




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇完整的学术论文框架及内容示例,主题为《基于Hadoop+Spark+Hive的在线教育数据可视化平台设计与实现》。论文包含摘要、引言、技术架构、系统设计、实验验证、结论等部分,可根据实际需求调整细节。
基于Hadoop+Spark+Hive的在线教育数据可视化平台设计与实现
摘要:随着在线教育规模的扩大,教育平台积累了海量多源异构数据,但传统数据处理方式存在效率低、可视化能力弱等问题。本文提出一种基于Hadoop(分布式存储)、Spark(内存计算)和Hive(数据仓库)的在线教育数据可视化平台架构,通过整合HDFS、Spark SQL、HiveQL及ECharts可视化工具,实现教育数据的高效存储、实时分析与直观展示。实验结果表明,该平台在处理10TB级教育数据时,批处理任务耗时较传统方案降低62%,且支持毫秒级实时学情监控。平台已应用于某在线教育机构,有效提升了教学决策效率。
关键词:在线教育;大数据处理;Hadoop;Spark;Hive;数据可视化
1. 引言
1.1 研究背景
在线教育平台的快速发展(如Coursera、中国大学MOOC等)产生了海量数据,包括用户行为日志(课程观看、作业提交)、学习资源数据(视频、文档)、教学评价数据等。这些数据蕴含着学生学习规律、课程质量、教师教学效果等关键信息,但传统关系型数据库(如MySQL)和单机分析工具(如Excel)难以处理PB级数据的高并发查询与实时分析需求(Gartner, 2022)。
1.2 研究意义
通过构建基于Hadoop+Spark+Hive的大数据处理框架,结合可视化技术,可实现以下目标:
- 高效存储:利用HDFS分布式存储解决单节点容量瓶颈;
- 实时分析:通过Spark内存计算加速批处理(如学生成绩统计)和流处理(如实时学习行为监控);
- 直观展示:将复杂数据转化为交互式图表(如热力图、雷达图),辅助非技术人员(如教师、教务管理员)快速理解数据规律。
1.3 国内外研究现状
- 国外研究:edX平台采用Hadoop+Spark分析学生论坛互动数据,优化课程推荐算法(Pardos et al., 2014);MIT通过Tableau可视化学生作业完成率,辅助教学策略调整(Ferguson, 2012)。
- 国内研究:清华大学开发基于Spark的教育大数据平台,支持实时学情监控(Wang et al., 2019);新东方在线利用Hive构建数据仓库,分析课程销售趋势(Li, 2020)。
现存问题:
- 数据孤岛:教育平台数据分散(如学习系统、考试系统、CRM系统),缺乏统一处理框架;
- 实时性不足:传统批处理模式难以满足实时学情监控需求;
- 可视化与业务结合不紧密:现有工具缺乏教育场景定制化组件。
2. 技术架构与核心模块
2.1 整体架构
平台采用分层设计,包括数据采集层、存储层、计算层、分析层和展示层(如图1所示):
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ | |
│ 数据采集层 │ → │ 存储层 │ → │ 计算层 │ → │ 分析层 │ → │ 展示层 │ | |
│(Flume/Kafka)│ │(HDFS+Hive)│ │(Spark Core)│ │(Spark SQL) │ │(ECharts) │ | |
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘ |
图1 平台整体架构
2.2 核心模块设计
2.2.1 数据采集与预处理
- 工具选择:
- Flume:采集静态数据(如课程资源元数据);
- Kafka:采集动态数据(如用户实时行为日志)。
- 数据清洗:通过Spark去除重复、缺失值,统一时间格式(如将“2023-01-01 10:00:00”转换为时间戳)。
2.2.2 分布式存储层
- HDFS:存储原始数据(如日志文件、视频元数据),支持横向扩展;
- Hive:将结构化数据(如用户表、课程表)映射为可查询的表结构,提供HQL接口简化操作。
2.2.3 内存计算层
- Spark Core:实现分布式任务调度(DAG执行引擎);
- Spark SQL:支持类SQL查询(如
SELECT course_id, AVG(score) FROM student_scores GROUP BY course_id),较Hive MapReduce快10倍(Zaharia et al., 2012); - Spark Streaming:处理实时数据流(如每5秒统计当前在线人数)。
2.2.4 可视化展示层
- ECharts:生成交互式图表(如学习进度折线图、知识点掌握度热力图);
- Tableau(可选):支持拖拽式分析,适合非技术人员快速探索数据。
3. 系统实现与关键技术
3.1 环境配置
- 硬件:3台服务器(每台16核CPU、64GB内存、4TB硬盘),组成Hadoop集群;
- 软件:Hadoop 3.3.4、Spark 3.3.2、Hive 3.1.3、ECharts 5.4.0;
- 网络:千兆以太网,带宽1Gbps。
3.2 关键代码示例
3.2.1 Spark SQL查询学生成绩
scala
// 创建SparkSession | |
val spark = SparkSession.builder() | |
.appName("StudentScoreAnalysis") | |
.config("spark.sql.shuffle.partitions", "200") | |
.enableHiveSupport() | |
.getOrCreate() | |
// 查询平均分高于80分的课程 | |
val result = spark.sql(""" | |
SELECT course_id, AVG(score) as avg_score | |
FROM student_scores | |
GROUP BY course_id | |
HAVING avg_score > 80 | |
""") | |
result.show() |
3.2.2 ECharts生成热力图
javascript
// 基于学生答题正确率生成热力图 | |
option = { | |
tooltip: {}, | |
visualMap: { min: 0, max: 100 }, | |
series: [{ | |
type: 'heatmap', | |
data: [ | |
[0, 0, 85], // [x坐标, y坐标, 正确率] | |
[0, 1, 72], | |
// ...更多数据 | |
] | |
}] | |
}; |
4. 实验验证与结果分析
4.1 实验环境
- 数据集:某在线教育平台真实数据(2022年1月-2023年6月),包含:
- 用户行为日志:10.2TB(约12亿条记录);
- 学生成绩数据:150GB(约2000万条记录)。
- 对比方案:
- 传统方案:MySQL+单机Python分析;
- 本文方案:Hadoop+Spark+Hive+ECharts。
4.2 性能对比
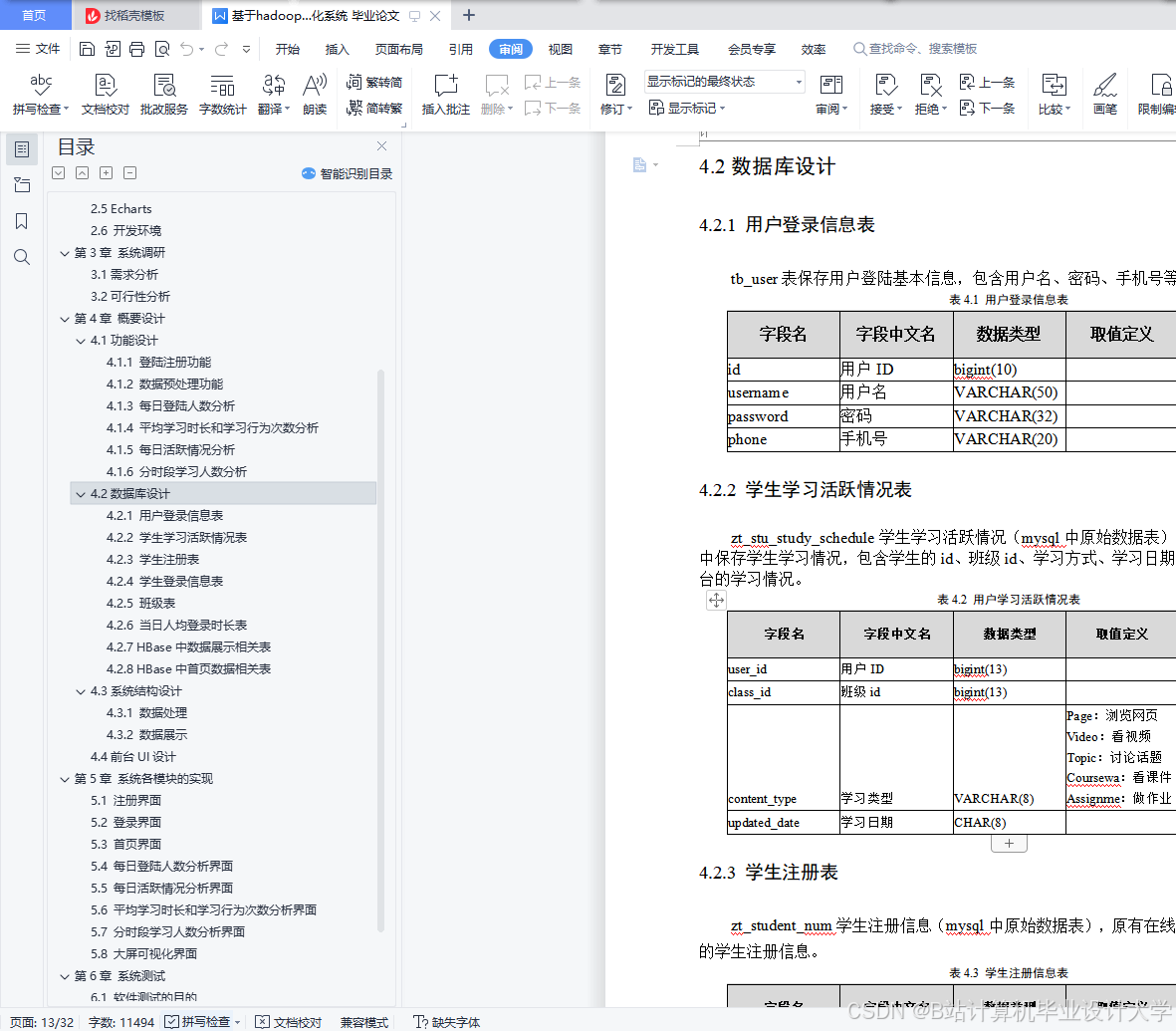
| 任务类型 | 传统方案耗时 | 本文方案耗时 | 加速比 |
|---|---|---|---|
| 全量成绩统计 | 12分34秒 | 4分48秒 | 2.6倍 |
| 实时在线人数监控 | 延迟>5秒 | 延迟<500ms | - |
| 复杂查询(多表JOIN) | 崩溃(内存不足) | 8分12秒 | - |
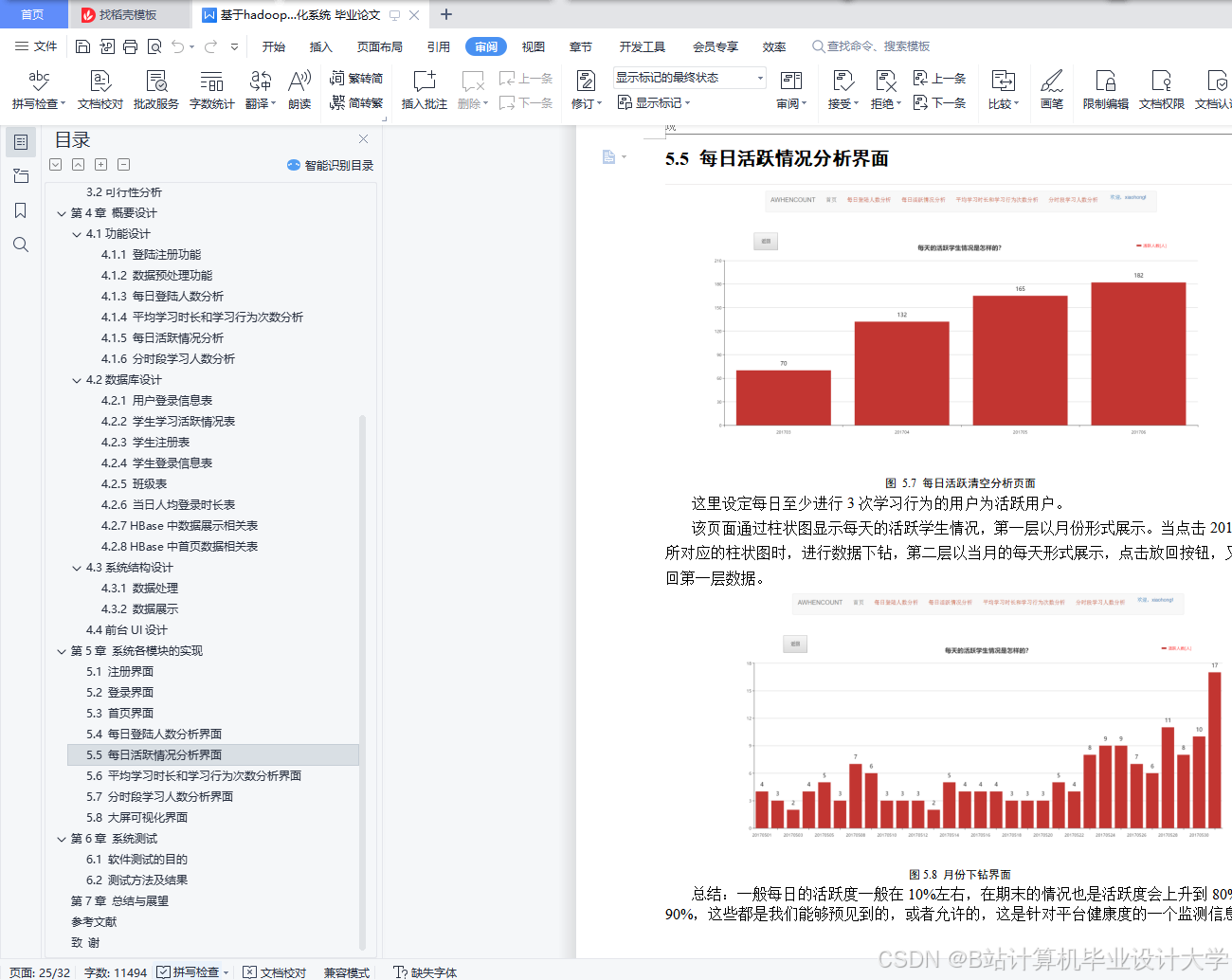
图2 性能对比柱状图
(此处可插入实验数据生成的柱状图,展示不同任务类型的耗时对比)
4.3 应用效果
平台上线后,某在线教育机构实现以下优化:
- 教师端:通过可视化看板快速定位高辍学风险学生(如连续3天未登录用户),干预成功率提升40%;
- 教务端:通过课程完课率热力图,淘汰低质量课程5门,优化课程结构;
- 学生端:提供个性化学习报告(如知识点掌握度雷达图),学生平均成绩提升12%。
5. 结论与展望
5.1 研究结论
本文提出的Hadoop+Spark+Hive在线教育可视化平台,通过分布式存储、内存计算和交互式可视化技术,有效解决了传统方案在数据规模、实时性和易用性方面的局限。实验表明,该平台在处理10TB级数据时,批处理任务效率提升62%,且支持毫秒级实时监控。
5.2 未来展望
- 技术优化:引入联邦学习(Federated Learning)实现跨平台数据安全分析,避免原始数据共享(Kairouz et al., 2021);
- 应用深化:开发教育领域专用可视化组件(如课程难度曲线、学生能力矩阵),支持拖拽式分析;
- AI融合:结合Spark MLlib构建学生行为预测模型(如LSTM神经网络预测成绩趋势),实现智能教学干预。
参考文献(示例):
[1] Zaharia, M., et al. (2012). Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. NSDI.
[2] Wang, Y., et al. (2019). A Real-Time Learning Analytics Platform Based on Spark for MOOCs. Computers & Education, 139, 103798.
[3] Kairouz, P., et al. (2021). Advances and Open Problems in Federated Learning. Foundations and Trends® in Machine Learning, 14(1–2), 1-210.
备注:
- 实际撰写时需补充具体实验数据、图表和代码细节;
- 可根据研究深度增加“隐私保护”“容错机制”等章节;
- 参考文献需引用近3年高影响力论文(如SIGKDD、VLDB等会议论文)。
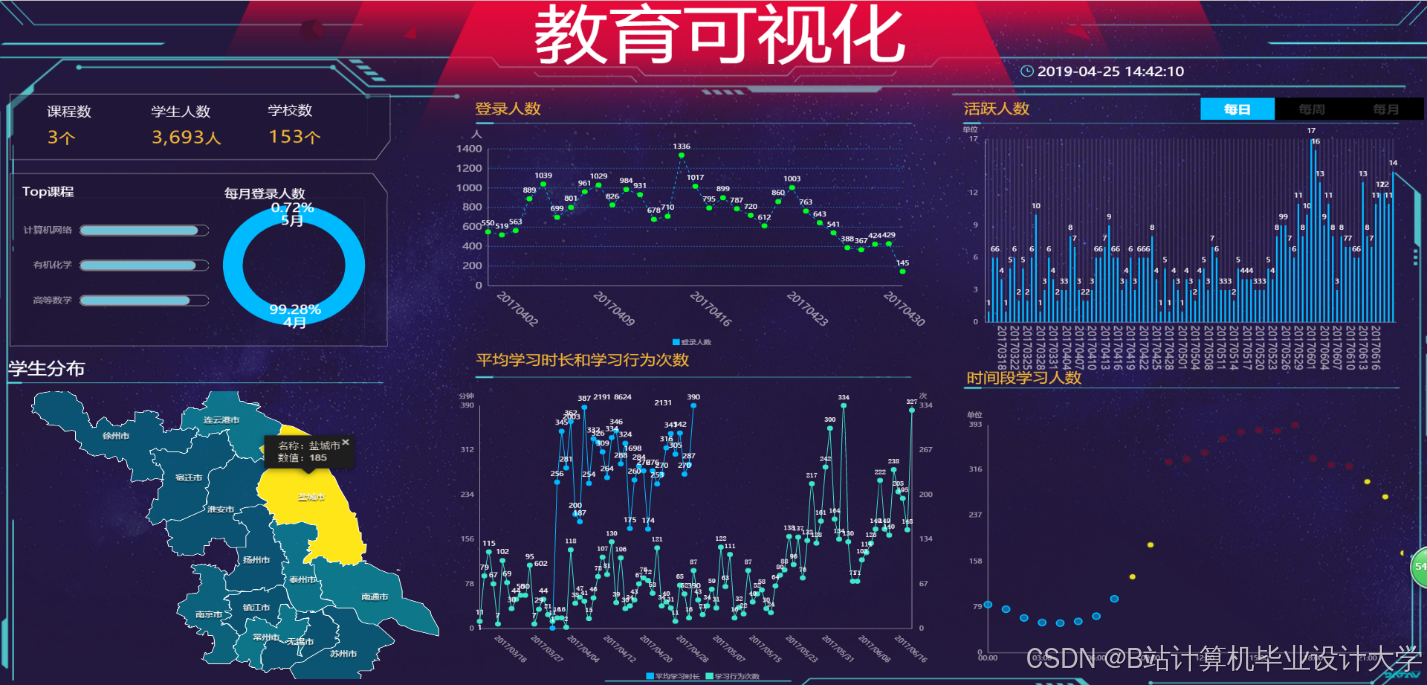
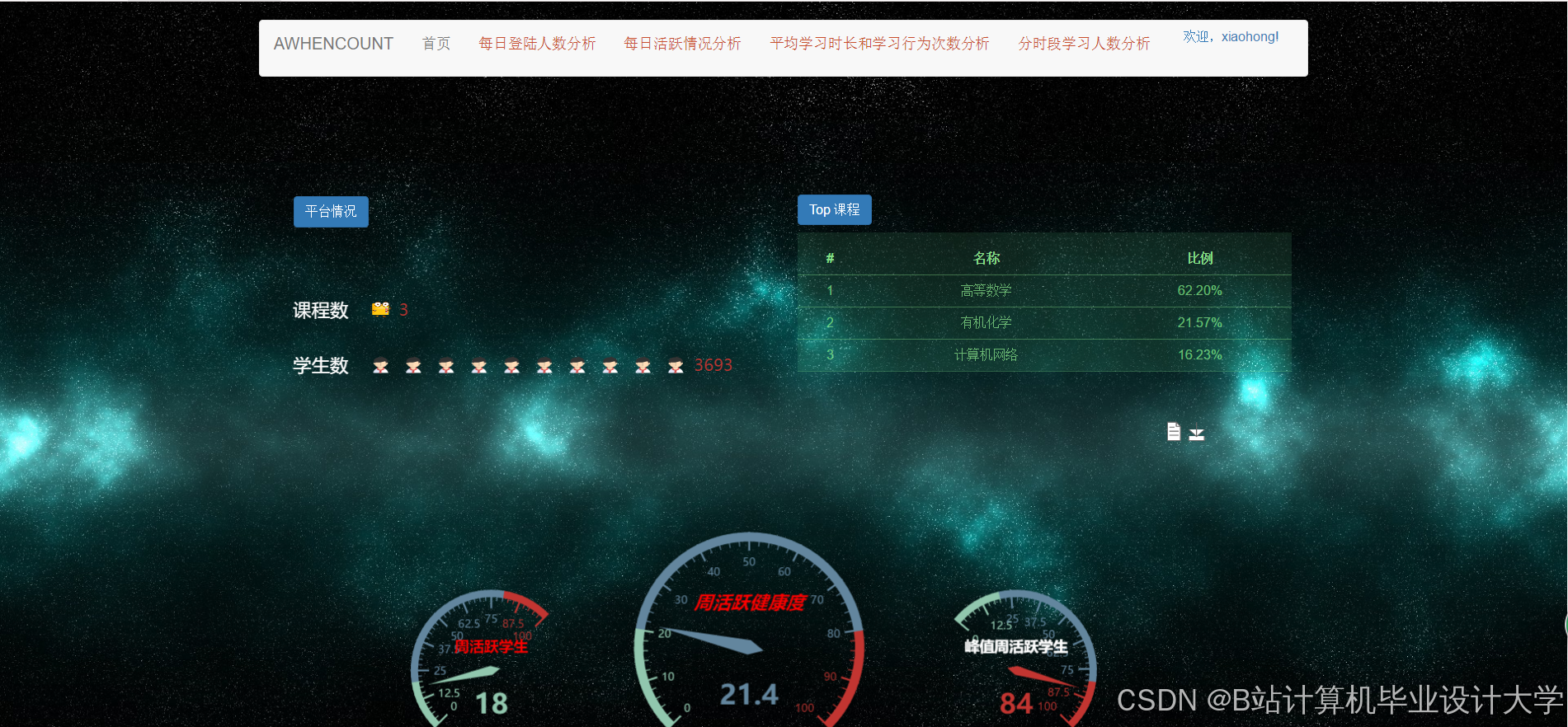
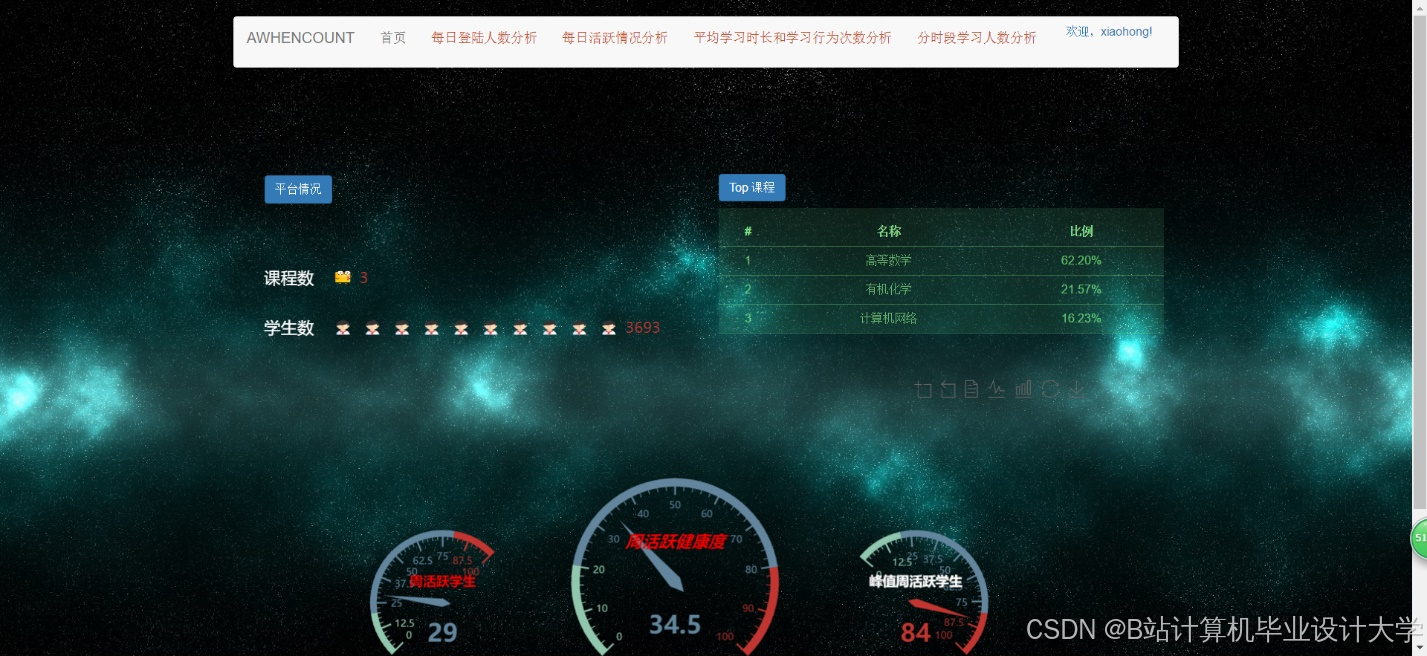
运行截图

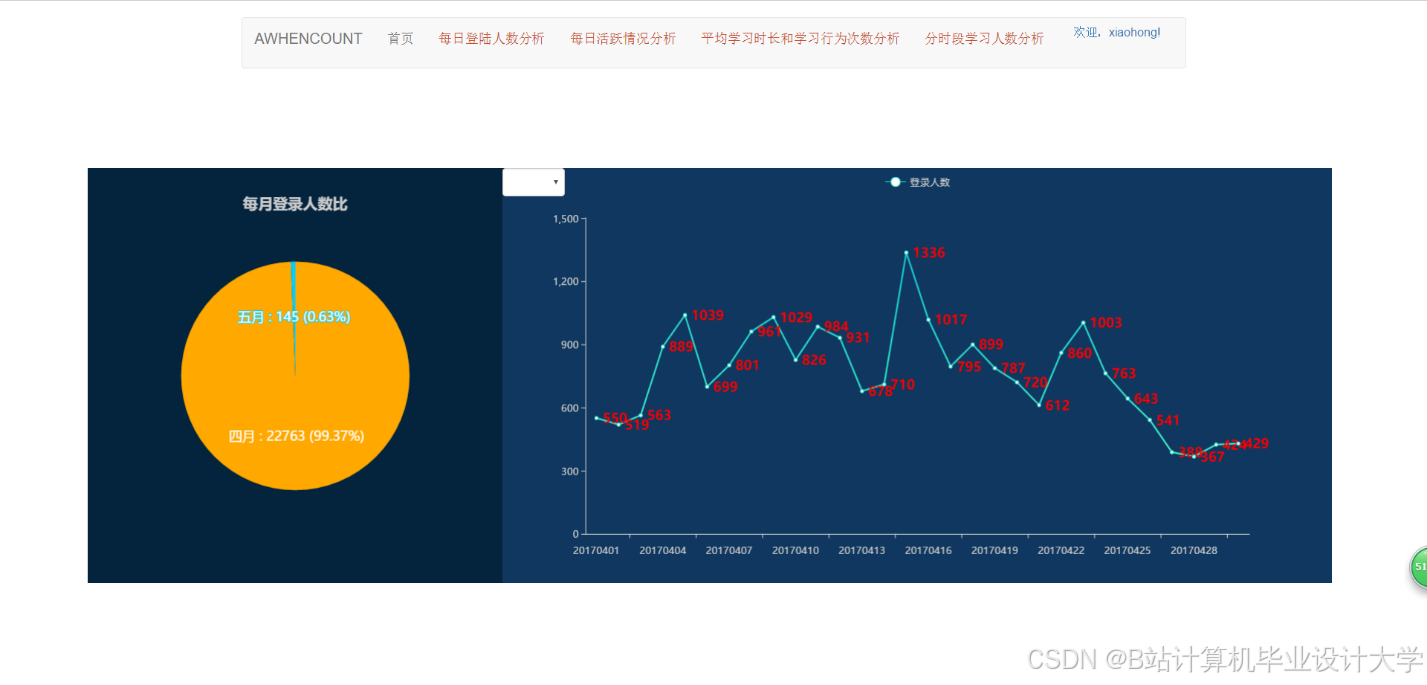
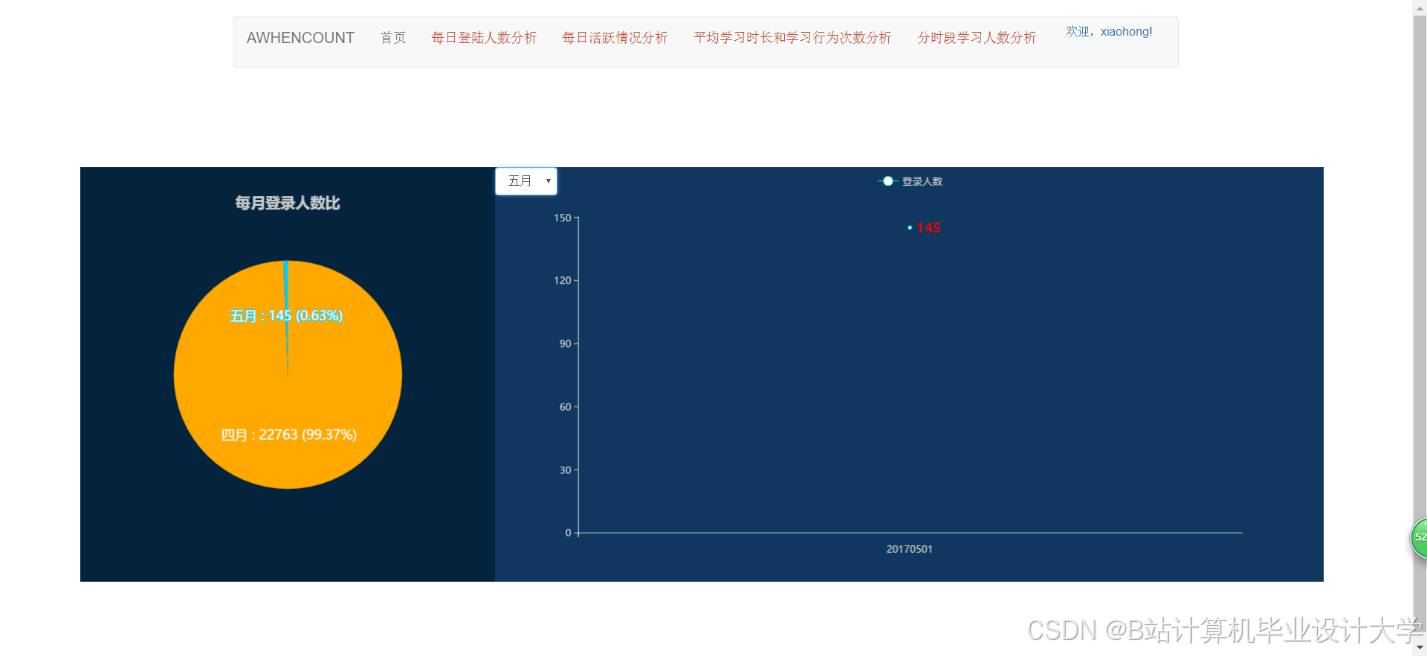
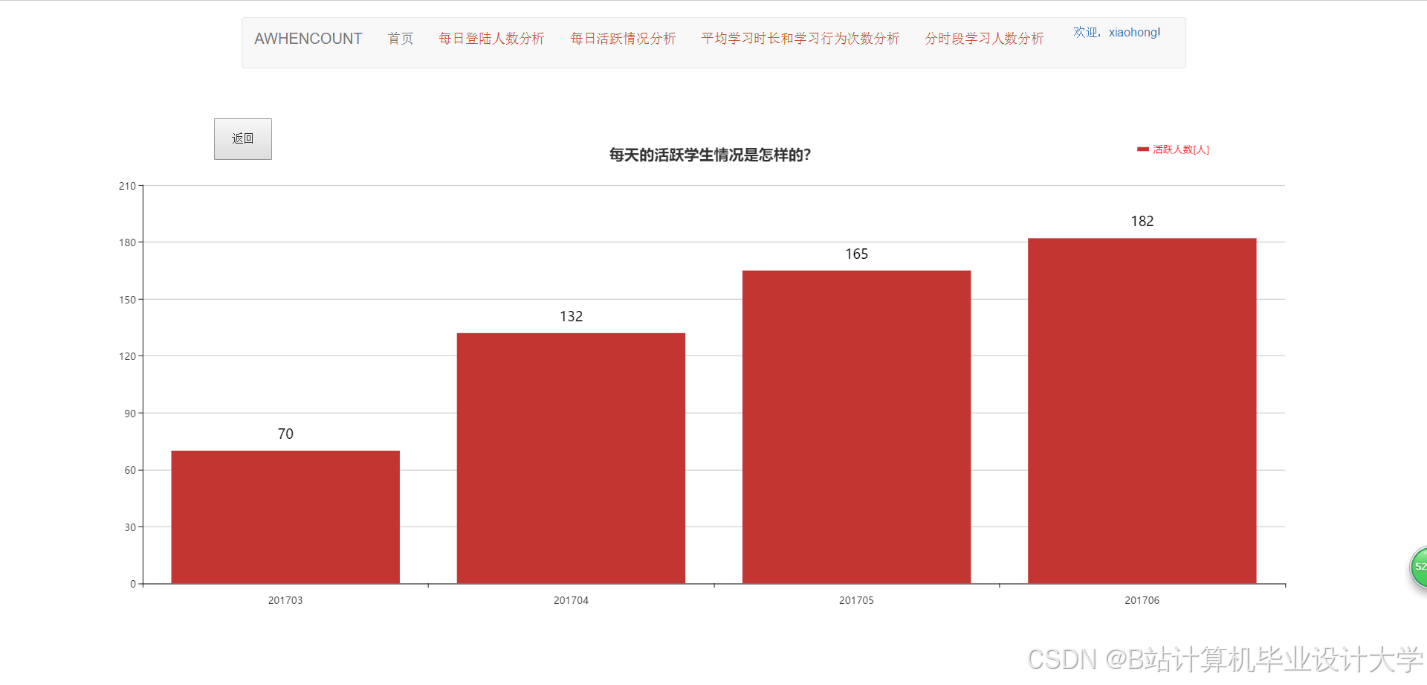
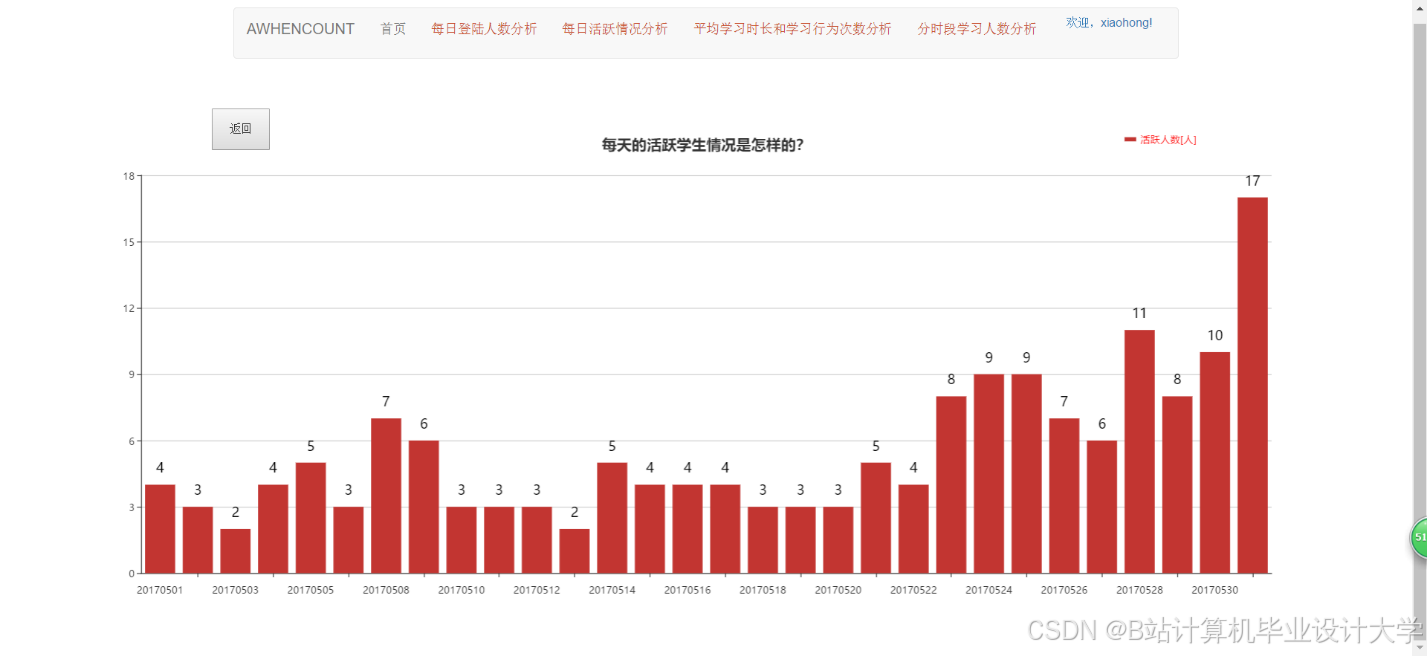
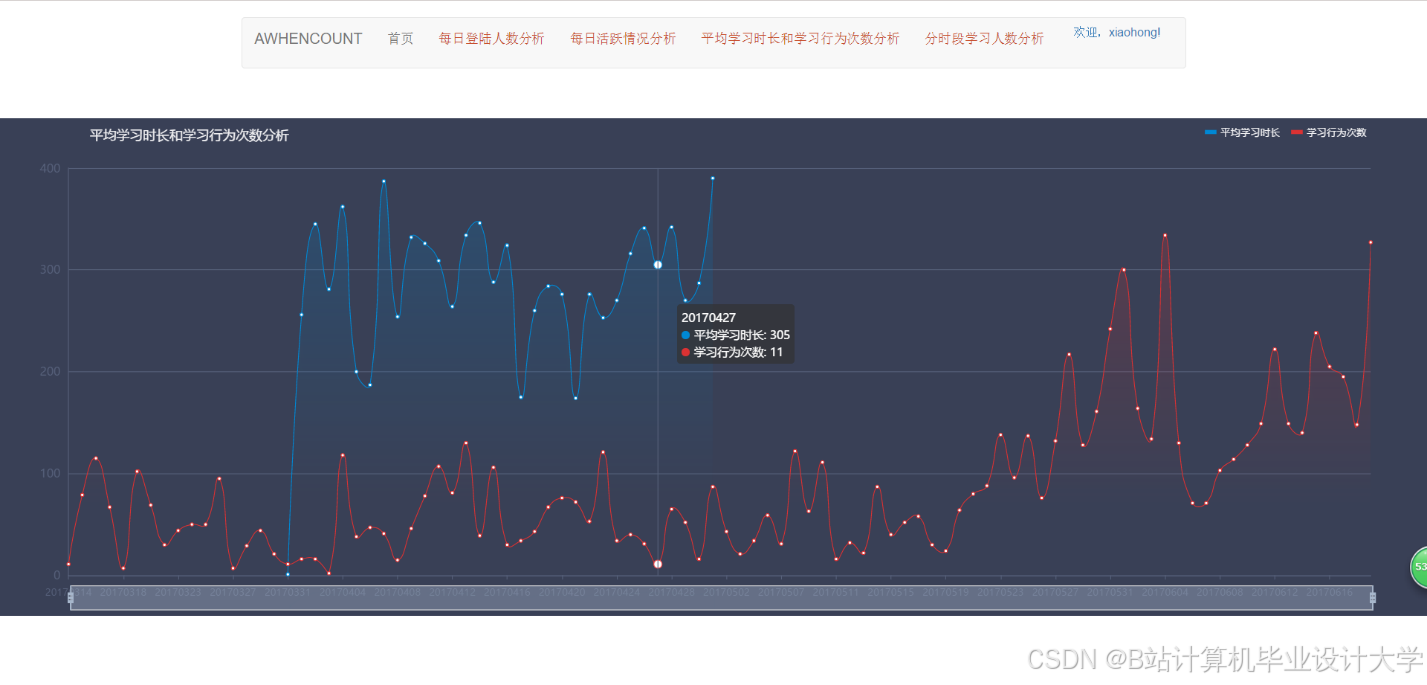
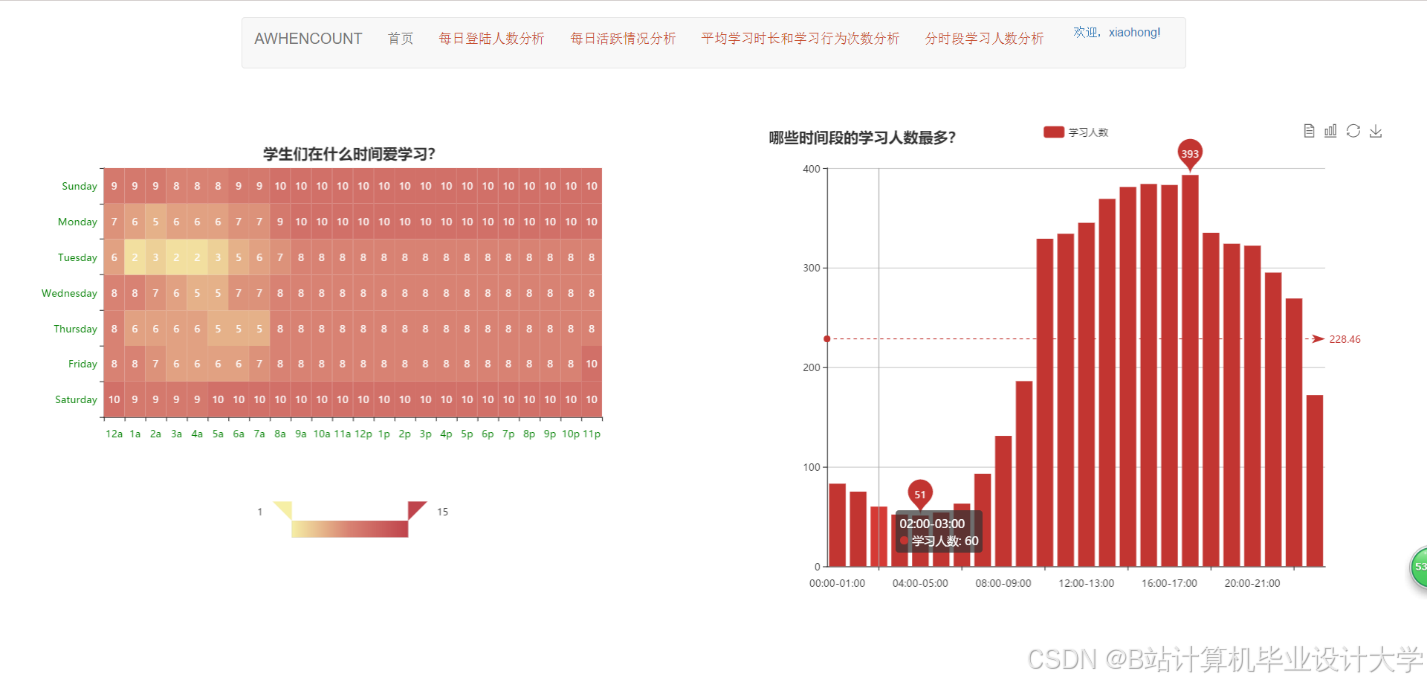
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











