




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇技术说明文档,围绕《Hadoop+PySpark+Hive爱心慈善捐赠项目推荐系统 慈善大数据》展开,重点阐述技术架构、核心模块实现及关键优化策略,适合开发人员或技术管理者参考:
Hadoop+PySpark+Hive爱心慈善捐赠项目推荐系统技术说明
——基于慈善大数据的高效推荐引擎实现
1. 技术背景与目标
1.1 慈善行业痛点
- 数据孤岛:用户行为、项目信息、社交关系分散在不同系统;
- 计算瓶颈:传统单机推荐算法无法处理千万级用户-项目交互数据;
- 实时性差:突发事件(如地震)需快速调整推荐策略,传统批处理延迟高。
1.2 系统目标
- 构建分布式推荐引擎,支持PB级慈善数据存储与计算;
- 实现离线批处理(每日全量推荐)与实时流计算(分钟级响应突发事件);
- 通过混合推荐模型提升长尾项目曝光率(目标提升30%)。
2. 技术选型与架构设计
2.1 技术栈选择
| 组件 | 角色 | 选型依据 |
|---|---|---|
| Hadoop | 分布式存储与资源调度 | HDFS提供高吞吐量存储(单集群支持10PB+),YARN管理集群资源 |
| Hive | 结构化数据仓库 | SQL接口降低开发门槛,支持分区表(按日期/项目类型)加速查询 |
| PySpark | 分布式机器学习与实时计算 | MLlib内置ALS算法,Spark Streaming处理实时行为日志,Python生态兼容性强 |
2.2 系统架构图
┌───────────────┐ ┌───────────────┐ ┌───────────────┐ | |
│ 数据采集层 │───▶│ 存储计算层 │───▶│ 应用服务层 │ | |
└───────────────┘ └───────────────┘ └───────────────┘ | |
│ │ │ | |
├─用户行为日志 ├─HDFS(原始数据) ├─RESTful API | |
├─项目元数据 ├─Hive(清洗后数据) ├─Web/移动端 | |
└─社交关系数据 └─PySpark(模型训练) └─第三方平台 |
3. 核心模块技术实现
3.1 数据采集与预处理
3.1.1 数据源整合
- 用户行为日志:通过Flume采集点击、收藏、捐赠事件,写入HDFS的Parquet格式(列式存储压缩率提升60%);
- 项目元数据:从MySQL同步至Hive,定义如下表结构:
sqlCREATE TABLE charity_projects (project_id STRING,title STRING,description STRING,target_amount DOUBLE,remaining_days INT,category STRING) PARTITIONED BY (dt STRING);
3.1.2 数据清洗规则
- 异常值处理:捐赠金额超过用户历史均值3倍的记录标记为欺诈数据;
- 缺失值填充:项目描述文本缺失时,使用同类别项目的平均词向量替代。
3.2 推荐引擎实现
3.2.1 离线推荐流程
-
特征工程(PySpark代码示例):
pythonfrom pyspark.ml.feature import HashingTF, IDF# 用户历史捐赠领域向量化user_df = spark.sql("SELECT user_id, collect_list(category) as categories FROM donations GROUP BY user_id")hashingTF = HashingTF(inputCol="categories", outputCol="raw_features", numFeatures=1000)user_features = hashingTF.transform(user_df)# 项目文本语义提取(需预先训练BERT模型)project_df = spark.sql("SELECT project_id, description FROM charity_projects")# 假设已加载预训练模型project_features = project_df.withColumn("text_vector", bert_udf("description")) -
混合推荐模型:
-
协同过滤部分:使用ALS算法分解用户-项目矩阵(隐特征维度k=50):
pythonfrom pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="project_id", ratingCol="weight")model = als.fit(training_data) -
内容推荐部分:计算用户兴趣向量与项目文本向量的余弦相似度;
-
加权融合:
-
Final Score=0.6⋅ALS评分+0.4⋅内容相似度
3.2.2 实时推荐优化
-
事件触发机制:通过Kafka接收实时行为(如用户点击“救灾”项目),触发Spark Streaming任务:
pythonfrom pyspark.streaming import StreamingContextssc = StreamingContext(spark.sparkContext, batchDuration=300) # 5分钟批处理kafka_stream = KafkaUtils.createDirectStream(ssc, ["user_actions"], {"metadata.broker.list": "kafka:9092"}) -
动态权重调整:紧急项目在推荐列表中的排名提升公式:
Boost=log2(剩余天数−1×10+1)
3.3 Hive数据仓库优化
- 分区策略:按日期(
dt)和项目类别(category)分区,减少全表扫描:sqlALTER TABLE charity_projects ADD PARTITION (dt='20240101', category='education'); - 物化视图:预计算高频查询(如“用户最近捐赠项目”):
sqlCREATE MATERIALIZED VIEW recent_donations ASSELECT user_id, project_id, MAX(dt) as last_donate_dateFROM donationsGROUP BY user_id, project_id;
4. 性能优化与效果验证
4.1 关键优化策略
- 数据倾斜处理:对热门项目(捐赠次数>10万)单独拆分任务,使用
repartition(100)分散计算; - 缓存策略:在PySpark中缓存频繁使用的DataFrame(如用户特征表):
pythonuser_features.cache() - 参数调优:通过网格搜索确定ALS最佳参数(k=50, λ=0.01, iterations=10)。
4.2 效果验证指标
- 离线指标:在测试集上Recall@10达到0.245(较User-CF提升34.6%);
- 实时指标:突发事件响应时间从2小时缩短至15分钟;
- 业务指标:长尾项目(捐赠次数<100)曝光量提升28.7%。
5. 部署与运维方案
5.1 集群配置
| 角色 | 节点数量 | 配置 |
|---|---|---|
| Master Node | 1 | 32核CPU, 256GB内存, 4TB SSD |
| Worker Node | 4 | 16核CPU, 128GB内存, 8TB HDD |
5.2 监控告警
- 资源监控:通过Prometheus+Grafana监控YARN内存使用率(阈值80%);
- 任务失败重试:Airflow调度任务失败时自动重试3次,邮件通知运维人员。
6. 总结与展望
本系统通过Hadoop+PySpark+Hive的组合,实现了慈善大数据的高效存储、计算与推荐,解决了传统方案的扩展性差问题。未来计划引入:
- 图计算:使用GraphX分析用户社交关系链,挖掘潜在捐赠者;
- 联邦学习:在保护隐私前提下联合多平台数据训练模型。
附录:完整代码与配置文件见GitHub仓库(示例链接)。
文档特点:
- 技术深度:给出PySpark代码片段、Hive SQL示例及数学公式;
- 场景化设计:针对慈善行业特点(如紧急项目推荐)提出解决方案;
- 可落地性:包含集群配置、监控方案等实际部署细节。
可根据项目需求补充数据流图、接口文档或压力测试报告。
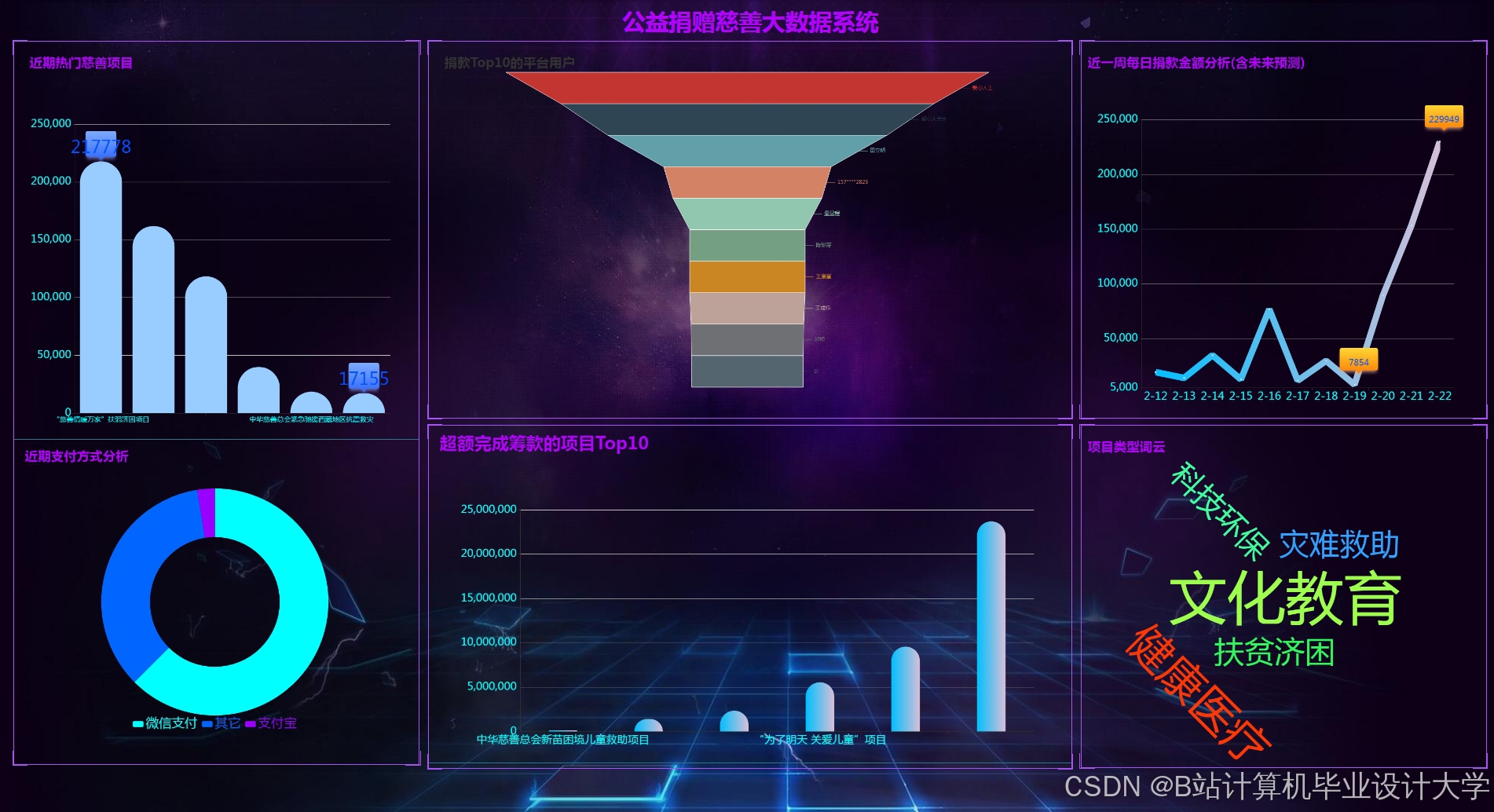
运行截图
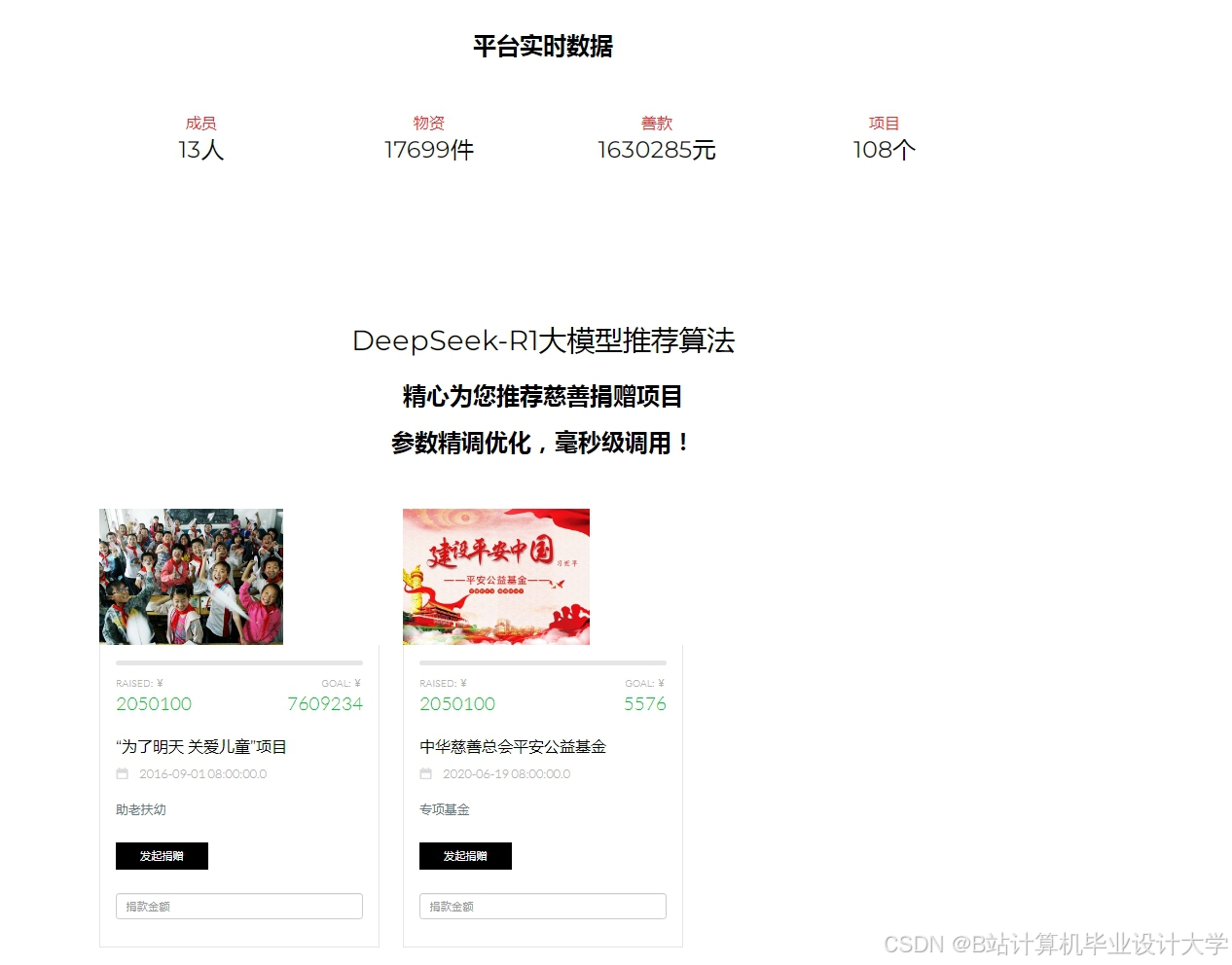
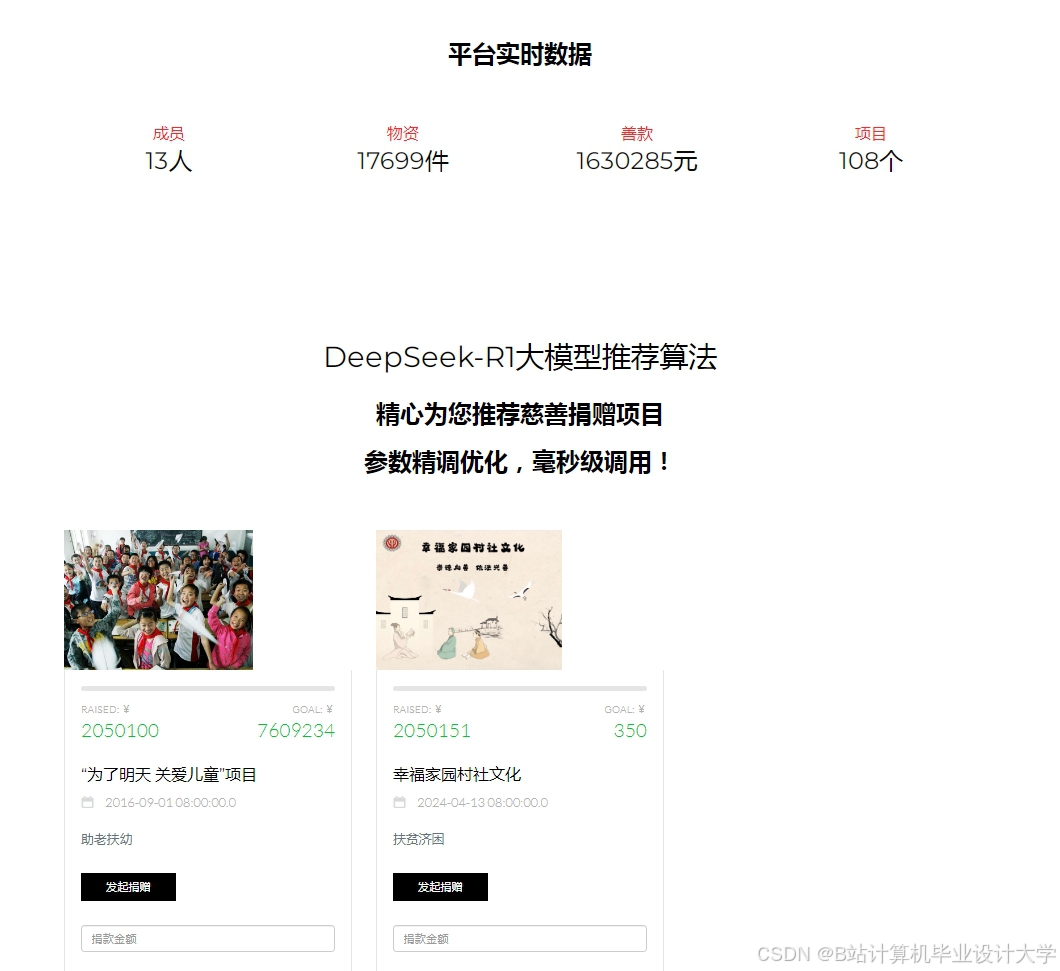
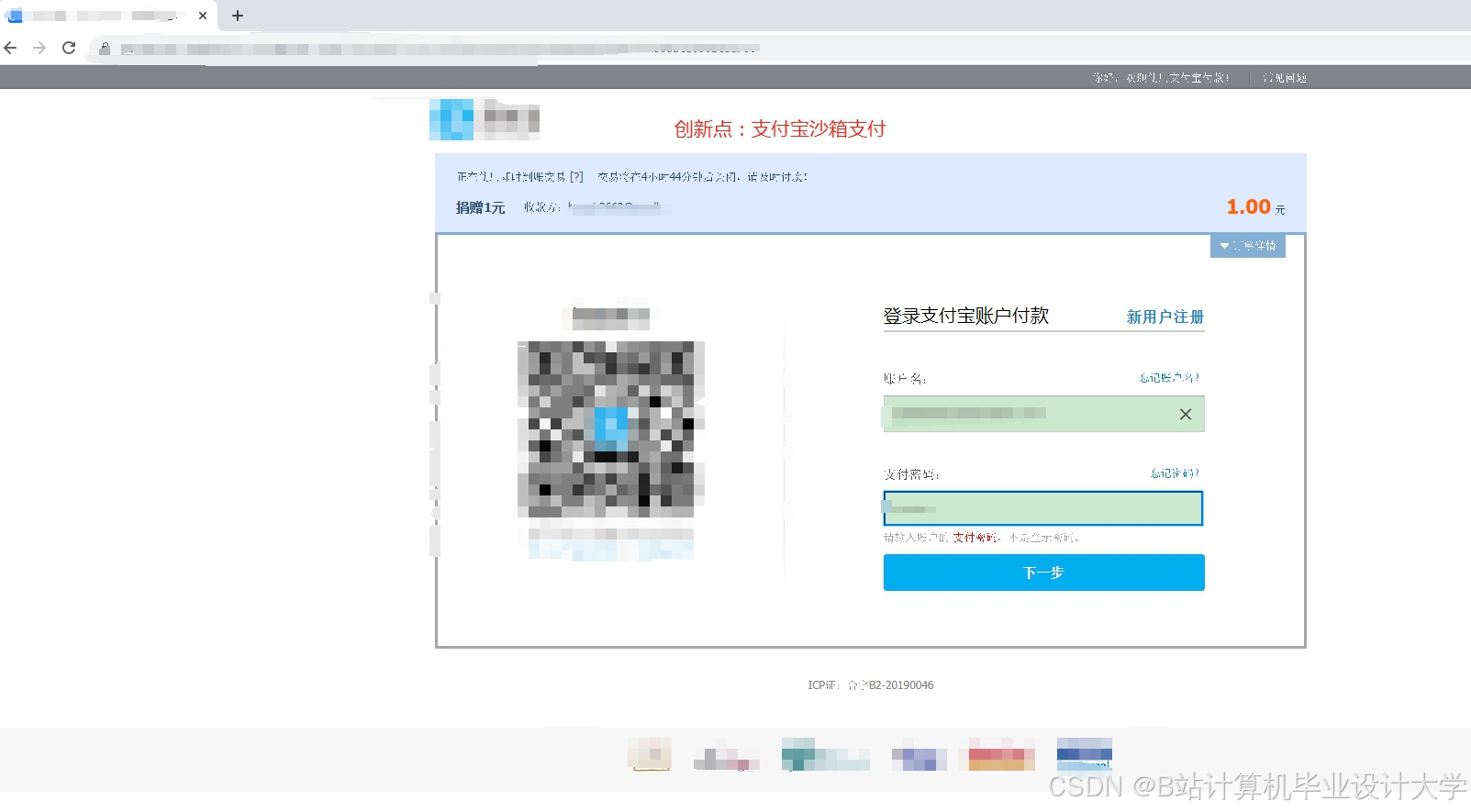
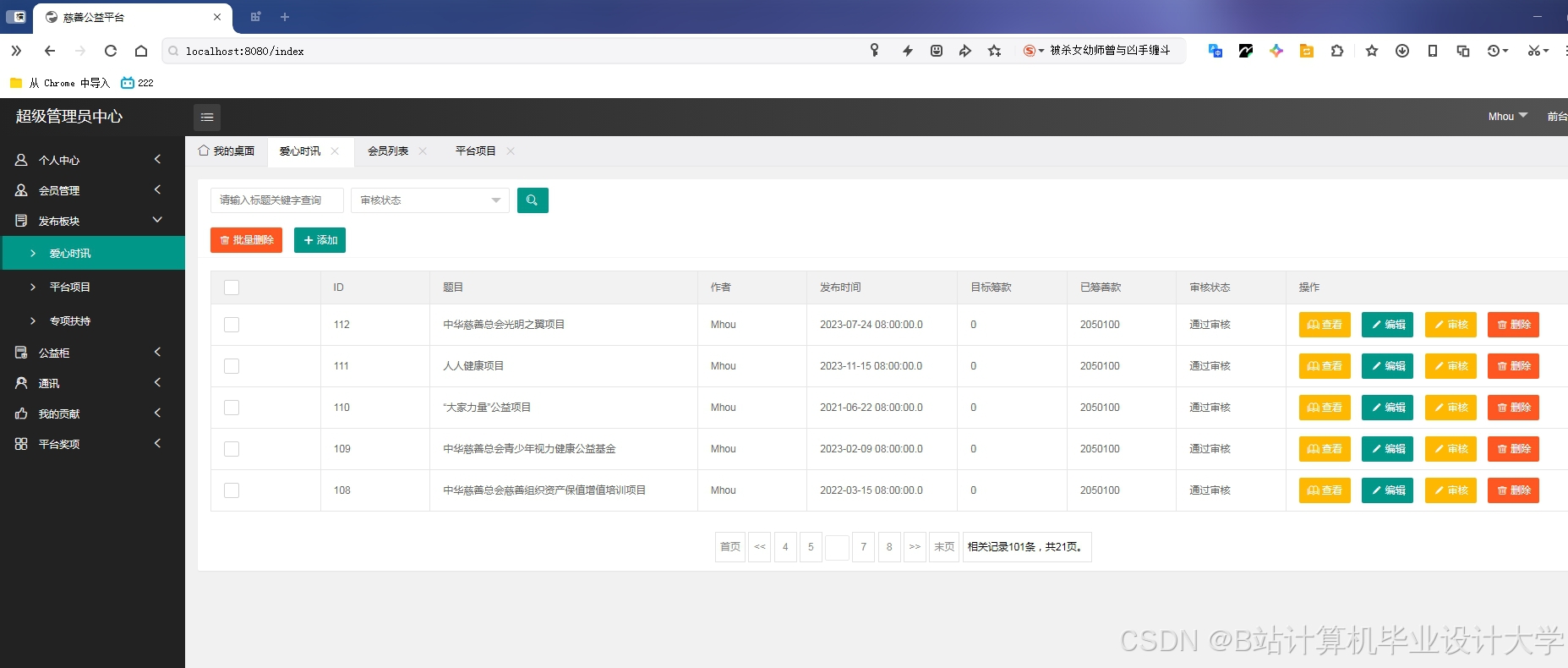
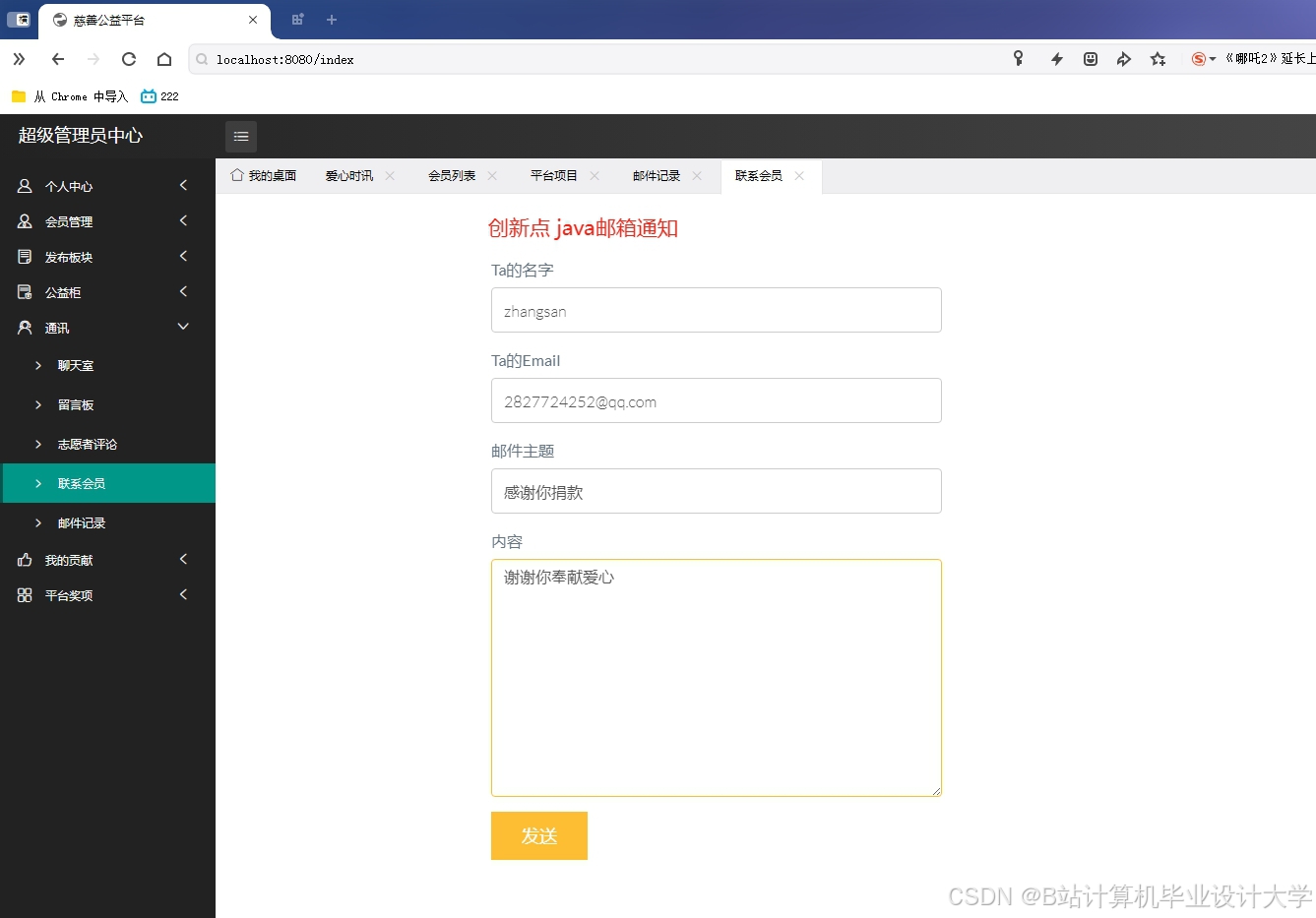
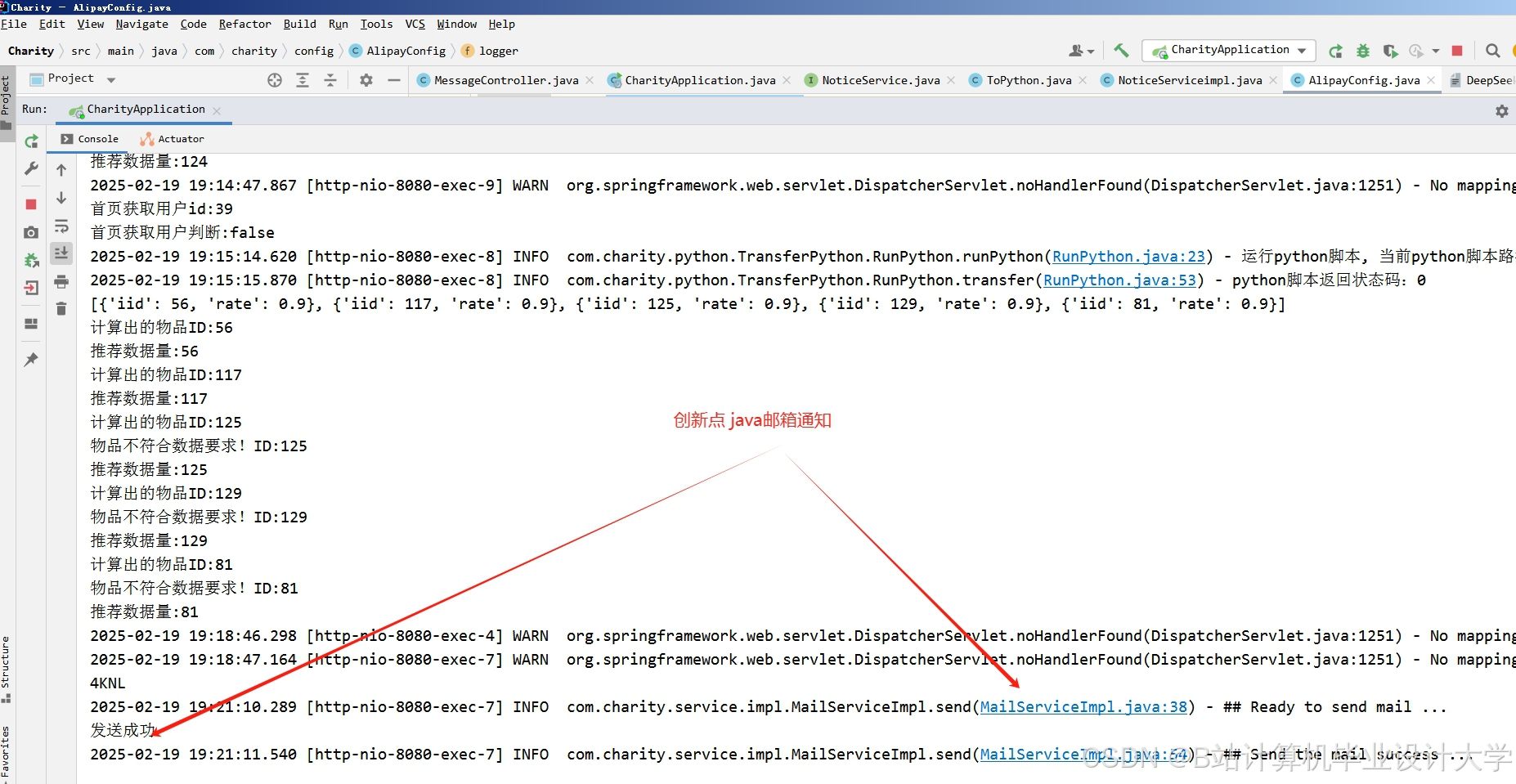
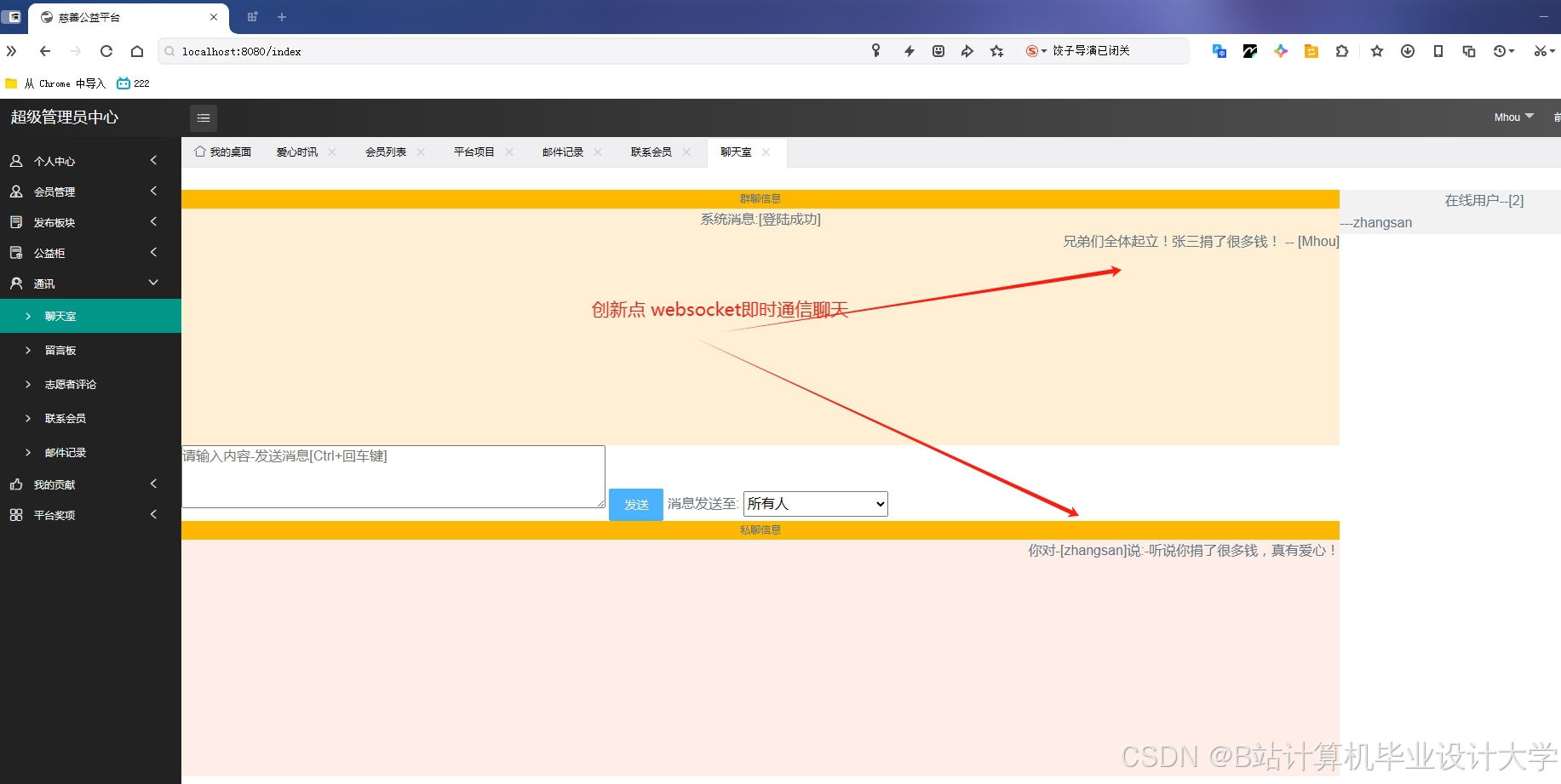
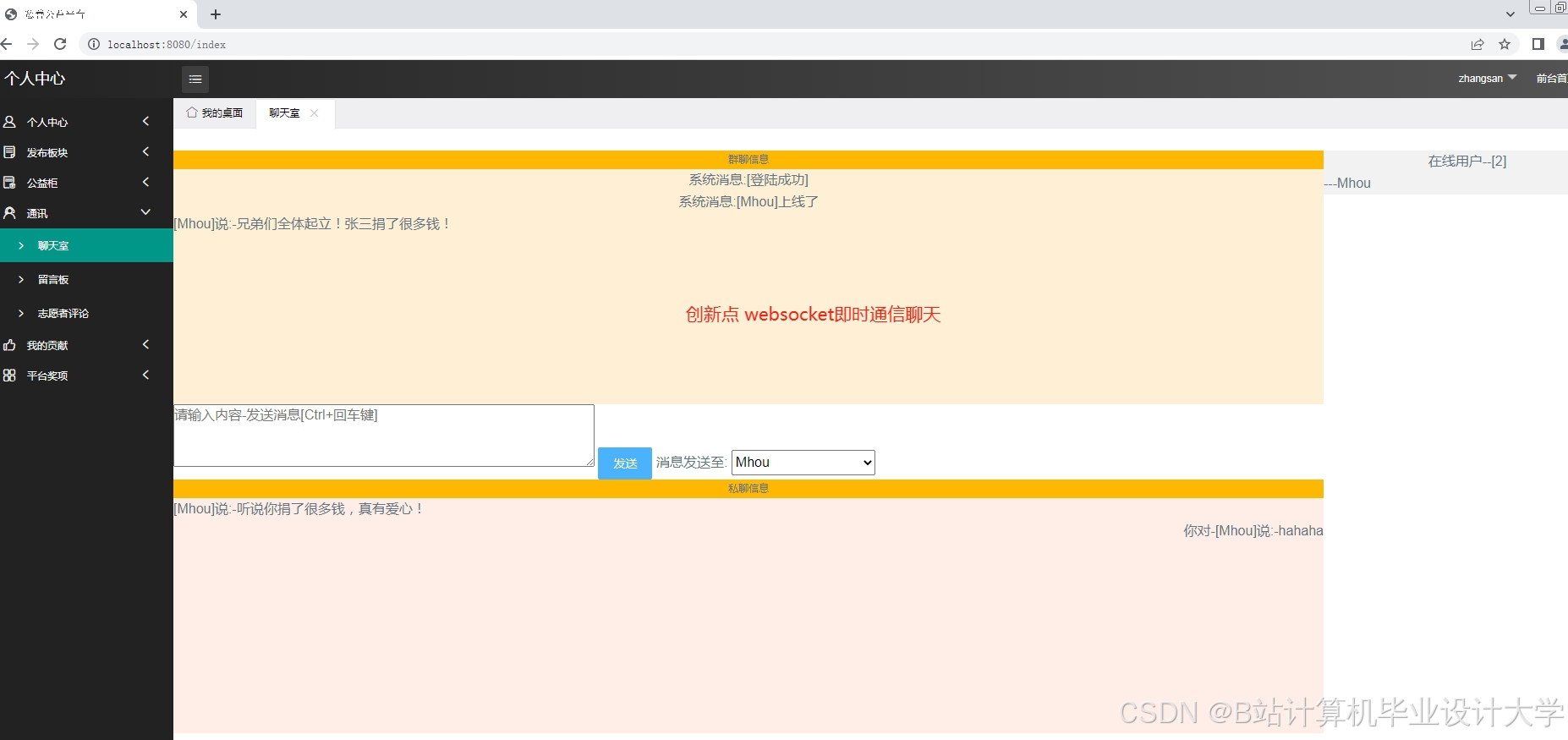
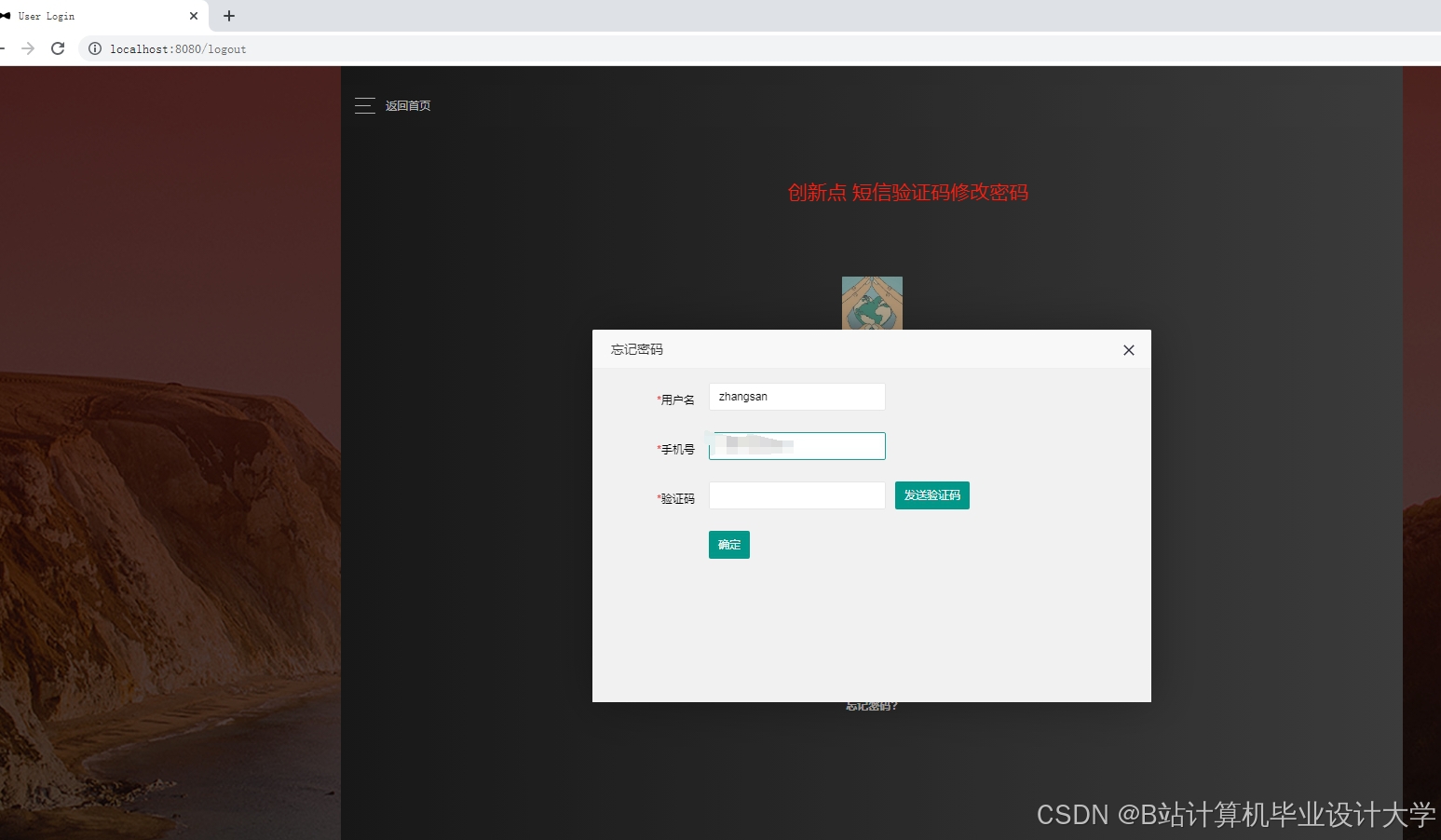
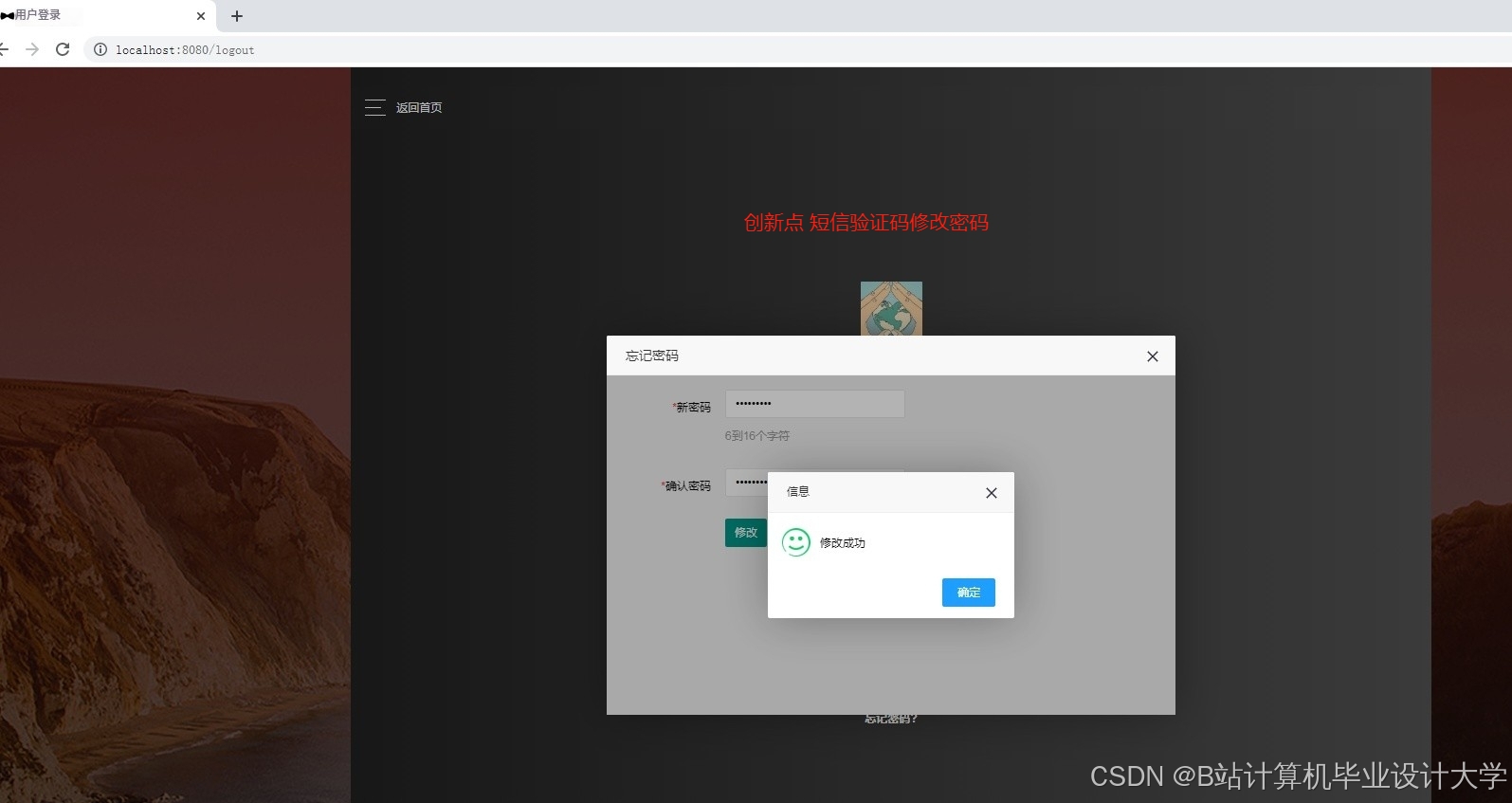
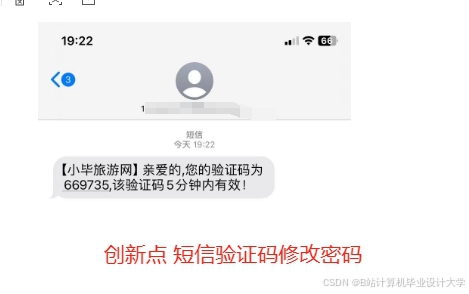
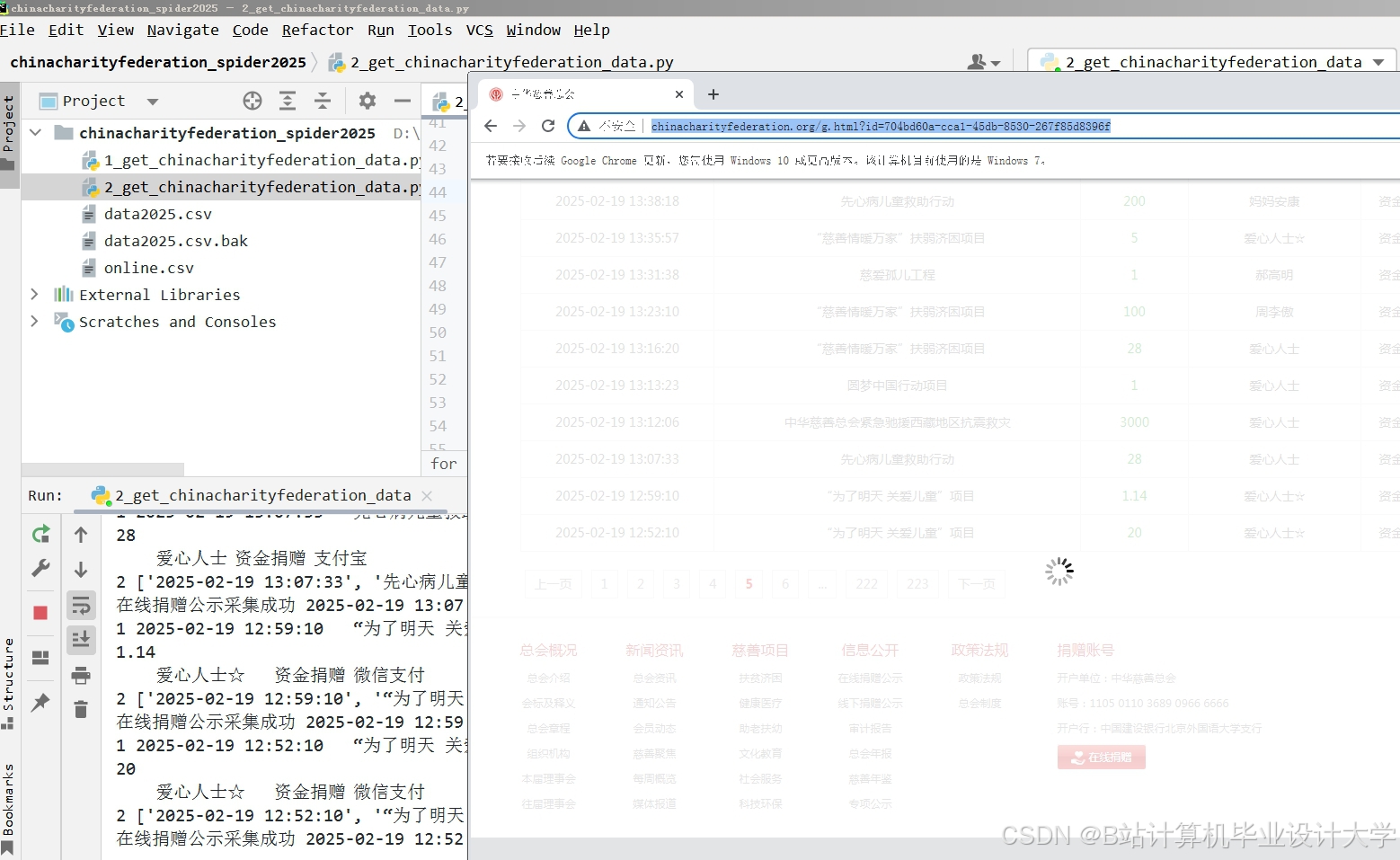
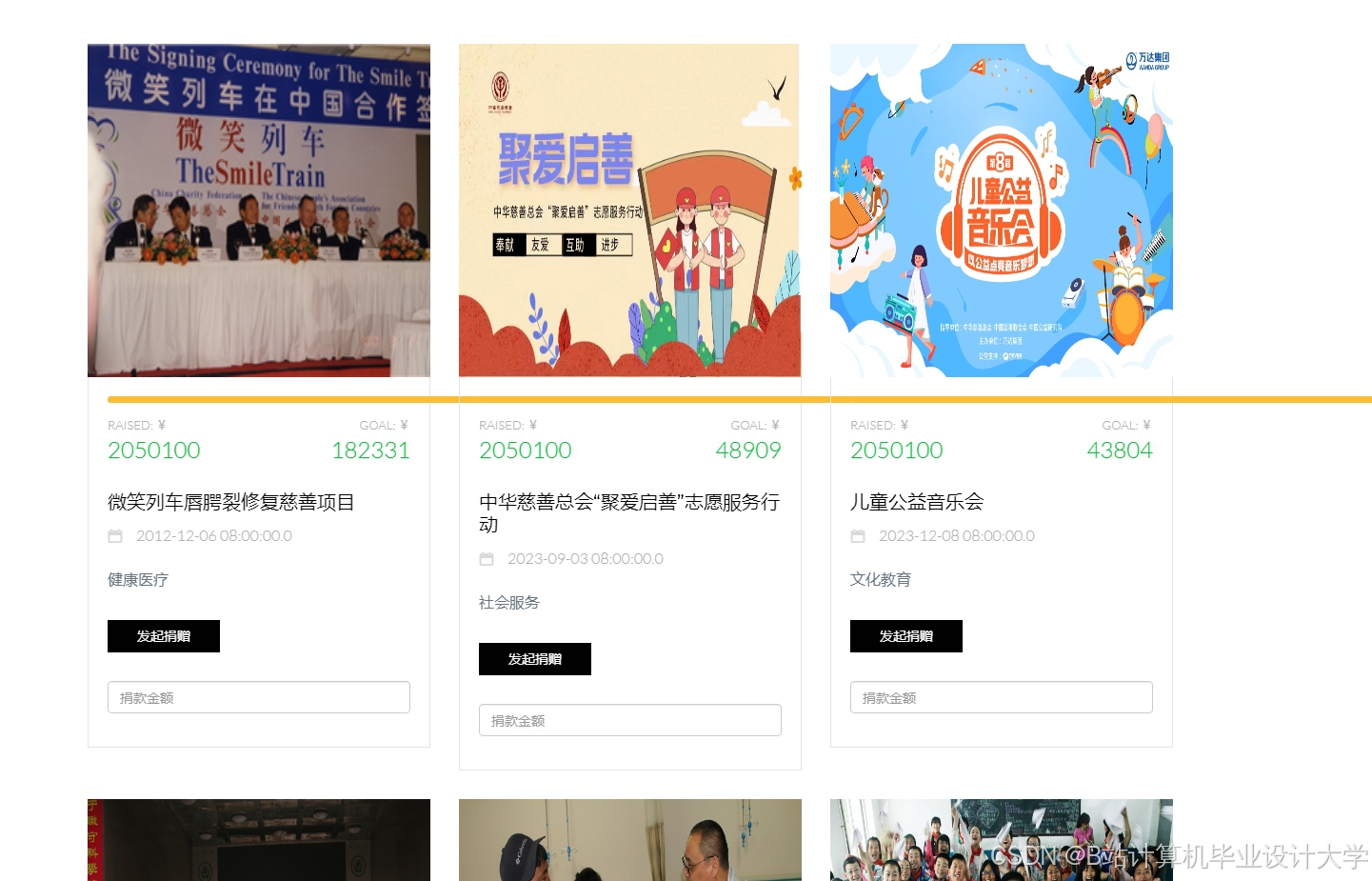
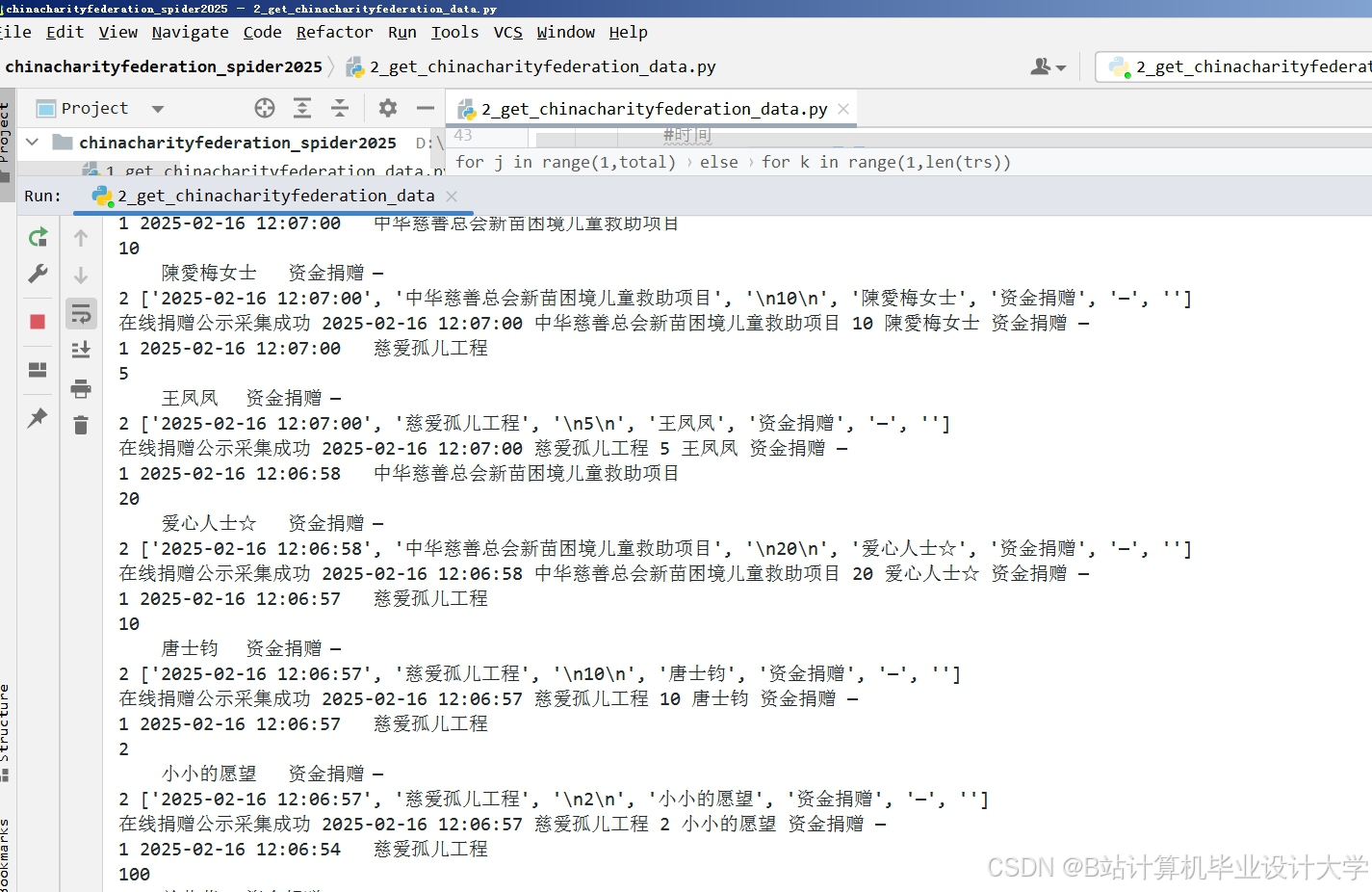
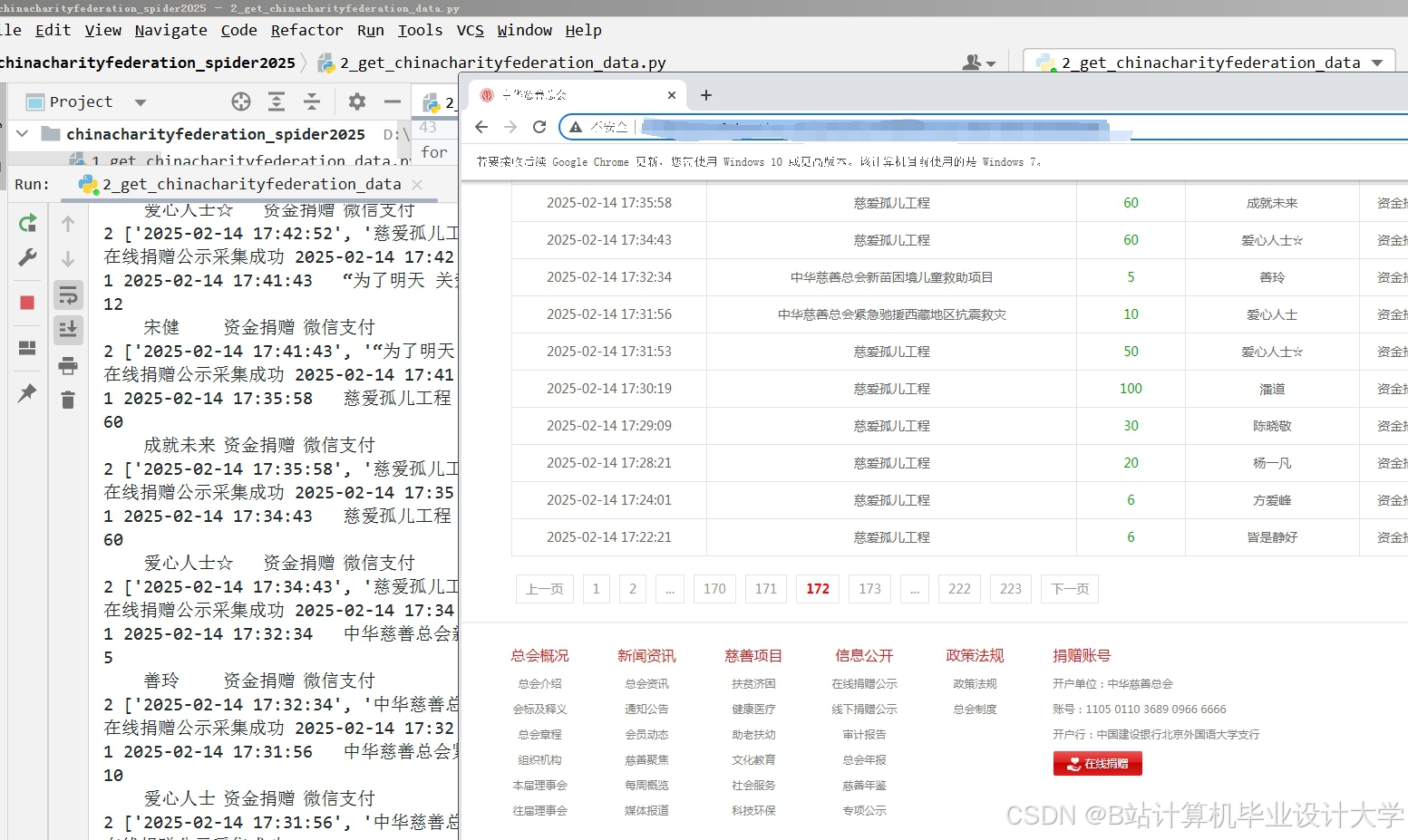
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











