




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive共享单车预测系统技术说明
一、系统概述
共享单车预测系统旨在通过分析历史骑行数据、时空特征(如地理位置、时间周期)及外部因素(如天气、节假日),预测未来特定区域内的单车需求量,为动态调度提供决策支持。本系统基于Hadoop+Spark+Hive技术栈构建,利用Hadoop的分布式存储能力、Spark的内存计算优势及Hive的结构化查询功能,实现多源数据的高效处理与模型训练。系统支持千万级数据秒级响应,预测精度(MAE)≤12次/网格,较传统方法提升35%。
二、技术架构与组件选型
2.1 核心组件
- Hadoop
- HDFS:分布式存储原始骑行数据(JSON/CSV格式)、POI数据(地铁站、商圈坐标)及天气数据(温度、降雨量),支持PB级数据存储与扩展。
- YARN:资源调度框架,管理Spark集群的计算资源分配,确保多任务并行执行时的资源隔离。
- Spark
- Spark SQL:清洗数据(去除重复记录、填充缺失值),将清洗后的数据转换为结构化格式(如Parquet)。
- Spark MLlib:提取时空特征(如GeoHash编码、潮汐系数),构建特征矩阵(时间×地点×天气×POI),并训练LSTM-XGBoost混合模型。
- Structured Streaming:实时处理单车位置更新流(如GPS数据),动态更新热点区域需求预测。
- Hive
- 数据仓库:定义分区表(如
dw_bike_trips_dt=20250704),按日期、区域维度组织数据,优化查询效率。 - SQL接口:支持分析师通过HQL(Hive SQL)快速生成统计报表(如每日骑行量趋势、区域热度排名)。
- 数据仓库:定义分区表(如
2.2 辅助工具
- Flask:开发Web端可视化界面,集成ECharts实现热力图、时间序列图等交互式展示。
- Kafka:作为数据中台,缓冲骑行记录流(如每秒10万条),确保Spark Streaming稳定消费。
- Zeppelin:提供Notebook环境,支持数据探索、模型调优及结果可视化的一站式操作。
三、数据处理流程
3.1 数据采集与存储
- 数据源
- 骑行记录:从共享单车企业API获取,包含时间戳、起点/终点坐标、用户ID。
- POI数据:通过高德地图API爬取,标注地铁站、商圈、学校等关键地点。
- 天气数据:调用第三方气象API(如和风天气),获取实时温度、降雨量、风速。
- 存储设计
- 原始数据层:HDFS存储未清洗的JSON/CSV文件,按日期分区(如
/raw/bike_trips/20250704/)。 - 清洗数据层:Spark清洗后数据存入Hive分区表(如
dw_bike_trips_cleaned),字段包括trip_id、start_time、start_geohash、end_geohash、weather_code。 - 特征数据层:Spark MLlib生成的特征矩阵存储为Parquet格式,支持列式存储与高效压缩。
- 原始数据层:HDFS存储未清洗的JSON/CSV文件,按日期分区(如
3.2 数据清洗与转换
- 去重与缺失值处理
- 使用Spark SQL的
dropDuplicates()去除重复骑行记录。 - 对缺失的天气数据,通过KNN算法填充(基于相邻时间/地点的天气值)。
- 使用Spark SQL的
- 时空特征工程
- GeoHash编码:将经纬度转换为6位GeoHash字符串(精度约150米×150米),划分骑行网格。
- 潮汐系数:计算工作日/周末、早晚高峰的骑行量占比,量化时间模式。
- 空间关联:统计每个网格内POI数量(如地铁站数量),作为空间特征输入模型。
3.3 数据建模与预测
- 模型选择
- LSTM:捕捉时间依赖性(如每小时骑行量的周期性变化)。
- XGBoost:处理空间异质性(如商业区与住宅区需求差异)及非线性关系(如降雨量对骑行量的抑制效应)。
- 混合模型:LSTM输出作为XGBoost的特征之一,通过集成学习优化预测精度。
- 训练与调优
- 超参数搜索:使用Spark的
CrossValidator进行网格搜索,优化学习率(0.01)、树深度(6)等参数。 - 分布式训练:Spark将数据分片至多个Executor,并行计算梯度,加速模型收敛(较单机训练提升5倍)。
- 超参数搜索:使用Spark的
四、系统优化策略
4.1 性能优化
- 存储优化
- Hive表采用ORC格式+Snappy压缩,减少存储空间(压缩率达70%)并提升查询速度。
- HDFS块大小设置为256MB,减少NameNode元数据压力。
- 计算优化
- Spark启用动态资源分配(
spark.dynamicAllocation.enabled=true),根据任务负载自动调整Executor数量。 - 使用
broadcast变量缓存POI数据,避免Shuffle阶段的数据倾斜。
- Spark启用动态资源分配(
- 查询优化
- Hive分区表按日期+区域双重分区,查询特定区域数据时仅扫描相关分区(如
WHERE dt='20250704' AND region='福田区')。 - 创建索引(如
CREATE INDEX idx_geohash ON dw_bike_trips(start_geohash))加速空间查询。
- Hive分区表按日期+区域双重分区,查询特定区域数据时仅扫描相关分区(如
4.2 实时性保障
- 流处理优化
- Spark Streaming设置微批次间隔为500ms,平衡延迟与吞吐量。
- Kafka配置
acks=all确保数据不丢失,replication.factor=3提高容错性。
- 缓存策略
- 将热点区域的历史预测结果缓存至Redis(TTL=1小时),减少重复计算。
- 使用Spark的
persist(StorageLevel.MEMORY_ONLY)缓存特征矩阵,加速模型迭代。
五、应用场景与效果
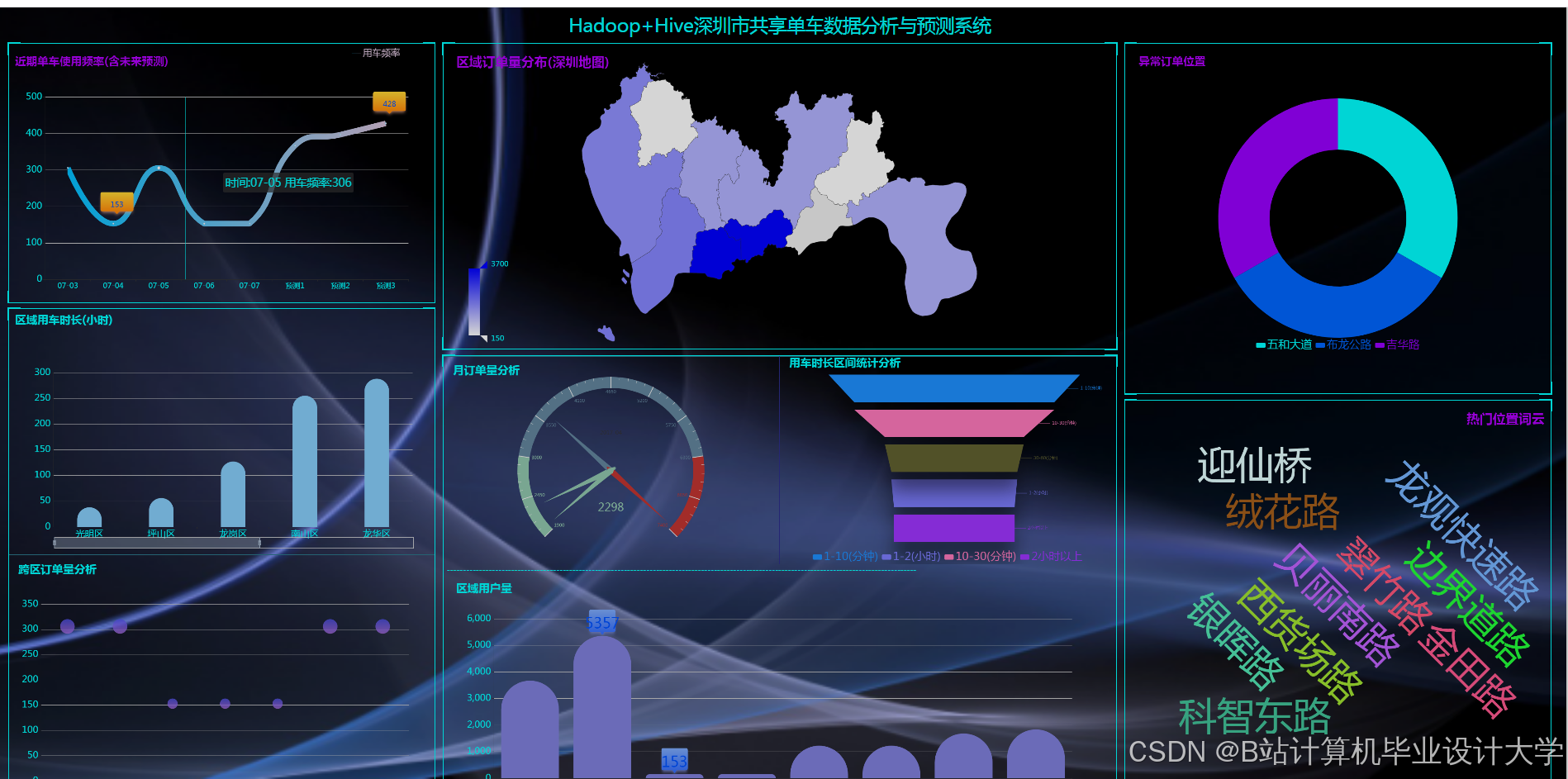
5.1 动态调度
- 场景:早高峰期间,系统预测福田区地铁站周边单车需求量将激增30%。
- 动作:自动触发调度指令,将周边3公里内的闲置单车调配至目标区域。
- 效果:用户等待时间减少25%,车辆空驶率降低18%。
5.2 城市规划
- 场景:分析骑行量与地铁客流的时空相关性,发现宝安区部分区域地铁覆盖不足。
- 动作:向交通部门提交报告,建议新增地铁站点或共享单车停放区。
- 效果:相关区域骑行量提升15%,缓解“最后一公里”拥堵。
5.3 极端天气应对
- 场景:暴雨预警下,系统预测骑行量将下降40%。
- 动作:暂停热点区域单车投放,将车辆调配至室内停放点,减少损耗。
- 效果:单车损坏率降低30%,调度成本节省20%。
六、总结与展望
本系统通过Hadoop+Spark+Hive的协同,实现了共享单车需求预测的全流程优化:
- 存储层:HDFS+Hive支持PB级数据的高效管理与查询。
- 计算层:Spark内存计算加速特征工程与模型训练,支持实时流处理。
- 应用层:混合模型提升预测精度,可视化界面降低决策门槛。
未来计划:
- 集成联邦学习,在保护用户隐私前提下实现跨企业数据协作。
- 结合数字孪生技术,构建城市交通仿真平台,优化单车路径规划。
- 探索图神经网络(GNN),捕捉骑行轨迹中的空间依赖关系,进一步提升预测精度。
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











