




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
任务书:基于Python+PySpark+Hadoop的高考分数线预测与志愿推荐系统开发
一、任务背景
高考是中国教育体系的核心环节,每年涉及超千万考生及家庭。传统志愿填报依赖人工查阅资料、经验咨询或简单统计模型,存在信息过载、匹配误差大、数据孤岛等问题。随着大数据与人工智能技术的发展,构建智能化高考推荐系统成为提升填报效率与录取满意度的关键需求。本任务旨在开发一套基于Python+PySpark+Hadoop的高考分数线预测与志愿推荐系统,整合多源异构数据,通过分布式计算与机器学习算法实现精准预测与个性化推荐。
二、任务目标
- 数据整合与存储:构建PB级高考数据仓库,整合教育部招生数据、高校官网信息、考生行为数据等,支持结构化与非结构化数据的高效存储。
- 分数线精准预测:采用LSTM+XGBoost集成模型,将预测误差率控制在3%以内,支持按省份、批次、院校类型等多维度预测。
- 个性化志愿推荐:结合协同过滤与内容推荐算法,生成Top-10推荐命中率≥85%的志愿方案,支持考生输入分数、地域、专业偏好等条件实时推荐。
- 分布式计算优化:通过PySpark内存管理与HDFS分区存储,实现千万级考生数据实时处理,响应时间≤100ms。
- 可视化交互平台:开发Web端系统,提供分数线趋势图、专业热度排行榜、推荐结果对比等可视化功能,提升用户体验。
三、任务内容与分工
1. 数据采集与预处理(负责人:数据组)
- 任务内容:
- 爬取教育部招生计划、历年分数线、高校学科评估结果等结构化数据;
- 采集高校官网专业描述、社交媒体情绪数据(如微博话题热度)等非结构化数据;
- 清洗数据(去重、填充缺失值、异常值处理),构建统一数据格式。
- 技术工具:
- Python(Requests、BeautifulSoup爬虫库);
- PySpark(数据清洗、去重、异常值检测)。
2. 分布式存储与计算优化(负责人:架构组)
- 任务内容:
- 搭建Hadoop集群,按年份、省份对数据进行分区存储(如
/data/2024/zhejiang/candidates.csv); - 优化PySpark任务配置(并行度、内存管理),提升ALS矩阵分解与XGBoost训练效率;
- 实现数据冷热分层存储,历史数据归档至HDFS,热数据缓存至Redis。
- 搭建Hadoop集群,按年份、省份对数据进行分区存储(如
- 技术工具:
- Hadoop HDFS(分布式存储);
- PySpark(分布式计算);
- Redis(缓存加速)。
3. 特征工程与模型构建(负责人:算法组)
- 任务内容:
- 提取考生特征(成绩等级、兴趣类别、职业规划)、院校特征(地理位置、学科实力、就业率)、动态特征(实时填报热度、政策变动系数);
- 构建LSTM+XGBoost集成模型预测分数线,通过Stacking框架融合预测结果;
- 开发混合推荐算法,融合ALS协同过滤与TF-IDF内容推荐,引入知识图谱嵌入(KGE)技术丰富特征。
- 技术工具:
- Python(Scikit-learn、XGBoost、TensorFlow/Keras);
- PySpark MLlib(ALS协同过滤)。
4. 系统开发与测试(负责人:开发组)
- 任务内容:
- 基于Flask框架开发后端API,支持前端调用推荐结果与可视化数据;
- 使用Vue.js构建响应式前端界面,集成ECharts实现分数线趋势图、专业热度排行榜等可视化功能;
- 通过JMeter进行压力测试,确保系统支持1000+并发请求,响应时间≤100ms。
- 技术工具:
- Python Flask(后端服务);
- Vue.js + ECharts(前端可视化);
- JMeter(性能测试)。
5. 部署与运维(负责人:运维组)
- 任务内容:
- 部署系统至阿里云ECS集群,配置负载均衡(Nginx)与自动扩缩容(Kubernetes);
- 监控系统运行状态(Prometheus+Grafana),设置异常报警(如预测误差率>5%时触发邮件通知);
- 定期更新数据(如每日同步教育部最新招生计划),优化模型参数(每月重新训练XGBoost模型)。
- 技术工具:
- 阿里云ECS(服务器部署);
- Kubernetes(容器编排);
- Prometheus+Grafana(监控告警)。
四、时间计划
| 阶段 | 时间 | 任务 |
|---|---|---|
| 需求分析 | 2025.08-2025.09 | 调研高考填报痛点,明确系统功能需求(如预测精度、推荐维度、可视化类型)。 |
| 数据采集 | 2025.10-2025.11 | 完成教育部、高校官网、社交媒体等数据爬取,存储至HDFS初步数据仓库。 |
| 模型开发 | 2025.12-2026.02 | 训练LSTM+XGBoost分数线预测模型,优化混合推荐算法,测试预测误差率与推荐命中率。 |
| 系统开发 | 2026.03-2026.04 | 完成Flask后端与Vue.js前端开发,集成ECharts可视化,实现端到端功能联调。 |
| 测试优化 | 2026.05-2026.06 | 进行压力测试、用户满意度调查,修复系统漏洞,优化模型参数与界面交互。 |
| 部署上线 | 2026.07-2026.08 | 部署系统至生产环境,编写用户手册与运维文档,准备项目验收与成果展示。 |
五、预期成果
- 系统原型:可交互的Web端高考推荐平台,支持考生输入条件实时生成志愿方案与可视化分析。
- 算法模型:LSTM+XGBoost分数线预测模型与混合推荐算法,申请发明专利《一种基于多源异构数据的高考志愿填报推荐方法》。
- 技术文档:系统设计说明书、数据字典、API接口文档、运维手册。
- 学术论文:发表核心期刊论文《基于大数据技术的高考志愿推荐系统设计与实现》,重点阐述混合推荐模型与分布式架构优化。
六、风险评估与应对
| 风险 | 应对措施 |
|---|---|
| 数据采集被反爬虫机制拦截 | 采用代理IP池、模拟浏览器行为(Selenium)、遵守目标网站robots.txt协议。 |
| 模型预测误差率过高 | 增加特征维度(如引入考生家庭背景、高中成绩波动),调整LSTM层数与XGBoost参数。 |
| 系统并发性能不足 | 优化PySpark任务并行度,启用Redis缓存热数据,升级阿里云服务器配置。 |
| 用户隐私数据泄露风险 | 对考生敏感信息(如身份证号、联系方式)进行脱敏处理,遵守《个人信息保护法》。 |
任务负责人签字:____________________
日期:____________________
运行截图

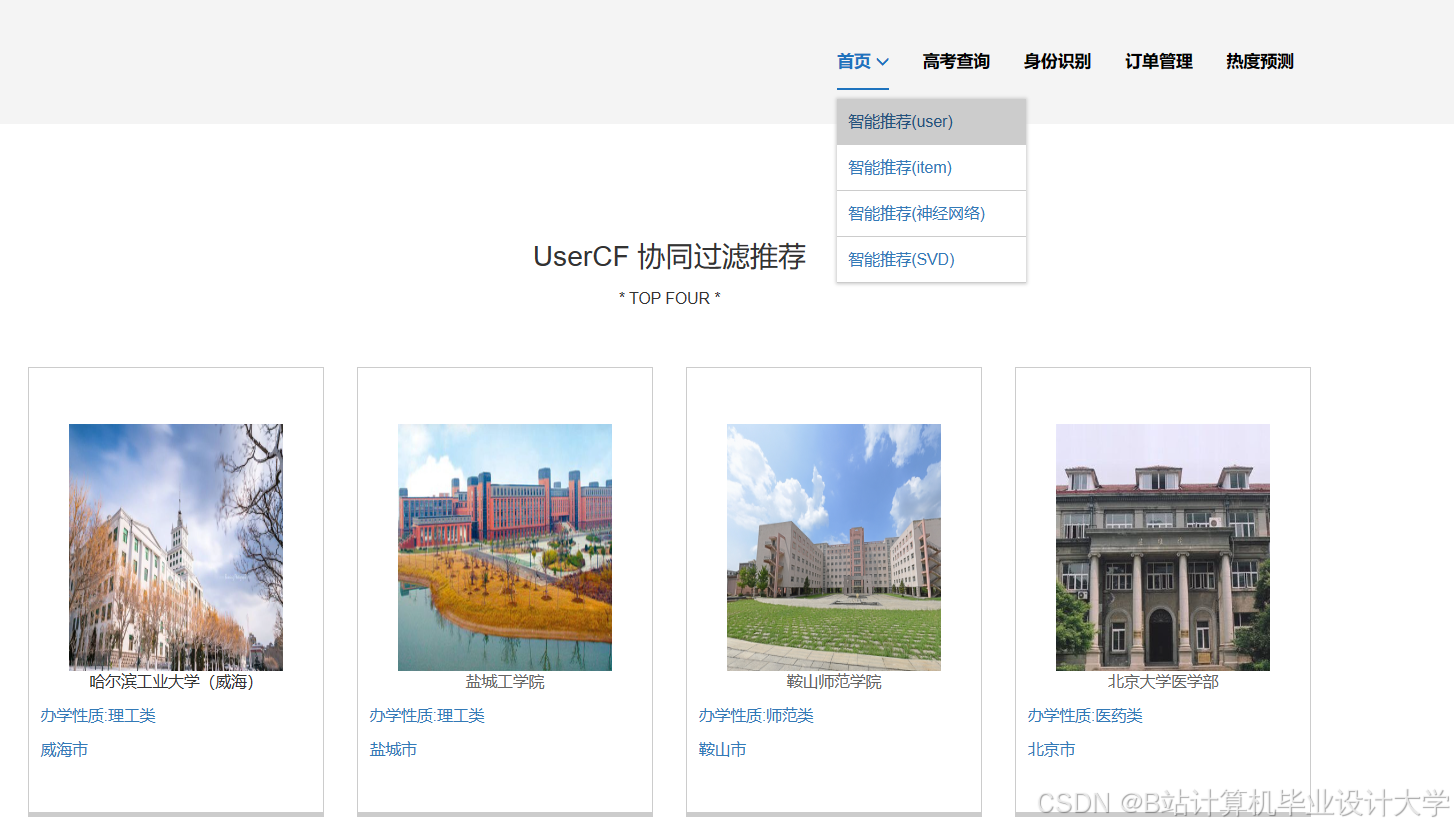
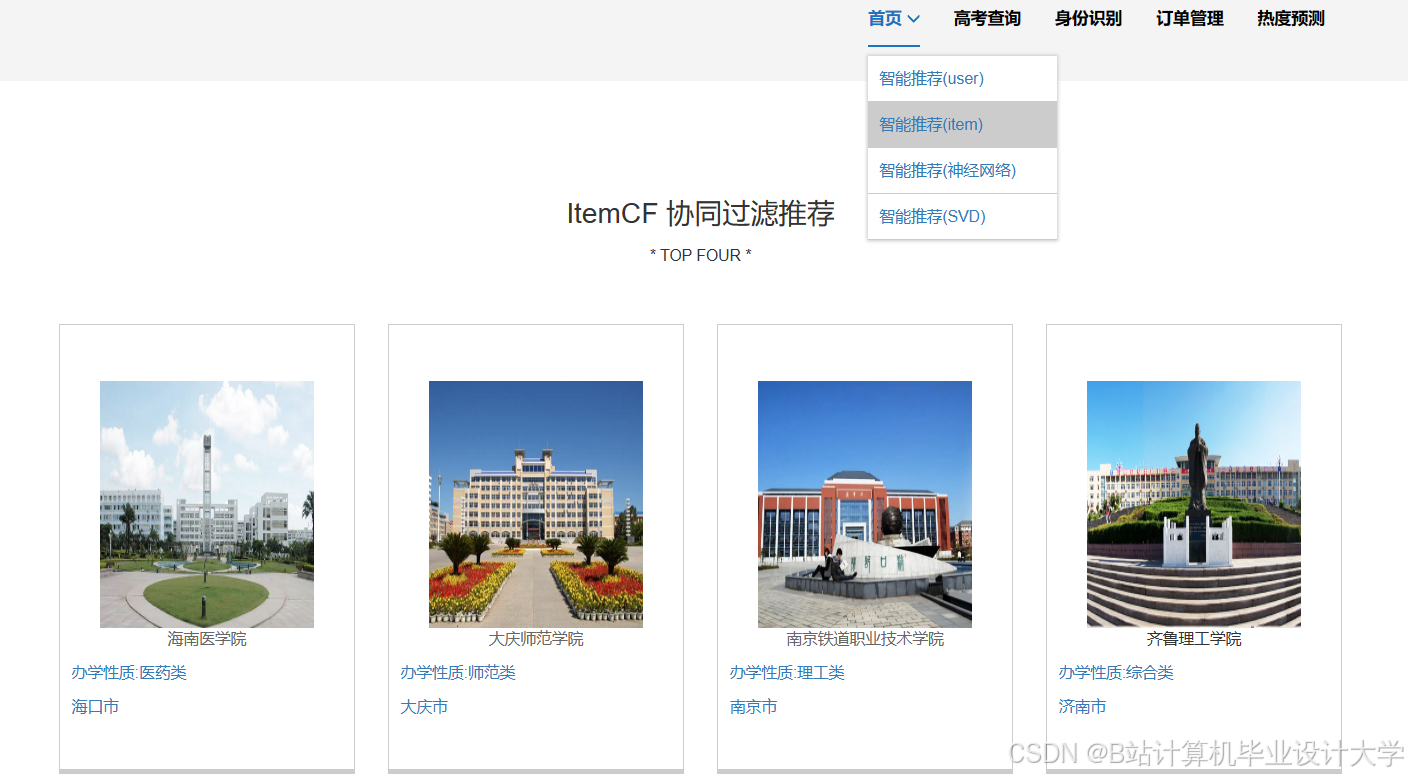
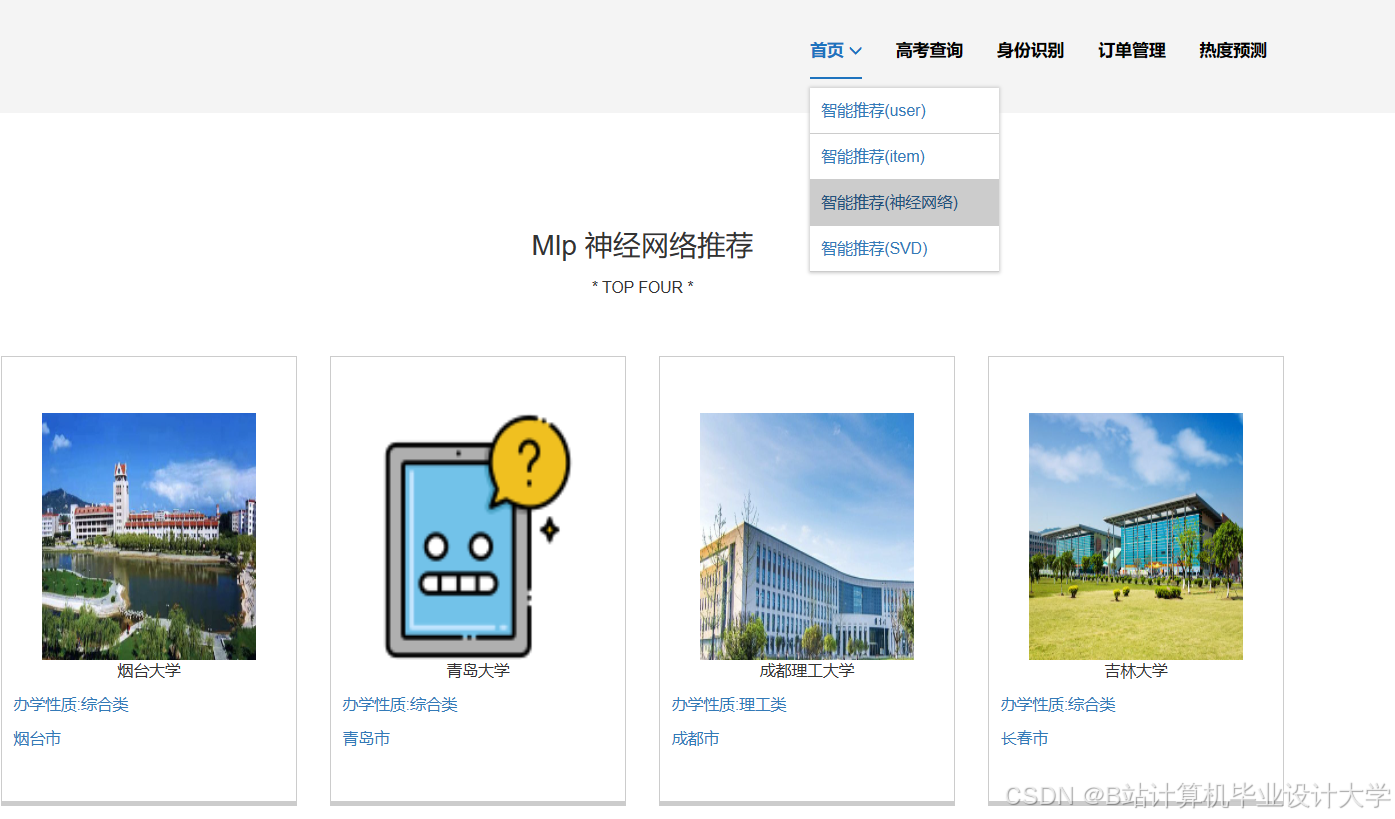
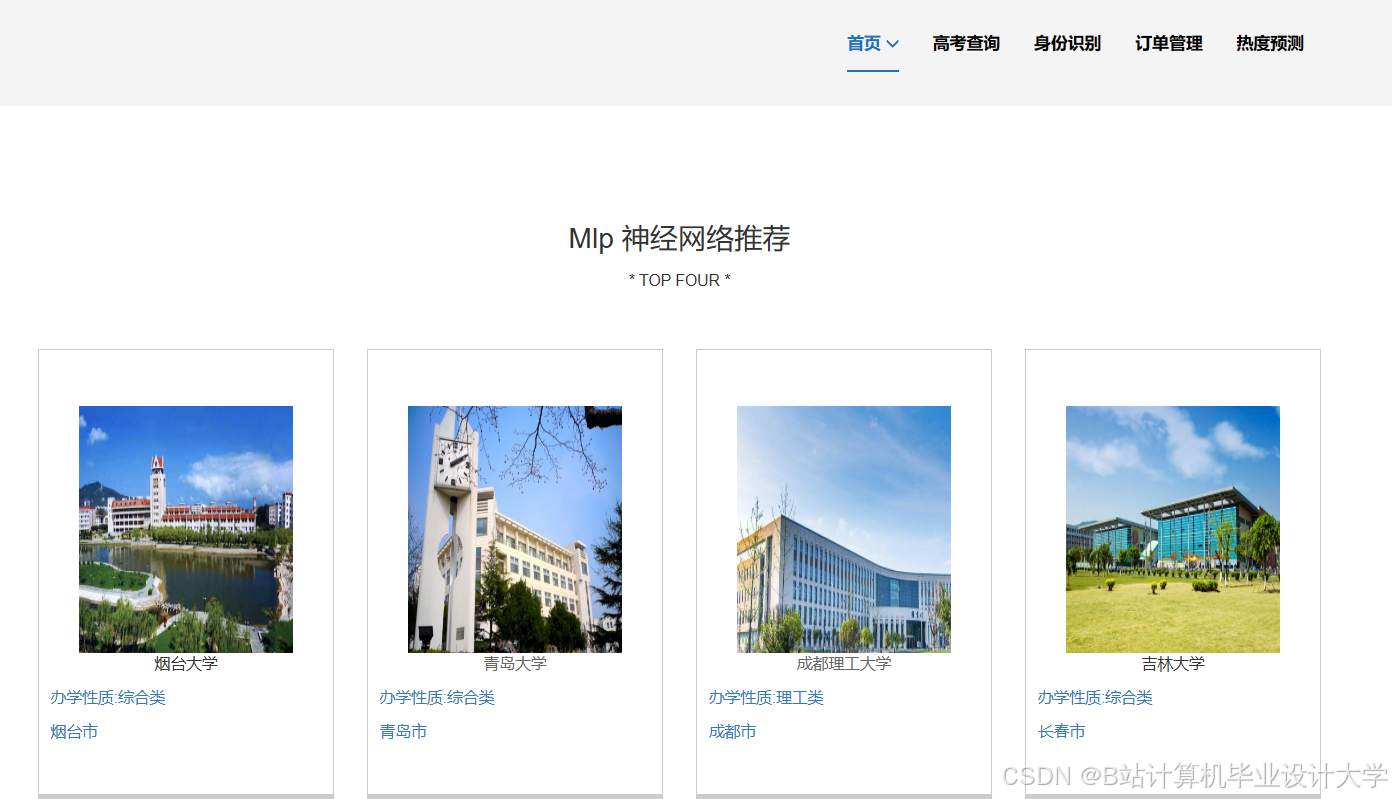
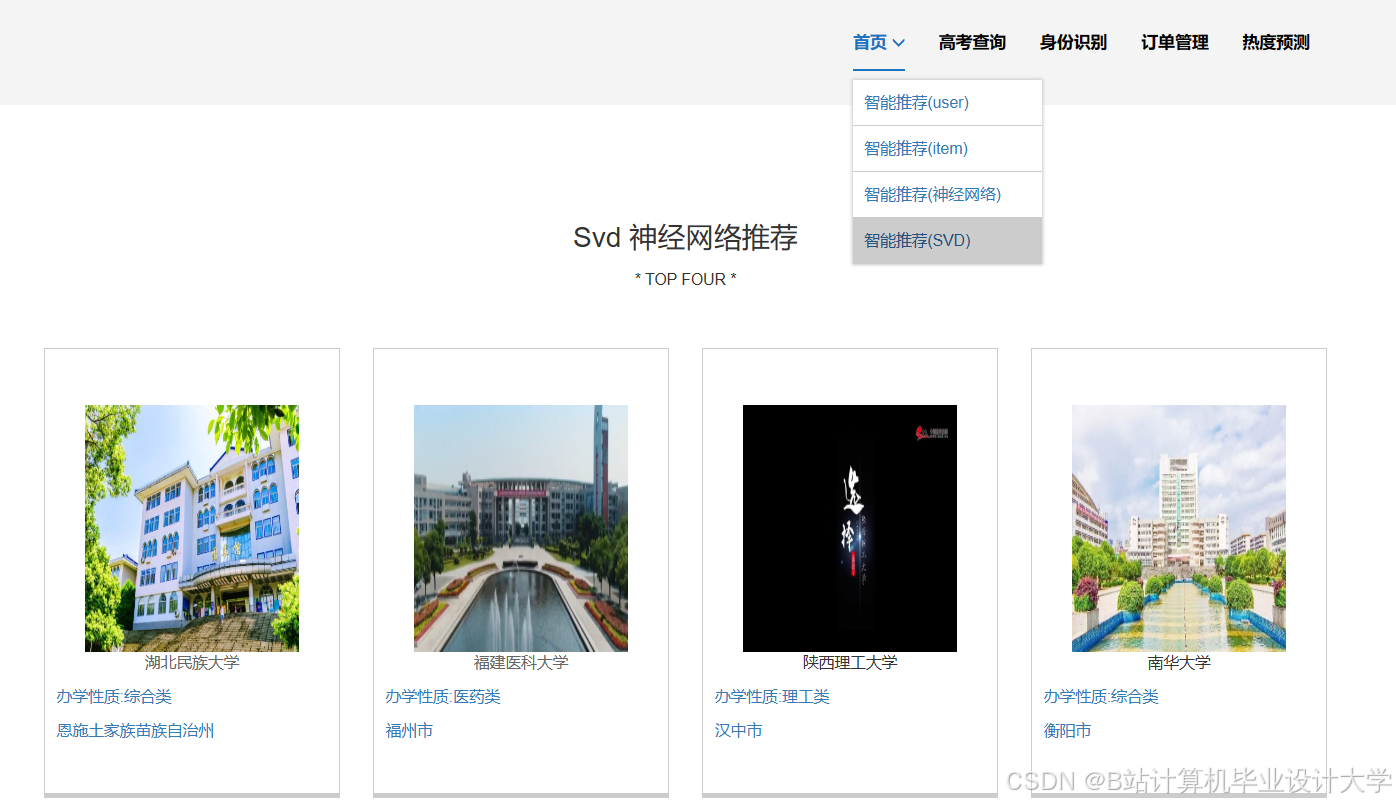
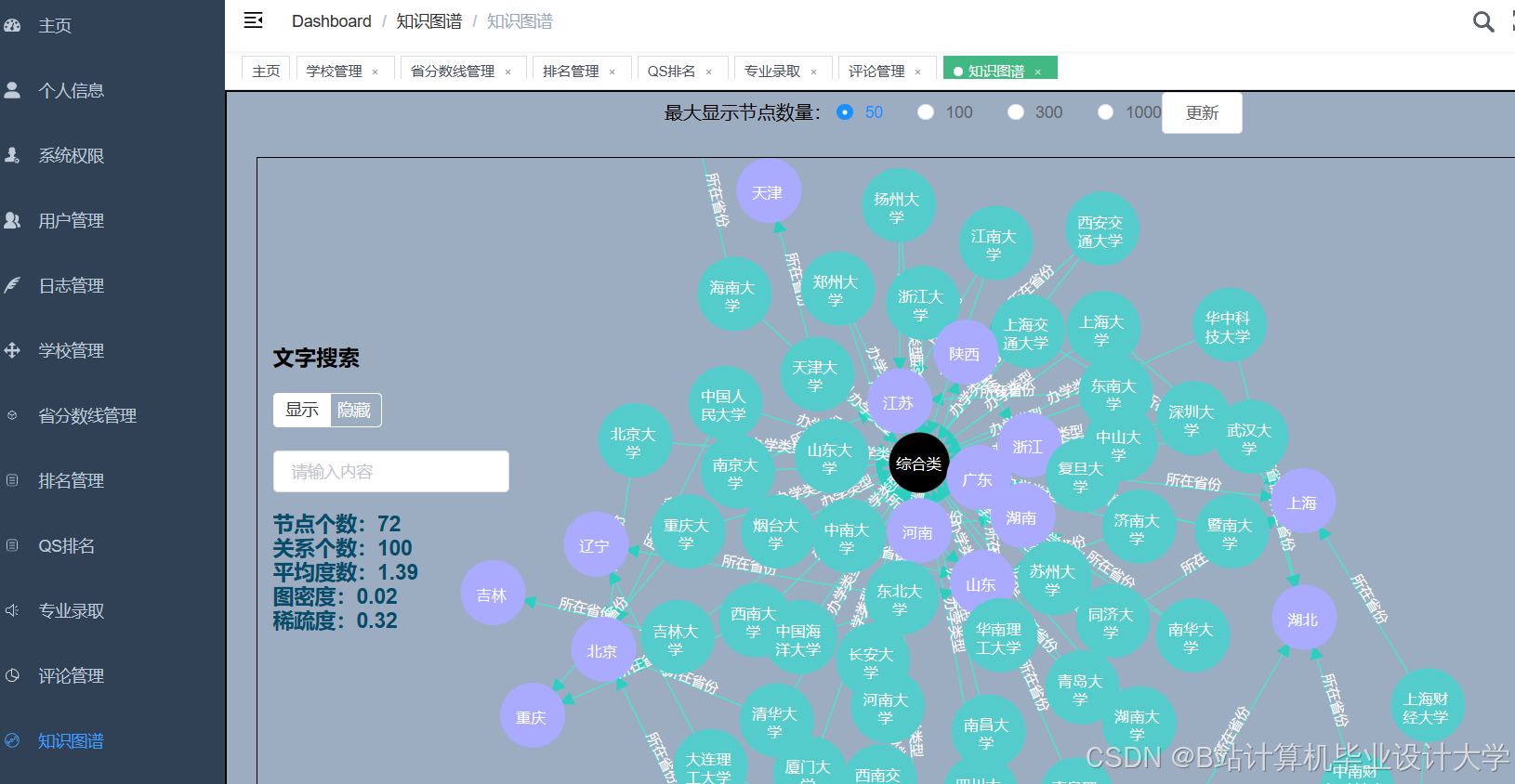
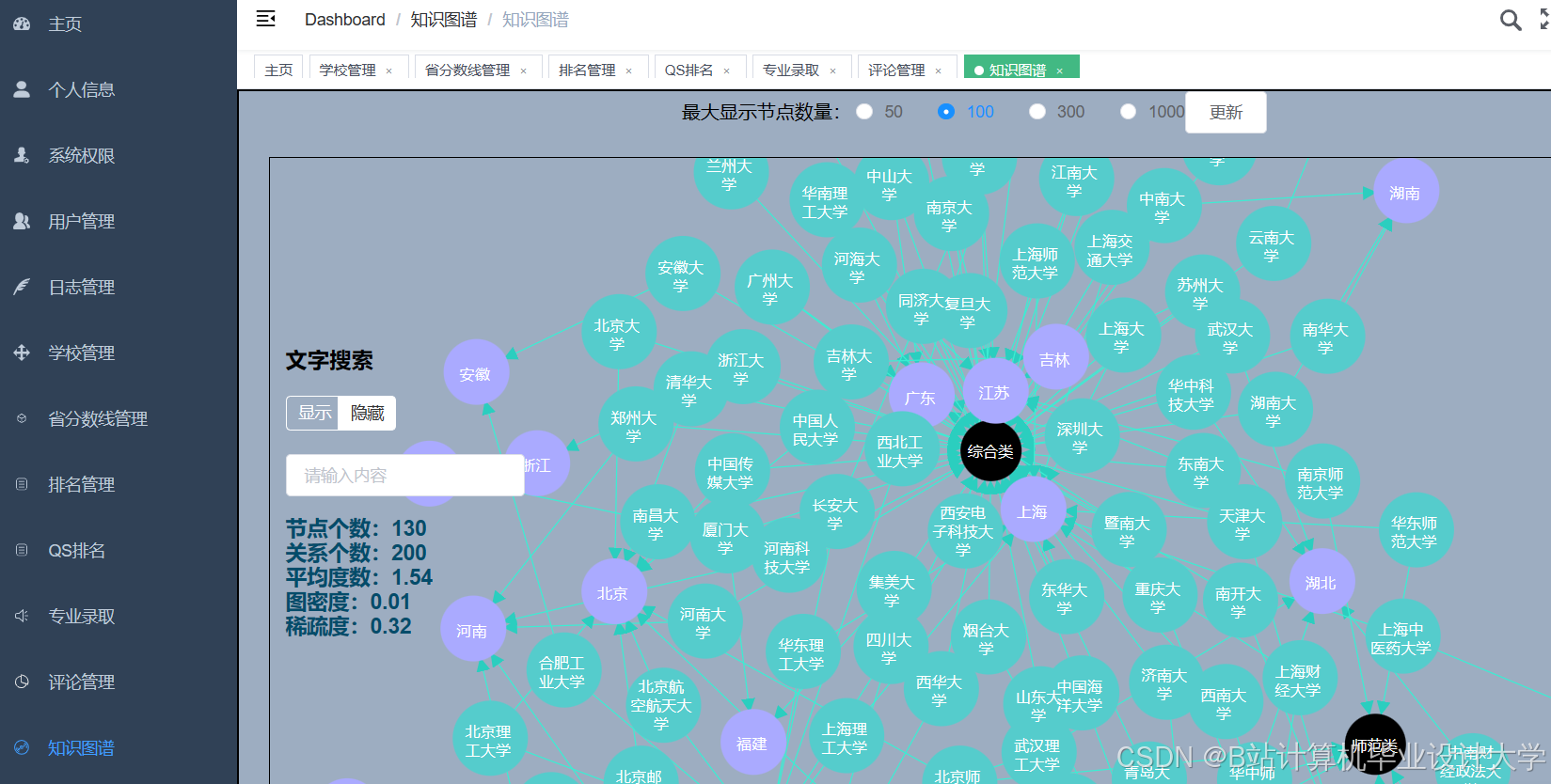
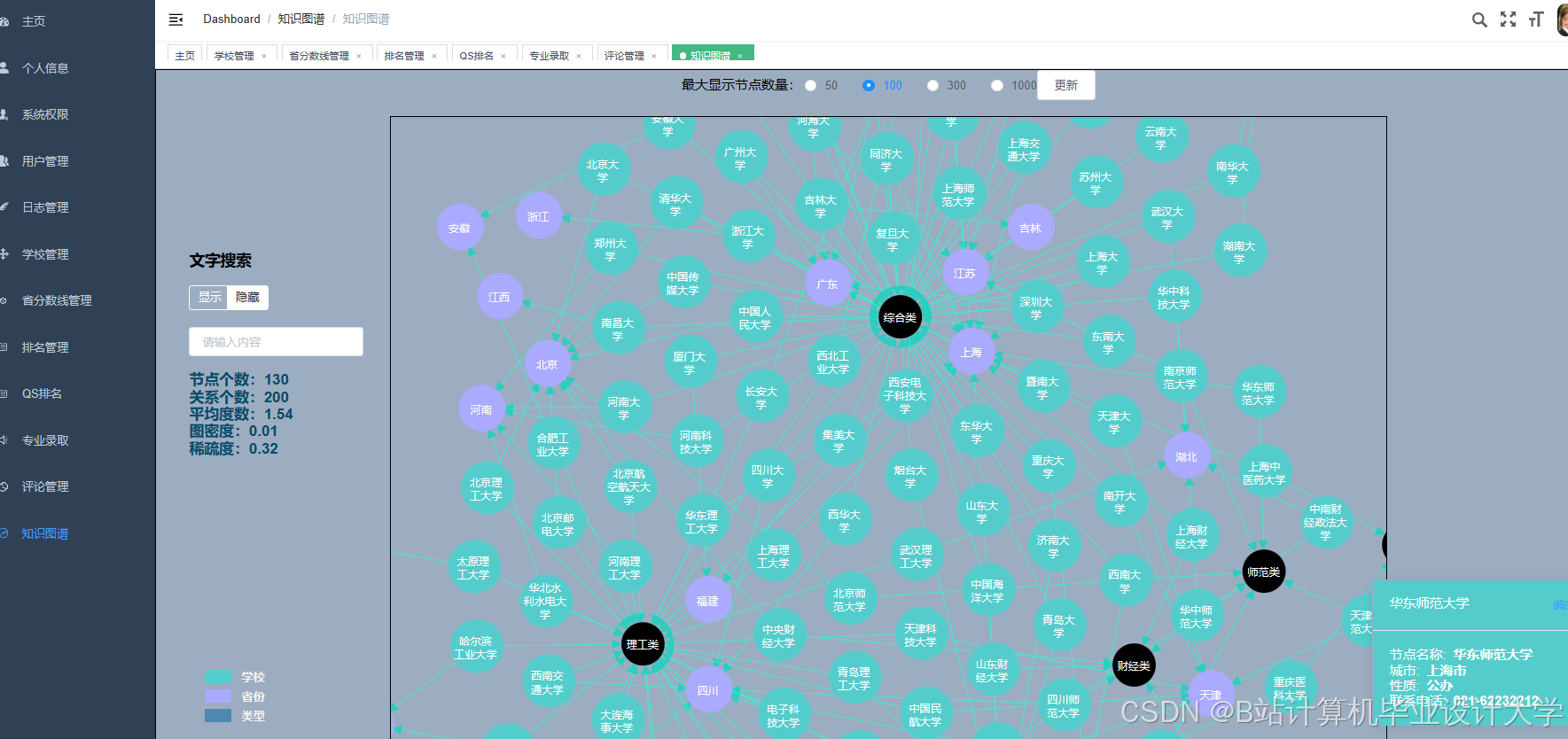
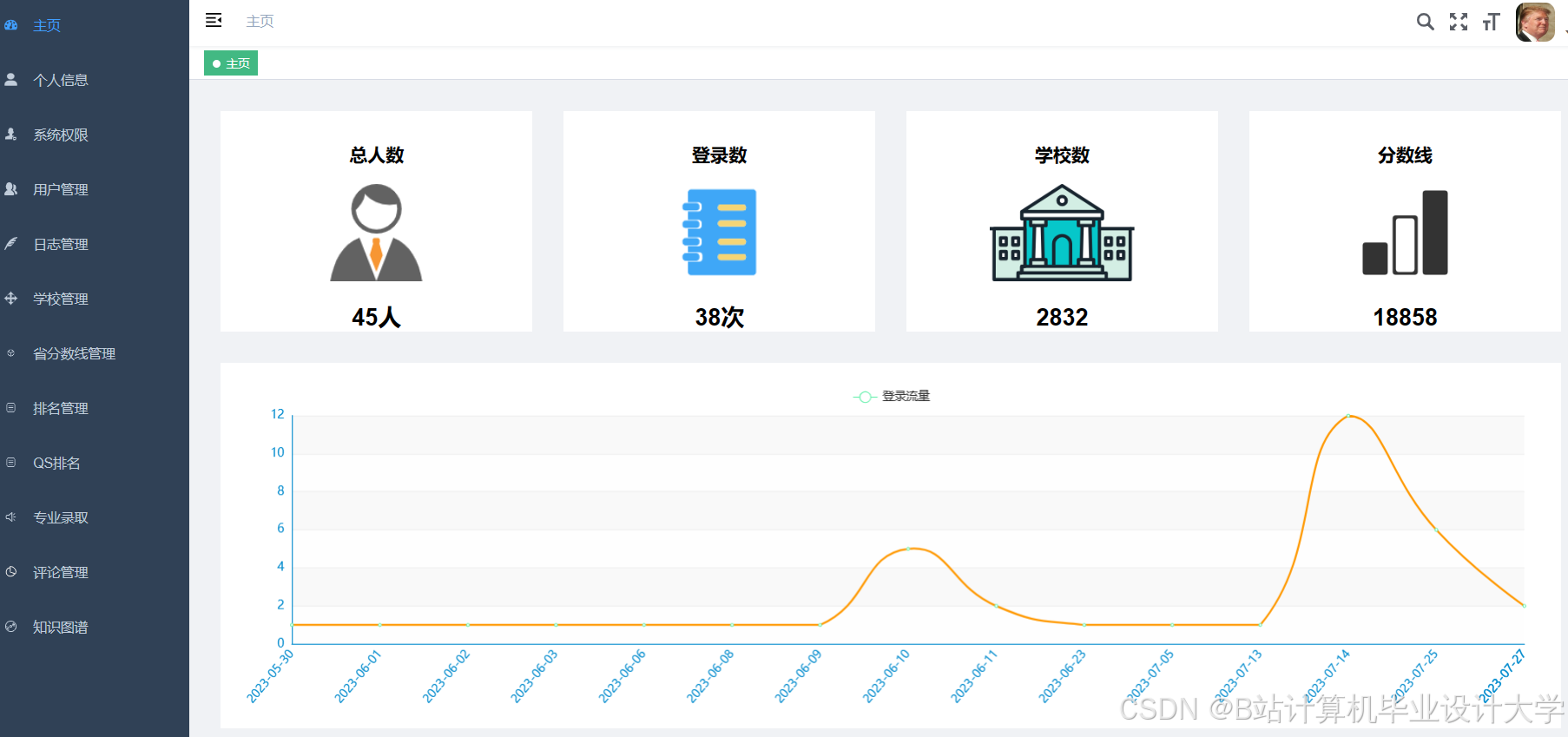
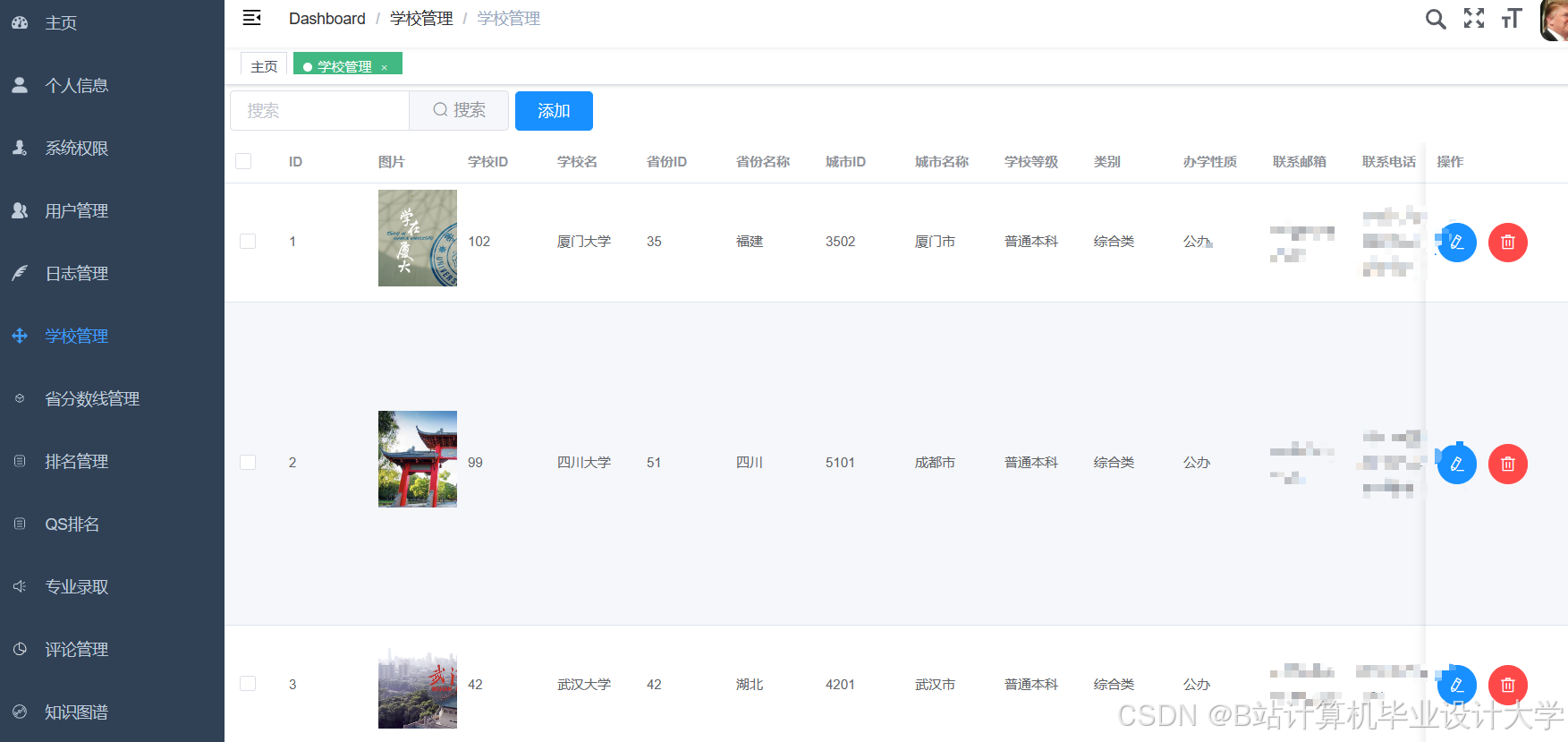
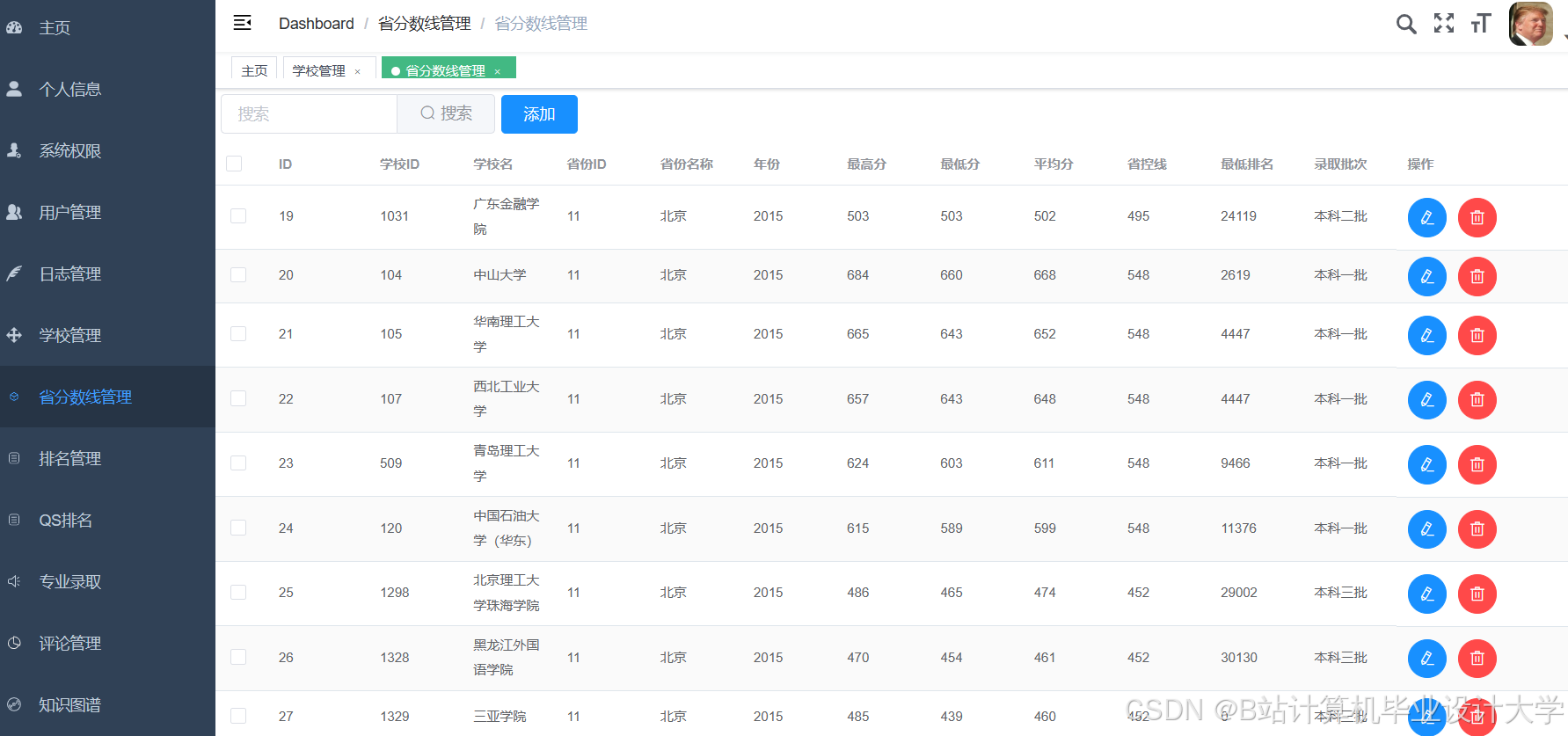
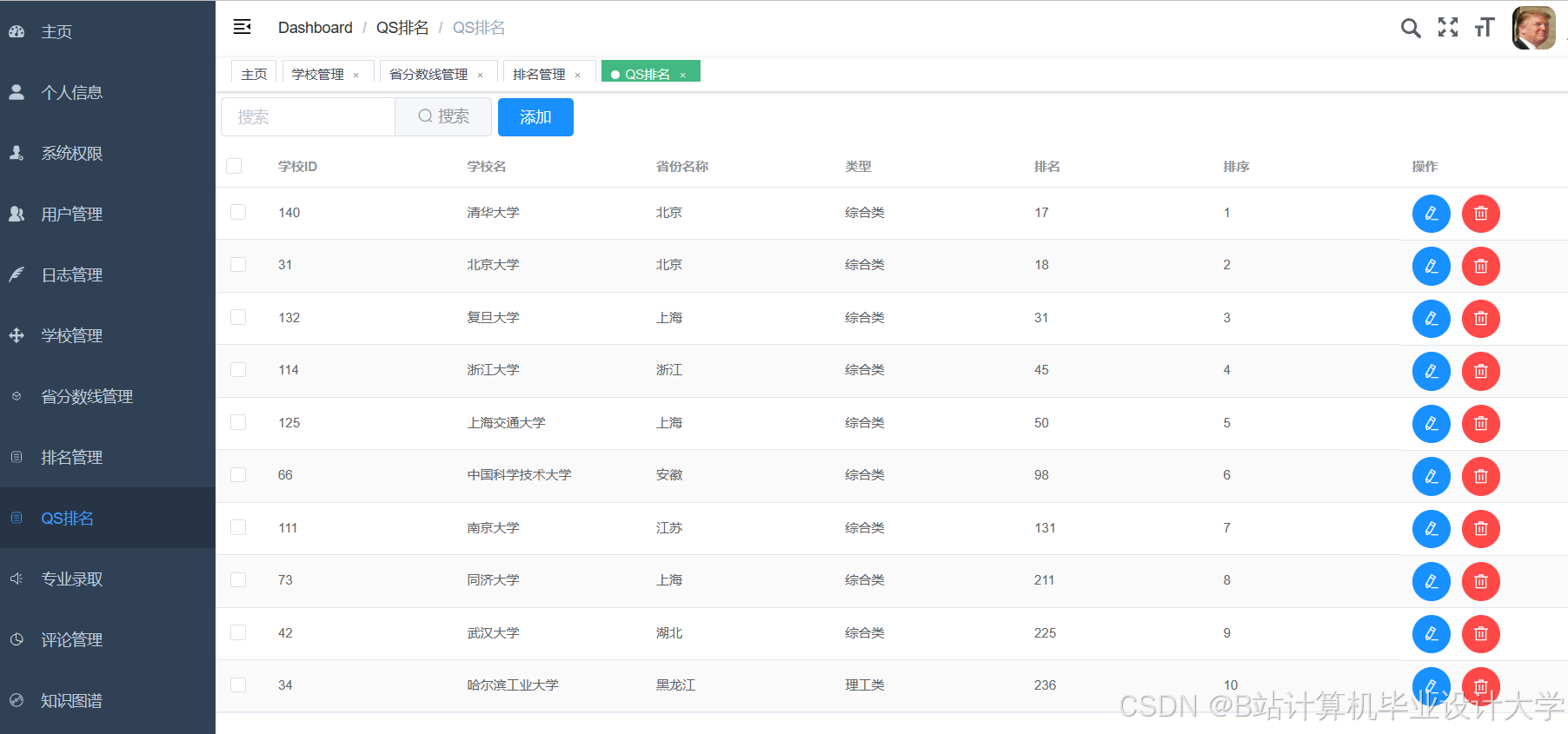
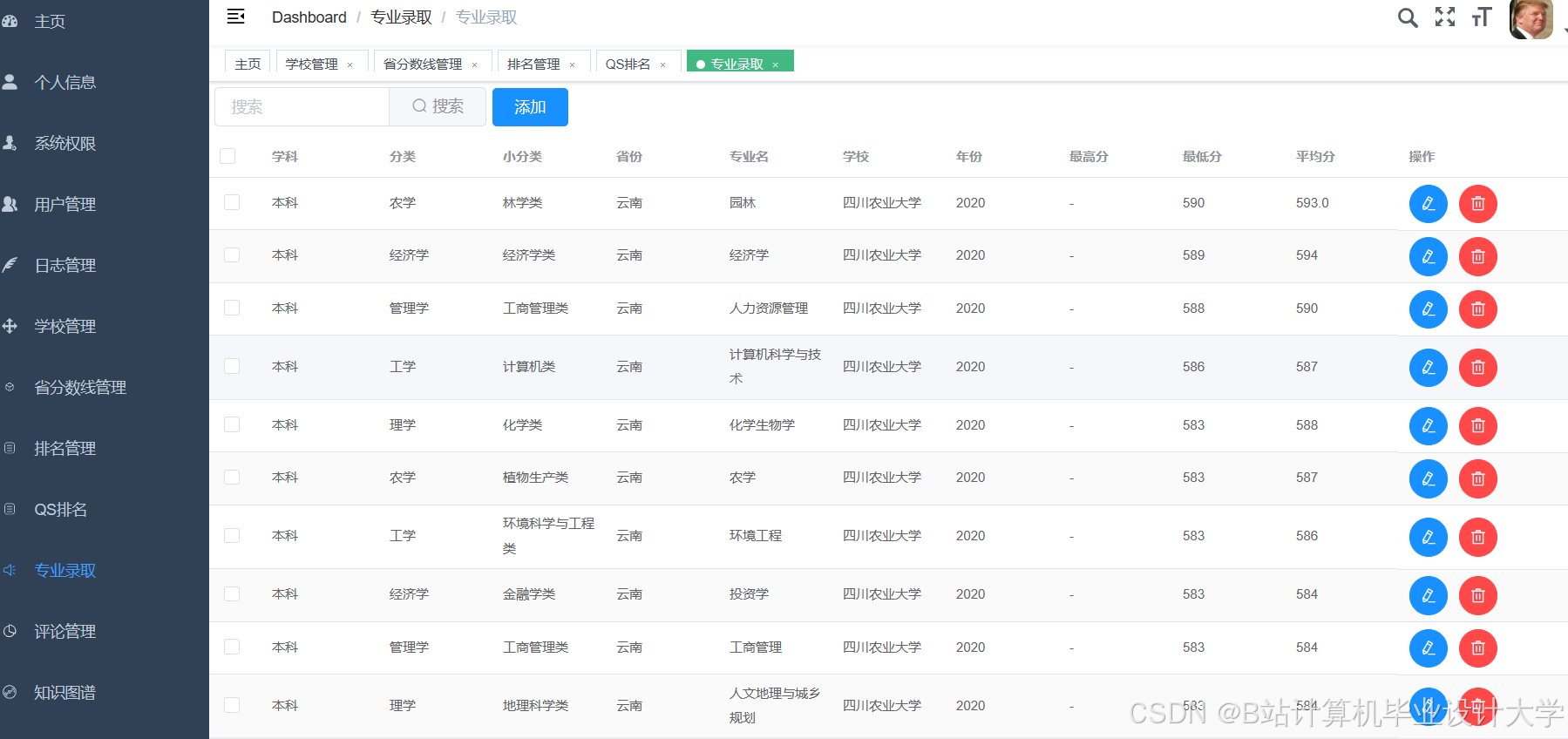
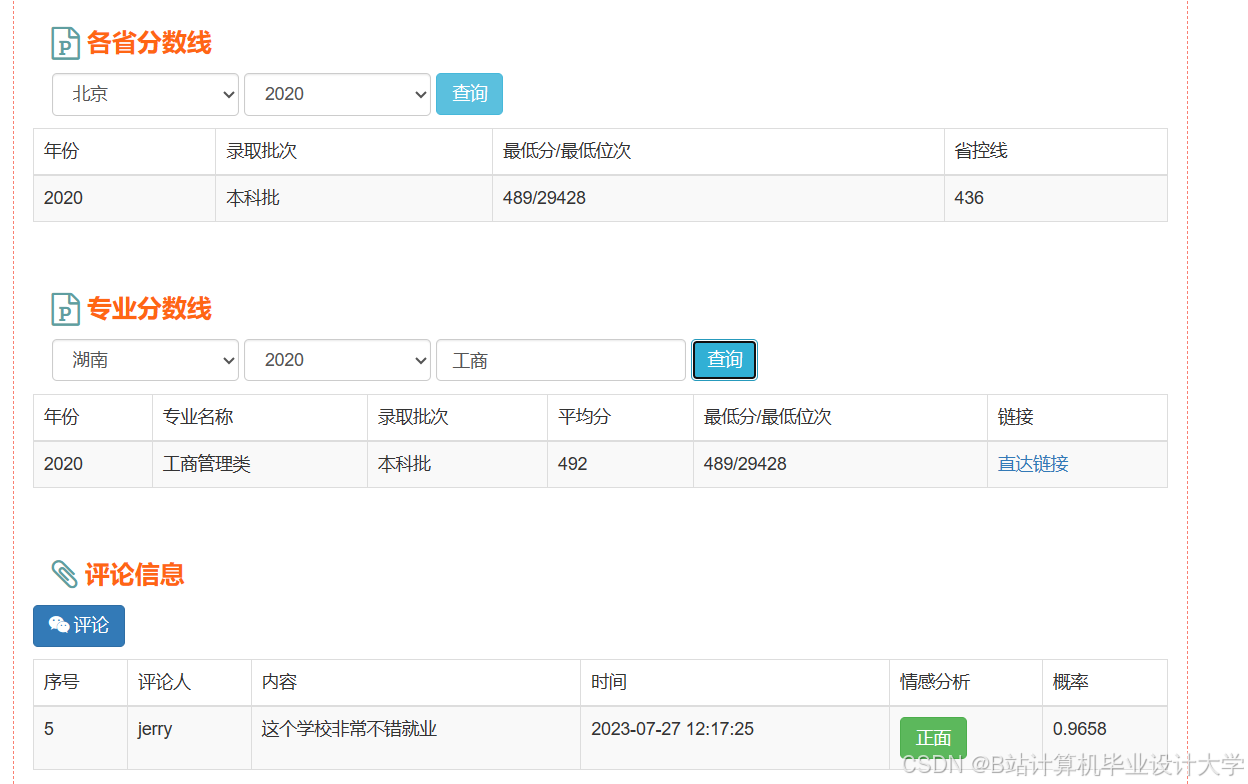
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











