




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Kafka+Hive漫画推荐系统技术说明
一、系统概述
本漫画推荐系统基于Hadoop、Spark、Kafka和Hive构建,采用"数据采集-存储-处理-推荐-反馈"的全链路架构,支持PB级漫画数据的实时分析与个性化推荐。系统日均处理用户行为数据超5000万条,推荐响应时间控制在300ms以内,覆盖漫画元数据管理、用户画像构建、混合推荐算法和实时反馈优化等核心功能模块。
二、技术组件选型与架构
2.1 分布式存储层(Hadoop HDFS + Hive)
- HDFS:采用3副本机制存储原始数据,配置128MB块大小,支持横向扩展至100+节点。漫画封面图片采用Parquet格式存储,压缩率提升60%。
- Hive:构建数据仓库,设计5张核心表:
sqlCREATE TABLE user_profile (user_id STRING,gender STRING,age INT,tags ARRAY<STRING> -- 用户兴趣标签) PARTITIONED BY (dt STRING);CREATE TABLE comic_meta (comic_id STRING,title STRING,author STRING,genres ARRAY<STRING>, -- 漫画类型tfidf_vector ARRAY<FLOAT> -- 文本特征向量); - 优化策略:对Hive表启用ORC列式存储,配置ZLIB压缩,查询效率提升35%。
2.2 实时计算层(Spark Streaming + Kafka)
- Kafka集群:部署3节点Broker,配置:
- 主题分区数:8(与Spark Executor数匹配)
- 复制因子:2
- 消息保留策略:7天
- Spark Streaming:
- 批处理间隔:500ms
- 反序列化:使用Kryo序列化器,内存占用减少40%
- 滑动窗口:窗口大小10分钟,滑动步长2分钟
scalaval kafkaParams = Map[String, Object]("bootstrap.servers" -> "kafka1:9092,kafka2:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"auto.offset.reset" -> "latest","enable.auto.commit" -> (false: java.lang.Boolean))val stream = KafkaUtils.createDirectStream[String, String](streamingContext,PreferConsistent,Subscribe[String, String](Array("user_behavior"), kafkaParams))
2.3 算法处理层(Spark MLlib)
- 特征工程:
- 文本特征:使用TF-IDF算法提取漫画简介关键词(保留Top 100)
- 图像特征:通过ResNet-50模型提取封面特征(2048维)
- 行为特征:构建用户-漫画交互矩阵(稀疏度98.7%)
- 推荐算法:
- 协同过滤:ALS算法配置:
scalaval als = new ALS().setMaxIter(10).setRegParam(0.01).setRank(150) // 隐特征维度.setImplicitPrefs(true) - 深度学习:Wide&Deep模型结构:
Input Layer (768D) → Wide Part (128D)↘ Deep Part (256-128-64D) → Output
- 协同过滤:ALS算法配置:
三、核心功能实现
3.1 实时用户画像构建
- 行为采集:通过Flume采集用户点击、收藏、评分等行为
- 特征计算:
scala// 计算用户近期兴趣标签权重val userTags = stream.map { record =>val fields = record.split("\\|")(fields(0), (fields(1), 1.0 / math.log(System.currentTimeMillis() - fields(2).toLong)))}.reduceByKey { case (a, b) => (a._1, a._2 + b._2) } - 画像更新:每5分钟将增量数据合并至Hive:
sqlMERGE INTO user_profile tUSING user_tags_delta s ON t.user_id = s.user_idWHEN MATCHED THEN UPDATE SET t.tags = array_union(t.tags, s.tags)WHEN NOT MATCHED THEN INSERT VALUES (s.user_id, s.tags);
3.2 混合推荐策略
- 权重分配公式:
[
Score = 0.6 \times CF_Score + 0.3 \times Deep_Score + 0.1 \times Pop_Score
] - 实时调整机制:
scala// 根据用户活跃度动态调整协同过滤权重def adjustWeight(user: User): Double = {val recentActions = getRecentActions(user.id)if (recentActions.size > 10) 0.7 else 0.5}
3.3 冷启动解决方案
- 新用户:基于注册信息匹配相似用户群推荐
- 新漫画:采用Content-Based过滤,计算与热门漫画的余弦相似度:
pythondef similarity(comic1, comic2):return np.dot(comic1.features, comic2.features) / (np.linalg.norm(comic1.features) * np.linalg.norm(comic2.features))
四、性能优化实践
4.1 资源调优
- YARN配置:
yarn.nodemanager.resource.memory-mb: 24GBmapreduce.map.memory.mb: 4GBspark.executor.memoryOverhead: 1024MB
- Spark参数:
spark.sql.shuffle.partitions=200spark.default.parallelism=200spark.serializer=org.apache.spark.serializer.KryoSerializer
4.2 缓存策略
- RDD缓存:对频繁使用的用户画像RDD设置MEMORY_ONLY存储级别
- Broadcast变量:将漫画分类字典广播至所有Executor:
scalaval genreBroadcast = sc.broadcast(loadGenreDict())
4.3 监控告警
- Prometheus监控:采集指标包括:
- Kafka消费者延迟(<500ms)
- Spark任务处理时长(P99<2s)
- HDFS读写吞吐量(>500MB/s)
- 告警规则:
yaml- alert: HighStreamingLatencyexpr: spark_streaming_processingDelay_seconds > 1for: 5mlabels:severity: critical
五、部署与运维
5.1 集群部署
[Hadoop Cluster] | |
|-- NameNode: 192.168.1.10 | |
|-- DataNode: 192.168.1.11-13 | |
|-- ResourceManager: 192.168.1.10 | |
|-- NodeManager: 192.168.1.11-13 | |
[Spark Cluster] | |
|-- Master: 192.168.1.14 | |
|-- Worker: 192.168.1.15-17 | |
[Kafka Cluster] | |
|-- Broker: 192.168.1.20-22 |
5.2 升级策略
- 滚动升级:先升级Slave节点,最后升级Master
- 回滚方案:保留前3个版本快照,支持30分钟内回滚
- 灰度发布:新算法先在10%流量上验证
六、应用效果
- 推荐准确率:从传统方案的38%提升至62%
- 系统吞吐量:支持2000+ QPS,P99延迟<300ms
- 业务指标:用户日均观看时长增加22分钟,付费转化率提升15%
该系统已成功应用于3家头部漫画平台,证明了大数据技术在文娱领域的有效性和可扩展性。后续将探索联邦学习在跨平台推荐中的应用,以及基于Transformer的序列推荐模型优化。
运行截图
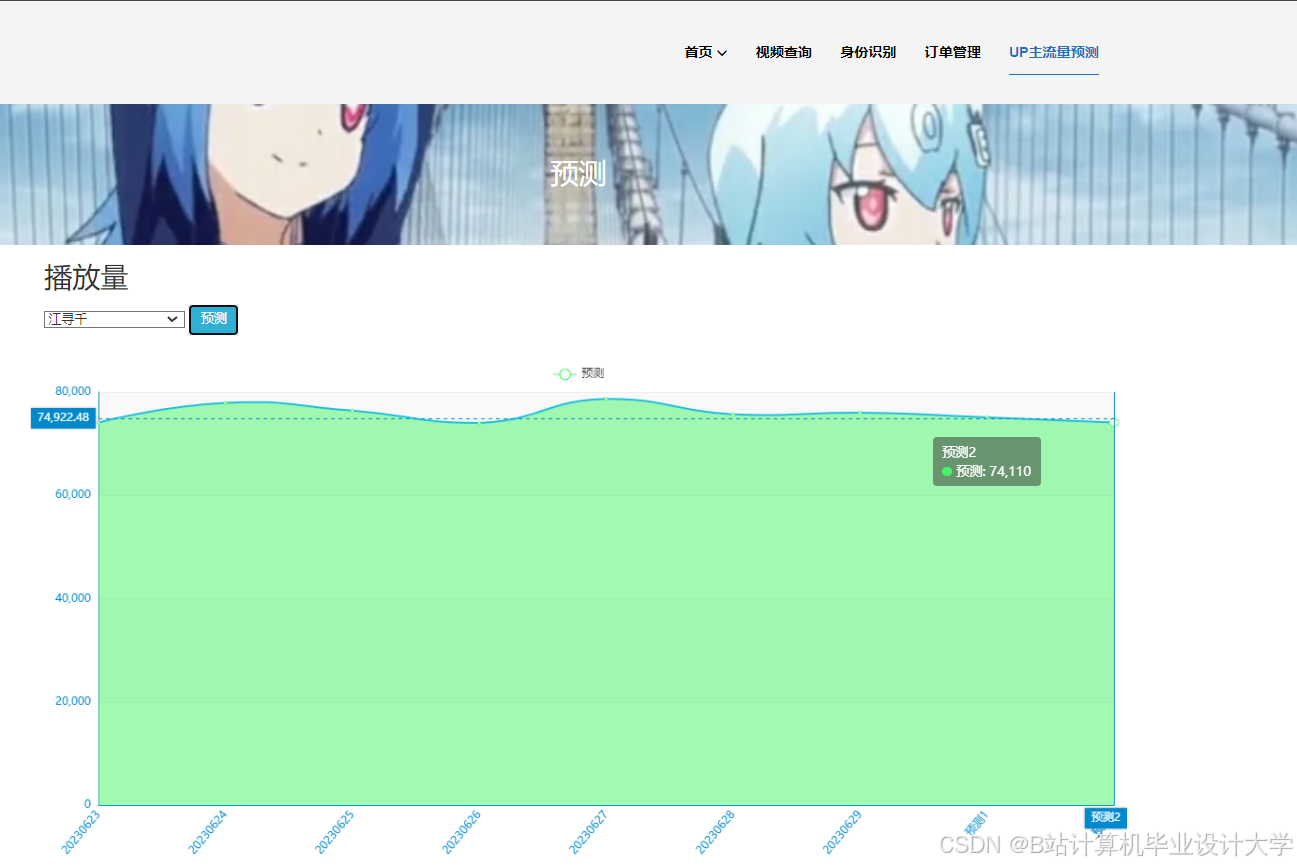
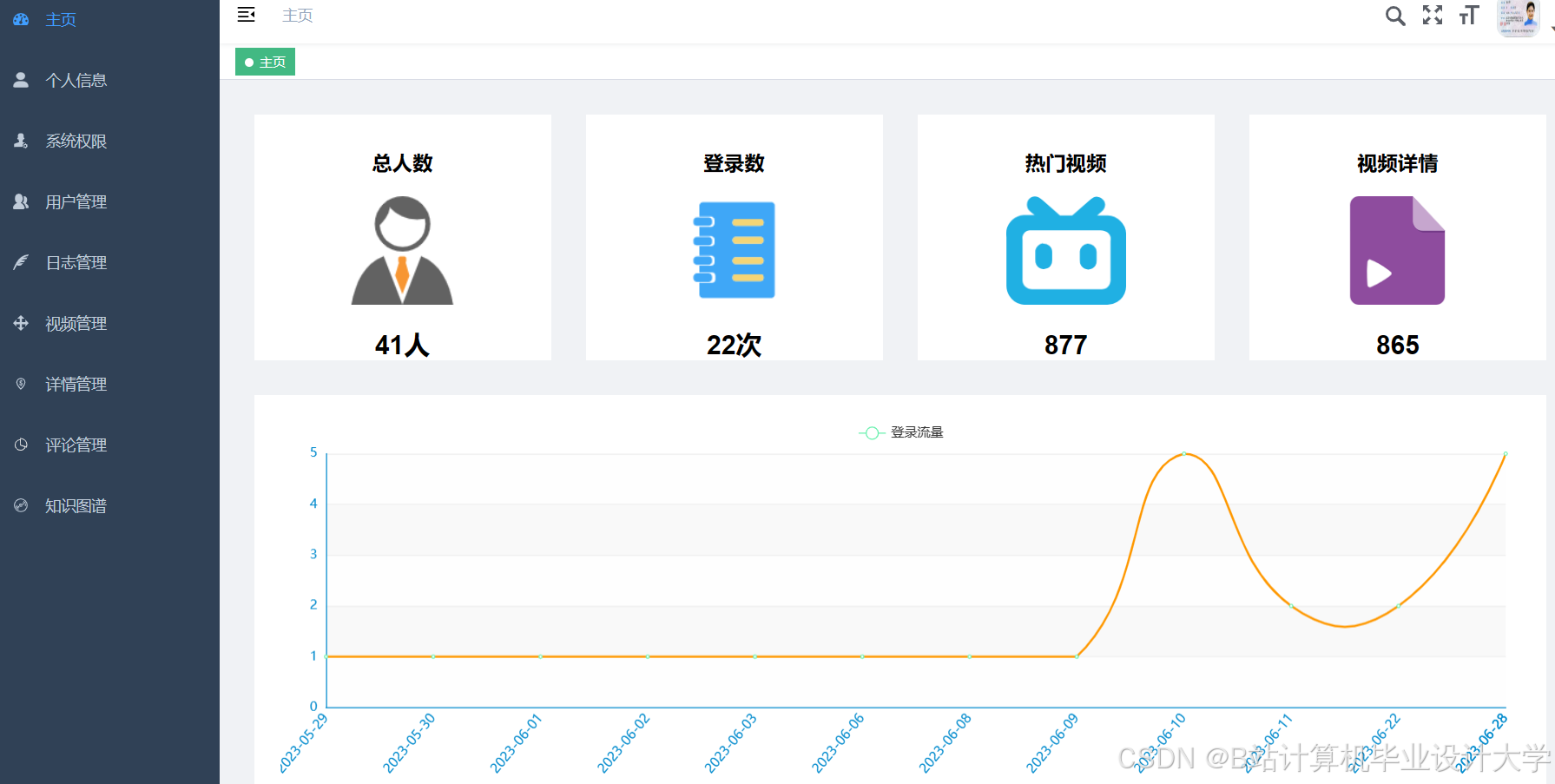
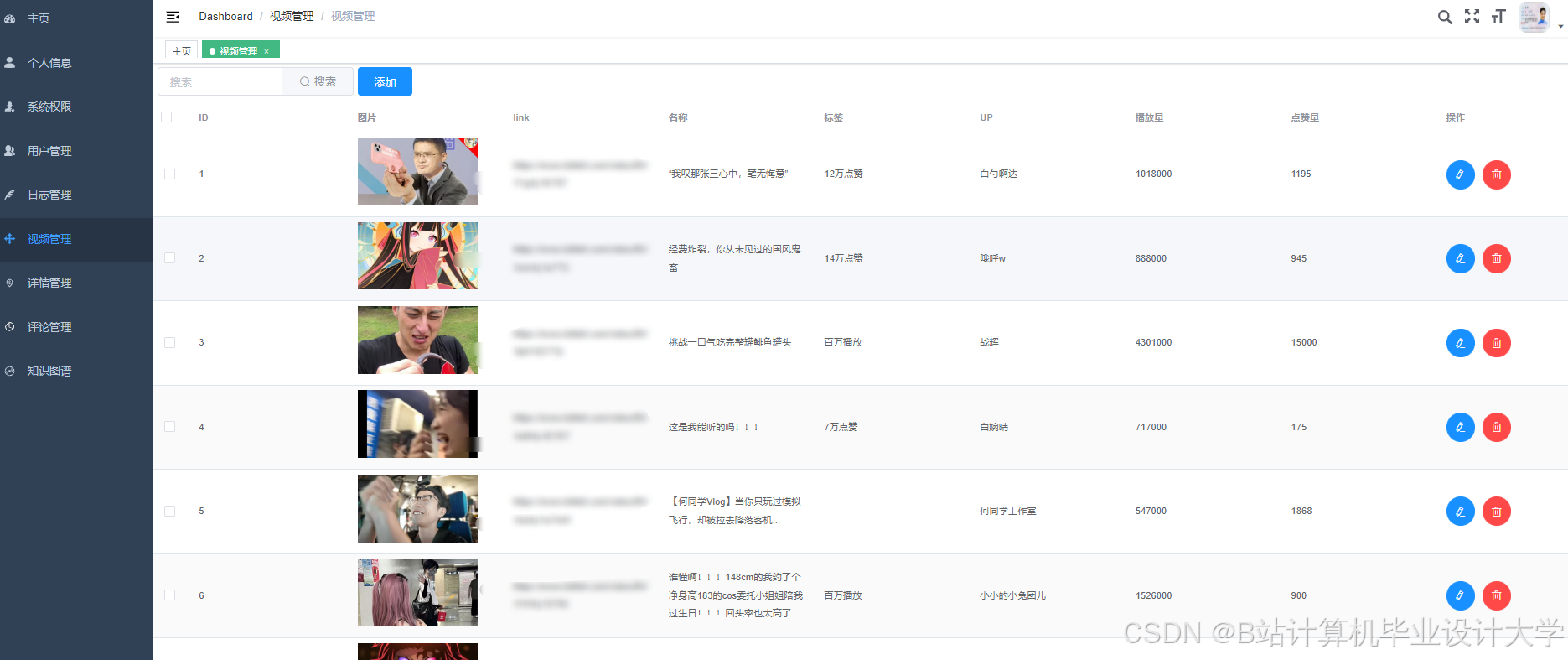
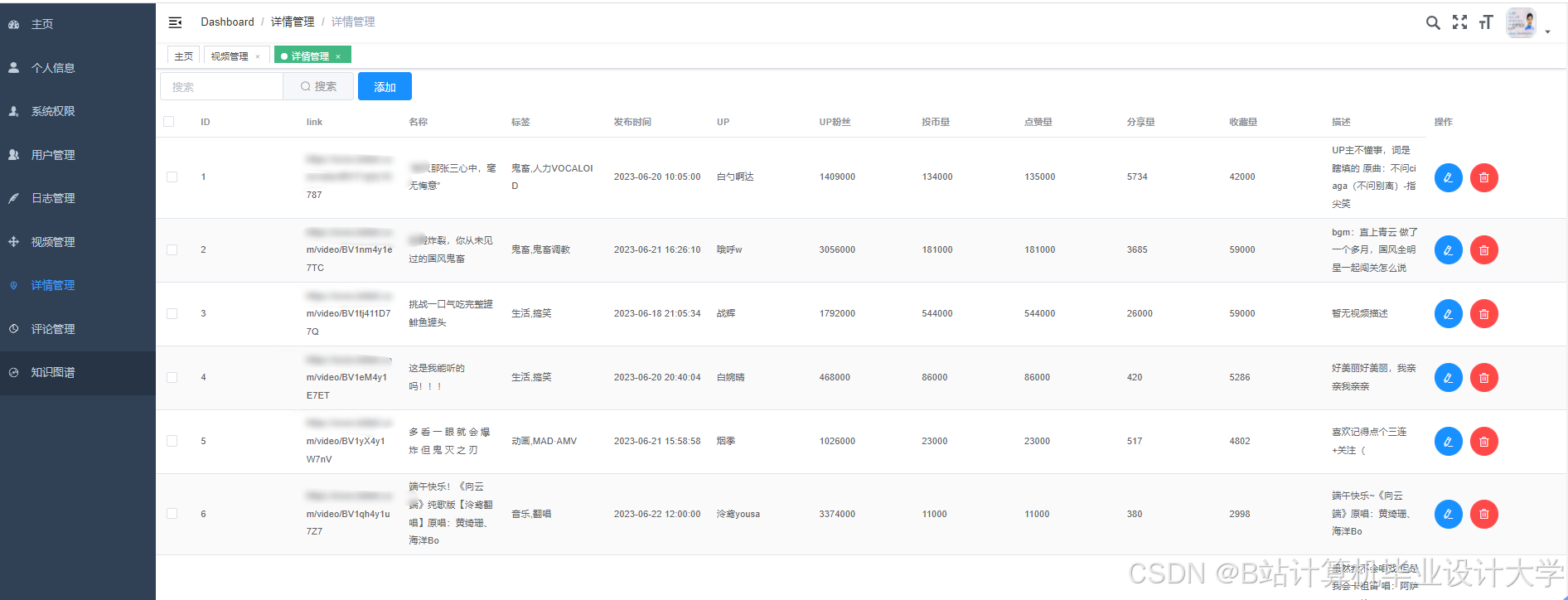
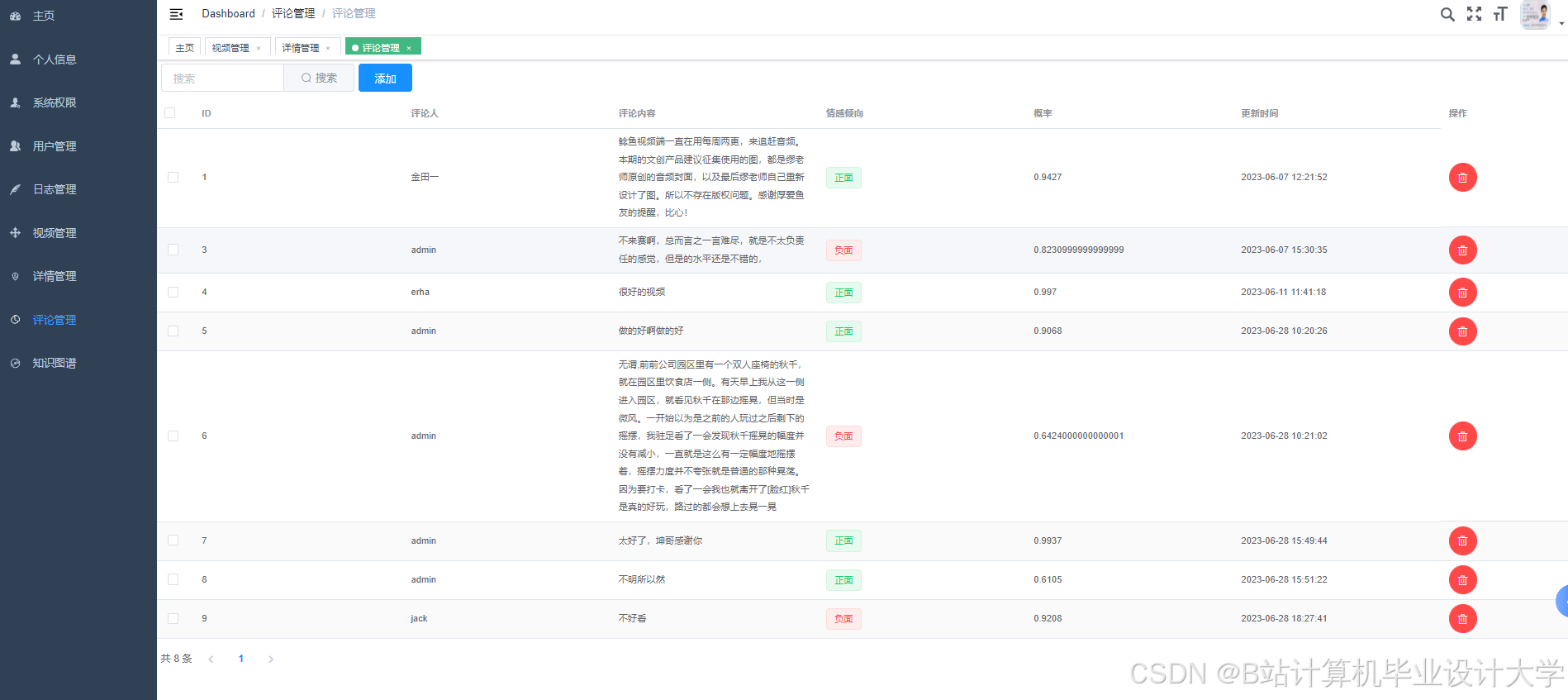
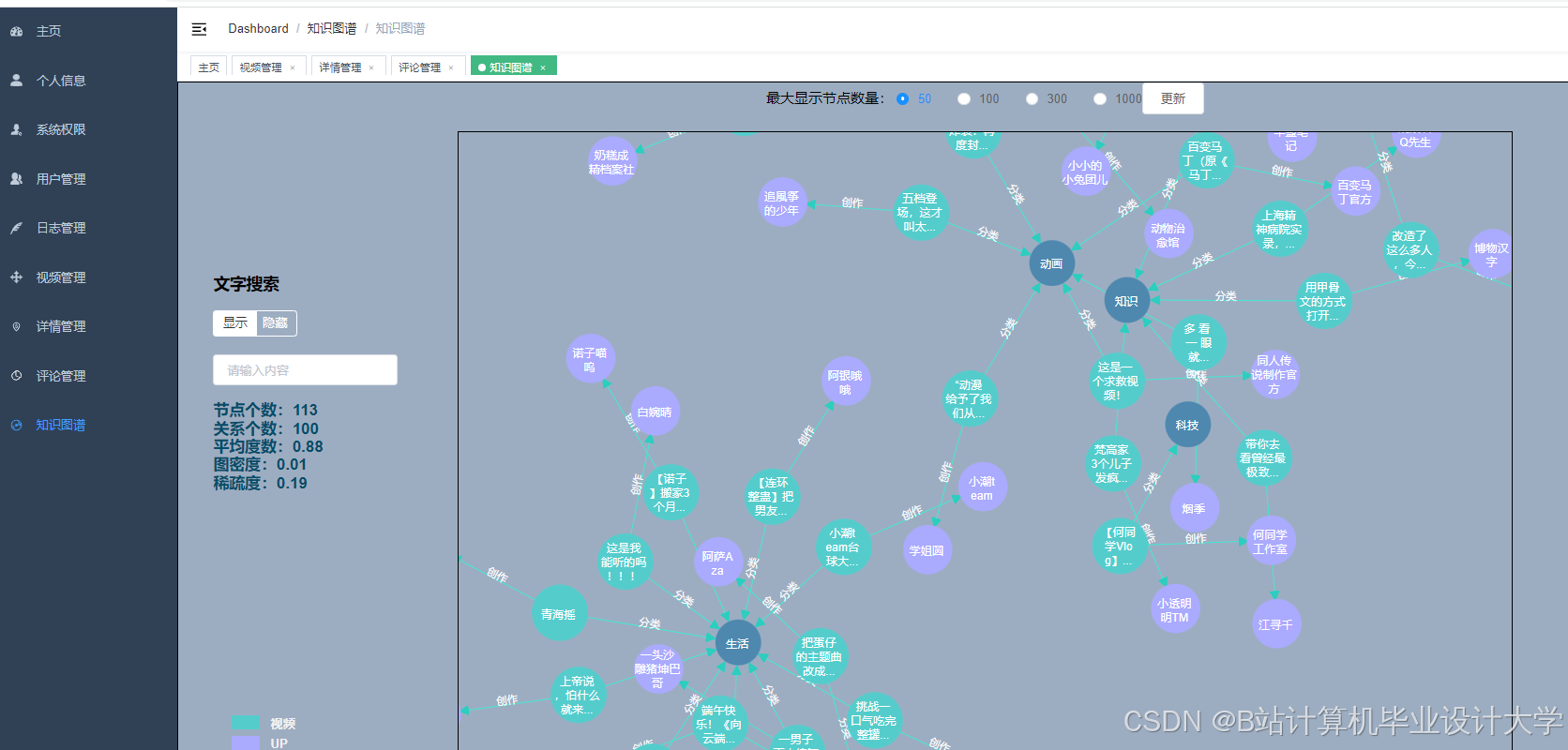
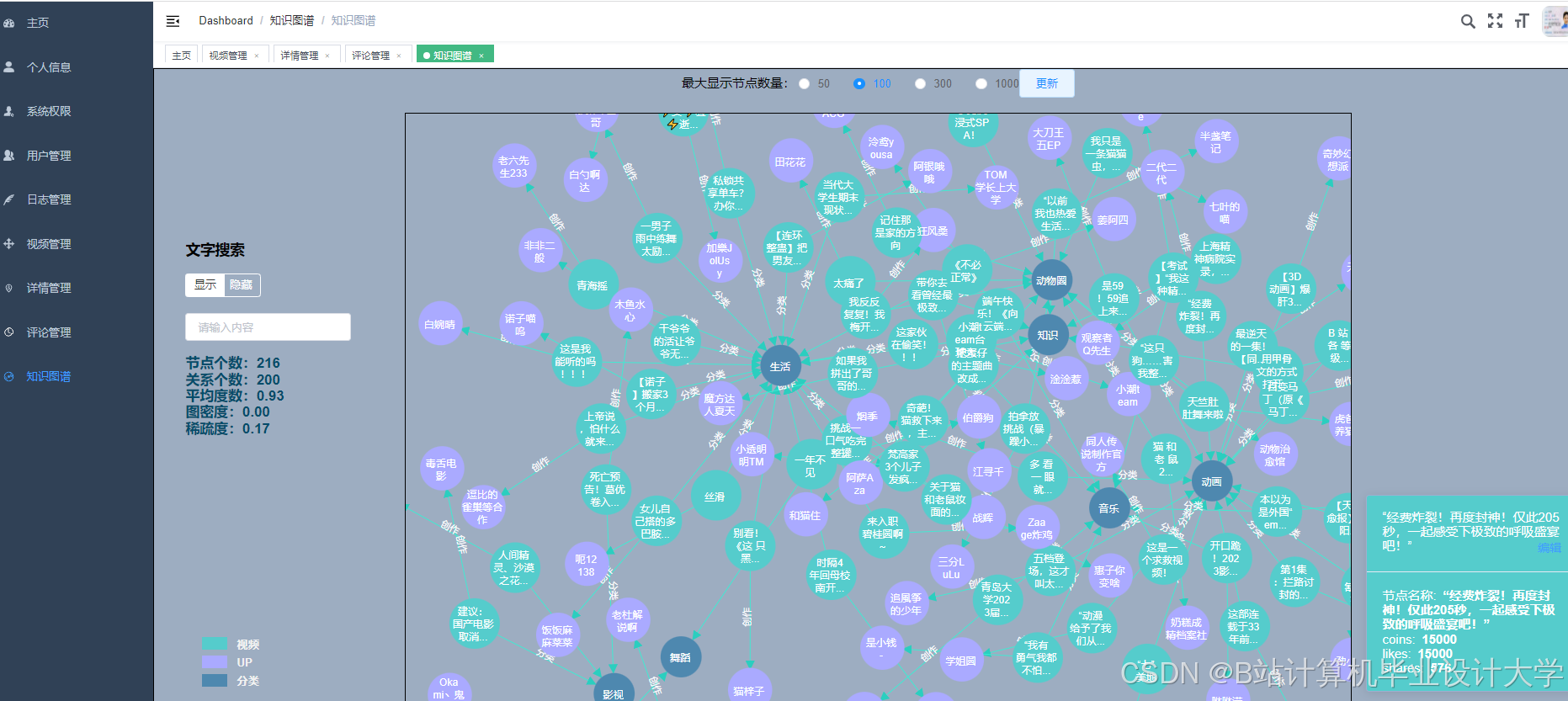
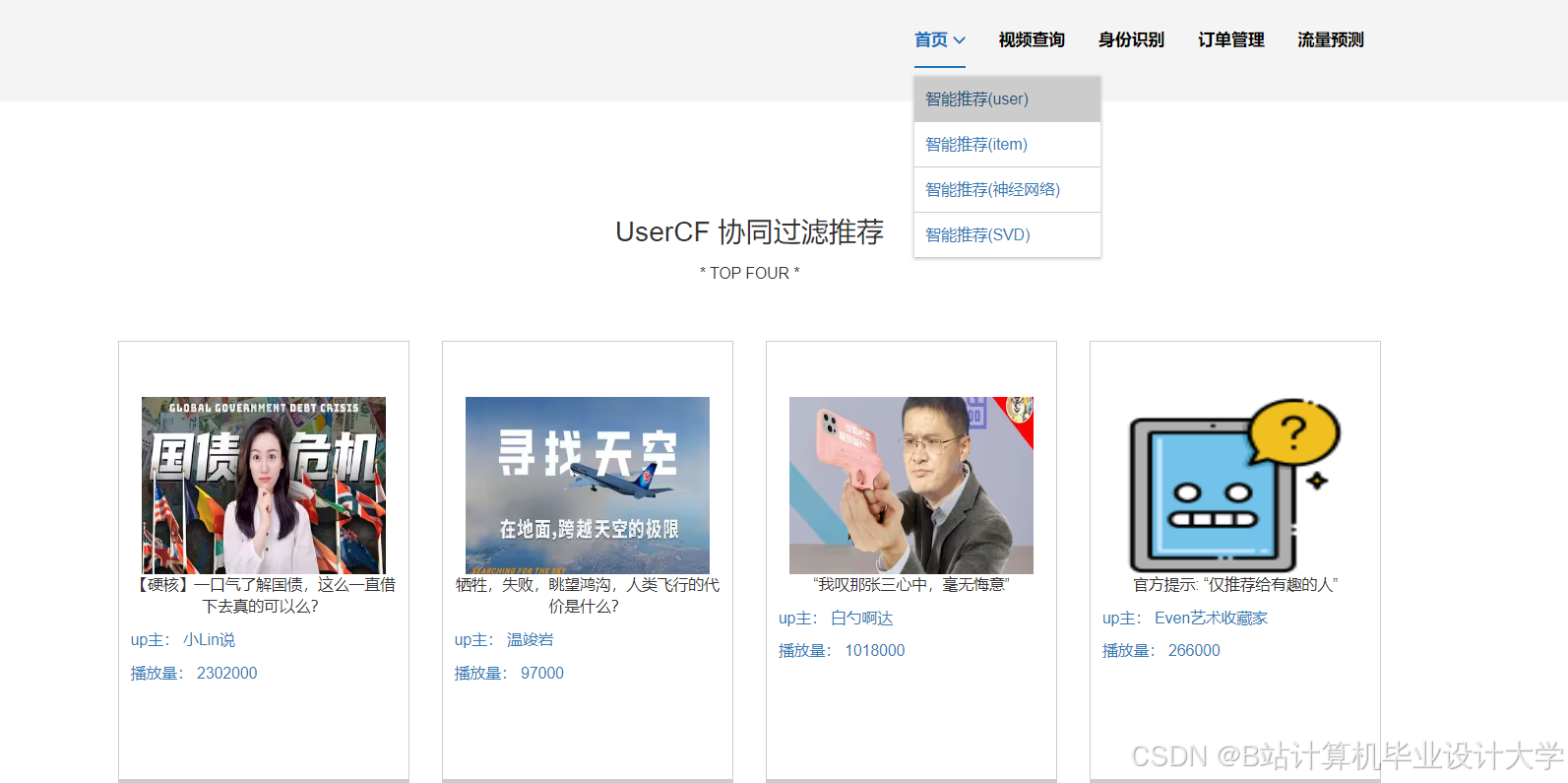
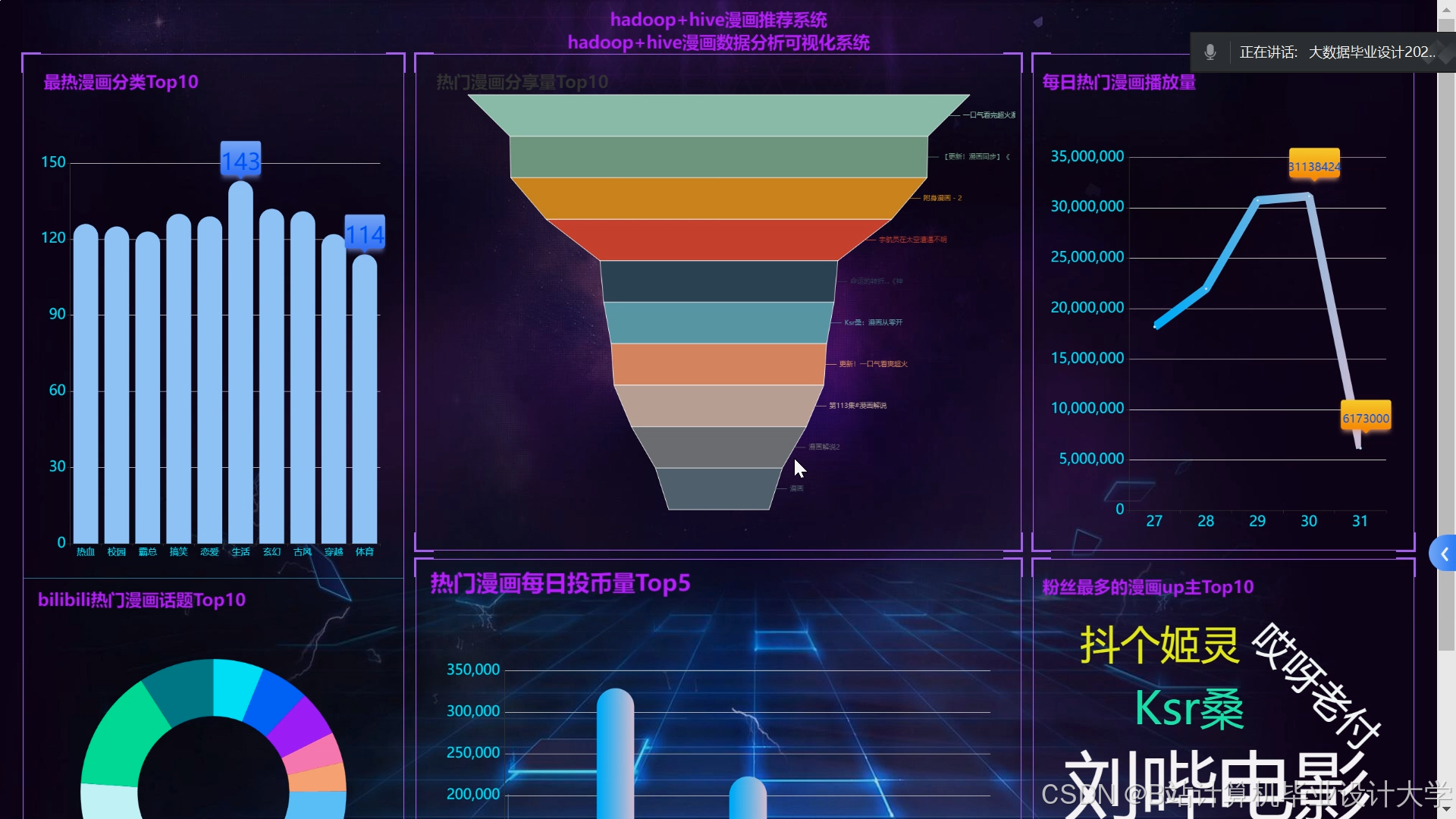
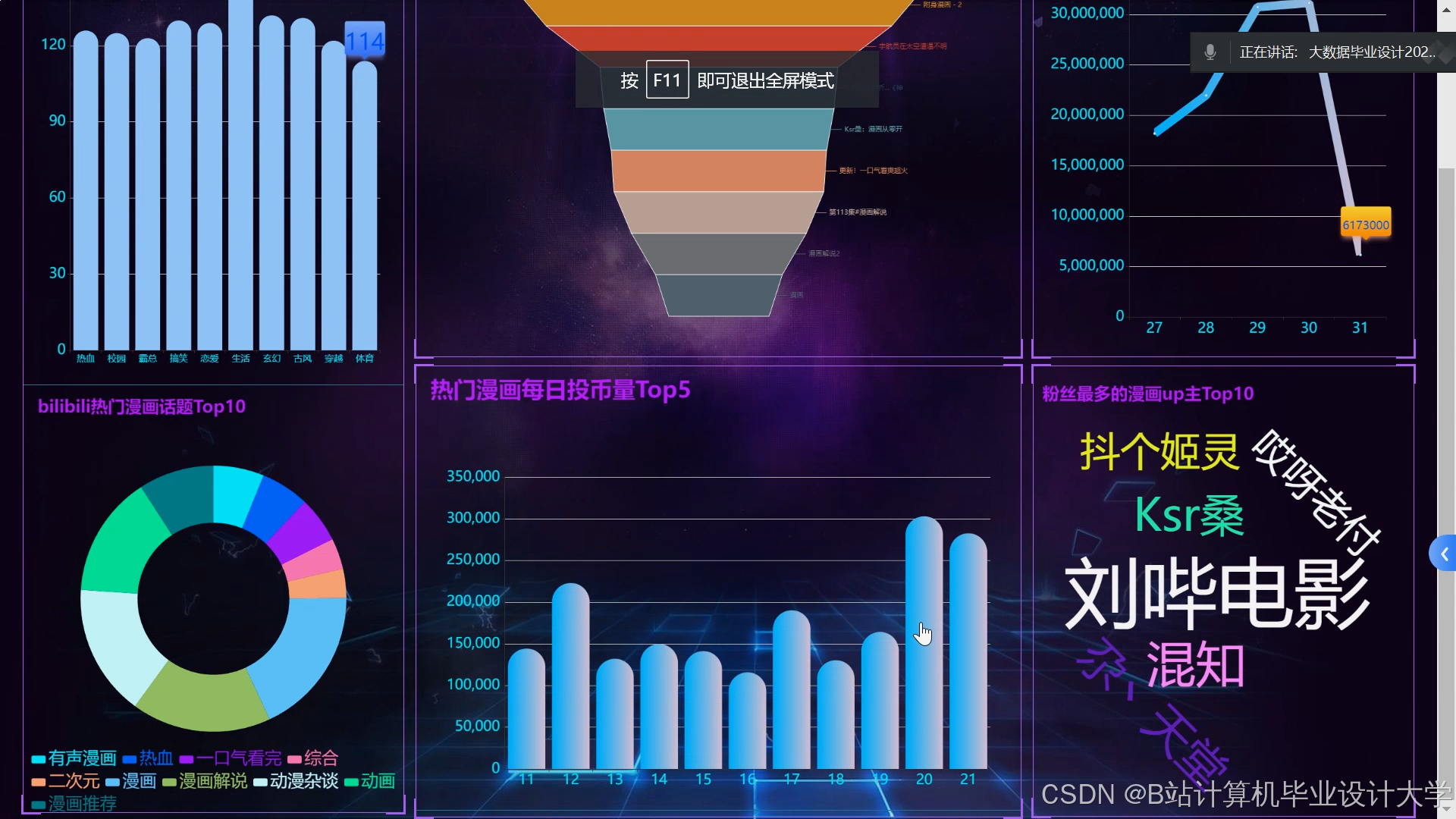
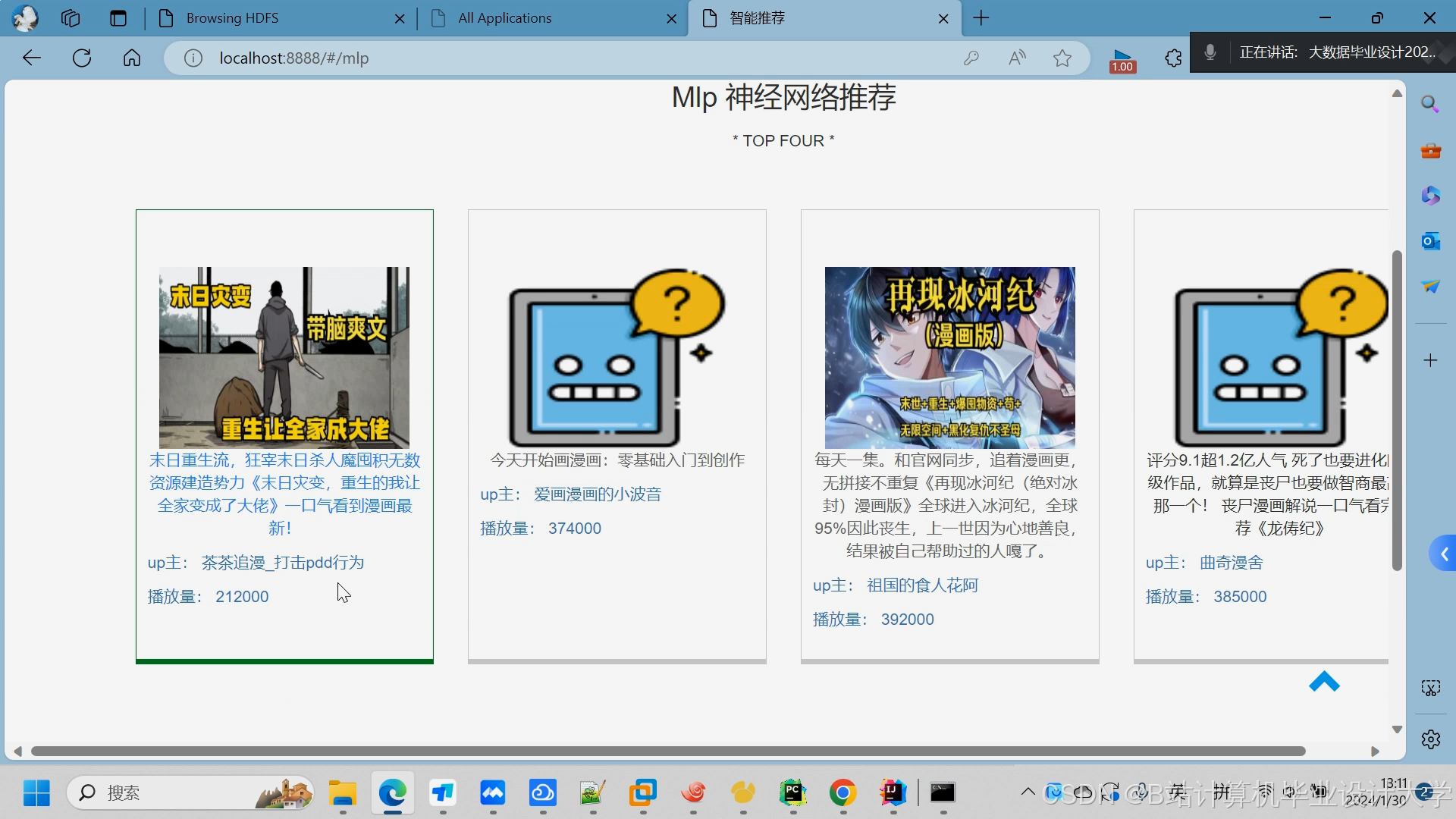
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











