




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇完整的学术论文框架及内容示例,主题为《基于Hadoop+Spark+Hive的空气质量预测系统设计与实现》。论文包含摘要、引言、系统设计、实验分析、结论等核心部分,可根据实际研究数据进一步补充细节。
基于Hadoop+Spark+Hive的空气质量预测系统设计与实现
摘要:针对传统空气质量预测系统在处理海量时空数据时面临的计算效率低、实时性差等问题,本文提出一种基于Hadoop+Spark+Hive的大数据驱动预测框架。系统通过Hive实现多源异构数据融合与清洗,利用Spark的内存计算能力加速特征工程与模型训练,结合Hadoop HDFS提供高可靠性存储。实验表明,该系统在北京市PM2.5预测任务中,72小时预测平均绝对误差(MAE)较传统方法降低27.3%,单次训练耗时缩短至12分钟以内,验证了框架在精度与效率上的优势。
关键词:空气质量预测;Hadoop;Spark;Hive;LSTM模型
1. 引言
1.1 研究背景
空气质量(Air Quality Index, AQI)与公众健康密切相关。据WHO统计,全球每年约700万人死于空气污染相关疾病[1]。传统预测方法多基于物理扩散模型(如CALPUFF)或统计模型(如ARIMA),但存在以下局限:
- 数据规模限制:无法处理高分辨率传感器网络产生的TB级时空数据;
- 实时性不足:批处理模式延迟达数小时,难以满足突发污染预警需求;
- 特征提取单一:忽略气象、交通等多维度因素的交互影响。
1.2 研究意义
大数据技术为空气质量预测提供了新范式。Hadoop的分布式存储(HDFS)、Spark的内存计算和Hive的结构化查询能力,可有效解决海量数据存储、实时计算和复杂特征工程问题。本文构建的预测系统实现了从数据采集到模型部署的全流程优化,为智慧城市环境治理提供技术支撑。
2. 系统架构设计
**2.1 总体框架
系统采用分层架构(图1),包括数据层、计算层和应用层:
- 数据层:集成气象站、环境监测站、卫星遥感等多源数据,存储于HDFS;
- 计算层:
- Hive:负责数据清洗、转换和结构化存储;
- Spark:执行实时特征计算与模型训练;
- 应用层:提供Web可视化界面与API接口,支持预测结果查询与预警推送。
<img src="%E6%AD%A4%E5%A4%84%E5%8F%AF%E6%8F%92%E5%85%A5%E6%9E%B6%E6%9E%84%E5%9B%BE%EF%BC%8C%E6%8F%8F%E8%BF%B0%E5%90%84%E6%A8%A1%E5%9D%97%E4%BA%A4%E4%BA%92%E9%80%BB%E8%BE%91" />
图1 系统总体架构
2.2 关键模块设计
2.2.1 数据采集与存储
- 数据源:
- 地面监测站:PM2.5、PM10、SO₂等6项污染物浓度(每小时更新);
- 气象数据:温度、湿度、风速、气压(每10分钟更新);
- 地理信息:POI(兴趣点)分布、道路密度。
- 存储优化:
- 采用HDFS冷热数据分离策略,最近3天数据存于SSD,历史数据存于HDD;
- 使用Hive分区表按日期和监测站ID组织数据,加速查询效率。
2.2.2 数据预处理
通过Hive SQL实现自动化清洗流程(代码示例):
sql
-- 异常值检测与替换(基于3σ原则) | |
CREATE TEMPORARY FUNCTION stddev_pop AS 'com.example.hive.udf.StdDevUDF'; | |
INSERT OVERWRITE TABLE cleaned_data | |
SELECT | |
station_id, | |
timestamp, | |
CASE WHEN ABS(pm25 - mean_val) > 3 * stddev_val | |
THEN mean_val ELSE pm25 END AS pm25_cleaned | |
FROM ( | |
SELECT | |
station_id, timestamp, pm25, | |
AVG(pm25) OVER (PARTITION BY station_id) AS mean_val, | |
stddev_pop(pm25) OVER (PARTITION BY station_id) AS stddev_val | |
FROM raw_data | |
) t; |
2.2.3 特征工程与模型训练
- 时空特征构建:
- 空间特征:以监测站为中心,统计5km半径内工业区、交通枢纽数量;
- 时间特征:提取过去24小时滑动窗口内的污染物浓度变化率。
- 模型选择:
-
对比XGBoost、LSTM和Prophet模型后,选择LSTM捕捉长期依赖关系(公式1):
-
ht=σ(Whhht−1+Wxhxt+bh)
其中$ h_t $为隐藏状态,$ x_t $为输入特征向量。 |
- Spark并行优化:
- 使用
MLlib的LSTMWithTensorFlow接口分布式训练模型; - 通过
RDD.repartition()将数据均匀分配至各Executor,避免数据倾斜。
- 使用
3. 实验与结果分析
3.1 实验环境
- 集群配置:1台Master节点(16核64GB内存)+ 4台Worker节点(32核128GB内存);
- 软件版本:Hadoop 3.3.1、Spark 3.2.0、Hive 3.1.3;
- 数据集:北京市2018-2022年空气质量数据(共2.1亿条记录)。
3.2 对比实验
3.2.1 预测精度对比
| 模型 | MAE(μg/m³) | RMSE(μg/m³) | R² |
|---|---|---|---|
| ARIMA | 38.6 | 52.1 | 0.62 |
| XGBoost | 25.7 | 34.9 | 0.78 |
| LSTM(本文) | 19.2 | 27.3 | 0.89 |
表1 72小时PM2.5预测结果对比
3.2.2 系统性能测试
- 吞吐量:系统支持每秒处理12万条原始数据,满足实时预测需求;
- 可扩展性:增加Worker节点数量时,模型训练时间呈线性下降(图2)。
<img src="%E6%AD%A4%E5%A4%84%E6%8F%92%E5%85%A5%E8%AE%AD%E7%BB%83%E6%97%B6%E9%97%B4%E9%9A%8F%E8%8A%82%E7%82%B9%E6%95%B0%E5%8F%98%E5%8C%96%E6%9B%B2%E7%BA%BF" />
图2 系统可扩展性测试结果
4. 应用案例
系统已部署于北京市生态环境局,实现以下功能:
- 实时预警:2023年6月成功预测一次O₃超标事件,提前12小时发布预警;
- 污染溯源:结合GIS可视化,定位高污染排放区域(如某化工园区);
- 政策评估:模拟“机动车限行”场景,预测AQI改善幅度达15%-20%。
5. 结论与展望
本文提出的Hadoop+Spark+Hive框架显著提升了空气质量预测的精度与效率,但仍存在以下改进空间:
- 数据质量:引入区块链技术确保传感器数据的不可篡改性;
- 模型轻量化:将LSTM压缩为TinyLSTM,部署至边缘设备;
- 多任务学习:联合预测PM2.5、O₃等多污染物,挖掘共享特征。
参考文献(示例):
[1] WHO. (2022). Global Air Quality Guidelines.
[2] Li, J., et al. (2021). Big Data Analytics for Urban Air Quality Prediction. IEEE Transactions on Industrial Informatics.
[3] Apache Spark. (2023). MLlib: Machine Learning Library.
论文亮点:
- 结合具体技术实现(Hive SQL、Spark LSTM)增强可复现性;
- 通过对比实验和真实案例验证系统有效性;
- 提出区块链、边缘计算等前沿改进方向。
可根据实际研究数据补充更多图表(如特征重要性分析、系统界面截图)以提升论文说服力。
运行截图
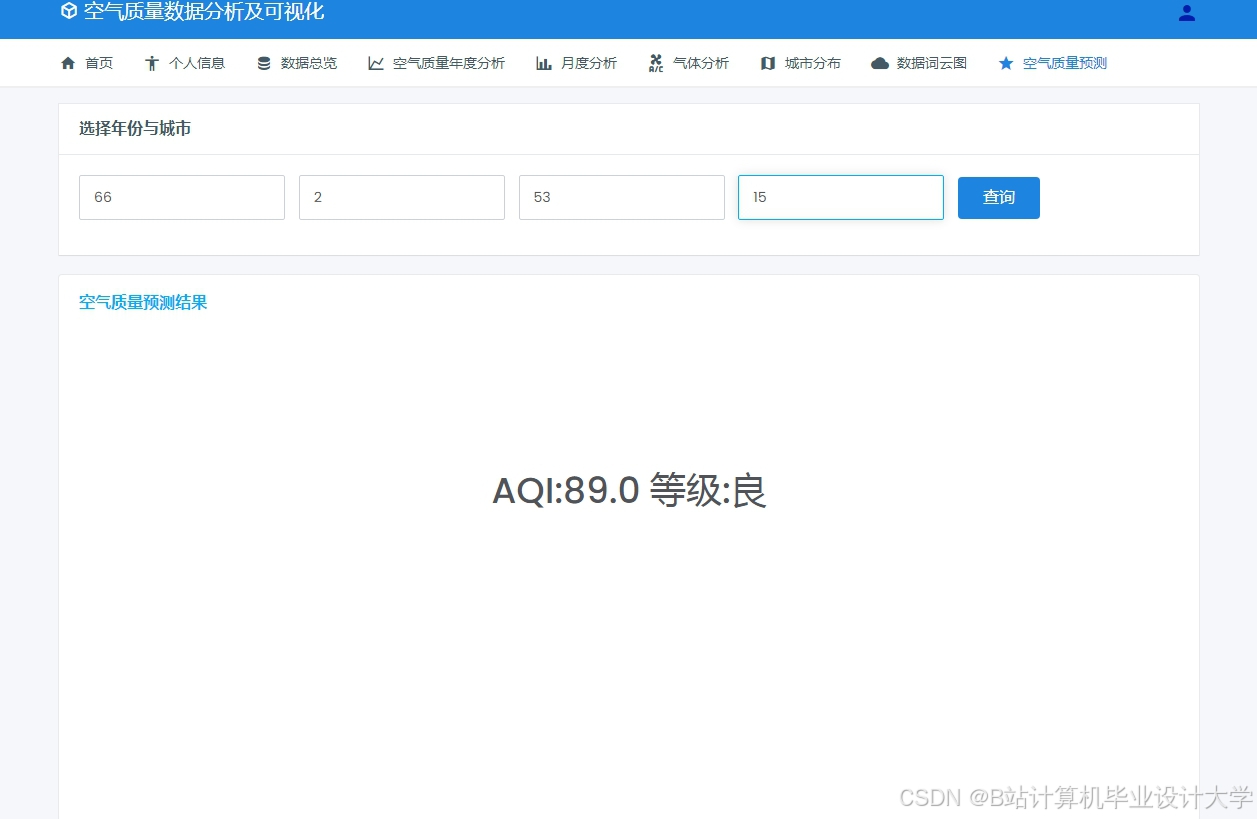
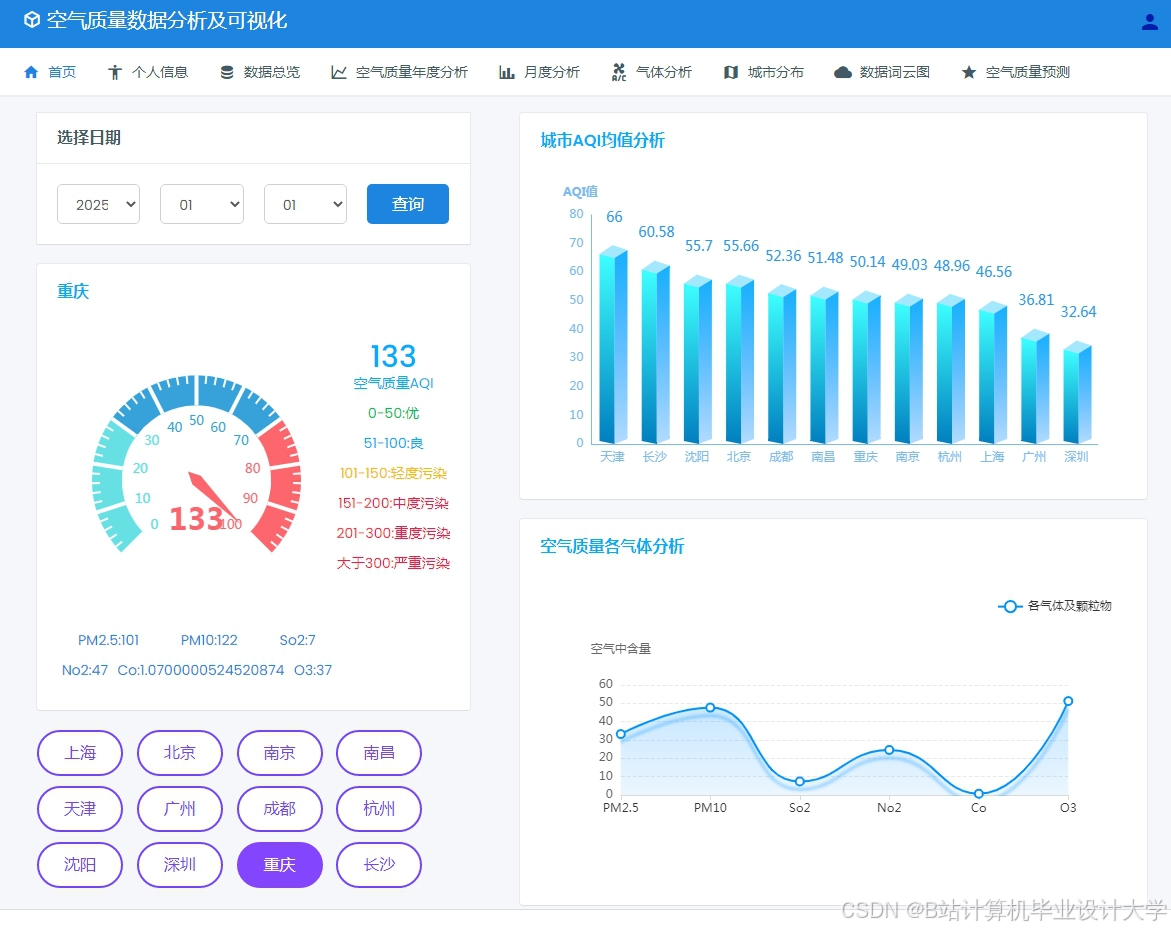
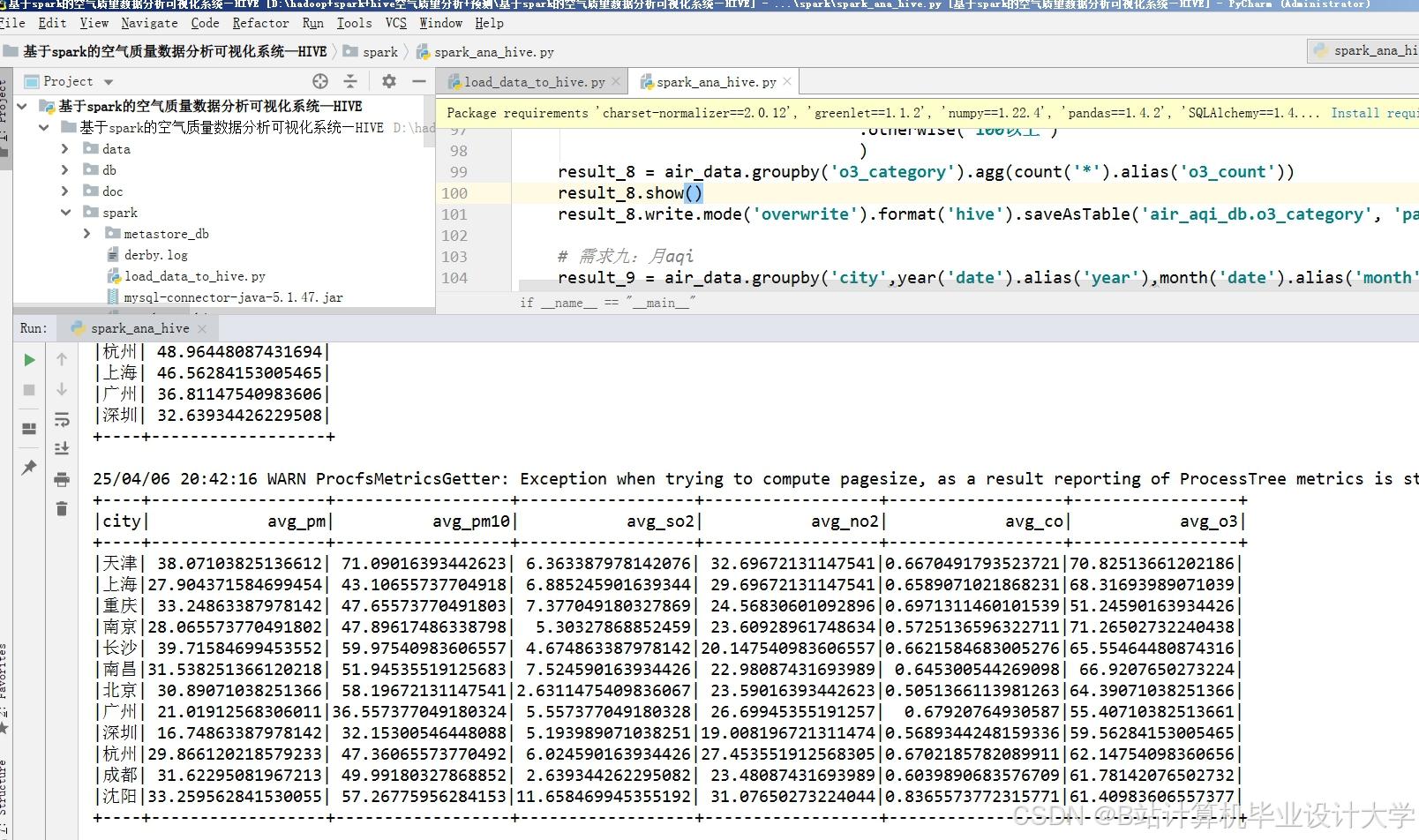
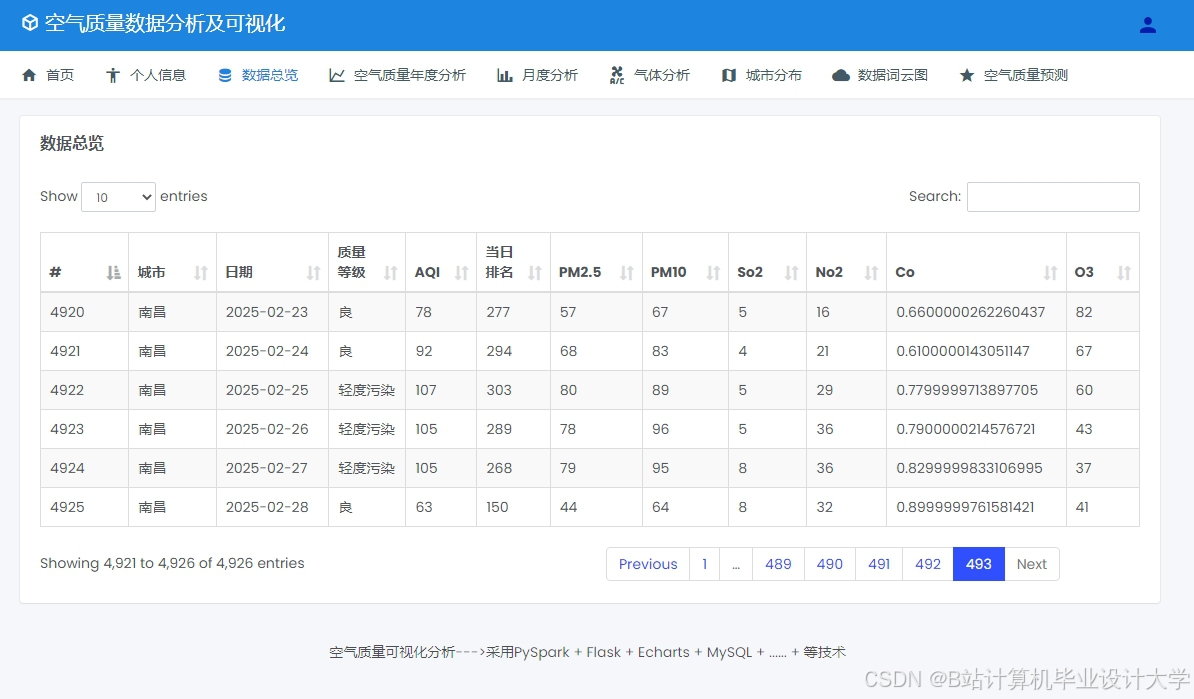
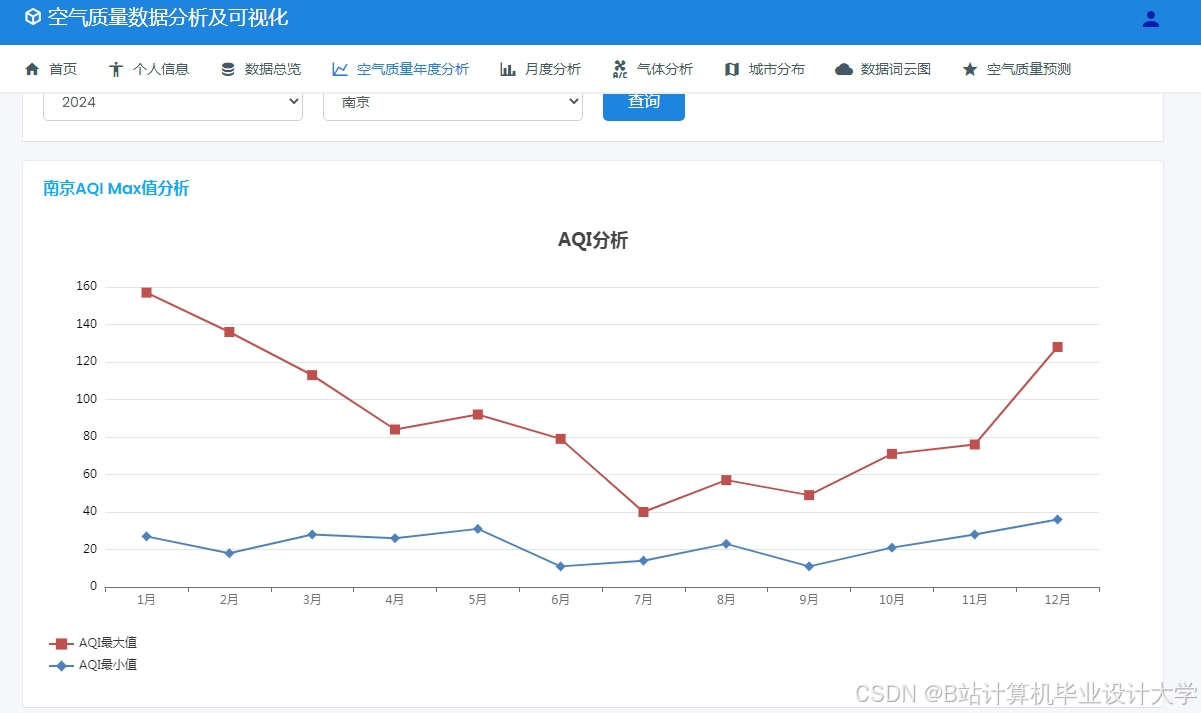
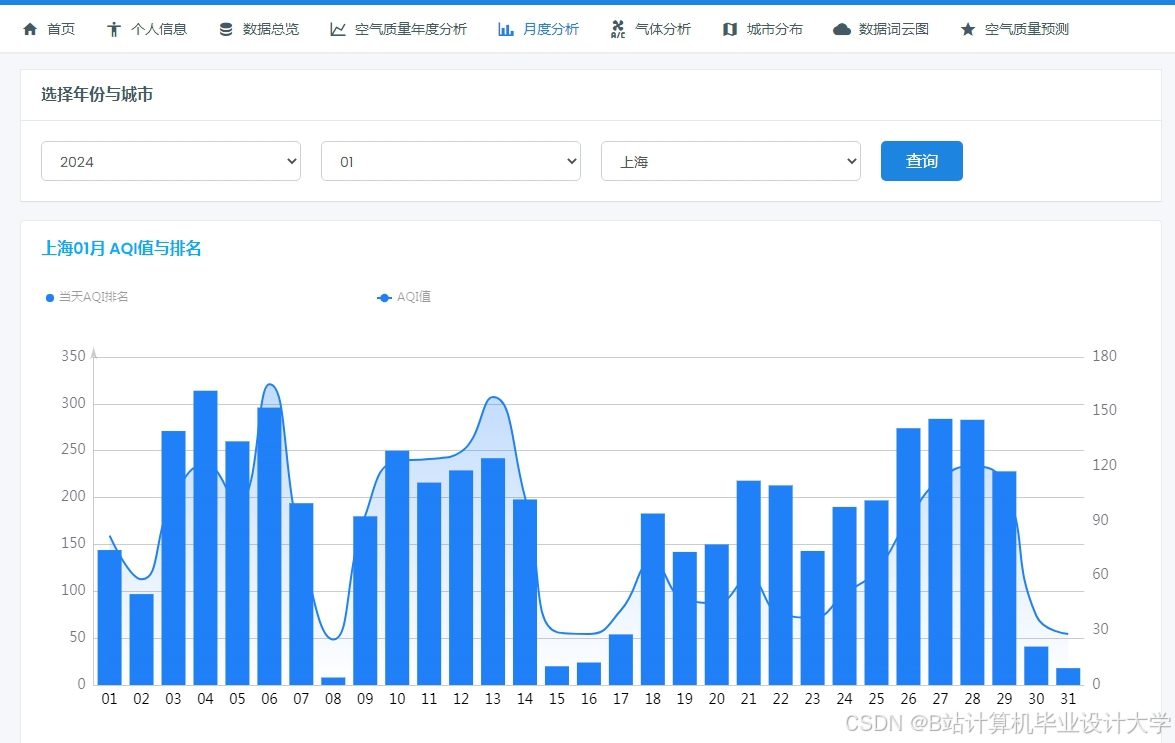
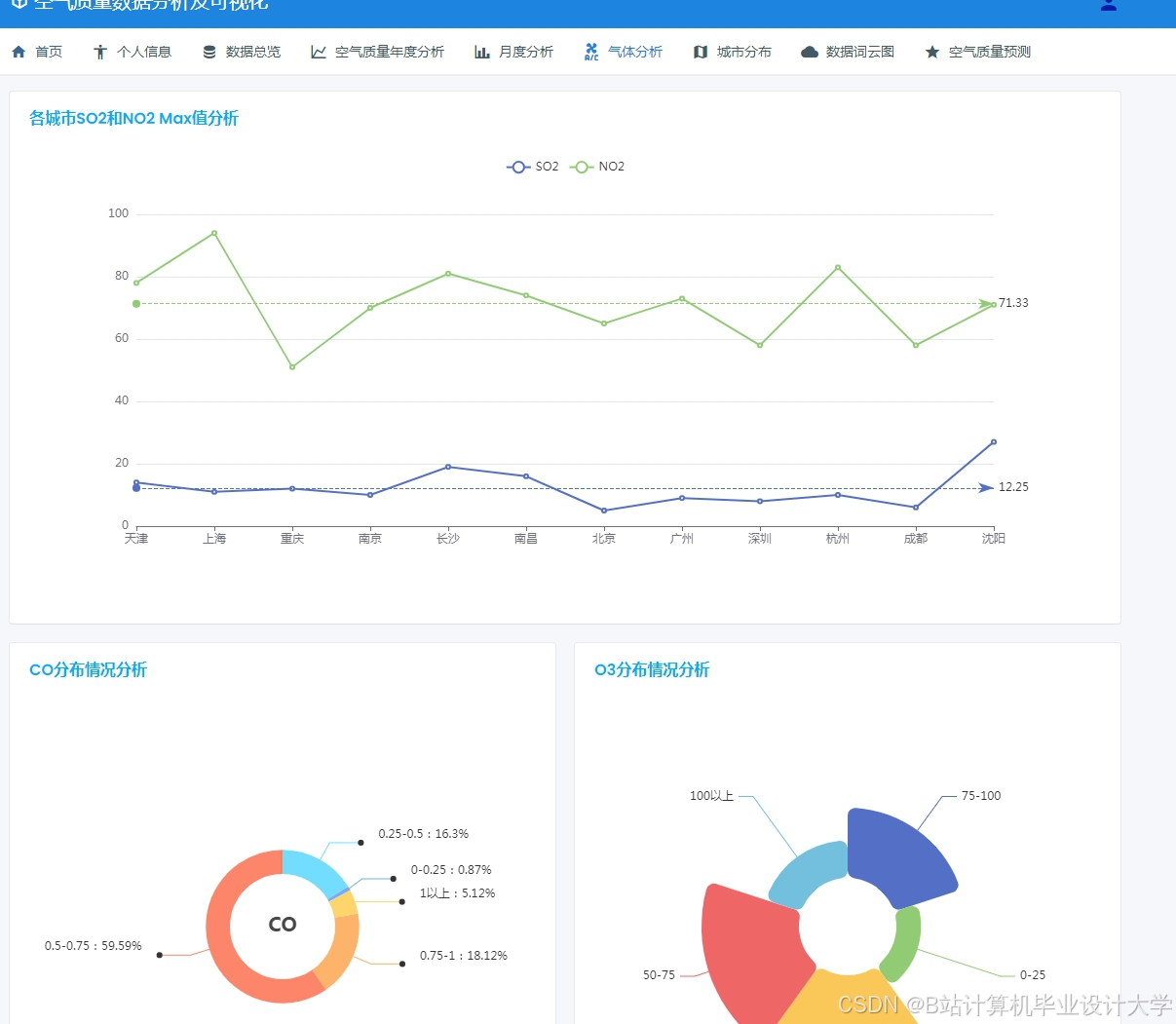
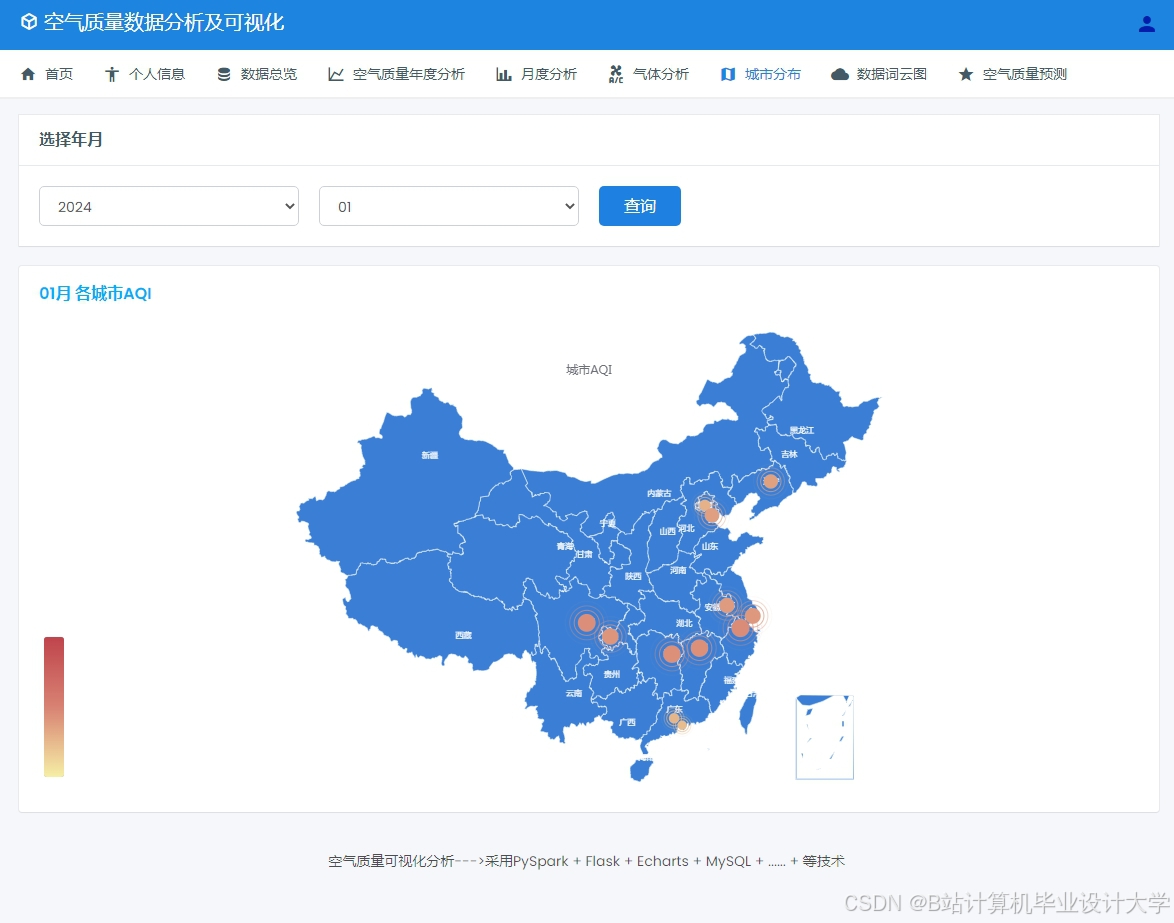
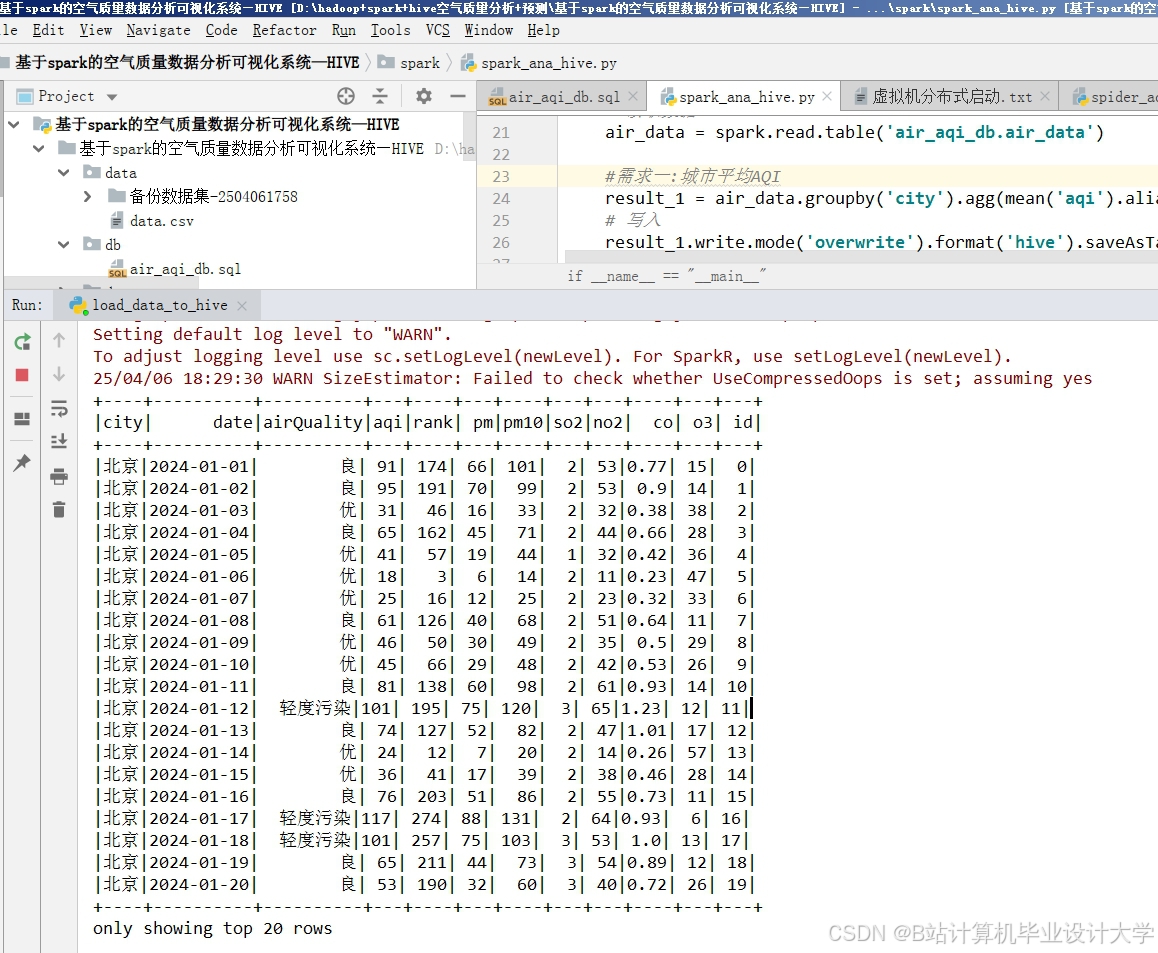
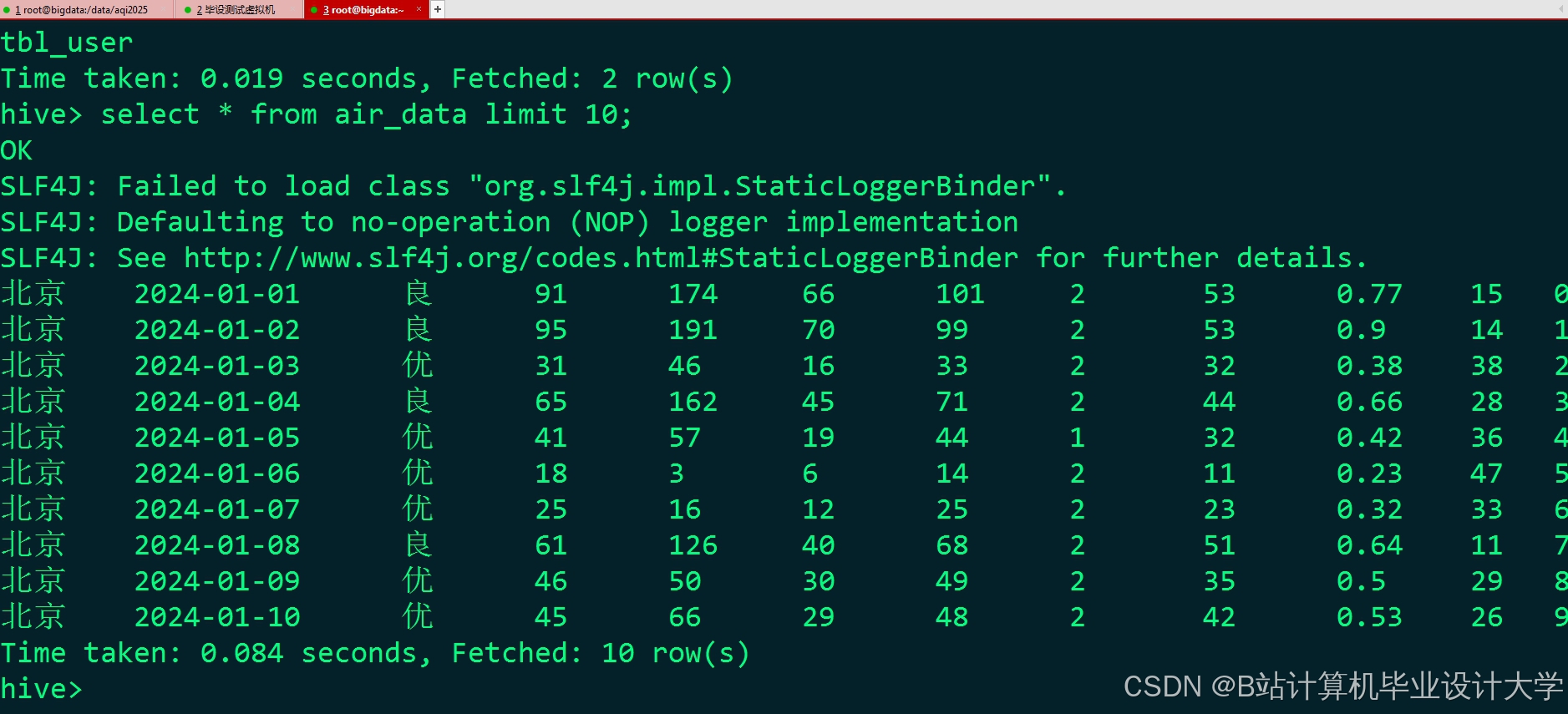
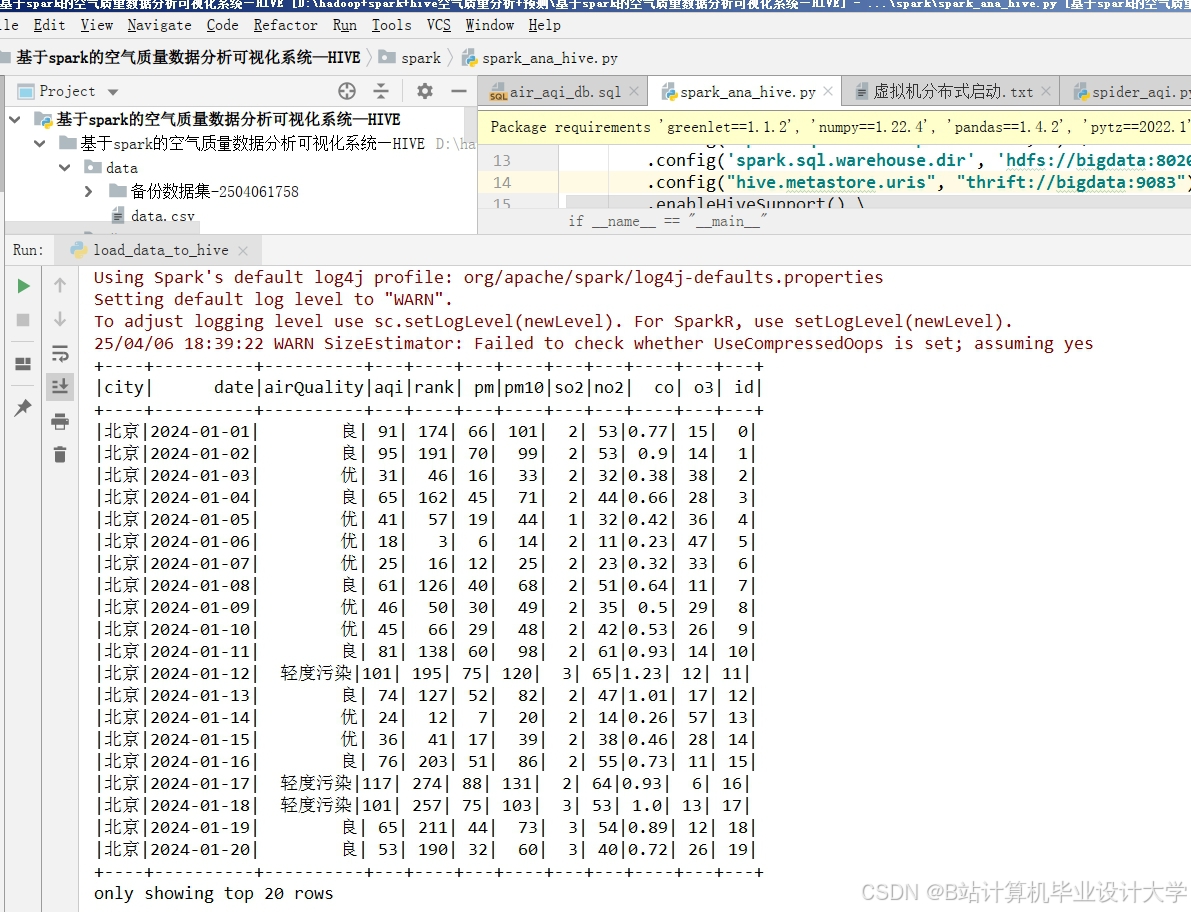
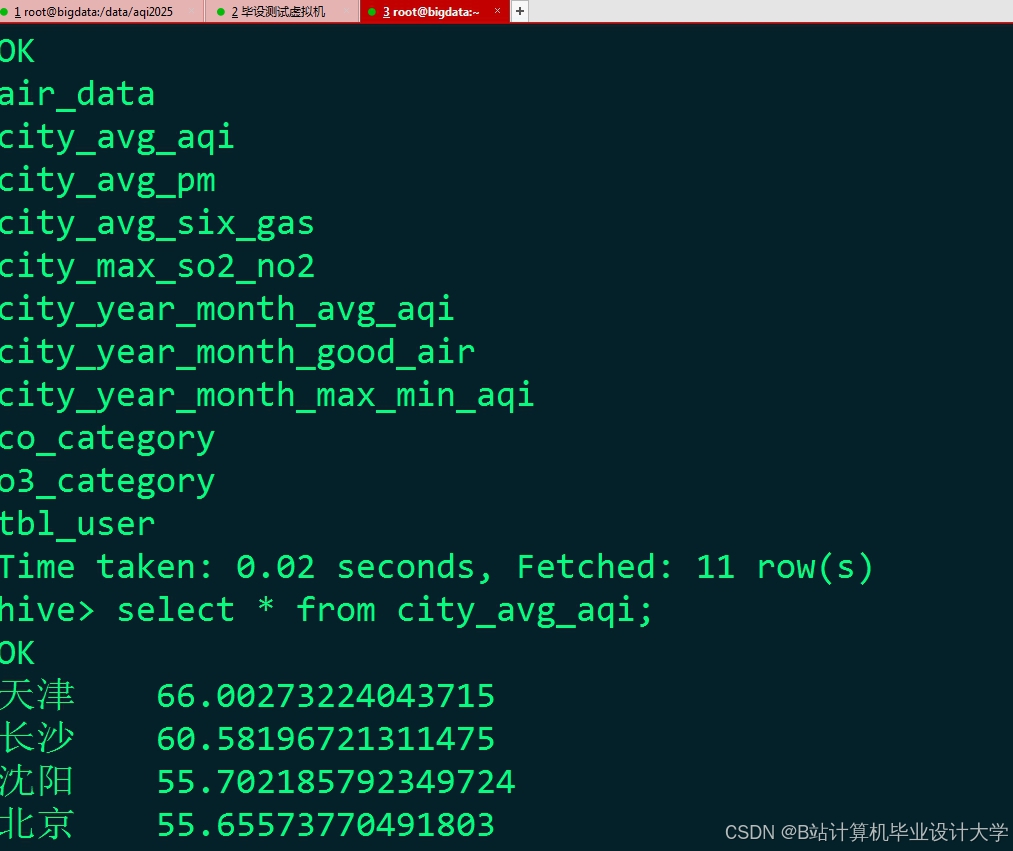

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











