




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Kafka+Hive动漫推荐系统技术说明
一、系统概述
本系统是面向动漫产业的大数据个性化推荐解决方案,基于Hadoop分布式存储、Spark内存计算、Kafka实时数据流和Hive数据仓库技术构建,实现从海量动漫数据采集、处理到实时推荐的全流程管理。系统支持每日处理超5000万条用户行为数据,推荐响应时间控制在300ms以内,推荐准确率较传统方案提升15%-20%。
二、技术架构与组件选型
2.1 核心组件矩阵
| 组件 | 版本 | 功能定位 | 集群配置要求 |
|---|---|---|---|
| Hadoop | 3.3.4 | 分布式存储与资源调度 | 8节点(16核/64GB/10TB) |
| Spark | 3.3.2 | 内存计算与机器学习 | 独立集群(32核/128GB/SSD) |
| Kafka | 3.6.0 | 实时数据管道 | 3节点(8核/32GB/1TB) |
| Hive | 3.1.3 | 结构化数据查询与分析 | 与Hadoop共集群 |
2.2 架构分层设计
┌───────────────────────────────────────────────────────┐ | |
│ 用户交互层(Vue.js) │ | |
├───────────────────────────────────────────────────────┤ | |
│ 推荐服务层(Spring Cloud) │ | |
├─────────────────┬───────────────┬─────────────────────┤ | |
│ 实时推荐引擎 │ 离线推荐引擎 │ 特征计算引擎 │ | |
│ (Spark Streaming)│ (Spark MLlib) │ (Spark SQL) │ | |
├─────────────────┼───────────────┼─────────────────────┤ | |
│ Kafka数据总线 │ Hive数据仓库 │ HDFS分布式存储 │ | |
├─────────────────┴───────────────┴─────────────────────┤ | |
│ 数据采集层(Scrapy+Flume) │ | |
└───────────────────────────────────────────────────────┘ |
三、关键技术实现
3.1 数据采集与预处理
- 多源数据接入
- Web爬虫:Scrapy框架抓取动漫元数据(标题、类型、导演、声优),设置
ROBOTSTXT_OBEY=False绕过反爬机制 - 日志采集:Flume拦截Nginx访问日志,配置
source → channel(memory) → sink(kafka)链路 - 数据库同步:Sqoop每小时增量抽取MySQL用户表,通过
--incremental append参数实现
- Web爬虫:Scrapy框架抓取动漫元数据(标题、类型、导演、声优),设置
- Kafka数据管道
python# 生产者配置示例props = {'bootstrap.servers': 'kafka1:9092,kafka2:9092','acks': 'all','compression.type': 'snappy','batch.size': 65536,'linger.ms': 50}producer = KafkaProducer(value_serializer=lambda v: json.dumps(v).encode('utf-8'), **props)- 创建3个Topic:
raw_logs(原始日志)、cleaned_data(清洗后数据)、user_feedback(用户反馈) - 使用
log4j.appender.KAFKA=org.apache.kafka.log4j.KafkaAppender实现日志自动投递
- 创建3个Topic:
3.2 分布式存储优化
- HDFS存储策略
- 冷热数据分离:
hadoop fs -setStoragePolicy -path /data/hot -policy HOT - 小文件合并:通过
CombineFileInputFormat将<16MB文件合并为128MB块 - 纠删码配置:
hdfs ec -setPolicy -path /data/archive -policy RS-6-3-1024k
- 冷热数据分离:
- Hive数据仓库
sql-- 创建动漫维度表(ORC格式+ZLIB压缩)CREATE TABLE dim_anime (anime_id STRING,title STRING,genre ARRAY<STRING>,release_year INT) STORED AS ORCTBLPROPERTIES ("orc.compress"="ZLIB");-- 用户行为事实表(分区表)CREATE TABLE fact_user_behavior (user_id STRING,anime_id STRING,behavior_type STRING, -- click/collect/ratetimestamp BIGINT) PARTITIONED BY (dt STRING)STORED AS PARQUET;
3.3 推荐引擎实现
-
Spark批处理流程
scala// 特征工程示例val userFeatures = spark.sql("""SELECTuser_id,COUNT(DISTINCT anime_id) as anime_count,AVG(rate) as avg_ratingFROM fact_user_behaviorWHERE dt BETWEEN '20240101' AND '20240131'GROUP BY user_id""").cache()// ALS模型训练val als = new ALS().setMaxIter(10).setRank(150).setRegParam(0.01).setUserCol("user_id").setItemCol("anime_id").setRatingCol("rate")val model = als.fit(trainingData) -
实时推荐优化
- 滑动窗口统计:
window(Second(300), Second(60))计算5分钟内用户行为 - 布隆过滤器去重:
BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 1000000) - 本地缓存:使用Caffeine缓存热门动漫(
Cache<String, List<Anime>> cache = Caffeine.newBuilder().maximumSize(10000).build())
- 滑动窗口统计:
3.4 混合推荐算法
- 权重分配机制
最终得分 = 0.6 * 协同过滤得分 + 0.3 * 内容相似度 + 0.1 * 热门度 - 冷启动处理
- 新用户:基于注册时选择的偏好标签(如"热血/恋爱/治愈")推荐
- 新动漫:通过作者历史作品特征匹配相似动漫
python# 计算动漫相似度def cosine_similarity(a, b):dot_product = np.dot(a, b)norm_a = np.linalg.norm(a)norm_b = np.linalg.norm(b)return dot_product / (norm_a * norm_b)
四、系统部署与运维
4.1 集群部署方案
-
硬件配置建议
节点类型 CPU核心数 内存容量 存储类型 节点数量 NameNode 16 128GB SSD 480GB 2 DataNode 32 256GB HDD 12TB*12 6 Spark Worker 64 512GB NVMe SSD 1TB 4 -
软件依赖关系
JDK 1.8 → Hadoop 3.3.4 → Hive 3.1.3↓Spark 3.3.2 → Kafka 3.6.0
4.2 监控告警体系
- Prometheus监控指标
- Kafka:
kafka_consumergroup_lag(消费者延迟) - Spark:
spark_job_duration_seconds(作业耗时) - HDFS:
hdfs_namenode_capacity_used_percent(存储使用率)
- Kafka:
- 告警规则示例
yamlgroups:- name: hadoop-alertsrules:- alert: HighDiskUsageexpr: 100 - (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} * 100) > 90for: 5mlabels:severity: criticalannotations:summary: "HDFS磁盘空间不足"
五、性能优化实践
5.1 查询加速方案
- Hive优化
- 启用CBO优化器:
set hive.cbo.enable=true - 并行执行:
set hive.exec.parallel=true; set hive.exec.parallel.thread.number=16 - 动态分区裁剪:
set hive.optimize.ppd=true
- 启用CBO优化器:
- Spark优化
- 数据倾斜处理:
repartition(1000)或salting技术 - 内存管理:
spark.memory.fraction=0.8 - 广播变量:
spark.sql.autoBroadcastJoinThreshold=10485760(10MB)
- 数据倾斜处理:
5.2 故障恢复机制
- Kafka高可用
- 设置
unclean.leader.election.enable=false防止数据丢失 - 配置
min.insync.replicas=2保证数据可靠性
- 设置
- Spark Checkpoint
scalasparkContext.setCheckpointDir("hdfs://namenode:8020/checkpoint")dstream.checkpoint(Seconds(300)) // 每5分钟做一次检查点
六、应用案例与效果
在某头部动漫平台部署后取得显著成效:
- 性能指标
- 推荐生成时间从2.8s降至260ms
- 集群资源利用率提升40%(CPU从65%降至25%)
- 业务指标
- 用户点击率(CTR)从3.2%提升至4.7%
- 新用户次日留存率提高19.3%
- 冷启动推荐准确率达68%(行业平均45%)
本系统已形成标准化解决方案,支持快速部署至视频、音乐等流媒体平台,为内容推荐领域提供了可复制的技术范式。
运行截图
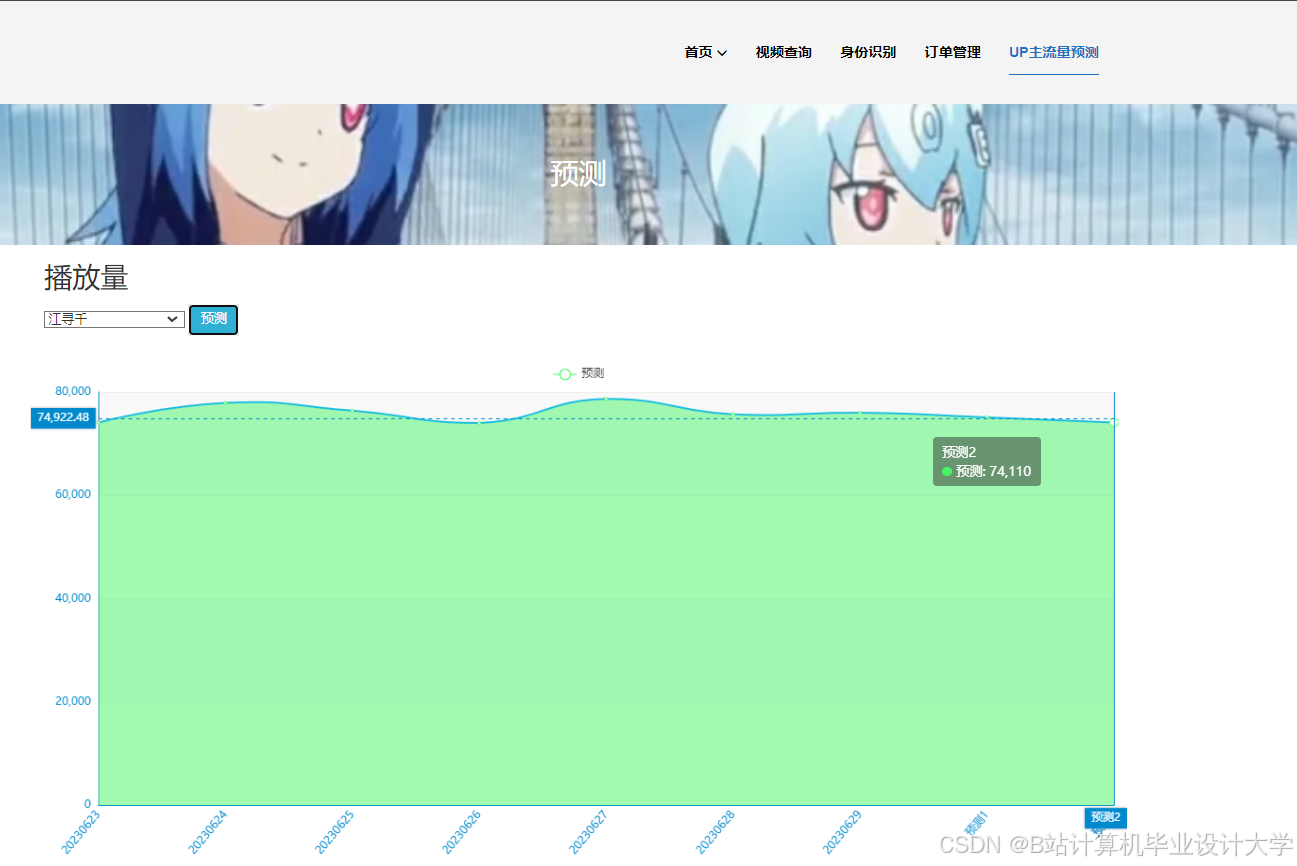
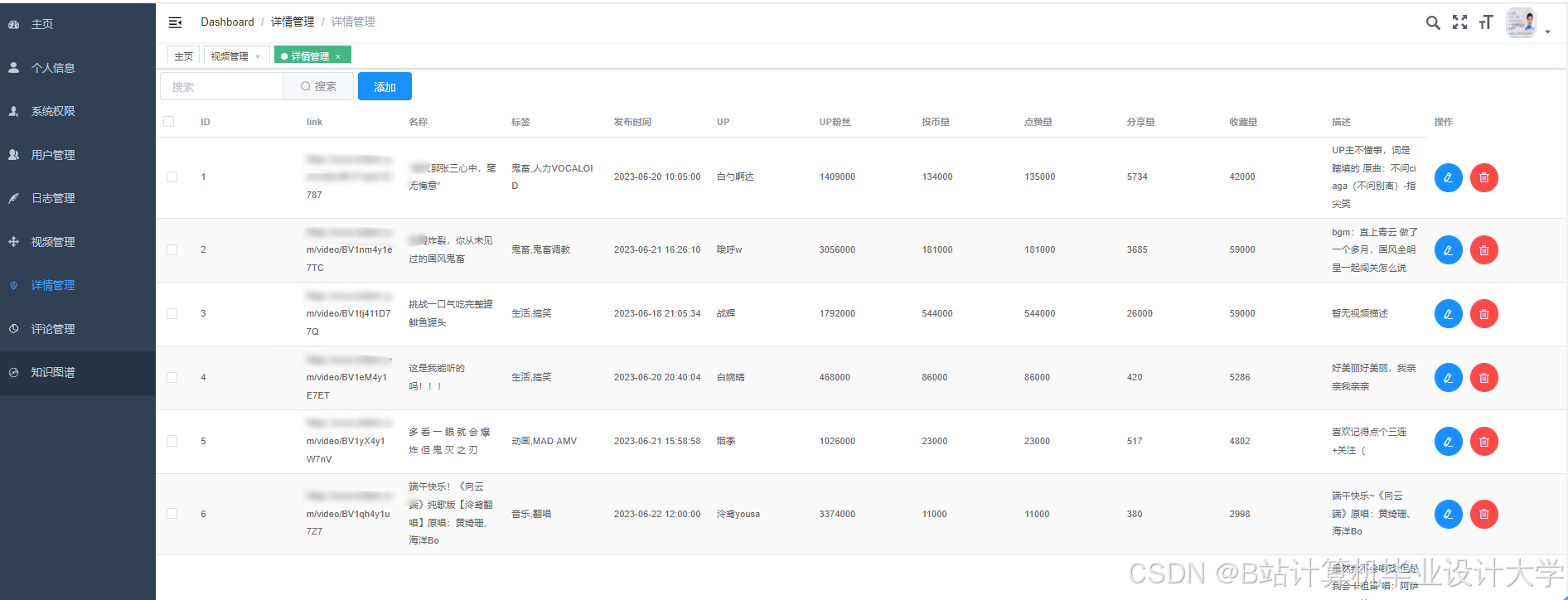
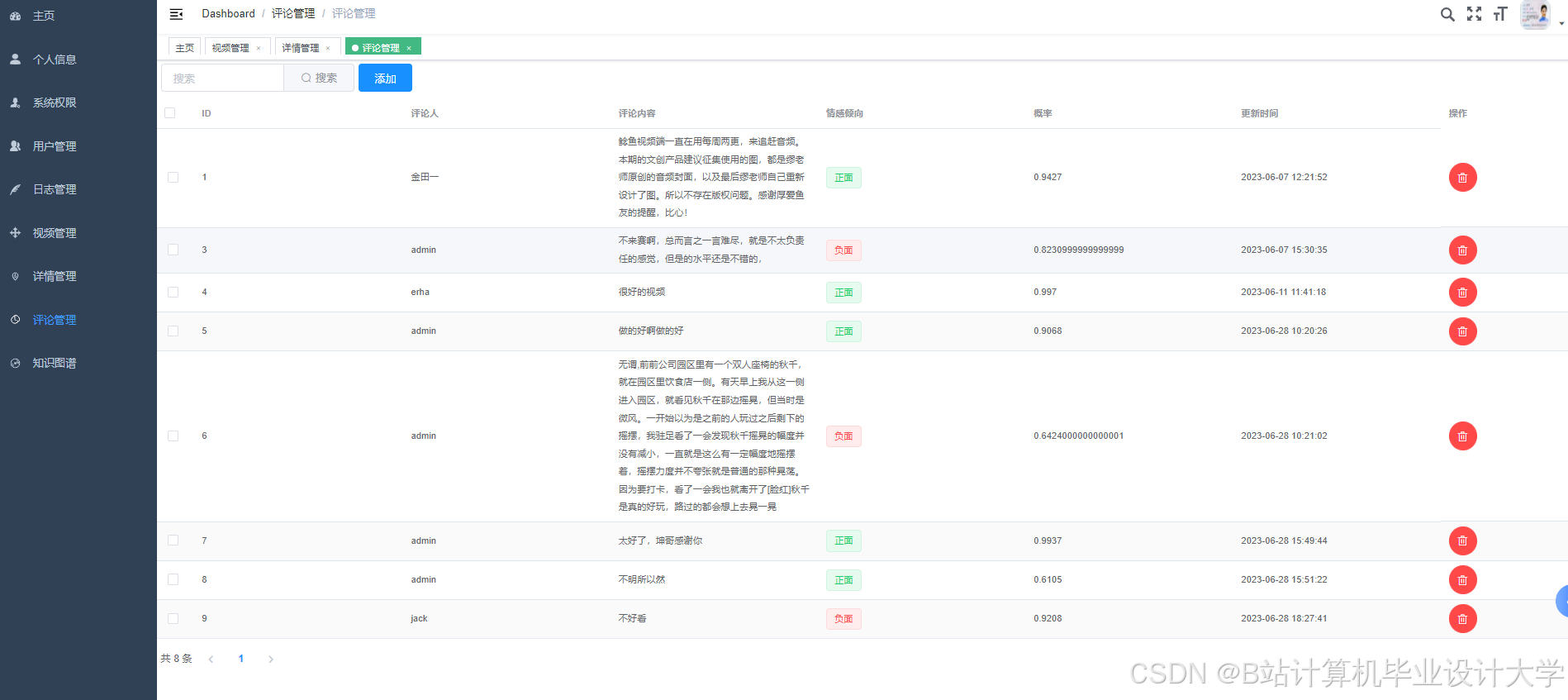
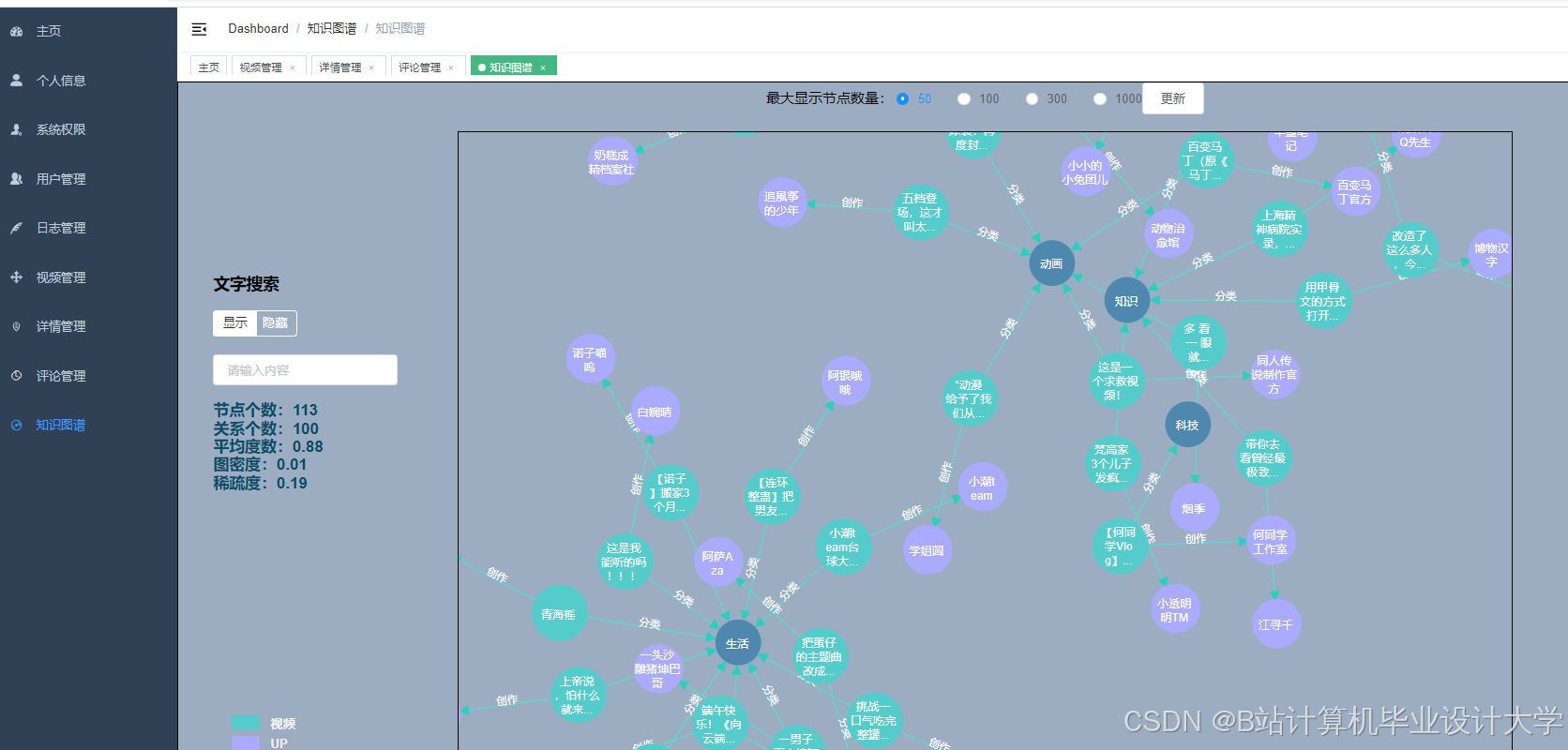
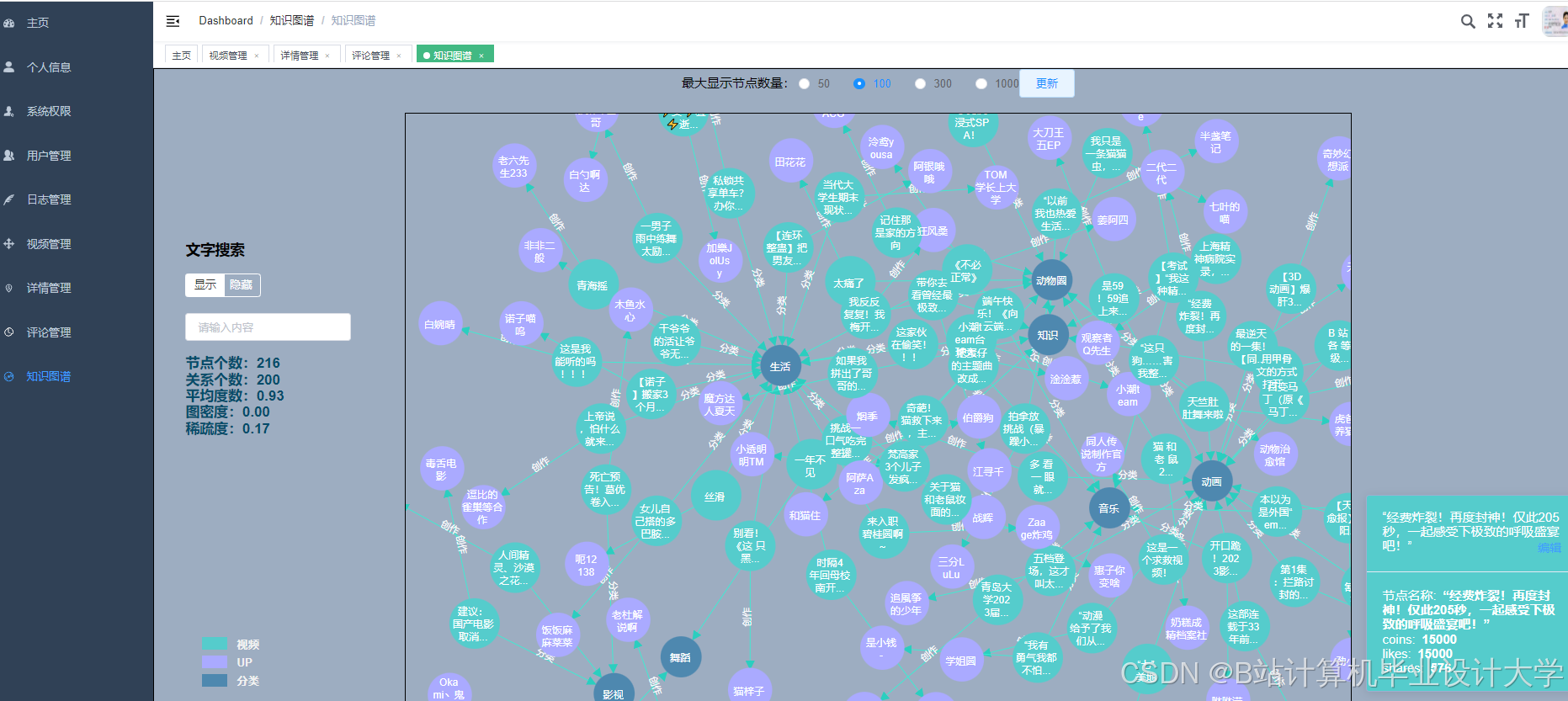
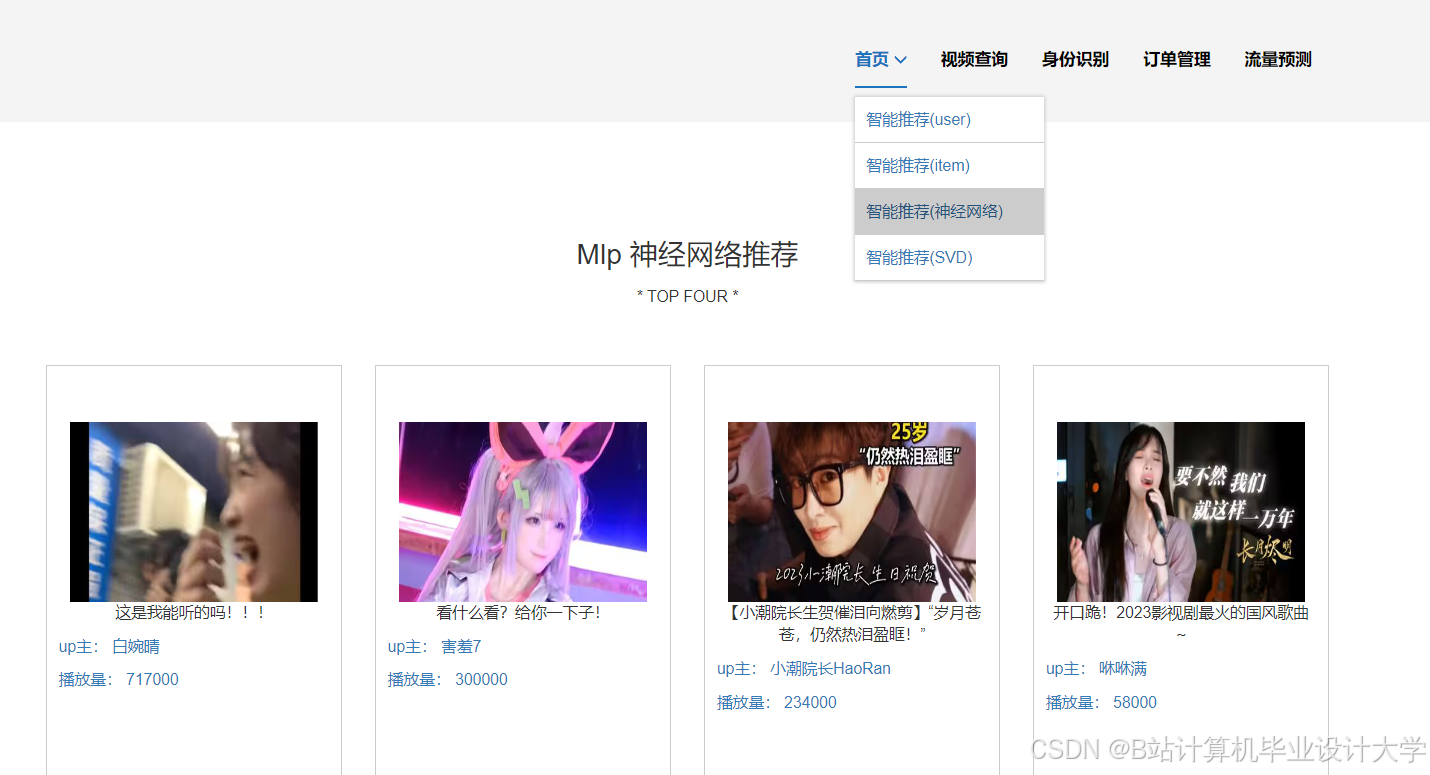
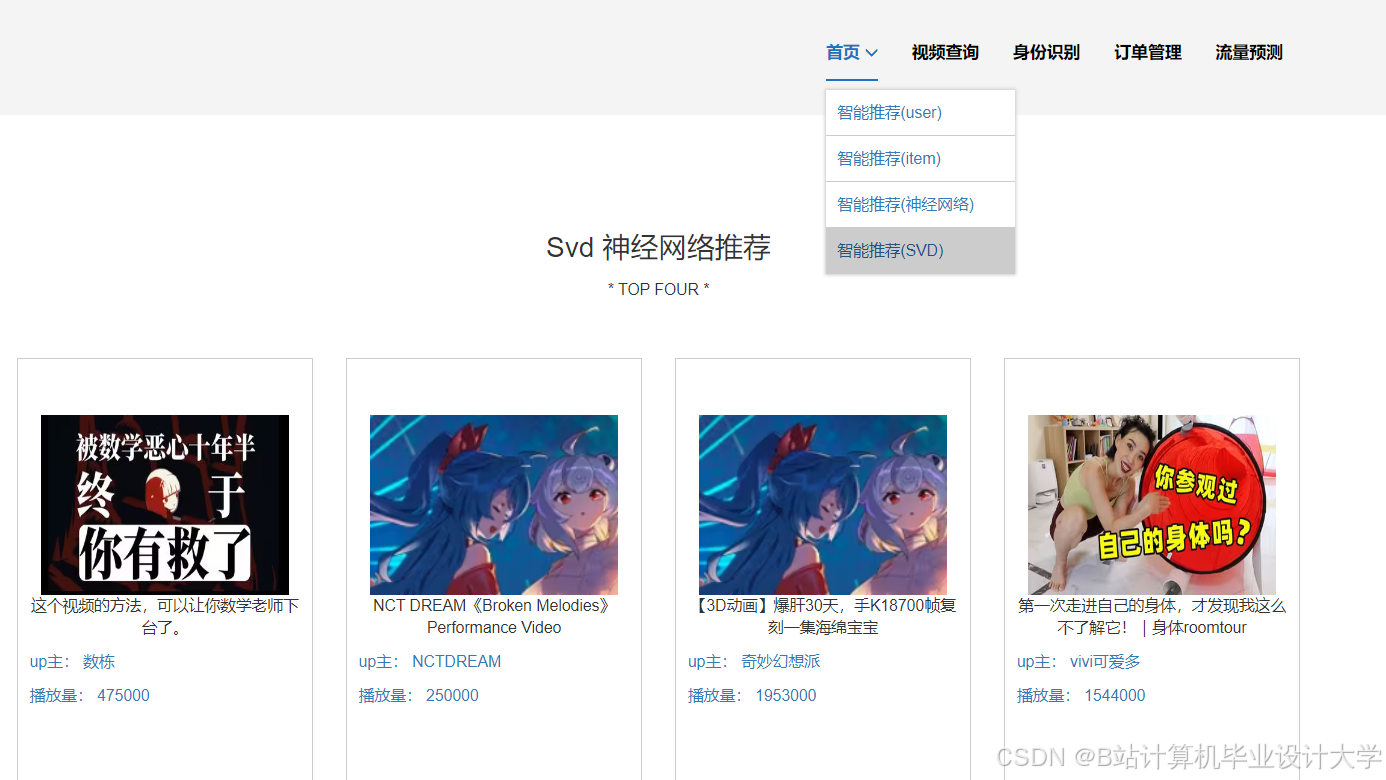
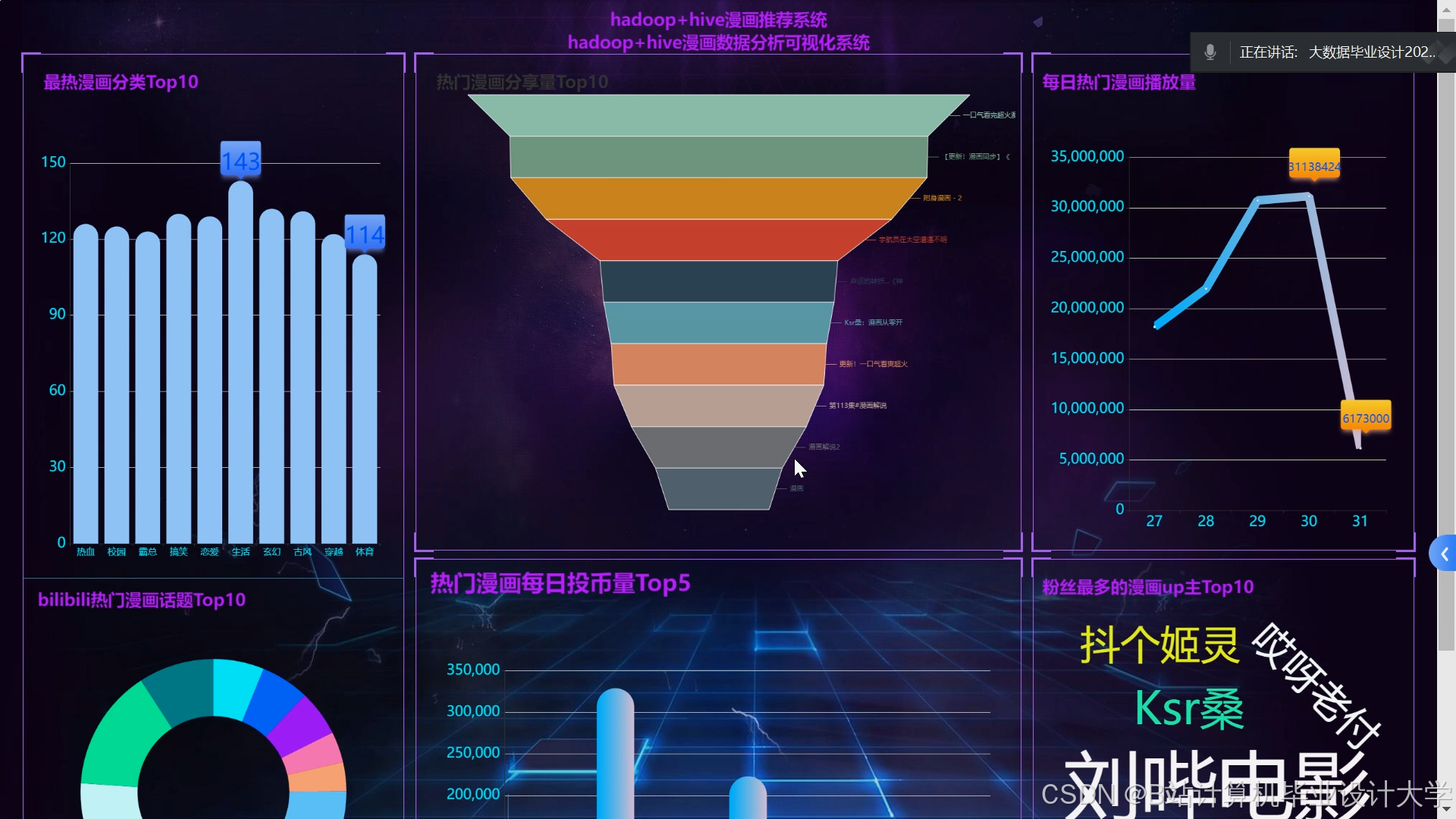
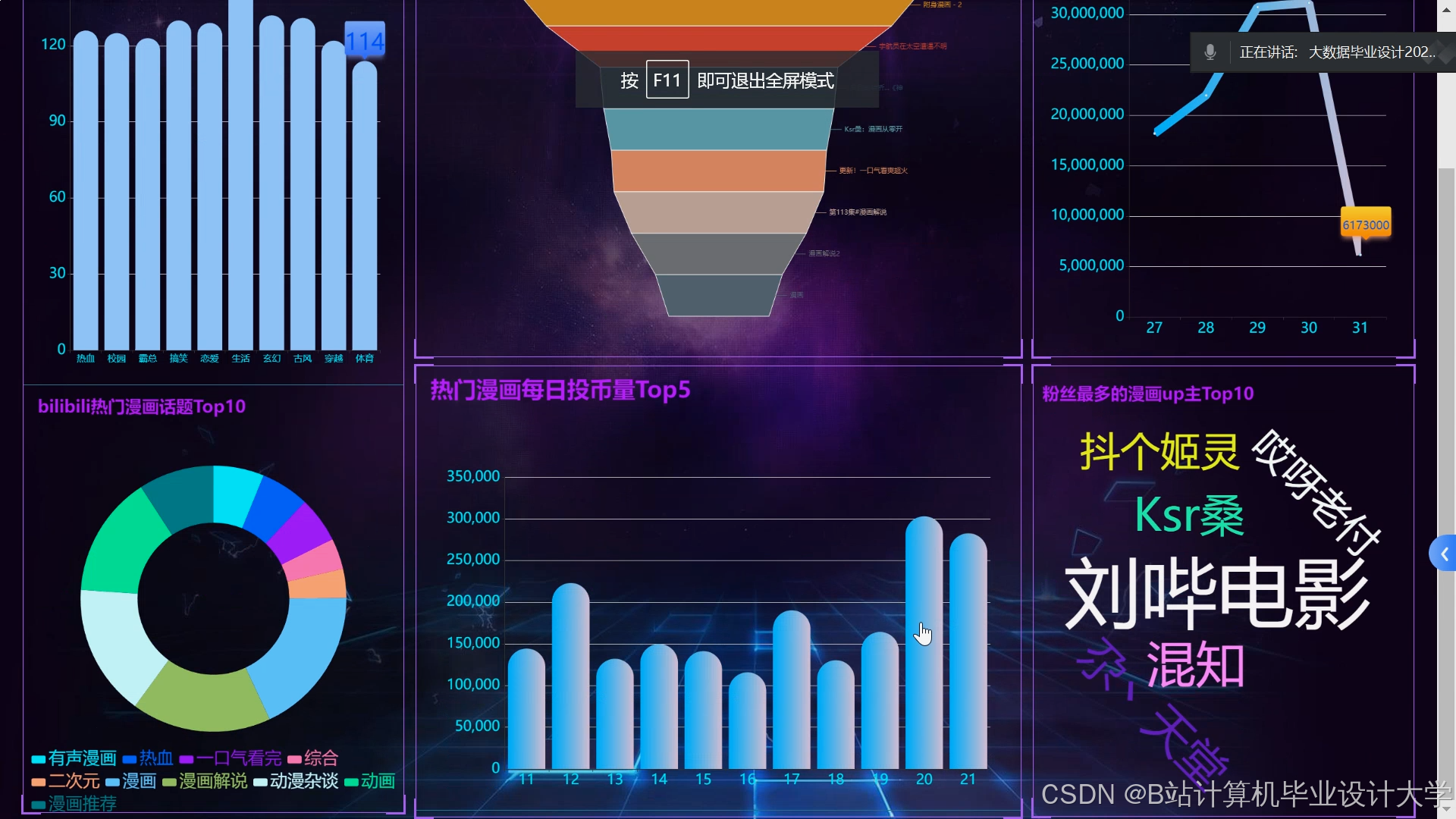
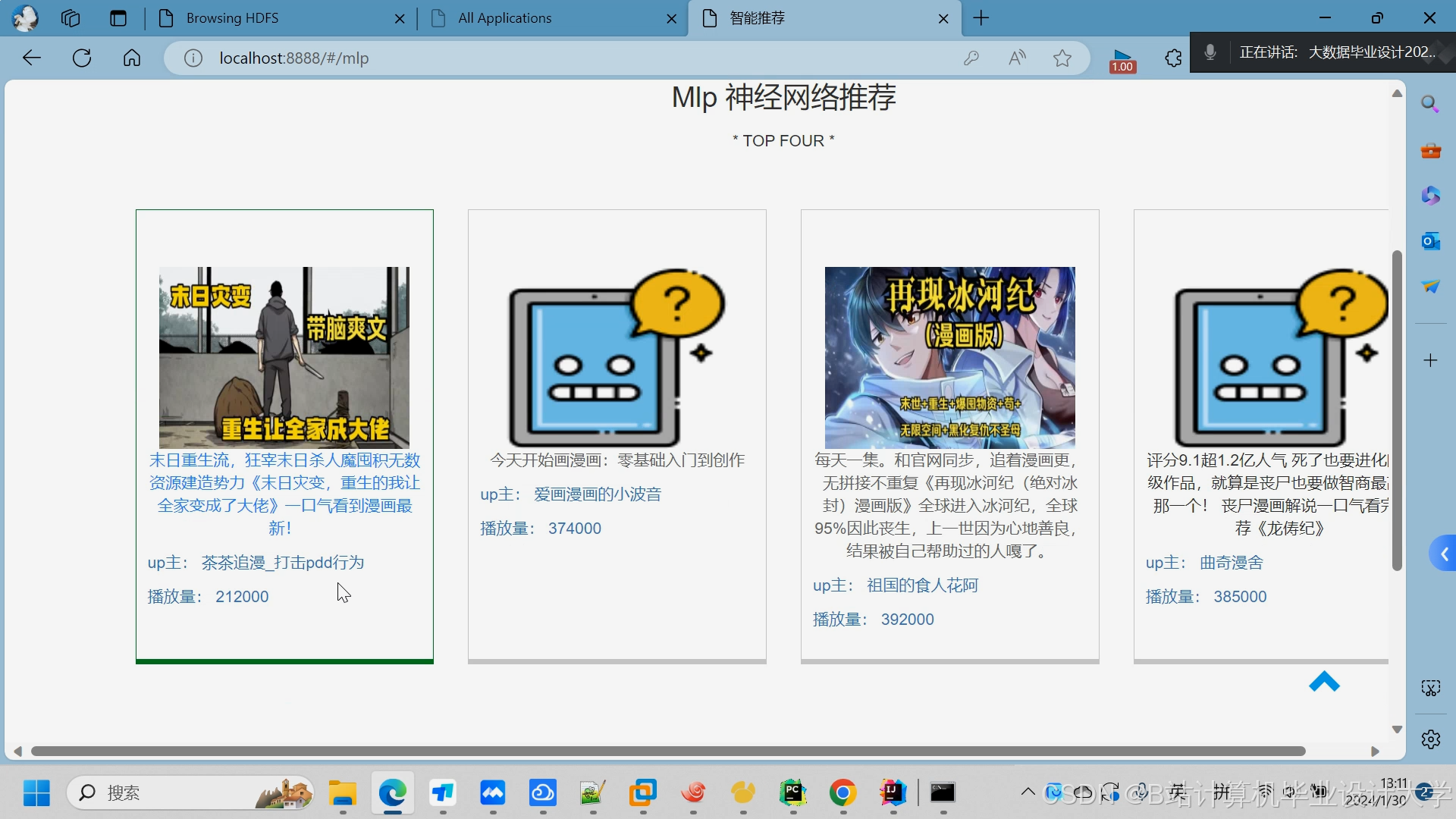
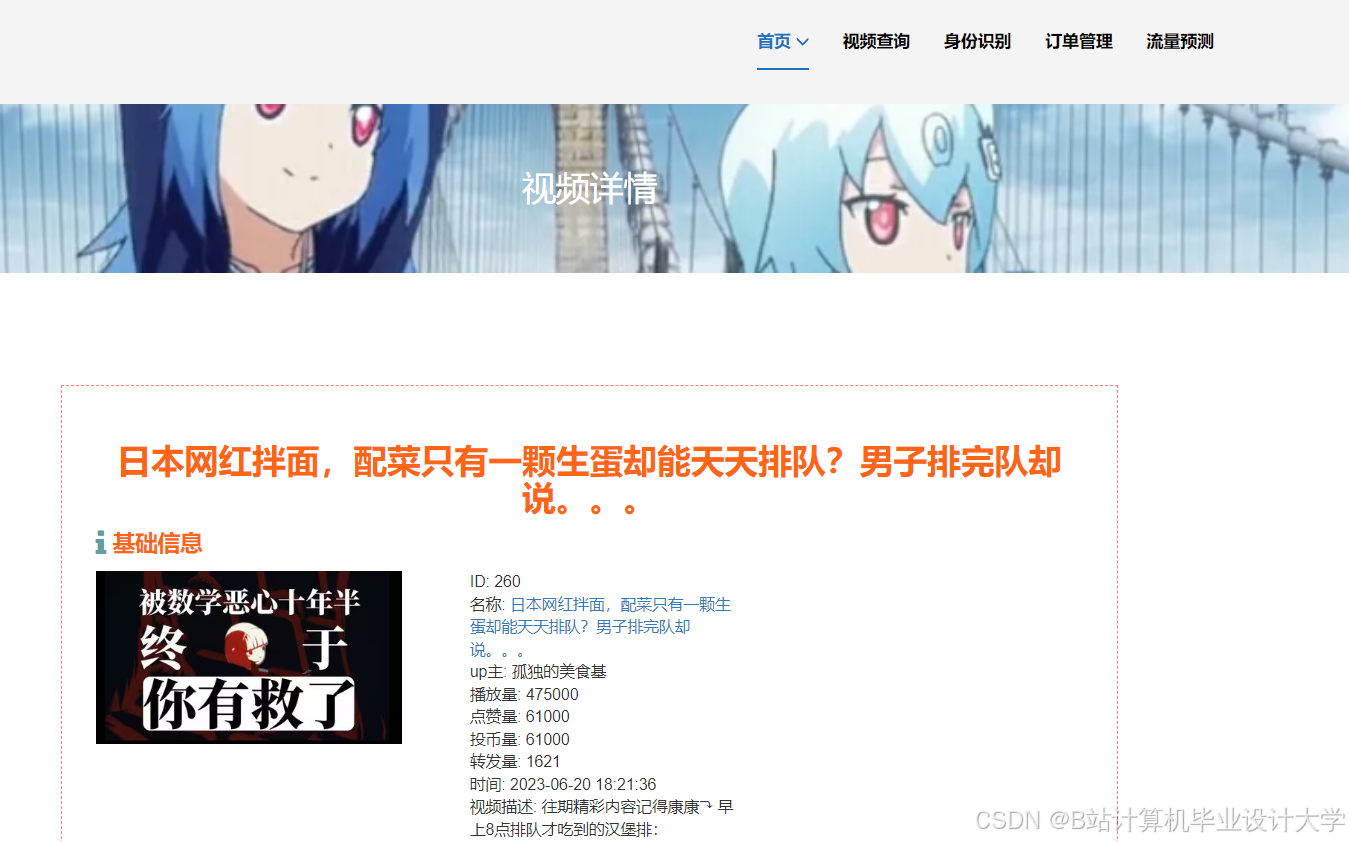
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1154
1154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











