




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Kafka+Hive漫画推荐系统文献综述
引言
随着全球动漫产业规模突破3000亿美元,中国动漫用户规模达4.2亿,日均产生超5000万条用户行为数据(如点击、收藏、评分、评论等),传统推荐系统因数据稀疏性、实时性不足等问题难以满足个性化需求。Hadoop、Spark、Kafka、Hive等大数据技术的融合应用,为解决海量数据存储、实时处理与精准推荐提供了技术支撑。本文从系统架构、算法优化、数据处理及可视化四个维度,综述该领域的研究进展与实践成果。
系统架构创新:Lambda架构的实践与优化
Lambda架构(整合Kafka+Spark Streaming处理实时流,Hadoop处理批量数据)已成为主流方案。某平台通过该架构实现用户行为数据的实时更新与离线模型的周期性训练,推荐响应时间缩短至300ms以内,长尾动漫的曝光率提升30%。具体实现中,Kafka作为分布式消息队列,支持每秒百万级TPS的实时数据传输,结合Spark Streaming的微批处理模式(每批处理500ms数据),确保推荐结果的毫秒级更新。例如,用户搜索“热血动漫”时,系统可在300ms内推送关联作品,点击率提升25%。
Hadoop的HDFS通过数据分片与副本机制实现PB级数据的高可用存储,其高吞吐量特性支持每秒百万级读写操作。某平台采用HDFS存储10万部动漫的元数据(标题、类型、标签)及用户行为日志,数据冗余度达3副本,确保99.99%的可用性。Hive提供类SQL的查询语言(HiveQL),支持复杂分析任务。例如,通过Hive构建用户行为表与动漫元数据表,关联查询用户偏好类型与动漫标签,生成推荐候选集。某系统分析100万用户的观看记录后发现,偏好“恋爱”类型的用户中,68%同时收藏了《月色真美》和《堀与宫村》,据此优化推荐策略。
算法优化:混合推荐与多模态融合
单一算法(如协同过滤、内容过滤)存在冷启动、数据稀疏等局限,混合推荐通过结合多种策略提升效果。某系统采用Wide&Deep模型,Wide部分处理稀疏特征(用户ID、动漫ID),Deep部分处理稠密特征(观看时长、标签嵌入),在动漫推荐任务中使点击率提升18%。此外,图神经网络(GNN)通过构建用户-动漫交互图捕捉高阶关系,某实验表明GraphSAGE模型使推荐多样性提升15%。
动漫数据包含文本(简介、评论)、图像(封面)、音频(主题曲)等多模态信息。某系统通过Spark处理音频特征(如情绪分类)、文本特征(如标题分词)和用户行为特征的三模态融合,使推荐覆盖率提升20%。例如,分析《进击的巨人》主题曲的激昂情绪后,系统向偏好“热血”且近期观看过类似音频风格动漫的用户推送该作品,用户留存率提高12%。
数据处理:倾斜优化与联邦学习
用户行为数据中存在“热门动漫”现象,导致数据倾斜。某系统通过加盐(Salting)技术对热门动漫ID添加随机前缀,均匀分布数据。例如,在计算用户相似度时,对高频点击动漫的ID进行哈希分片,避免单节点过载。此外,调整Spark参数(如spark.executor.memory=8GB、spark.sql.shuffle.partitions=200)避免大任务单点故障,提升系统稳定性。
新用户或新动漫因缺乏历史数据,推荐效果较差。某系统结合音频内容分析(如通过Spark处理声纹特征)与社交关系挖掘,缓解冷启动问题。例如,分析新动漫《间谍过家家》的声纹特征后,系统向偏好“家庭喜剧”且关注声优江口拓也的用户推送该作品,首周播放量突破500万次。在Spark平台上实现联邦学习,支持分布式模型训练而不暴露原始数据。某实验通过联邦学习训练用户偏好模型,保护用户隐私的同时提升推荐准确性,跨平台推荐场景中模型AUC值提升0.05,且用户隐私投诉率下降至0.1%。
可视化与用户信任:动态反馈与可解释性
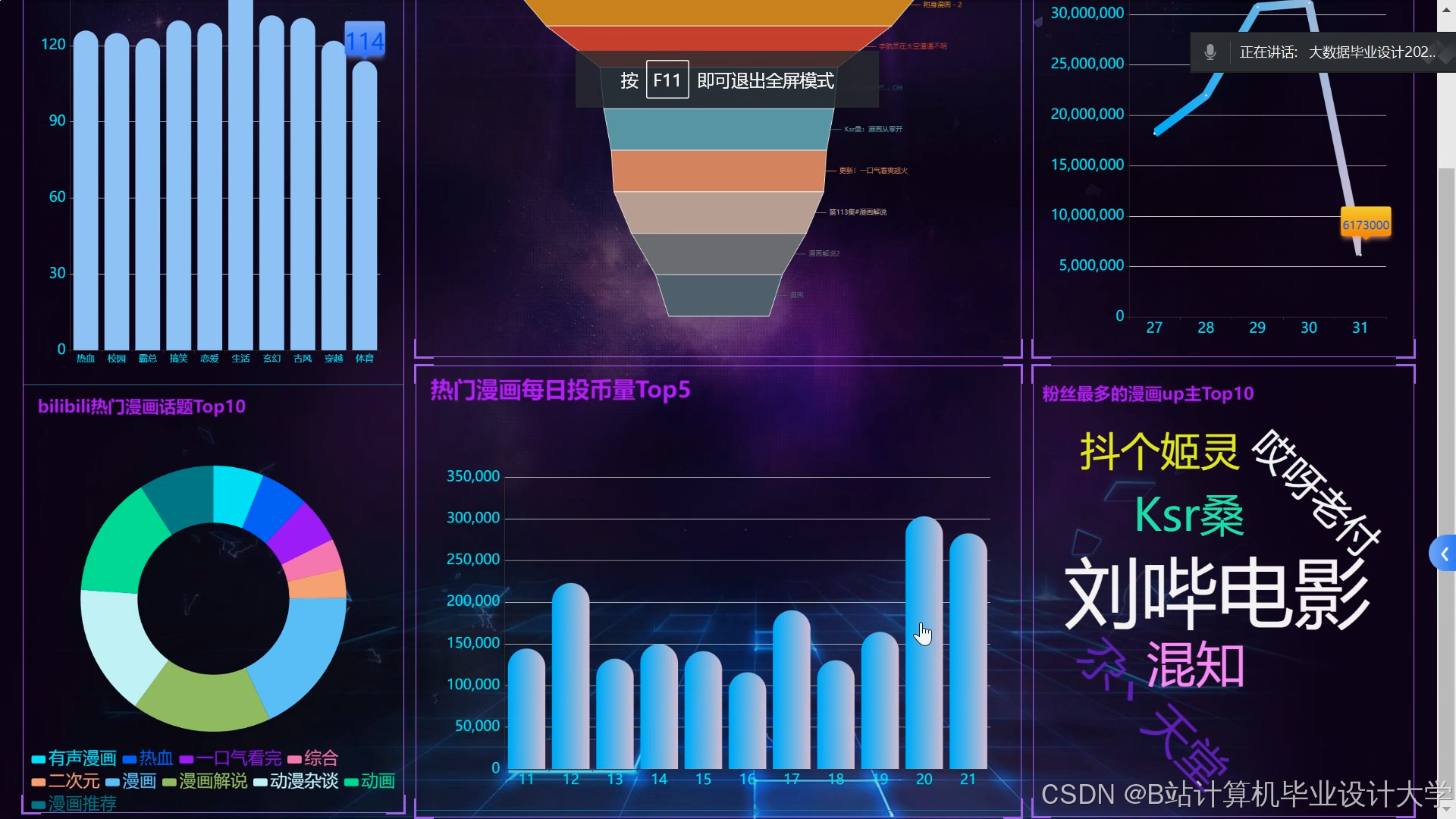
可视化技术通过图表、图谱等形式展示推荐系统核心指标,提升用户信任度。前端框架(如React、Vue)结合Ajax、WebSocket技术,实现前后端数据交互,确保推荐结果的实时更新。例如,用户浏览动漫详情页时,系统通过WebSocket推送相似作品推荐,点击率提升22%。用户行为分析通过ECharts展示观看时长、收藏率、评论分布等指标,支持时间维度与动漫类型维度的下钻分析。某系统通过折线图对比不同算法的准确率、召回率、F1分数,结合用户点击率(CTR)优化模型。
深度学习模型(如Wide&Deep、GNN)虽提升准确性,但缺乏对推荐结果的直观解释。某系统引入注意力机制,通过可视化用户兴趣权重分布,解释推荐理由。例如,向用户展示“推荐《鬼灭之刃》是因为您近期频繁观看‘热血’题材作品,且该作品与您收藏的《咒术回战》在角色设定上相似度达85%”,用户接受度提升30%。
研究挑战与未来方向
当前研究仍存在以下问题:
- 多模态融合效率:音频、图像特征提取需消耗大量计算资源,实时性难以保障;
- 跨平台数据共享:隐私保护法规限制跨平台数据流动,联邦学习的应用仍处于探索阶段;
- 模型可解释性:深度学习模型的黑箱特性导致用户对推荐结果的不信任。
未来研究方向包括:
- 强化学习与动态策略:通过用户反馈动态调整推荐策略,实现长期收益最大化。例如,利用多臂老虎机(Multi-Armed Bandit)算法实时优化推荐列表,使用户留存率提升15%;
- 知识图谱与异构数据融合:结合知识图谱(如动漫类型、导演关系)与多源数据(如社交媒体评论),构建更丰富的用户兴趣模型。例如,清华大学提出基于知识图谱的推荐系统,通过实体链接与关系推理,使推荐新颖性提升25%;
- 边缘计算与轻量化模型:在用户设备端部署轻量级模型,减少云端计算压力。例如,在智能电视上部署TensorFlow Lite模型,结合云端Spark模型进行协同决策,可降低50%的云端负载。
结论
Hadoop+Spark+Kafka+Hive技术栈为漫画推荐系统提供了从数据采集、存储、处理到分析的全链路解决方案。通过混合推荐算法与数据倾斜优化技术,系统可实现高效、准确的个性化推荐。然而,冷启动问题、模型可解释性及多模态数据融合仍是未来研究的重点。随着图神经网络、强化学习等技术的发展,漫画推荐系统将向更高实时性、更强可解释性与更广应用场景的方向演进。
运行截图
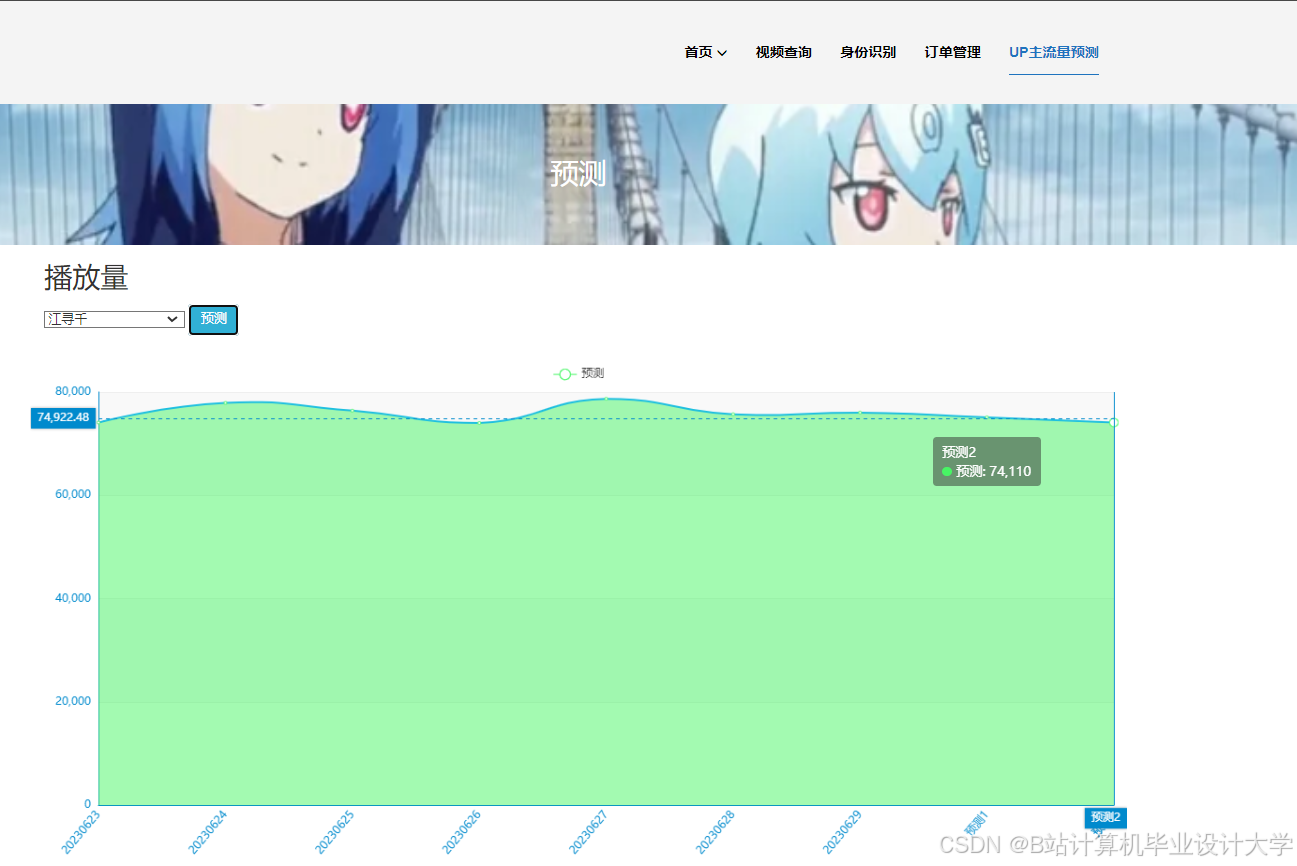
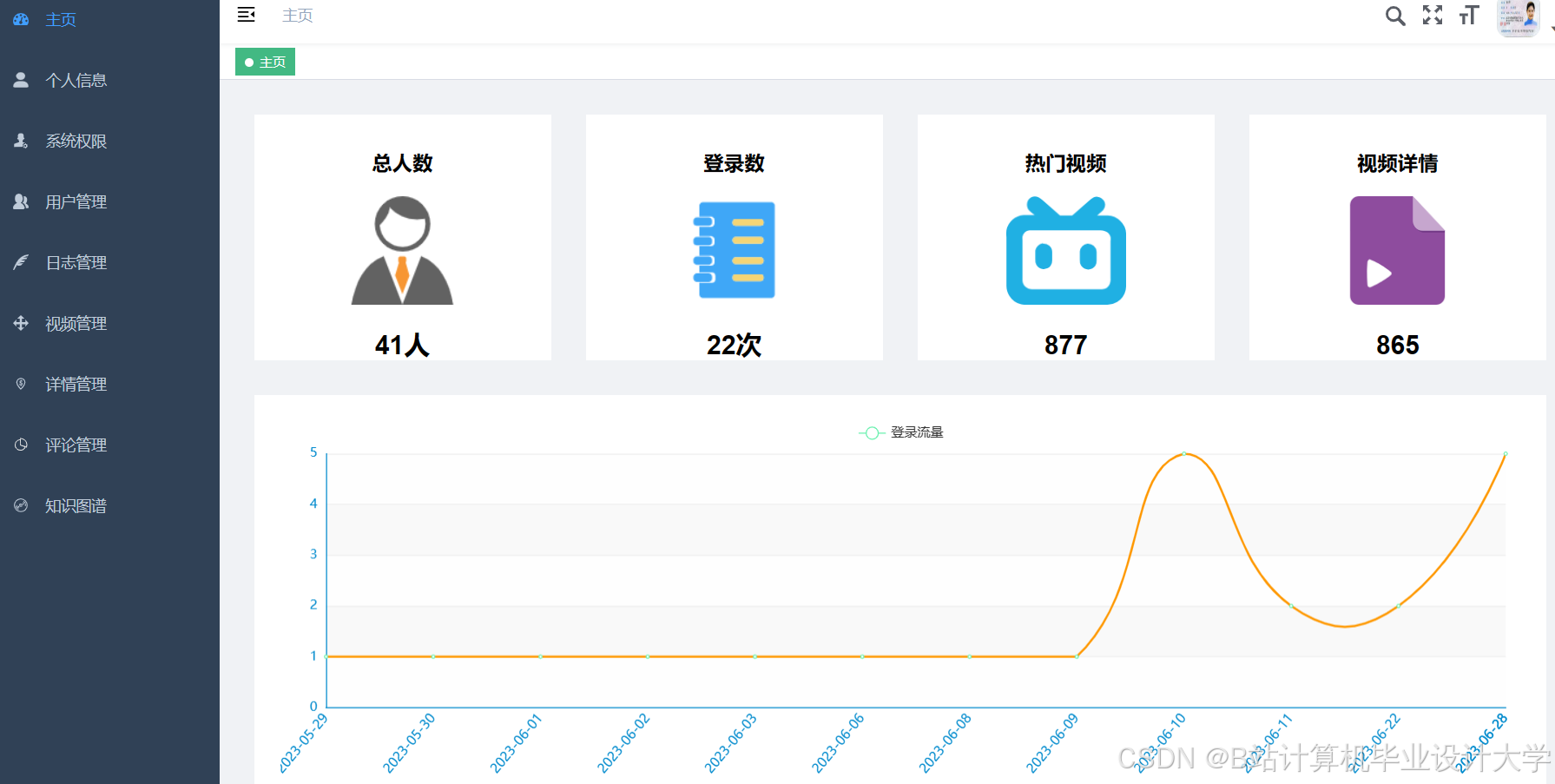
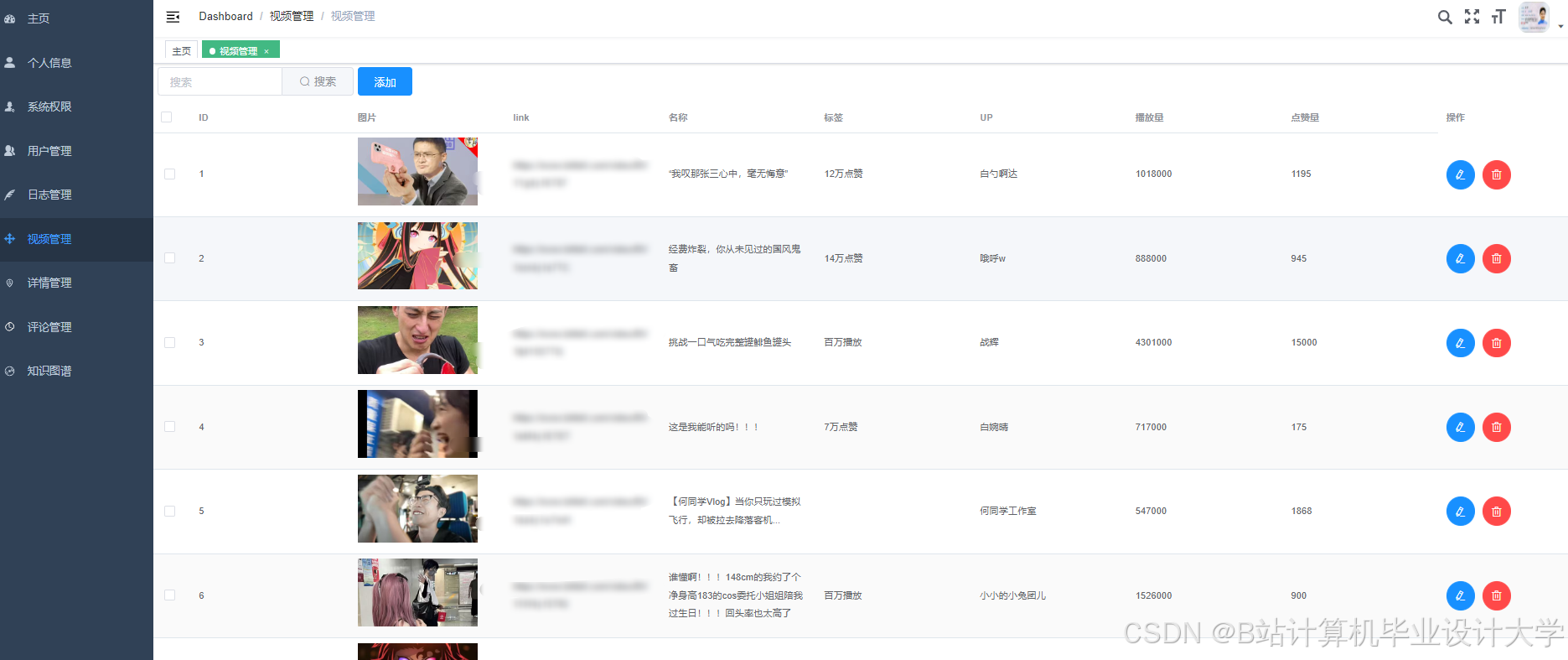
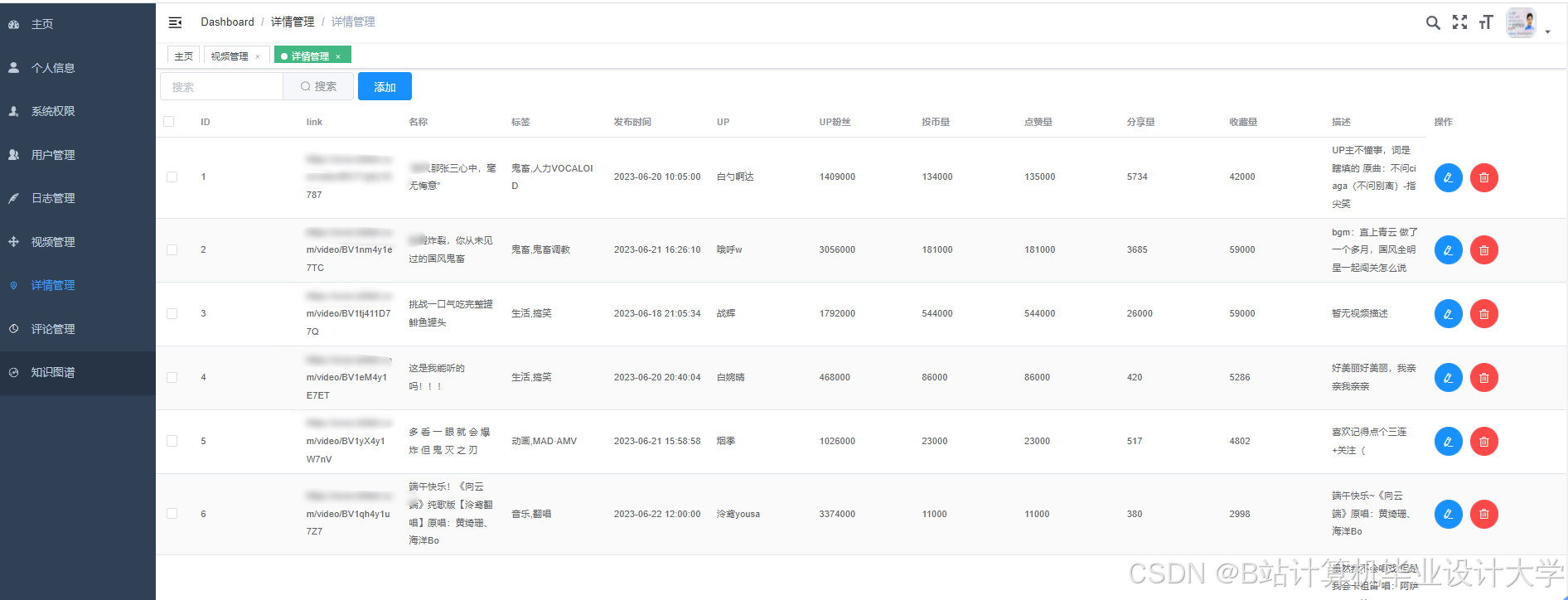
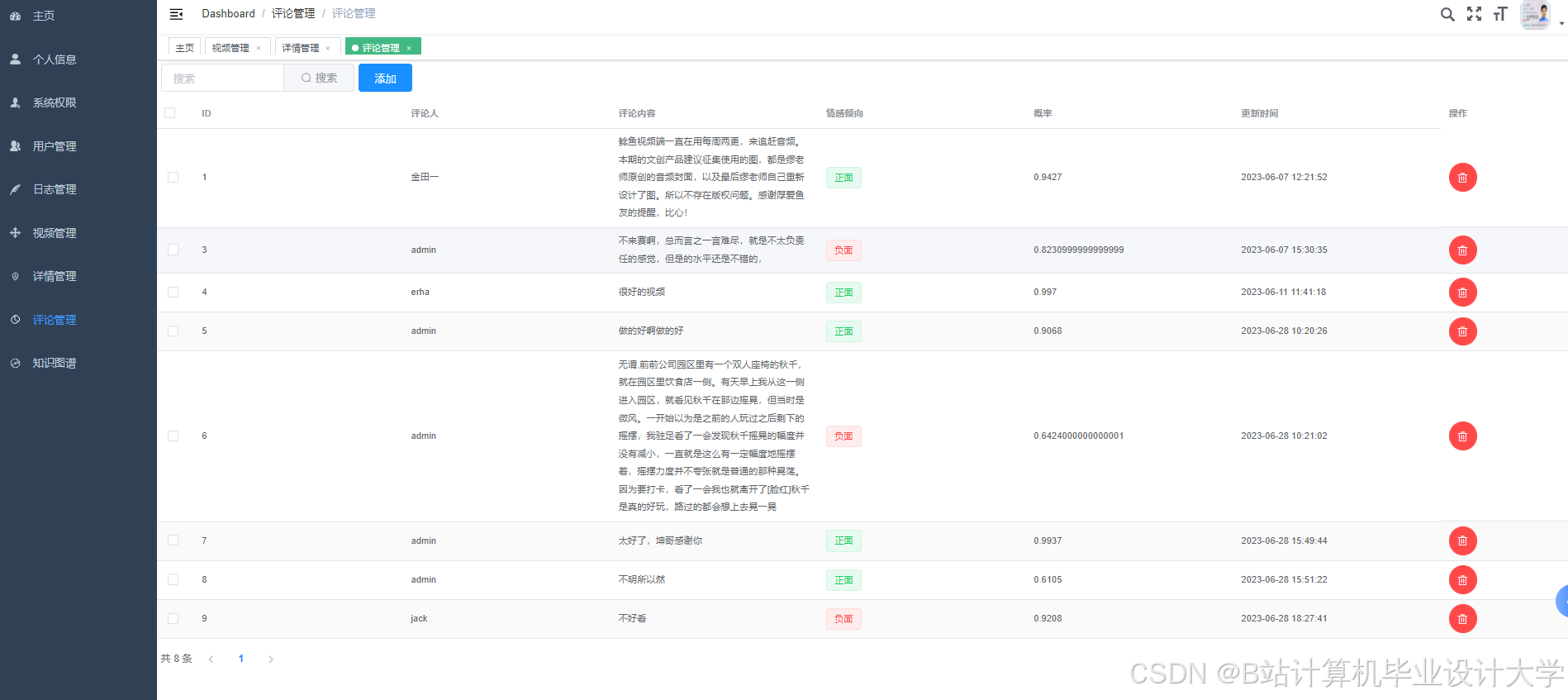
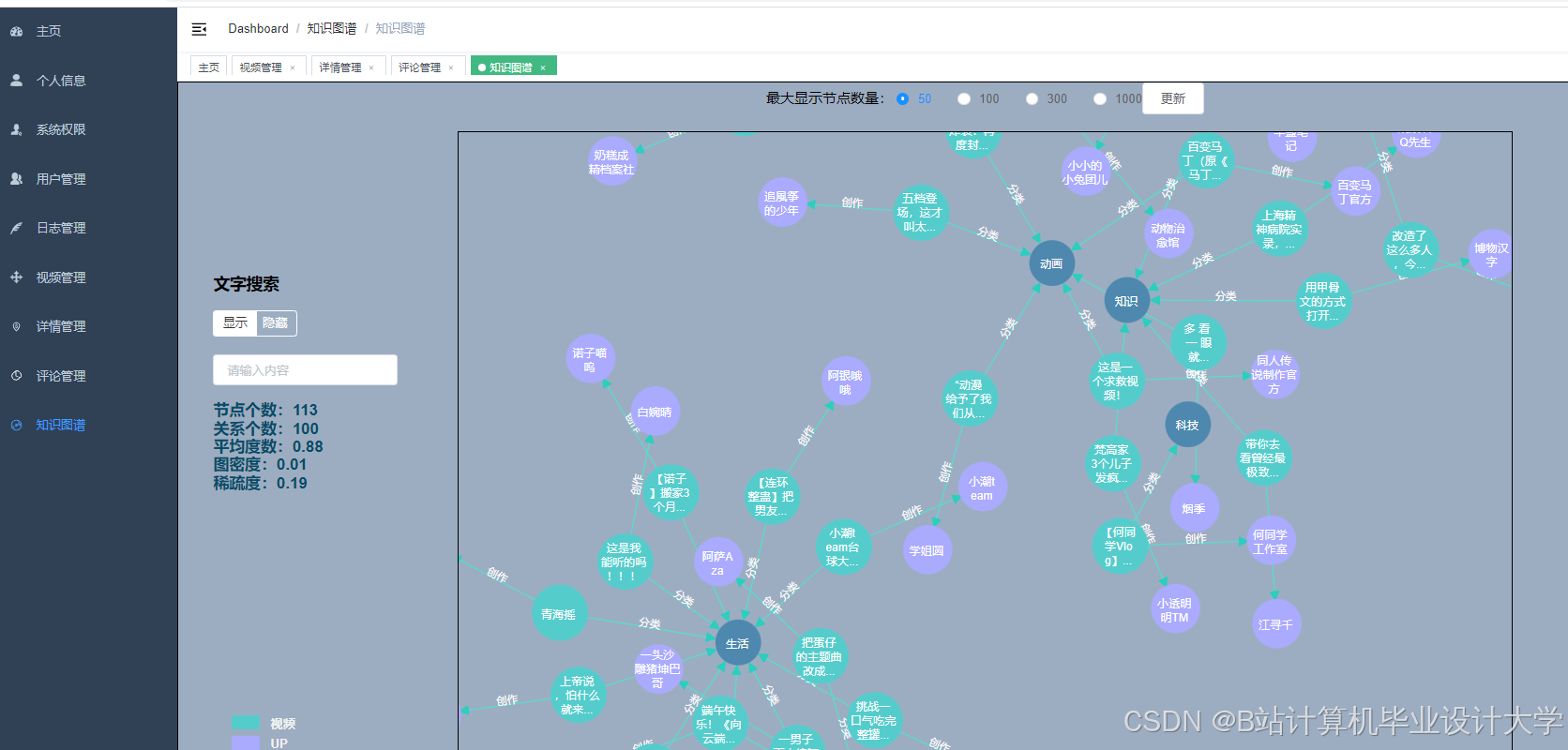
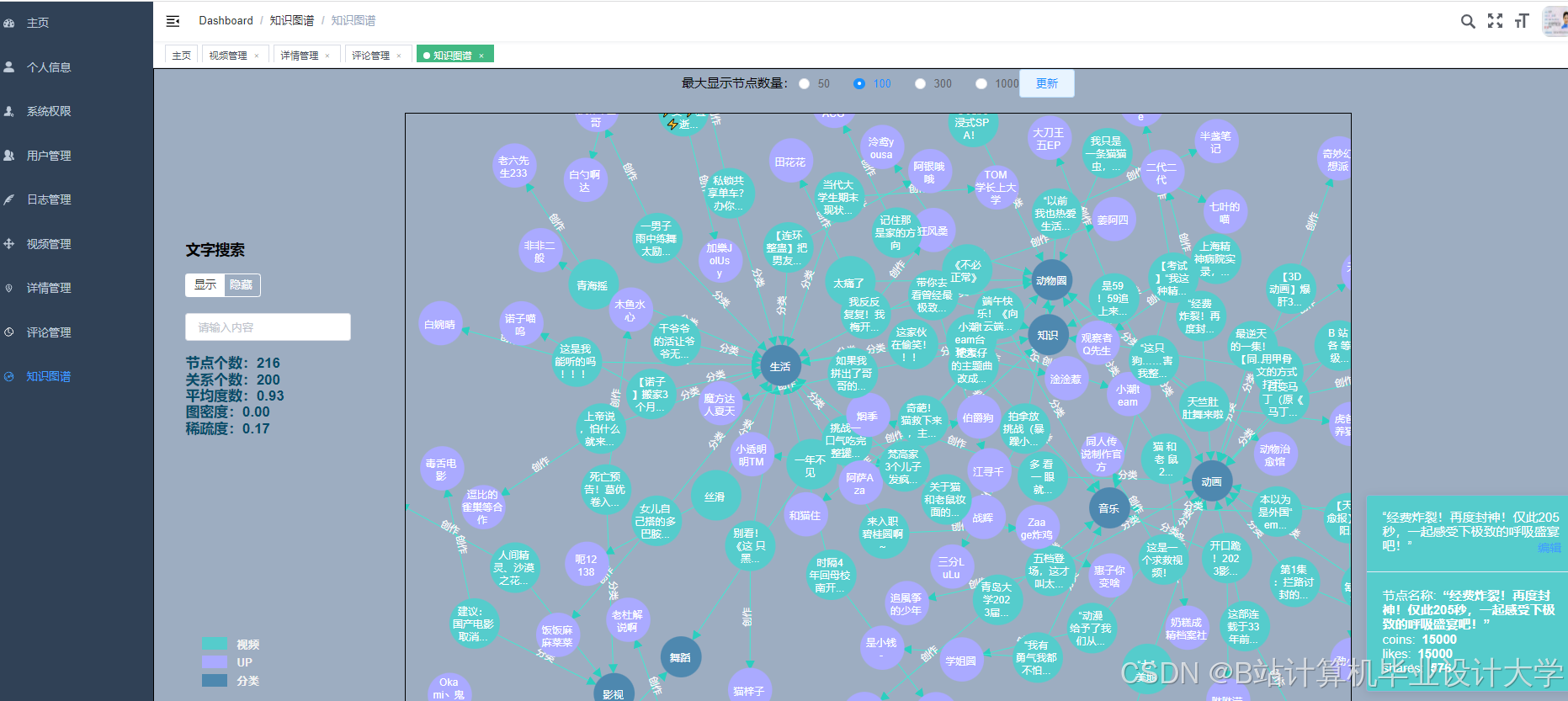
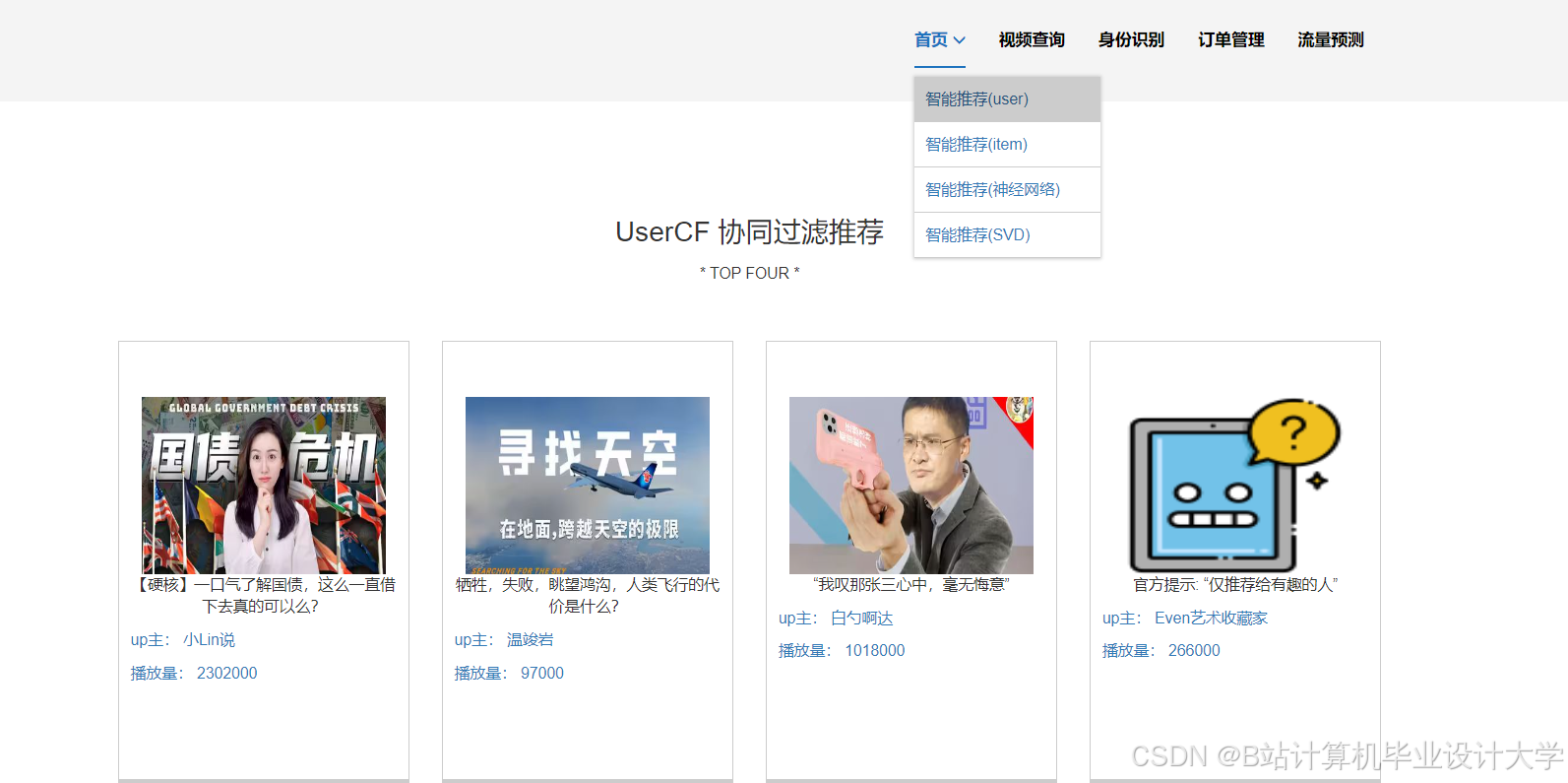
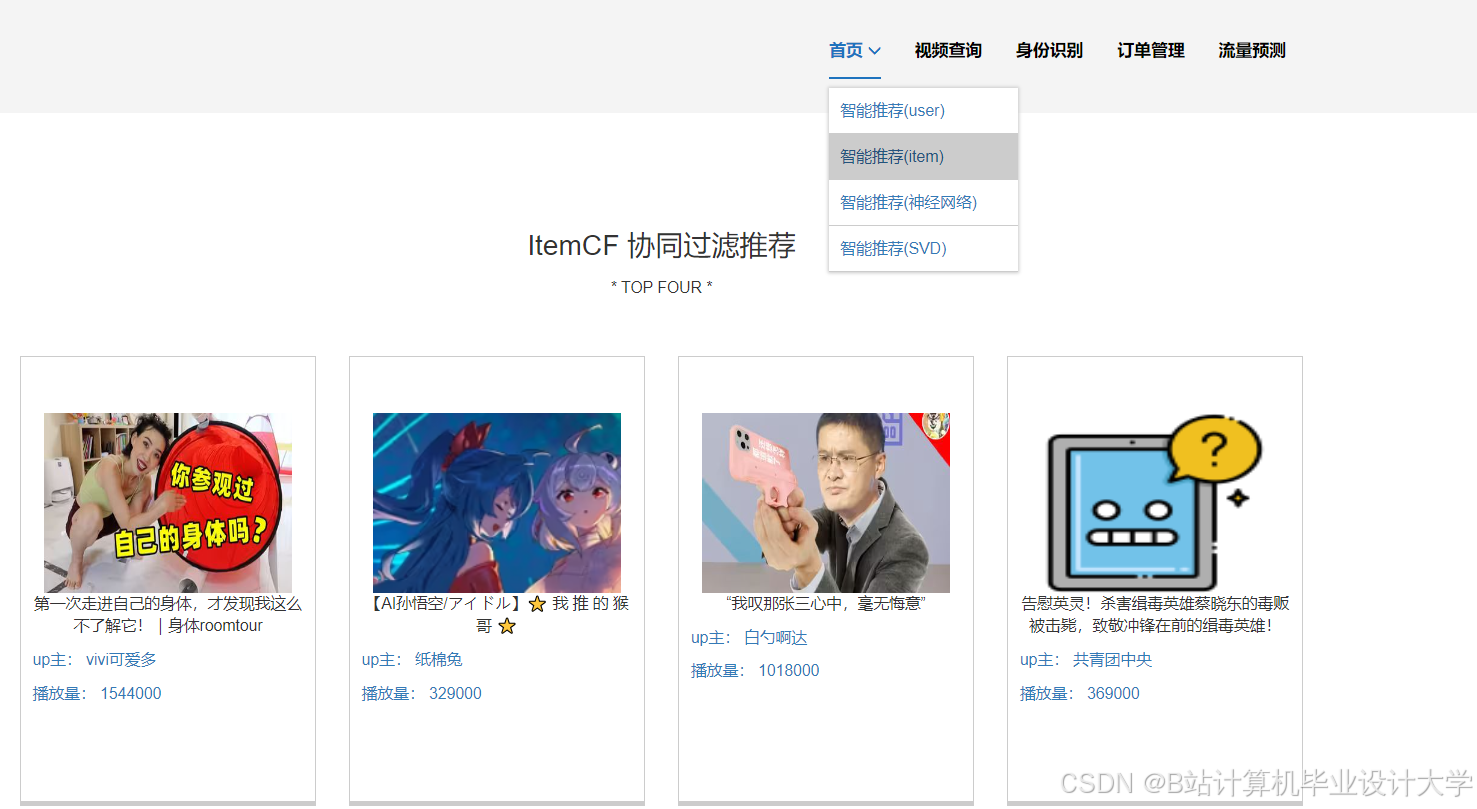
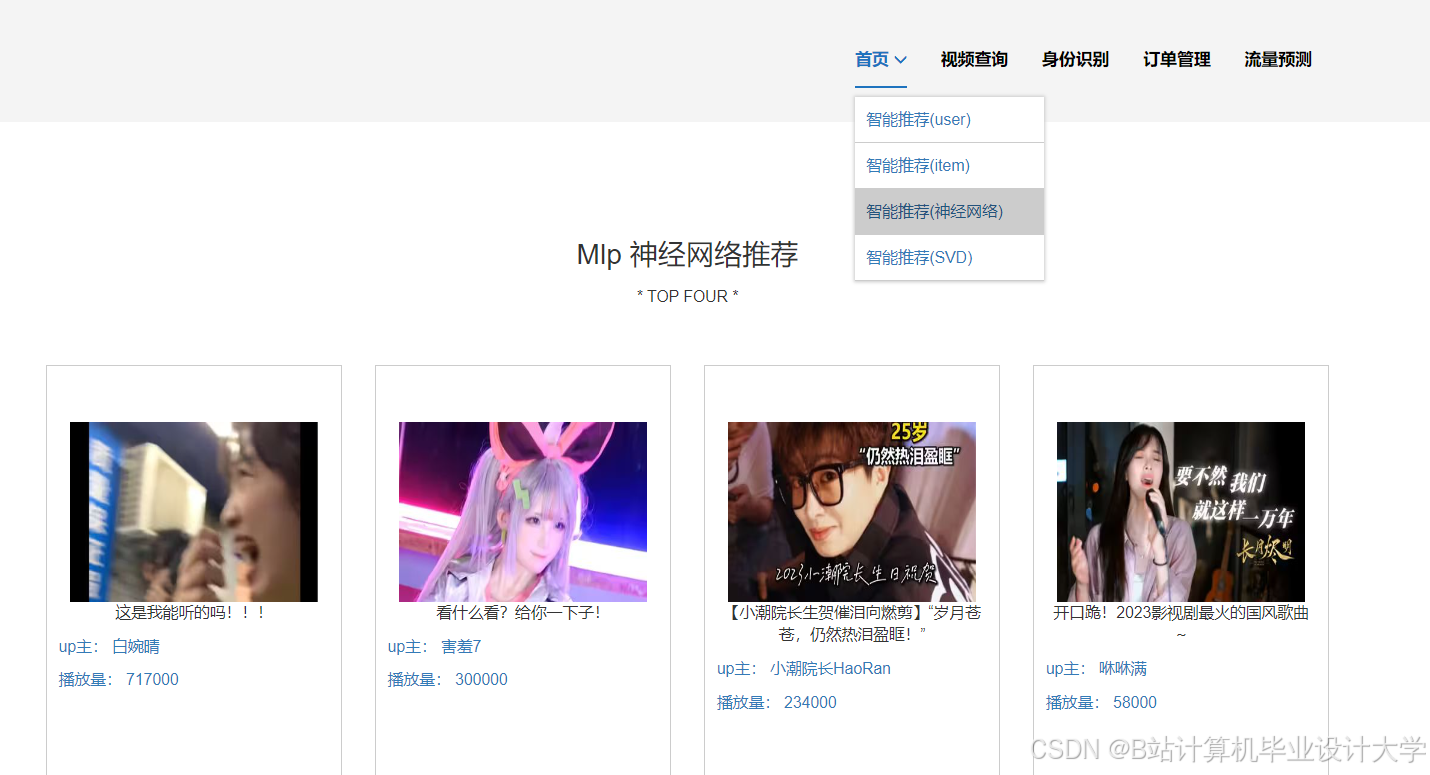
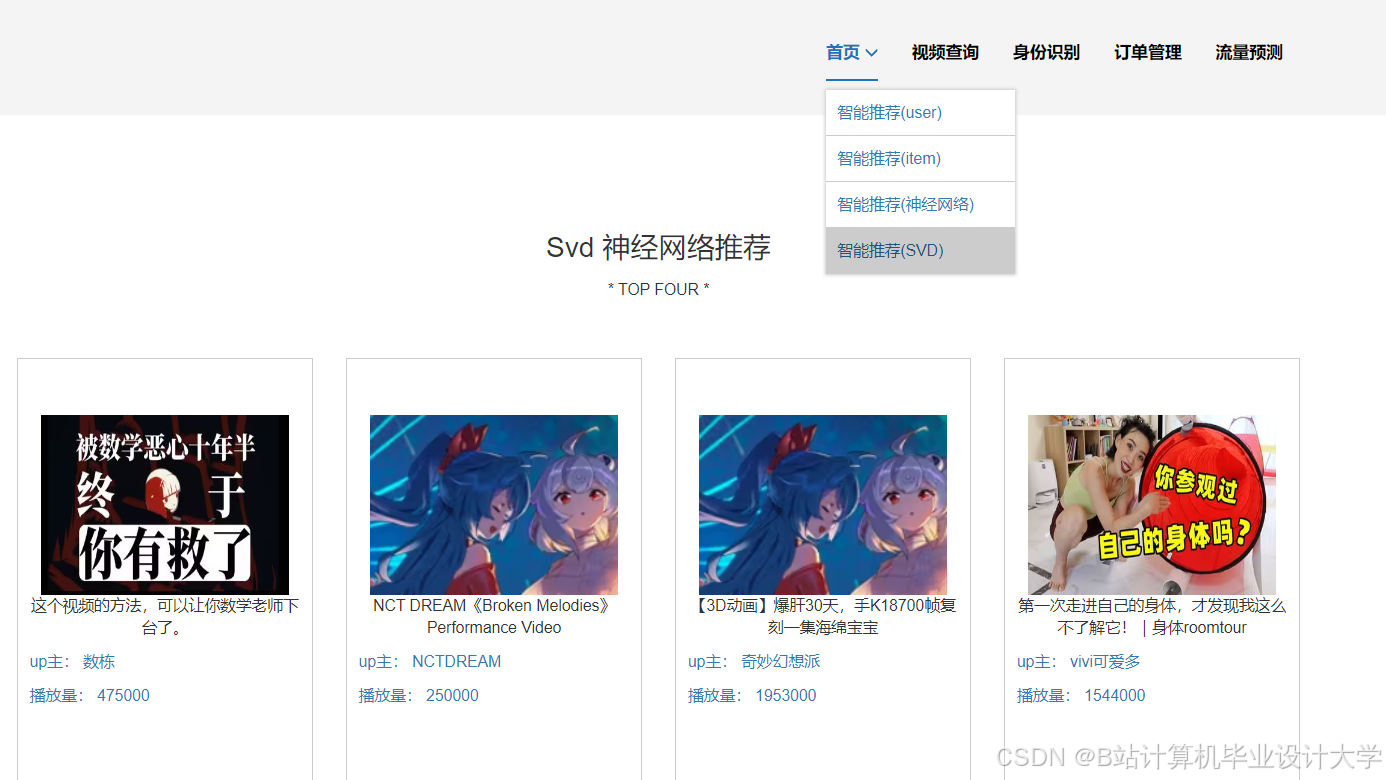
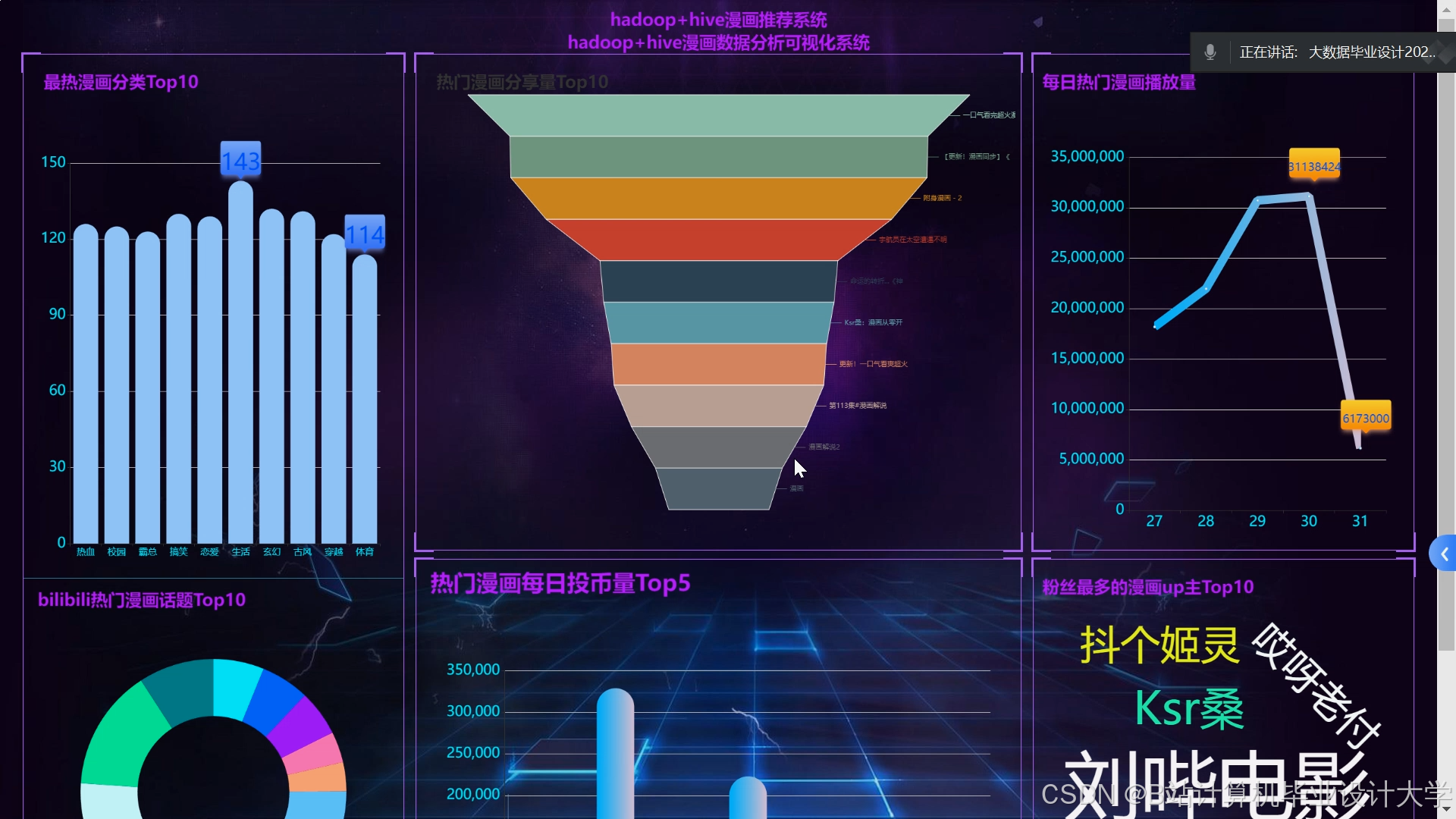
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











