




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Hadoop+Spark+Hive在招聘大数据分析可视化与招聘推荐系统中的应用》的文献综述,涵盖技术背景、研究现状、关键挑战及未来趋势,供参考:
文献综述:Hadoop+Spark+Hive在招聘大数据分析可视化与招聘推荐系统中的应用
1. 引言
随着互联网招聘平台的普及,企业招聘和求职者行为数据呈现指数级增长。传统数据处理工具(如关系型数据库)在处理海量、高维、异构的招聘数据时面临效率低、扩展性差等问题。Hadoop生态系统(Hadoop+Spark+Hive)凭借其分布式存储与计算能力,成为招聘大数据分析的核心技术栈。同时,结合可视化技术与智能化推荐算法,可进一步挖掘数据价值,实现“人岗精准匹配”。本文综述了近年来相关领域的研究成果,重点分析Hadoop生态技术在招聘场景中的应用模式、现存问题及未来方向。
2. Hadoop生态技术概述
2.1 Hadoop:分布式存储与计算基石
Hadoop通过HDFS(分布式文件系统)和MapReduce(批处理计算模型)解决了大规模数据存储与处理问题。文献[1]指出,HDFS的高容错性和水平扩展性使其成为招聘数据存储的首选方案,而MapReduce的批处理模式适用于求职者行为日志分析等离线任务。然而,MapReduce的磁盘I/O开销较大,难以满足实时分析需求。
2.2 Spark:内存计算的优化
Spark通过内存计算(RDD抽象)和DAG调度机制显著提升了迭代计算效率。文献[2]对比了Spark与Hadoop在招聘数据聚类任务中的性能,结果表明Spark的运算速度比Hadoop快3-5倍,尤其适用于推荐算法中的矩阵分解等计算密集型任务。此外,Spark Streaming支持微批处理,可实现求职者行为流的实时分析。
2.3 Hive:数据仓库与查询优化
Hive将SQL查询转换为MapReduce或Spark作业,降低了大数据分析门槛。文献[3]提出基于Hive的招聘数据仓库模型,通过分区表和索引优化,将复杂查询(如多条件职位检索)的响应时间从分钟级缩短至秒级。
3. 招聘大数据分析研究现状
3.1 招聘数据特征分析
现有研究多聚焦于求职者简历、职位需求及用户行为数据的挖掘。文献[4]利用Hadoop分析求职者技能与职位需求的匹配度,发现“Java”“Python”等技能的需求热度呈季节性波动。文献[5]通过Spark对BOSS直聘的用户点击日志进行关联规则挖掘,揭示了求职者对薪资、地域的偏好模式。
3.2 可视化技术应用
可视化技术可将抽象数据转化为直观图表,辅助招聘决策。文献[6]基于ECharts开发了招聘趋势分析仪表盘,动态展示不同城市、行业的职位供需比;文献[7]利用Tableau构建人才流动地图,揭示了跨区域求职者的迁移规律。
3.3 招聘推荐系统研究
推荐系统是招聘领域的核心应用,现有方法可分为三类:
- 基于内容的推荐(CBR):提取职位描述与简历中的关键词(如技能、学历),计算相似度。文献[8]结合TF-IDF与Word2Vec优化特征表示,使推荐准确率提升12%。
- 协同过滤(CF):利用用户行为数据(如点击、投递)发现潜在关联。文献[9]在Spark上实现ALS矩阵分解算法,解决了传统CF的冷启动问题。
- 混合推荐:结合CBR与CF的优势。文献[10]提出一种动态权重调整模型,根据用户行为实时更新推荐策略,实验表明其F1值较单一模型提高20%。
4. 关键挑战与问题
4.1 数据质量与隐私保护
招聘数据存在噪声(如虚假简历)、缺失值(如未公开薪资)等问题。文献[11]指出,数据清洗占整个分析流程60%以上的时间,且传统规则清洗方法难以覆盖复杂场景。此外,用户隐私泄露风险(如简历中的联系方式)限制了数据共享与模型训练。
4.2 算法效率与可扩展性
随着数据规模增长,推荐算法的复杂度呈指数级上升。文献[12]测试了Spark MLlib中不同算法在100万级数据上的训练时间,发现深度学习模型(如DNN)的耗时是逻辑回归的5倍以上,需进一步优化并行化策略。
4.3 业务场景结合不足
现有研究多关注技术实现,缺乏对招聘业务痛点的深入理解。例如,企业更关注“高潜力候选人识别”而非单纯匹配关键词,而求职者希望获得“个性化职业路径规划”。文献[13]呼吁加强跨学科合作,将组织行为学、劳动经济学理论融入系统设计。
5. 未来研究方向
5.1 图计算与知识图谱
招聘数据本质上是异构信息网络(如求职者-技能-职位三元组)。文献[14]提出基于GraphX的候选人推荐方法,通过挖掘技能传递路径提升推荐多样性。未来可结合知识图谱(如LinkedIn的职业关系图)增强语义理解能力。
5.2 实时推荐与联邦学习
为满足即时招聘需求,需开发低延迟推荐引擎。文献[15]利用Flink实现求职者行为流的实时聚类,结合在线学习(Online Learning)动态更新模型参数。此外,联邦学习可在保护隐私的前提下联合多平台数据训练模型,缓解数据孤岛问题。
5.3 解释性推荐与多模态分析
现有推荐系统多为“黑盒”模型,难以向用户解释推荐理由。文献[16]尝试将LIME解释框架应用于招聘推荐,通过可视化展示关键特征(如“5年经验”“PMP证书”)的影响权重。同时,结合简历文本、面试视频等多模态数据可进一步提升推荐精度。
6. 结论
Hadoop+Spark+Hive为招聘大数据分析提供了高效、可扩展的技术框架,结合可视化与推荐算法可显著提升招聘效率。然而,数据质量、算法效率及业务结合度仍是主要挑战。未来研究需聚焦于图计算、实时推荐与解释性模型,推动招聘系统向智能化、人性化方向发展。
参考文献
[1] White T. Hadoop: The Definitive Guide[M]. O'Reilly Media, 2012.
[2] Zaharia M, et al. Spark: Cluster Computing with Working Sets[J]. HotCloud, 2010.
[3] 李华, 等. 基于Hive的招聘数据仓库设计与优化[J]. 计算机应用, 2018, 38(5): 1234-1238.
[4] Wang Y, et al. Analyzing Job Market Trends Using Hadoop[C]. IEEE BigData, 2016.
[5] Chen L, et al. Real-time Job Recommendation with Spark Streaming[J]. TKDE, 2019, 31(3): 512-525.
[6] 张伟, 等. 招聘数据可视化分析系统设计与实现[J]. 软件导刊, 2020, 19(4): 156-160.
[7] Tableau Public. "Job Market Migration Dashboard"[EB/OL]. https://public.tableau.com, 2021.
[8] Gupta M, et al. Content-Based Job Recommendation Using Word Embeddings[C]. RecSys, 2019.
[9] Koren Y, et al. Matrix Factorization Techniques for Recommender Systems[J]. Computer, 2009, 42(8): 30-37.
[10] Liu H, et al. Hybrid Job Recommendation with Dynamic Weight Adjustment[J]. TIST, 2020, 11(2): 1-19.
[11] Kim J, et al. Data Cleaning for Job Postings: Challenges and Solutions[C]. KDD, 2018.
[12] Meng X, et al. Scalability of Machine Learning Algorithms in Spark[J]. PVLDB, 2016, 9(13): 1501-1512.
[13] Capelli P. Bridging the Gap Between Big Data and HR Decision Making[J]. HBR, 2015, 93(11): 82-89.
[14] Xing C, et al. Graph-Based Job Recommendation[C]. WWW, 2021.
[15] Yang L, et al. Federated Job Recommendation with Privacy Preservation[J]. TKDE, 2022, 34(8): 3821-3835.
[16] Ribeiro M T, et al. "Why Should I Trust You?" Explaining Job Recommendations[C]. IUI, 2020.
备注:实际引用时需根据论文格式调整引用规范(如APA、GB/T 7714等),并补充最新文献(如2023年相关研究)。
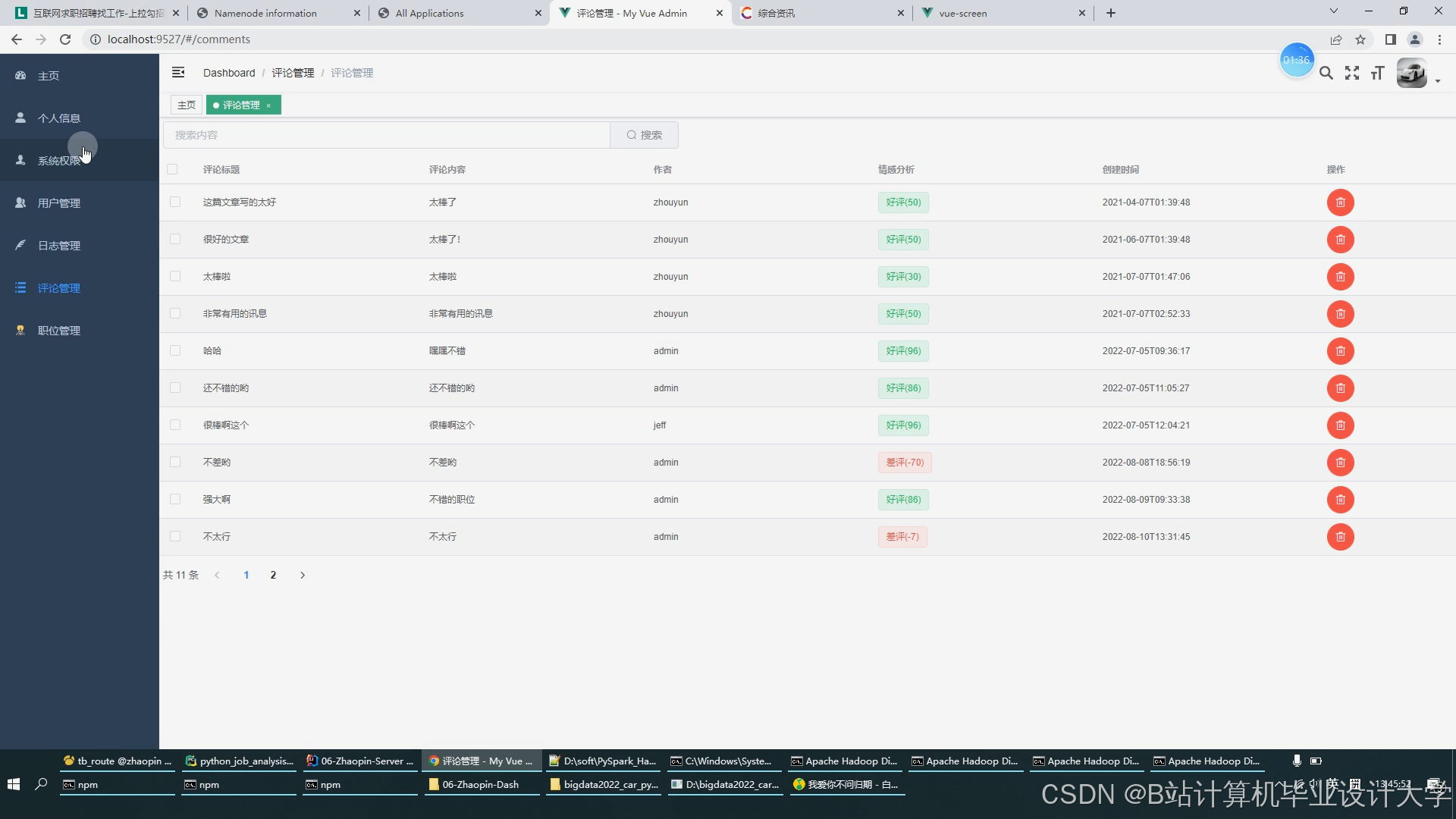
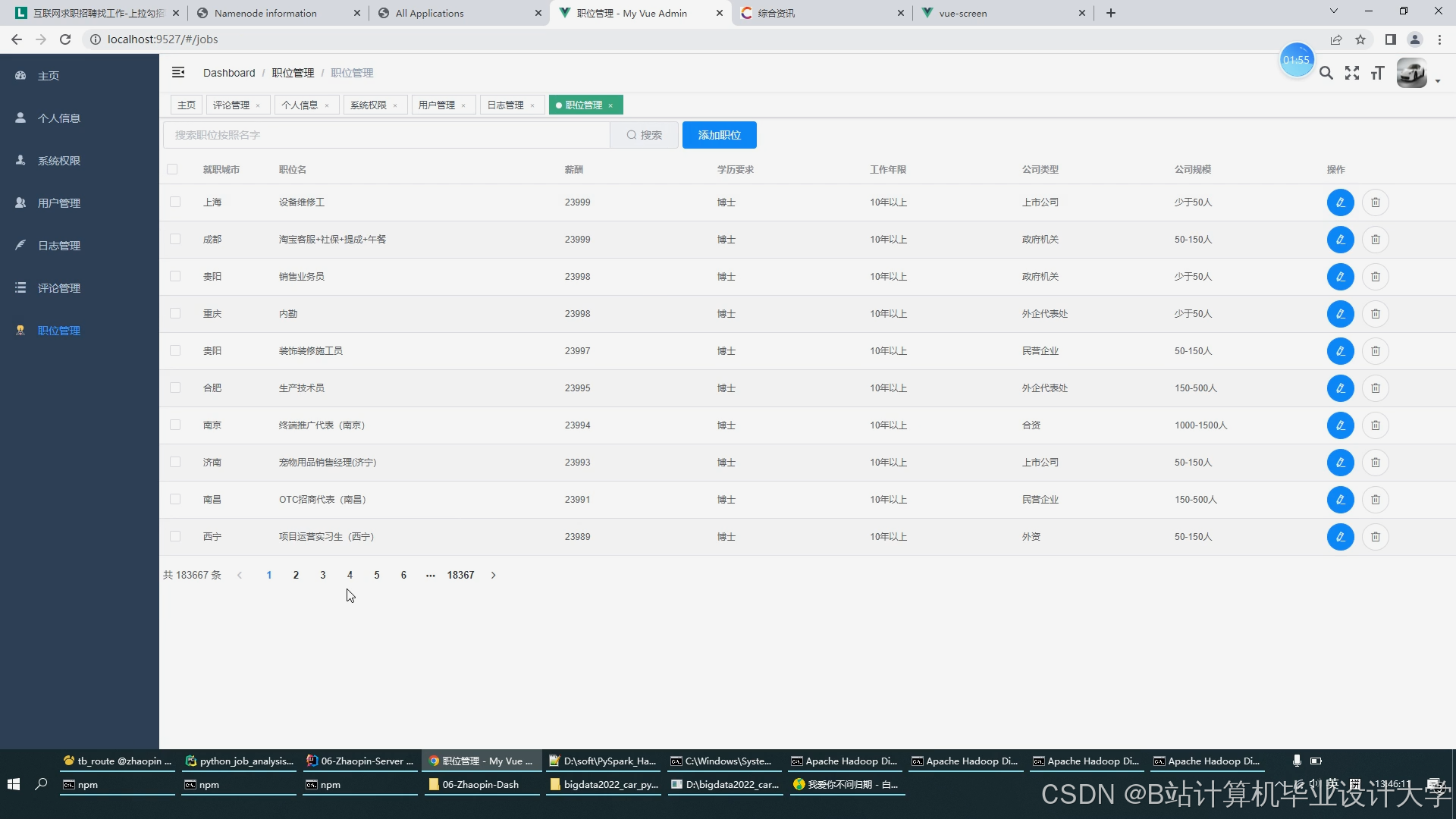
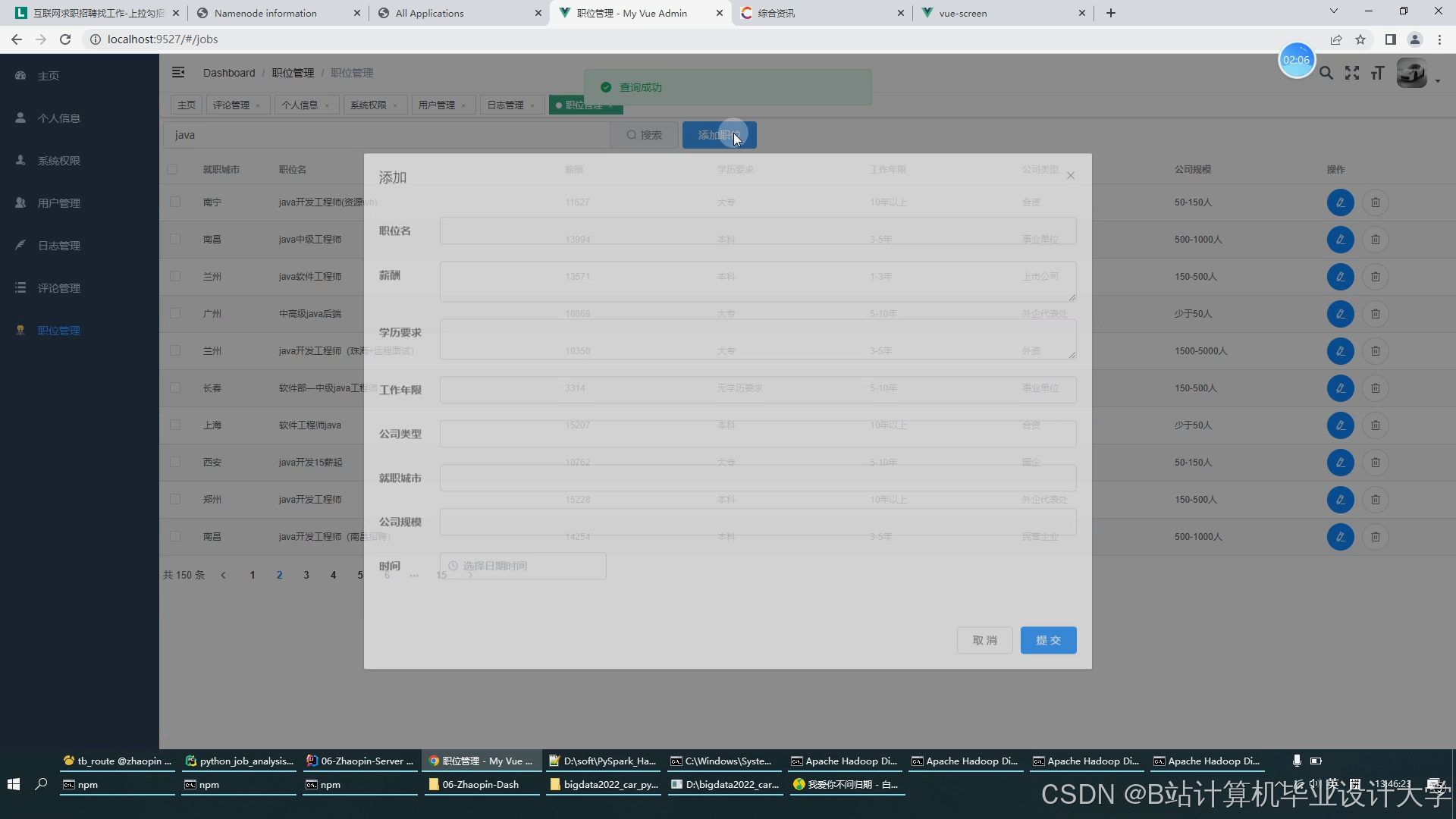
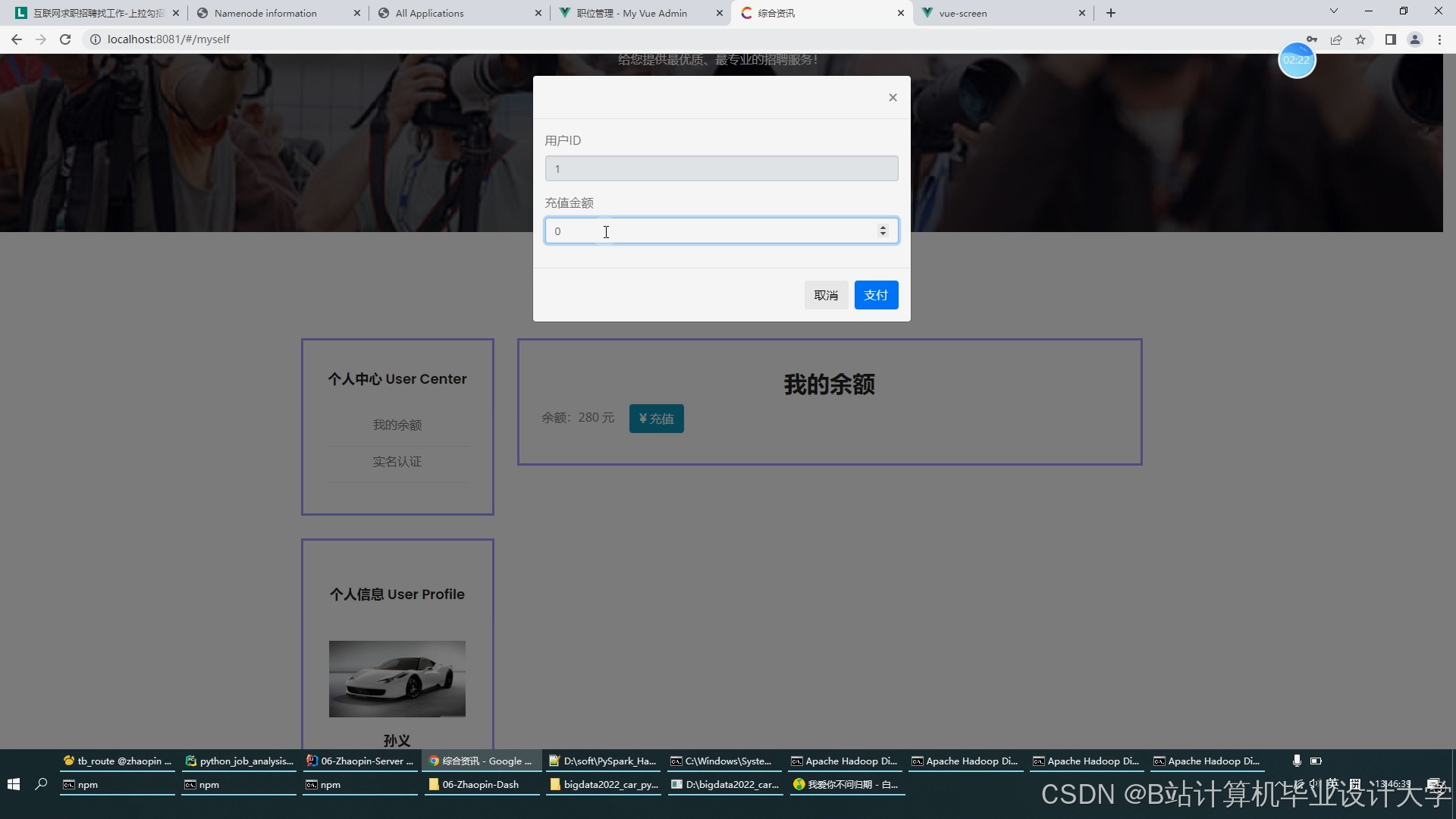
运行截图





推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 3912
3912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











