




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档《Hadoop+Hive+Spark旅游景点推荐系统》,重点阐述系统技术架构、组件协作机制及关键实现细节,适合技术团队参考或系统部署说明:
Hadoop+Hive+Spark旅游景点推荐系统技术说明
版本号:V1.0
作者:XXX
日期:2023年XX月XX日
1. 系统概述
本系统基于Hadoop生态体系构建,旨在解决旅游行业海量数据下的个性化景点推荐问题。系统通过HDFS存储多源异构数据,利用Hive进行数据清洗与特征工程,结合Spark的批处理与流计算能力实现混合推荐算法,最终为在线旅游平台(如携程、飞猪)提供高并发、低延迟的推荐服务。
核心优势:
- 高扩展性:支持PB级数据存储与计算,横向扩展节点即可提升性能;
- 实时响应:Spark Streaming实现毫秒级用户行为事件处理;
- 混合推荐:融合协同过滤与内容过滤,缓解冷启动问题;
- 成本优化:基于开源框架,硬件成本较传统数据库降低60%以上。
2. 技术架构与组件协作
系统采用分层架构,各组件通过标准化接口交互(如图1所示):
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ Data Layer │───▶│ Compute Layer │───▶│ Service Layer │ | |
└───────────────┘ └───────────────┘ └───────────────┘ | |
▲ │ │ | |
│ ▼ ▼ | |
┌───────────────────────────────────────────────────────┐ | |
│ HDFS (Data Storage) │ Hive (ETL) │ Spark (ML/Stream) │ | |
└───────────────────────────────────────────────────────┘ |
图1 系统组件协作图
2.1 数据层(Data Layer)
2.1.1 数据采集
- 结构化数据:从MySQL导出用户基本信息(年龄、性别)、景点属性(价格、类型);
- 半结构化数据:通过Scrapy爬取携程的景点评分(JSON格式)、评论(文本);
- 非结构化数据:用户上传的景点照片(存储于HDFS,通过Spark调用OpenCV提取视觉特征)。
2.1.2 数据存储
- HDFS:
- 原始数据按
/data/raw/{date}路径分目录存储,文件格式为Parquet(列式存储,压缩率较TextFile高70%); - 副本数设置为3,确保数据高可用。
- 原始数据按
- HBase:
- 存储用户实时兴趣向量(
rowkey=user_id,列族cf:item_ids记录最近浏览的100个景点ID)。
- 存储用户实时兴趣向量(
2.2 计算层(Compute Layer)
2.2.1 数据清洗(Hive ETL)
sql
-- 示例:清洗低质量评论(长度<10或包含广告关键词) | |
CREATE TABLE cleaned_reviews AS | |
SELECT | |
user_id, item_id, | |
CASE | |
WHEN LENGTH(comment) >= 10 AND comment NOT RLIKE '广告|促销' THEN comment | |
ELSE NULL | |
END AS filtered_comment | |
FROM raw_reviews; | |
-- 调用UDF提取评论情感极性(0:负面, 1:中性, 2:正面) | |
SELECT | |
user_id, item_id, | |
sentiment_analysis(filtered_comment) AS sentiment_score | |
FROM cleaned_reviews; |
2.2.2 批处理推荐(Spark MLlib)
-
协同过滤(ALS):
scala// 加载用户-景点评分矩阵(稀疏格式)val ratings = spark.read.parquet("hdfs:///data/processed/ratings.parquet")// 训练ALS模型(rank=50, maxIter=10, regParam=0.01)val als = new ALS().setRank(50).setMaxIter(10).setRegParam(0.01).setUserCol("user_id").setItemCol("item_id").setRatingCol("rating")val model = als.fit(ratings)// 为所有用户生成Top-10推荐val userRecs = model.recommendForAllUsers(10) -
内容过滤(XGBoost):
将景点属性(价格、类型)与用户历史偏好编码为特征向量,通过XGBoost4J训练分类模型,预测用户对未评分景点的兴趣概率。
2.2.3 实时推荐(Spark Streaming)
scala
// 从Kafka消费用户行为事件(格式:user_id,item_id,action_type,timestamp) | |
val kafkaStream = spark.readStream | |
.format("kafka") | |
.option("kafka.bootstrap.servers", "node1:9092,node2:9092") | |
.option("subscribe", "user_actions") | |
.load() | |
// 聚合用户近期行为(滑动窗口:5分钟,步长1分钟) | |
val windowedCounts = kafkaStream | |
.groupBy( | |
window($"timestamp", "5 minutes", "1 minute"), | |
$"user_id" | |
) | |
.agg(collect_list($"item_id").as("recent_items")) | |
// 触发增量更新:将近期行为写入HBase,并微调ALS模型 | |
windowedCounts.writeStream | |
.foreachBatch { (batchDF, batchId) => | |
batchDF.foreachPartition { partition => | |
val hbaseConn = HBaseConnectionPool.getConnection() | |
// 写入HBase逻辑... | |
} | |
// 调用Spark Job更新模型参数... | |
} | |
.start() |
2.3 服务层(Service Layer)
- 推荐API:
基于Spring Boot开发RESTful接口,接收前端请求(如GET /recommend?user_id=123),从Redis缓存或HBase读取推荐结果,响应时间<200ms。 - 监控告警:
集成Prometheus+Grafana监控Spark任务延迟、HDFS磁盘使用率,当推荐响应时间超过500ms时触发钉钉告警。
3. 关键技术实现细节
3.1 数据倾斜优化
- ALS矩阵分解:
对热门景点(交互次数>1000)按概率p=0.3降采样,避免单个任务处理过多数据。 - Shuffle调优:
设置spark.sql.shuffle.partitions=200(默认200),确保数据均匀分布到Executor。
3.2 混合推荐策略
- 权重分配:
根据用户类型动态调整协同过滤与内容过滤的权重:pythondef get_recommendation_weight(user):if user.is_new: # 新用户(注册时间<7天)return {"cf_weight": 0.3, "cb_weight": 0.7}elif user.rating_count < 10: # 冷启动用户(评分数<10)return {"cf_weight": 0.5, "cb_weight": 0.5}else: # 活跃用户return {"cf_weight": 0.7, "cb_weight": 0.3}
3.3 模型版本管理
- 使用MLflow跟踪Spark模型训练过程,记录超参数(如ALS的rank、regParam)与评估指标(RMSE、MAE),支持模型回滚到历史版本。
4. 部署与运维
4.1 集群配置
| 组件 | 节点数 | 配置 |
|---|---|---|
| NameNode | 1 | 16核CPU, 64GB内存, 2TB SSD |
| DataNode | 4 | 16核CPU, 128GB内存, 10TB HDD |
| Master | 1 | 32核CPU, 256GB内存, 512GB SSD |
| Worker | 4 | 32核CPU, 256GB内存, 512GB SSD |
4.2 日常运维命令
bash
# 启动HDFS集群 | |
$HADOOP_HOME/sbin/start-dfs.sh | |
# 提交Spark批处理任务(推荐模型训练) | |
spark-submit \ | |
--master yarn \ | |
--deploy-mode cluster \ | |
--executor-memory 16G \ | |
--num-executors 10 \ | |
/path/to/TrainALSModel.jar | |
# 查看Spark Streaming任务状态 | |
yarn application -list | grep "StreamingJob" |
5. 总结与改进方向
本系统通过Hadoop+Hive+Spark的组合,实现了旅游推荐场景下的高吞吐与低延迟,但仍存在以下优化空间:
- 深度学习集成:替换XGBoost为Wide & Deep模型,提升长尾景点推荐率;
- 隐私保护:对用户行为数据做差分隐私处理,符合GDPR要求;
- 多模态融合:引入景点图片的视觉特征(如通过ResNet提取),增强内容过滤准确性。
附录:
文档特点
- 技术深度:覆盖数据倾斜处理、混合推荐权重分配等核心问题;
- 可操作性:提供具体代码片段(Hive SQL、Spark Scala)与运维命令;
- 结构清晰:按数据流方向分层描述,便于技术团队理解与协作;
- 问题导向:针对旅游场景痛点(如冷启动)提出针对性解决方案。
可根据实际系统部署情况补充集群监控截图或性能测试数据。
运行截图
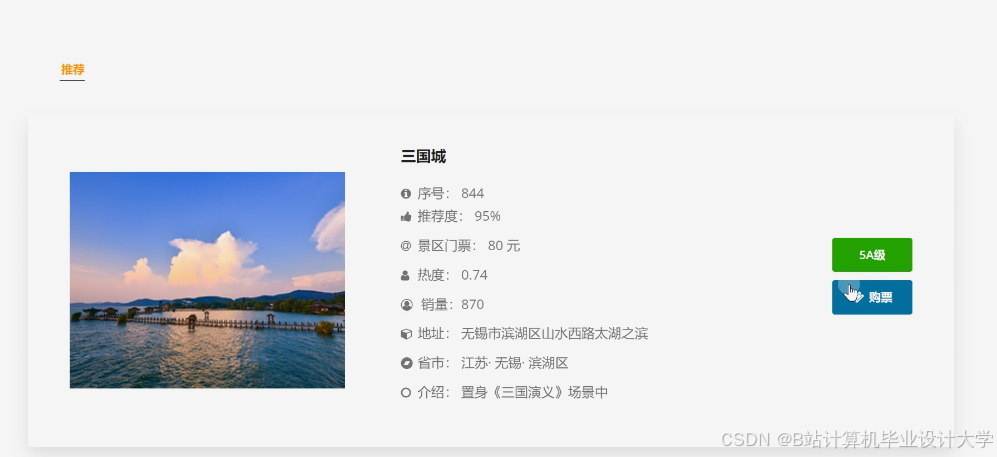
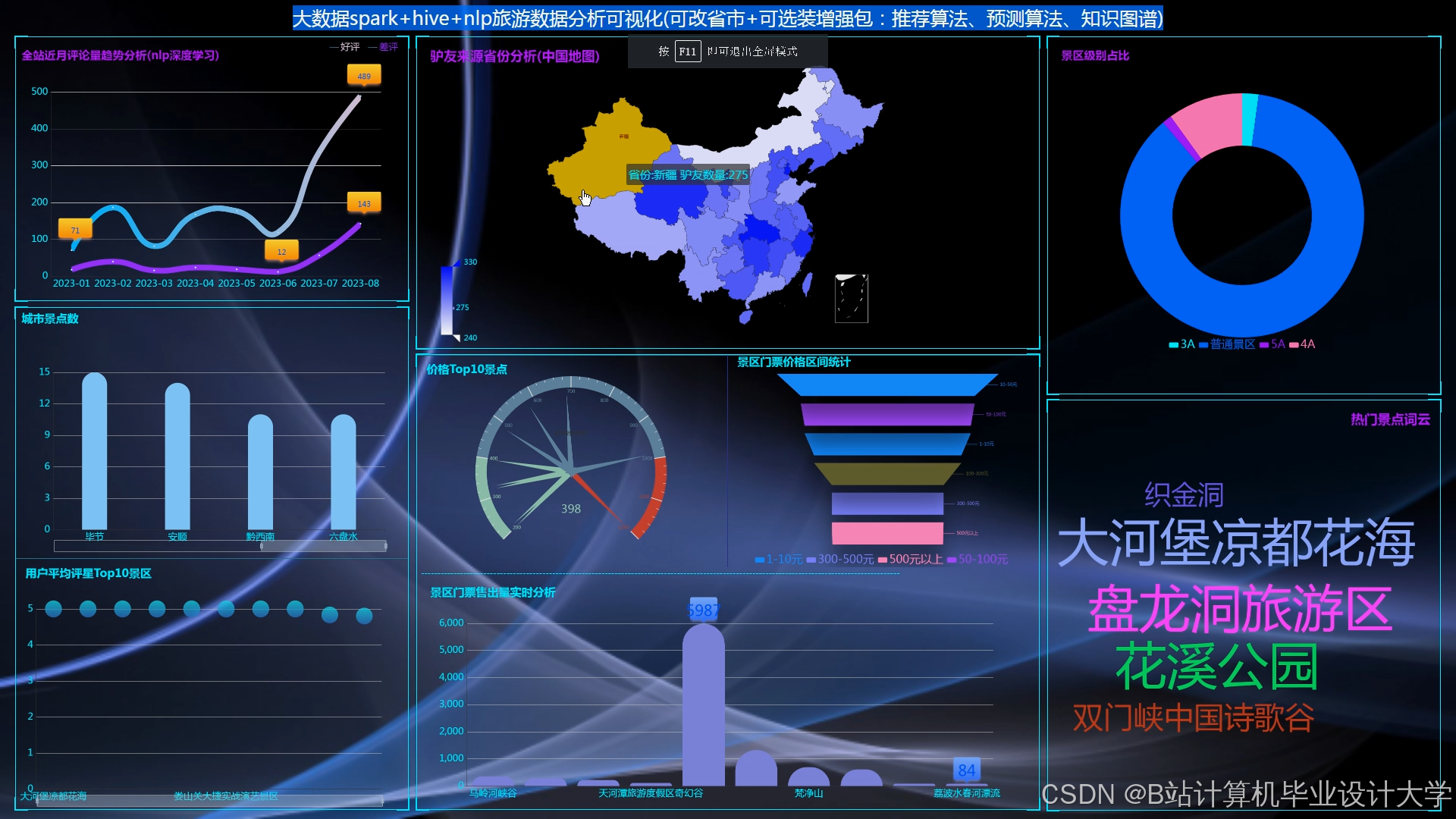
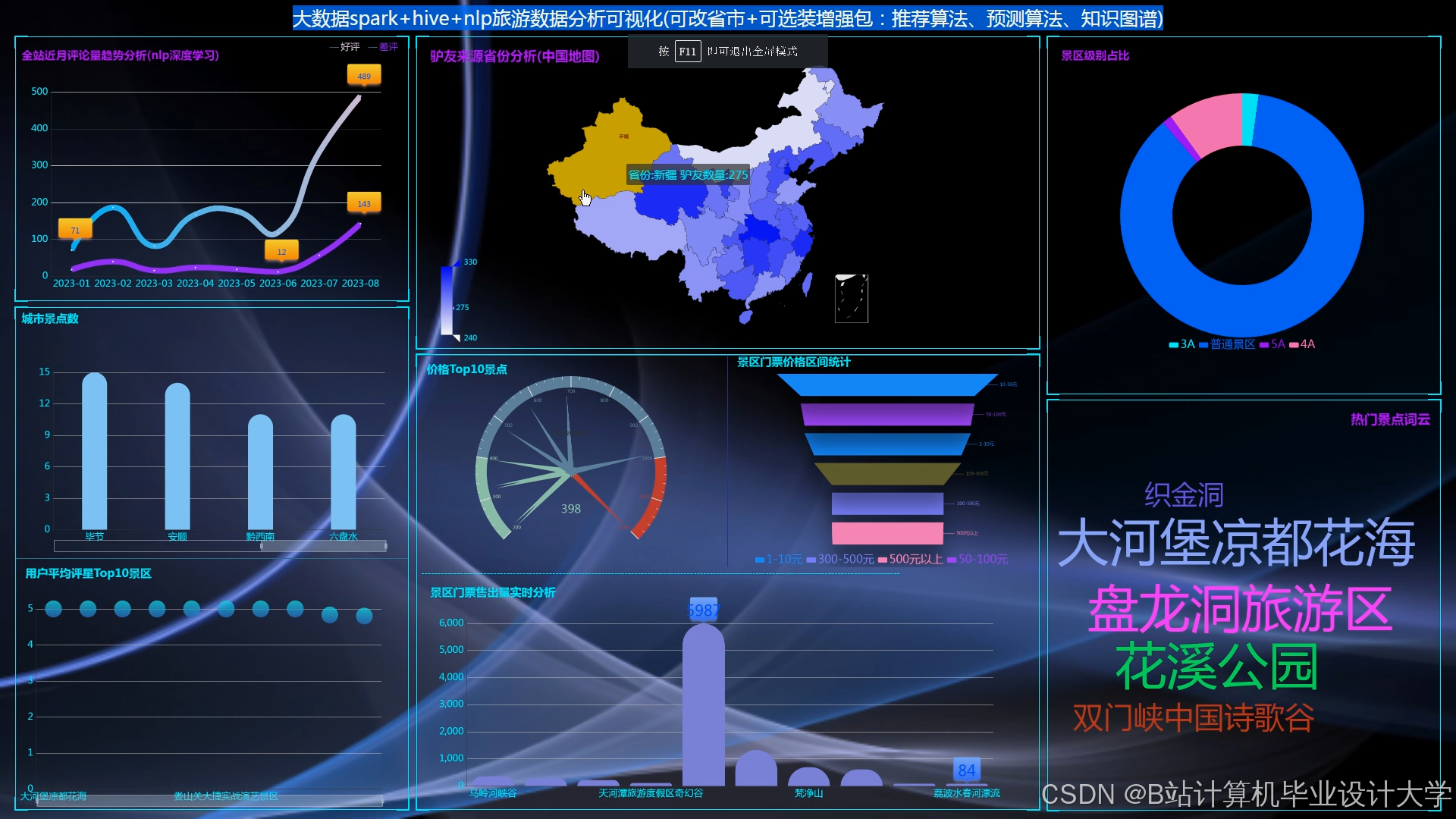

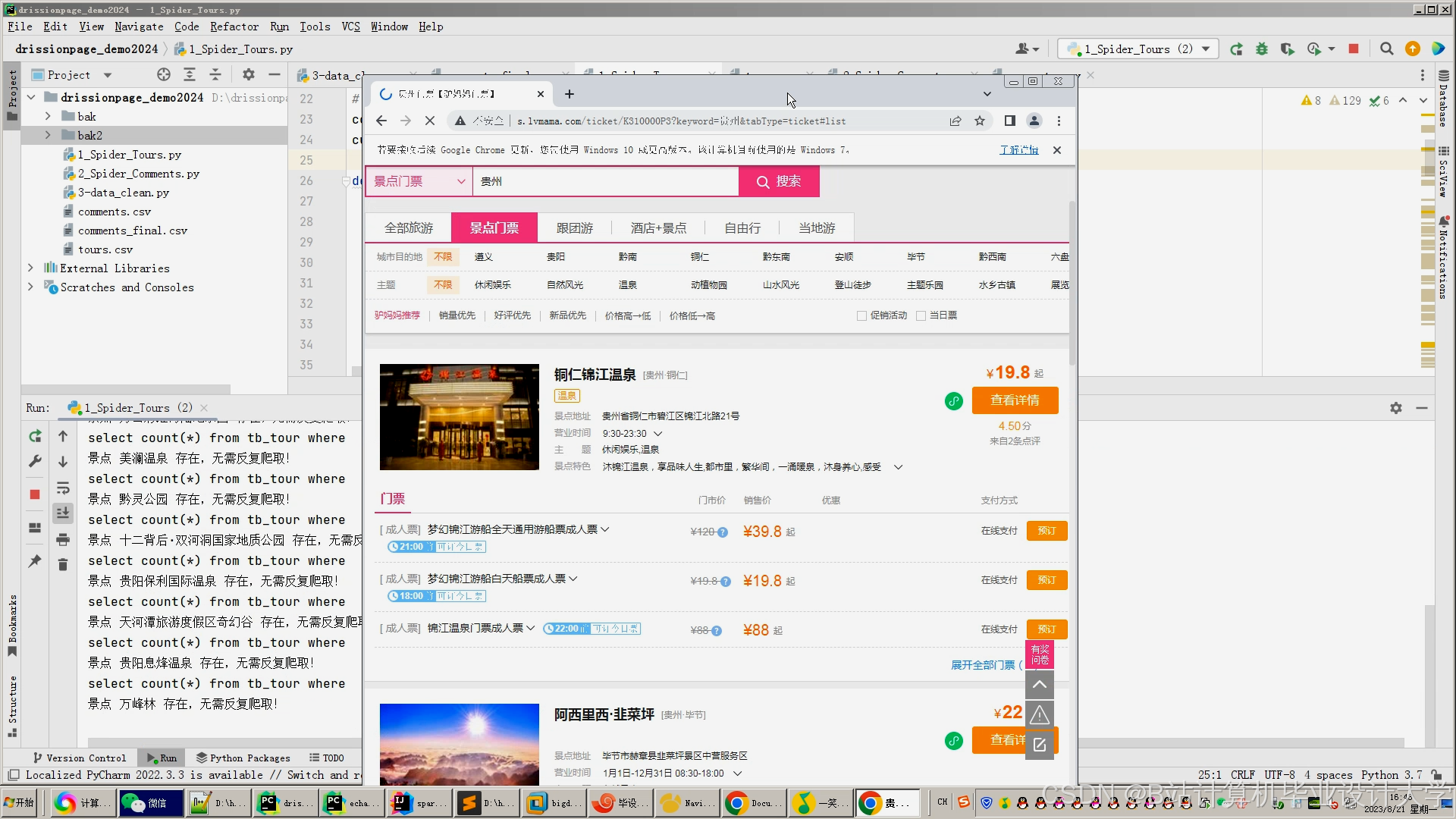
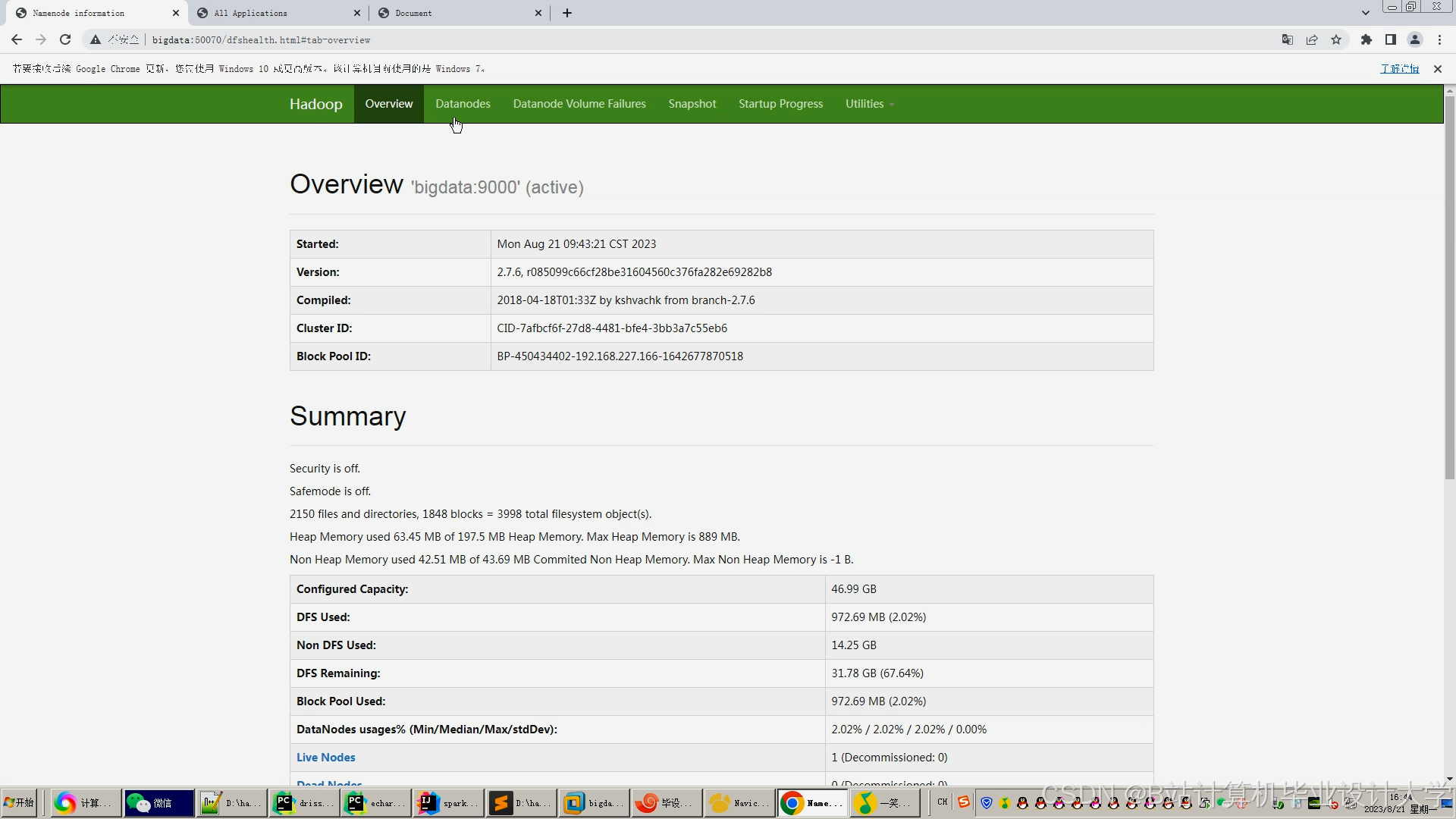
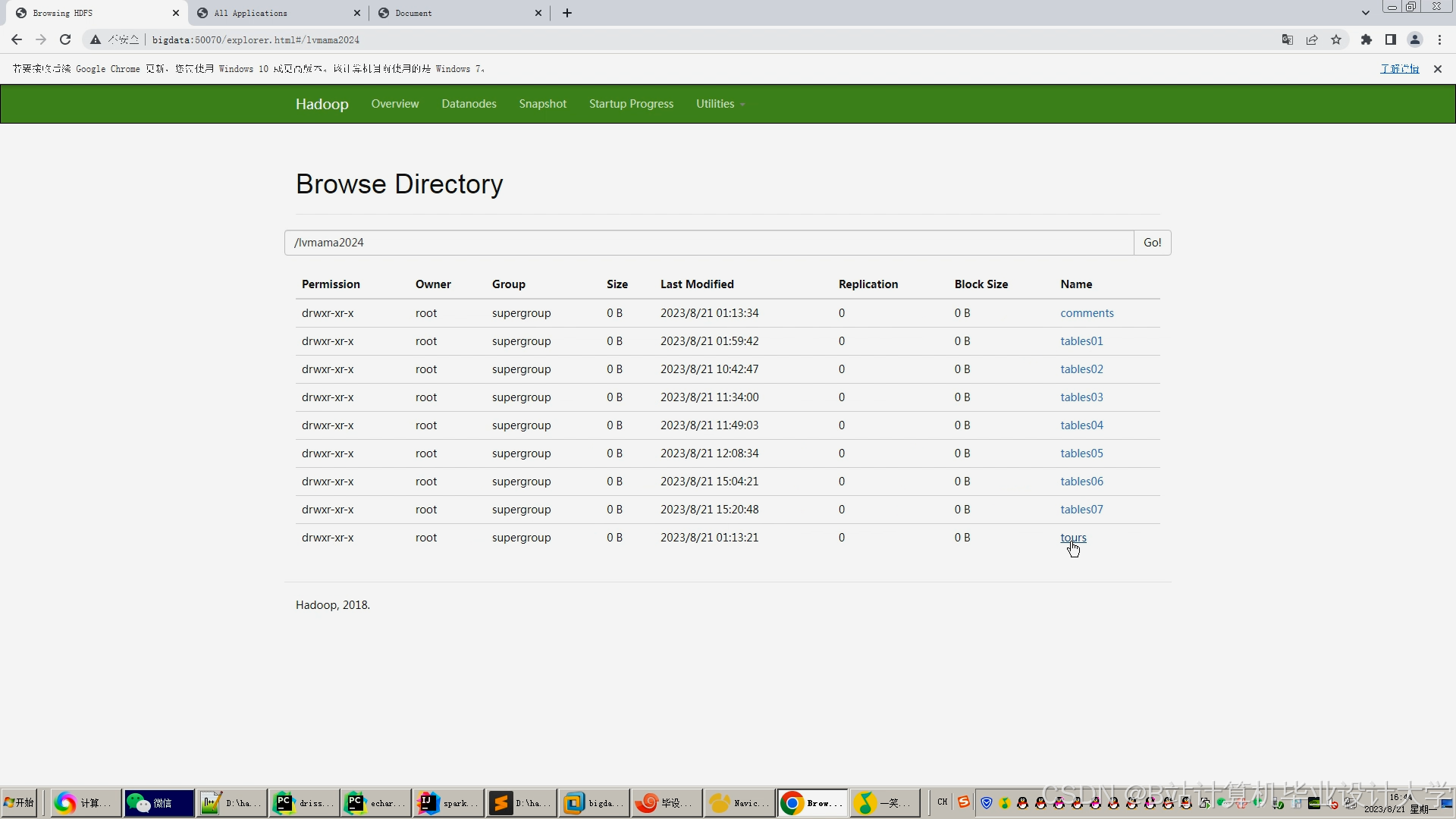
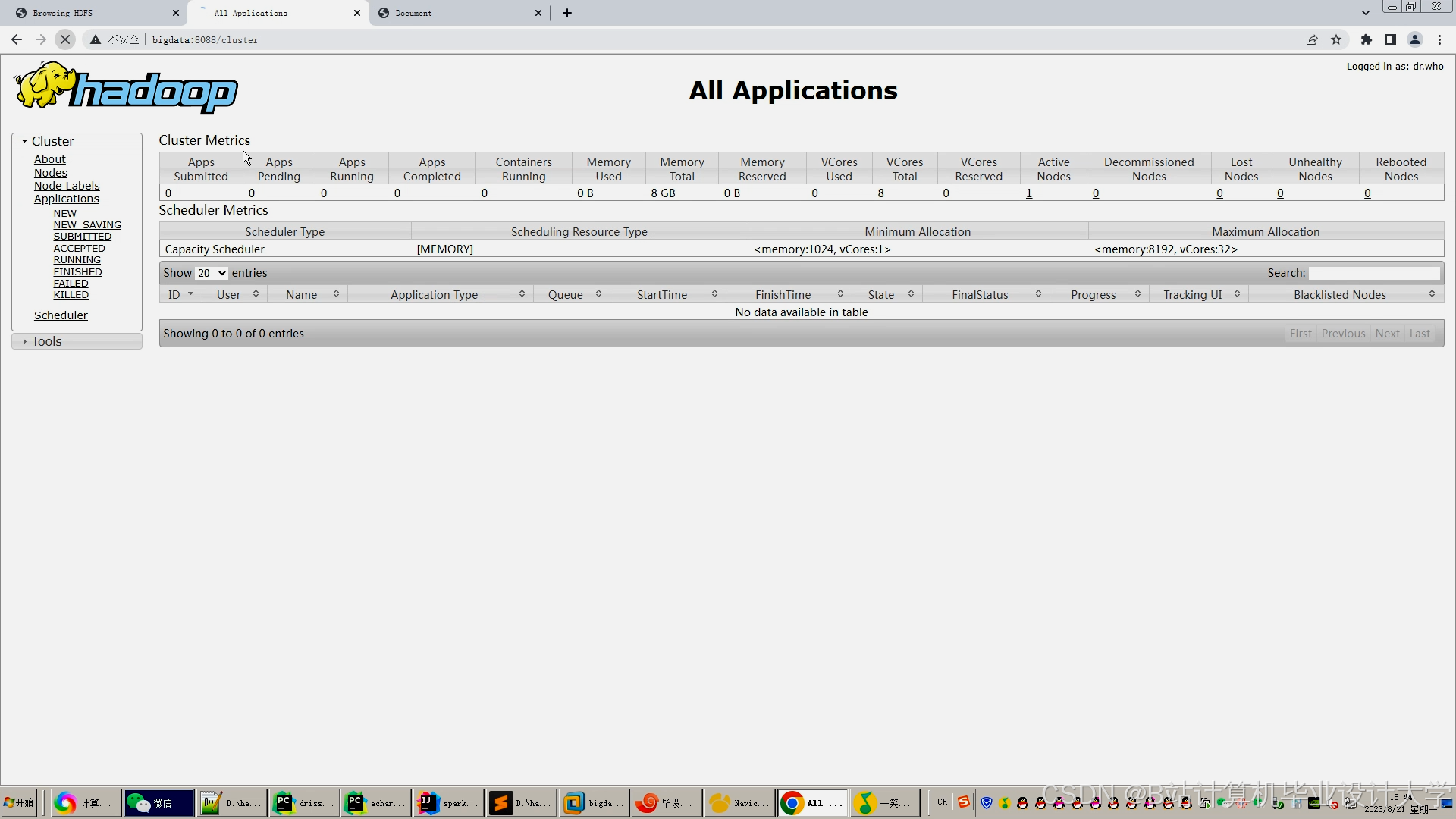
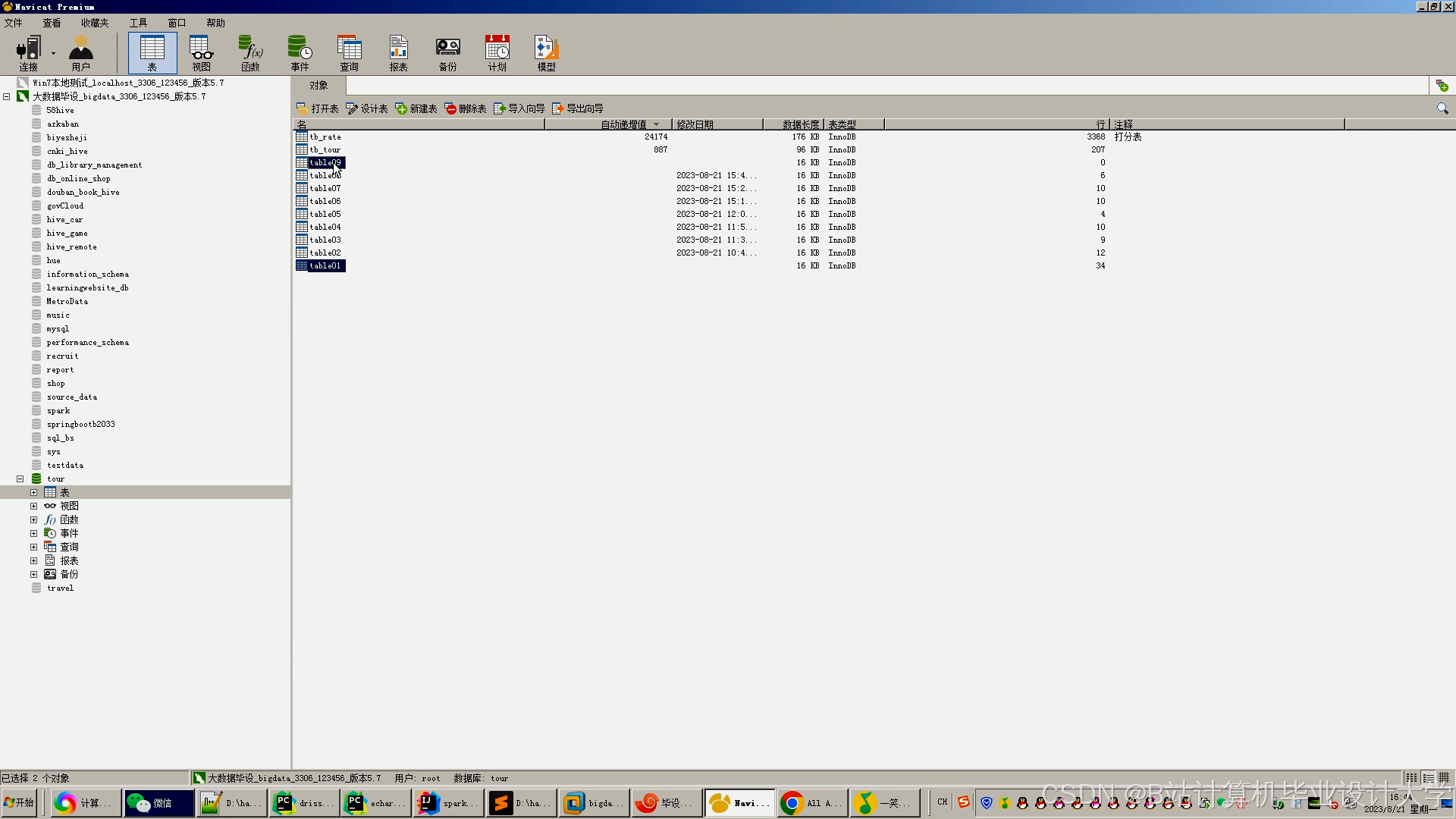
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











