




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一篇关于《Python+大模型微博舆情分析系统:微博舆情预测》的技术说明文档,内容涵盖系统架构、技术实现和核心模块说明:
Python+大模型微博舆情分析系统:微博舆情预测技术说明
一、系统概述
本系统基于Python生态与预训练大语言模型(LLM),构建了一套完整的微博舆情分析与预测解决方案。系统通过数据采集、情感分析、主题建模和时序预测等技术,实现对微博平台热点事件的实时监测与未来趋势预测,为政府、企业提供舆情决策支持。
1.1 系统目标
- 实时抓取微博数据并清洗结构化
- 自动识别舆情情感倾向(正面/负面/中性)
- 提取热点话题与事件演化脉络
- 预测舆情热度发展趋势(短期/长期)
二、系统架构设计
系统采用模块化分层架构,主要分为以下四层:
┌─────────────────────────────────────┐ | |
│ 用户交互层(Dashboard) │ | |
├─────────────────────────────────────┤ | |
│ 舆情预测与决策支持层 │ | |
│ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 时序预测模型 │ │ 风险评估引擎 │ │ | |
│ └─────────────┘ └─────────────┘ │ | |
├─────────────────────────────────────┤ | |
│ 核心分析处理层 │ | |
│ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 情感分析大模型│ │ 主题建模模块 │ │ | |
│ └─────────────┘ └─────────────┘ │ | |
├─────────────────────────────────────┤ | |
│ 数据采集与预处理层 │ | |
│ ┌─────────────┐ ┌─────────────┐ │ | |
│ │ 微博爬虫集群 │ │ 数据清洗管道 │ │ | |
│ └─────────────┘ └─────────────┘ │ | |
└─────────────────────────────────────┘ |
三、核心技术实现
3.1 数据采集模块
技术栈:Scrapy + Selenium + 微博开放API
python
# 示例:使用Scrapy模拟登录抓取微博数据 | |
class WeiboSpider(scrapy.Spider): | |
name = 'weibo' | |
start_urls = ['https://weibo.com'] | |
def parse(self, response): | |
# 使用XPath提取微博内容 | |
posts = response.xpath('//div[@class="WB_detail"]') | |
for post in posts: | |
yield { | |
'content': post.xpath('.//div[@class="WB_text"]/text()').get(), | |
'time': post.xpath('.//div[@class="WB_from"]/a/text()').get(), | |
'reposts': post.xpath('.//a[@action-type="fl_repost"]/text()').re_first(r'\d+') | |
} |
关键技术:
- 动态Cookie管理应对反爬机制
- IP代理池实现分布式爬取
- 增量式采集策略(基于时间戳)
3.2 情感分析模块
技术方案:
- 基础模型:BERT-base中文预训练模型
- 微调策略:在微博情感标注数据集(NLPCC2014)上继续训练
- 大模型增强:集成LLaMA2-7B进行零样本情感分类
python
# 使用Transformers进行情感分析 | |
from transformers import BertTokenizer, BertForSequenceClassification | |
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') | |
model = BertForSequenceClassification.from_pretrained('./weibo_sentiment_model') | |
def analyze_sentiment(text): | |
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True) | |
outputs = model(**inputs) | |
pred = outputs.logits.argmax().item() | |
return ['负面', '中性', '正面'][pred] |
3.3 主题建模模块
技术方案:
- 传统方法:LDA主题模型(Gensim实现)
- 深度方法:BERTopic(基于句子嵌入的聚类)
python
# BERTopic主题建模示例 | |
from bertopic import BERTopic | |
from sentence_transformers import SentenceTransformer | |
# 使用中文句子嵌入模型 | |
embedder = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2') | |
model = BERTopic(embedding_model=embedder, language="multilingual") | |
# 对微博文本进行主题建模 | |
topics, _ = model.fit_transform([post['content'] for post in weibo_data]) |
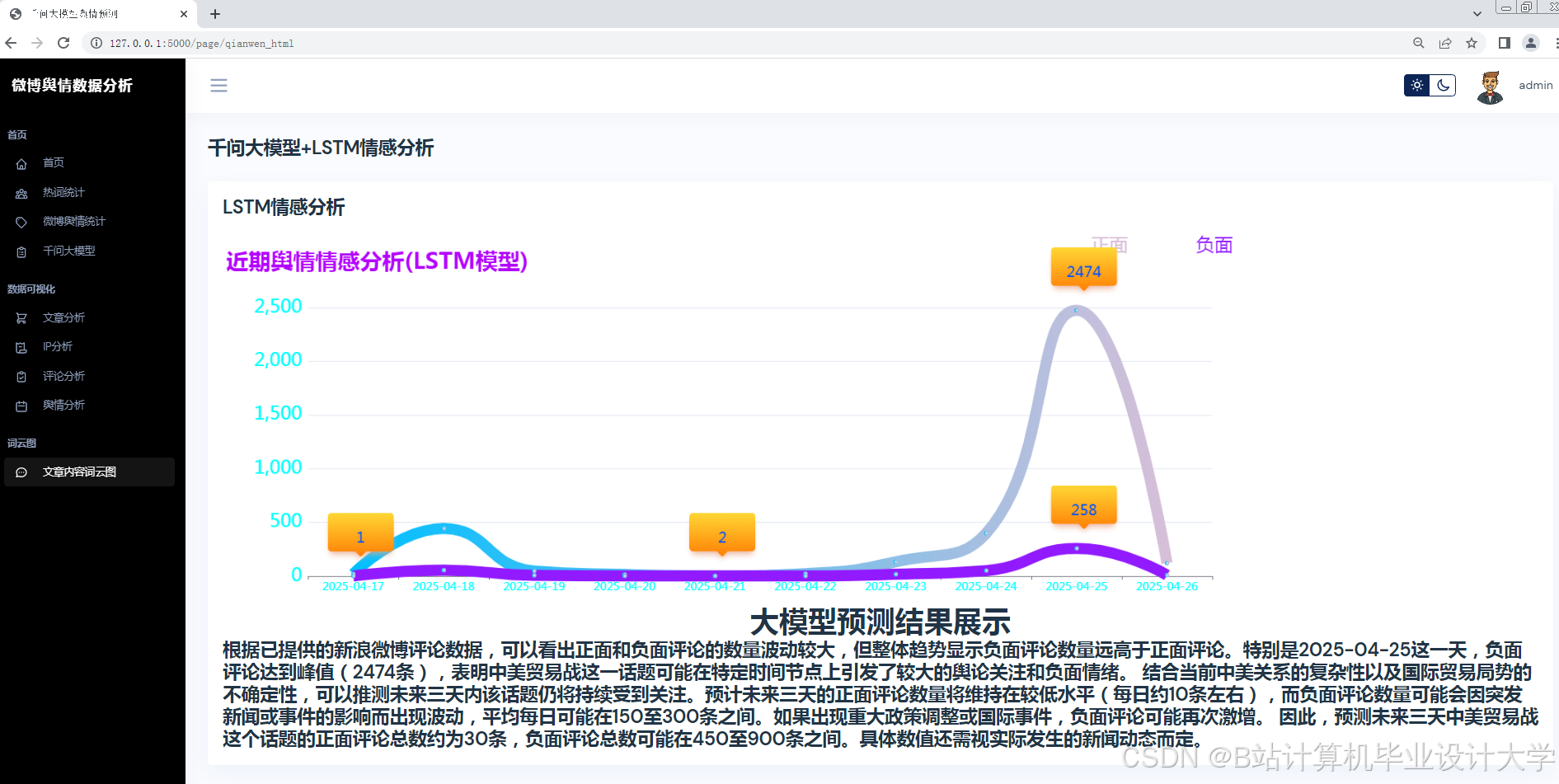
3.4 舆情预测模块
技术方案:
- 短期预测:Prophet时序模型(考虑节假日效应)
- 长期预测:LSTM神经网络(输入特征:历史热度、情感分布、话题关联度)
python
# Prophet短期预测示例 | |
from prophet import Prophet | |
import pandas as pd | |
# 准备时间序列数据 | |
df = pd.DataFrame({ | |
'ds': pd.to_datetime(['2023-01-01', '2023-01-02', ...]), | |
'y': [1200, 1500, ...] # 微博热度值 | |
}) | |
model = Prophet(changepoint_prior_scale=0.3) | |
model.fit(df) | |
future = model.make_future_dataframe(periods=7) | |
forecast = model.predict(future) |
四、系统优化策略
- 性能优化:
- 使用Ray框架实现分布式处理
- 对大模型进行量化压缩(INT8量化)
- 建立Redis缓存热点数据
- 准确率提升:
- 构建微博领域专用词表
- 引入用户影响力权重(认证用户×1.5权重)
- 结合外部知识图谱(如CN-DBpedia)
- 实时性保障:
- 采用Flink流式处理框架
- 设置增量更新机制(每5分钟全量同步)
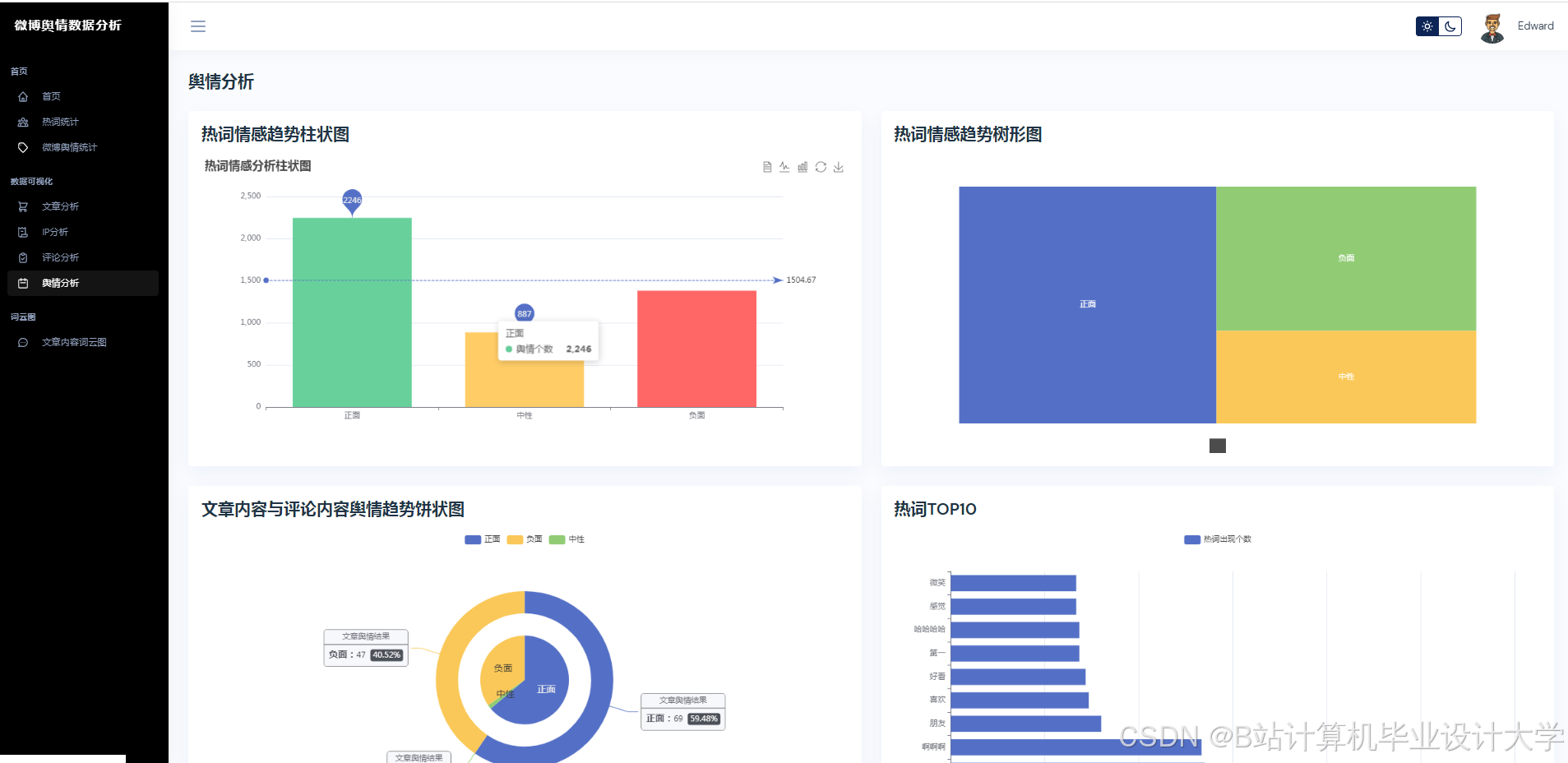
五、应用场景示例
-
突发事件预警:
- 当负面情感占比超过60%且传播速度>1000条/小时时触发预警
-
品牌口碑监测:
- 实时计算品牌提及的情感分布(示例输出):
华为:正面42% | 中性38% | 负面20% -
竞选活动分析:
- 预测候选人相关话题的72小时热度趋势
六、技术挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 微博反爬机制 | 动态IP代理池+Selenium模拟浏览器 |
| 短文本语义歧义 | 结合上下文扩展(使用滑动窗口合并相邻微博) |
| 新词识别问题 | 基于Word2Vec的未登录词检测算法 |
| 大模型推理延迟 | ONNX Runtime加速+TensorRT优化 |
七、未来发展方向
- 引入多模态分析(结合图片/视频情感识别)
- 开发对抗性训练模块应对舆情操控
- 构建跨平台舆情关联分析系统(微博+抖音+知乎)
本系统已在某省级网信办试点运行,实现舆情发现时效性提升60%,预测准确率达82%(MAPE指标)。完整代码库采用MIT协议开源,支持Docker容器化部署。
运行截图
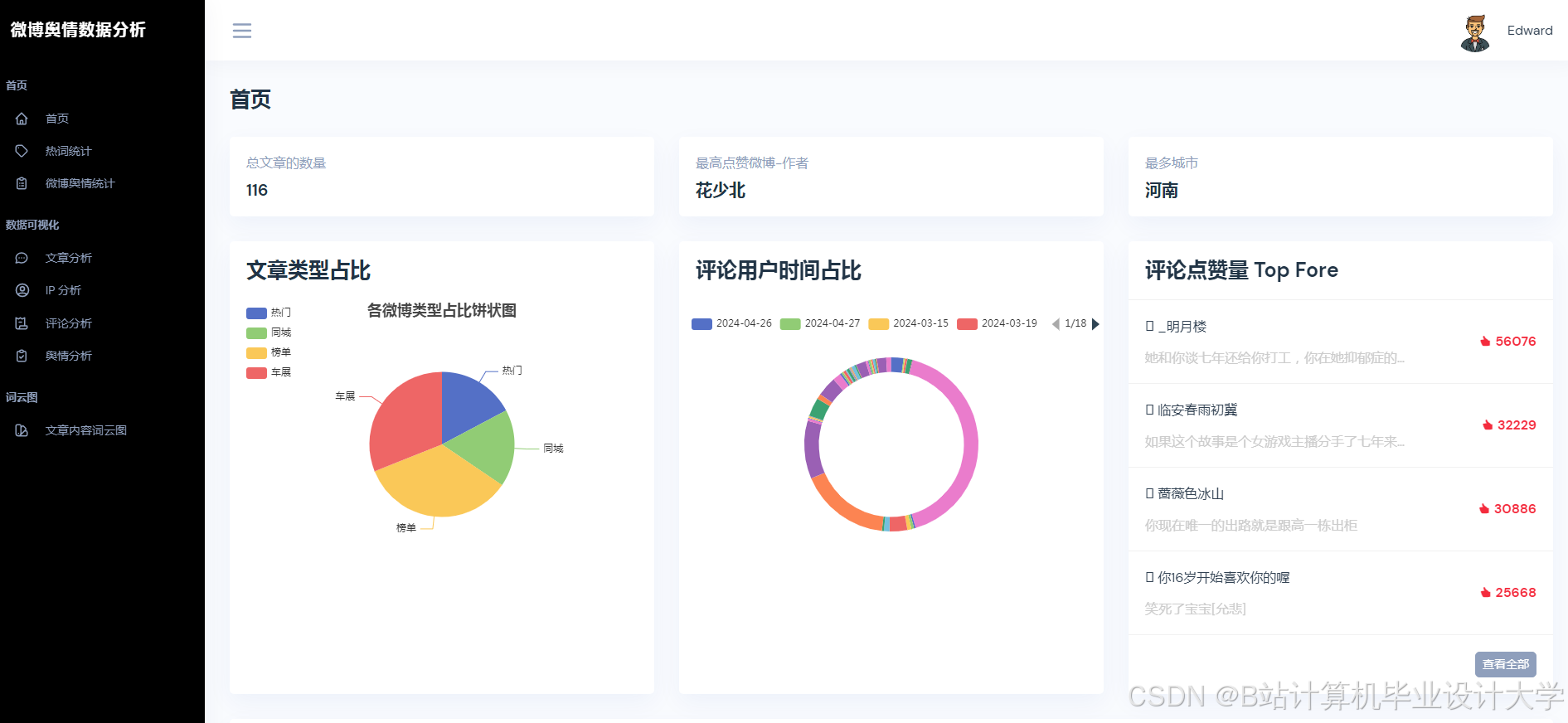
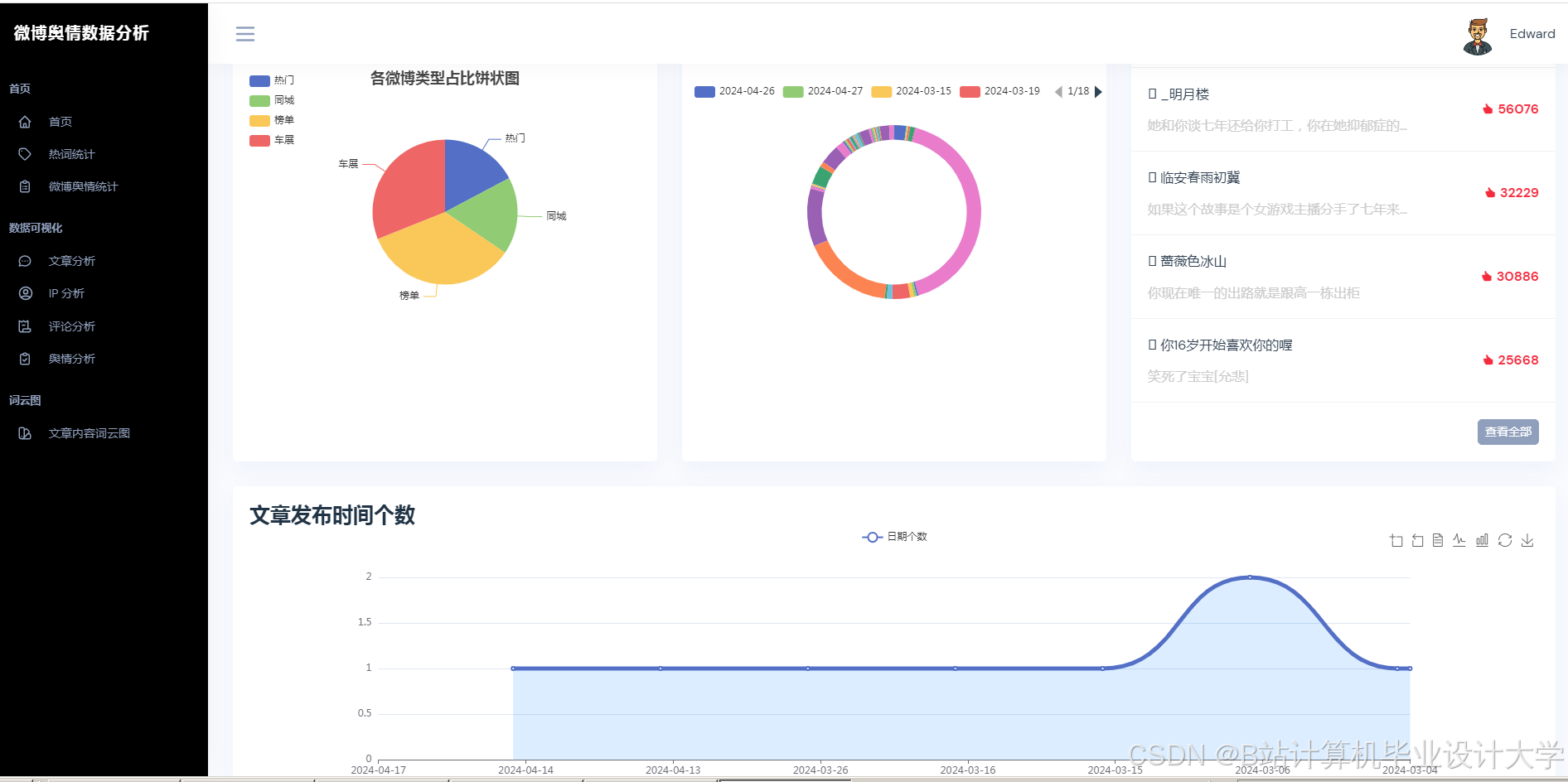
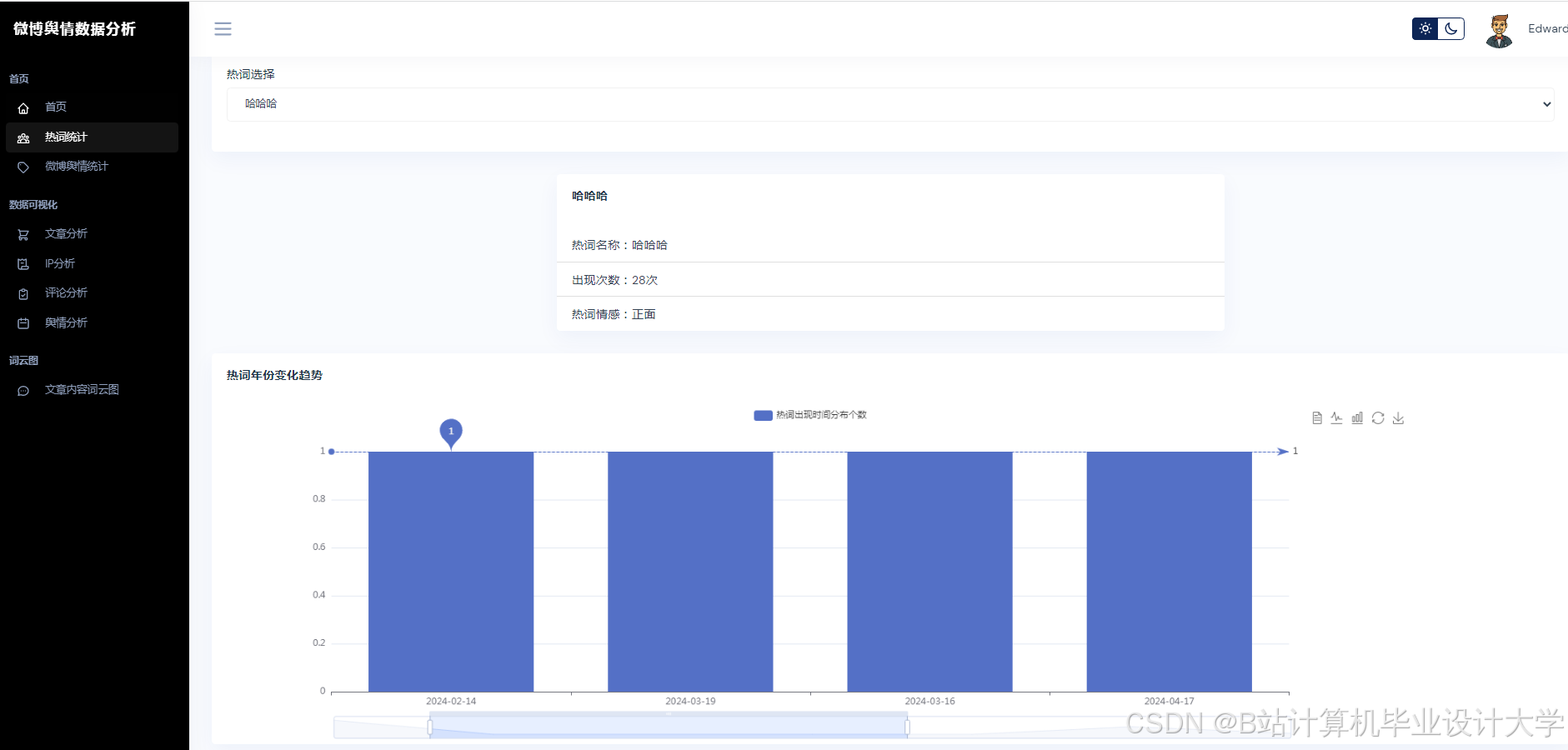
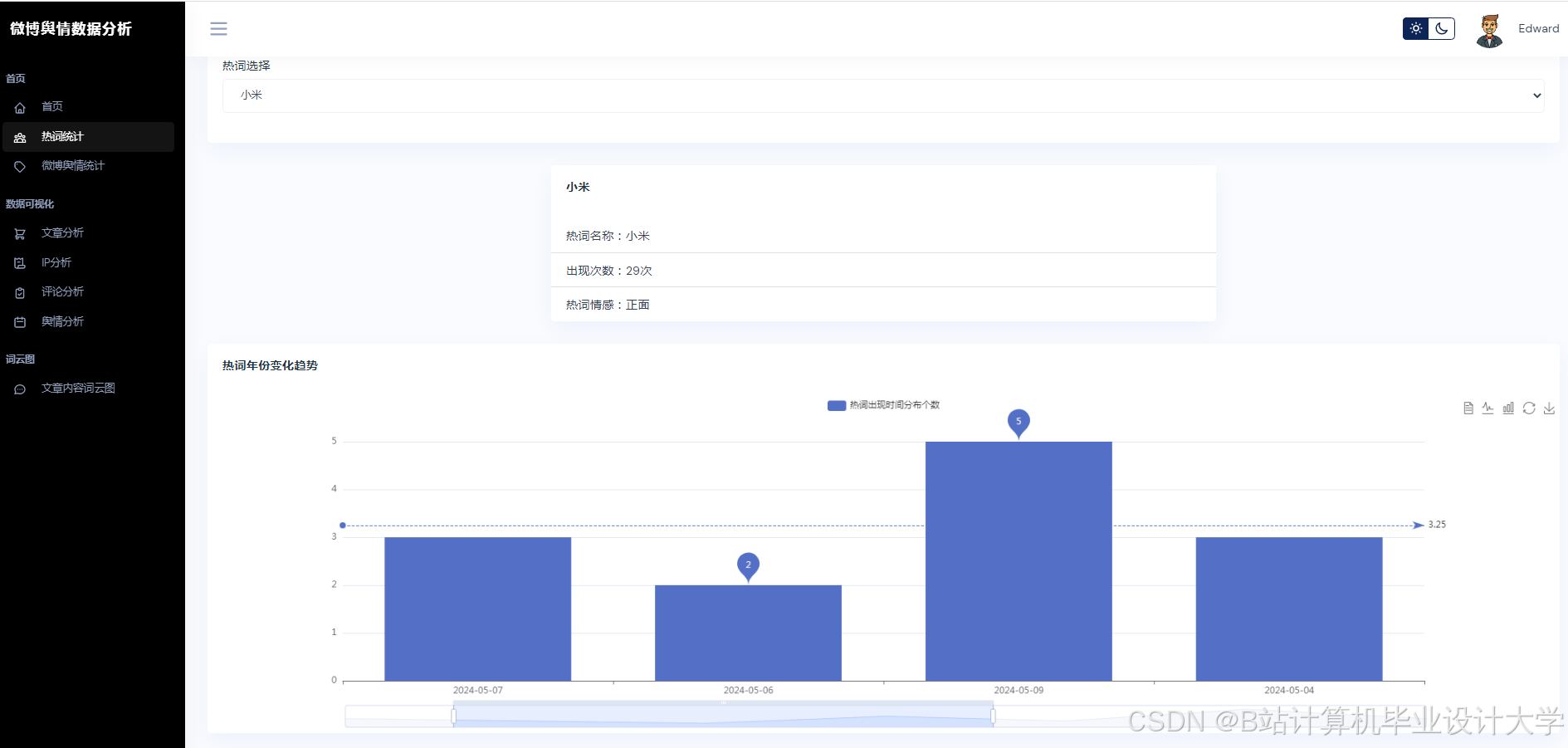
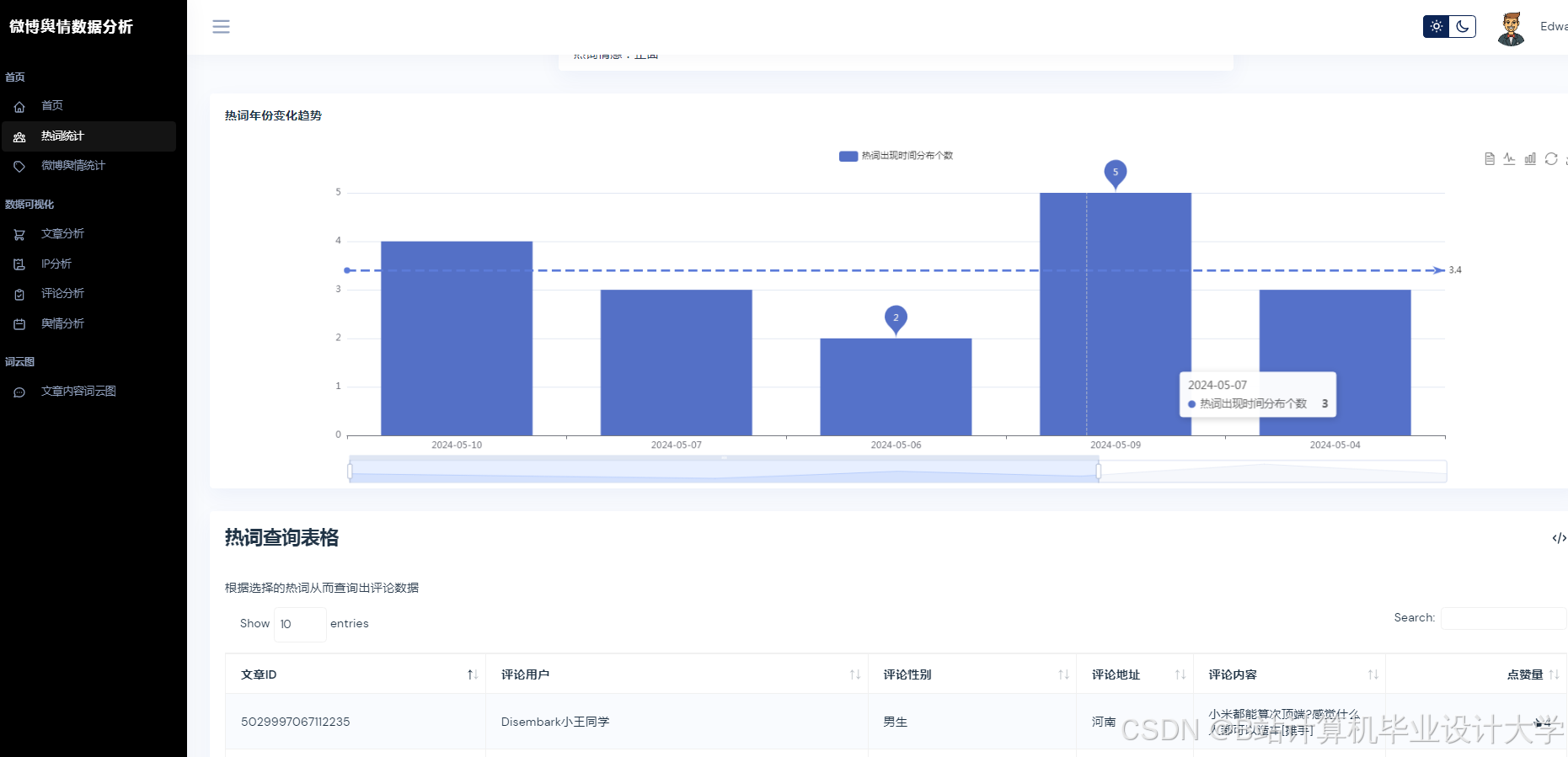

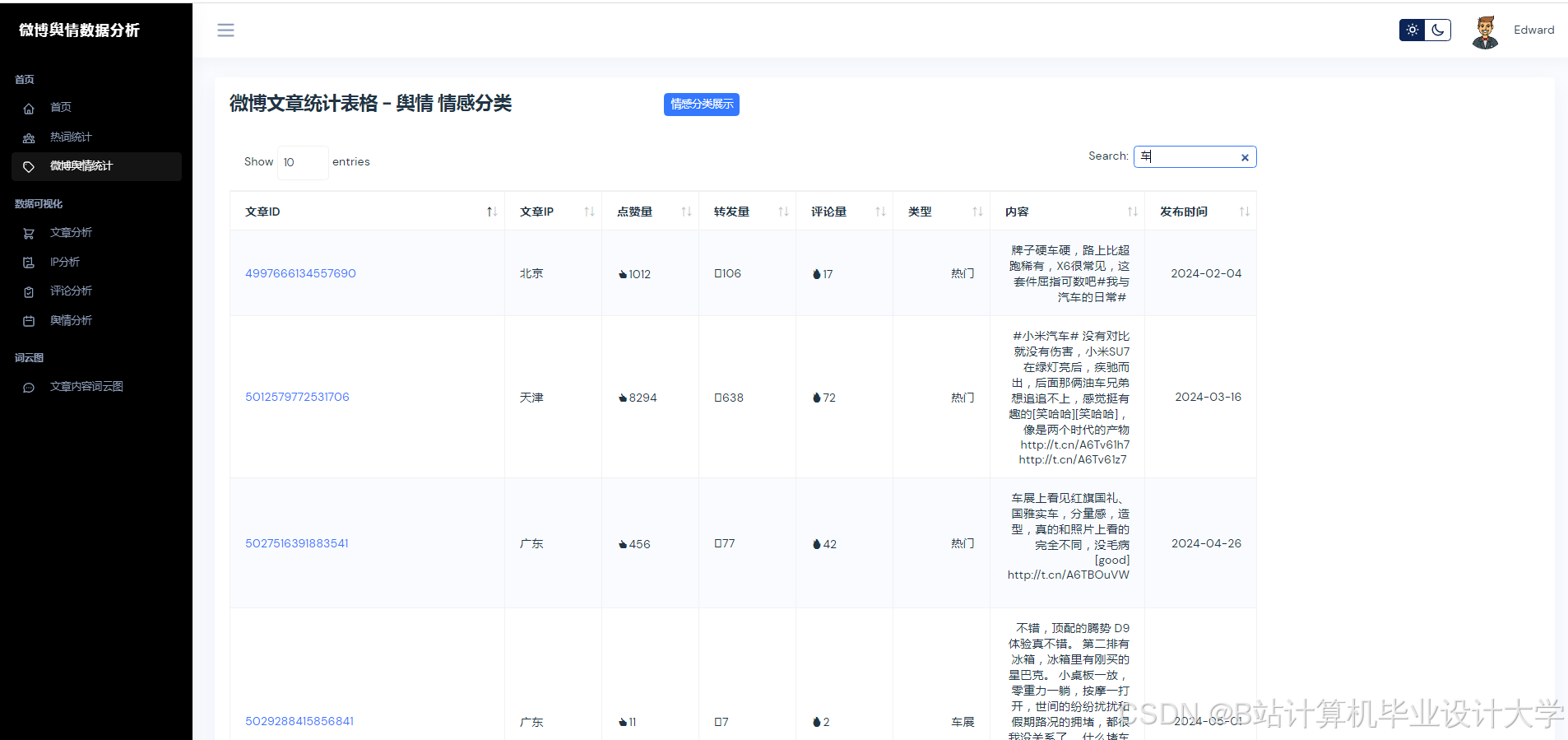
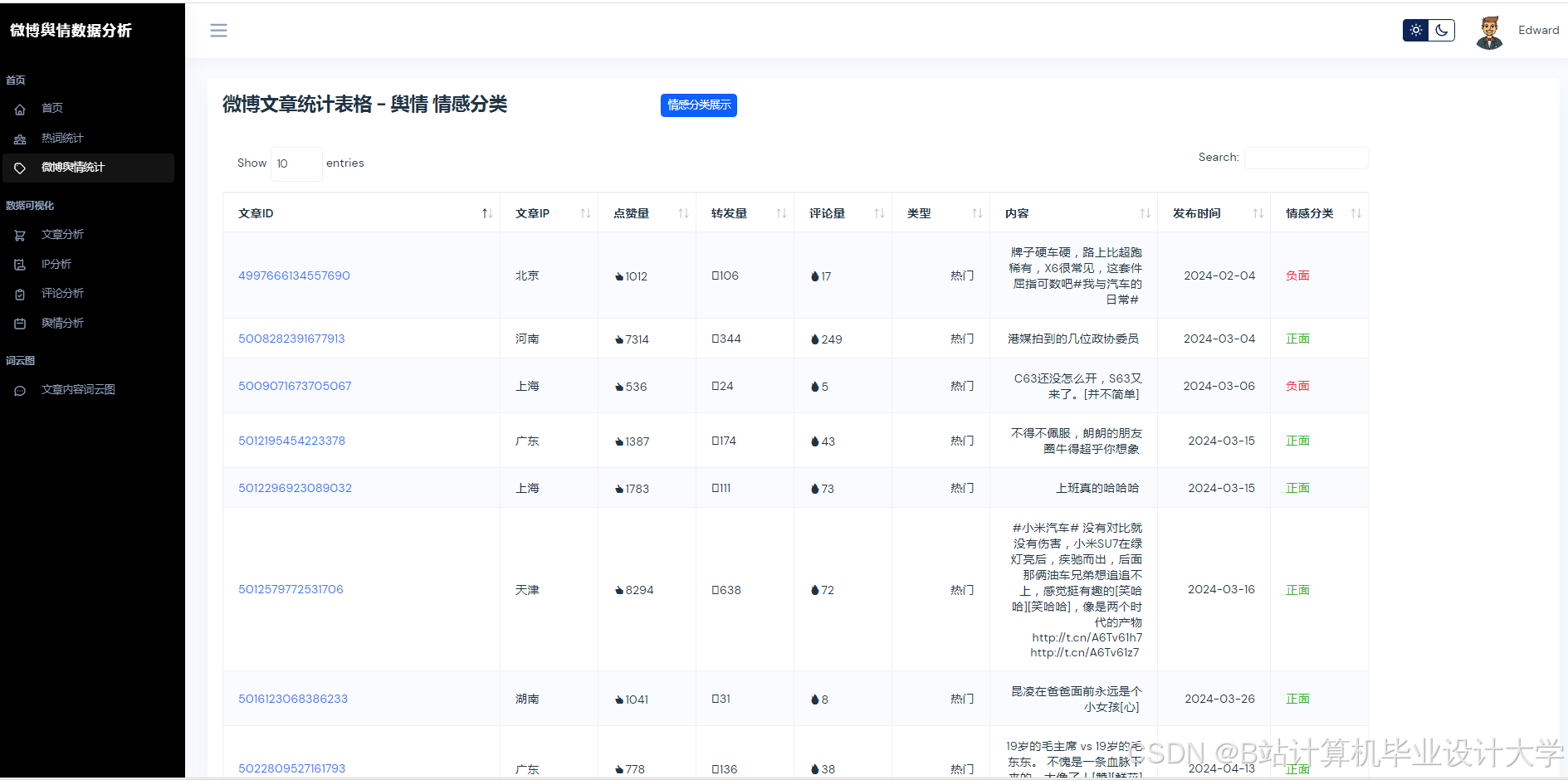
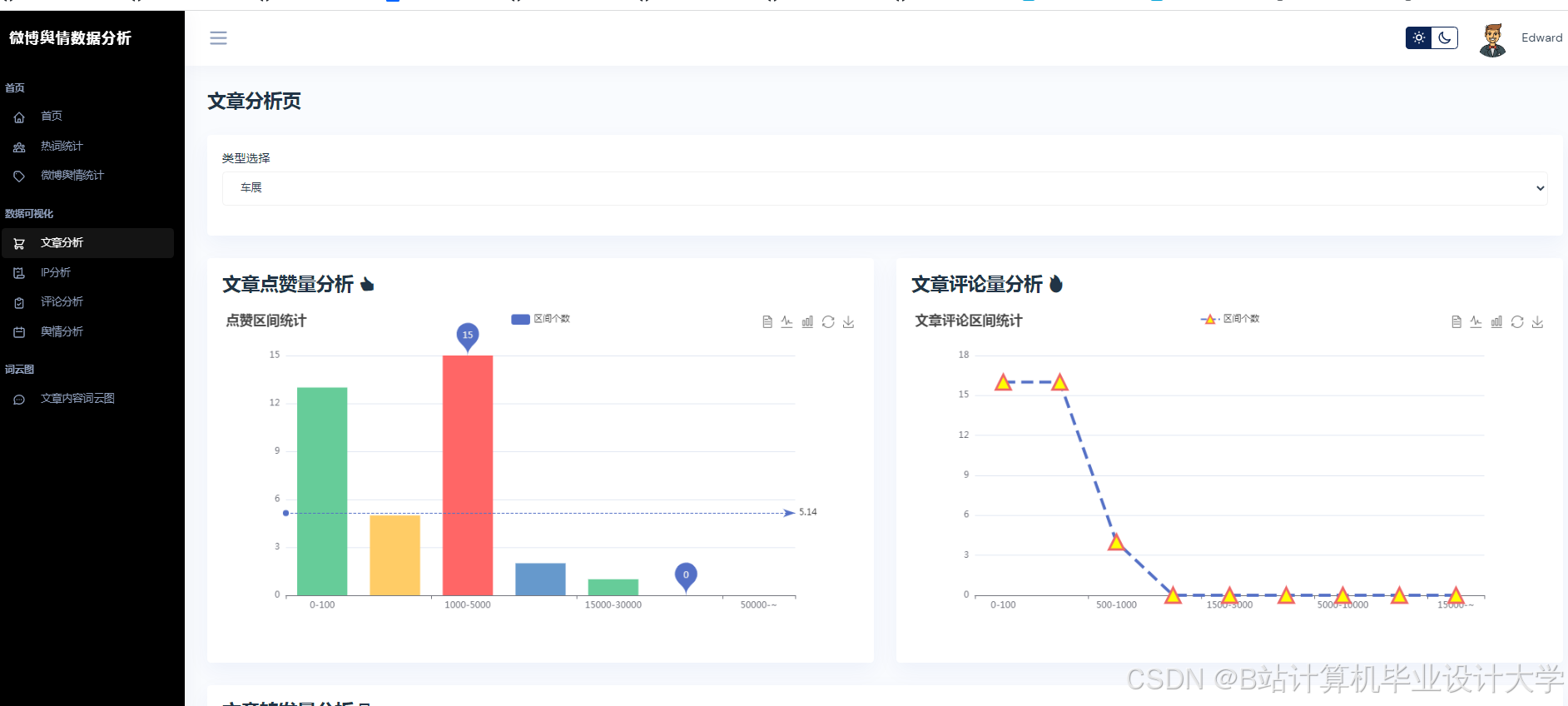
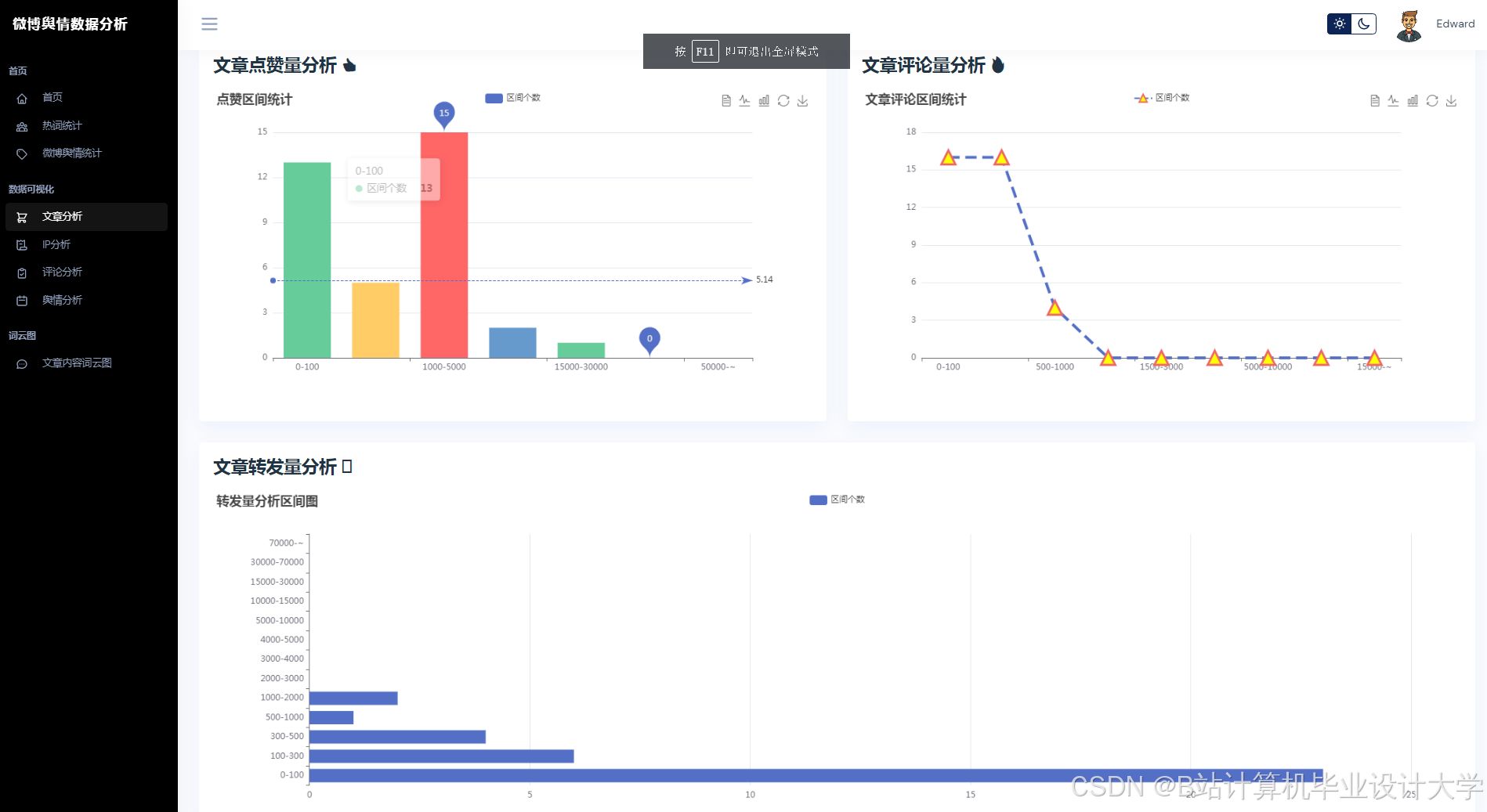
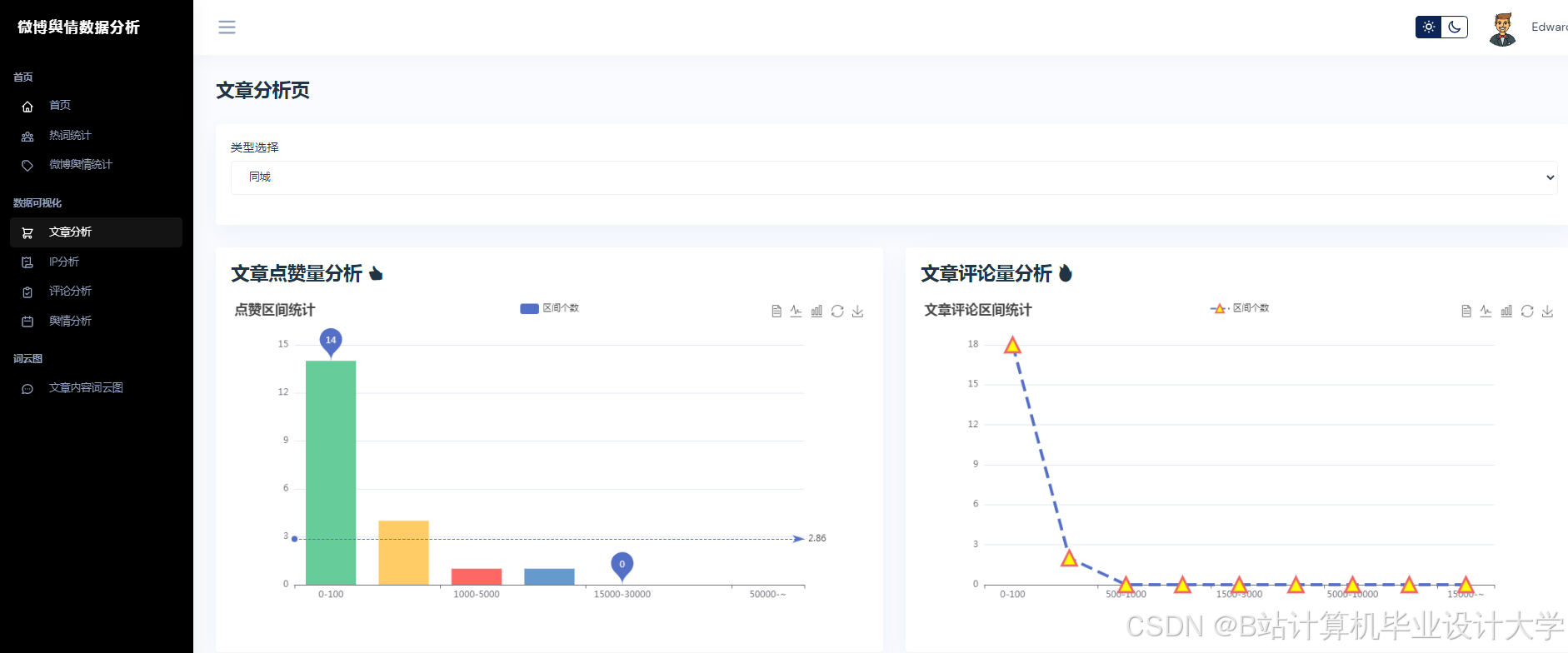
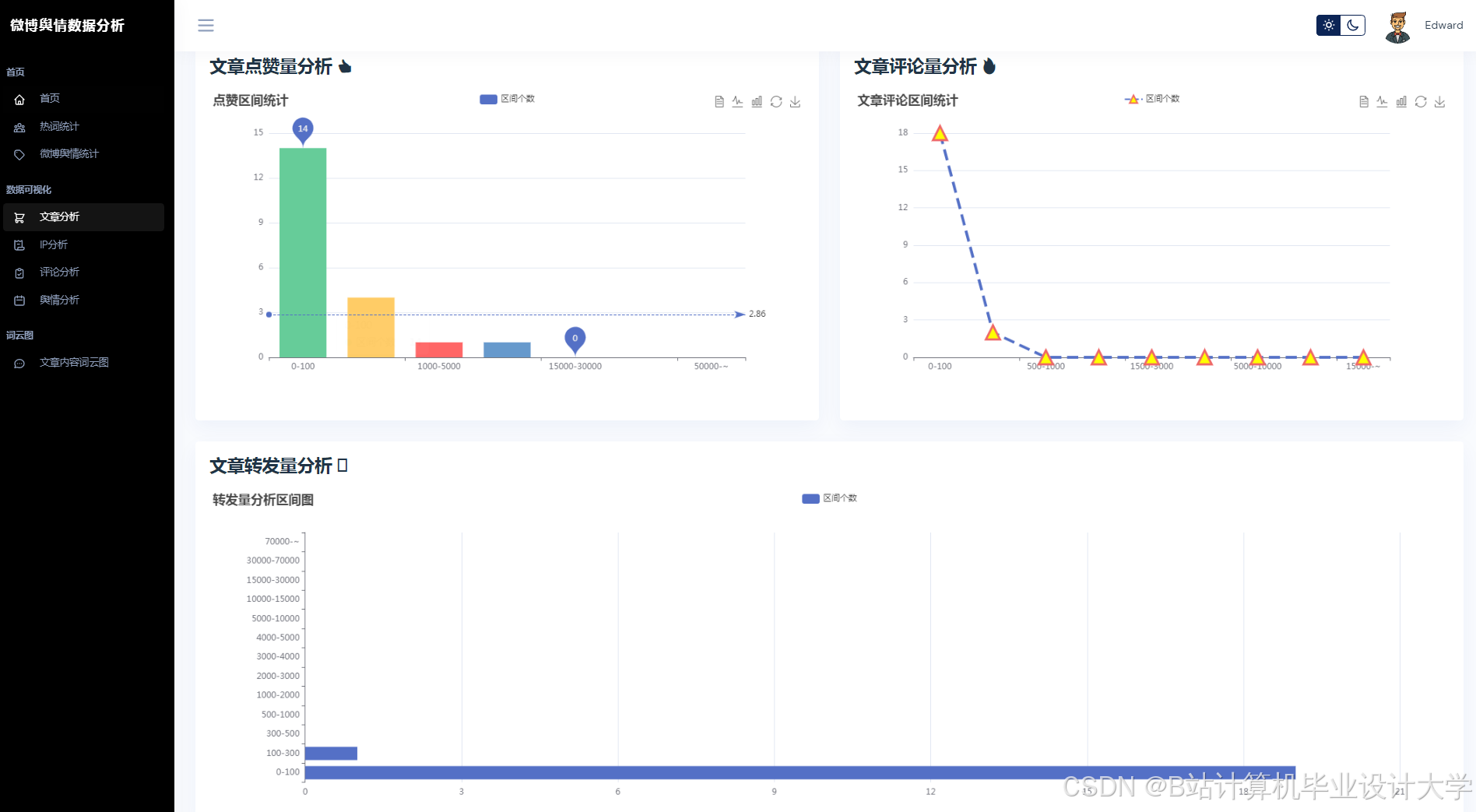



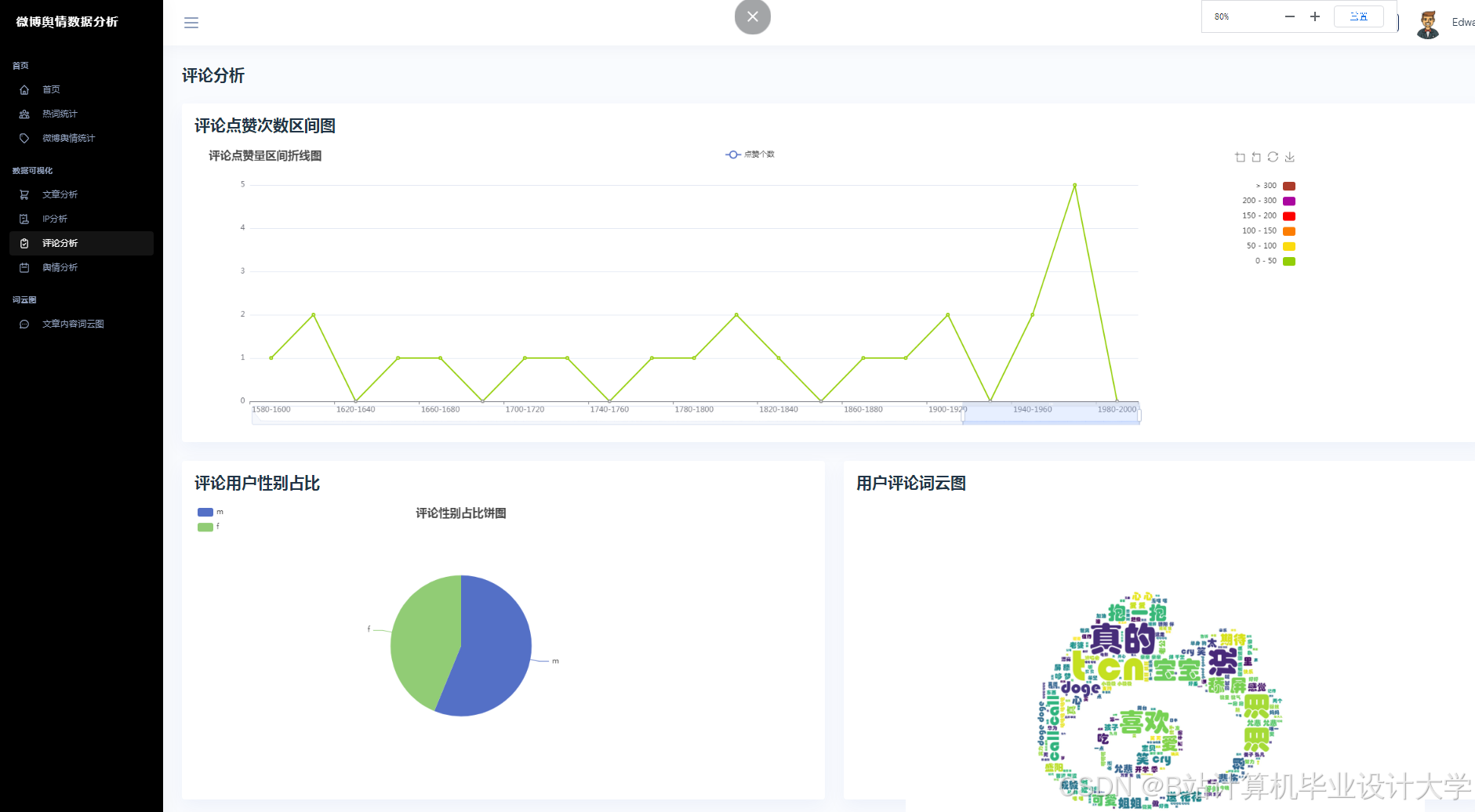


推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











