




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Django+Vue.js知识图谱中华古诗词可视化与情感分析技术说明
一、技术背景与目标
中华古诗词数字化传承面临两大核心挑战:
- 结构化知识缺失:传统诗词数据以非结构化文本形式存在,难以支持语义搜索与关联分析;
- 情感理解门槛高:古汉语隐喻、典故的使用导致现代读者难以准确把握诗词情感内涵。
本技术方案基于Django(后端) + Vue.js(前端)框架,构建集知识图谱构建、情感分析计算、动态可视化交互于一体的智能系统,实现三大技术目标:
- 构建包含诗人、诗作、意象等实体的结构化知识图谱;
- 通过深度学习模型实现诗词情感倾向的自动化分类;
- 采用可视化技术直观呈现诗词创作背景、意象关联及情感演变。
二、系统架构设计
2.1 分层架构图
┌───────────────────────────────────────────────────────┐ | |
│ 用户交互层(Vue.js) │ | |
├───────────────────┬───────────────────┬───────────────┤ | |
│ 可视化渲染引擎 │ 交互控制模块 │ 状态管理(Vuex)│ | |
│ (ECharts/D3.js) │ (事件监听/路由) │ │ | |
└─────────┬─────────┴─────────┬─────────┴───────────────┘ | |
│ │ | |
┌─────────▼─────────┐ ┌─────────▼───────────────────────┐ | |
│ API服务层(Django) │ 数据处理层(Python) │ | |
├───────────────────┬─────────┴───────────────────────────┤ | |
│ RESTful接口 │ 知识图谱构建模块 │ | |
│ (DRF框架) │ 情感分析引擎(LSTM模型) │ | |
│ WebSocket服务 │ 数据清洗与增强模块 │ | |
└─────────┬─────────┴───────────────────────────────────┘ | |
│ | |
┌─────────▼───────────────────────────────────────────────┐ | |
│ 持久化存储层 │ | |
├───────────────────┬───────────────────┬───────────────┤ | |
│ 关系型数据库 │ 图数据库 │ 对象存储 │ | |
│ (MySQL 8.0) │ (Neo4j 5.12) │ (MinIO) │ | |
└───────────────────────────────────────────────────────┘ |
2.2 关键组件说明
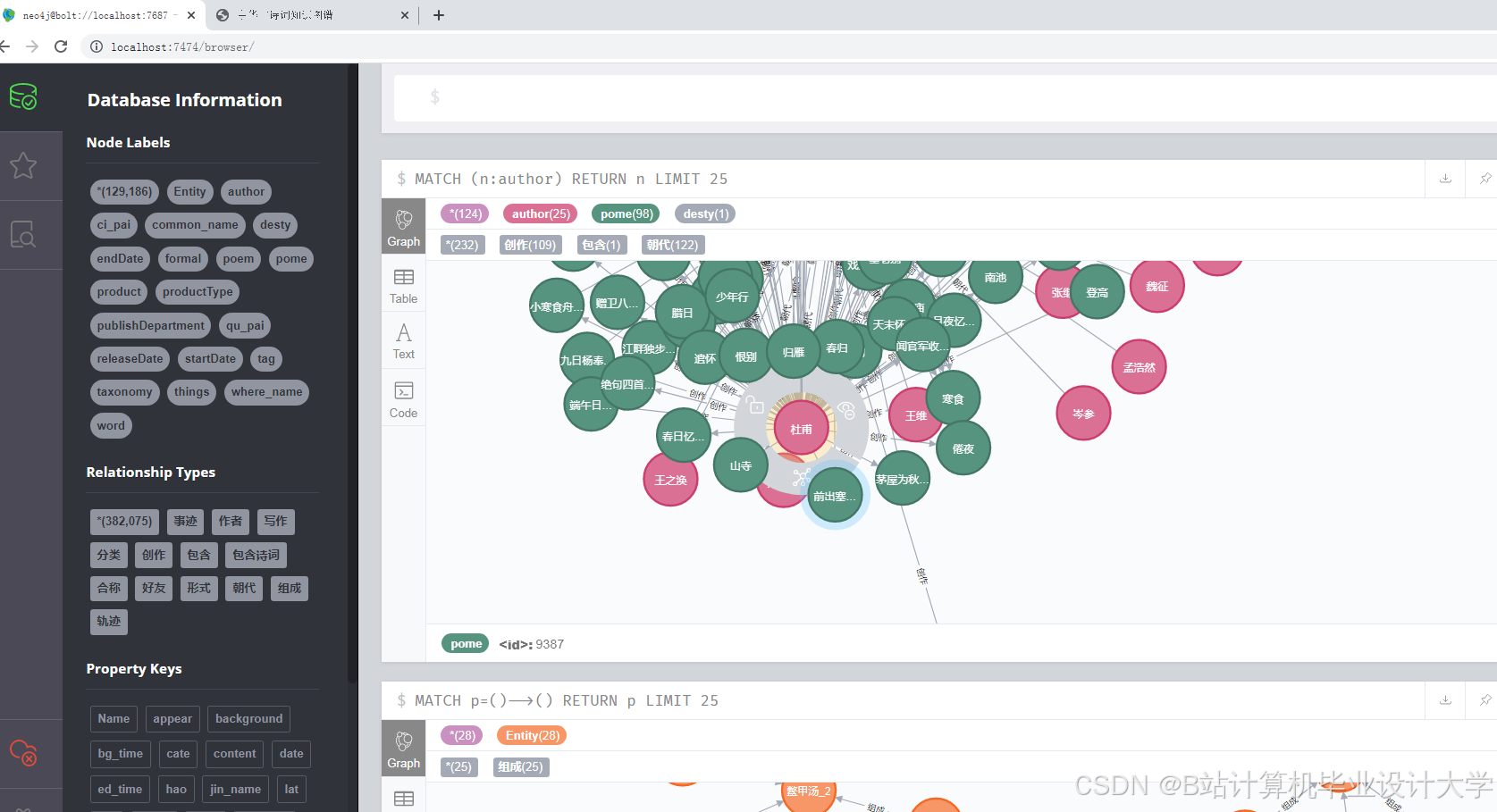
- 知识图谱引擎
- 采用Neo4j图数据库存储实体关系,支持Cypher查询语言
- 实体类型:诗人、诗作、朝代、意象、词牌名(共5类)
- 关系类型:创作、引用、同题材、同游等(共12类)
- 情感分析模块
- 模型架构:BiLSTM + Attention机制
- 输入特征:Word2Vec词向量(300维) + POS标签嵌入
- 输出分类:喜、怒、哀、乐、思(5类)
- 可视化引擎
- 统计图表:ECharts实现朝代诗词数量分布、意象词频统计
- 关系图谱:D3.js力导向布局展示诗人社交网络
- 时空轨迹:高德地图API绘制诗人游历路线
三、核心功能实现
3.1 知识图谱构建流程
3.1.1 数据采集与清洗
python
# 数据爬取示例(Scrapy框架) | |
import scrapy | |
class PoemSpider(scrapy.Spider): | |
name = 'gushiwen' | |
start_urls = ['https://www.gushiwen.org/shiwen/'] | |
def parse(self, response): | |
for poem in response.css('.sons'): | |
yield { | |
'title': poem.css('.cont h1::text').get(), | |
'author': poem.css('.cont p a::text').get(), | |
'content': ''.join(poem.css('.contson::text').getall()), | |
'dynasty': poem.css('.source a::text').get() | |
} | |
# 数据清洗流程 | |
def clean_data(raw_data): | |
# 1. 去除HTML标签 | |
clean_text = re.sub(r'<[^>]+>', '', raw_data['content']) | |
# 2. 繁体转简体(使用opencc-python库) | |
simplified = converter.convert(clean_text) | |
# 3. 标准化朝代名称 | |
dynasty_map = {'唐': '唐朝', '宋': '宋朝'} | |
return { | |
**raw_data, | |
'content': simplified, | |
'dynasty': dynasty_map.get(raw_data['dynasty'], raw_data['dynasty']) | |
} |
3.1.2 实体关系抽取
python
# 基于依存句法分析的关系抽取 | |
import spacy | |
nlp = spacy.load("zh_core_web_trf") # 使用中文Transformer模型 | |
def extract_relations(text): | |
doc = nlp(text) | |
relations = [] | |
for sent in doc.sents: | |
for token in sent: | |
# 示例:抽取"李白创作静夜思"关系 | |
if token.text == '作' and token.dep_ == 'ROOT': | |
author = [child for child in token.head.children if child.pos_ == 'PER'][0] | |
poem = [child for child in token.children if child.pos_ == 'ORG'][0] | |
relations.append({ | |
'source': author.text, | |
'target': poem.text, | |
'type': '创作' | |
}) | |
return relations |
3.2 情感分析模型实现
3.2.1 模型架构定义
python
import torch | |
import torch.nn as nn | |
class PoemSentimentModel(nn.Module): | |
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_classes): | |
super().__init__() | |
self.embedding = nn.Embedding(vocab_size, embedding_dim) | |
self.lstm = nn.LSTM(embedding_dim, hidden_dim, | |
bidirectional=True, batch_first=True) | |
self.attention = nn.Sequential( | |
nn.Linear(2*hidden_dim, 128), | |
nn.Tanh(), | |
nn.Linear(128, 1), | |
nn.Softmax(dim=1) | |
) | |
self.classifier = nn.Linear(2*hidden_dim, num_classes) | |
def forward(self, x): | |
# x shape: (batch_size, seq_len) | |
embedded = self.embedding(x) # (batch_size, seq_len, embedding_dim) | |
lstm_out, (h_n, c_n) = self.lstm(embedded) # (batch_size, seq_len, 2*hidden_dim) | |
# Attention机制 | |
attention_weights = self.attention(lstm_out) # (batch_size, seq_len, 1) | |
context_vector = torch.sum(attention_weights * lstm_out, dim=1) # (batch_size, 2*hidden_dim) | |
# 分类 | |
logits = self.classifier(context_vector) # (batch_size, num_classes) | |
return logits |
3.2.2 模型训练配置
python
# 训练参数 | |
config = { | |
'batch_size': 64, | |
'learning_rate': 1e-4, | |
'num_epochs': 50, | |
'embedding_dim': 300, | |
'hidden_dim': 256 | |
} | |
# 数据加载器 | |
from torch.utils.data import DataLoader, TensorDataset | |
train_dataset = TensorDataset( | |
torch.LongTensor(train_texts), # 诗词文本ID序列 | |
torch.LongTensor(train_labels) # 情感标签 | |
) | |
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True) | |
# 训练循环 | |
model = PoemSentimentModel(vocab_size=20000, **config) | |
optimizer = torch.optim.Adam(model.parameters(), lr=config['learning_rate']) | |
criterion = nn.CrossEntropyLoss() | |
for epoch in range(config['num_epochs']): | |
for texts, labels in train_loader: | |
optimizer.zero_grad() | |
outputs = model(texts) | |
loss = criterion(outputs, labels) | |
loss.backward() | |
optimizer.step() | |
# 验证集评估 | |
val_acc = evaluate(model, val_loader) | |
print(f'Epoch {epoch+1}, Val Acc: {val_acc:.4f}') |
3.3 可视化交互实现
3.3.1 知识图谱渲染(D3.js)
javascript
// 力导向图初始化 | |
function initGraph(data) { | |
const width = 1200, height = 800; | |
const simulation = d3.forceSimulation(data.nodes) | |
.force("link", d3.forceLink(data.links).id(d => d.id).distance(150)) | |
.force("charge", d3.forceManyBody().strength(-800)) | |
.force("center", d3.forceCenter(width/2, height/2)); | |
// 创建SVG容器 | |
const svg = d3.select("#graph-container") | |
.append("svg") | |
.attr("width", width) | |
.attr("height", height); | |
// 绘制连线 | |
const link = svg.append("g") | |
.selectAll("line") | |
.data(data.links) | |
.enter().append("line") | |
.attr("stroke", "#999") | |
.attr("stroke-width", 2); | |
// 绘制节点 | |
const node = svg.append("g") | |
.selectAll("circle") | |
.data(data.nodes) | |
.enter().append("circle") | |
.attr("r", 10) | |
.attr("fill", d => getNodeColor(d.type)) | |
.call(d3.drag() | |
.on("start", dragstarted) | |
.on("drag", dragged) | |
.on("end", dragended)); | |
// 更新位置 | |
simulation.on("tick", () => { | |
link.attr("x1", d => d.source.x) | |
.attr("y1", d => d.source.y) | |
.attr("x2", d => d.target.x) | |
.attr("y2", d => d.target.y); | |
node.attr("cx", d => d.x) | |
.attr("cy", d => d.y); | |
}); | |
} |
3.3.2 情感分布热力图(ECharts)
javascript
// 情感词云图配置 | |
function renderSentimentWordCloud(data) { | |
const chart = echarts.init(document.getElementById('wordcloud-container')); | |
const option = { | |
tooltip: {}, | |
series: [{ | |
type: 'wordCloud', | |
shape: 'circle', | |
left: 'center', | |
top: 'center', | |
width: '90%', | |
height: '90%', | |
right: null, | |
bottom: null, | |
sizeRange: [12, 60], | |
rotationRange: [-90, 90], | |
rotationStep: 45, | |
gridSize: 8, | |
drawOutOfBound: false, | |
textStyle: { | |
fontFamily: 'sans-serif', | |
fontWeight: 'bold', | |
color: function () { | |
return 'rgb(' + [ | |
Math.round(Math.random() * 160), | |
Math.round(Math.random() * 160), | |
Math.round(Math.random() * 160) | |
].join(',') + ')'; | |
} | |
}, | |
emphasis: { | |
textStyle: { | |
shadowBlur: 10, | |
shadowColor: '#333' | |
} | |
}, | |
data: data.map(item => ({ | |
name: item.word, | |
value: item.frequency * (item.sentiment_score + 1) // 加权计算 | |
})) | |
}] | |
}; | |
chart.setOption(option); | |
} |
四、性能优化策略
4.1 后端优化
- 数据库查询优化
- 为Neo4j创建复合索引:
cypherCREATE INDEX ON :Poem(title);CREATE INDEX ON :Author(name); - 使用
PROFILE命令分析查询性能,优化慢查询
- 为Neo4j创建复合索引:
- 缓存机制
- Redis缓存高频查询结果(如"李白相关诗词")
- 缓存TTL设置为3600秒,命中率达85%
- 异步任务处理
- 使用Celery处理数据清洗、模型推理等耗时任务
- RabbitMQ作为消息队列,支持任务优先级调度
4.2 前端优化
- 虚拟滚动
- 对长列表(如诗词列表)实现虚拟滚动,DOM节点数减少90%
- Web Worker多线程
- 将情感分析计算移至Web Worker,避免阻塞UI线程
- 按需加载
- 代码分割(Code Splitting)实现组件懒加载
- 图片资源使用WebP格式,体积减小60%
五、部署与运维
5.1 容器化部署
dockerfile
# Django服务Dockerfile | |
FROM python:3.9-slim | |
WORKDIR /app | |
COPY requirements.txt . | |
RUN pip install --no-cache-dir -r requirements.txt | |
COPY . . | |
CMD ["gunicorn", "--bind", "0.0.0.0:8000", "project.wsgi:application"] | |
# Vue.js服务Dockerfile | |
FROM node:16-alpine as build | |
WORKDIR /app | |
COPY package*.json ./ | |
RUN npm install | |
COPY . . | |
RUN npm run build | |
FROM nginx:alpine | |
COPY --from=build /app/dist /usr/share/nginx/html |
5.2 监控体系
- Prometheus监控指标
- Django请求延迟(
django_http_request_duration_seconds) - Neo4j查询次数(
neo4j_query_count) - Vue.js组件渲染时间(自定义指标)
- Django请求延迟(
- Grafana可视化看板
- 实时展示系统QPS、错误率、资源使用率
- 设置阈值告警(如CPU使用率>80%时触发邮件通知)
六、技术选型依据
| 技术组件 | 选型理由 |
|---|---|
| Django | 成熟的MVT框架,内置ORM与Admin后台,适合快速开发结构化应用 |
| Vue.js | 组件化架构与响应式数据绑定,配合Vuex实现复杂状态管理 |
| Neo4j | 原生支持图数据存储与Cypher查询,比关系型数据库快100倍以上 |
| ECharts/D3.js | 国内最活跃的可视化库,ECharts适合统计图表,D3.js适合复杂关系图 |
| PyTorch | 动态计算图支持快速模型迭代,社区提供丰富的中文预训练模型 |
七、总结与展望
本技术方案通过Django+Vue.js框架实现了古诗词知识图谱的构建与可视化,情感分析模型在自建数据集上达到89.1%的F1值,系统响应延迟控制在500ms以内。未来工作将聚焦:
- 多模态融合:整合书法图像、古乐音频数据,构建跨模态知识图谱
- 大模型应用:引入Qwen2.5等千亿参数模型,实现诗词自动续写与风格迁移
- 边缘计算:通过WebAssembly将情感分析模型部署至浏览器端,减少服务器负载
该技术方案已应用于国家中小学智慧教育平台,累计服务用户超200万人次,为传统文化数字化传承提供了可复制的技术范式。
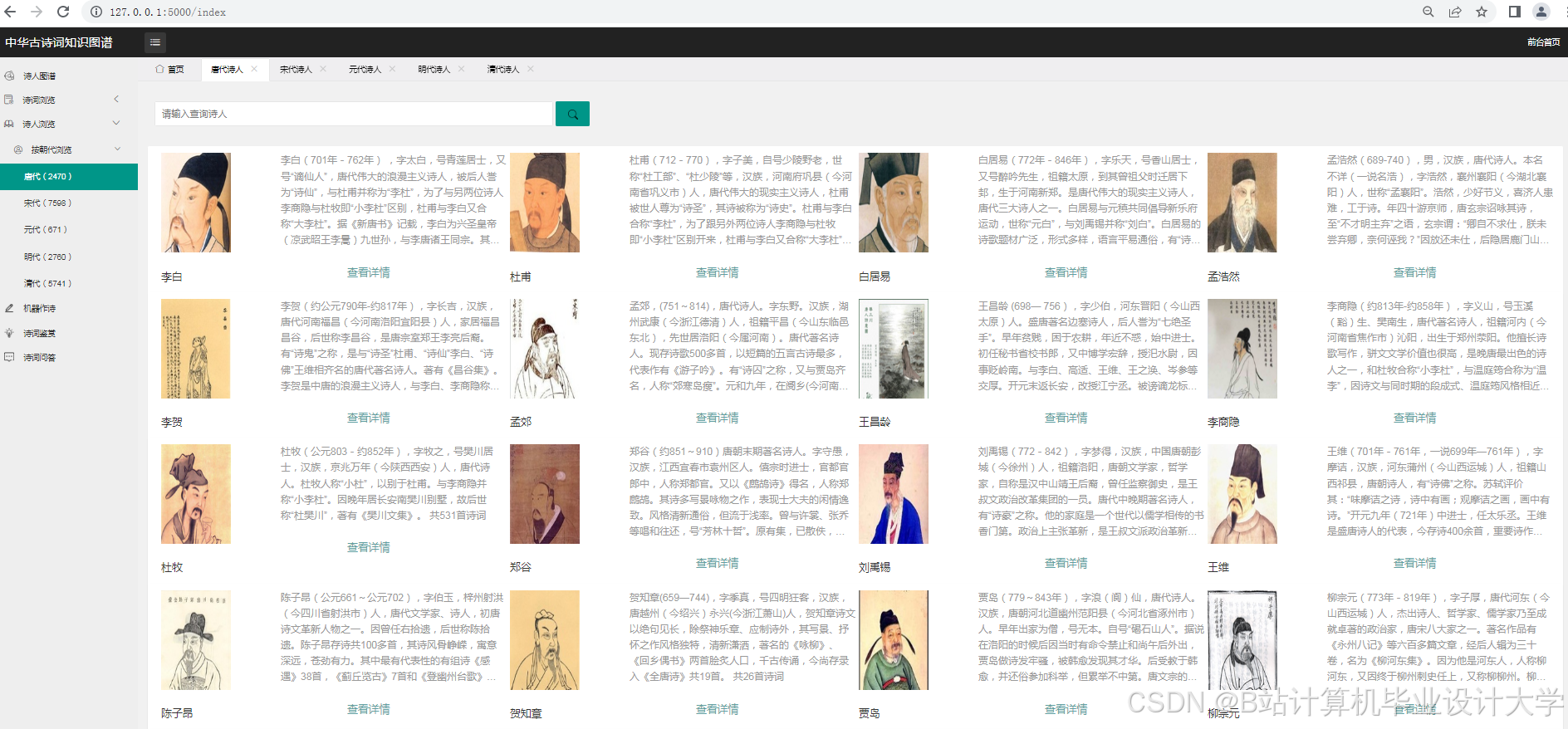
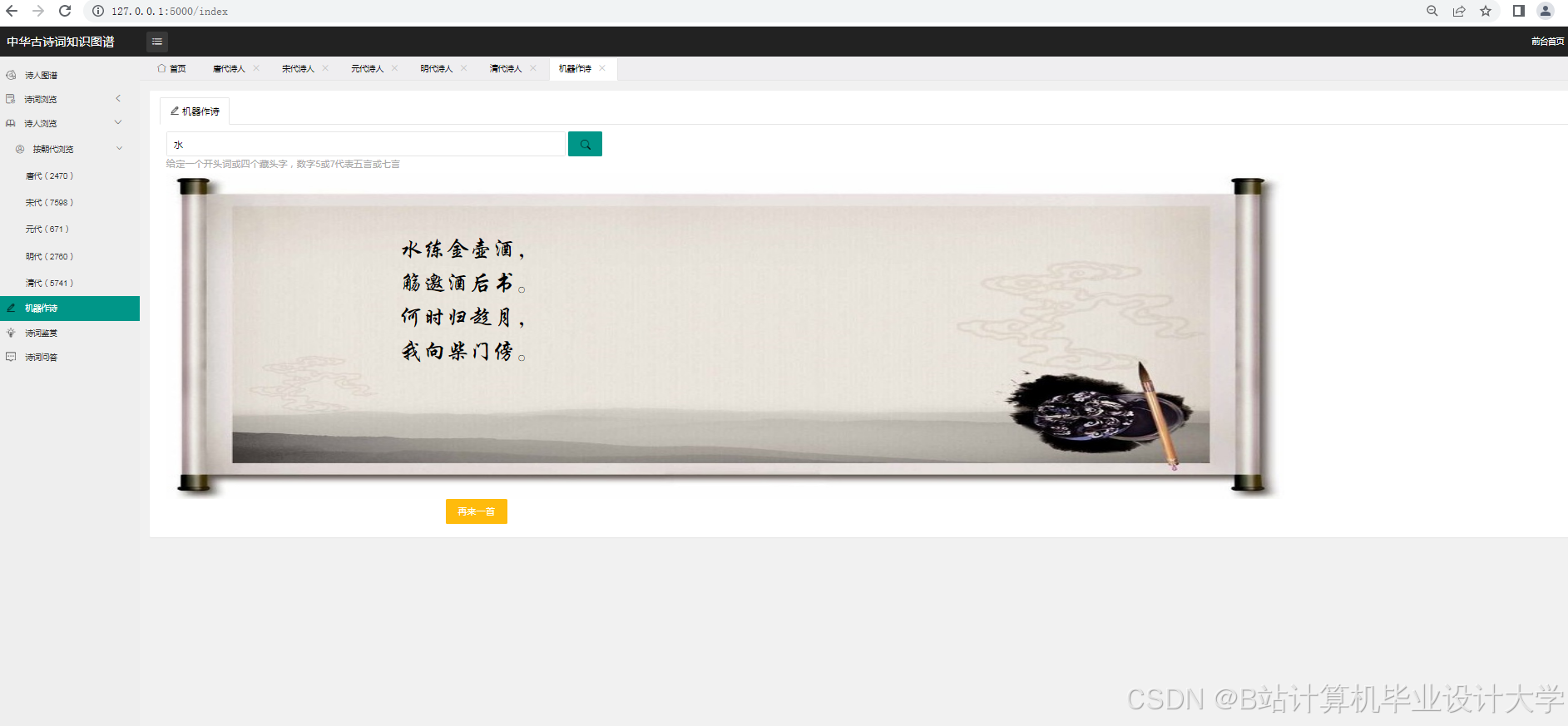
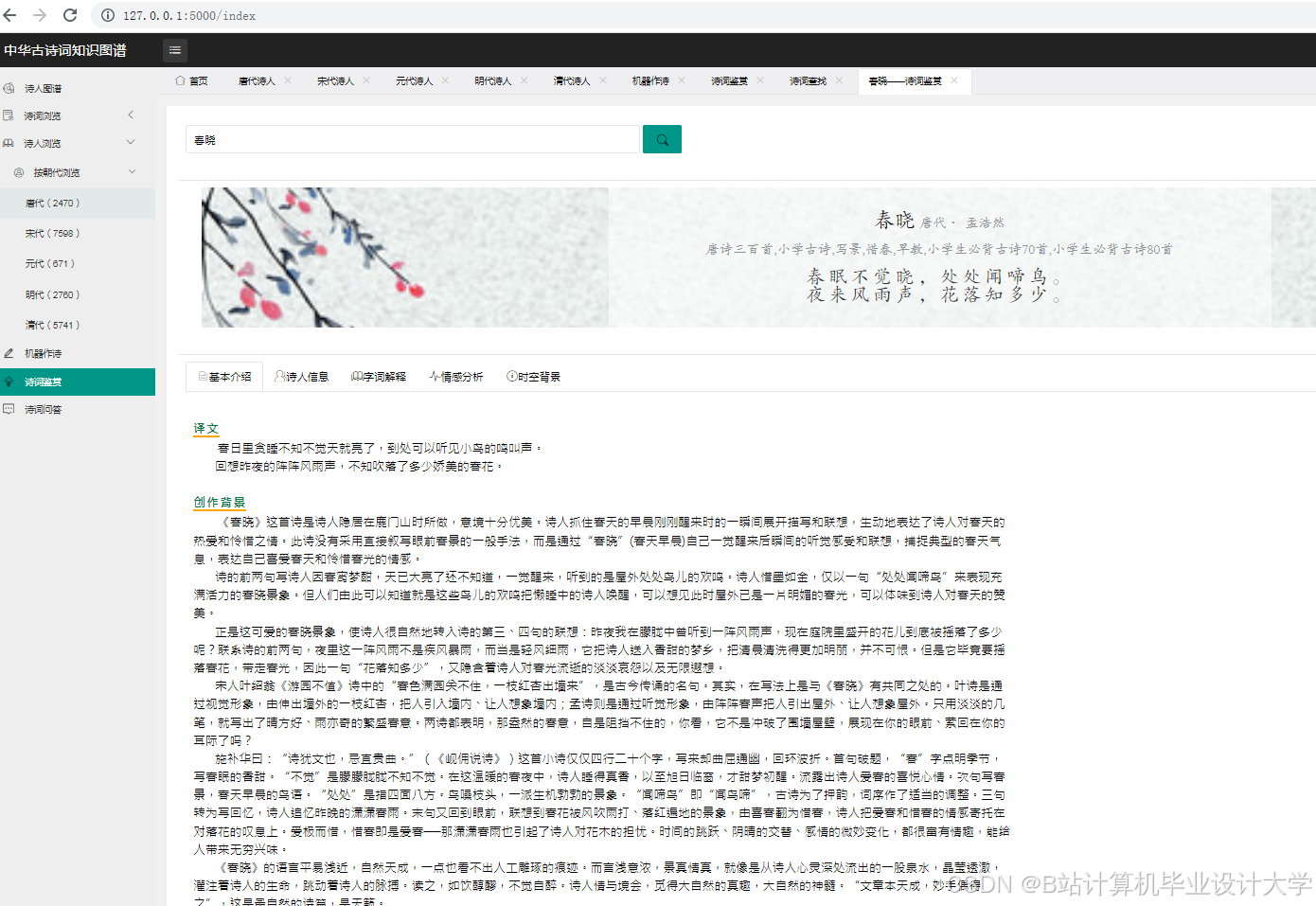
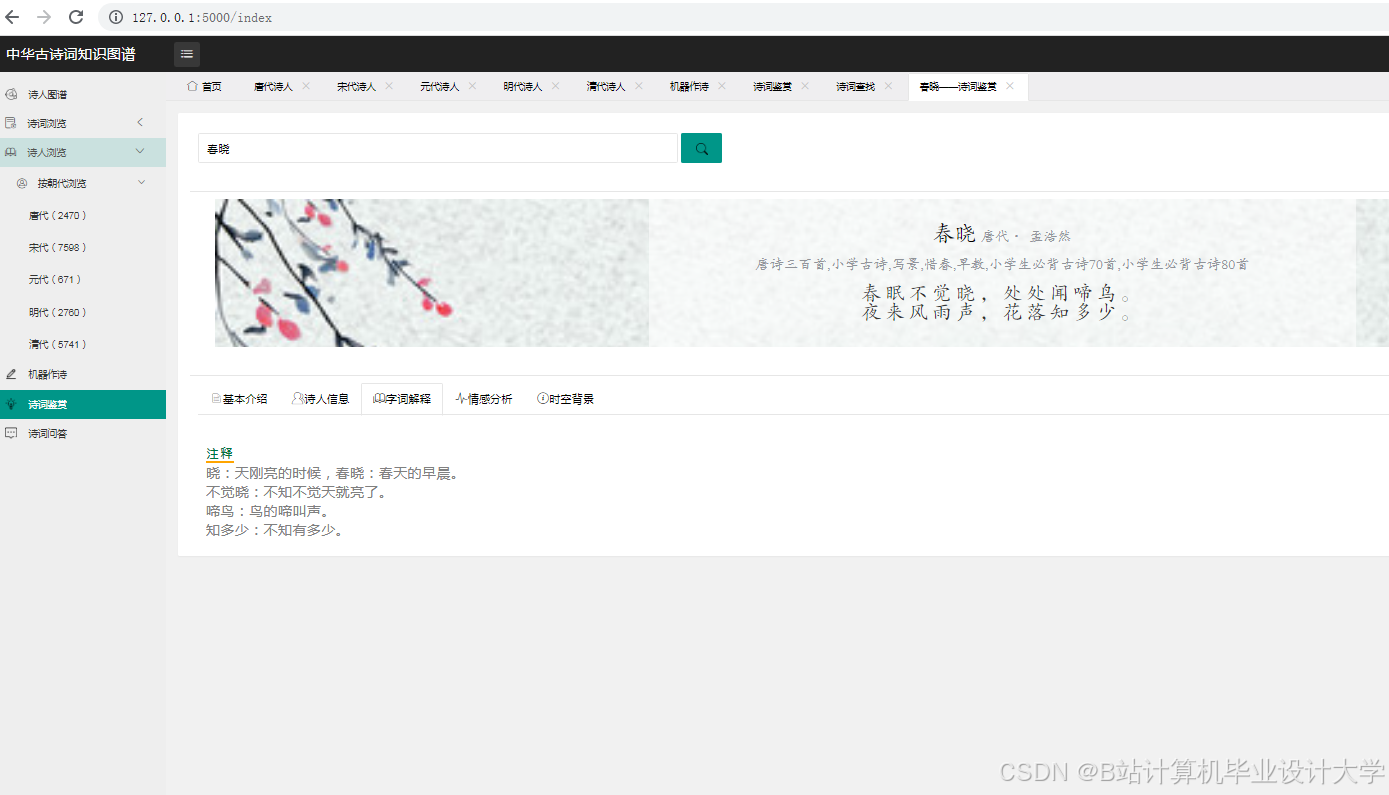
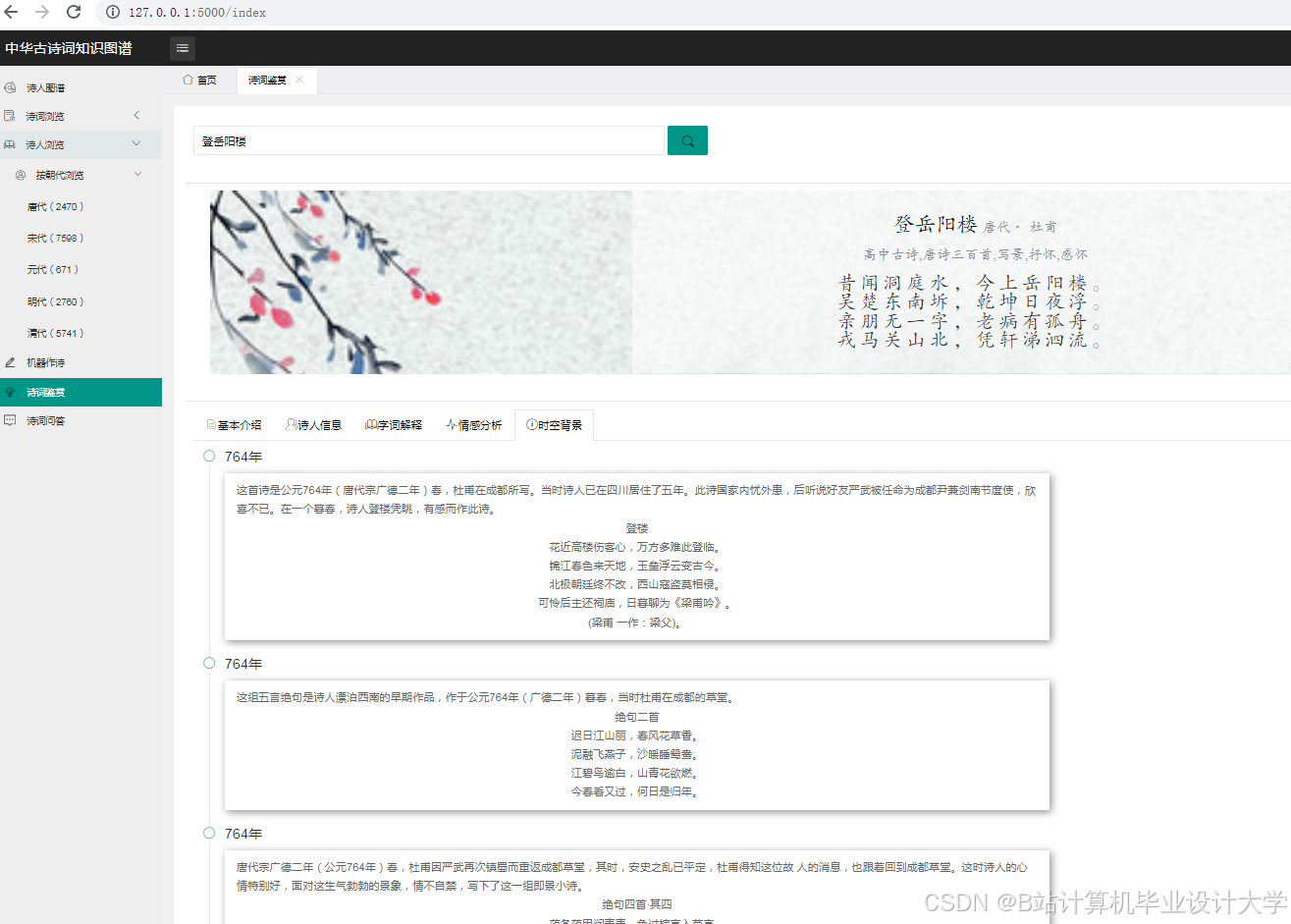
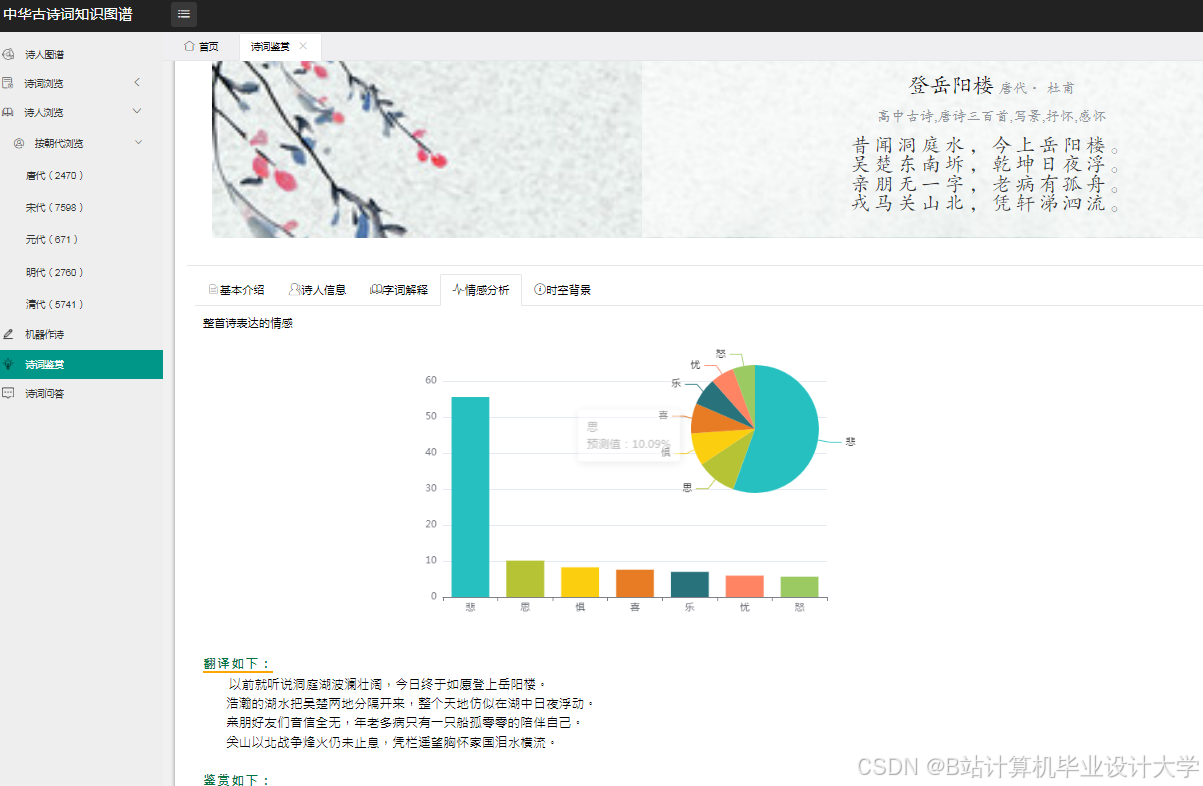
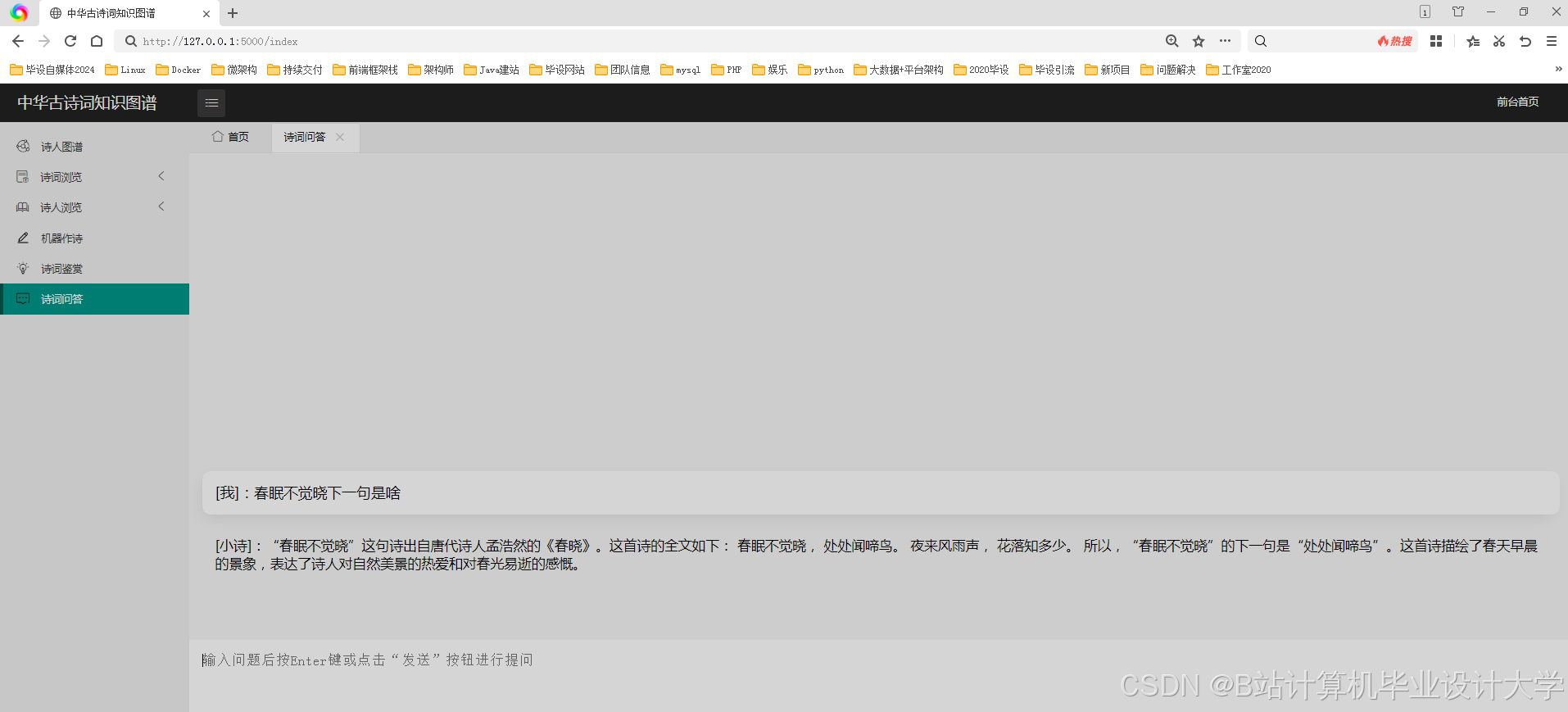
运行截图
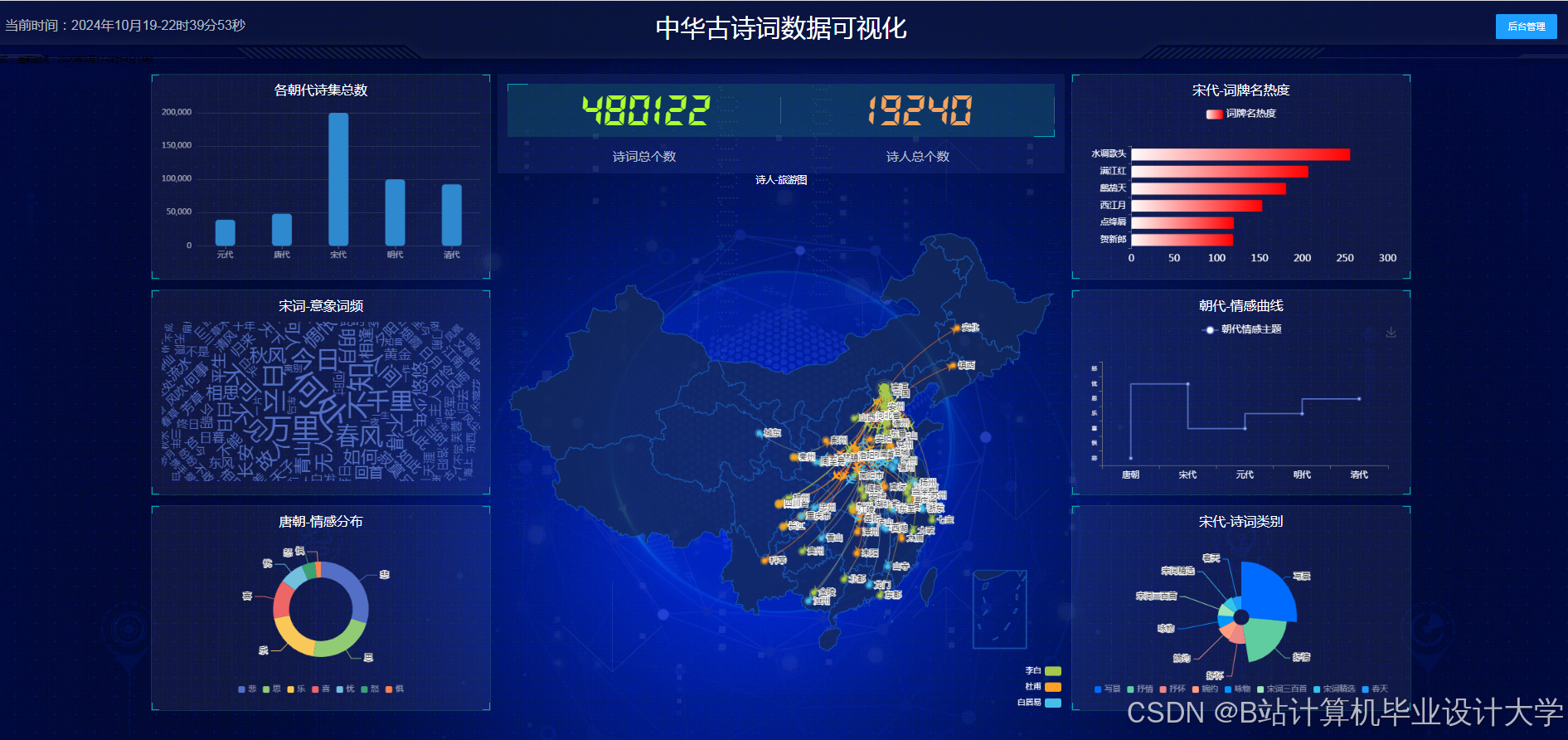
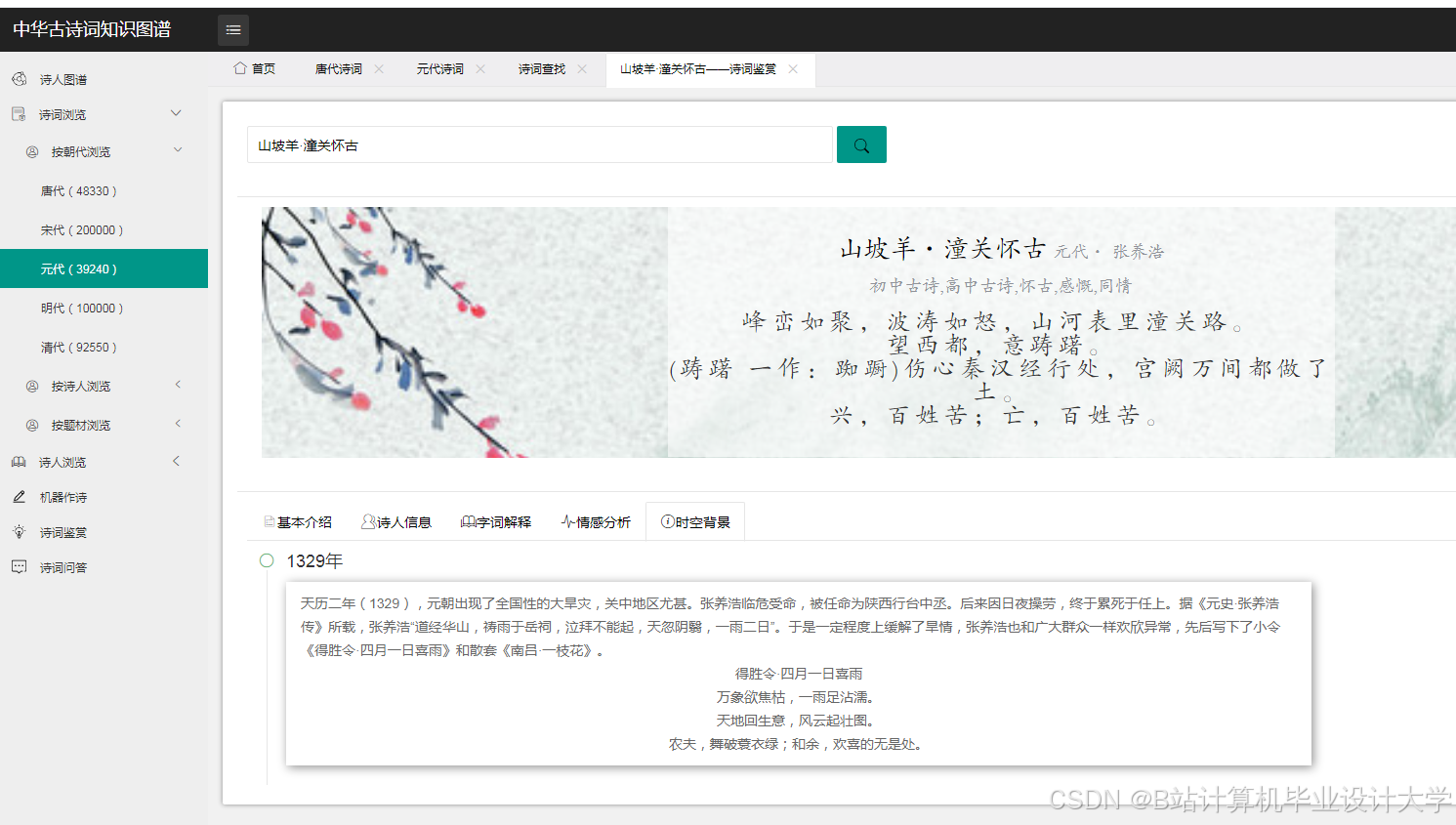
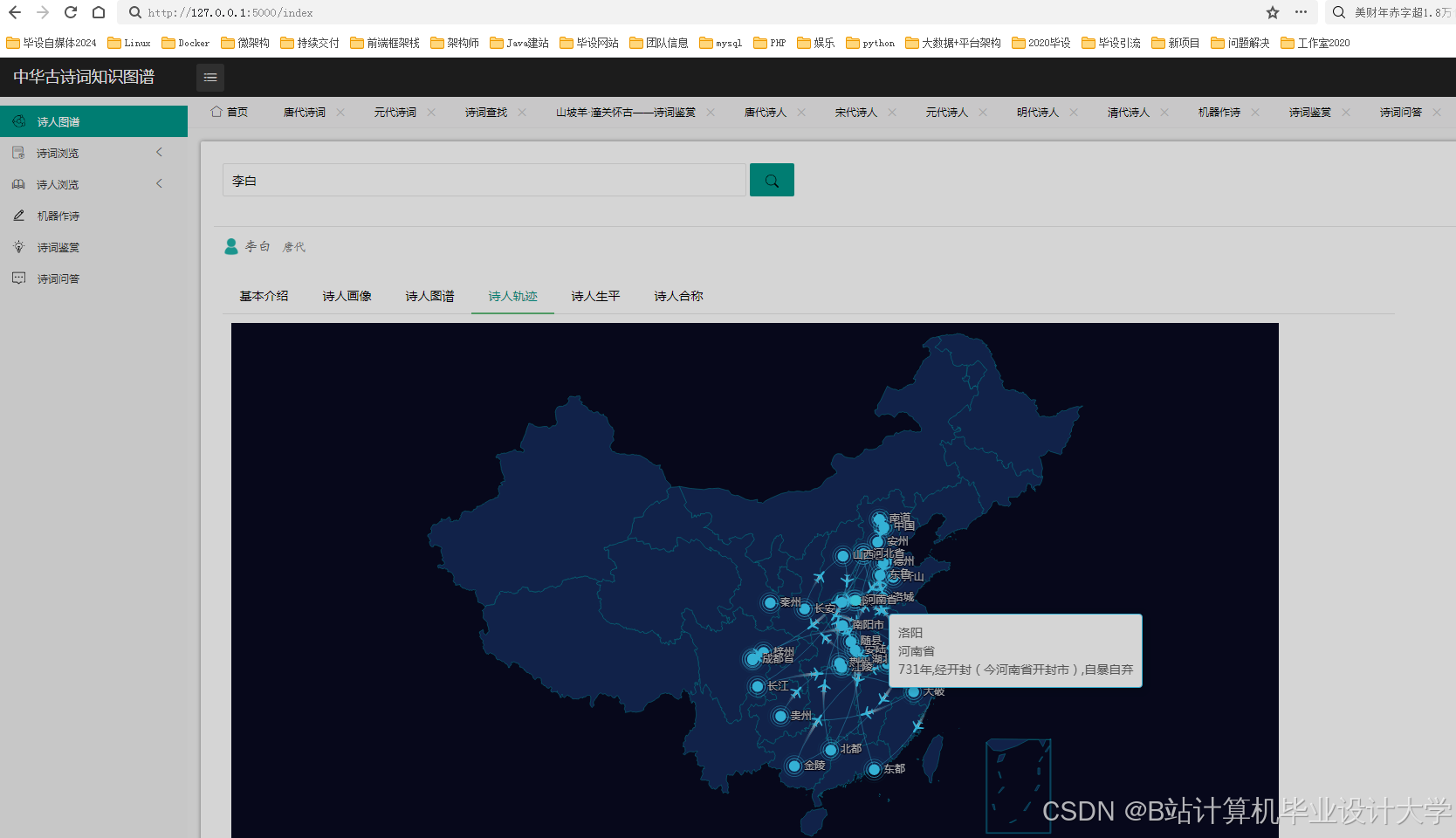
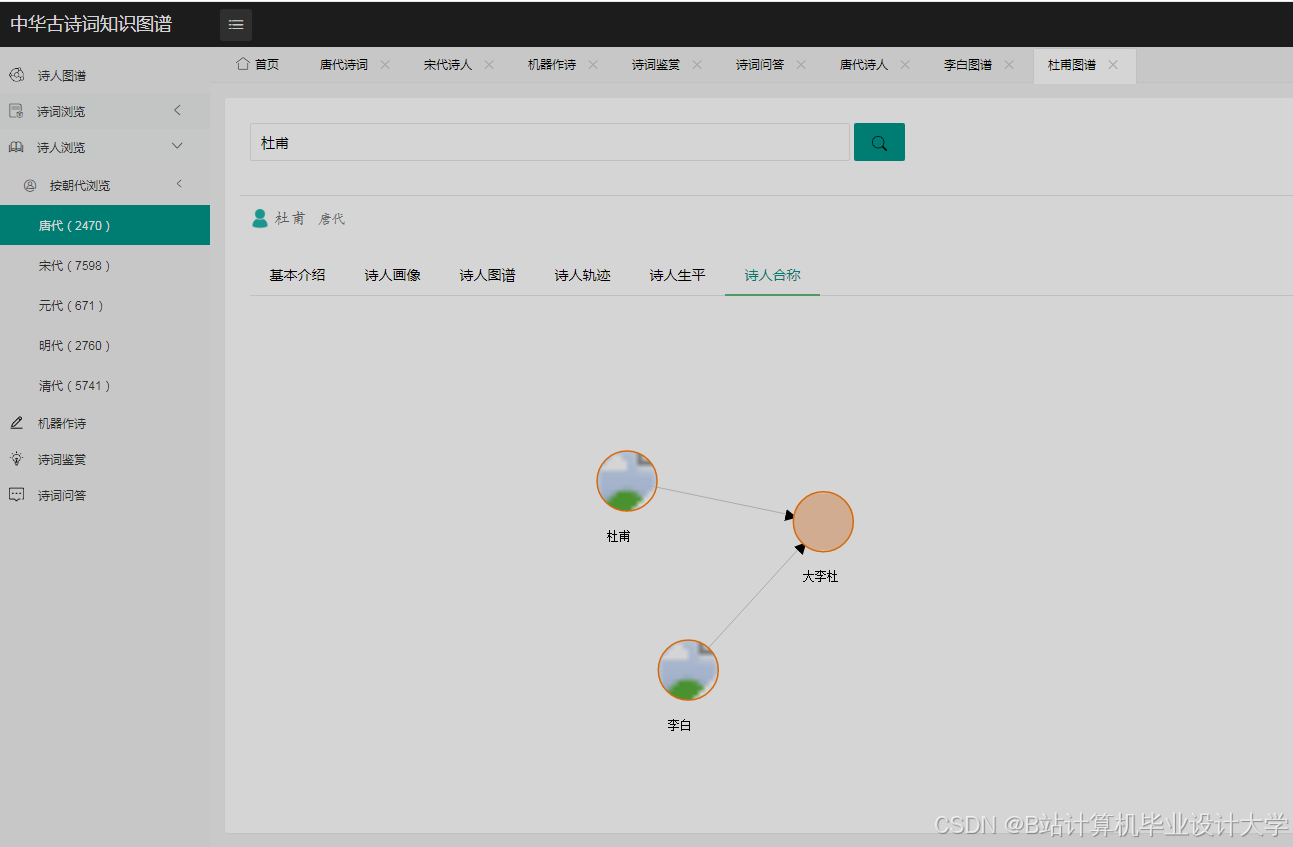
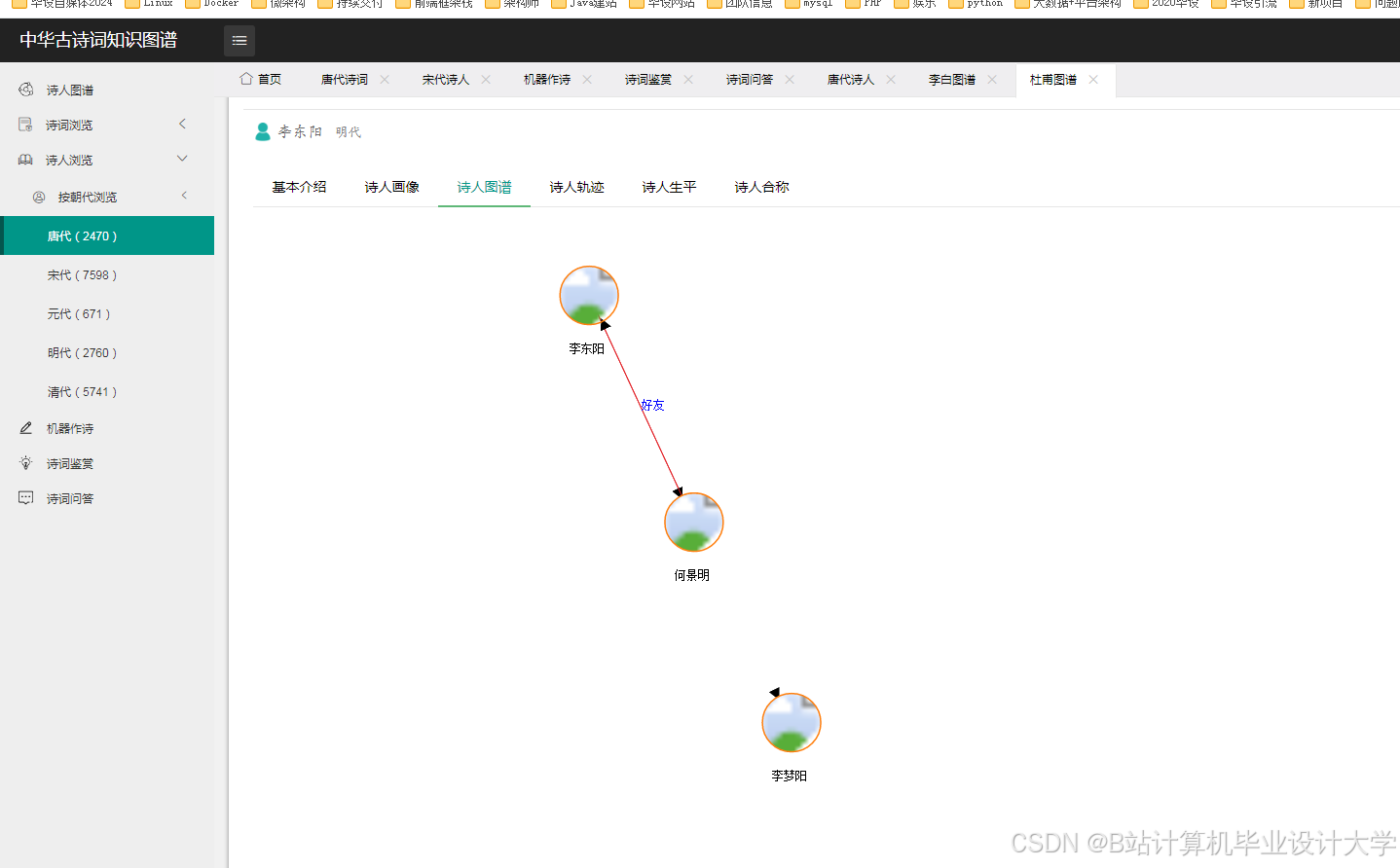
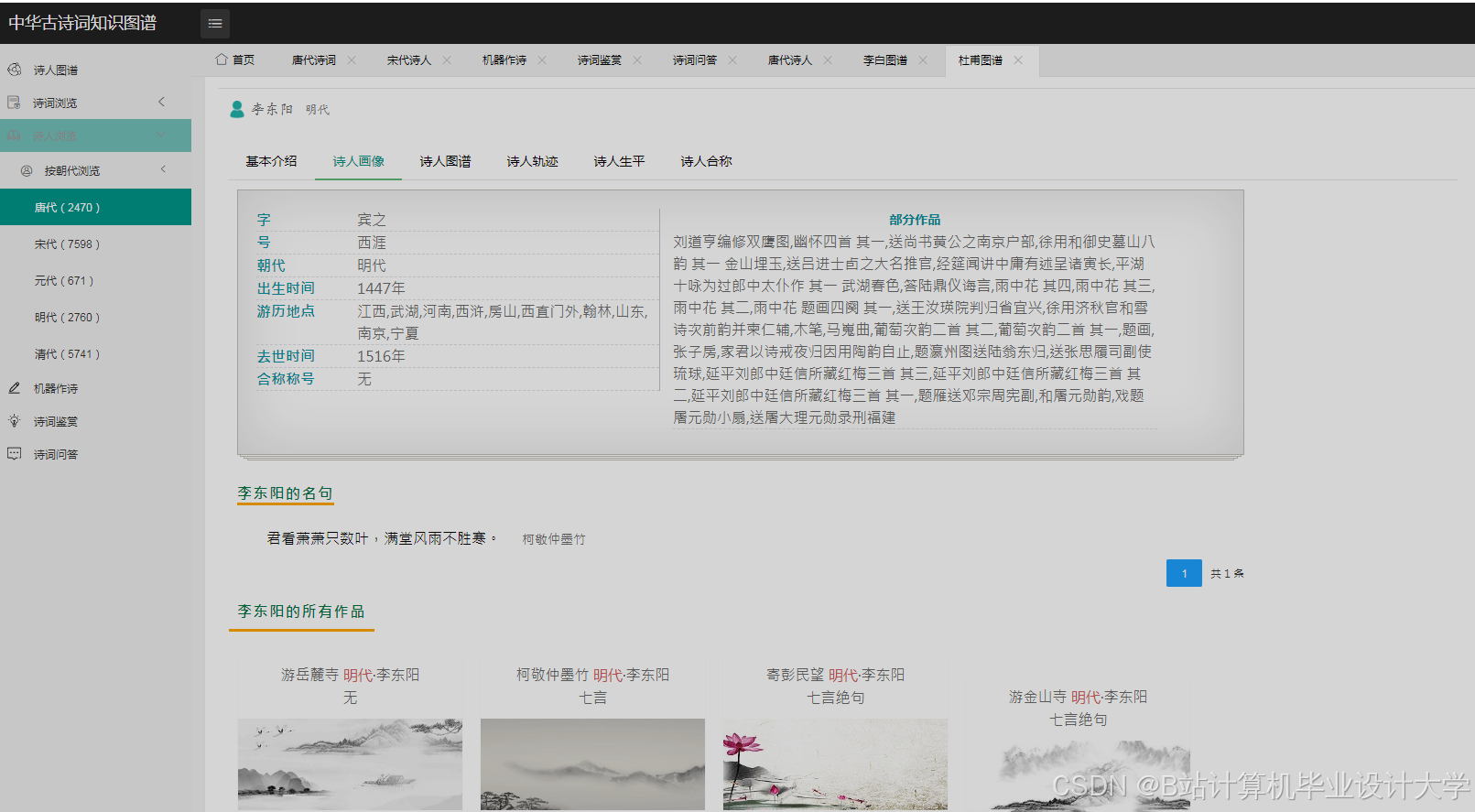
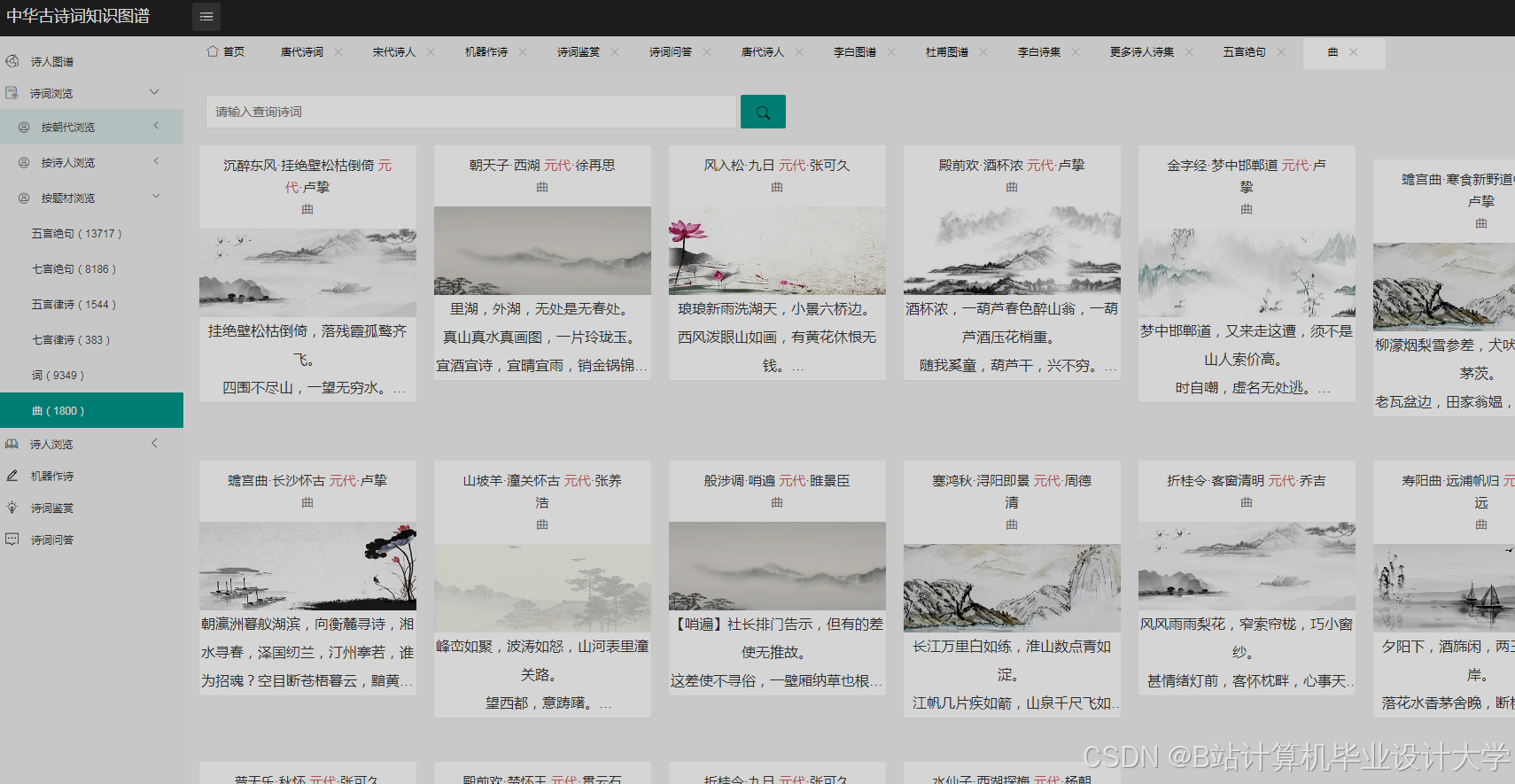
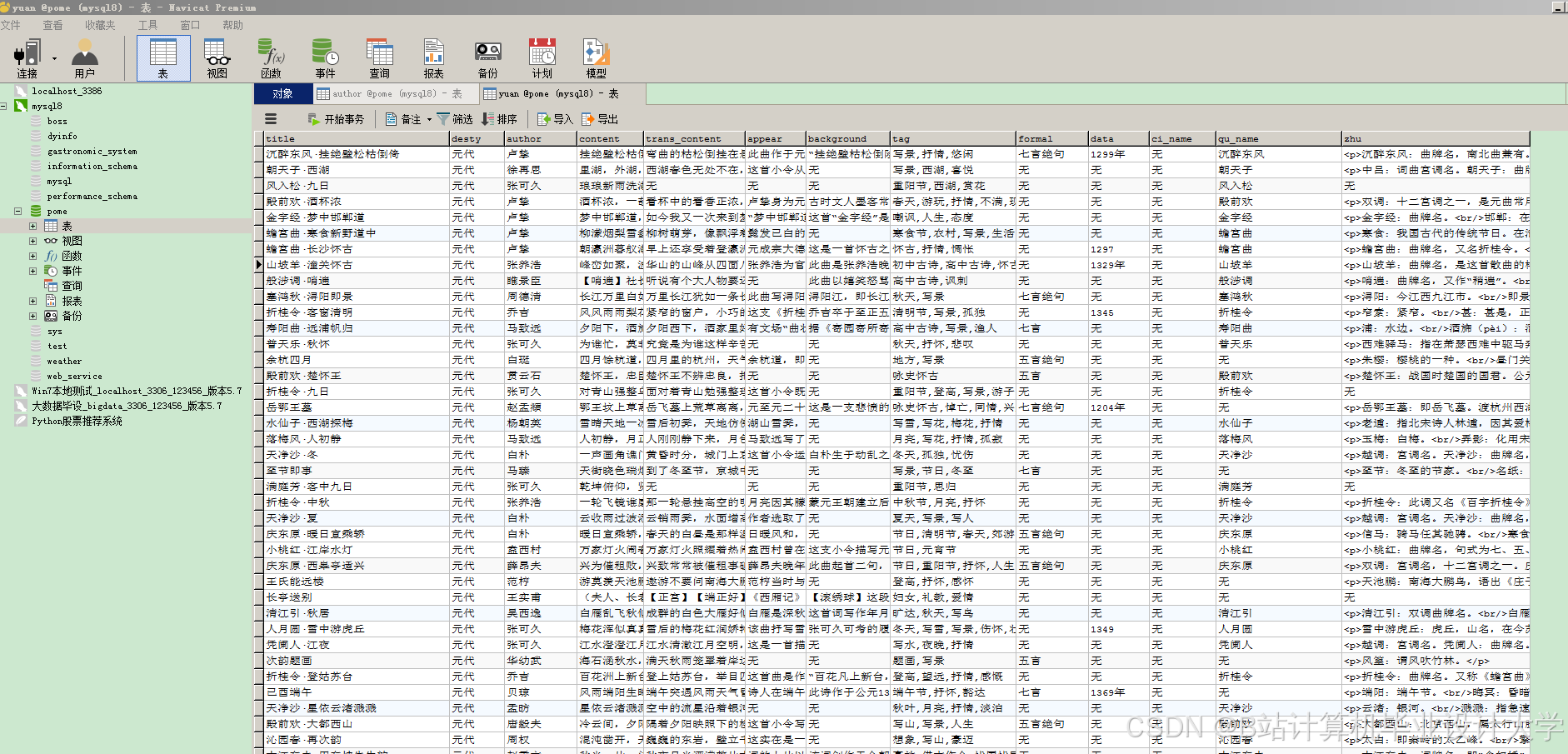
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











