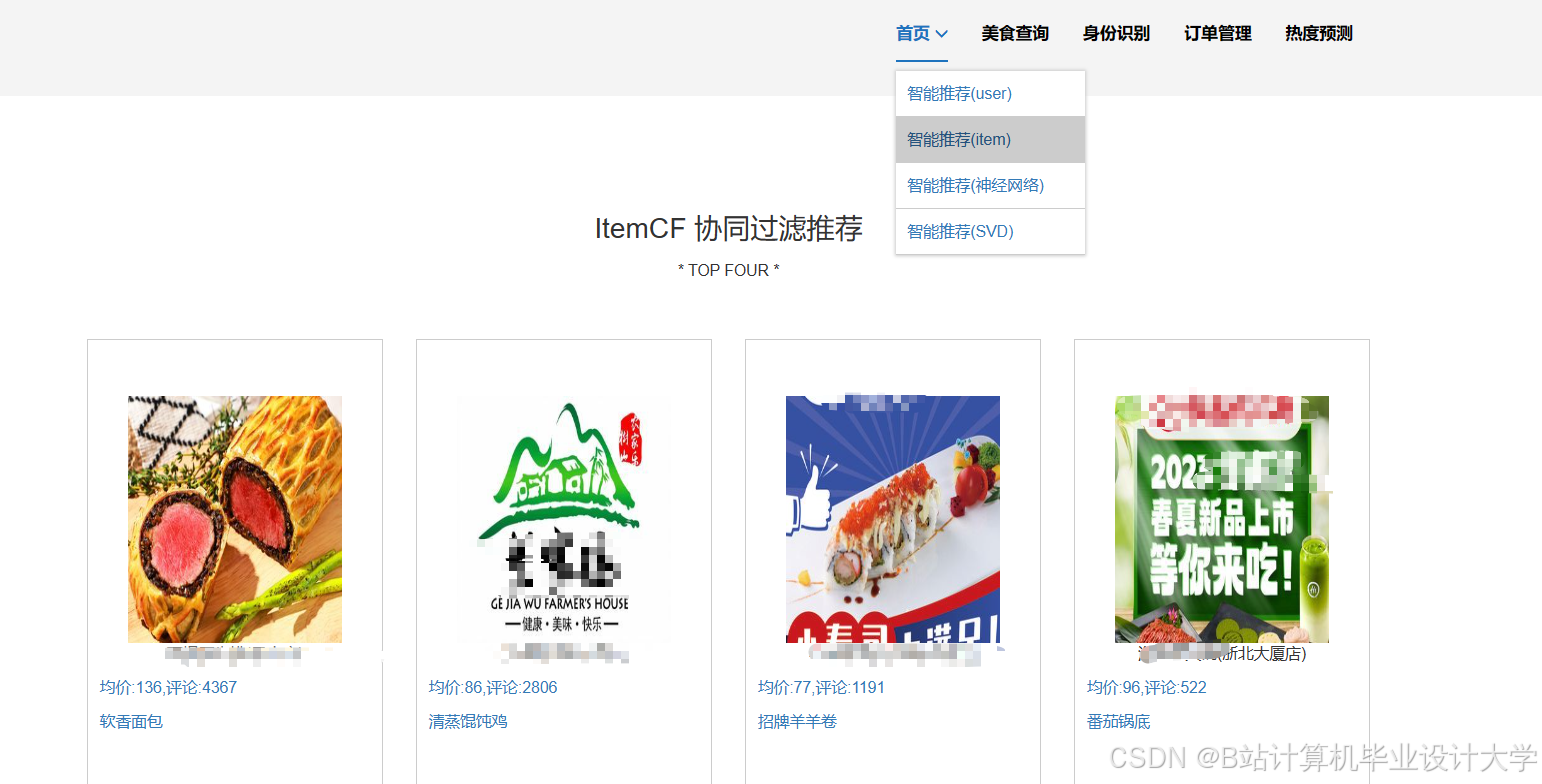
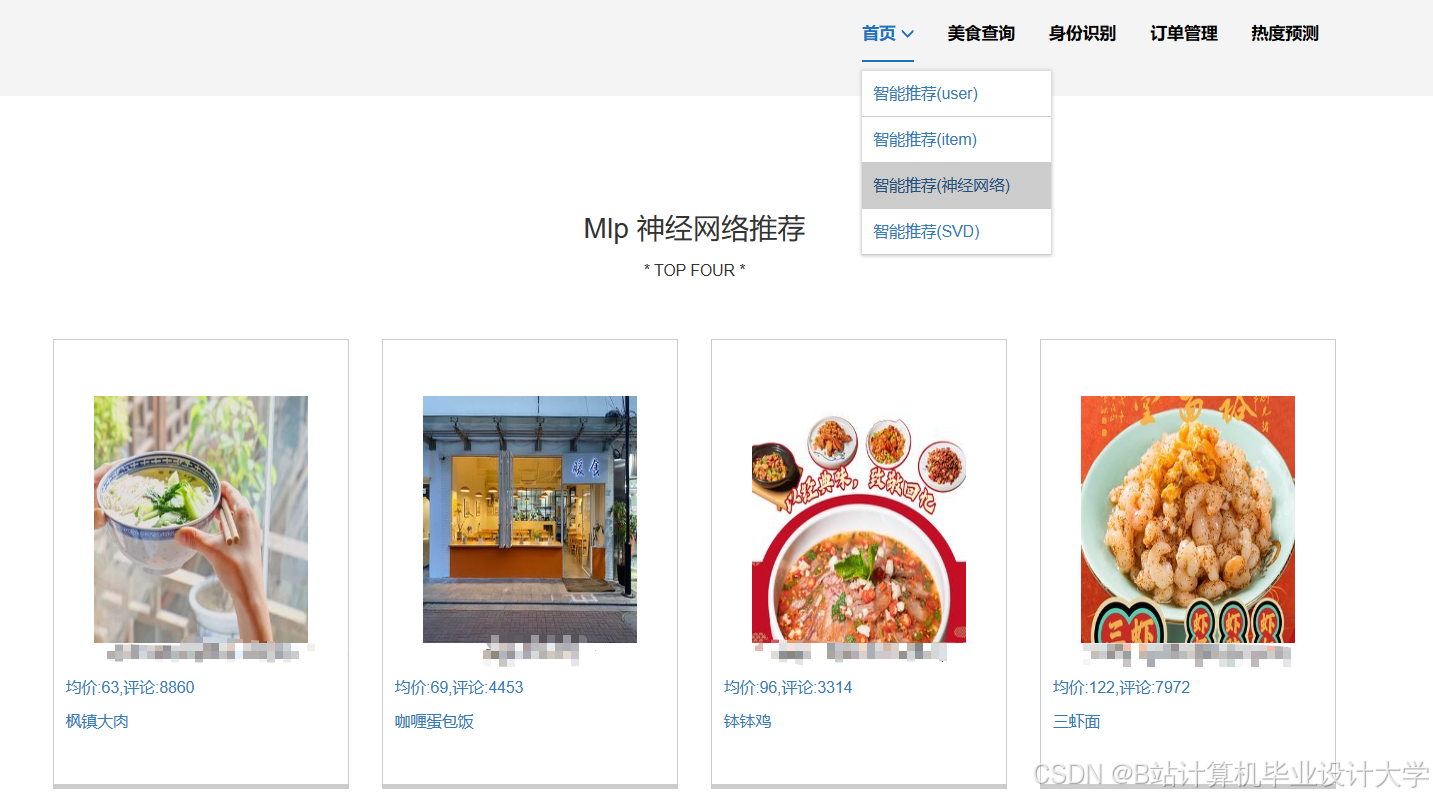
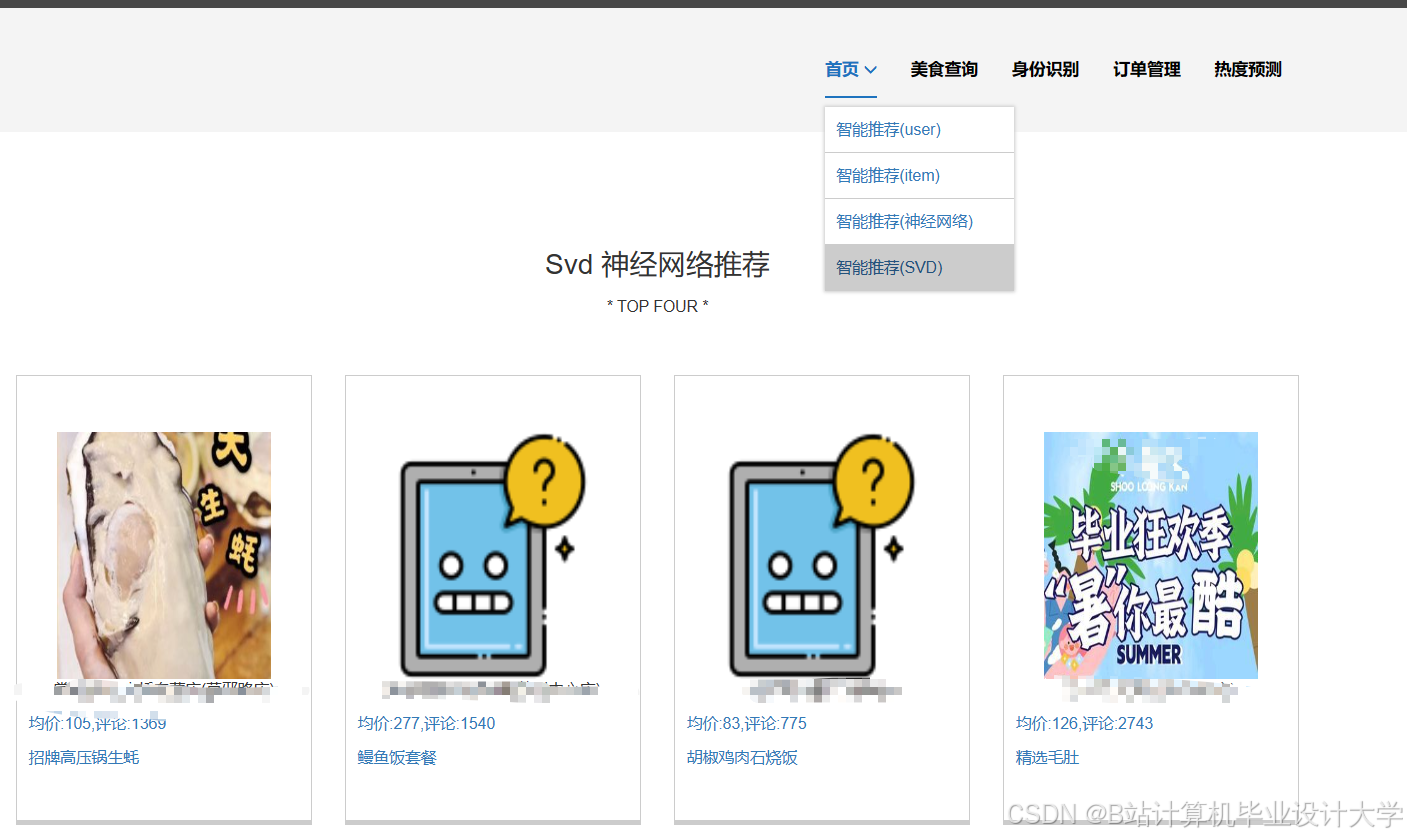
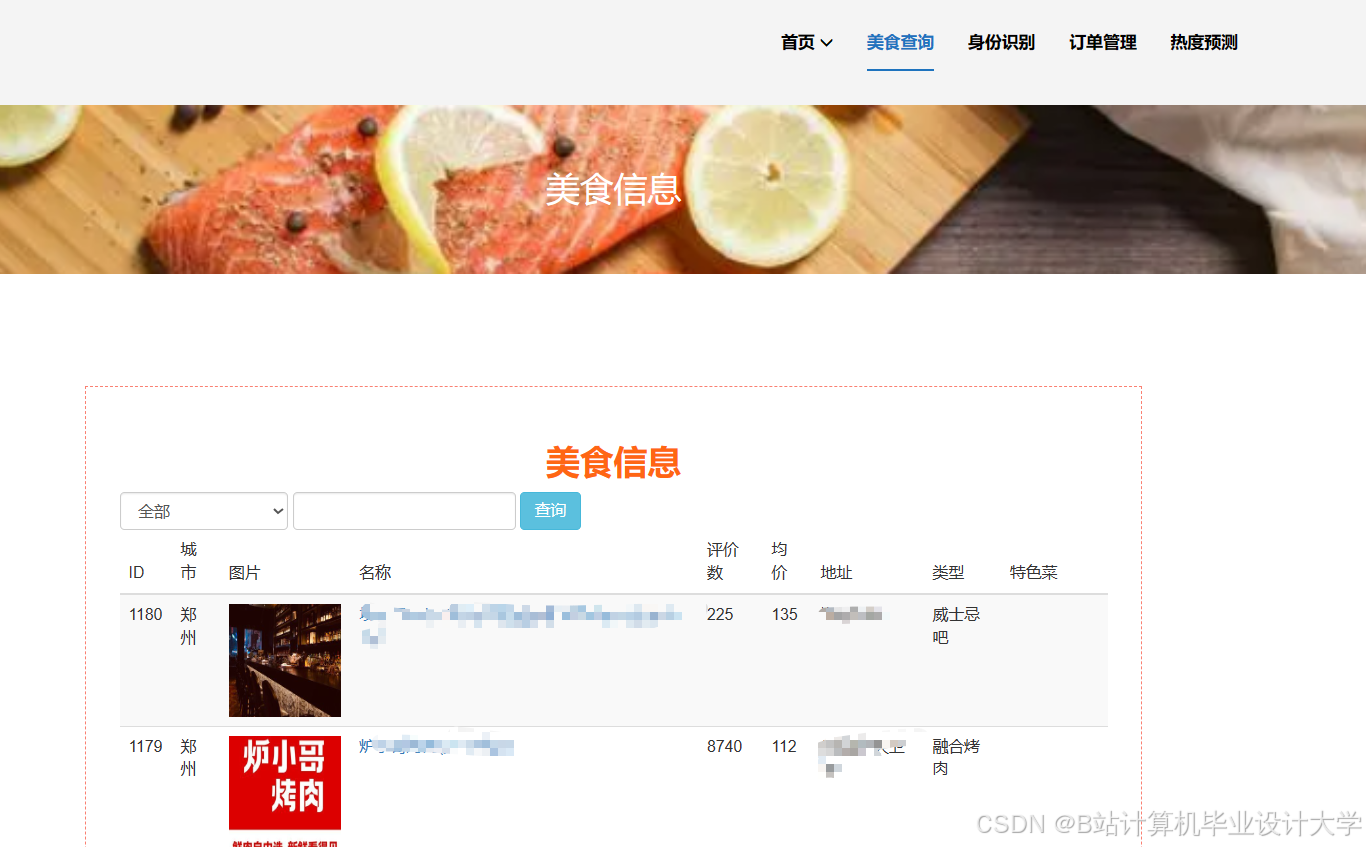
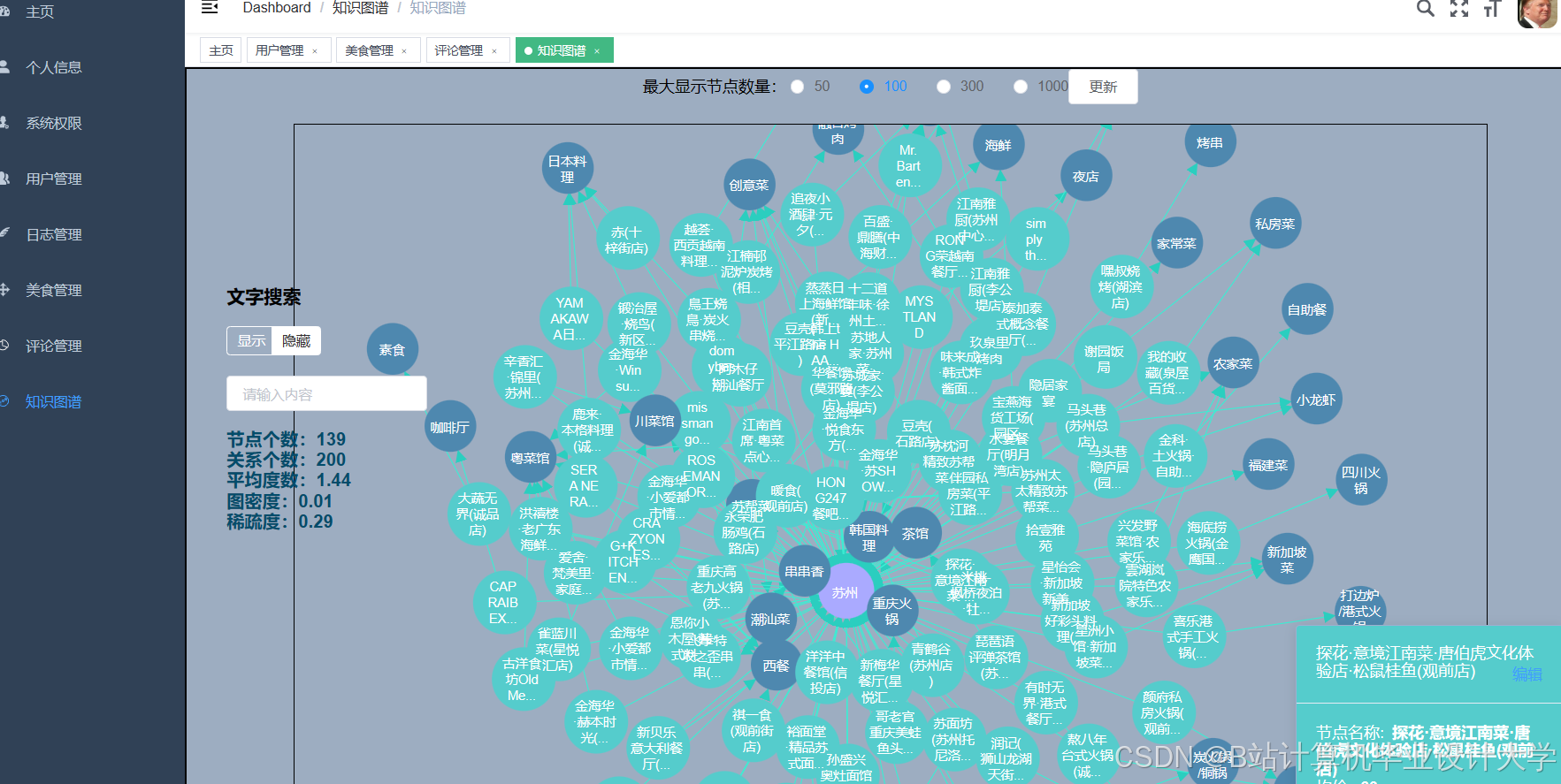
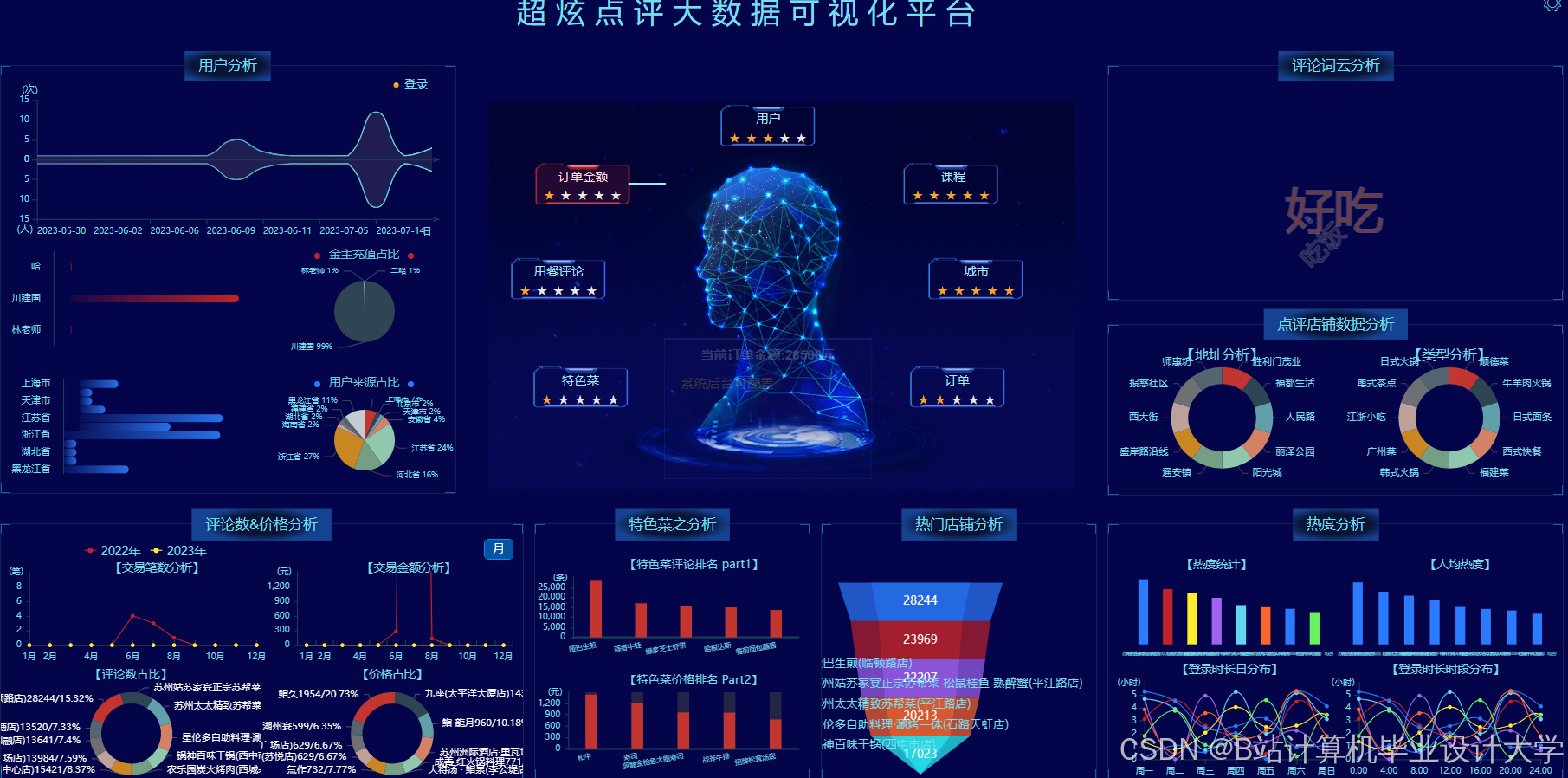
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











