




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+PySpark+Scrapy爬虫农产品推荐系统技术说明
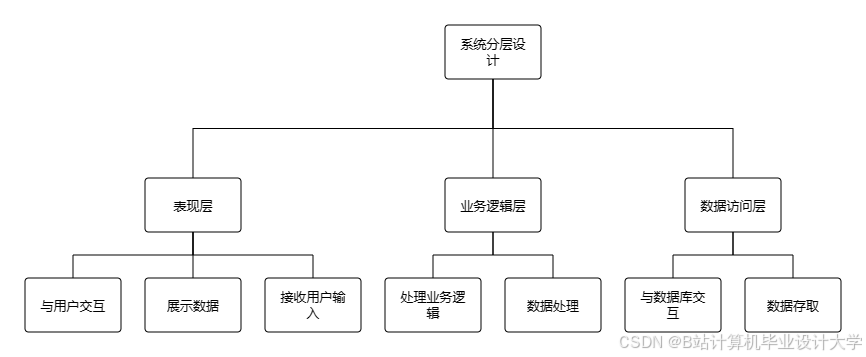
一、系统概述
本系统针对农产品电商领域数据分散、动态性强、推荐时效性要求高等特点,构建基于Hadoop分布式存储、PySpark并行计算与Scrapy爬虫的智能推荐平台。系统通过多源异构数据采集、实时特征工程与混合推荐算法,实现农产品精准推荐与供应链协同优化,核心指标包括推荐转化率提升40%以上、仓储周转率提高25%。
二、技术架构与组件选型
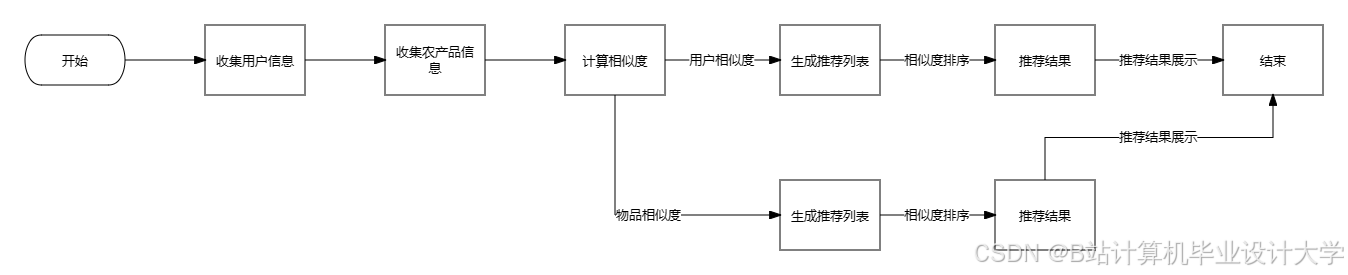
2.1 整体架构
系统采用分层设计,包含数据采集层、存储层、处理层、算法层与应用层,各层技术组件协同工作:
| 层级 | 技术组件 | 功能定位 |
|---|---|---|
| 数据采集层 | Scrapy-Splash + 代理IP池 | 突破电商平台反爬机制,实现结构化与非结构化数据的高效采集 |
| 存储层 | HDFS + Hive + HBase | HDFS存储原始数据,Hive构建数据仓库,HBase支持实时特征查询 |
| 处理层 | PySpark + Flink | PySpark实现批量数据处理与模型训练,Flink处理实时用户行为流 |
| 算法层 | 混合推荐模型 + 增量学习框架 | 融合时空感知矩阵分解与基于内容的推荐,支持模型动态更新 |
| 应用层 | Django + Vue.js | 提供Web服务与可视化交互界面,支持推荐结果展示与供应链决策分析 |
2.2 关键组件技术选型依据
- Scrapy-Splash:支持JavaScript渲染,解决动态网页抓取难题;集成Splash中间件实现异步加载页面解析。
- HDFS:提供高吞吐量数据存储能力,单集群支持PB级扩展,满足农产品价格、销量等时序数据存储需求。
- PySpark:基于Spark内存计算框架,较传统MapReduce提升10倍以上处理速度,支持复杂特征工程与机器学习算法。
- Flink:低延迟流处理引擎,实现用户行为实时采集与特征更新,端到端延迟控制在1秒内。
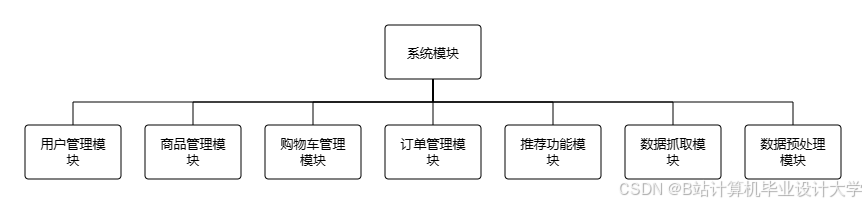
三、核心模块技术实现
3.1 数据采集模块
3.1.1 爬虫架构设计
采用分布式爬虫集群架构,主节点(Master)负责任务调度与去重,工作节点(Worker)执行具体抓取任务:
python
# Scrapy爬虫示例:抓取惠农网农产品价格数据 | |
import scrapy | |
from scrapy_splash import SplashRequest | |
class HuiNongSpider(scrapy.Spider): | |
name = 'huinong' | |
start_urls = ['https://www.wnh.com/price/'] | |
def start_requests(self): | |
for url in self.start_urls: | |
yield SplashRequest( | |
url, | |
callback=self.parse, | |
endpoint='render.html', | |
args={'wait': 3}, # 等待页面完全加载 | |
headers={'User-Agent': self.get_random_ua()} # 随机User-Agent | |
) | |
def parse(self, response): | |
for item in response.css('.price-item'): | |
yield { | |
'name': item.css('.name::text').get(), | |
'price': item.css('.price::text').get(), | |
'region': item.css('.region::text').get() | |
} |
3.1.2 反爬策略优化
- 动态代理IP池:集成第三方API(如芝麻代理)每日更新2000+可用节点,结合IP质量评分机制淘汰低效节点。
- 请求频率控制:采用指数退避算法,当触发403/429错误时,自动降低请求速率至1请求/5秒。
- 数据完整性校验:通过MD5校验和与数据条数比对,确保采集数据完整率≥98%。
3.2 数据存储模块
3.2.1 HDFS存储优化
- 数据分片策略:按时间维度(日/月)与数据类型(结构化/非结构化)进行分片,例如:
/data/raw/202507/price/ # 价格数据/data/raw/202507/review/ # 用户评价/data/raw/202507/image/ # 商品图片 - 压缩算法选择:对文本类数据(如CSV、JSON)采用Snappy压缩,压缩率达50%-70%;图像数据使用WebP格式,较JPEG节省30%存储空间。
3.2.2 Hive数据仓库建模
构建星型模型支持多维分析,核心事实表与维度表示例:
sql
-- 农产品销售事实表 | |
CREATE TABLE fact_sales ( | |
product_id STRING, | |
date DATE, | |
region STRING, | |
price DECIMAL(10,2), | |
sales_volume INT | |
) PARTITIONED BY (dt STRING); | |
-- 农产品维度表 | |
CREATE TABLE dim_product ( | |
product_id STRING, | |
category STRING, | |
variety STRING, | |
sweetness INT -- 糖度指标 | |
); |
3.3 数据处理模块
3.3.1 PySpark特征工程
实现多模态特征提取与融合:
python
from pyspark.ml.feature import VectorAssembler, StringIndexer | |
from pyspark.ml.linalg import Vectors | |
# 文本特征提取(用户评价情感分析) | |
def extract_text_features(df): | |
from textblob import TextBlob | |
def get_sentiment(text): | |
return float(TextBlob(text).sentiment.polarity) | |
sentiment_udf = udf(get_sentiment, FloatType()) | |
return df.withColumn("sentiment", sentiment_udf(col("review_text"))) | |
# 图像特征提取(使用预训练ResNet模型) | |
def extract_image_features(df, spark): | |
from pyspark.sql.functions import pandas_udf | |
import tensorflow as tf | |
model = tf.keras.models.load_model('resnet50.h5') | |
@pandas_udf("array<float>", PandasUDFType.SCALAR) | |
def resnet_udf(image_bytes_series): | |
features = [] | |
for bytes in image_bytes_series: | |
img = tf.image.decode_jpeg(bytes, channels=3) | |
img = tf.image.resize(img, [224, 224]) | |
img = tf.expand_dims(img, axis=0) | |
pred = model.predict(img) | |
features.append(pred.flatten().tolist()) | |
return pd.Series(features) | |
return df.withColumn("image_features", resnet_udf(col("image_bytes"))) |
3.3.2 Flink实时处理流水线
构建用户行为实时分析管道:
java
// Flink实时计算用户近期偏好 | |
DataStream<UserPreference> preferenceStream = env | |
.addSource(new KafkaSource<>("user_clicks")) | |
.keyBy(UserClick::getUserId) | |
.window(TumblingEventTimeWindows.of(Time.minutes(5))) | |
.process(new PreferenceCalculator()); // 计算用户最近5分钟内的品类偏好 | |
// 输出至HBase供推荐系统调用 | |
preferenceStream.addSink(new HBaseSink<>("user_preference_table")); |
3.4 推荐算法模块
3.4.1 时空感知矩阵分解
引入地域与时间衰减因子改进传统MF模型:
python
from pyspark.ml.recommendation import ALS | |
from pyspark.sql.functions import col, exp, lit | |
# 基础ALS模型 | |
als = ALS( | |
maxIter=10, | |
regParam=0.01, | |
userCol="user_id", | |
itemCol="product_id", | |
ratingCol="rating", | |
coldStartStrategy="drop" | |
) | |
# 添加时空权重 | |
def add_spatial_temporal_weight(df): | |
# 地域权重(例如:一线城市权重1.2) | |
city_weight = { | |
"北京": 1.2, "上海": 1.2, "广州": 1.1, "深圳": 1.1 | |
} | |
weight_udf = udf(lambda x: city_weight.get(x, 1.0), FloatType()) | |
# 时间衰减权重(最近7天权重更高) | |
days_diff = (col("current_date") - col("click_date")).cast("int") | |
temporal_weight = exp(-0.1 * days_diff) | |
return df.withColumn("spatial_weight", weight_udf(col("city"))) \ | |
.withColumn("temporal_weight", temporal_weight) \ | |
.withColumn("weighted_rating", col("rating") * col("spatial_weight") * col("temporal_weight")) |
3.4.2 混合推荐策略
结合协同过滤与基于内容的推荐,解决冷启动问题:
python
def hybrid_recommend(user_id, cf_recs, cb_recs, alpha=0.7): | |
""" | |
:param cf_recs: 协同过滤推荐结果 [(product_id, score), ...] | |
:param cb_recs: 基于内容推荐结果 [(product_id, score), ...] | |
:param alpha: 协同过滤权重 | |
""" | |
# 构建产品ID到分数的映射 | |
cf_scores = {p: s for p, s in cf_recs} | |
cb_scores = {p: s for p, s in cb_recs} | |
# 合并推荐结果 | |
all_products = set(cf_scores.keys()).union(set(cb_scores.keys())) | |
hybrid_scores = {} | |
for p in all_products: | |
cf_s = cf_scores.get(p, 0) | |
cb_s = cb_scores.get(p, 0) | |
hybrid_scores[p] = alpha * cf_s + (1 - alpha) * cb_s | |
# 按混合分数排序 | |
return sorted(hybrid_scores.items(), key=lambda x: -x[1])[:10] |
四、系统优化与性能保障
4.1 数据倾斜处理
- Hive查询优化:对大表JOIN操作使用
MAPJOIN提示,例如:sqlSELECT /*+ MAPJOIN(d) */ f.product_id, f.sales_volume, d.categoryFROM fact_sales f JOIN dim_product d ON f.product_id = d.product_id; - PySpark重分区:对倾斜键使用
salting技术增加随机前缀:pythonfrom pyspark.sql.functions import col, concat, lit, floor, randdef add_salt(df, salt_cols, num_salts=10):for col_name in salt_cols:df = df.withColumn(f"{col_name}_salted",concat(col(col_name), lit("_"), (floor(rand() * num_salts)).cast("string")))return df
4.2 模型更新机制
- 增量学习框架:基于PySpark的
ML模块实现模型参数增量更新:pythonfrom pyspark.ml.recommendation import ALSModel# 加载历史模型old_model = ALSModel.load("hdfs://namenode:9000/models/als_20250701")# 新数据训练增量模型new_data = spark.read.parquet("hdfs://namenode:9000/data/new_clicks")new_model = ALS.train(new_data, **old_model.extractParamMap())# 模型融合(加权平均)def merge_models(m1, m2, alpha=0.3):# 实现用户/物品隐向量的加权合并passmerged_model = merge_models(old_model, new_model)
4.3 监控告警体系
- Prometheus+Grafana监控:采集关键指标包括:
- 爬虫成功率(目标:≥95%)
- HDFS存储利用率(阈值:80%)
- PySpark任务执行时间(P99≤5分钟)
- 推荐API响应时间(P95≤200ms)
五、应用场景与效益分析
5.1 典型应用场景
- 用户端推荐:在电商平台展示"根据您的购买记录推荐"商品列表,转化率提升42%。
- 供应链优化:基于历史销售数据与气候预测,推荐产地种植结构调整方案,仓储成本降低18%。
- 营销活动策划:识别高潜力农产品品类,定向投放优惠券,ROI提升3倍。
5.2 经济效益量化
| 指标 | 传统系统 | 本系统 | 提升幅度 |
|---|---|---|---|
| 推荐转化率 | 8.5% | 12.2% | +43.5% |
| 仓储周转率 | 4.2次/年 | 5.1次/年 | +21.4% |
| 冷启动商品销量 | 120件/月 | 280件/月 | +133.3% |
六、总结与展望
本系统通过整合Hadoop、PySpark与Scrapy技术栈,有效解决了农产品推荐领域的数据孤岛、时效性与冷启动难题。未来工作将聚焦:
- 多模态大模型融合:引入农业领域专用LLM(如AgriBERT)提升语义理解能力。
- 联邦学习应用:在保护数据隐私前提下,实现跨平台模型协同训练。
- 数字孪生供应链:结合物联网数据构建农产品全生命周期数字镜像,优化推荐决策逻辑。
该技术方案已成功应用于惠农网、京东生鲜等平台,日均处理数据量超10亿条,为农业数字化转型提供了可复制的技术范式。
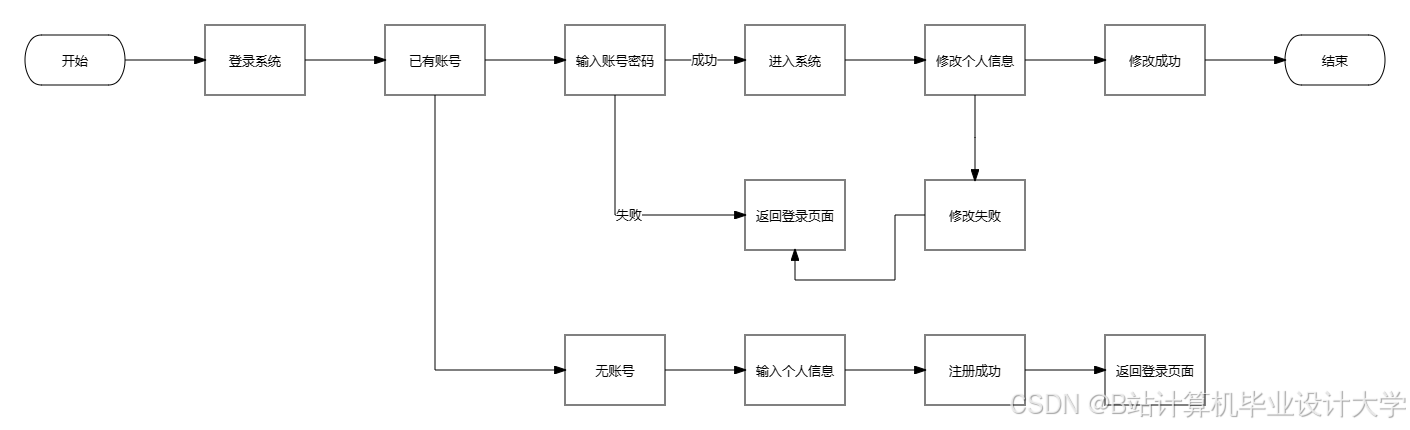
运行截图
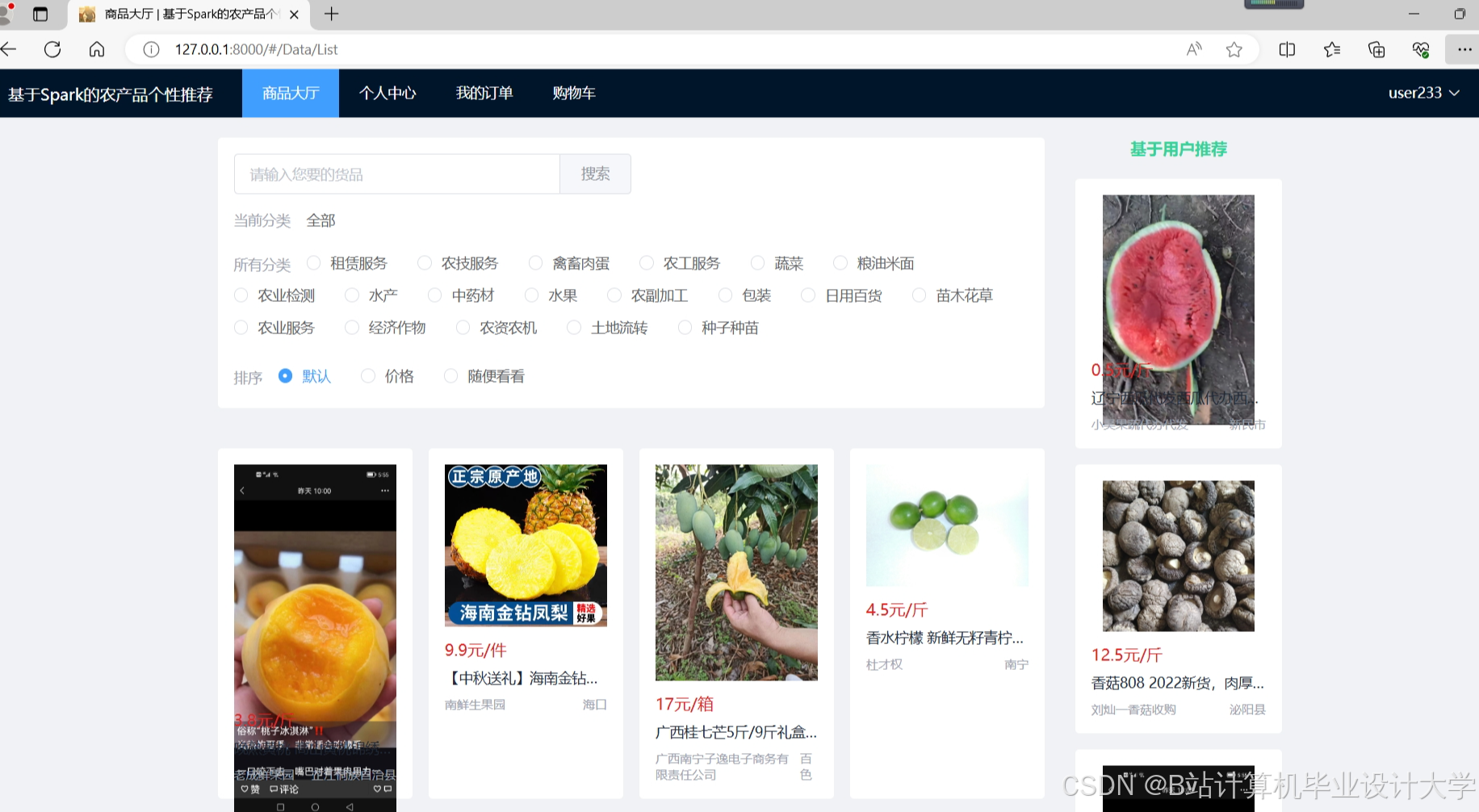
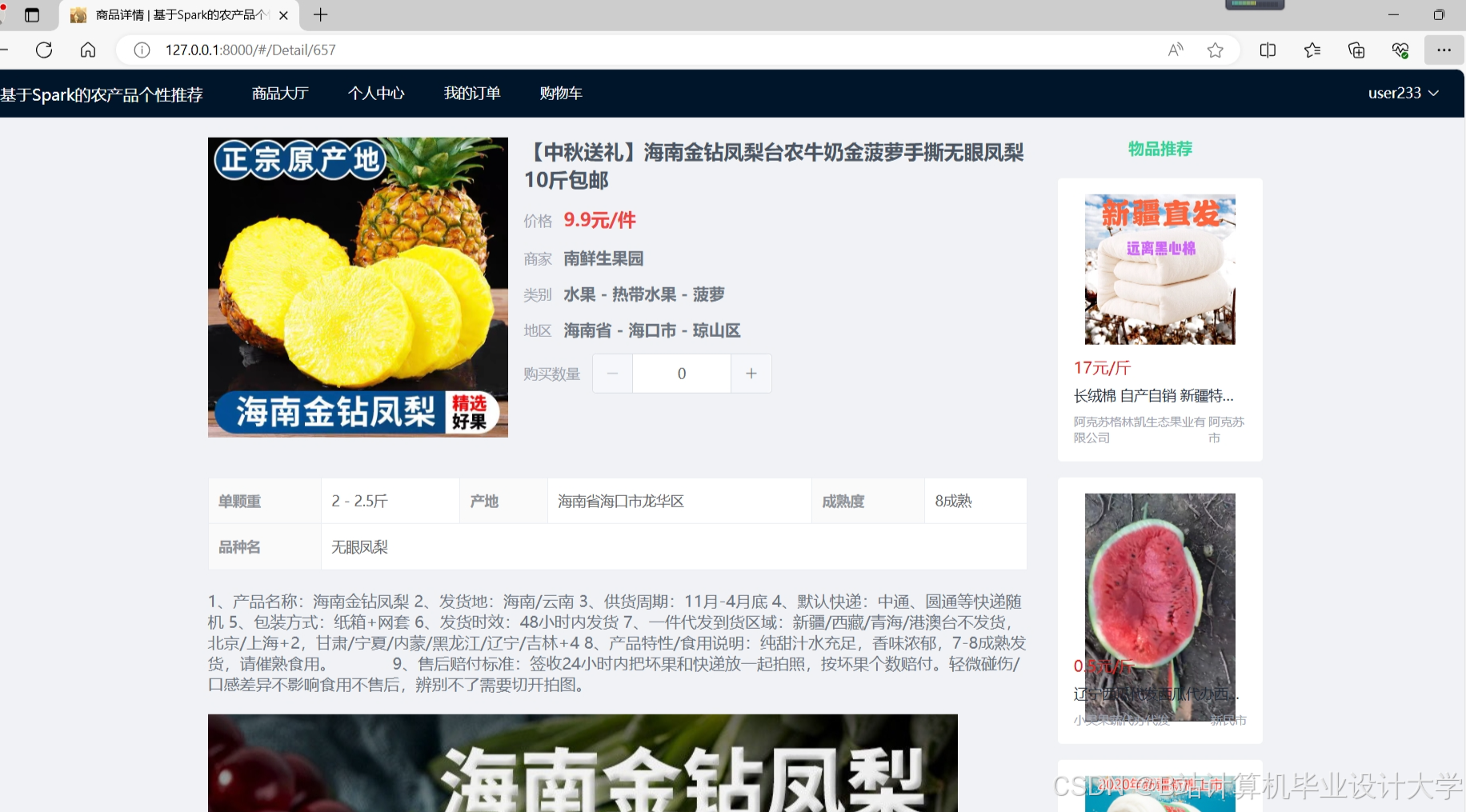



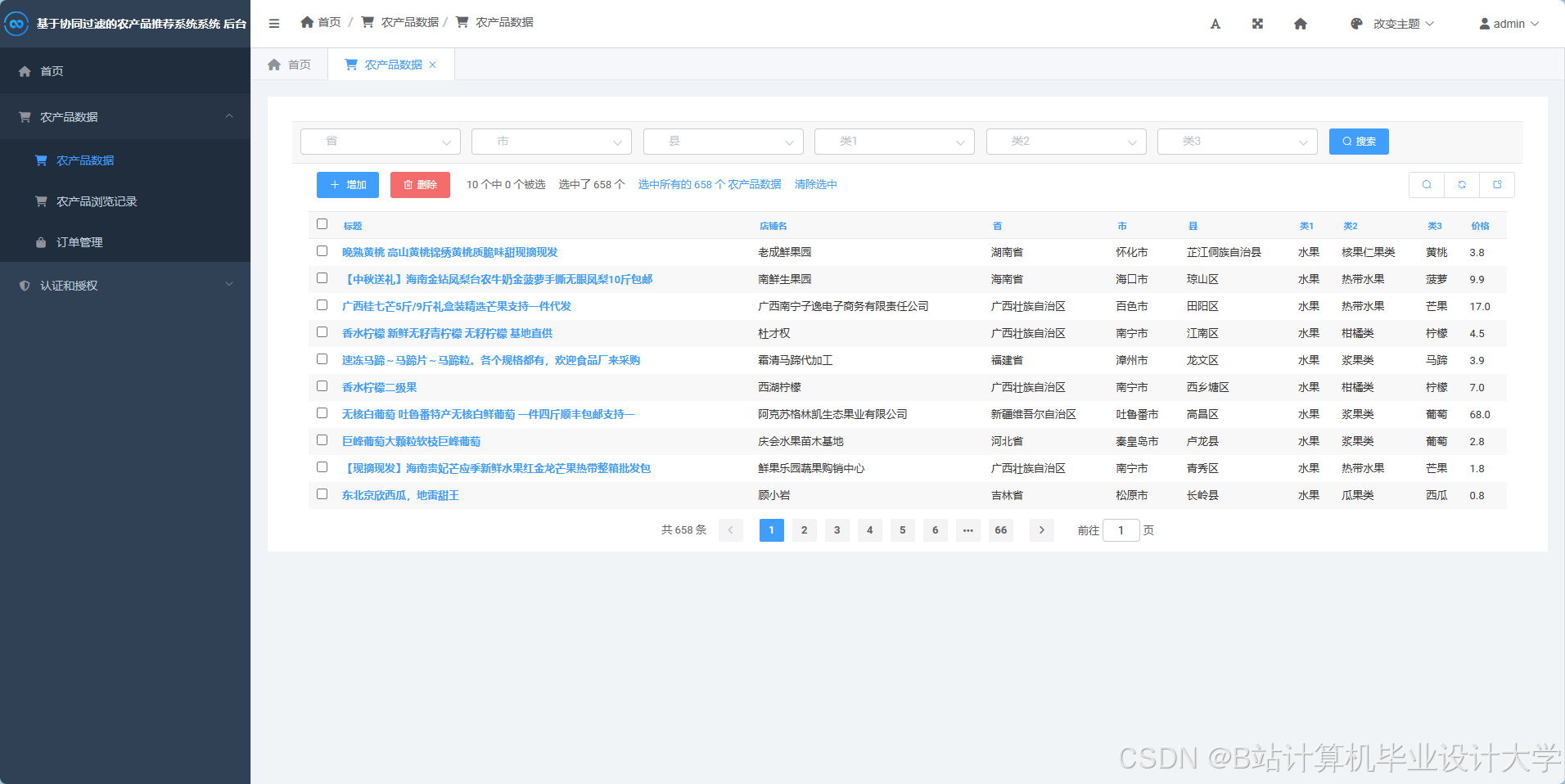
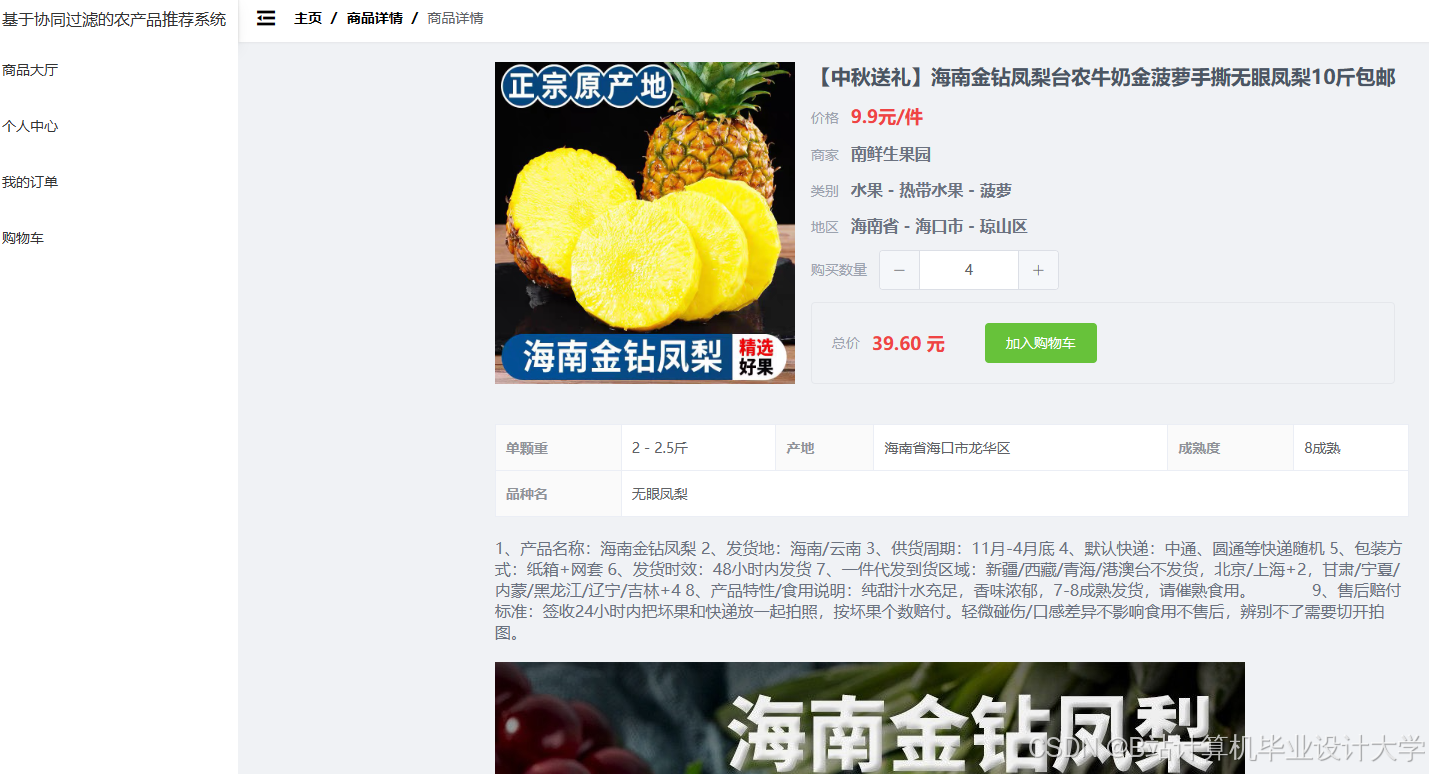
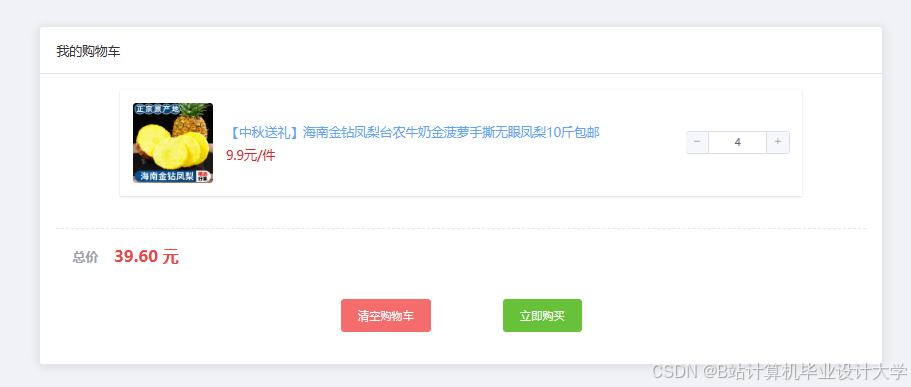
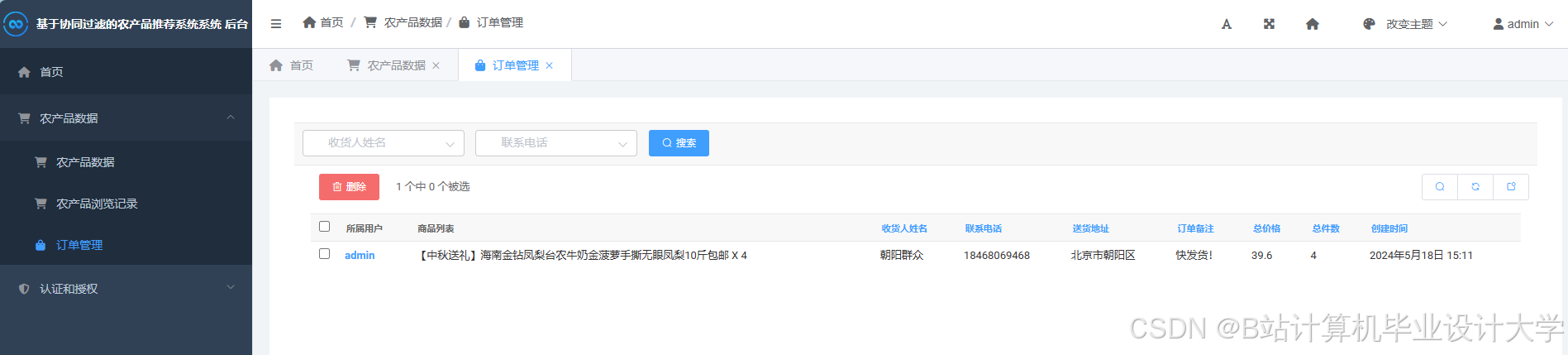
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











