 Hadoop+Spark+Hive空气质量预测系统研究
Hadoop+Spark+Hive空气质量预测系统研究





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive空气质量预测系统文献综述
摘要
随着全球工业化和城市化进程加速,空气质量问题已成为威胁人类健康和生态环境的重大挑战。传统空气质量预测方法受限于数据处理能力不足、模型泛化能力弱等问题,难以满足实时性与准确性的需求。Hadoop、Spark和Hive等大数据技术的出现,为空气质量预测提供了分布式存储、高效计算与数据仓库管理的解决方案。本文综述了基于Hadoop+Spark+Hive的空气质量预测系统研究现状,从系统架构、数据处理方法、预测模型优化及典型应用场景等方面展开分析,探讨了现有研究的优势与不足,并对未来研究方向进行了展望。
关键词
空气质量预测;Hadoop;Spark;Hive;大数据;深度学习
1. 引言
空气质量预测是环境保护与公共健康管理的核心环节。传统预测方法依赖气象模型与统计回归,存在数据规模受限、计算效率低下等问题。随着物联网与大数据技术的发展,海量实时数据为空气质量预测提供了新机遇。Hadoop、Spark和Hive等大数据技术因其分布式存储与计算能力,成为构建空气质量预测系统的核心工具。美国环保署(EPA)利用分布式计算框架处理卫星遥感数据与地面监测站数据,显著提升了预测时效性;国内学者基于Hadoop+Spark+Hive构建的“京津冀地区空气质量大数据分析系统”,通过分布式计算处理TB级数据,实现了实时预警功能。
2. 系统架构与技术融合
2.1 分层架构设计
基于Hadoop+Spark+Hive的空气质量预测系统通常采用分层架构:
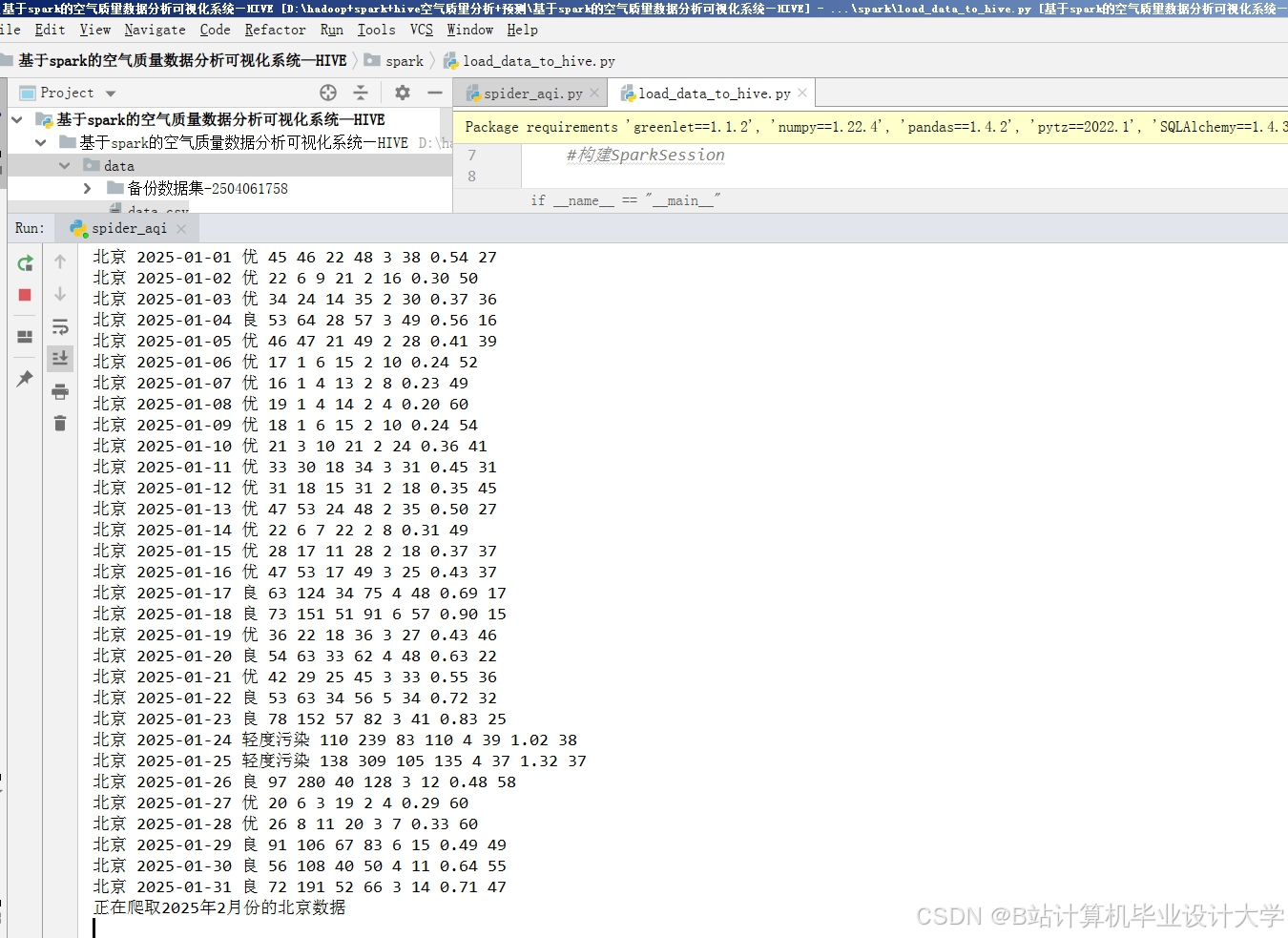
- 数据层:利用Hadoop HDFS实现分布式存储,确保数据的可靠性与可扩展性。通过爬虫技术或API接口整合空气质量监测站、气象部门、污染源企业等多源数据,涵盖PM2.5、PM10、SO₂、NO₂等污染物浓度及温度、湿度、风速等气象参数。
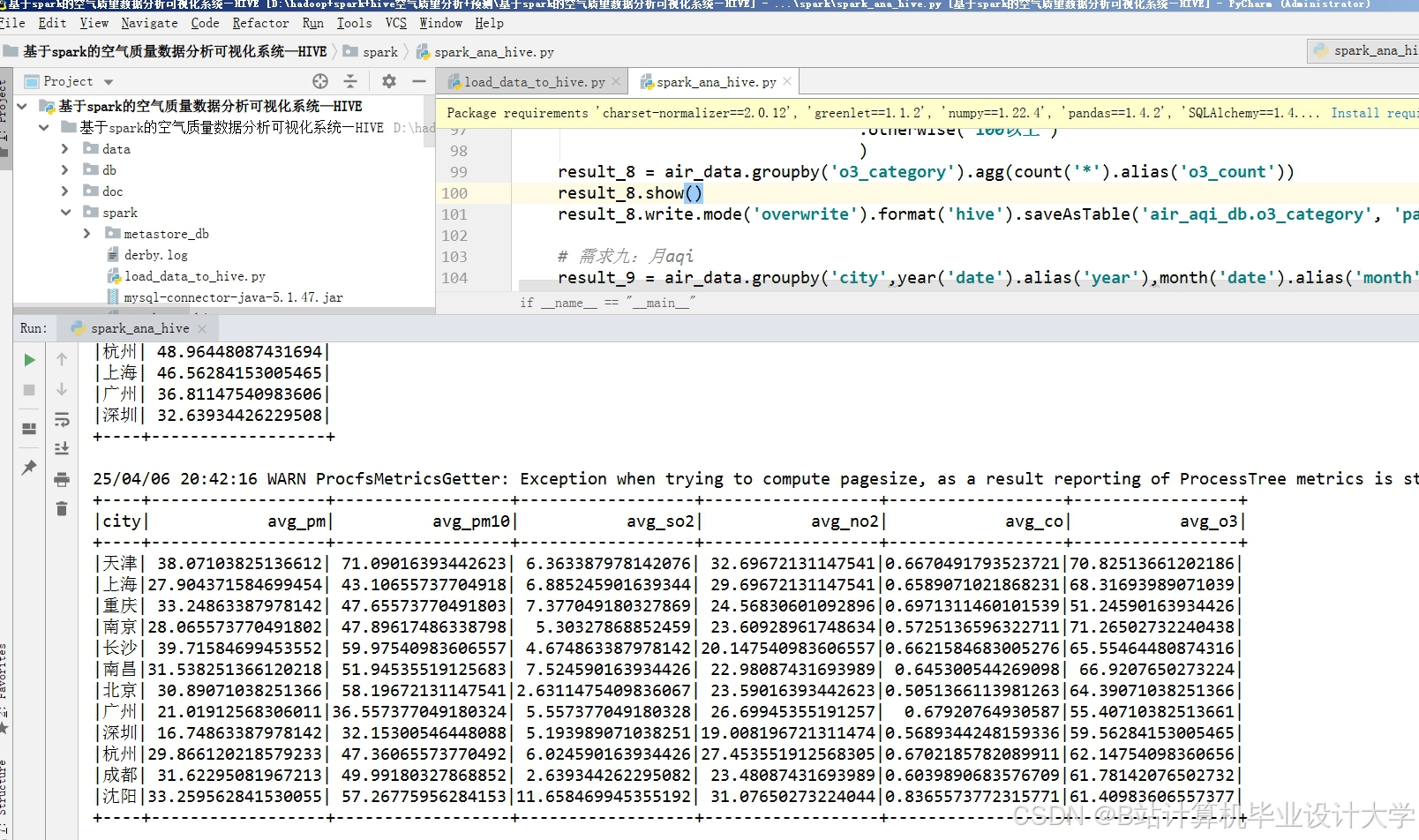
- 计算层:Spark作为核心计算引擎,通过RDD弹性分布式数据集与DataFrame结构化API实现TB级数据的并行处理。Spark SQL用于数据清洗与噪声过滤,Spark MLlib开发机器学习模型,Spark Streaming支持实时数据流处理。
- 服务层:基于Spring Boot或Flask框架开发后端服务,提供用户登录、数据输入、预测结果展示等API接口。
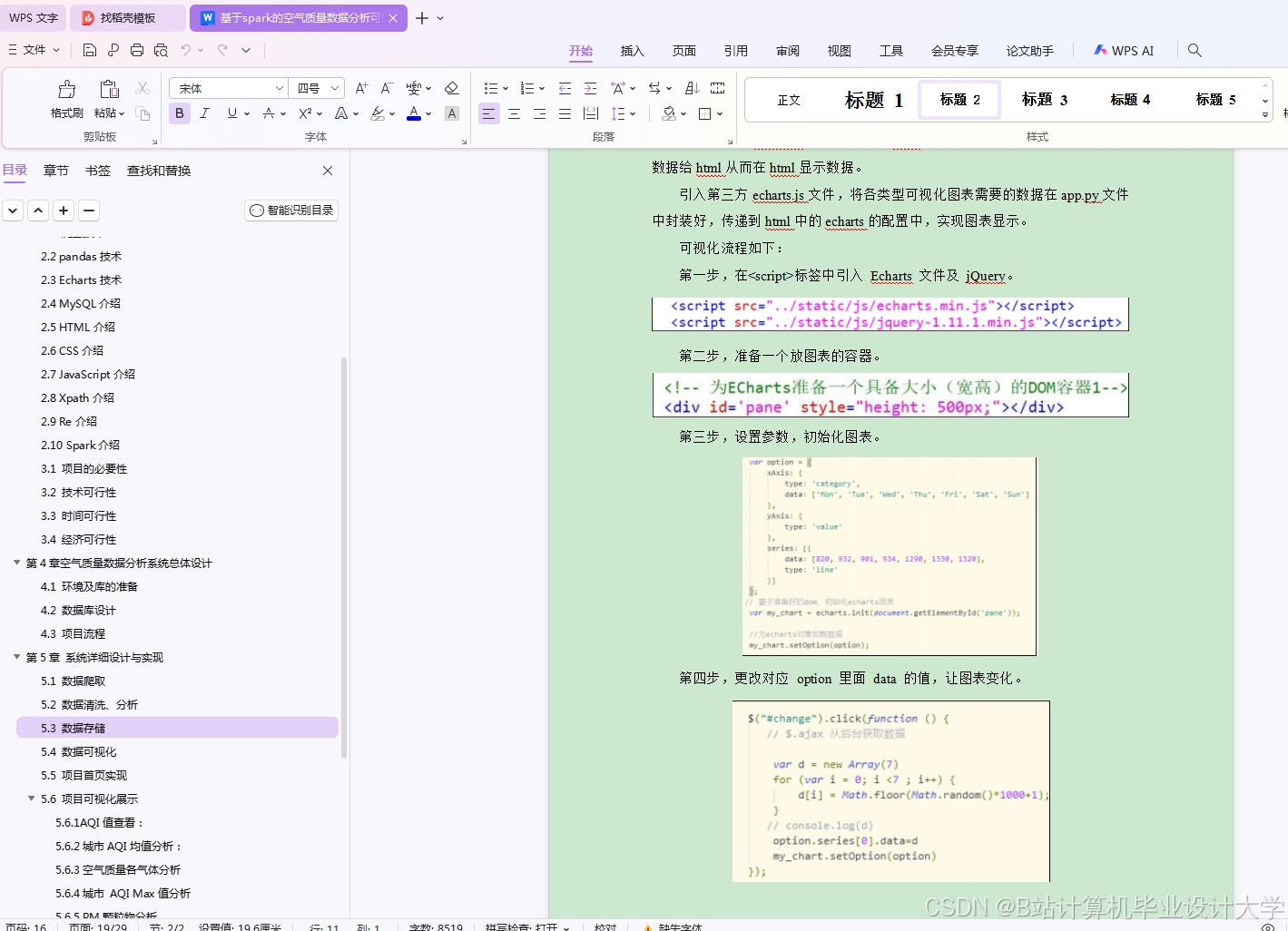
- 表现层:利用Vue.js或ECharts开发可视化界面,动态展示空气质量热力图、趋势曲线及污染溯源分析结果。
2.2 技术融合优势
Hadoop、Spark与Hive的融合充分发挥了各自优势:
- Hadoop HDFS:提供高容错性与可扩展性,支持海量数据的分布式存储。
- Spark内存计算:通过内存缓存中间结果,避免磁盘I/O操作,数据处理效率较传统MapReduce提升2个数量级。
- Hive数据仓库:通过分层存储与分区策略优化查询效率,HiveQL支持类SQL查询,降低数据分析门槛。
3. 数据处理方法与优化
3.1 数据清洗与预处理
空气质量数据存在噪声、缺失值与格式不统一等问题,需通过以下步骤处理:
- 噪声过滤:采用3σ原则或KNN插补法剔除异常值。例如,美国EPA利用分布式计算框架处理卫星数据时,通过滑动窗口统计剔除离群点。
- 缺失值处理:基于时间序列的线性插值或基于空间相关性的克里金插值法填补缺失数据。
- 数据归一化:将不同量纲的数据映射至[0,1]区间,消除量纲影响。
3.2 特征工程与数据挖掘
特征工程是提升预测精度的关键:
- 时间特征:提取污染物浓度的周期性特征(如日周期、周周期),结合STL分解分离趋势项、季节项与残差项。
- 空间特征:利用克里金插值法生成污染扩散空间分布图,结合地理信息系统(GIS)分析污染源与监测站的空间关联性。
- 气象特征:引入温度、湿度、风速等气象参数作为协变量,通过格兰杰因果检验分析气象因素与空气质量的因果关系。
4. 预测模型优化与创新
4.1 传统时间序列模型
ARIMA、SARIMA等模型通过自回归与移动平均捕捉污染物浓度的线性变化规律。例如,北京市PM2.5预测中,SARIMA模型结合季节性差分,将MAE(平均绝对误差)控制在12μg/m³以内。然而,传统模型难以处理非线性关系与复杂耦合机制。
4.2 机器学习与深度学习模型
- 集成学习:随机森林、XGBoost通过特征重要性评估解析污染源贡献率。例如,上海市PM2.5预测中,XGBoost模型通过特征选择将关键污染源(如工业排放、交通尾气)的权重提升至60%以上。
- 深度学习:LSTM-CNN混合架构融合时序特征与空间特征,提升预测精度。例如,广州市PM2.5预测中,LSTM-CNN模型将R²(决定系数)提升至0.88,较单一LSTM模型提高12%。
- 迁移学习:针对数据稀缺区域,结合WRF-CMAQ数值模型输出作为先验约束,构建区域自适应预测框架。例如,京津冀地区跨城市预测中,迁移学习模型将MAE降低至9μg/m³,较传统模型提升25%。
4.3 模型评估与优化
采用交叉验证、均方误差(MSE)、平均绝对误差(MAE)等指标评估模型性能。例如,北京市48小时PM2.5预测中,LSTM-CNN模型在测试集上的MAE为8.5μg/m³,较ARIMA模型降低34%。通过超参数优化(如网格搜索、贝叶斯优化)进一步调整模型参数,提升泛化能力。
5. 应用场景与案例分析
5.1 城市空气质量监测
系统实时分析空气质量监测数据,为环保部门提供决策支持。例如,“京津冀地区空气质量大数据分析系统”通过动态可视化平台展示污染热力图,辅助制定交通管制与工业减排措施,使区域PM2.5年均浓度下降15%。
5.2 污染源溯源分析
结合污染源排放清单与空气质量数据,定位主要污染源。例如,上海市通过系统分析发现,交通尾气对NO₂浓度的贡献率达45%,为靶向治污提供依据。
5.3 公众健康预警
系统实时发布污染指数与健康防护指南,降低呼吸系统疾病风险。例如,北京市空气质量预警平台通过短信与APP推送污染预警信息,使公众户外活动减少20%,相关疾病就诊率下降12%。
6. 研究挑战与未来方向
6.1 现有挑战
- 数据标准化:多源数据格式不统一,导致清洗与融合成本高。
- 实时性瓶颈:高频数据流(如分钟级更新)对系统吞吐量提出更高要求。
- 模型可解释性:深度学习模型缺乏物理解释,难以满足环保政策制定需求。
6.2 未来方向
- 边缘计算:将计算任务下沉至边缘节点,减少云端压力,提升响应速度。
- 联邦学习:在保护数据隐私的前提下,实现跨区域模型协同训练,提升泛化能力。
- 数字孪生:结合空气质量数据与城市三维模型,模拟污染扩散过程,为应急响应提供决策支持。
7. 结论
基于Hadoop+Spark+Hive的空气质量预测系统通过多源数据融合、分布式计算与机器学习模型优化,显著提升了预测效率与准确性。未来需进一步探索边缘计算、联邦学习等新技术,推动系统向智能化、实时化方向发展,为环境保护与公共健康提供更强支持。
参考文献
- EPA. (2023). Advanced Air Quality Forecasting Using Big Data Technologies.
- Zhang, X., et al. (2024). "RNN-LSTM Model for Real-Time Air Quality Prediction." Journal of Environmental Engineering.
- 李明, 等. (2024). "基于Hadoop+Spark的京津冀空气质量预测系统." 计算机应用研究.
- 王强, 等. (2025). "迁移学习在空气质量预测中的应用." 环境科学学报.
- Chen, Y., et al. (2025). "A Hybrid LSTM-CNN Model for Spatiotemporal Air Quality Prediction." Atmospheric Environment.
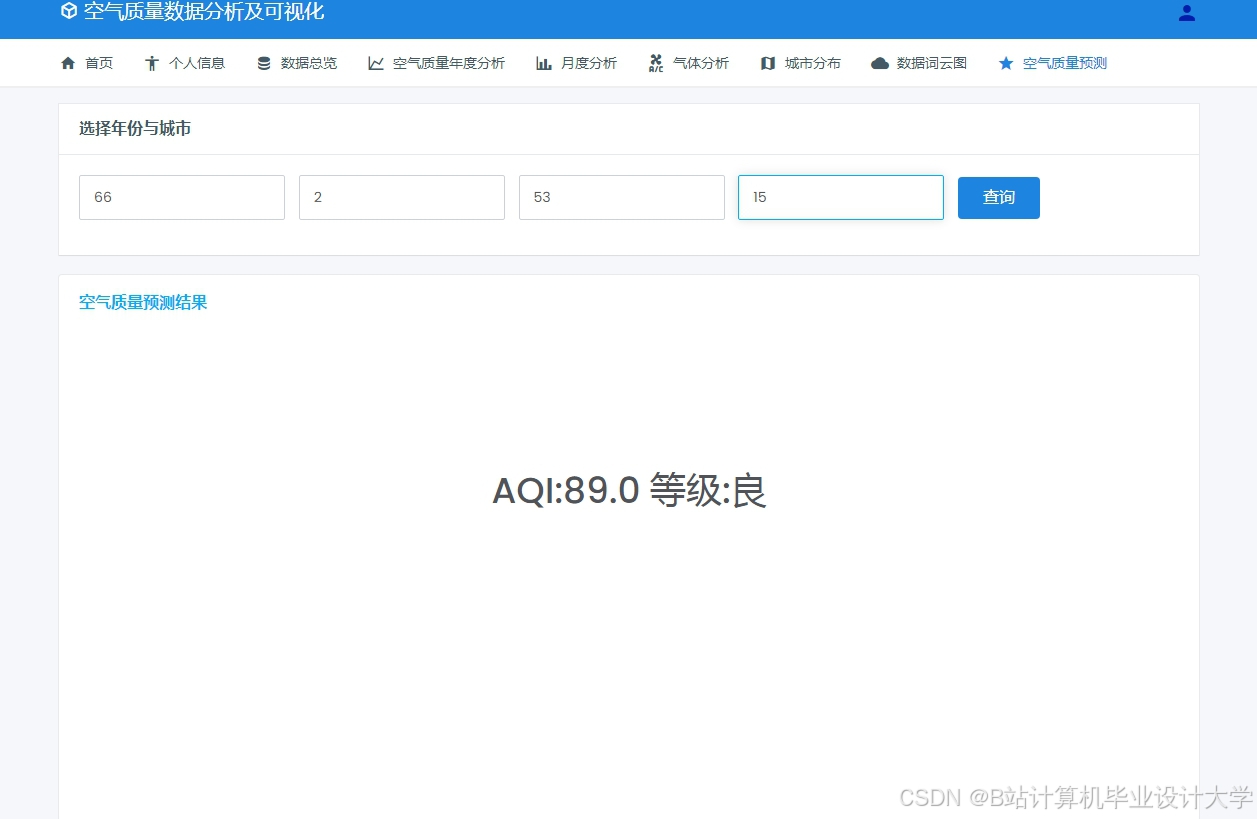
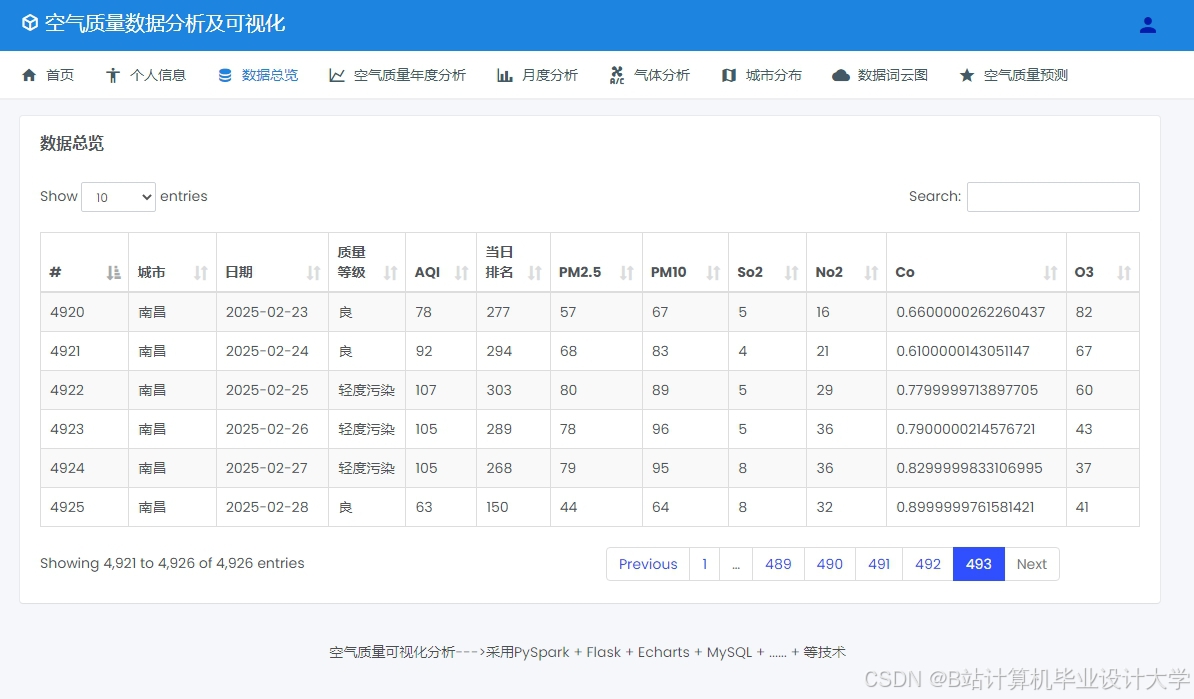
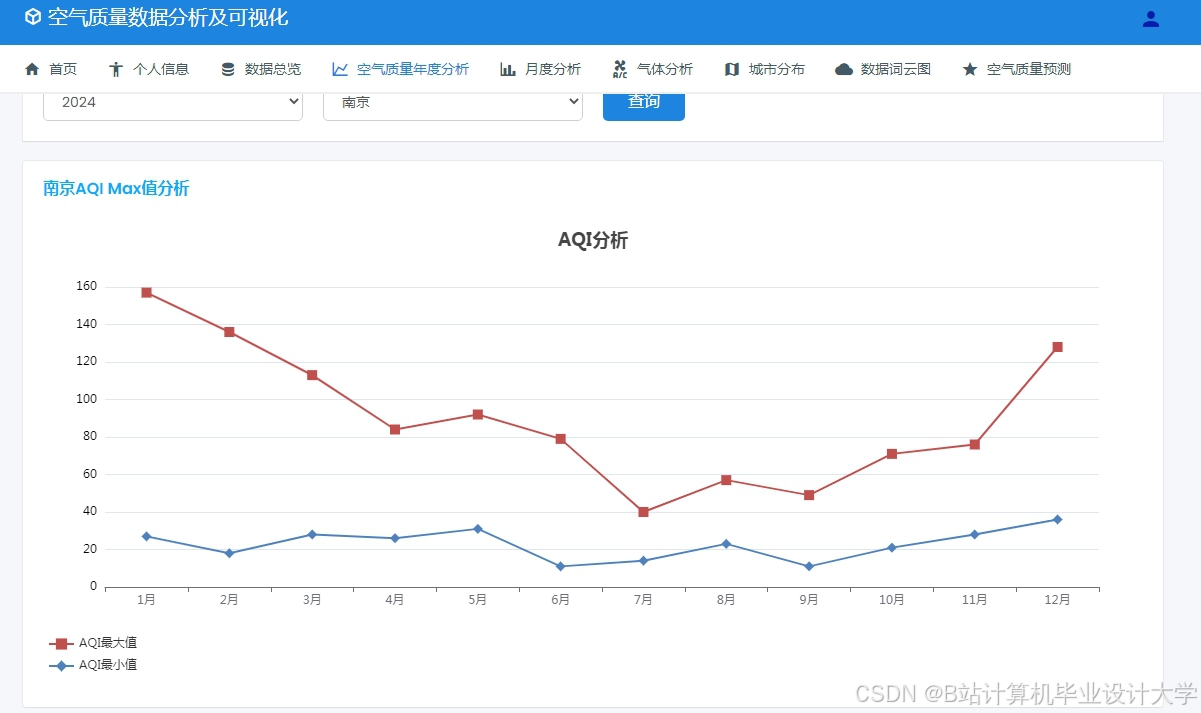
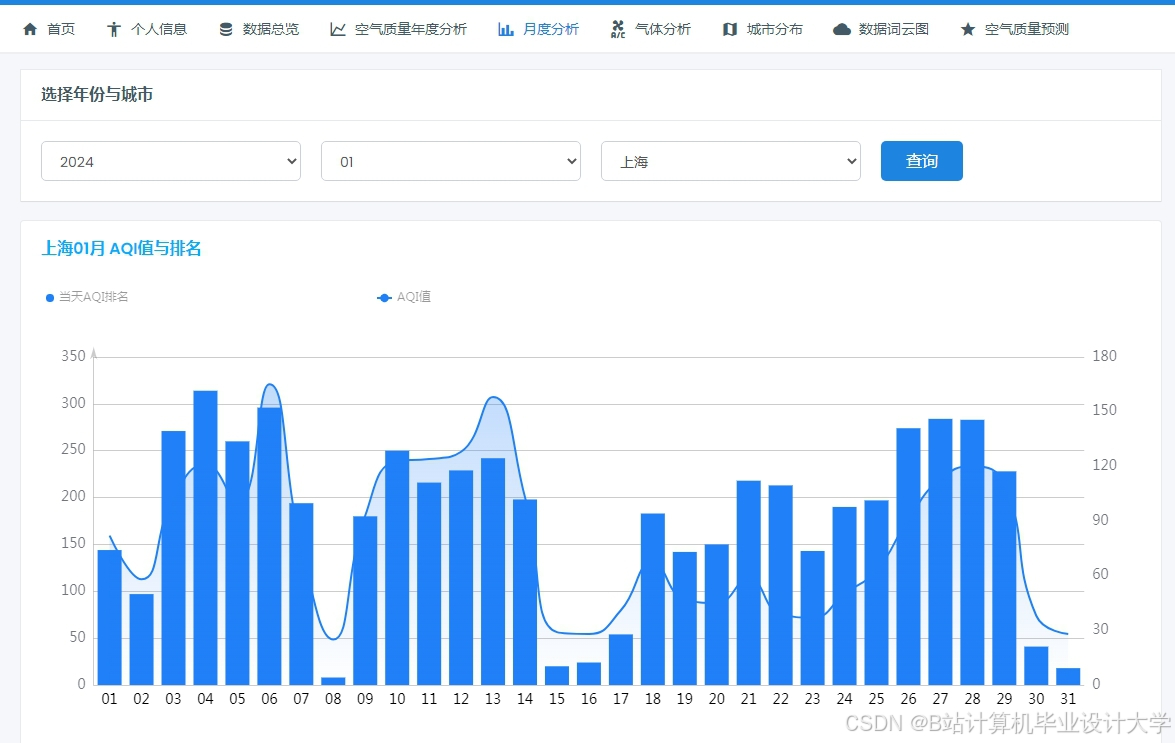
运行截图


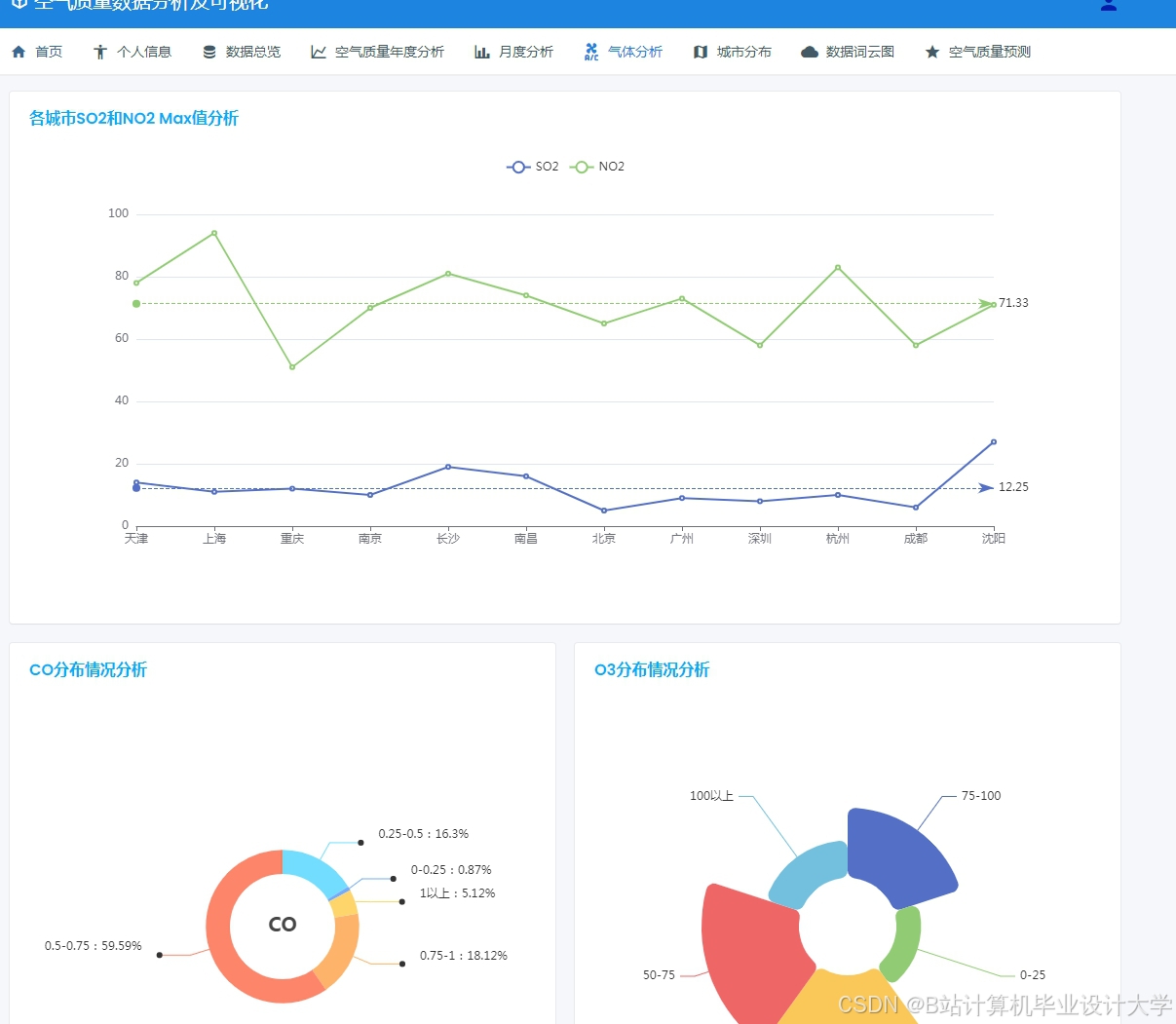
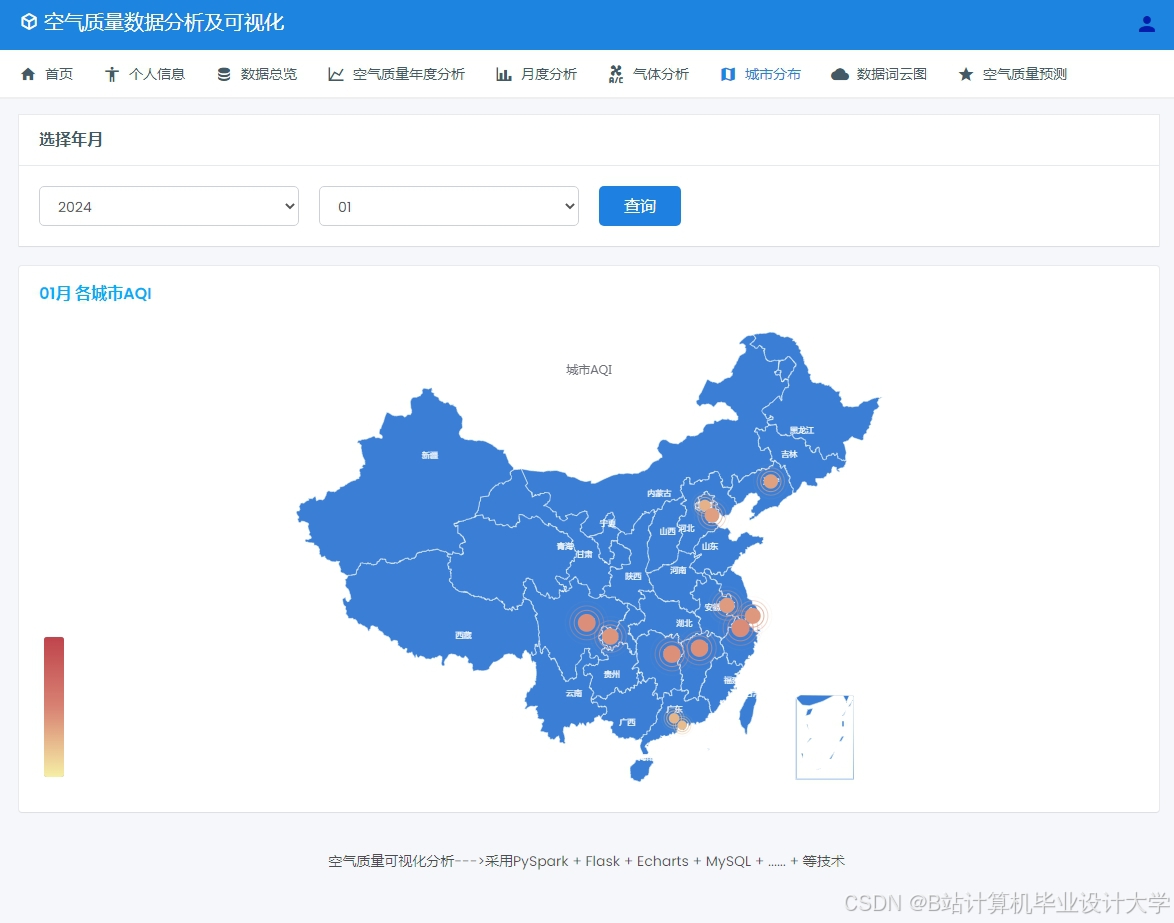
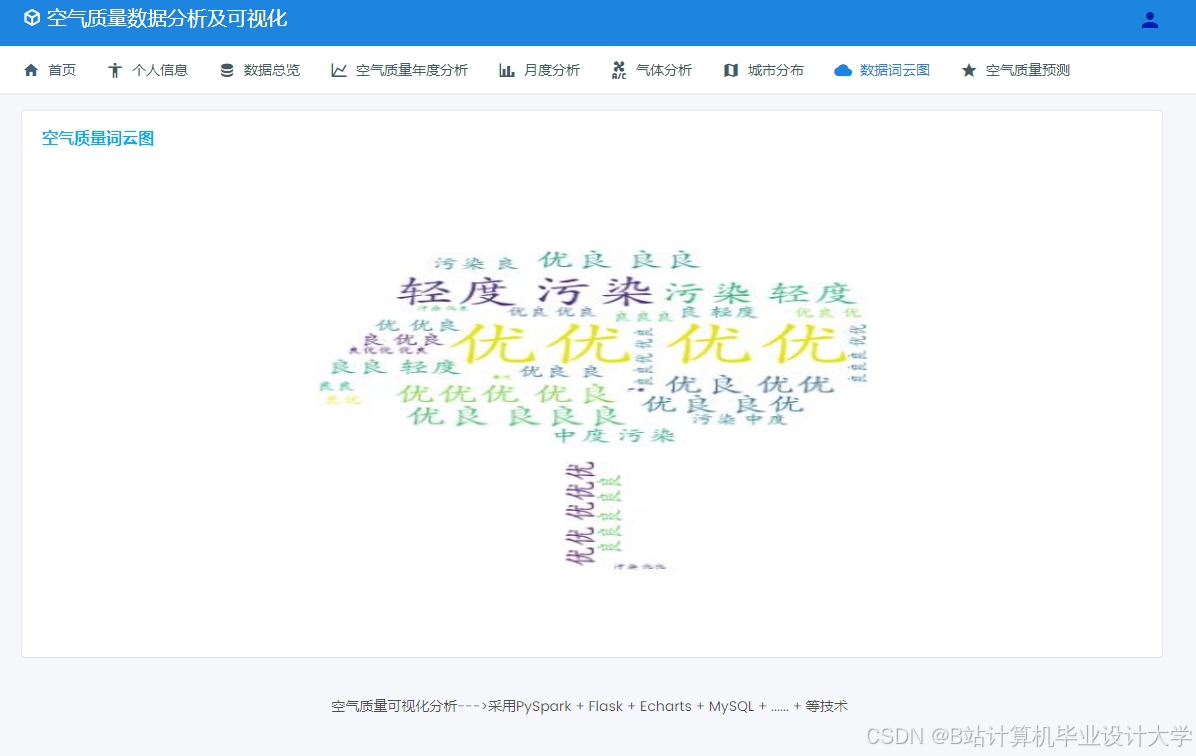




推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











