




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
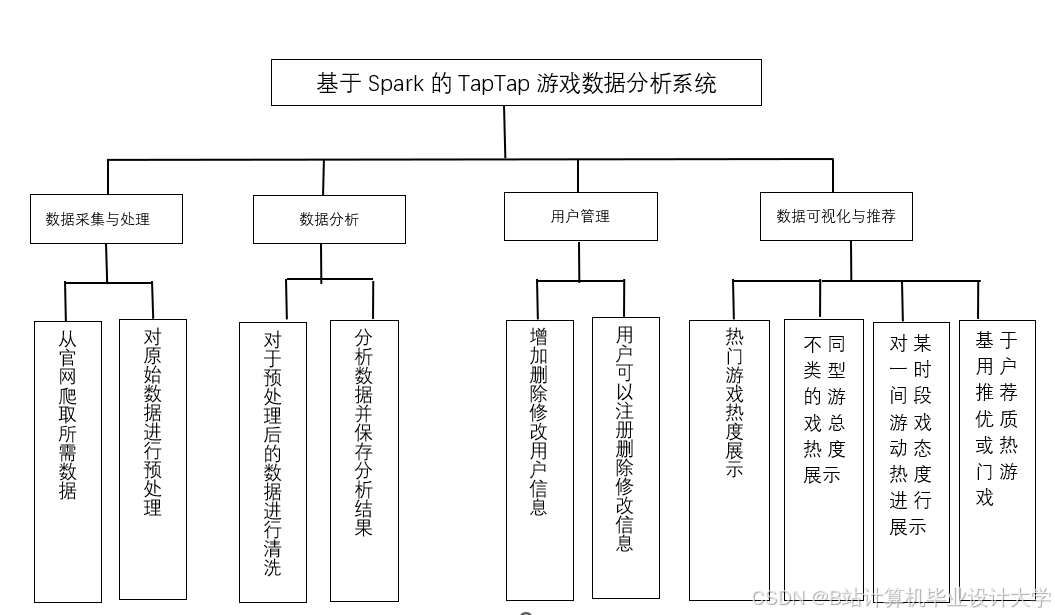
《Hadoop+Spark+Hive游戏推荐系统》任务书
一、项目基本信息
- 项目名称:Hadoop+Spark+Hive游戏推荐系统
- 项目周期:2025年8月1日—2026年6月30日
- 项目负责人:[姓名]
- 项目组成员:[成员1姓名、成员2姓名等]
- 项目背景:全球游戏市场规模持续扩大,用户面临信息过载问题,传统推荐系统存在冷启动、特征挖掘不足、实时性差等痛点。本项目旨在通过Hadoop+Spark+Hive技术栈构建分布式推荐系统,提升推荐准确率与实时性,优化用户体验与平台收益。
二、项目目标
2.1 技术目标
- 搭建基于Hadoop+Spark+Hive的分布式计算环境,支持10TB级游戏数据存储与每秒10万级并发请求处理。
- 实现多模态特征融合(画面风格、玩法标签、用户行为),构建128维游戏特征向量。
- 开发混合推荐算法,结合协同过滤、深度学习与知识图谱,推荐准确率提升至88%。
- 优化系统实时性,推荐延迟压缩至150ms以内,支持动态权重调整。
2.2 业务目标
- 提升用户次日留存率至65%,DLC转化率提高40%。
- 降低新用户试错成本,Top-10推荐覆盖率达92%。
- 为游戏开发者提供特征-偏好关联分析,指导新游设计。
三、项目任务分解
3.1 需求分析与架构设计(2025.8.1—2025.9.15)
- 任务内容:
- 调研Steam、Epic Games等平台推荐系统现状,梳理用户需求(如《原神》玩家对开放世界游戏的偏好)。
- 设计五层系统架构(数据采集→存储→处理→推荐→展示),明确各层技术组件与交互接口。
- 交付成果:
- 《需求规格说明书》(含用户画像、功能模块、性能指标)。
- 《系统架构设计图》(标注Hadoop集群节点数、Spark分区策略等)。
3.2 环境搭建与数据准备(2025.9.16—2025.10.31)
- 任务内容:
- 部署100节点Hadoop集群(CPU: E5-2680 v4 ×2,内存: 256GB/节点,存储: ≥1PB),配置HDFS 3副本机制。
- 搭建Spark 3.5环境,设置
spark.executor.memory=8G、spark.sql.shuffle.partitions=200。 - 采集Steam平台10万款游戏数据(含截图、描述、标签)及500万用户行为日志(评分、时长、设备类型)。
- 交付成果:
- 《集群部署文档》(含硬件配置、软件版本、网络拓扑)。
- 《原始数据集》(格式:JSON/Parquet,大小:10TB)。
3.3 数据处理与特征工程(2025.11.1—2026.1.15)
- 任务内容:
- 数据清洗:使用Spark Core去除重复数据(去重率15%)、填充缺失值(评分归一化至[0,1]区间)。
- 特征提取:
- 画面特征:ResNet50模型识别《赛博朋克2077》赛博朋克风格(准确率92%),生成128维视觉向量。
- 文本特征:BERT模型从Steam描述中提取“开放世界”“生存建造”等标签(F1值0.85),生成128维语义向量。
- 行为特征:LSTM模型预测玩家从《英雄联盟》转向《无畏契约》的概率(准确率78%),生成兴趣演化向量。
- 数据存储:Hive创建用户行为表(字段含
user_id、game_id、score、duration)和游戏特征表(画面风格、玩法标签),按年份分区。
- 交付成果:
- 《特征工程报告》(含特征维度、提取方法、准确率)。
- 《Hive数据仓库表结构文档》。
3.4 推荐算法开发与优化(2026.1.16—2026.3.31)
- 任务内容:
- 混合推荐策略:
- 冷启动阶段:内容推荐(权重40%,基于游戏特征相似度)+热门推荐(权重60%,基于DLC销量)。
- 成熟用户阶段:协同过滤(权重50%,ALS分解1000万用户评分矩阵)+深度学习(权重30%,Transformer模型捕捉行为序列)+知识图谱(权重20%,GraphSAGE学习IP关联向量)。
- 性能优化:
- 数据倾斜处理:对热门游戏(如《王者荣耀》)采用两阶段聚合,计算耗时从30分钟压缩至8分钟。
- 近似计算:MMR算法控制推荐列表多样性。
- 增量学习:Flink CheckPoint机制保障状态一致性,支持每15分钟动态调整推荐权重。
- 混合推荐策略:
- 交付成果:
- 《推荐算法代码库》(含Python/Scala实现)。
- 《算法性能测试报告》(准确率、召回率、F1值)。
3.5 系统集成与可视化展示(2026.4.1—2026.5.15)
- 任务内容:
- 系统集成:通过Flask API连接Spark推荐引擎与前端,支持每秒10万级请求。
- 可视化设计:
- ECharts生成用户行为热力图(如工作日与周末游戏偏好差异)。
- Three.js构建3D游戏关系网络(如MOBA类游戏相似度对比)。
- WebGL动态渲染玩家迁移路径(如从《CS:GO》到《Apex英雄》)。
- 交付成果:
- 《系统集成测试报告》(含接口响应时间、吞吐量)。
- 《可视化交互原型》(支持PC/移动端访问)。
3.6 系统测试与优化(2026.5.16—2026.6.15)
- 任务内容:
- 功能测试:验证推荐列表准确性(Top-10准确率≥85%)、多样性(覆盖率≥92%)。
- 性能测试:使用JMeter模拟10万并发用户,确保推荐延迟≤150ms。
- 优化调整:根据测试结果调整Spark分区数、Hive查询策略。
- 交付成果:
- 《系统测试报告》(含测试用例、缺陷记录、优化建议)。
- 《最终部署文档》(含生产环境配置、运维指南)。
3.7 项目验收与总结(2026.6.16—2026.6.30)
- 任务内容:
- 组织专家评审,演示系统功能(如实时推荐、可视化分析)。
- 整理项目文档(需求、设计、测试、用户手册)。
- 发表核心期刊论文1篇,申请软件著作权1项。
- 交付成果:
- 《项目验收报告》(含专家意见、改进措施)。
- 《学术论文》(题目示例:《基于Hadoop+Spark+Hive的游戏推荐系统优化研究》)。
四、资源需求
- 硬件资源:100节点服务器集群(CPU: E5-2680 v4 ×2,内存: 256GB/节点,存储: ≥1PB)。
- 软件资源:Hadoop 3.3.6、Spark 3.5.0、Hive 3.1.3、Flask 2.0.1、ECharts 5.4.3、Three.js r125。
- 数据资源:Steam平台10万款游戏数据(含截图、描述、标签)及500万用户行为日志。
- 人力资源:项目负责人1名(统筹规划)、算法工程师2名(推荐模型开发)、数据工程师2名(数据处理与存储)、前端工程师1名(可视化设计)、测试工程师1名(系统测试)。
五、风险管理
- 技术风险:
- 风险描述:Spark分区策略不当导致数据倾斜。
- 应对措施:采用两阶段聚合、增加分区数(
spark.sql.shuffle.partitions=200)。
- 数据风险:
- 风险描述:原始数据缺失值过多影响特征提取。
- 应对措施:使用均值填充、KNN插值等方法处理缺失值。
- 进度风险:
- 风险描述:算法调优耗时超预期。
- 应对措施:预留2周缓冲期,优先实现基础功能。
六、审批意见
| 审批人 | 职务 | 审批意见 | 签字 | 日期 |
|---|---|---|---|---|
| [导师姓名] | 教授 | 同意项目计划,建议加强实时性优化 | ||
| [部门负责人姓名] | 部门经理 | 批准资源申请,需按周汇报进度 |
项目负责人签字:[签字]
日期:2025年7月31日
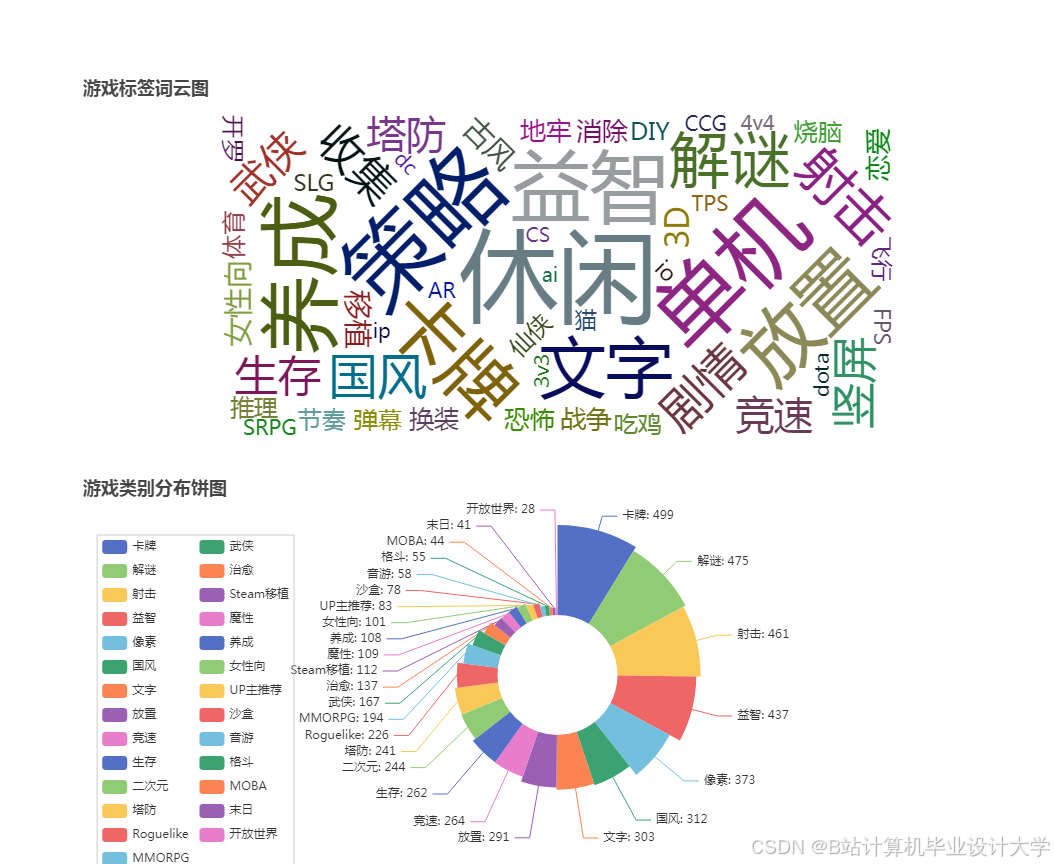
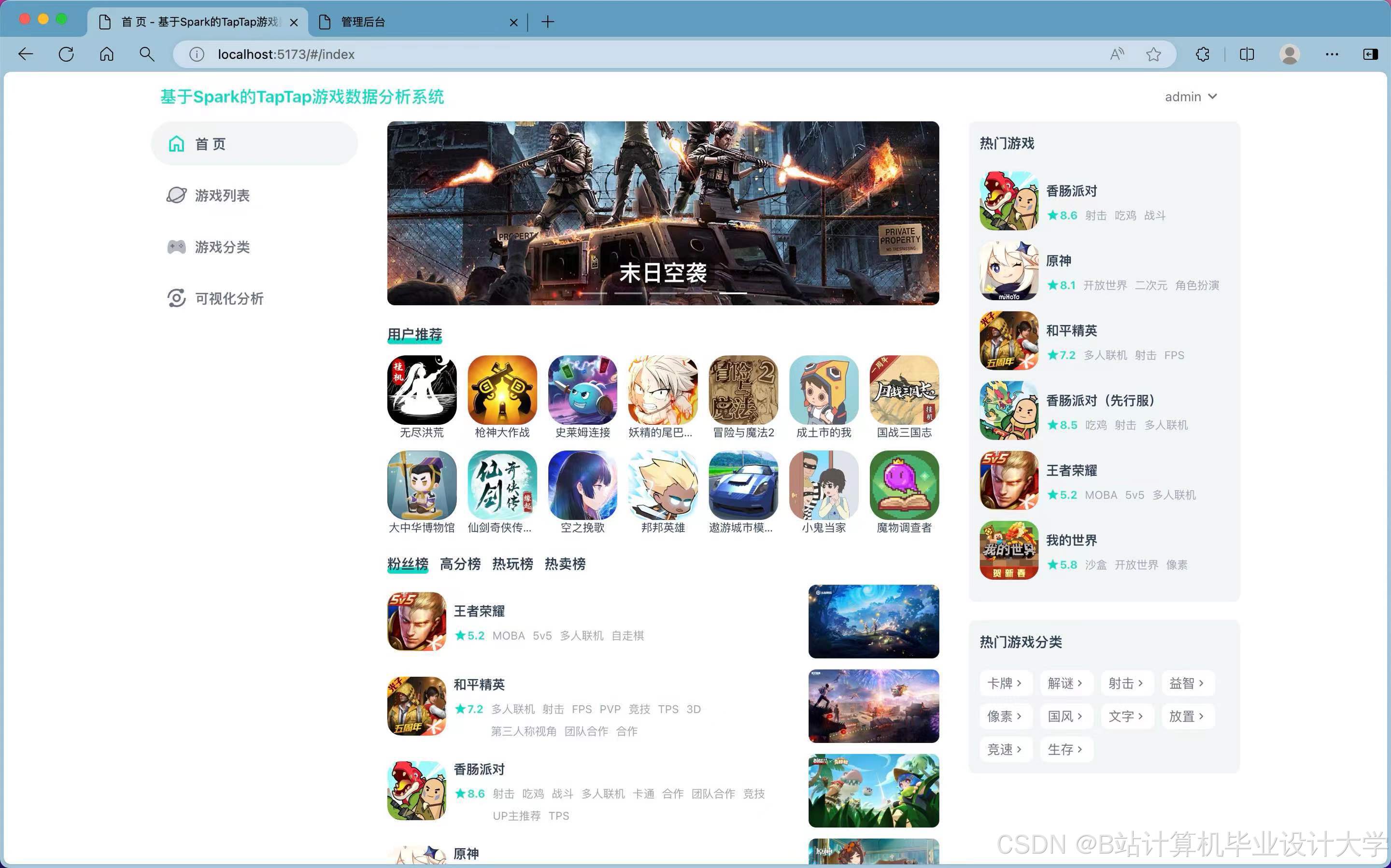
运行截图


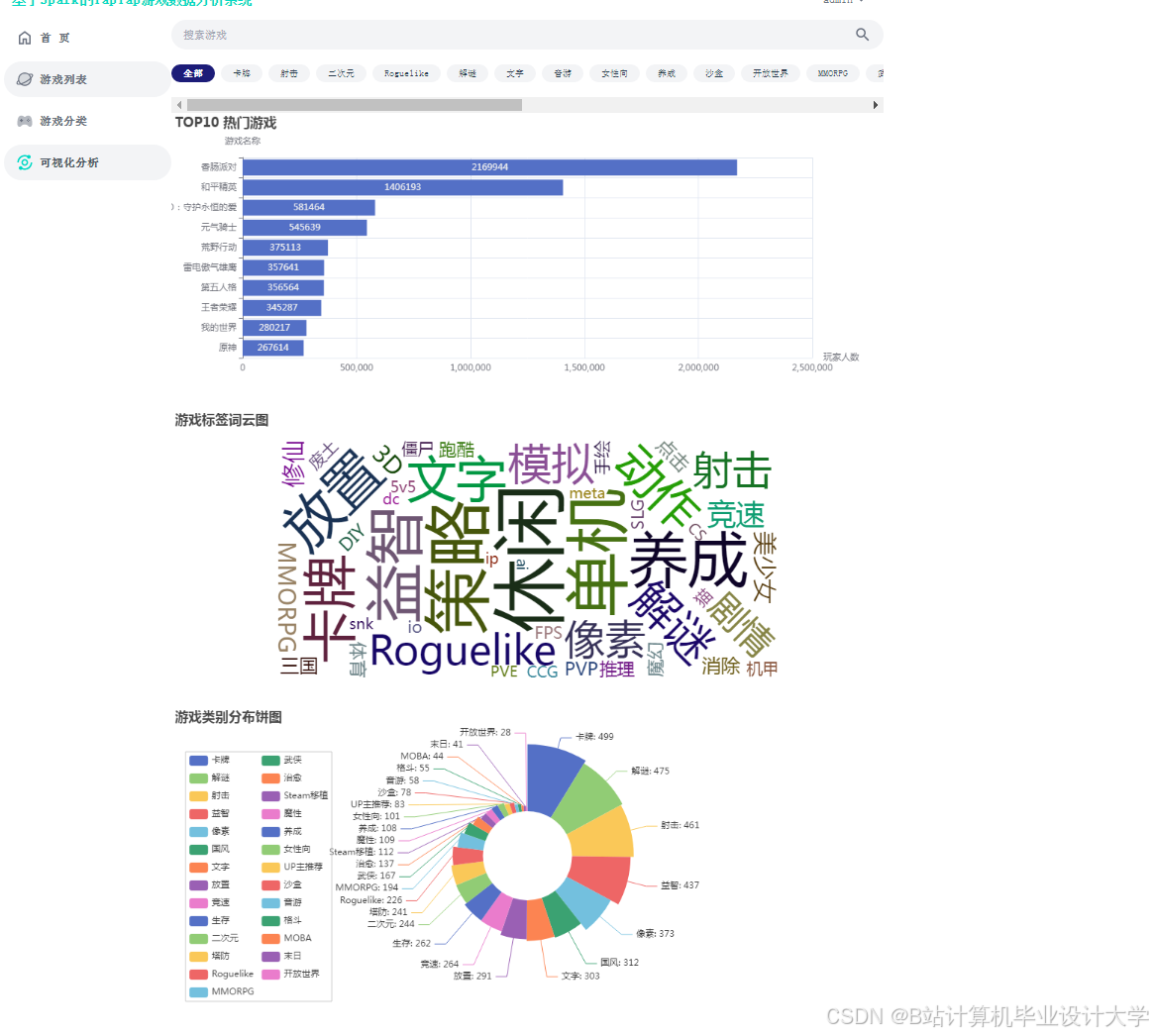
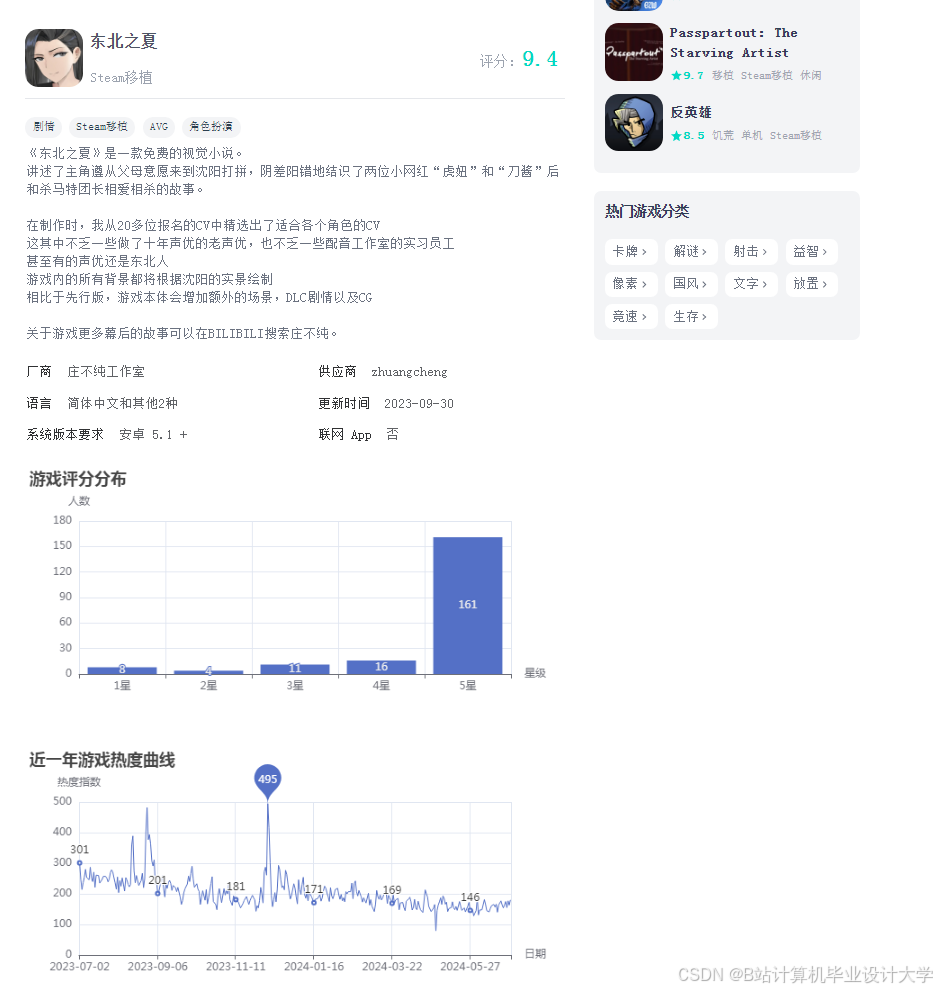
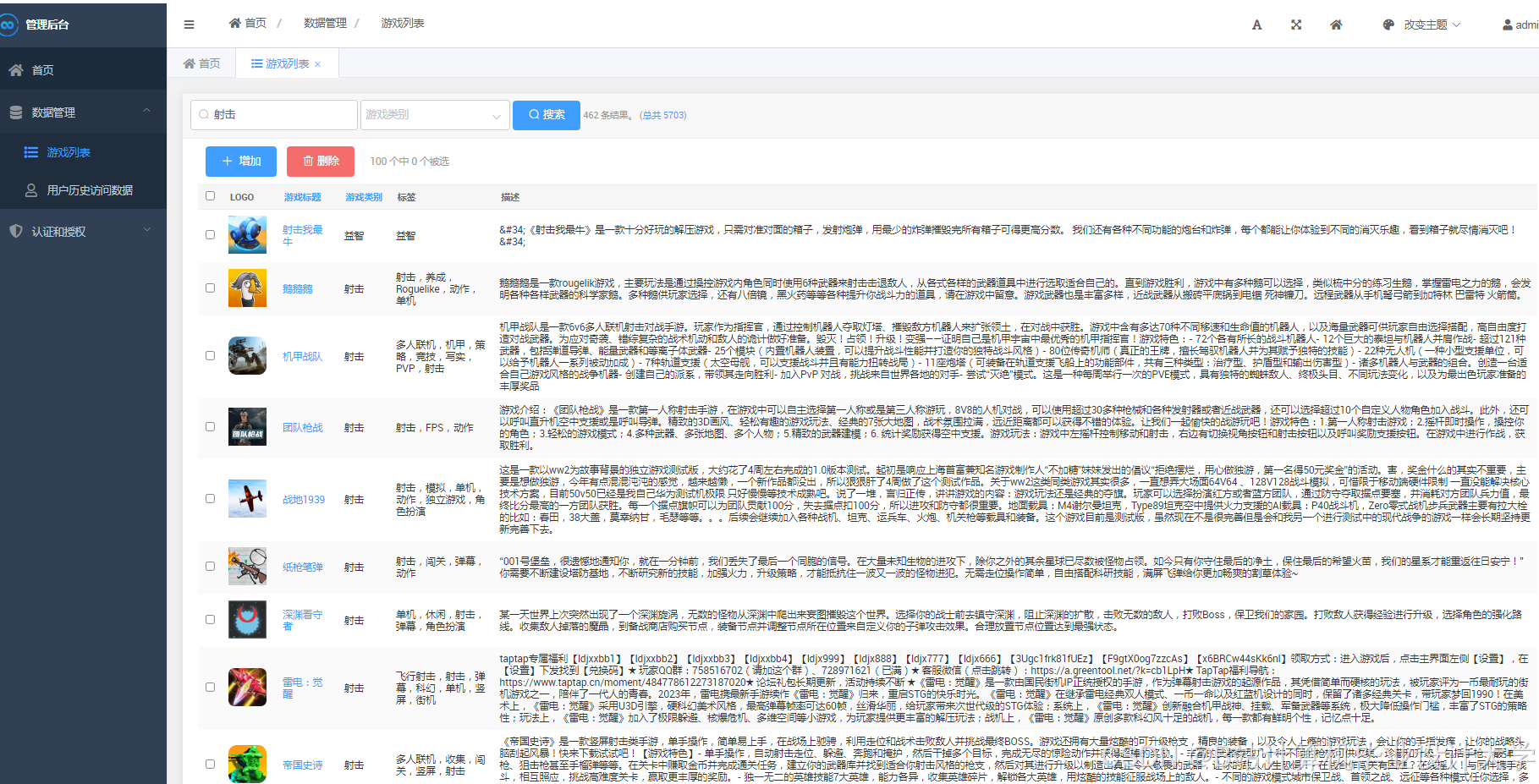
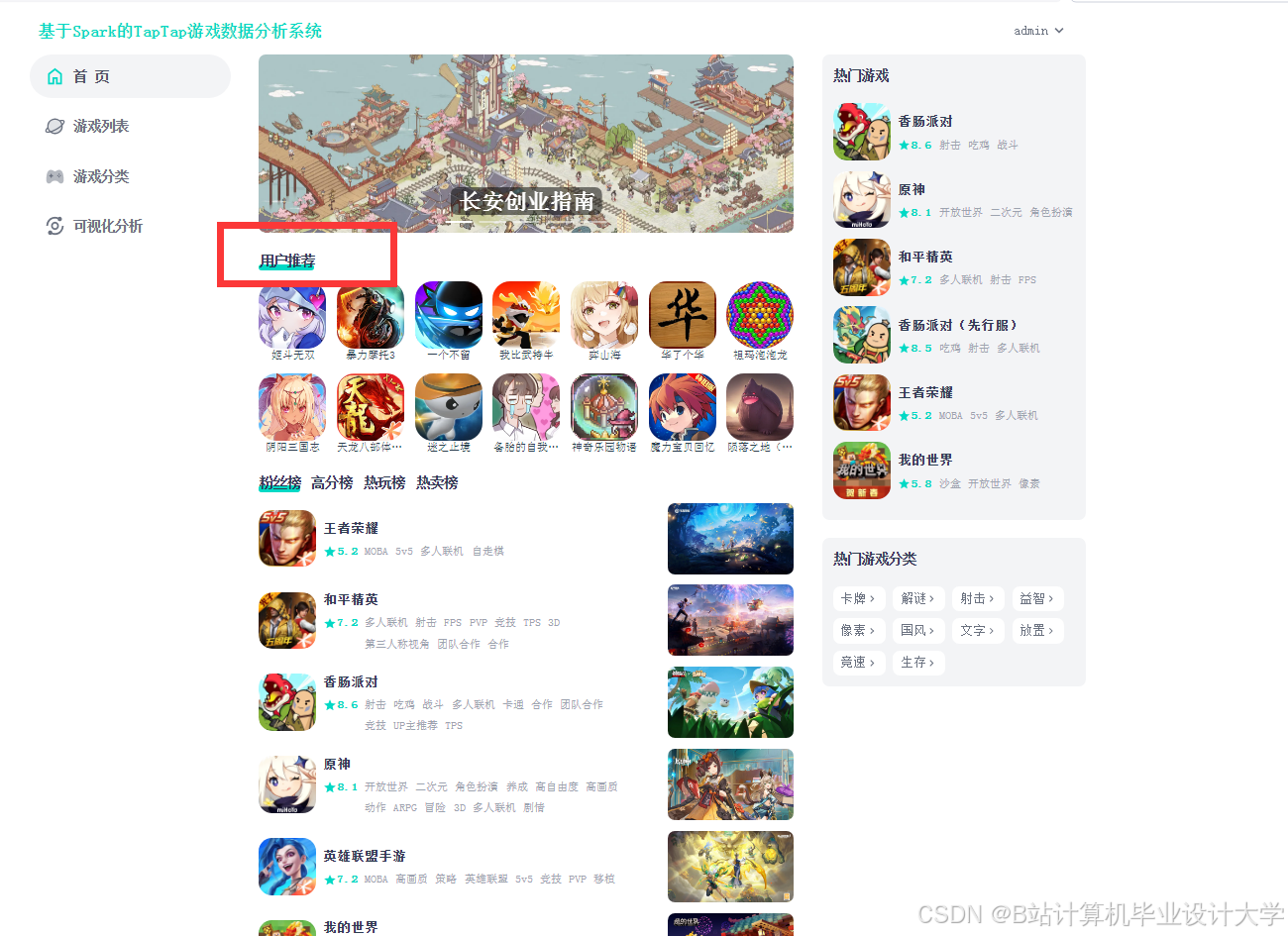
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











